

В последний год в Badoo стали очень активно использовать связку Hadoop + Spark и построили свою систему сбора и обработки десятков миллионов метрик при помощи Spark Streaming.
Для того чтобы расширить наши знания и познакомиться с последними новинками в этой сфере, в конце мая этого года разработчики отдела BI (Business Intelligence) отправились в Лондон, где проходила очередная конференция серии Hadoop + Strata, посвященная широкому спектру вопросов в области машинного обучения, обработки и анализа больших данных.
В первую очередь нас интересовал именно стек технологий, который мы используем. Под доклады про Spark был выделен целый поток, на котором выступали создатели, активные «контрибьюторы» и авторы книг из Cloudera, Databricks, Hortonworks и IBM.
Организаторами конференции являются компания O’Reilly, известная всем как издательство в области IT, выпускающее книги с причудливыми животными на обложках, и IT-компания Cloudera, специализирующая на Hadoop-based решениях.
В этом году местом проведения конференции стал огромный выставочный зал London ExCel. Его размеры потрясают воображение. Оно расположено между двумя станциями поезда DLR, и если не знать, в какой части будет проходить нужное мероприятие, то можно потратить 15-20 минут, чтобы дойти из одного конца здания в другой.
Не менее масштабным был размах и самого мероприятия. Конференция длилась 4 дня, со вторника по пятницу. В первые два дня проходили вводные лекции, семинары и мастер-классы, в следующие — непосредственно сама конференция. Как, наверное, и полагается конференции, посвященной работе с большими данными, представленный на ней объем информации был колоссальным. Она началась серией из восьми (!) пленарных докладов, после чего открылось больше 10 параллельных секций, в каждой из которых было по 6 часовых докладов.
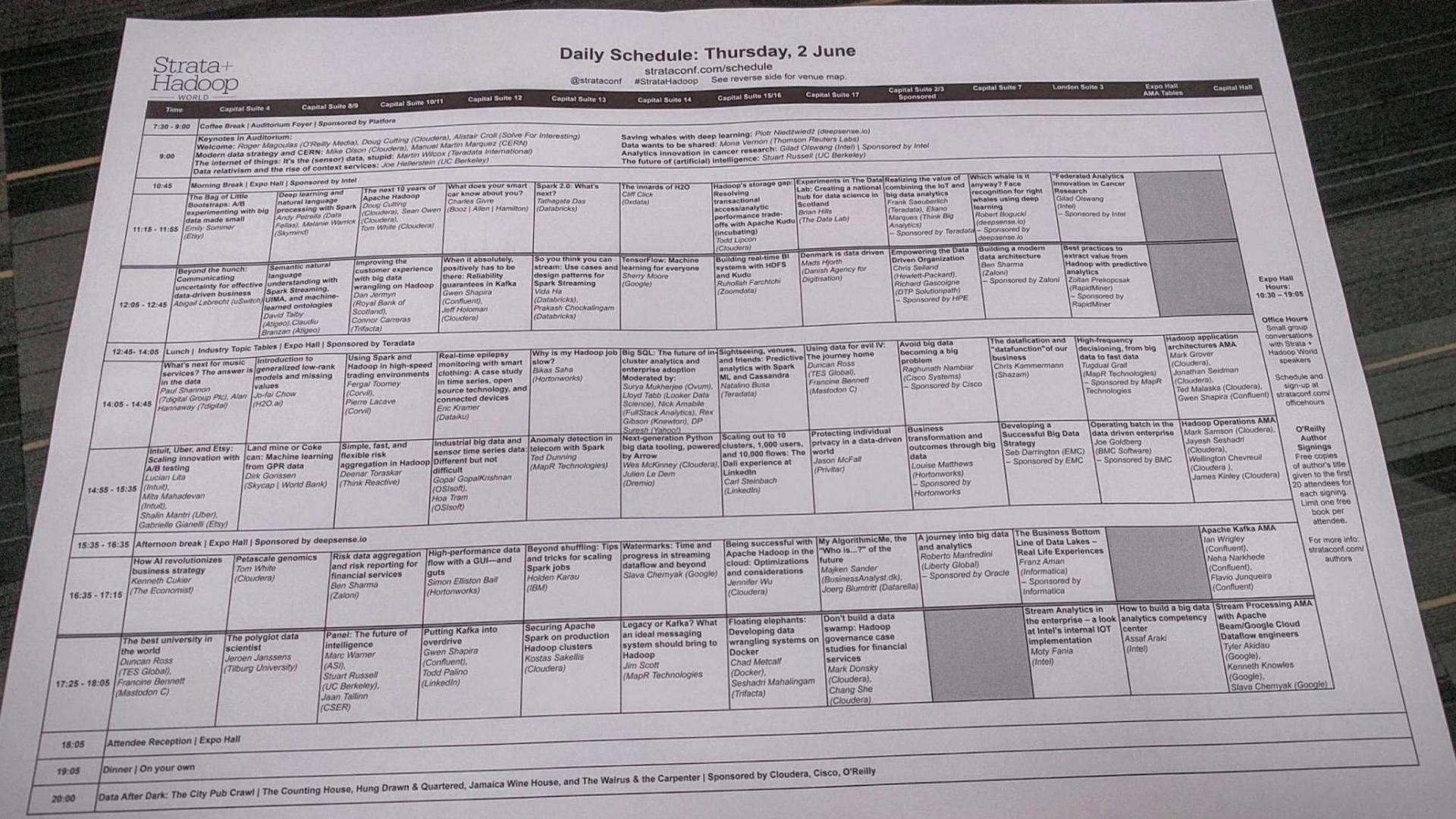
Имея такое плотное расписание, организаторам стоило бы уделить больше внимания тому, как сделать его понятным. Можно было бы, например, указать тематику каждой из секций, или сделать разделение докладов по целевой аудитории (т.е. разделить на доклады для инженеров, аналитиков и представителей бизнеса).
Вместо этого при регистрации раздавались листы A3 с расписанием, написанным мельчайшим шрифтом. Правда, в качестве альтернативы можно было использовать мобильное приложение, в котором была возможность отслеживать происходящие в данный момент мероприятия и составить свое собственное расписание.
Каждый день конференции открывался серией коротких keynotes, в которых спикеры за 10-15 минут делились своими взглядами на основные тренды в области искусственного интеллекта, анализа данных, машинного обучения, безопасности. После этих выступлений открывались секции с докладами. Про доклады, которые показались нам наиболее интересными, мы и расскажем в сегодняшнем обзоре.
Spark 2.0 What’s next?
Первым в секции, посвященной Apache Spark, выступил Tathagata Daz, разработчик из Databricks (он сразу отметил, что имя его никто выговорить не может, поэтому все зовут его просто TD). В своем докладе он рассказал о том, чего нам ждать в релизе Apache Spark 2.0.
TD сообщил, что «мажорный» релиз запланирован на июнь этого года. На момент написания статьи по-прежнему всем доступна только версия unstable preview release. Также докладчик заверил, что несмотря на «мажорность» релиза, обратная совместимость с 1.х почти полностью сохранена.
Теперь непосредственно об обещанных прорывных фичах этого релиза:
- Tungsten Phase 2. Проект Tungsten — это комплекс оптимизаций, направленных на улучшение работы памяти и утилизации железа в фреймворке Spark. В обновленной версии обещают ускорение работы Tungsten в 5-10 раз. Оно было достигнуто за счет оптимизации кодогенерации и улучшения алгоритмов работы с памятью. Если раньше запрос из нескольких последовательных операций требовал цепочку виртуальных вызовов, то теперь он будет компилироваться в единый кусок кода.
- Structured Streaming. Получив много откликов от разработчиков, команда Spark серьезно переработала модель стриминга. Обновленная версия предполагает использование «интерактивного» стриминга под названием Structured Streaming, в котором можно будет в runtime выполнять различные запросы на существующем стриме и строить модели machine learning. По сути, это высокоуровневое API, построенное поверх SQL API. Благодаря этому стриминг должен получить все оптимизации от Tungsten.
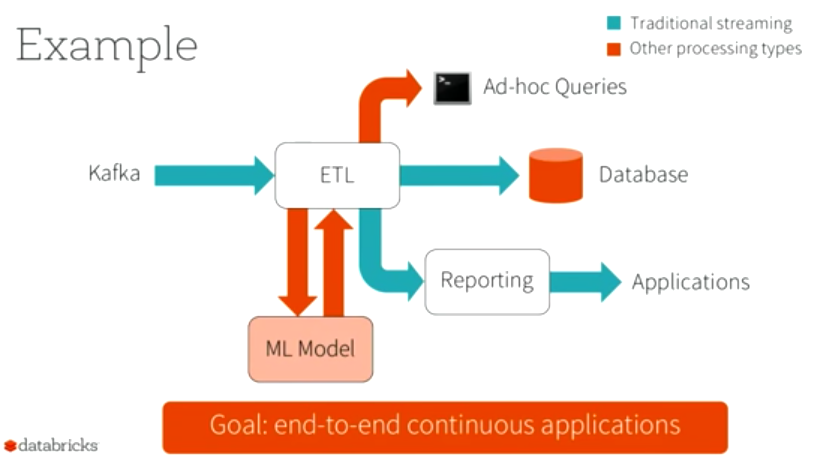
- Datasets and DataFrames. В новой версии при создании объекта DataFrame = Dataset[Row] происходит объединение этих двух API. Это дает возможность производить над объектами DataFrame в Dateset операции map, filter и т.п. Функционал Dataset помечен как экспериментальный и является одним из тех мест, где ломается совместимость с 1.x-версиями.

Если вы разрабатываете приложения на Spark, то обязательно выделите время летом, чтобы подготовиться и перейти на новую версию. Улучшения API и прирост производительности обещают быть впечатляющими.
Очень похожий доклад со Spark Summit от Матея Закарии (англ. Matei Zaharia), CTO Databricks и создателя Spark, можно посмотреть тут: Spark 2.0.
The future of Streaming in Spark. Structured Streaming
Вторым докладом от TD на конференции был более детальный рассказ о том, как будет развиваться направление Spark Streaming — компонента фреймворка, который отвечает за быструю и устойчивую к отказам обработку потока данных в реальном времени. Со слов спикера, больше половины разработчиков, использующих Spark, считают, что Spark Streaming — наиболее важный компонент системы.
Основной вывод, который разработчики сделали за 3 года существования стриминга: этот процесс не должен происходить в изоляции. Пользователям нужно не просто получить поток данных, обработать его и положить в БД для последующего использования. В большинстве случаев необходимо также к этому потоку подключить мониторинг, забирать данные для машинного обучения и т.п.
В связи с этим разработчики стали мыслить шире и называть новый проект не просто Streaming, а Continuous Applications, в рамках которого будут добавлены все вышеперечисленные возможности.
TD рассмотрел основные проблемные места текущей модели D-Streams, после чего представил новое решение, называемое Structured Streaming.
Structured Streaming — новая концепция, которая предлагает взглянуть на стриминг как на работу с бесконечной таблицей.

Данные из этой таблицы можно запрашивать при помощи SQL-запросов через DataFrames API. В зависимости от того, что нужно пользователю, запрос можно вызывать как по всем данных, так и только по дельте полученных данных.
Благодаря объединению API dstreams и DataFrames стало возможным выполнять операции объединения данных из стрима со статическим набором.
Также в этом докладе рассмотрели, как новая система работает «под капотом» и, что особенно важно, каким образом будет достигать fault tolerance.
Если вы строите сложные системы поверх Spark Streaming, то вам обязательно стоит изучить новую концепцию Structured Streaming, так как, по заверениям разработчиков, вы получите быстрый, устойчивый к отказам стриминг с максимально упрощенным API.
Спецификацию можно почитать тут: Structured Streaming Programming Abstraction Semanticsand APIs.
Запись аналогичного доклада от того же автора, но со Spark Summit, можно посмотреть тут: A Deep Dive Into Structured Streaming
Обед по расписанию
В перерывах между докладами организаторы устраивали совершенно стандартные кофе-брейки, а в час дня начинался обед. В отличие от многих IT-конференций, обед на Hadoop+Strata не являлся дополнительной опцией, а предоставлялся спонсорами конференции. Например, в первый день обеды от компании Teradata были остывшими и пресными, а на второй, от IBM — сытными и горячими.
Beyond shuffling by Holden Karau

Экстравагантная докладчица под перезвон металлических колец на шее рассказала много интересного про внутренности Spark.
Выполняется Spark-задача, приходит время стадии Shuffle и… OOM-killer!
А хочется счастья и котиков. Кстати, о котиках: их в докладе было предостаточно. Ну нравятся они ей. Не придавайте значения, просто «ми-ми-ми», и все.
Итак, откуда может возникнуть лишнее потребление памяти и падение производительности?
- Выполнение ненужной группировки по ключу. Если есть возможность, нужно использовать не groupByKey, а reduceByKey. Это сразу сокращает объем данных.
- Неравномерно распределенные данные. Если по одному ключу данных намного больше, чем по остальным, то после выполнения shuffle все эти данные попадут на один reducer и… OOM-killer тут как тут! Поэтому может пригодиться замена shuffler.
- Необходимость использовать join с другими наборами данных. Ну, это вообще беда всех map-reduce-алгоритмов, потому что невозможно уменьшать объемы данных, можно только увеличивать. Надо быть осторожным, чтобы не было взрывного увеличения.
Все это разбирается и объясняется, предлагаются пути решения. Рассказано, какие проблемы могут подстерегать при дальнейших оптимизациях.
Ну и конечно, куда же без новых возможностей готовящегося к выпуску Spark 2.0.
Далее речь шла о unit-тестировании для Spark. И на закуску — предложение присылать неподдающийся оптимизации код.
В общем, было интересно и познавательно, хотя без применения на практике не всем и не все понятно.
Слайды к докладу на Slideshare
Демонстрации на стендах
На стендах компаний можно было пообщаться с их представителями, а на некоторых — и с авторами продуктов.
Например, на стенде MapR Ted Dunning показал мне, как работает MapR-FS. Подмонтировал кластер как домашний каталог, в одной консоли начал периодически записывать в файл текущее время, а в другой запустил tail -f. В общем, круто! Просто работаем с файлами, а файловая система сама занимается серверами, репликацией и всем прочим. И читать данные, опять же, можно не только как файлы примонтированной к клиенту FS, но и использовать в Hive/Spark для обработки.
Есть у этой FS и community-версия. Думаю, надо попробовать использовать!
Securing Apache Spark on production Hadoop clusters

Если Вам предстоит настраивать безопасность Spark или Hadoop — однозначно добавляйте это выступление в закладки! Сначала докладчик немного рассказал из истории развития системы безопасности в Hadoop, какие компоненты в нее входят. В общем-то, изначально никакой безопасности там не предполагалось, все появилось гораздо позже, и отчасти этим объясняется то, как все устроено.
Безопасность данных в Spark базируется на безопасности данных в Hadoop. Поэтому рассказ начинается с Kerberos для авторизации пользователей и настройки HDFS/YARN.
Итак, защищаем все по порядку:
- авторизация пользователей;
- HDFS;
- YARN;
- Web UI;
- PRC API;
- EncryptedFS;
- оn-the-wire data encryption;
- память JVM;
- шифрование временных shuffle-блоков.
Уф, вроде ничего не забыл. Если забыл — все есть в докладе!
Потом рассказывалось, какие есть варианты раздачи привилегий: на уровне файлов, на уровне таблиц Hive, на уровне строк и столбцов. Когда какие возможны, чем отличаются.
Рассказано про перспективы развития безопасности в Spark.
Так что теперь я знаю про безопасность все. Ну, как мне кажется.
Аналогичный доклад с Hadoop Summit можно посмотреть тут Securing Spark on Production Hadoop Clusters
Хлеб и зрелища

В конце первого дня докладов прошли сразу две afterparty. Сначала большинство спикеров и участников конференции отправились в выставочный зал, где прямо на стендах спонсоров организаторы выставили алкогольные и прохладительные напитки и горячие закуски, чем снизили градус формальности мероприятия до минимума и разогрели публику для второй вечеринки — традиционного для конференции Bar Crawl (популярной в Лондоне забавы, когда участники проводят вечер, перемещаясь из одного паба в другой по определенному маршруту).
В течение дня организаторы и волонтеры раздавали участникам конференции «маршрутные листы», в которых была указана цепочка из 4-х лондонских пабов, в которых необходимо было последовательно «отдохнуть». Как и обеды, пиво и закуски в пабах были предоставлены спонсорами. Некоторые заведения были полностью арендованы на весь вечер, в других участники наводили ужас на местных завсегдатаев.

На утро следующего дня по помятым лицам и призовым худи легко можно было отличить участников, которые смогли посетить все пабы.
Не все смогли после бурной ночи прийти на второй день конференции. Но мы смогли и даже попали на пару интересных докладов. Далее делимся впечатлениями.
Why is my Hadoop job slow?
Познавательный доклад про инструменты мониторинга состояния Hadoop-кластера Apache Ambari.
Приведены примеры использования Ambari Metrics System, стандартных дашбордов по подсистемам (HDFS, YARN, HBase).
Показаны и конкретные случаи наблюдаемых ситуаций.

Показано, как и что можно обнаружить в логах аудита HDFS и YARN, как работать с логами через Ambari.
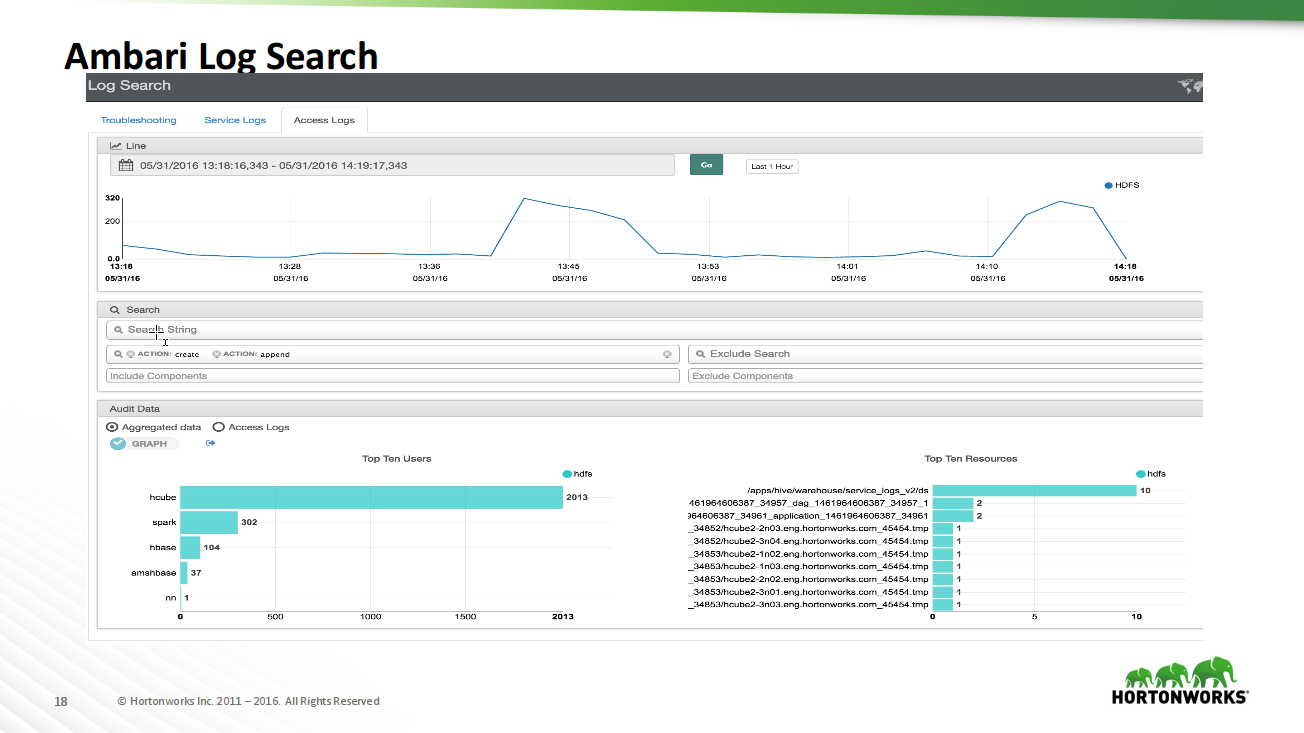
Полезный инструмент! Позволяет более детально понять, почему кластер ведет себя так или иначе, хватает ли ресурсов задачам, как и что выполняется.
Попытался разобраться, как бы и нам такую штуковину использовать, но пока запнулся на том, что по официальной документации кластер должен разворачиваться через Ambari, а у нас уже есть кластер. Не убивать же его? Так что буду копать дальше.
Слайды презентации (осторожно ссылка на файл .pptx)
Автограф-сессии
Организатором конференции была компания O'Reilly, и ей, разумеется, принадлежал большой стенд на самом входе в выставочный зал. Здесь можно было приобрести по сниженным ценам их книжные новинки, посвященные Big Data, а потом найти на конференции авторов и подписать книги.
Также на стенде висело расписание автограф-сессий, и в длинных перерывах между докладами можно было получить в подарок из рук авторов подписанные early release будущих книг.

Впрочем, как и все бесплатное, эти early release книги оказывались довольно бесполезными, а в некоторых случаях — откровенно рекламными.
Ложка дегтя и хитрости спонсоров
Как и любую конференцию, Strata не обошли стороной маркетологи, которых хлебом не корми, а только дай расставить свои хитрые ловушки по всей территории.
Умные опытные люди еще перед началом конференции предостерегли от посещения докладов, отмеченных в расписании словами Sponsored by X, так как все они несут исключительно рекламный характер.
Также, к сожалению, попадались доклады, в названии и описании которых использовались нужные слушателям buzzwords, но на практике докладчики продвигали свой продукт и могли вообще словом не обмолвиться о заявленных в описании технологиях.
У каждого участника конференции был бейдж с личной пластиковой карточкой и установленной rfid-меткой, и на каждом стенде хитрые спонсоры раздавали наклейки, мягкие игрушки и другие сувениры только после того, как подошедший давал отсканировать свой бейдж, т.е. делился всеми своими регистрационными данными с этим спонсором.
На некоторых стендах умудрялись отсканировать бейдж еще до того, как отвечали слушателю на его вопросы.
Из-за этих фокусов потом пришлось потратить некоторое время на отписывание от всех спонсорских рассылок.
Вместо заключения
Конференция Strata + Hadoop проходит в разных странах мира 5 раз в год. Следующая, например, будет в начале августа в Пекине. Если вы еще не решили, стоит ли вам посещать конференции этой серии, то рекомендовать тут довольно сложно.
С одной стороны, если ваш интерес сконцентрирован преимущественно на инженерных докладах и конкретных технологиях, то стоит скорее посетить какое-нибудь более узкоспециализированное мероприятие. Например, Spark Summit. Там, судя по описанию, выступает очень много инженеров, и многие из них сами жаждут получить от слушателей обратную связь и «фичереквесты» для будущей разработки.
С другой стороны, если у вас довольно большая команда BI, то благодаря очень широкому спектру докладов для каждого найдется много интересного и вы точно не потратите время зря. Также вы обязательно получите очень профессиональную организацию мероприятия, позитивную атмосферу и возможность пообщаться с создателями всех популярных продуктов в области data science, machine learning и business analytics.
Вадим Бабаев, инженер-программист BI
Валерий Старынин, инженер-программист BI
Поделиться с друзьями
skullodrom
>В обновленной версии обещают ускорение работы Tungsten в 5-10 раз.
Мне нравится маркетинг новых технологий.
2008 Hadoop is faster than Oracle in 10 times
2010 Hive is faster than Hadoop in 5 times
2012 Spark is faster than Hive in 600 times
2014 Parket is faster than Spark in 5 times
2016 Tungsten is faster than Parket in 10 times.
Так примерно посчитал что современный джуноровские оупенсорсные технологии чисто математический должны сделать Оракл в 100500 раз, а на практике… а воз и ныне там :)
vbabaev
Ну вот, 26го числа спарк 2 таки вышел, теперь можно попробовать оценить.
Скорее всего их 5-10 раз будут только в каком-нибудь частном случае вида select count(*)