
Основная цель статьи — поделиться практическим опытом создания и анализа индексов с помощью Spark SQL. Разумеется, это настолько обширная тема, что данная статья только поверхностно коснётся основных подходов в контексте упомянутой задачи. Создание индексов часто требуется после сложного анализа огромного числа документов. Допустим, аналитическая система записывает в лог уникальный идентификатор документа и ряд его метрик. Необходимо проанализировать этот отчёт, чтобы выбрать только необходимые идентификаторы документов.
Прежде всего, начну с некоторых самых базовых вещей. Из учебников мы помним, что индексом называет особый объект базы данных, который специально придуман для ускорения поиска. Вначале взглянем на индекс типа HASH. Он частенько используется в счётчиках со следующей логикой работы: при наступлении отслеживаемого события мы не создаём новую запись, а инкрементируем существующую.
Получение, добавление или удаление из хэш-таблиц (первое упоминание ещё в 1953 году) в среднем составляет О(1). Когда мы используем Redis, Memcached, Coherence и Tarantool, то сталкиваемся с подобным индексом (получая информацию из хранилища данных типа «ключ — значение»). Посмотрим на следующий пример (tarantool):
area = box.schema.space.create('area')
area:create_index('primary', {type = 'hash', parts = {1, 'NUM'} })
area:insert({1, 'Aaa', 'Bbb', 'Ccc', 'Ddd'})
area:insert({2, 'F1', 'F2'})
area:insert({3, 'H', 'A', 'B', 'R', 100, 1000, 20, 30, 40, 50, 60, 70, 80})
area:select{3}Как видно, tarantool использует первичный ключ типа HASH (есть и другие, такие как: TREE, BITSET и RTREE). Более того, первичный ключ должен быть у всех кортежей. Добавленные записи хранятся не в таблицах, а в так называемых пространствах (space).
Когда речь идёт о реляционной базе данных, то системе приходится обойти все записи в таблице. По логике работы простой SELECT должен пройти каждый кортеж (tuple) из нужной relational (таблица) и проверить указанные в WHERE условия добавления кортежей в результирующее подмножество. Похожим образом работает механизм соединения JOIN (для каждого кортежа найти соответствие ON в другой таблице с помощью вложенного цикла).
В реляционных базах данных часто сталкиваемся с BTREE. На самом деле, кластерный индекс легче представить не как справочник, а как структуру хранения данных (самой таблицы). Именно по этой причине нельзя создать для одной таблицы более одного кластерного индекса, но можно создать несколько индексов другого типа. Более того, без кластерного индекса не обходится ни одна таблица на движке InnoDB. Даже, если вы не создадите никаких индексов, то она сама создаст скрытый суррогатный ключ.
Кстати, при поиске по вторичному индексу логика работы РСУБД потребует два обхода: достать из вторичного индекса идентификаторы, соответствующие условию фильтрации, а потом достать из кластерного индекса (по найденным ID) нужные кортежи. Самое главное, что индексы помогают избежать полного сканирования (это будет видно в EXPLAIN). Это также помогает РСУБД более эффективно выполнять JOIN (при соединении индексы используются не только в алгоритмах объединения с помощью вложенных циклов, но и в алгоритмах хэш-объединения, а также в алгоритмах объединения слиянием). А как быть, если невероятно огромный набор данных не подходит для РСУБД? Более того, данные плохо структурированы и требуют первичной обработки сложными алгоритмами.
А вот в поисковых системах (Sphinx, Solr, Elasticsearch, Lucene, Endeca MDEX Engine) повсеместно используется и другой вид индексов. Я могу очень быстро найти все документы, в которых встречается нужное слово. При условии, что у меня есть соответствующий справочник. Как вы уже догадались, я говорю о такой структуре данных, которая называется inverted index (инвертированный индекс). Она напоминает ассоциативный массив, где в качестве ключа указан идентификатор объекта, а в качестве значения перечислены идентификаторы документов, в которых он встретился.
Часто инвертированный индекс ассоциируется исключительно с поисковыми системами, однако, подобная структура данных активно применяется в сложных системах автоматической классификации, где есть большое число подгрупп. Даже когда мы в MySQL выводим (с применением классического many-to-many relationship) список всех объектов в группе, то получаем некое подобие инвертированного индекса:
CREATE TABLE `example_doc` (
`example_id` int(10) NOT NULL,
`doc_id` int(10) NOT NULL,
PRIMARY KEY (`example_id`,`doc_id`)
)
CREATE TABLE `example` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
)
CREATE TABLE `doc` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
)
-- Схематическая имитация inverted index
SELECT e.`name`, GROUP_CONCAT(d.`name`)
FROM example_doc ed
JOIN example e ON e.`id` = ed.`example_id`
JOIN doc d ON d.`id` = ed.`doc_id`
GROUP BY ed.`example_id`;А теперь перейдём к более правдоподобному примеру. Допустим, существует некое огромное хранилище. Может быть это Apache Cassandra, а может и совсем иное решение. Есть набор документов, о которых мы ничего не знаем. Там только идентификатор и текст самого документа. Мы только знаем, что это обычный текст. Далее привожу пример структуры для Cassandra (самое забавное, что глядя на подобный пример не сразу догадаешься, что за система используется):
CREATE TABLE docs (
id int,
content text,
PRIMARY KEY (id));
INSERT INTO docs (id, content) VALUES (1, 'Aaa');
INSERT INTO docs (id, content) VALUES (2, 'Bbb');
INSERT INTO docs (id, content) VALUES (3, 'Ccc');
SELECT * FROM docs WHERE id IN (1, 2, 3);По условиям задачи известно, что все эти документы обрабатываются невероятно сложным набором алгоритмов (предположим, что там целый ансамбль: Random Forests, Gradient-Boosted Trees, Correlations, Logistic regression, Linear regression, Alternating least squares и множество иных сложных алгоритмов). Разумеется, всё это работает не самым быстрым образом. После обработки система сохраняет отчёт: идентификатор документа, класс, группа, тип и другие характеристики.
Индекс может формироваться в момент импорта данных. Допустим, не исключена ситуация, когда некий компонент импорта записывает (по условию) в лог идентификаторы и некоторые характеристики документов. Используя этот лог можно получить необходимые данные для формирования индекса, допустим, список идентификаторов документов заданного класса. Для наглядности можно привести такой схематический пример на PHP (для упрощения он просто импортирует один документ и только его текст):
/**
* По условиям задачи мы получаем некий документ.
*/
interface ImportInterface
{
/**
* Возвращает текст документа.
*
* @return string основной контент
*/
public function getContent();
}
/**
* Класс, который отвечает за получение и первичную обработку нужных данных.
*/
class ImportOne implements ImportInterface
{
use ImportHelper;
/**
*
* @var string параметры получения данных
*/
const CONTENT_TYPE = 'нужные параметры #1';
/**
* Логика получение данных соответствующего типа (запросы и обработка).
*
* @return string основной контент
*/
public function getContent()
{
// В момент обработки может быть запись в лог неких метрик документа.
return $this->import(self::CONTENT_TYPE);
}
}
/**
* Класс, который отвечает за получение и первичную обработку нужных данных.
*/
class ImportTwo implements ImportInterface
{
use ImportHelper;
/**
*
* @var string параметры получения данных
*/
const CONTENT_TYPE = 'нужные параметры #2';
/**
* Логика получение данных соответствующего типа (запросы и обработка).
*
* @return string основной контент
*/
public function getContent()
{
// В момент обработки может быть запись в лог неких метрик документа.
return $this->import(self::CONTENT_TYPE);
}
}
/**
* Клиент.
*/
class ImportClient
{
/**
*
* @var ImportInterface тип импорта
*/
private $importType;
/**
*
* @param ImportInterface $importType
*/
public function setType(ImportInterface $importType)
{
$this->importType = $importType;
}
/**
*
* @return string основной контент
*/
public function getContent()
{
return $this->importType->getContent();
}
}
/**
* Вспомогательный trait для получения данных.
*/
trait ImportHelper
{
/**
* Используем коннектор для запроса данных.
*
* @param string $query
* @return string
*/
public function import($query = 'name')
{
return $query; // реализация...
}
}
/**
* Проверим написанный код.
*/
$client = new ImportClient();
foreach (['ImportOne', 'ImportTwo'] as $type) {
$client->setType(new $type());
var_dump($client->getContent());
}Или другой пример. Допустим происходит сканирование (обход с помощью crawler) большого числа документов в интернет. Для этого могут быть использованы различные технологии. Если нужно эмитировать работу браузера (например, мы хотим сохранить скриншот или увидеть результат работы JavaScript), то нередко используют PhantomJS или Selenium. Вот только это медленный способ. Для быстрого обхода применяют Jsoup (совместно с Google Guava) и другие решения (не буду перечислять коммерческие, чтобы не было скрытой рекламы). Тут тоже можно привести схематический пример на JAVA:
/**
* Для упрощения примера паук умеет только сканировать.
*/
public interface ICrawler {
void scan(String url);
}
/**
* Реализация некой логики сканирования и создания отчёта.
*/
public class OldCrawler implements ICrawler {
@Override
public void scan(String url) {
System.out.println("OldCrawler: " + url);
}
}
/**
* Реализация другой логики сканирования и создания отчёта.
*/
public class NewCrawler implements ICrawler {
@Override
public void scan(String url) {
System.out.println("NewCrawler: " + url);
}
}
/**
* Strategy предполагает создание класса контекста.
*/
public class Context {
private ICrawler crawler;
public Context(ICrawler crawler){
this.crawler = crawler;
}
public void run(String url) {
crawler.scan(url);
}
}
/**
* Проверим написанный код.
*/
public class Run {
public static void main(String []args) {
List<Context> contextList = new ArrayList<Context>();
contextList.add(new Context(new OldCrawler()));
contextList.add(new Context(new NewCrawler()));
for (Context context : contextList) {
context.run("Habr :-)");
}
}
}В реальной системе принцип работы аналогичный. Только там несколько потоков на каждом сервере и весьма много серверов. Предположим, что в результате работы будет сформирован очень большой лог. Первым делом, необходимо изучить этот отчёт (лог).
Иногда для обработки данных используют такие решения как ClickHouse или Tarantool (если на Lua писать логику). Часто бывает, что для получения относительно небольших наборов данных (несколько тысяч кортежей) необходимо проанализировать астрономически большой dataset. Именно подобная обработка сверхбольших объёмов информации требует использования специальных суперкомпьютеров, которые состоят из внушительных кластеров. Весьма часто подобные решения делают на базе Hadoop, у которого есть надстройки Impala, Drill и Spark SQL. Вот именно об Spark SQL я и постараюсь рассказать чуть более подробно.
У Spark есть компонент, который позволяет использовать стандартный синтаксис запросов SQL. Для начала попробуем получить небольшой набор данных из файла формата JSON. Запустим на исполнение несколько запросов, которые первые пришли мне в голову. Вот простой пример на Scala:
val log = sqlContext.read.json(jsonFile)
log.printSchema()
log.registerTempTable("log")
val sqlQueryList = List(
"SELECT * FROM log",
"SELECT MAX(id) max FROM log",
"SELECT id AS `Max ID` FROM log ORDER BY id DESC LIMIT 1",
"SELECT l1.id AS `Max ID` FROM log l1 LEFT JOIN log l2 ON l1.id < l2.id WHERE l2.id IS NULL",
"SELECT user_id, COUNT(event_id) cnt FROM log GROUP BY user_id HAVING cnt >= 2",
"SELECT SUM(id), MIN(id), AVG(id), STDDEV_POP(id) FROM log",
"SELECT id, LOG(id), TAN(id), BIN(id), CONCAT('X = ', 3/4 * PI() * POW(id, 3)) FROM log"
)
for (sqlQuery <- sqlQueryList) {
println(sqlQuery)
sqlContext.sql(sqlQuery).show
}Вывод в консоль будет следующий:
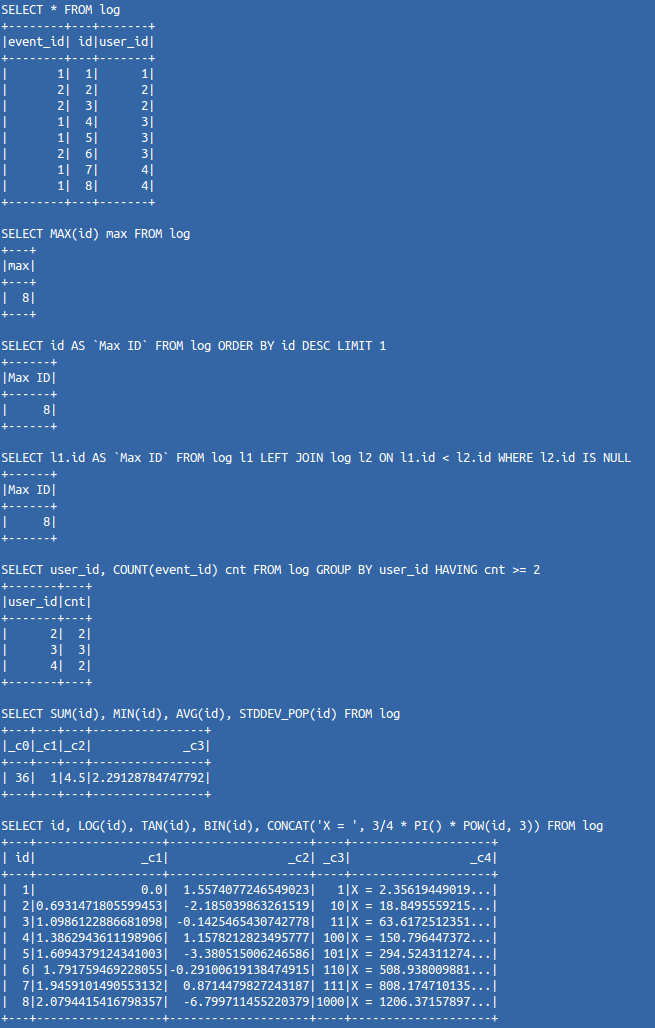
Конечно, его возможности не ограничиваются загрузкой данных из JSON файлов. Для создания более сложного функционала нам не потребуется писать много кода. Spark сделает основную часть работы самостоятельно. А язык программирования Scala позволяет буквально одной строкой создать объект хранения данных:
case class Log(docId: Int, typeId: Int)Как вы можете видеть, в качестве атрибутов используются только идентификаторы. Нет никакого смысла для подобной задачи хранить в памяти избыточную информацию. Теперь загрузка и преобразование в DataFrame:
val df = sc.textFile(logFile).map(_.split(",")).map(p => Log(p(0).trim.toInt, p(1).trim.toInt)).toDF()Вот и всё. Теперь можно начинать работу с данными. Прежде всего, попробуем проверить работоспособность на небольшом объёме данных. Исполним указанный код:
df.showДанные уже структурированы как таблица базы данных. У них тоже есть схема, которую мы можем посмотреть с помощью команды:
df.printSchemaТеоретически, мы ожидаем, что все идентификаторы документов будут уникальными. Посмотрим общее количество идентификаторов документа, а также количество уникальных идентификаторов документа:
df.select("docId").count
df.select("docId").distinct.countЗамечательно. Теперь мне интересно сгруппировать по идентификатору типа все записи. Посмотрю на количество:
df.groupBy("typeId").count.showХотелось бы взглянуть на некоторые документы заданного типа:
df.filter(df("typeId").equalTo(1)).showВесьма круто (извиняюсь за оценочное суждение с эмоциональной окраской) получается в интерактивном режиме делать запросы и сразу видеть результат, как при работе с обычной базой данных.
В реальной задаче всё оказалось намного проще, чем мне представлялось. Обработка логов с помощью Spark SQL субъективно показалась мне удобной. Он использовался для ручного анализа в интерактивном режиме. Этого было достаточно, чтобы сформировать правила создания нужных индексов, которые использовала специальная система (In-memory database), чтобы помогать быстро искать идентификаторы объектов по заданным метрикам. Проект невероятно сильно нагружен (даже два очень больших кластера от усталости бросают с помощью Zabbix кучи SMS).
Ради интереса я запустил обработку (для эксперимента взял файл лога размером в 18 Гб) на ноутбуке. Примерно десять минут и всё готово (процесс работы можно наблюдать через удобный интерфейс: http://127.0.0.1:4040/jobs/).
case class Doc(alias: String, classId: Int, typeId: Int)
val data = sc.textFile(bigFile).map(_.split("\\|"))
val docs = data.map(p => Doc(p(0).trim, p(1).trim.toInt, p(2).trim.toInt))
val df = docs.toDF()
df.show
df.printSchema
df.groupBy("classId").count.show
df.registerTempTable("docs")
sqlContext.sql("SELECT COUNT(alias) FROM docs WHERE typeId = 99999").showС использованием полученных в результате анализа идентификаторов документов производится импорт только подходящих материалов в обычную реляционную базу данных. Поиск в ней осуществляется не по первичному ключу, а по иному атрибуту. У алиаса (мы будем искать по нему) очень хорошее cardinality. Алиас по логике должен быть уникальным. Как известно, термином cardinality обозначают мощность множества (количество кортежей, принадлежащих таблице). Однако, для индекса это не просто количество строк, а количество уникальных значений поля.
Для наглядности пример. Создавая контроллер, мы знаем, какие параметры необходимо передавать в адресной строке клиента. Контроллер принимает параметры и вызывает модель, которая отвечает за запрос в базу данных. Следовательно, миграция для этой модели должна содержать индексы, оптимизирующие таблицу под этот запрос. Небольшой пример на Yii2 (PHP). И так. На странице выводится содержимое документа:
/**
* @var frontend\widgets\EncyclopediaWidget $this->context
*/
use yii\helpers\Html;
?>
<h1><?= Html::encode($this->context->title) ?></h1>
<div class="well">
<?= $this->context->content ?>
</div>Предположим, что это представление принадлежит вот такому виджету:
namespace frontend\widgets;
use yii\base\Widget;
/**
* Виджет для Encyclopedia
*
* @author Kalinin Alexandr
*/
class EncyclopediaWidget extends Widget
{
/**
* @var string заголовок заметки
*/
public $title;
/**
* @var string содержимое заметки
*/
public $content;
/**
* {@inheritDoc}
* @see \yii\base\Object::init()
*/
public function init()
{
parent::init();
if (empty($this->title)) {
$this->title = 'Нет заголовка.';
}
if (empty($this->content)) {
$this->content = 'Нет содержимого.';
}
}
/**
* {@inheritDoc}
* @see \yii\base\Widget::run()
*/
public function run()
{
return $this->render('encyclopedia');
}
}А он используется в неком представлении контроллера:
/**
* @var frontend\controllers\EncyclopediaController $this->context
* @var common\models\Encyclopedia $encyclopedia
*/
use frontend\widgets\EncyclopediaWidget;
?>
<?= EncyclopediaWidget::widget([
'title' => $encyclopedia->title,
'content' => $encyclopedia->content
]) ?>Контроллер просит нас указать в запросе алиас (система должна найти документ по этому алиасу, а не по ID, который является первичным ключом кластерного индекса):
namespace frontend\controllers;
use yii\web\NotFoundHttpException;
use common\models\Encyclopedia;
use yii\web\Controller;
/**
* Encyclopedia
*
* @author Kalinin Alexandr
*/
class EncyclopediaController extends Controller
{
/**
* @var integer время кэширования
*/
const CACHE_TIME = 20;
/**
* @param string $alias
* @return string
*/
public function actionDoc($alias)
{
$encyclopedia = Encyclopedia::getDb()->cache(function ($db) use ($alias) {
return Encyclopedia::getByAlias($alias);
}, self::CACHE_TIME);
if ($encyclopedia === null) {
throw new NotFoundHttpException('Нет такого документа в нашей энциклопедии.');
}
return $this->render('doc', ['encyclopedia' => $encyclopedia]);
}
}Модель создал с помощью Gii, затем добавил один метод, способный находить документ по упомянутому атрибуту:
namespace common\models;
use Yii;
/**
* This is the model class for table "{{%encyclopedia}}".
*
* @property integer $id
* @property string $alias
* @property string $title
* @property string $content
* @property integer $created_at
* @property integer $updated_at
*/
class Encyclopedia extends \yii\db\ActiveRecord
{
/**
* @inheritdoc
*/
public static function tableName()
{
return '{{%encyclopedia}}';
}
/**
* @inheritdoc
*/
public function rules()
{
return [
[['alias', 'title', 'content', 'created_at', 'updated_at'], 'required'],
[['content'], 'string'],
[['created_at', 'updated_at'], 'integer'],
[['alias', 'title'], 'string', 'max' => 255],
[['alias'], 'unique']
];
}
/**
* @inheritdoc
*/
public function attributeLabels()
{
return [
'id' => 'ID',
'alias' => 'Alias',
'title' => 'Title',
'content' => 'Content',
'created_at' => 'Created At',
'updated_at' => 'Updated At',
];
}
/**
* @param string $alias
* @return Encyclopedia|null
*/
public static function getByAlias($alias)
{
return static::find()->where(['alias' => $alias])->one();
}
}Вот класс миграции:
use yii\db\Migration;
/**
* Миграция для encyclopedia
*
* @author Kalinin Alexandr
*/
class m160706_130958_id100_encyclopedia extends Migration
{
/**
* @var string имя таблицы
*/
const TABLE_NAME = '{{%encyclopedia}}';
/**
* @var string параметры таблицы
*/
const TABLE_PARAMS = 'CHARACTER SET utf8 COLLATE utf8_unicode_ci ENGINE=InnoDB';
/**
* {@inheritDoc}
* @see \yii\db\Migration::up()
*/
public function up()
{
$this->createTable(self::TABLE_NAME, [
'id' => $this->primaryKey(),
'alias' => $this->string()->notNull()->unique(),
'title' => $this->string()->notNull(),
'content' => $this->text()->notNull(),
'created_at' => $this->integer()->notNull(),
'updated_at' => $this->integer()->notNull(),
], self::TABLE_PARAMS);
}
/**
* {@inheritDoc}
* @see \yii\db\Migration::down()
*/
public function down()
{
$this->dropTable(self::TABLE_NAME);
}
}Обратите внимание, что в миграции unique уже создаст соответствующий индекс. Как вы прекрасно знаете, подавляющее большинство специальной литературы и рекомендаций (включая публикации Oracle и Percona) много рассказывают про анализ запросов с помощью EXPLAIN, SHOW FULL PROCESSLIST, SHOW PROFILE. Разумеется, оптимизация не обходится без анализа индексов (SHOW INDEX), во время которого есть смысл заинтересоваться типом индекса (Index_type), его возможностью содержать дубли (Non_unique) и количеством уникальных значений (Cardinality). Современные базы данных имеют весьма мощный механизм оптимизации запросов (Cost Based Optimization) с использованием Selectivity, Cardinality и Cost (все они тесно связаны друг с другом), определяемые оценщиком (в англоязычной научной литературе используется термин estimator). Например, если вы используете MySQL 5.7.5 или новее, то можете посмотреть показатели в таблицах server_cost (атрибуты cost_name, cost_value) и engine_cost.
Да, рассказ можно продолжать и продолжать. Тема интересная. С каждым годом видны существенные изменения в некоторых направлениях развития информационных технологий. Искренни желаю вам удачи, интересных технологий и комфортной работы.