
Надо “SELECT * WHERE a=b FROM c” или “SELECT WHERE a=b FROM c ON *” ?
Если вы похожи на меня, то согласитесь: SQL — это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || ' ' || members.lastname
AS "Full Name"
FROM borrowings
INNER JOIN members
ON members.memberid=borrowings.memberid
INNER JOIN books
ON books.bookid=borrowings.bookid
WHERE borrowings.bookid IN (SELECT bookid
FROM books
WHERE stock>(SELECT avg(stock)
FROM books))
GROUP BY members.firstname, members.lastname;Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT, FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:

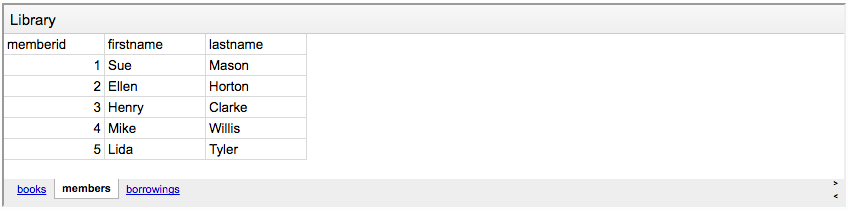
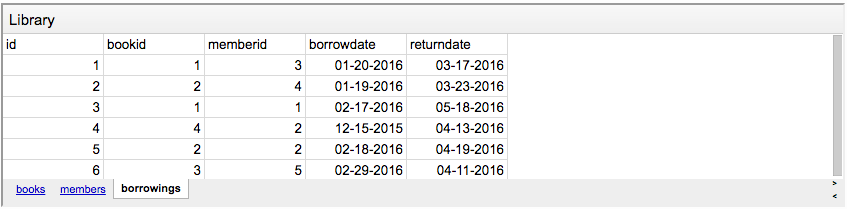
У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” — имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка
bookidотносится к идентификатору взятой книги в таблице “books”, а колонкаmemberidотносится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
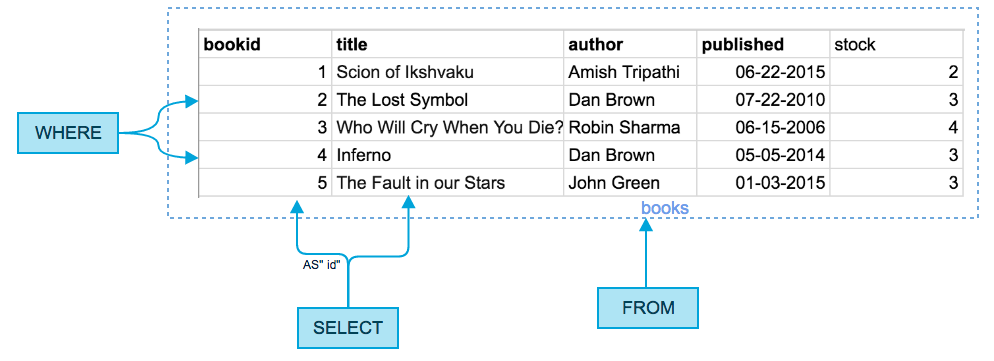
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title
FROM books
WHERE author='Dan Brown';А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM — откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE — какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк, которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author — это “Dan Brown”.
3.3 SELECT — как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT. Заодно можно переименовать колонку используя AS.
Весь запрос можно визуализировать с помощью простой диаграммы:
4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date"
FROM borrowings JOIN books ON borrowings.bookid=books.bookid
WHERE books.author='Dan Brown';Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM. Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid — это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberidРезультат соединения можно увидеть по ссылке.
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
WHERE books.author='Dan Brown'Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name"Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name"
FROM borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberid
WHERE books.author='Dan Brown';Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name",
count(*) AS "Number of books borrowed"
FROM borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberid
WHERE books.author='Dan Brown'
GROUP BY members.firstname, members.lastname;Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY. Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY. В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count, которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.

Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY, или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT'ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock)
FROM books
GROUP BY author;Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов — использовать подзапросы:
SELECT *
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE author='Robin Sharma';Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
6.2 Одномерный массив
Запросы, которые возвращают несколько строк одной колонки, можно использовать не только как двумерные таблицы, но и как массивы.
Допустим, мы хотим узнать названия и идентификаторы всех книг, написанных определенным автором, но только если в библиотеке таких книг больше трех. Разобьем это на два шага:
1. Получаем список авторов с количеством книг больше 3. Дополняя наш прошлый пример:
SELECT author
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE sum > 3;Результат:
| author |
|---|
| Robin Sharma |
| Dan Brown |
Можно записать как: ['Robin Sharma', 'Dan Brown']
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid
FROM books
WHERE author IN (
SELECT author
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE sum > 3);Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid
FROM books
WHERE author IN ('Robin Sharma', 'Dan Brown');6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;Что дает нам:
| avg |
|---|
| 3.000 |
И это можно использовать в качестве скалярной величины 3.
Теперь, наконец, можно написать весь запрос:
SELECT *
FROM books
WHERE stock>(SELECT avg(stock) FROM books);Это то же самое, что:
SELECT *
FROM books
WHERE stock>3.000И результат:
| bookid | title | author | published | stock |
|---|---|---|---|---|
| 3 | Who Will Cry When You Die? | Robin Sharma | 2006-06-15 00:00:00 | 4 |
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT'ом, мы задаем знаения SET'ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books
SET stock=0
WHERE author='Dan Brown';WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT, который использовался при чтении, мы теперь используем SET. Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.

7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE, блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books
WHERE author='Dan Brown';7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT. Формат такой:
INSERT INTO x
(a,b,c)
VALUES
(x, y, z);Где a, b, c это названия колонок, а x, y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT, который заполняет всю таблицу "books":
INSERT INTO books
(bookid,title,author,published,stock)
VALUES
(1,'Scion of Ikshvaku','Amish Tripathi','06-22-2015',2),
(2,'The Lost Symbol','Dan Brown','07-22-2010',3),
(3,'Who Will Cry When You Die?','Robin Sharma','06-15-2006',4),
(4,'Inferno','Dan Brown','05-05-2014',3),
(5,'The Fault in our Stars','John Green','01-03-2015',3);8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT, FROM, WHERE, GROUP BY, и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || ' ' || members.lastname AS "Full Name"
FROM borrowings
INNER JOIN members
ON members.memberid=borrowings.memberid
INNER JOIN books
ON books.bookid=borrowings.bookid
WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books) )
GROUP BY members.firstname, members.lastname;Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Комментарии (166)

alexkunin
19.07.2016 12:57+22Неприятная мелочь: я бы обязательно вывел вложенный SELECT на новую строку и уровень индентации (кроме однострочных случаев). Т.е. вместо:
SELECT author FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE sum > 3;
написал бы:
SELECT author FROM ( SELECT author, sum(stock) FROM books GROUP BY author ) AS results WHERE sum > 3;
В тыщу раз легче читать, имхо, особенно новичкам.Taragolis
20.07.2016 10:35+3А зачем в данном примере вложенный запрос, можно же:
SELECT author
FROM books
GROUP BY author
HAVING sum(stock) > 3;

boodda
19.07.2016 13:22+6с SQL надо аккуратнее, а то потом подсаживаешься и начинается что то подобное:
INSERT INTO stats_search_engine_hot SELECT CURRENT_DATE as date, visitors.user_id, visitors.host_id, visitors.search_engine_id, visitors.visitorquant, IFNULL(dialogs.dialogquant, 0) as dialogquant FROM ( SELECT sess.user_id, sess.host_id, sess.search_engine_id, count(sess.id) as visitorquant FROM ( SELECT s.id FROM session as s WHERE s.date = current_date UNION SELECT sh.id FROM session_hot as sh ) as subquery INNER JOIN session as sess ON sess.id = subquery.id WHERE sess.search_engine_id > 0 GROUP BY sess.user_id, sess.host_id, sess.search_engine_id ) as visitors LEFT JOIN ( SELECT s.user_id, s.host_id, s.search_engine_id, count(s.id) as dialogquant FROM( SELECT m.session_id, min(m.id) as mid FROM message as m WHERE m.date >= DATE_FORMAT(NOW(),"%Y-%m-%d 00:00:00") GROUP BY DATE(m.date), m.session_id ) as a LEFT JOIN message as b ON b.id = a.mid LEFT JOIN session as s ON s.id = a.session_id WHERE b.direct = 0 AND s.search_engine_id > 0 GROUP BY s.user_id, s.host_id, s.search_engine_id ) as dialogs ON visitors.user_id = dialogs.user_id AND visitors.host_id = dialogs.host_id AND visitors.search_engine_id = dialogs.search_engine_idmayorovp
19.07.2016 13:27+2Это еще нормально выглядит. Хотя бы не в одну строчку, как тот запрос, который я отлаживал на прошлой неделе...
ikovrigin
19.07.2016 16:04По-моему тот кто написал это не понял структуры таблиц и условий:
visitors легко упростить до
SELECT
sess.user_id,
sess.host_id,
sess.search_engine_id,
count(sess.id) as visitorquant
FROM session as sess
WHERE sess.search_engine_id > 0
AND (s.date = current_date OR sess.id IN (SELECT sh.id FROM session_hot as sh))
GROUP BY
sess.user_id,
sess.host_id,
sess.search_engine_id
dialogs можно заинлайнить тогда там уйдет куча группировок, а min(m.id) и последующий джойн заменить на TOP 1.
Так же бросается в глаза DATE_FORMAT(NOW(),"%Y-%m-%d 00:00:00") который вероятнее всего можно заменить на уже имеющийся CURRENT_DATE
artbear
20.07.2016 14:41Это вы еще запросы на 1С в конфигурации «Зарплата и управление персоналом».
Есть запросы на тысячу с лишним строк!!!





BlessMaster
19.07.2016 13:24+8SELECT members.firstname || ' ' || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
SELECT members.firstname || ' ' || members.lastname AS "Full Name" FROM borrowings, members, books WHERE members.memberid=borrowings.memberid AND books.bookid=borrowings.bookid AND books.stock > (SELECT avg(stock) FROM books) GROUP BY members.firstname, members.lastname;BlessMaster
19.07.2016 13:28+4Нужно осознать, что SQL — это язык описания запроса, а не язык «почти естественного» общения человека с компьютером.
Все те же претензии «на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить» — справедливы для того же Си или любого другого языка. Английские термины в качестве ключевых слов — облегчают их мнемоническое запоминание, но не более того. Они не являются эквивалентом конструкций естественного языка.
vlivyur
19.07.2016 14:03-1FROM borrowings, members, books
Это ужасно. Настолько же ужасно, как
(а MSSQL такое позволяет).FROM borrowings INNER JOIN members INNER JOIN books ON members.memberid=borrowings.memberid ON books.bookid=borrowings.bookidBlessMaster
19.07.2016 14:20+1В чём суть «ужасности»? Список источников в своей секции, список условий — в своей.
Так же как по секциям расположены описание полей на выходе, сортировка, группировка.vlivyur
19.07.2016 15:18Непонятно как об'единены эти три таблицы меж собой — заставляет держать в уме разрозненные таблицы и потом дорисовывать меж ними связи (хорошо что запрос короткий и всё видно). Ну и такая форма подразумевает что там скорее всего inner join и тем печальнее вдруг обнаружить что там left или right join.
Удивительно что мой пример у вас вызвал отторжение, хотя по структуре он точно такой же, как и первоначальный.BlessMaster
19.07.2016 23:18+2Так все три одинаковы. Разная сложность чтения. Все три источника в любом случае нужно держать в уме, а визуально искать легче, когда искать нужно в одном месте, а не разбросанные по запросу. Перечисленные через запятую они «собираются» — «одним взглядом», растянутые на несколько строчек — пока найдёшь одно, можешь уже забыть другое (особенно в сложном запросе).
В монстро-запросе будет другая ситуация. Если планировщик базы хорошо оптимизирует подобное — возможно имеет смысл разбивать сложный запрос на более простые и оформлять их в виде функций или WITH выражений, хотя это не всегда полезно.
Я не претендую на истину в последней инстанции и всегда можно найти обратный пример. Просто привёл пример для сравнения, как можно упростить простой запрос и сделать его легко читаемым для человека. Фанатизм же до добра не доведёт.vlivyur
22.07.2016 10:15+1Вот именно что сложность разная. У меня слишком маленький об'ём ОЗУ для сложных запросов. В вашем случае я вынужден целиком (целиком — это имя + об'ём) держать в уме ворох таблиц и я даже не догадываюсь что с ними собираются делать и каков масштаб беды (единственное в чём уверен — он должен уменьшиться), пока не найду where. Да, я видел список результирующих колонок, но я пока даже близко не предполагаю откуда они и какую смысловую нагрузку несут. Найдя where, я вынужден сортировать куски условий (а они ещё будут делиться на условия соединения и фильтрации) меж этими таблицами попарно и выстраивать связи между ними (хорошо если разработчик эти куски написал в том же порядке, что и таблицы в from, тогда я просто буду по одной таблице к общей куче пристыковывать, а не держать в уме кучу пар, которые потом будут об'единяться в бОльшие группы) попутно фильтруя весь об'ём соединения.
В моём же случае я сразу вижу как две таблицы об'единяются (from и первый join), осознаю их смысловую нагрузку, лишнее я уже отбросил и предполагаю об'ём результата. Если в join'ах ещё есть таблицы, то к результату предыдущего шага добавляю ещё одну таблицу и проделываю то же самое дальше.
BlessMaster
19.07.2016 14:24+1То, что ужасно
FROM borrowings INNER JOIN members INNER JOIN books ON members.memberid=borrowings.memberid ON books.bookid=borrowings.bookid
не могу не согласиться — здесь просто месиво операторов вместо лаконичного и визуально структурированного перечисления.
BlessMaster
19.07.2016 14:35+1В принципе, учитывая структуру наименований, можно также вспомнить и такую форму JOIN'ов:
FROM borrowings INNER JOIN members USING (memberid) INNER JOIN books USING (bookid)
Но, имхо, это тоже сложнее читается, чем лаконичная секция FROM и подробная WHERE.
paolo77
19.07.2016 17:03Вы уверены? Oracle такого не позволяет. Но позволяет.
SELECT * FROM books INNER JOIN members INNER JOIN borrowings ON members.memberid=borrowings.memberid ON books.bookid=borrowings.bookid;
И хотя на выходе получается тоже самое, что и в исходном запросе, логика у них разная, это не просто стиль оформления.vlivyur
19.07.2016 17:23Ну я не проверял конкретно этот запрос, конечно, но в том, что все ON можно в конце JOIN'ов писать — уверен.
vlivyur
19.07.2016 17:58Хотя не, не уверен. В одном из открытых запросов передвинул ON в конец к другому и там сработало, а сейчас попытался написать похожий на пример запрос и оно не заработало, пришлось колдовать. Планы у запросов одинаковые, так что логику я пока не до конца познал и где такое применять я тоже не знаю.
mayorovp
19.07.2016 18:54Логика тут простая:
SELECT * FROM books INNER JOIN ( members INNER JOIN borrowings ON members.memberid=borrowings.memberid ) ON books.bookid=borrowings.bookid;
paolo77
19.07.2016 19:00+1Все станет совсем понятно если в мой запрос добавить скобочки.
SELECT * FROM books INNER JOIN (members INNER JOIN borrowings ON members.memberid=borrowings.memberid) ON books.bookid=borrowings.bookid;
И это будет тоже самое, что выше. А если чуть переписать запрос и добавить, столь не любимое вами внешнее соединение, то разница станет наглядной.
SQL> CREATE TABLE borrowings 2 ( 3 memberid INTEGER, 4 bookid INTEGER 5 ); Table created. SQL> SQL> CREATE TABLE books (bookid INTEGER); Table created. SQL> SQL> CREATE TABLE members (memberid INTEGER); Table created. SQL> SQL> INSERT INTO borrowings 2 SELECT LEVEL, LEVEL + 1 3 FROM DUAL 4 CONNECT BY LEVEL < 10; 9 rows created. SQL> SQL> INSERT INTO books 2 SELECT LEVEL + 2 3 FROM DUAL 4 CONNECT BY LEVEL < 10; 9 rows created. SQL> SQL> INSERT INTO members 2 SELECT LEVEL + 3 3 FROM DUAL 4 CONNECT BY LEVEL < 10; 9 rows created. SQL> SQL> SELECT members.memberid, 2 borrowings.memberid, 3 books.bookid, 4 borrowings.bookid 5 FROM books 6 LEFT JOIN borrowings ON books.bookid = borrowings.bookid 7 INNER JOIN members ON members.memberid = borrowings.memberid 8 ORDER BY members.memberid, 9 borrowings.memberid, 10 books.bookid, 11 borrowings.bookid; MEMBERID MEMBERID BOOKID BOOKID ---------- ---------- ---------- ---------- 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 6 rows selected. SQL> SQL> SELECT members.memberid, 2 borrowings.memberid, 3 books.bookid, 4 borrowings.bookid 5 FROM books 6 LEFT JOIN borrowings 7 INNER JOIN members 8 ON members.memberid = borrowings.memberid 9 ON books.bookid = borrowings.bookid 10 ORDER BY members.memberid, 11 borrowings.memberid, 12 books.bookid, 13 borrowings.bookid; MEMBERID MEMBERID BOOKID BOOKID ---------- ---------- ---------- ---------- 4 4 5 5 5 5 6 6 6 6 7 7 7 7 8 8 8 8 9 9 9 9 10 10 3 4 11 9 rows selected.
В первом случае это список всех взятых книг, второе внутренне соединение убирает не взятые книги.
Во втором это список всех книг без исключения и информация о их взятии исключая те взятия у которых не определены читатели.
sasha1024
19.07.2016 17:44+3Запятая в перечне WHERE — это всего лишь alias к CROSS JOIN.
Т.е. в Вашем варианте Вы сначала CROSS JOIN'ите все 3 таблицы, а потом фильтруете получившееся месиво с помощью WHERE.
(Да, DBMS оптимизируют CROSS JOIN + WHERE до того же, что получается в результате INNER JOIN… ON. Только вот мои мозги не оптимизируют. В смысле, что человеку понимать INNER JOIN… ON гораздо проще.)BlessMaster
20.07.2016 00:32+2Так и есть — это полное пересечение и современые DBMS его хорошо «понимают».
Я не знаю, возможно это отпечаток какой-то привычки, но не могу подтвердить описанного эффекта — моё сознание просто воспринимает «берём то, что нам нужно». Я в реальной жизни не «джойню» в уме сущности, чтобы осознать такие вещи как «все читатели, которые держат хоть одну книгу, которой в наличии больше среднего». Само описание на русском языке в данном случае строится через взятие полного множества всех читателей и последовательного исключения из него через перечисление правил — это, прямо скажем, легко и естественно. И это хорошо ложится на структуру FROM [источники данных] WHERE с перечислением вышеуказанных ограничений. По другому мне наверно нужно было бы думать «возьмём все комбинации книг, читателей и записей в формулярах, теперь начнём проверять, что id читателя указан в одной из записей о чтении и id книги указан в этой же записи, при этом в наличии этой книги больше среднего». Это слишком непривычно, чтобы читать подобным образом, хотя технически именно это и написано.
Секция FROM — техническая, в ней просто перечислены сущности, секция WHERE логическая — в ней перечислены правила, идущие из естественного языка и при их естественном чтении легко искать ошибки.
Вот так это выглядит для меня:
SELECT -- возьмём: member.first_name || ' ' || member.last_name AS "full_name" -- имя и фамилию читателя, объединив их в одну строку FROM -- будем смотреть источники: member, book, borrowing -- «читатель», «книга», «задолженность» WHERE -- ожидая получить: member.id = borrowing.member_id AND -- «все читатели, которые держат ...» book.id = borrowing.book_id AND -- «... хоть одну книгу, ...» book.stock > (SELECT avg(stock) FROM book) -- «... которой в запасе больше среднего»
Подобная логическая интерпретация сразу позволяет обратить внимание на «странности», которые были бы неочевидны в разбросанных JOIN… ON — сравните исходный запрос и реорганизованный и обратите внимание на тезис, с которого начиналась статья — «SQL очень далёк от естественного языка». Получается, что он на самом деле не так уж и далёк, хотя тезис справедлив, поскольку речь шла немного о другом. Можно с помощью ORM нагенерировать ужас, понятный только машине и SQL это с радостью позволит. Но можно адаптировать для человека — у нас есть для этого достаточно свободы.
Одна проблема: человеки сразу займутся сравнением вкуса фломастеров и этого у нас не отнять :-)sasha1024
20.07.2016 14:17+2Для меня FROM — не техническая секция. Для меня FROM — основная секция.
Выбираю я всегда из одной (основной) таблицы:SELECT s.* FROM students s;
Хотя к ней могут быть прицеплены цепочки других:- по связям многие-к-одному (или один-к-одному):
SELECT s.*, f.* FROM students s join faculties f on s.faculty_id=f.id; -- цепочка длиной 1 SELECT s.*, f.*, u.* FROM students s join faculties f on s.faculty_id=f.id join universities u on f.university_id=u.id; -- цепочка длиной 2 SELECT s.*, f.*, t.* FROM students s join faculties f on s.faculty_id=f.id join towns t on s.home_town_id=t.id; -- две цепочки длиной 1
- реже, по связям один-ко-многим (или многие-ко-многим) для агрегирования:
SELECT f.*, some_aggs(s.*) FROM faculties f join students s on f.id=s.faculty_id GROUP BY f.*; SELECT u.*, some_aggs(s.*) FROM universities u join faculties f on u.id=f.university_id join students s on f.id=s.faculty_id GROUP BY u.*; -- цепочка длиной 2
А реже, потому что в таком случае гораздо изящнее смотрятся подзапросы (в смысле, указывать в FROM только саму основную таблицу, а статистику по таблицам, которые прицеплены связями -ко-многим, выбирать подзапросами).
К сожалению, и со способом «указать -ко-многим в join'е и group by», и со способом «использовать подзапрос для -ко-многим» есть проблемы (в первом случае мы не можем получить статистику по нескольким цепочкам, а во втором случае нам неудобно (приходится через ROW()) получать несколько статистик из одной цепочки).
Также таблица, из которой идёт запрос, может быть динамически сконструированной — подзапросом. Правда, join — это тоже де-юре динамически сконструированная таблица.
Join де-юре всегда left (выше не указывал для простоты). Я надеюсь, СУБД автоматически оптимизирует left join при foreign key'е с not null constraint'ом (а также при foreign key'е без not null constraint'а, но с WHERE t.key_field is not null или WHERE t.* is not null) до inner join'а. Хотя де-факто я часто пишу inner join и вручную (если точно уверен, что здесь not null и оно не поменяется).
Как по мне, технической является скорее секция с набором выражений (до FROM). Логичнее было бы, если бы выражения в запросе не указывались и СУБД всегда возвращала набор handle'ов строк. Хотя, может быть, это действительно фломастеры.- по связям многие-к-одному (или один-к-одному):
ikovrigin
20.07.2016 09:44+5То что вы сделали в запросе называется old-style-join и является устаревшим со времен ввода стандарта SQL-92. Более 20 лет прошло может быть пора уже перейти на «новый» стандарт?
Есть несколько причин использовать «новый» стиль (если стандарта по вашему мнению не достаточно) могу привести еще несколько аргументов в пользу нового стиля. Во-первых разделения объединения и фильтраци в разные блоки. Во-вторых в случае если вы забыли указать условие объединения старый стиль приведет к расчету огроного объема данных и неверного результата (который может быть не так легко обнаружить), в то время как новый выдаст синтаксическую ошибку (http://blog.sqlauthority.com/2015/10/08/sql-server-why-should-you-not-to-use-old-style-join/). Можно продолжить гуглить и находить «за» и «против», а можно просто перейти на использование стандартов и выбросить дурное из головы. Ваш код могут читать люди которые родились после введения стандарта SQL-92 и ваш код будет выглядеть для них так, как будто его писали мамонты.
PsyHaSTe
21.07.2016 19:39+3Как раз хотел что-то в таком духе написать. Когда я вижу 10 INNER JOIN'ов, я всегда знаю, какое количество записей будет: в реальной жизни получается такое же, как в «главной» табличке либо чуть меньше в случае NULL-ов. В случае вот таких перемножений множества нить сразу теряется, непонятно, какой порядок записей вернет запрос — N? N*M? N*M*K? Нужно разбираться с условиями, смотреть что там прописанно. Видешь LEFT JOIN'ы — гарантированно знаешь, сколько записей. видешь INNER JOIN — понимаешь порядок. Видишь CROSS JOIN — предполагаешь M*N записей. А когда оказывается, что это нифига не CROSS, а самый что ни на есть INNER, чувствуешь себя обманутым — пообещали одно, а на деле совсем другое.

Whitenoiseonair
19.07.2016 13:58freetonik можно ли указать ссылку на исходную учебную таблицу? Чтобы новички могли скопировать её и потренироваться с запросами локально.

freetonik
19.07.2016 14:00
freetonik
19.07.2016 14:03Сделал свою копию, на случай если авторский файл удалят или изменят. Вот > https://docs.google.com/spreadsheets/d/1ELGKU-pjgyMlCib1O3Tn6H27VmJkxhUmCJtQ9-IpJFo/edit?usp=sharing

aspirineilia
19.07.2016 14:07+8Главное чтобы потом тому кто это всё прочитал рассказали про HAVING до того как он начнёт лепить вложенные запросы везде где это нужно и не нужно.
mayorovp
19.07.2016 19:01+2ЕМНИП, HAVING не дает возможности использовать назначенное имя для колонки, а потому вложенные запросы могут быть предпочтительнее даже когда достаточно HAVING:
SELECT foo, длинное-длинное-выражение as bar GROUP BY foo HAVING длинное-длинное-выражение > 42 SELECT * FROM ( SELECT foo, длинное-длинное-выражение as bar GROUP BY foo ) AS temp WHERE bar > 42
Начиная с некоторой длины выражения, второй вариант смотрится лучше. И редактировать его проще.

Mingun
19.07.2016 19:10-1А также, если в качестве
длинного-длинного-выраженияиспользуется вызов функции, которое во фразуgroup byне засунешь.
aspirineilia
20.07.2016 08:52+1За все СУБД не скажу, но в MySQL можно использовать алиасы из SELECT в HAVING.
SELECT foo, длинное-длинное-выражение as bar GROUP BY foo HAVING bar > 42PsyHaSTe
21.07.2016 19:42Это идеологически неправильно с точки зрения стандартов, но достаточно удобно для разработчиков. В некотором смысле типичное решение для MySQL.
PsyHaSTe
21.07.2016 19:41Начиная с некоторой длины стоит вместо подзапросов использовать CTE, который суть те же подзапросы, только расположенные в человекопонятном порядке.

savostin
19.07.2016 14:14+2А чего это Вы member'ов так уважаете (имя и фамилия отдельно), а авторов — нет?
И вообще, авторов в отдельную таблицу бы. И многие ко многим авторы-книги.
А то мало ли, вдруг кто-то напишет книгу в соавторстве с кем-то?
Что потом делать с запросомSELECT bookid AS "id", title FROM books WHERE author='Dan Brown';
А еще таблицу поступлений книг, и триггеры на обновление поля stock на приход/уход.
Вот тогда уже будет интереснее.
claygod
19.07.2016 14:21И многие ко многим авторы-книги.
Как-то писал небольшую соцсеть, и тоже пришлось сделать «многие ко многим», чтобы у статьи могло быть несколько авторов, а у авторов несколько (или много) статей. Так что пожелание весьма правильное.
BlessMaster
19.07.2016 14:38Ещё стоит заметить, что
member_id, book_id, first_name, last_name
читается легче, чем
memberid, bookid, firstname, lastname
Это кажется незначительным различием в простом запросе. Но когда запрос сложный и нужно посидеть, «распарсить» его и понять — каждая подобная мелочь сильно облегчает работу.

Danik-ik
19.07.2016 15:06+3Не хватает оператора HAVING (для выборки по результатам группировки)
По поводу конструкции:
WHERE borrowings.bookid IN (SELECT bookid
FROM books…
Не знаю, как сегодня, а лет десять назад на файрбёрде она «оптимизировалась» в список сравнений через OR, что при большой выборке делало мегависюк на стороне сервера. MS SQL кушал такое с лёгкостью.
Есть мнение, что это «джойн для бедных» и вместо него надо использовать именно джойн:
Вместо
Select name from authors
Where id in (select author_id from bests)
Надо:
Select a.name
From authors a
Inner join bests b
On a.id=b.author_id
Where b.id is nullAlexeyVD
19.07.2016 15:36+1Про WHERE… IN (...) полностью поддерживаю. Скажу за MySQL. До версии 5.6 такие подзапросы в секции WHERE сервер вообще никак не оптимизировал. Позже была добавлена оптимизация простых подзапросов без JOIN'ов.
Так что лучше избегать подобных конструкций и выносить их в секцию с JOIN'ами как, например, показано в комментарии выше.geher
19.07.2016 17:38Помнится, в IBM DB/2 был инструмент, позволяющий увидеть, как именно (в какой последовательности и как быстро) запрос будет выполняться в реальности.
Как показала реальная практика, результат оптимизации и скорость выполнения запроса в большей степени зависели от наличия индексов, чем от формы записи запроса.
И при некоторых комбинациях индексов наличие подзапроса во WHERE существенно ускорало выполнение запроса, в то время как использование JOIN приводило к игнорированию индексов, что приводило к замедлению.
Например, при наличии индексов по полям, используемым в WHERE для вложенного запроса и отсутствии индексов для таблицы из FROM, если не путаю за давностью лет, конечно.
Отсюда, кстати, вывод. SQL-оводу имеет смысл знать об индексах, используемых в его СУБД и их особенностях.
mayorovp
19.07.2016 19:11+2Если в подзапросе есть дубликаты — то JOIN продублирует строки основного запроса, в отличии от IN. Избавляться от дублей придется с помощью группировки — а она может сказаться на оптимальности плана, поскольку требует упорядоченности.
MS SQL и сейчас кушает такие подзапросы с легкостью (более того, в плане выполнения IN и JOIN превращаются в одинаковые операции).
Поэтому при использовании СУБД с мощным оптимизатором я бы напротив, советовал в подобных случаях предпочитать IN джойнам.
Danik-ik
19.07.2016 23:24+2> Если в подзапросе есть дубликаты — то JOIN продублирует строки основного запроса, в отличии от IN. Избавляться от дублей придется с помощью группировки — а она может сказаться на оптимальности плана, поскольку требует упорядоченности.
Мне ли учить монстров SQL удалять дубликаты?
… JOIN (SELECT DISTINCT author_id FROM bests) b
По поводу неоптимальности. Оптимальность плана — штука такая, её по месту надо смотреть. Выше я писал про «оптимизацию» в файрбёрде (в середине нулевых) именно при использовании where...in. Буквально запрос превращался в что-то вроде WERE (a.OKP='11356432525' or a.OKP='9808958635'… <и так несколько тысяч раз>) и заново разбирался. Эпичненько?
Я не навязываю решение, но говорю об альтернативном мнении. Так что мнения — отдельно, факты — отдельно. А факты для каждой системы могут быть разные. Я всегда использовал в MSSQL Where...in и не парился, а файрбёрд тогда выкинул (именно потому, что имел много таких запросов). Но если у кого-то где-то запрос where...in не оптимизируется или влечёт проблемы — есть ещё вариант с джойном!!!Taragolis
20.07.2016 17:48Привык уже использовать WHERE EXISTS вместо WHERE X IN (SELECT Y FROM ...)
Если нужно будет сделать отрицающее условие, то в первом случае надо будет сделать WHERE NOT EXISTS, а вот NOT IN уже использовать опасно, и придется немного переписать в WHERE X NOT IN (SELECT Y FROM… WHERE Y IS NOT NULL)
Danik-ik
20.07.2016 00:07+2Меня очень правильно поправили:
Select a.name
From authors a
Inner join bests b
On a.id=b.author_id
вместо where… in
Select a.name
From authors a
left join bests b
On a.id=b.author_id
Where b.id is null
вместо where not… in
paolo77
19.07.2016 15:06+2Мне кажется читать SQL станет намного проще если использовать более реальные примеры. Зачем писать
WHERE borrowings.bookid IN (SELECT bookid
FROM books
WHERE stock>(SELECT avg(stock)
FROM books))
Когда можно написать.
WHERE books.stock>(SELECT avg(stock) FROM books)
Зачем писать
SELECT * FROM (SELECT author, sum(stock)
FROM books
GROUP BY author) AS results
WHERE author='Robin Sharma';
Когда можно написать
SELECT author, sum(stock)
FROM books
WHERE author='Robin Sharma'
GROUP BY author;
И почему бы не использовать конструкцию HAVING, здесь?
SELECT author
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE sum > 3;
Возможно вы усложнили запросы, чтобы показать некоторые возможности SQL? Но такой подход боюсь только собьет с толку новичка.

V-core
19.07.2016 15:06Умею писать на SQL по древней методичке. Использую сейчас в основном MSSQL.
Надеялся, что хоть тут мне толково объяснят что такое INNER JOIN и чем он отличается от JOIN, но, видимо, не судьба :)vlivyur
19.07.2016 15:24+1Ничем. Если есть слева, то будет и справа. Например, у книги всегда есть автор (я тут разделил книжку с фамилиями авторов, чтоб легче искать было), смысла нет ставить меж ними left join. А вот читатель у книги не всегда может быть, поэтому в книга-join-читатель должен быть left join, если мы хотим найти те книги, которые сейчас никто не взял.
Free_ze
19.07.2016 16:04Почитали бы MSDN, например.
INNER
Specifies all matching pairs of rows are returned. Discards unmatched rows from both tables. When no join type is specified, this is the default.
mayorovp
19.07.2016 19:14Есть 5 видов операции JOIN: INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER и CROSS.
INNER — это вид JOIN по умолчанию, это слово можно пропускать. Т.е. формы
a JOIN bиa INNER JOIN b— это строго одно и то же, просто второй вариант считается "академичнее".
Слово OUTER тоже можно не писать.
Taragolis
21.07.2016 00:15И тут врывается NATURAL JOIN
martin_wanderer
21.07.2016 00:53И говорит: «Ой, я же синтаксический сахар»! Ничего не добавляет к семантике запроса — только сокращает запись, и может быть как inner, так и left/right.
Taragolis
21.07.2016 01:10Ну все равно он существует )) И поэтому нельзя сказать, что их всего 5. Конечно в реальной жизни NATURAL JOIN используется так же часто как и RIGHT JOIN.
sasha1024
21.07.2016 01:06+2Бесполезный и опасный тип джоина.
Не говоря уже о том, что это не отдельный тип (это всего лишь указание «сам угадай колонки», по которым джоинить — бывает NATURAL INNER, NATURAL LEFT OUTER, NATURAL RIGHT OUTER и NATURAL FULL OUTER). (Правда, CROSS тоже не отдельный тип.)
Т.е. если подходить формально, джоины можно делить:- По поведению в случае отсутствия записей с одной из сторон:
- INNER
- LEFT OUTER
- RIGHT OUTER
- FULL OUTER
- По способу указания условий соединения:
ON условие— явное указание условийUSING (колонка1, колонка2, …)— сокращение для «ON левая_таблица.колонка1=правая_таблица.колонка1 and левая_таблица.колонка2=правая_таблица.колонка2 and …»NATURAL— сокращение для «USING (все-колонки-присутствующие-в-обеих-таблицах-сразу)»CROSS— сокращение для «ON true» (в отличие от прошлых трёх способов, CROSS может быть только INNER, правда возможно это нюанс PostgreSQL)
Taragolis
21.07.2016 01:42По бесполезности и возможности отстрелить ногу — я полностью согласен. Как уже говорил, в продакшене я не видел чтобы использовали Natural (и без него веселья много).
А вот по классификации, я не то что не согласен, просто это бесполезное занятие, вон Oracle класифицирует их так:
1. Equi Joins
2. Self Joins
3. Cartesian Products
4. Inner Joins
5. Outer Joins
6. Antijoins
7. Semijoins
Хотя по мне Equijoin это частный случай Inner Join, а Antijoins и Semijoins это вообще NOT EXISTS и EXISTS соответственноsasha1024
21.07.2016 02:241. А можно источник, где они их так классифицируют?
2. Ну, скажу честно, я пока не вижу никакой причины классифицировать по-другому, чем у меня.Taragolis
21.07.2016 07:25Да конечно, только ссылка в виде текста, наверное между GT и хабром есть разница в доступности тегов для Read&Comment пользователей:
Ссылка из доки по 12с: https://docs.oracle.com/database/121/SQLRF/queries006.htm
Интересно стало, а что же там у MS: https://technet.microsoft.com/en-us/library/ms191472(v=sql.105).aspx
sasha1024
21.07.2016 12:28+1Выводы:
1. Oracle не классифицирует джоины так. В той статье у них не классификация, а список важных определений. То, что приведенные названия являются подзаголовками одного уровня, не делает их классификацией (нигде явно не сказано, что это классификация; иначе можно было бы и первый подгалоговок «Join Conditions» считать типом джоина; да и вообще, логика, Equi Join может быть одновременно и Self, и Inner/Outer).
2. Oracle в той статье говорит в джоинах в гораздо более широком смысле. Они рассматривают джоины, не как операторы секции FROM, а как любые действия, приводящие к соединению таблиц (в т.ч. подзапросы) — в отличие от статей в доках postgres и MS. Т.е. это, формально говоря, «другие джоины».
> Хотя по мне Equijoin это частный случай Inner Join
Нет. Equi Join — это когда критерием соединения является явная (указанная в ON/WHERE) или неявная (с USING/NATURAL) система равенств (в впротивоположность, например, «table1 t1 JOIN table2 t2 ON (t1.x-t2.x)?+(t1.y-t2.y)??1.0»). Equi/не-Equi и Inner/Outer — это несвязанные вещи.
> а Antijoins и Semijoins это вообще NOT EXISTS и EXISTS
Так и есть. Поймите, Oracle говорит о «других» джоинах — она в отличие от postgres и MS говорит не о синтаксисе, а о конечном результате. Тот же «FROM table1 t1, table2 t2 WHERE t1.id=t2.id» по postgres/MS будет cross join, а по Oracle — equi inner.
Т.е. классификация джоинов-по-Oracle выглядит как-то так: 1. По типу критериев: (а) equi — система равенств, (б) cartesian product — полное отсутствие критериев, (в) все другие. 2. По включению-при-отсутствии-пары: (а) inner — не включаем, (б) outer — включаем, (в) anti — включаем ТОЛЬКО когда нет пары, (г) другое. 3. По связи с самим собой: (а) self, (б) не-self. Semi — отдельная история.
MS смотрит аналогично postgres'у.Taragolis
21.07.2016 14:31>Oracle говорит о «других» джоинах
Магические «другие» JOIN мы можем увидеть в плане запросов.
NESTED LOOPS (Equi | Self | Cartesian | Outer | Anti | Semi)
HASH JOIN (Equi | Self | Cartesian | Outer | Anti | Semi)
MERGE JOIN (Equi | Self | Cartesian | Outer | Anti | Semi)
Причем зачастую они будут одинаковы и у Oracle и у SQL Server (pg под рукой сейчас нет)
>Нет. Equi Join — это когда критерием соединения является явная (указанная в ON/WHERE) или неявная (с USING/NATURAL) система равенств
Тогда скажите запрос:
SELECT *
FROM a, b
WHERE a.id = b.id
Это EQUI JOIN или INNER JOINsasha1024
21.07.2016 17:31> Тогда скажите запрос
Ответ на Ваш вопрос содержится в том сообщении, на которое Вы отвечаете: equi inner.
> Это EQUI JOIN или INNER JOIN
Вопрос поставлен некорректно. Тот перечень, что Вы приводили, — это не непересекающиеся классы.
Вот типы джоинов.
- По поведению в случае отсутствия записей с одной из сторон:
sasha1024
21.07.2016 01:11Бесполезный и опасный тип джоина.
Не говоря уже о том, что это не отдельный тип (это всего лишь указание «сам угадай колонки, по которым джоинить» — бывает NATURAL INNER, NATURAL LEFT OUTER, NATURAL RIGHT OUTER и NATURAL FULL OUTER). (Правда, CROSS тоже не отдельный тип.)
Т.е., строго говоря, джоины можно делить:- По поведению в случае отсутствия записей с одной из сторон:
- INNER
- LEFT OUTER
- RIGHT OUTER
- FULL OUTER
- По способу указания условий соединения:
ON условие— явное указание условийUSING (колонка1, колонка2, …)— сокращение для «ON левая_таблица.колонка1=правая_таблица.колонка1 and левая_таблица.колонка2=правая_таблица.колонка2 and …»NATURAL— сокращение для «USING (все-колонки-присутствующие-в-обеих-таблицах-сразу)»CROSS— сокращение для «ON true» (в отличие от способов 1-3, CROSS в PostgreSQL может быть только INNER)
- По поведению в случае отсутствия записей с одной из сторон:


maxru
19.07.2016 15:31-3Средний разработчик, боящийся SQL? Импосибру.
Хотя, «средний» разработчик, который всю дорогу ORM использовал в режиме «оно само», может и испугается.

technont64
19.07.2016 17:44-1SQL — важная и нужная штука, но мои глаза всегда мозолил такой порядок аргументов, сравните:
SELECT поля FROM таблица…
DELETE FROM таблица…
UPDATE таблица (поля) SET…
INSERT INTO таблица (поля)…
Что-то примерно такое представляется мне более структурированным:
SELECT FROM таблица [FIELDS поля]…
DELETE IN таблица…
UPDATE IN таблица FIELDS поля=новые значения…
INSERT IN таблица [FIELDS поля[=новые значения]]… /*или по-старому*/
Что лучше:
1. Консистентный порядок
2. Более заметна разница между модификацией данных и получением
3. Единый формат описания полей
В общем, помечтал и хватит (:sasha1024
19.07.2016 19:14Что список полей перед FROM в SELECT — нелогично, — абсолютно согласен (получается, мы сначала используем alias таблицы и только потом объявляем его).
Но уж так сложилось…
PretorDH
19.07.2016 21:14SELECT импользуєтся не только для таблиц… но и для переменных… потому вот как есть — логичнее…
INSERT таблица (asd,asd) VALUE («2»,«3») в этих дужечках еще на этапе расшифровки запроса, создается набор значений, которой потом ставится в базу. И запутаться сложнее — вставка и выбор визуально совсем разные…
sasha1024
19.07.2016 23:46+1потому вот как есть — логичнее…
Отнюдь. Всего лишь можно опускать секцию FROM (аналогично тому, как сейчас опускаются секции FROM/GROUP BY/пр., когда они не нужны), когда запрос идёт не из таблиц (хранимая функция и пр.):
SELECT FROM users u WHERE u.birthdate<'1950-01-01' EXPRESSIONS u.name, u.surname; SELECT EXPRESSIONS myfunction(1, 2) as myfunc12result;
sasha1024
19.07.2016 23:51Т.е. текущий синтаксис такой как он есть не потому, что он самый логичный, а потому, что так сложилось.
Про INSERT то не я говорил,INSERT INTO table t (f1, f2) VALUES (v1, v2), (v3, v4)меня устраивает, это уже отвечайте тому, кто писал про INSERT (и, да, синтаксис никак не связан с тем, что «создается набор значений», например,INSERT INTO users SET name='vasya', surname='pupkin' SET name='fedya', surname='petrov'тоже прекрасно бы «создавало набор значений»).
sasha1024
20.07.2016 16:24И, кстати, вот ещё одна причина указывать выражения после всего, а не перед FROM (окромя общей логичности и использования ещё-не-объявленых алиасов-таблиц):
Чайники не понимают, что расчёт этих выражений происходит после группировки GROUP BY'ем, а не до.
https://habrahabr.ru/post/305926/#comment_9708148
При "SELECT FROM … WHERE … GROUP BY … HAVING … EXPRESSIONS …" бы таких проблем не было.
maxru
20.07.2016 14:36+1Вы так и говорите в жизни «возьмите из корзины мяч и кубик», а не «возьмите кубик и мяч из корзины»?
sasha1024
20.07.2016 14:53Это зависит от того, о чем мы говорили последнем.
Найди большую красную корзину. Нашёл? Возьми из корзины синий мячик.
Хочешь мячик? Возьми из его из красной корзины.
Т.е., если мы рассматриваем корзину как важный этап последовательности действий, мы указываем её в начале. Если мы рассматриваем корзину как незначительное уточнение, мы указываем её в конце. (Угадайте, чем является указание таблицы в SQL-запросе.)
И да, множественность предметов увеличивает вероятность того, что мы назовём корзину вначале: «возьми из корзины мячик, кубик, расчёску, бантик и погремушку».

Vlad_fox
19.07.2016 17:44для начинающих рекомендую почитать что-то из серии head first издательства O`Reily (с аббревиатурой SQL в названии).
Там в картинках, с хорошими примерами, последовательно и системно будет описана работа с запросами.
можно скачать в електронном виде…
Mingun
19.07.2016 19:21+2Конечно, в таком виде этот запрос читать невозможно:
SELECT members.firstname || ' ' || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Но после небольшого форматирования, выкидывания ненужных частей (зачем здесь соединение с
books, если таблица вообще никак не используется???) и простановки псевдонимов таблиц разобраться в нём уже не составляет труда:
select m.firstname||' '||m.lastname "full name" from members m join borrowings b on (b.memberid = m.memberid) where b.bookid in (select bookid from books where stock > (select avg(stock) from books)) group by m.firstname, m.lastname ;

sumanai
19.07.2016 20:57-2> Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY, или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT'ом, то непонятно, какие из возможных значений нужно брать.
В MySQL при настройках по умолчанию до 5.7 не обязательно, с 5.7 включено строгое соответствие ANSI SQL, которое можно включить и в более ранних версиях.
Меня вот всегда раздражает это требование перечислять в GROUP BY всё, что уже перечислил в SELECT.sasha1024
20.07.2016 00:06Требование очень логичное, если не считать одно «но»:
к сожалению, когда Вы уже перечислили в GROUP BY все поля первичного ключа (или другого уникального ключа) какой-то таблицы, при выборке других полей этой таблицы их всё равно приходится указывать в GROUP BY:
CREATE TABLE users ( id serial not null primary key, name text not null, surname text not null ); CREATE TABLE items ( id serial not null primary key, owner_user_id integer not null references users (id), ... ); SELECT u.id, u.name, u.surname, count(*) as item_count FROM users u left join items i on u.id=i.owner_user_id GROUP BY u.id; -- , u.name, u.surname
Почему-то в таком запросе приходится указывать в GROUP BY не только u.id, но и u.name, u.surname. Вот это меня выбешивает (нелогично, ведь если все поля уникального ключа таблицы перечислены в GROUP BY, то перечисляй/не перечисляй остальные — разницы уже нет). Но в остальном это требование очень логично.sumanai
20.07.2016 00:14-1> Требование очень логичное
Почему тогда в MySQL всё работает? У меня всегда поведение при выборке соответствовало ожидаемому.
> Почему-то в таком запросе приходится указывать в GROUP BY не только u.id, но и u.name, u.surname.
Я вроде про то и написал.sasha1024
20.07.2016 01:05+1Я давно не имел дела с MySQL, но насколько я помню, там всё было через ж#пу.
В случае с GROUP BY: там вообще это требование не проверялось, например, можно было сделатьSELECT t.field2 FROM table1 t GROUP BY t.field1, где field1 отнюдь не уникальный ключ.
Что полный бред (хотя может с тех пор что-то изменилось).sumanai
20.07.2016 01:32+2> Я давно не имел дела с MySQL, но насколько я помню, там всё было через ж#пу.
Это настраивается, как я написал в первом сообщении. Не знаю точно с какой версии, но на всех актуальных так точно.
> Что полный бред
Не вижу бреда в выборке одного поля при группировке по другому.
Просто при не уникальном ключе в группе будет по несколько строк, и возвращена будет первая.
Конечно, возвращаемое значение не определено и зависит от реализации, но думаю, делающие так знают о последствиях, и сортировка в группе их не интересует.
А вот требование прописывать остальные, как уже отписались выше- излишне и лишь заставляет дублировать все колонки в каждом запросе.
А если у меня они прописаны в коде (что поделать, не везде совершенный код), что теперь, менять запросы в куче мест при добавлении нового поля?sasha1024
20.07.2016 11:14+1Всё, к сожалению, не настраивается. Остаётся всё равно куча бреда не по стандарту. Например, в какой-то версии (не знаю как щас):
CREATE TABLE t3 ( ..., t1_id int not null REFERENCES t1 (id), -- тупо игнорируется!!! t2_id int not null, FOREIGN KEY (t2_id) REFERENCES t2 (id) );
Не вижу бреда в выборке одного поля при группировке по другому.
Если Вы хотите из набора строк (которые получаются в результате GROUP BY) получить одно значение, Вы используете агрегатную функцию. Точка. Получение первого значения из набора и получение неопределённого значения из набора — это, как и, например, получение суммы, тоже агрегатные функции.
Если таких функций нету, Вы можете их дописать.SELECT count(i.*) as count, sum(i.price) as total_price, agg_first(i.name) as first_name, agg_some(i.name) as some_name, agg_last(i.name) as last_name FROM items i GROUP BY i.category_id -- неуникальное поле
Теперь понимаете?sumanai
20.07.2016 13:20Давайте покажу на конкретном примере.
Есть таблица пользователей и сессий, стандартные для phpBB, вот для представления их урезанные версии:
CREATE TABLE `phpbb_sessions` (
`session_id` char(32) COLLATE utf8_bin NOT NULL DEFAULT '',
`session_user_id` mediumint(8) unsigned NOT NULL DEFAULT '0',
`session_time` int(11) unsigned NOT NULL DEFAULT '0',
`session_ip` varchar(40) COLLATE utf8_bin NOT NULL DEFAULT '',
`session_viewonline` tinyint(1) unsigned NOT NULL DEFAULT '1',
PRIMARY KEY (`session_id`),
KEY `session_time` (`session_time`),
KEY `session_user_id` (`session_user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
CREATE TABLE `phpbb_users` (
`user_id` mediumint(8) unsigned NOT NULL AUTO_INCREMENT,
`user_type` tinyint(2) NOT NULL DEFAULT '0',
`username` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`username_clean` varchar(255) COLLATE utf8_bin NOT NULL DEFAULT '',
`user_colour` varchar(6) COLLATE utf8_bin NOT NULL DEFAULT '',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin
Вот запрос для поучения текущих активных пользователей:
SELECT s.session_user_id AS user_id, s.session_viewonline, u.username, u.user_type, u.user_colour
FROM phpbb_sessions s
LEFT JOIN phpbb_users u ON s.session_user_id = u.user_id
WHERE s.session_time >= 1469004330 AND s.session_user_id <> 1
GROUP BY s.session_user_id
ORDER BY u.username_clean
На MySQL 5.6 со стандартными настройками он работает прекрасно, при других настройках или на других БД выдаёт что- то типа
'phpbb.u.username_clean' isn't in GROUP BY [1055]
Вопрос- зачем мне прописывать в группировку это поле? Если его прописать, будет ругаться на следующее, и так далее, пока не пропишешь все поля из SELECT:
GROUP BY s.session_user_id, s.session_viewonline, u.username, u.user_type, u.user_colourTaragolis
20.07.2016 14:23+1А что вы хотите этим GROUP BY сделать?
Попробую предпроложить, что раз нет ни одной агрегирующей функции, то наверное хотите получить уникальные записи
Может тогда лучше так?
SELECT DISTINCT
s.session_user_id AS user_id
, s.session_viewonline
, u.username
, u.user_type
, u.user_colour
FROM phpbb_sessions s
LEFT JOIN phpbb_users u
ON s.session_user_id = u.user_id
WHERE s.session_time >= 1469004330
AND s.session_user_id <> 1
ORDER BY u.username_cleansasha1024
20.07.2016 15:06У него в запросе логическая ошибка. Он хочет получить перечень активных пользователей (не сессий; на одного пользователя может приходиться несколько сессий). Для этого он group-by'ит по пользователю (точнее по s.session_user_id, но оно джоинится с первичным ключём пользователя). Однако поля сессии он не пропускает через агрегатные функции.
Скорее всего, логически-правильный запрос должен выглядеть так:SELECT u.*, bool_or(s.session_viewonline) as at_least_one_session_viewonline FROM phpbb_sessions s left join phpbb_users u on s.session_user_id=u.user_id WHERE s.session_time>=1469004330 and s.session_user_id<>1 GROUP BY u.* -- или "GROUP BY u.user_id", или "GROUP BY s.session_user_id" (пофиг) ORDER BY u.username_clean;sumanai
20.07.2016 16:36Тут же обсуждали невозможность использования конструкции вида GROUP BY u.*. Итог закономерен:
> Ошибка в запросe (1064): Syntax error near '* ORDER BY u.username_clean' at line 4
Само собой
«GROUP BY u.user_id», или «GROUP BY s.session_user_id» (пофиг)
не сработало, требует перечисления полей напрямую.
Ну и функции bool_or в MySQL моей версии (10.1.15-MariaDB) не завезли.sasha1024
20.07.2016 17:00Это я же и обсуждал.
Я потому и пишу «логически-правильный»; это псевдокод; в реале конечно же, к сожалению, придётся перечислять после GROUP BY все поля.
Я к тому, чтобы Вы отличали реализацию стандарта с недоработкой (когда выражение, единственность значения которого очевидна, нельзя выбрать, не указав явно в GROUP BY) от полной вседозволенности (когда вообще никаких проверок нет, что бред).
sumanai
20.07.2016 16:51Ну и выбирать все поля в phpbb_users излишне, как я писал, таблицу я запостил не всю, в оригинале там 50+ колонок.
sasha1024
20.07.2016 14:27Ну, в таком случае я согласен.
Просто Вы не путайте две разные вещи:- Употребление полей таблицы вне GROUP BY, когда первичный/уникальный ключ этой таблицы уже указан в GROUP BY. В принципе, с логической точки зрения допустимо, но в стандарте почему-то запрещено.
- Употребление вне GROUP BY полей, уникальность которых никак не гарантируется структурой запроса. Стандартом запрещено и очень правильно.
Т.е. в Вашем запросе ругается на u.username_clean излишне. В Вашем запросе будет ругаться на s.session_viewonline очень правильно.sasha1024
20.07.2016 14:40+1Потому что единственность s.session_user_id и u.* гарантируется структурой запроса (единственность s.session_user_id гарантируется тем, что оно непосредственно указано в GROUP BY, а единственность u.* гарантируется тем, что u.user_id (который первичный ключ для u) за-join-ен с первым).
Единственность всех остальных полей в s.* (кроме s.session_user_id) структурой запроса не гарантируется. Использоваться их вне агрегатных функций — нельзя. Даже просто с логической точки зрения (у Вас на одну строку результата приходится потенциально-несколько значений s.session_viewonline; какое из них брать: первое, bool_and или bool_or?).sumanai
20.07.2016 16:49> Даже просто с логической точки зрения (у Вас на одну строку результата приходится потенциально-несколько значений s.session_viewonline; какое из них брать: первое, bool_and или bool_or?).
Интересное замечание. Посмотрел- в оригинале в phpBB (достаточно популярный форумный движок) выбираются все подходящие значения, а дубли пропускаются на стороне PHP. То есть берётся первое. В принципе, как у меня, хотя понятие «первого» могут отличатся.
Mingun
20.07.2016 00:33В один прекрасный день окажется, что то поле, которое раньше было уникальным уже не может таковым быть. И вы убираете ограничение уникальности. Упс. Половина запросов сломалась на ровном месте… Так что о логичности вашей хотелки ещё можно поспорить.
sasha1024
20.07.2016 01:02Почему тогда
SELECT t.* FROM table1 t GROUP BY t.*;
сделать нельзя?
Упс…Danik-ik
20.07.2016 09:40+1Таки можно, но не так.
SELECT DISTINCT t.* FROM t
Не знаю только, можно ли добавить в выборку агрегатные функции. Проверить не могу, ибо сегодня я маляр-штукатур
Кстати, иметь в таблице полностью идентичные записи очень, очень некошерно, т.к средствами sql их невозможно идентифицировать по отдельности. Именно поэтому и вводят традиционно автоинкрементный id, если нет строгого регламента на наполнение, и осмысленного uid поля или комбинации полейsasha1024
20.07.2016 10:58Речь не о DISTINCT, а о том, что я хочу сделать, например:
SELECT t.*, count(i.*) as item_count, sum(i.price) as total_price FROM table1 t left join items i on t.id=i.parent_id GROUP BY t.*; -- а нельзя
И так тоже нельзя:SELECT t.*, count(i.*) as item_count, sum(i.price) as total_price FROM table1 t left join items i on t.id=i.parent_id GROUP BY t.id; -- подразумевая, что table1 имеет PRIMARY KEY (id)
Я об этом.
Кстати, иметь в таблице полностью идентичные записи очень, очень некошерно
Это вообще мимо кассы.Taragolis
20.07.2016 17:00Может быть так подойдет?
SELECT t.*
, count(*) over (PARTITION BY t.id) as item_count
, sum(i.price) over (PARTITION BY t.id) as total_price
FROM table1 t
LEFT JOIN items i
ON t.id = i.parent_id
;sasha1024
20.07.2016 17:26+1Ну и оно вернёт кучу повторяющихся записей (по одной строке на пару (t, i), а не на t).
Которые, конечно, можно убрать DISTINCT'ом.
Но, по-моему, это не самое логичное решение.
(Хотя, не спорю, приемлемое; наравне с ручным перечислением в GROUP BY и подзапросом.)Taragolis
20.07.2016 17:30+1Оконки еще будут медленнее GROUP BY.
Еще в голову пришло динамически собирать запрос.
Но вообще использовать SELECT * это как то не по феншую.sasha1024
20.07.2016 18:09У меня запросы и так динамически собираются :).
Тут вопрос (мой) не в том, как сделать, чтоб меньше писать.
Тут вопрос в том, что стандарт касательно GROUP BY (или его реализация в PostgreSQL — хотя скорее всё таки стандарт) немного недоработан.
То, что нельзя вне аггрегатных функций использовать выражения, единственность значений которых не гарантируется — тут я обомя руками за.
То, что считается, что единственность гарантируется только для выражений, явно указанных в GROUP BY — это недоработка. Если первичный ключ какой-то таблицы целиком указан в GROUP BY или целиком за-join-ен с полями, указанными в GROUP BY — то любые выражения над полями этой таблицы имеют единственное значение. Аналогично для non-null UNIQUE-ключей.
Особо прикалывает, что PostgresSQL позволяет писать «GROUP BY t» и «GROUP BY t.*» (где t — алиас таблицы), но обрабатывается оно неожиданно: первый вариант позволяет только непосредственно «SELECT t FROM …» и «SELECT func1(t) FROM …» (но не «SELECT t.field1 FROM …» — при том, что мы можем успешно заюзать «CREATE FUNCTION func1(t table1) RETURNS type1 AS $$begin return t.field1; end$$ LANGUAGE plpgsql IMMUTABLE»), а второй, судя по всему, вообще никак не срабатывает.
Danik-ik
20.07.2016 22:32+1>Это вообще мимо кассы.
Ну, каков вопрос, таков и ответ
SELECT t.* FROM table1 t GROUP BY t.*;
Здесь группировка бессмысленна, если в таблице нет дубликатов, или я не прав?
Про запрос с джойном: кто мешает группировать только правую таблицу по внешнему ключу в подзапросе?
SELECT t.*,i.item_count, i.total_price
FROM table1 t
left join (
select parent_id, count(*) as item_count, sum(price) as total_price
from items
group by parent_id
) i
on t.id=i.parent_id;
Заметь, группировка идёт по одному заведомо индексированному полю, и набор данных для джойна меньше, чем в исходной таблице. Так что и по производительности можно выигратьsasha1024
20.07.2016 23:15>Это вообще мимо кассы.
Ну, каков вопрос, таков и ответ
SELECT t.* FROM table1 t GROUP BY t.*;
Здесь группировка бессмысленна, если в таблице нет дубликатов, или я не прав?
Обсуждение велось в контексте. Имелось в виду «SELECT …, t.*, … FROM table1 t … GROUP BY …, t.*, …» — если уж буквально. Обсуждалась нелогичность того, что нельзя обращаться ко всем полям таблицы, указав в GROUP BY только её первичный ключ, а также того, что просто «t.*» в GROUP BY указать нельзя.
Про запрос с джойном: кто мешает группировать только правую таблицу по внешнему ключу в подзапросе?
SELECT t.*,i.item_count, i.total_price
FROM table1 t
left join (
select parent_id, count(*) as item_count, sum(price) as total_price
from items
group by parent_id
) i
on t.id=i.parent_id;
Заметь, группировка идёт по одному заведомо индексированному полю, и набор данных для джойна меньше, чем в исходной таблице. Так что и по производительности можно выиграть
Разумный вариант. Самый разумный из всех предложенных. Очень надеюсь, что он не быстрее (что DBMS оптимизирует его и исходный до одного состояния) — но по красоте он 100% лучше.sasha1024
20.07.2016 23:31Небольшая разница только между исходным вариантом и новым: если каким-то строкам table1 не соответствует ни одной строки items, то в новом варианте значения всех статистик будут NULL, а в старом — по специфике аггрегатной функции (например, count(*) в старом варианте вернёт 0). Но это несущественно.
P.S.: Если не секрет, почему маляр-штукатур?Danik-ik
22.07.2016 13:30Уже два дня как сантехник. Берусь за всё. Кушать хочется, а из разработчиков ушёл по глупости лет восемь назад на тёплое место. Место остыло, а специализация старая сегодня не востребована (работал в Дельфи ещё до .NET), теперь с тоски переучиваюсь на веб-разработку. Когда время есть, ибо я кормлю жену, четырёх детей и один банк.
Так что не спешите расслабляться раньше пенсии. А любимая работа в целом лучше хорошей работы.sasha1024
22.07.2016 14:56Зато у Вас есть жена и дети. То, что есть отнюдь не у каждого разработчика.
А почему веб-разработка? C++ разве не поближе к Delphi будет?Danik-ik
23.07.2016 20:26+1> А почему веб-разработка? C++ разве не поближе к Delphi будет?
Тут важнее не язык, а область его приложения. Дельфи всегда был заточен под БД и чуток под клиент-серверные технологии, из за чего остался живым именно в .NET. Я делал приложения для работы с базами данных управленческого учёта, аддоны для системы разработки технологической документации (с целью приведения интерфейса ко вменяемому уровню UX), до кучи программировал на полставки промышленные контроллеры в цехе спецстанков и систему сбора статистики со станков стороннего производителя. В общем, полноценная жизнь заводского программиста из спецназа местечкового значения АКА «Группа САПР».
В сухом остатке, помимо промышленных контроллеров (это были Мицубиси, а сейчас в тренде Сименс), фронтенд и базы данных.
Ушёл уже с должности руководителя группы (в мелкую фирму «главным» инженером) из-за того, что завод стагнировал и никому ничего было не надо. Бюджет отсутствовал («Вам же уже все программы купили ещё пять лет назад»), мы вырождались в группу документооборота электронных копий бумажных чертежей с двумя инженерами чтобы слать их по почте и класть на сервер и двумя студентами чтобы сканировать их (на планшетном сканере А3) и сшивать.
А в последнем марте я пробежался по работным сайтам, посмотрел, что мне близко из востребованного в нашей местности — и вот, учу веб-девелопмент, начиная с фронтенда (самое востребованное). Как в работе пауза, так и погружаюсь. Хотя мне, вероятно, был бы более по душе бекэнд, с его развитыми и хорошо структурированными фреймворками. Максимальное удовольствие от работы я получал именно тогда, когда строил универсальные инструменты для решения типовых задач или систематизировал и сериализовал подход к решению задач нетривиальных — и вот, пока я спал, оказалось, что это целый мир…
Такое вот «почему».
P.S. И хочется же в команду с развитыми понятиями о производстве ПО, где другим небезразличны вопросы организации процесса. В общем, в коллектив, который не является «толпой чёрных ящиков». Фриланса не хочется — это не только оставаться одиночкой (чего совсем не хочется), в пределе это наверняка выльется в узкую специализацию, отлаженный процесс и скуку смертную без дальнейшего развития. К тому же я наработался уже «строительным узбеком», и не хочется превращаться в «компьютерного индуса».
vlivyur
26.07.2016 15:17Меня тоже раздражает это, мог бы и автоматом доставить все поля, что в агрегатах не участвуют. Учился SQL когда не было такого требования (хочешь — пиши, не хочешь — не пиши), потом перешли на следующую версию и, помнится, тогда много запросов дописывали.
asmm
19.07.2016 22:07+2Можно добавить в статью, что тестирования запросов существует
sqlfiddle.com
там можно попробовать запросы на разных БД: MySQL, Oracle, PostgesSQL, MSSQL, SQLite
P.S. а ещё есть
eval.in

pilgrim83
20.07.2016 09:14-1а я вот такие пишу в интерпретации 1С:
«ВЫБРАТЬ
| ВложенныйЗапрос.Организация,
| ВложенныйЗапрос.Контрагент,
| ВложенныйЗапрос.ДоговорКонтрагента,
| ВложенныйЗапрос.ЗаказПокупателя,
| ВложенныйЗапрос.Номенклатура,
| ВложенныйЗапрос.ХарактеристикаНоменклатуры,
| ВложенныйЗапрос.Цена,
| ВложенныйЗапрос.СтавкаНДС,
| ВложенныйЗапрос.ДатаОтгрузки,
| ВложенныйЗапрос.ФактическаяДатаОтгрузки,
| ВЫБОР
| КОГДА ЕСТЬNULL(ВложенныйЗапрос.ОбъемПромежуточныхПоставок, 0) = 0
| ТОГДА ВложенныйЗапрос.ОбъемЗаказа
| ИНАЧЕ 0
| КОНЕЦ КАК ОбъемЗаказа,
| ВЫБОР
| КОГДА ЕСТЬNULL(ВложенныйЗапрос.СуммаПромежуточныхПоставок, 0) = 0
| ТОГДА ВложенныйЗапрос.СуммаЗаказа
| ИНАЧЕ 0
| КОНЕЦ КАК СуммаЗаказа,
| ВложенныйЗапрос.ОбъемРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок КАК ОбъемРеализованногоЗаказа,
| ВложенныйЗапрос.СуммаРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок КАК СуммаРеализованногоЗаказа,
| ВложенныйЗапрос.ОбъемПромежуточныхПоставок,
| ВложенныйЗапрос.СуммаПромежуточныхПоставок,
| ВложенныйЗапрос.ОбъемЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ВложенныйЗапрос.ОбъемРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ЕСТЬNULL(ВложенныйЗапрос.ОбъемПромежуточныхПоставок, 0) КАК Недопоставка,
| ВложенныйЗапрос.СуммаЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ВложенныйЗапрос.СуммаРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ЕСТЬNULL(ВложенныйЗапрос.СуммаПромежуточныхПоставок, 0) КАК СуммаНедопоставки,
| (ЕСТЬNULL(ВложенныйЗапрос.ОбъемПромежуточныхПоставок, 0) + ВложенныйЗапрос.ОбъемРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок) / (ВложенныйЗапрос.ОбъемЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок) * 100 КАК ПроцентПоставленногоТовара,
| (ВложенныйЗапрос.СуммаЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ВложенныйЗапрос.СуммаРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ЕСТЬNULL(ВложенныйЗапрос.СуммаПромежуточныхПоставок, 0)) / (100 + ВЫБОР
| КОГДА ВложенныйЗапрос.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.НДС18)
| ТОГДА 18
| КОГДА ВложенныйЗапрос.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.НДС10)
| ТОГДА 10
| КОГДА ВложенныйЗапрос.СтавкаНДС = ЗНАЧЕНИЕ(Перечисление.СтавкиНДС.БезНДС)
| ТОГДА 0
| ИНАЧЕ 0
| КОНЕЦ) * 100 КАК СуммаНедопоставкиБезНДС,
| ВЫБОР
| КОГДА ВложенныйЗапрос.УчитыватьПроцентПоставленногоТовара
| ТОГДА (ВложенныйЗапрос.СуммаЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ЕСТЬNULL(ВложенныйЗапрос.СуммаПромежуточныхПоставок, 0) — ВложенныйЗапрос.СуммаРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок) / 100 * ЕСТЬNULL(ПараметрыРасчетаПроцентПоставленногоТовара.КоэффициентШтрафа, 0)
| ИНАЧЕ 0
| КОНЕЦ КАК ШтрафСУчетомПроцентаПоставленногоТовара,
| ВЫБОР
| КОГДА ВложенныйЗапрос.СуммаЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ВложенныйЗапрос.СуммаРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ЕСТЬNULL(ВложенныйЗапрос.СуммаПромежуточныхПоставок, 0) > 0
| ТОГДА (ВложенныйЗапрос.СуммаЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ВложенныйЗапрос.СуммаРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок — ЕСТЬNULL(ВложенныйЗапрос.СуммаПромежуточныхПоставок, 0)) / 100 * ВЫБОР
| КОГДА ВложенныйЗапрос.ДопустимыйОбъемНедопоставкиВПроцентах > 0
| И (100 — ЕСТЬNULL(ВложенныйЗапрос.ОбъемПромежуточныхПоставок, 0) — ВложенныйЗапрос.ОбъемРеализованногоЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок) / (ВложенныйЗапрос.ОбъемЗаказа / ВложенныйЗапрос.КоличествоПромежуточныхПоставок) * 100 0»
ur002
20.07.2016 17:02Каждый раз когда вижу этот «русский код» в голове, как будто, что то подклинивает :)
pilgrim83
20.07.2016 17:38-1В интерфейсе разработчика можно переключить язык на привычный английский и вместо ВЫБРАТЬ будет SELECT, вместо ИЗ будет FROM, вместо ГДЕ будет WHERE. Там и не только английский, а и много других языков. А объекты ты волен сам разыменовывать на каком тебе нравится. А в условиях работы в России и Российского законодательства русские термины-разыменовывания объектов более рациональны. Кроме того это позволяет не комментировать код, т.к. когда объекты грамотно разыменованы, то код сам по себе несет смысловую нагрузку и назначение этого кода. Отсюда более быстрое восприятие. Стереотипы нужно ломать батенька и не подклиниваться :). Жаль запрос не весь поместился :( Уважаемые модераторы-администраторы увеличьте пожалуйста длину поля комментарий или поставьте неограниченную длину ;)
pilgrim83
20.07.2016 17:43+2p.s. Для новичков: я бы с осторожностью относился к этой статье как к мануалу :) пишите запросы, получайте выборки, учитесь :)
ur002
20.07.2016 17:45да, я знаю об этом, я про сам вариант описания операторов на русском, и про непривычность относительно повседневного SQL для лично меня .
mayorovp
20.07.2016 19:41+2Конкретно в запросе выше проблема не в русском языке — а в форматировании. Для начала — поставить отступы. Конструкцию "КОГДА… ТОГДА… ИНАЧЕ" лучше было бы записать в одну строку. Вместо капитанского "ВложенныйЗапрос" лучше бы написать что именно этот запрос делает. Или напротив, сократить псевдоним до "ВЗ", чтобы не отвлекал.
pilgrim83
20.07.2016 19:46Говорю же запрос полностью не уместился ))), кинь почту я тебе пришлю. А отступы и т.п. я тут не расставлял это так при копи-пасте получилось сорри ))). Меня не отвлекает ВложенныйЗапрос. Методику о том как лучше расставлять КОГДА ТОГДА ИНАЧЕ я нигде не видел. Кроме того если ты будешь строить запрос конструктором то конструкцию КОГДА ТОГДА ИНАЧЕ сам конструктор расставит в разные строки )))
mayorovp
20.07.2016 19:50+3Если строить запрос конструктором — то надо выкладывать не текст запроса, а скриншот конструктора :) Автогенерированный код никому не интересен.
А выкладывать такую простыню текста без форматирования потому что "это так при копи-пасте получилось сорри" — есть неуважение к читателям.
pilgrim83
20.07.2016 19:55-3Кто разбирается тот поймет эту простыню, а кто нет, тому значит ее еще пока рано читать :)
pilgrim83
20.07.2016 20:49-3Скриншот конструктора???? Ты читать то вообще умеешь и понимаешь о чем пишут? Я написал, что если строить конструктором запрос, то после того как составление запроса завершается и конструктор закрывается, то в модуле оказывается текст построенный конструктором, при чем в этом тексте конструкция КОГДА ТОГДА ИНАЧЕ будет располагаться в разных строках и это методика заложена теми, кто разрабатывал платформу между прочим!!! При чем тут скриншот конструктора? Что за бред ты несешь?
pilgrim83
20.07.2016 21:13-3Автогенерированный код?????? Построение запроса конструктором НЕ ЗНАЧИТ что конструктор за разработчика продумает логику!!! Конструктор лишь помогает не писать большие простыни вручную и не запутаться в сложных конструкциях и соединениях со сложными условиями и вложенными таблицами!!!
pilgrim83
20.07.2016 19:47-4А сам запрос работает, проблем из-за форматирования у меня никогда не было. Ты даже себе представить не можешь как я могу извратиться с форматированием запроса, а он все равно будет работать. )))
pilgrim83
20.07.2016 20:04-4Ну раз уж Вы мне тут начали минуса ставить уважаемый и докапываться до форматирования, а не до сути, то я прошу предоставить мне ссылки на методики как лучше конструкции записывать и как мне лучше разыменовывать запросы и должен ли я их сокращать. Пожалуйста в студию Капитан!
pilgrim83
20.07.2016 20:23-4Прошу модераторов повлиять на этого пользователя. Методики предоставлены не были. Авторитет этого пользователя никем не подтвержден. Может ли он давать рекомендации по тому как лучше какие конструкции записывать и какие имена лучше давать таблицам. Никакой объективности!!! У человека всего одна статья на хабре, а ведет себя как профессор информатики.
vEnFy
20.07.2016 10:35+1Низкий вам поклон от новичка, так как только начал заниматься SQL статья лично мне уже многим помогла.
tooleneff
20.07.2016 23:10Мне кажется в пункте 6.2 результат запроса не соответствует поставленной задаче.
Нужно: узнать названия и идентификаторы всех книг, написанных определенным автором, но только если в библиотеке таких книг больше трех.
Получили — книги авторов, чьих книг в библиотеке больше 3.
Книга, экземпляров которой в библиотеке больше 3, одна. Это Who Will Cry When You Die?
webhamster
21.07.2016 12:47Я один вижу, что в примерах используется ключевое слово INNER, но не объясняется что это такое?
sasha1024
21.07.2016 13:02+3«INNER JOIN» и «JOIN» — это одно и то же («INNER» в данном случае просто игнорируемое слово).
Объяснять 100%-необходимо было бы, если бы он где-то использовал другие формы JOIN'ов: «LEFT [OUTER] JOIN», «RIGHT [OUTER] JOIN» или «FULL [OUTER] JOIN» — но такого у него нет.
Хотя сказать пару слов по этому поводу и использовать везде однотипный синтаксис (или JOIN, или INNER JOIN) было бы безусловно лучше.pilgrim83
21.07.2016 18:52-2Вообще-то INNER JOIN это внутреннее соединение — это когда из обеих соединяемых таблиц выбираются только те строки, которые удовлетворяют условию соединения
sasha1024
21.07.2016 18:54+2И?
(В смысле, в чём противочение с тем что я писал? Я всего лишь имел в виду, что INNER — это тип джоина по-умолчанию (когда не указано другое).)pilgrim83
22.07.2016 05:34-2Противоречие в том что человек попросил объяснить что это такое, а в Вашем комментарии этого так и не произошло. Вот и И.
pilgrim83
22.07.2016 09:41-2Держи брат, INNER JOIN это внутреннее соединение — это когда из обеих соединяемых таблиц выбираются только те строки, которые удовлетворяют условию соединения
pilgrim83
23.07.2016 17:33-1Держи братуха, INNER JOIN это внутреннее соединение — это когда из обеих соединяемых таблиц выбираются только те строки, которые удовлетворяют условию соединения
vbif
26.07.2016 15:02А есть ли в каких-то БД какой-нибудь auto join? Например, если я задал в таблице связь между ACCOUNT.ACCOUNT_TYPE и ACCOUNT_TYPES.TYPE_ID, почему я не могу написать просто select ACCOUNT.ACCOUNT_NUMBER, ACCOUNT_TYPES.TYPE_NAME from ACCOUNT, ACCOUNT_TYPES или select ACCOUNT.ACCOUNT_NUMBER, ACCOUNT_TYPES.TYPE_NAME as TYPE from ACCOUNT auto join ACCOUNT_TYPES безо всяких дополнительных on или where?
vlivyur
26.07.2016 15:07Можно без всяких on и where — using есть и natural join. Но всё это фигня, ибо связей может быть больше одной.
vbif
26.07.2016 15:20А что мешает в случае если связей несколько просто выдавать ошибку?
sasha1024
26.07.2016 17:33+1То, что схема со временем имеет тенденцию усложняться. Сегодня из таблицы table1 одна связь на table2, через полгода добавили ещё одну (с другим смыслом). И половина уже отлаженного приложения перестала работать.
sasha1024
26.07.2016 17:49+1У меня была когда-то более здравая мысль — разрешить «ходить» по именованым foreign key'ам (при условии, что они указывают на UNIQUE/PRIMARY KEY).
Например, в схеме:
вместоCREATE TABLE universities ( id serial not null PRIMARY KEY, … ); CREATE TABLE faculties ( id serial not null PRIMARY KEY, …, university_id int not null, CONSTRAINT university FOREIGN KEY (university_id) REFERENCES universities (id) ); CREATE TABLE students ( id serial not null PRIMARY KEY, …, faculty_id int not null, CONSTRAINT faculty FOREIGN KEY (faculty_id) REFERENCES faculties (id) );
разрешить писатьSELECT s.…, f.…, u.… FROM students s join faculties f on s.faculty_id=f.id join universities u on f.university_id=u.id;SELECT s.…, s.faculty.…, s.faculty.university.… FROM students s;Taragolis
26.07.2016 20:03Немного о наболевшем, на чужом проекте можно столкнуться с такими вещами «FK / PK — не мы этим не пользуемся»
asmm
26.07.2016 16:07Нет, т.к. тебе могут разные типы соединений понадобится с этими таблицами.
Например, есть таблица USERS у которой необязательный ключ на Т.ACCOUNT — ACCOUNT_ID
Запрос 1:
SELECT * FROM USERS INNER JOIN ACCOUNT ON USERS.ACCOUNT_ID = ACCOUNT.ID INNER JOIN ACCOUNT_TYPES ON ACCOUNT.TYPE_ID = ACCOUNT_TYPES.ID
Запрос 2:
SELECT * FROM USERS LEFT JOIN ACCOUNT ON USERS.ACCOUNT_ID = ACCOUNT.ID LEFT JOIN ACCOUNT_TYPES ON ACCOUNT.TYPE_ID = ACCOUNT_TYPES.ID
И первый, и второй запросы верные, но выдают разные результаты.vlivyur
26.07.2016 16:21Смысл чтоб ON были необязательными, если ключ присутствует. Т.е., left, inner, full, cross остаются, но без on. Тогда разработчик будет каждый раз чесать репу «а по каким полям?», а сервак мусолить винт «а по каким полям?». Такое может прокатить, но на простых запросах. Проще разработчика разок напрячь, чтоб правильно написал что хочет, ему же потом самому легче будет.
SQL так-то любит чтоб всё было разжёвано.asmm
26.07.2016 16:44А так-то, без ON вполне здравая мысль.
Разработчику особо дела нет как там эти поля называются, БД может проверить что должен существовать FK в единственном числе и одним концом смотреть на PK и, если уж на то пошло, то IDE может подсказать разрабу что это за FK и какие ключи там есть.
Так что в целом мысль вполне годная.
Если я создал FK, то и соединять в 99% случаев буду по нему.
Лучше бы БД варнинги выдавала на JOIN'ы без FK.
Хотя тут тоже не однозначно, под «ACCOUNT» может быть накручена такая огромная VIEW
almkhaj
Статья для новичков, наверное, не плохая. Однако, большим опытом здесь не пахнет. Сразу в глаза бросается использование
EndUser
Я сам так пишу, если нет необходимости в алиасе.
martin_wanderer
Необходимость в алиасе есть практически всегда: не сразу так потом понадобится. Опять же алиас упрощает использование код-ассиста.
TITnet
Зачем нужны алиасы? В смысле, в чём именно необходимость?
martin_wanderer
Необходимость возникает в тот момент, когда запрос надо доработать:
martin_wanderer
Необходимость возникает в тот момент, когда запрос надо доработать.
Варианты:
1) надо добавить еще одно поле и я не помню, как оно точно называется. Набираю короткий алиас, и список полей таблицы у меня перед глазами. Нет алиаса — я вынужден идти смотреть описание таблицы.
2) надо приджойнить таблицу в которой есть совпадающее поле — тут же становится необходимо завести алиас
3) надо просто понять, что делает запрос, а в нем идет соединение таблиц без алиасов и не ясно, какое поле к какой таблице относится.
В общем я считаю, что обязательное использование алиасов — хороший стиль.
sasha1024
Я практически всегда юзаю алиасы по двум причинам:
students.surnameиbooks.title— как-то не комильфо. Т.е. названию таблицы во множественном делаю алиас в единственном числе (или вообще аббревиатурой), чтобы множественное число не задевало моё чувство прекрасного.А так, да, если таблица не джоинится сама с собой (и в запросе к таблице нету подзапросов к той же таблице), то критической необходимости использования алиасов, вроде бы, нет.
P.S.: К этому следует добавить, что я всегда префиксирую название поля названием или алиасом таблицы. Потому что если сейчас название поля уникальное, то не факт, что оно таким останется. Ну и плюс сразу ясно откуда поле.
Mingun
Например, обращаться к той же самой таблице в подзапросе. Простейший пример, у нас есть таблица-журнал операций:
и мы хотим выбрать самую последнюю запись по истории:
Без псевдонима это было бы сделать невозможно, поскольку таблица.и в основном запросе, и в подзапросе одна и та же.
Mingun
Но вообще, лично я для себя решил, что там, где псевдонимы для однозначного и чёткого определения принадлежности колонок не требуются, их не указывать. В примере выше такими местами являются:
order by entity_id— поскольку в выборке участвует всего одна таблица, псевдонимы при перечислении колонок указывать нет необходимости. Если бы в запросе участвовало бы две таблицы (соединённые черезjoin, к примеру), то имя каждой колонки в обязательном порядке указывалось бы вместе с псевдонимом таблицы;and entity_id > e.entity_id— аналогично, в подзапросе таблица всего одна, нет необходимости указывать псевдоним, движок СУБД сам определит, к какой таблице относятся поля — к самой ближайшей.Так запросы становится значительно легче воспринимать.