
Является ли ошибкой ответ 5хх, если его никто не видит? [1]

Вне зависимости от того, как долго и тщательно программное обеспечение проверяется перед запуском, часть проблем проявляется только в рабочем окружении. Например, race condition от параллельного обслуживания большого количества клиентов или исключения при валидации непредвиденных данных от пользователя. В результате эти проблемы могут привести к 5хх ошибкам.
HTTP 5хх ответы зачастую возвращаются пользователям и могут нанести ущерб репутации компании даже за короткий промежуток времени. В то же время, отладить проблему на рабочем сервере зачастую очень непросто. Даже простое извлечение проблемной сессии из логов может превратиться в поиск иголки в стоге сена. И даже если будут собраны все необходимые логи со всех рабочих серверов — этого может быть недостаточно для понимания причин проблемы.
Для облегчения процесса поиска и отладки могут быть использованы некоторые полезные приёмы в случае, когда NGINX используется для проксирования или балансировки приложения. В этой статье будет рассмотрено особое использование директивы
error_page в применении к типичной инфраструктуре приложения с проксированием через NGINX.Сервер отладки
Сервер отладки (отладочный сервер, Debug Server) — специальный сервер, на который перенаправляются запросы, вызывающие ошибки на рабочих серверах. Это достигается использованием того преимущества, что NGINX может детектировать 5xx ошибки, возвращаемые из upstream и перенаправлять приводящие к ошибкам запросы из разных групп upstream на отладочный сервер. А так как отладочный сервер будет обрабатывать только запросы, приводящие к ошибкам, то в логах будет информация, относящаяся исключительно к ошибкам. Таким образом, проблема поиска иголок в стоге сена сводится к горстке иголок.
Так как отладочный сервер не обслуживает рабочие клиентские запросы, то нет нужды затачивать его на производительность. Вместо этого, на нём можно включить максимальное логирование и добавить инструменты диагностики на любой вкус. Например:
- Запуск приложения в режиме отладки
- Включение подробного логирования на сервере
- Добавление профилирования приложения
- Подсчет ресурсов использованных сервером
Инструменты отладки обычно отключаются для рабочих серверов, так как зачастую замедляют работу приложения. Однако, для отладочного сервера их можно безопасно включить. Ниже приведён пример инфраструктуры приложения с отладочным сервером.
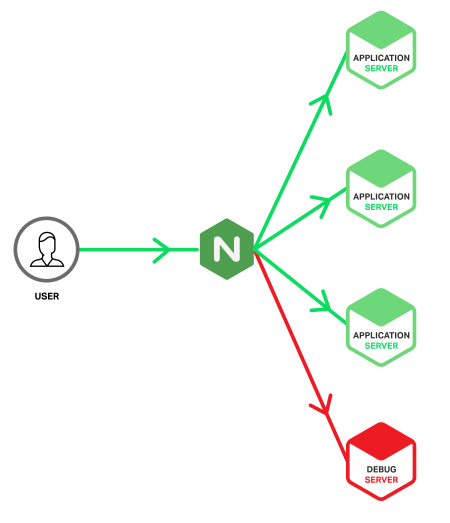
В идеальном мире, процесс конфигурирования и выделение ресурсов для отладочного сервера не должен отличаться от процесса настройки обычного рабочего сервера. Но если сделать сервер отладки в виде виртуальной машины, то в этом могут быть свои преимущества (например, клонирование и копирование для автономной аналитики). Однако, в таком случае, существует риск, что сервер может быть перегружен в случае возникновения серьёзной проблемы, которая вызовет внезапный всплеск ошибок 5xx. В NGINX Plus этого можно избежать с помощью параметра max_conns для ограничения количества параллельных соединений (ниже будет приведён пример конфигурации).
Так как сервер отладки загружен не так, как рабочий сервер, то не все ошибки 5xx могут воспроизводиться. В такой ситуации можно предположить, что вы достигли предела масштабирования приложения и исчерпали ресурсы, и никакой ошибки в самом приложении нет. Независимо от основной причины, использование отладочного сервера поможет улучшить взаимодействие с пользователем и предостеречь его от 5xx ошибок.
Конфигурация
Ниже приведен простой пример конфигурации сервера отладки для приема запросов, которые привели к 5xx ошибке на одном из основных серверов.
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
}
В блоке upstream
app_server указаны адреса рабочих серверов. Далее указывается один адрес сервера отладки в upstream debug_server.Первый блок location настраивает простое проксирование с помощью директивы proxy_pass для балансировки серверов приложения в
upstream app_server (в примере не указан алгоритм балансировки, поэтому используется стандартный алгоритм Round Robin). Включенная директива proxy_intercept_errors означает, что любой ответ с HTTP статусом 300 или выше будет обрабатываться с помощью директивы error_page. В нашем примере перехватываются только 500, 503 и 504 ошибки и передаются на обработку в блок location @debug. Все остальные ответы, такие как 404, отсылаются пользователю без изменений.В блоке
@debug происходят два действия: во-первых, проксирование в группу upstream debug_server, которая, разумеется, содержит сервер отладки; во-вторых, запись access_log и error_log в отдельные файлы. Изолируя сообщения, сгенерированные ошибочными запросами на рабочие сервера, можно легко соотнести их с ошибками, которые сгенерируются на самом отладочном сервере.Отметим, что директива access_log ссылается на отдельный формат логирования — detailed. Этот формат можно определить, указав в директиве log_format на уровне
http следующие значения:log_format detailed '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_length $request_time '
'$upstream_response_length $upstream_response_time '
'$upstream_status';
Формат detailed расширяет формат по умолчанию combined добавлением пяти переменных, которые предоставляют дополнительную информацию о запросе к отладочному серверу и его ответе.
$request_length– полный размер запроса, включая заголовки и тело, в байтах$request_time– время обработки запроса, в миллисекундах$upstream_response_length– длинна ответа полученного от отладочного сервера, в байтах$upstream_response_time– время затраченное на получение ответа от отладочного сервера, в миллисекундах$upstream_status– код статуса ответа от отладочного сервера
Перечисленные выше дополнительные поля в логе очень полезны для детектирования некорректных запросов и запросов с большим временем выполнения. Последние могут указывать на неверные таймауты в приложении или другие межпроцессные коммуникационные проблемы.
Идемпотентность при переотправке запросов
Возможно, в некоторых случаях, хочется избежать перенаправления запросов на сервер отладки. Например, если в приложении произошла ошибка при попытке изменить несколько записей в базе данных, то новый запрос может повторить обращение к базе данных и внести изменения ещё раз. Это может привести к беспорядку в базе данных.
Поэтому безопасно переотправлять запрос можно только в случае, если он идемпотентный – то есть запрос, при повторных отправках которого, результат будет один и тот же. HTTP
GET, PUT, и DELETE методы идемпотентны, в то время как POST – нет. Однако, стоит отметить, что идемпотентность HTTP методов может зависеть от реализации приложения и отличаться от формально определенных.Есть три варианта как обрабатывать идемпотентность на отладочном сервере:
- Запустить отладочный сервер в режиме read-only для базы данных. В таком случае переотправка запросов безопасна, так как не вносит никаких изменений. Логирование запросов на отладочном сервере будет происходить без изменений, но меньше информации будет доступно для диагностики проблемы (из-за режима read-only).
- Переотправлять на отладочный сервер только идемпотентные запросы.
- Развернуть второй отладочный сервер в режиме read-only для базы данных и переотправлять на него неидемпотентные запросы, а идемпотентные продолжать отправлять на основной сервер отладки. В таком случае будут обрабатываться все запросы, но потребуется дополнительная настройка.
Для полноты картины, рассмотрим конфигурацию для третьего варианта:
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
upstream readonly_server {
server 172.16.0.10 max_conns=20;
}
map $request_method $debug_location {
'POST' @readonly;
'LOCK' @readonly;
'PATCH' @readonly;
default @debug;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 $debug_location;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
location @readonly {
proxy_pass http://readonly_server;
access_log /var/log/nginx/access_readonly_server.log detailed;
error_log /var/log/nginx/error_readonly_server.log;
}
}
Используя директиву map с переменной $request_method, в зависимости от идемпотентности метода, устанавливается значение новой переменной
$debug_location. При срабатывании директивы error_page вычисляется переменная $debug_location, и определяется, на какой именно отладочный сервер будет переотправляться запрос.Нередко для повторной отправки неудавшихся запросов на остальные сервера в upstream (перед отправкой на отладочный сервер) используется директива proxy_next_upstream. Хотя, как правило, это используется для ошибок на сетевом уровне, но возможно также расширение и для 5xx ошибок. Начиная с версии NGINX 1.9.13 неидемпотентные запросы, которые приводят к ошибкам 5xx, не переотправляются по умолчанию. Для включения такого поведения, нужно добавить параметр
non_idempotent в директиве proxy_next_upstream. Такое же поведение реализовано в NGINX Plus начиная с версии R9 (апрель 2016г.).location / {
proxy_pass http://app_server;
proxy_next_upstream http_500 http_503 http_504 non_idempotent;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
Заключение
Не стоит игнорировать ошибки 5хх. Если вы используете модель DevOps, экспериментируете с Continuous Delivery или просто желаете уменьшить риск при обновлениях — NGINX предоставляет инструменты, которые могут помочь лучше реагировать на возникающие проблемы.
Поделиться с друзьями
Комментарии (4)

Bambr
06.09.2016 09:53В приведенных примерах юзеру придется ждать последовательной обработки его запроса двумя бекендами, прежде чем он получит болт. Это не очень хорошо. Обратите внимание на недокументированную (но давно работающую) директиву post_action. С ее помощью можно уже после обработки запроса для клиента перейти в именованный локейшн. Так, в вашем случае можно быстренько отдать клиенту какой-нибудь там /error/500.html, и уже неспешно сделать post_action на дебажный сервер. Юзер его результатов не увидит и ждать лишнее время не будет.

VBart
07.09.2016 02:30Ждать он будет когда попытается открыть другую страницу. Использовать недокументированную директиву, которая недокументирована по той причине, что её лучше не использовать — это плохая идея.
Andropolon
Спасибо за примеры конфигов.
Однако, стоит отметить, что одна из частых причин ошибок 5xx — это невыложенное обновление на одну из реплик серверов.
Причин может быть масса:
У нас на репликах серверов настроено независимое логирование 5xx ошибок. Да, оно менее информативное, и его можно комбинировать с вашим способом, но забывать про это не стоит.
thunderspb
Обновление ОС и ребут на продакшене? Звучит как «автоматическое» :) Но есть хорошая практика нотификаций и согласований с ответственными за систему и девопс отделом как минимум.
Еще хорошая практика проверить что прилетело на сервер физически. Есть serverspec например. К тому же вывести репику из апстрима тоже хорошая идея и вернуть только после теста.
Ну эт так, что первое в голову пришло. В общем — «что-то сбойнуло» — неправильно построенный деплой процесс как минимум.