
Например, ваша поисковая выдача меняется от пользователя к пользователю. И сортировка, основанная только на данных самого документа (TF/IDF или сортировки по любым полям документа), не дает нужного результата. При этом в поисковой выдаче интернет-магазина вы хотите показать товар, который пользователь уже смотрел на первых позициях.
Другой пример. Параметр, влияющий на сортировку, меняется слишком часто: Elasticsearch построен на базе Lucene и использует append-only хранилище, обновление документов фактически отсутствует. Каждое изменение документа приводит к его переиндексации и влечет периодическое перестроение сегментов хранилища. Иными словами, если вы хотите отсортировать выдачу по количеству просмотров документа на сайте, то самое тупое, что можно сделать, — это записывать каждый просмотр в Elasticsearch. И здесь, похоже, назрел вопрос использования внешнего хранилища мета-информации, используемой для сортировки документов.

В одном из своих проектов мы используем Elasticsearch в качестве основного хранилища. Это позволяет нам масштабировать систему под десятки миллионов документов без лишних телодвижений и при этом сохранять отклик, измеряемый десятками миллисекунд. Основу нашего проекта составляют документы (странички сайтов, посты в пабликах, GIF или Youtube-ролики. Каждый документ представляет собой страничку с распарсенным контентом. Документы имеют мета-информацию: оригинальный url, теги и т.д. Elasticsearch позволяет нам делать очень быстрые пересечения для построения фидов по интересам (несколько сайтов в одном фиде), а также использовать функциональность Google Alert, в рамках которой можно создать фид по любому словосочетанию.
Проблемы начались, когда мы решили добавить в наше приложение возможности голосований и сортировки документы по популярности. Как мы уже говорили, не стоит писать такие часто меняющиеся данные в ES.
Задача
Мы храним данные о голосованиях в Redis. Это очень быстрое хранилище, идеально подходящее для подобного рода задач. Нам необходимо отсортировать документы, хранящиеся в Elasticsearch (выборка по запросу), по данным, которые хранятся в Redis (голоса пользователей, количество просмотров документа).
Решение FUNCTION_SCORE_QUERY
Начиная с версии 0.90.4, Elasticsearch предоставляет механизм Function Score Query (далее FSQ). Это довольно гибкое решение. В общем, FSQ разрешает «вручную» вычислять вес документа, используемый при сортировке выдачи.
Нам достаточно того, что FSQ позволяет:
- установить callback(java), на вход которого поступает очередной документ из выборки;
- присвоить переданному на вход документу вес(поле _score), равное результату вычисленному в callback-е.
Следует заметить, что для установки callback необходимо написать плагин Elasticsearch. Здесь я приведу упрощенный код плагина, по которому проще будет понять основную идею:
public class AbacusPlugin extends AbstractPlugin {
@Override
public String name() {
return "myScore.plugin";
}
@Override
public String description() {
return "My Score Plugin";
}
// called by Elasticsearch in a initialization phase(reflection magic)
public void onModule(ScriptModule module) {
module.registerScript(
"myScore", // NOTE: script name
MyScriptFactory.class
);
}
/*
* Script Factory should implement NativeScriptFactory
*/
public static class MyScriptFactory implements NativeScriptFactory {
// Some Score Calculation Service
private final MyScoreService service;
public MyScriptFactory() {
service = new MyScoreService();
}
@Override
public ExecutableScript newScript(
@Nullable Map<String, Object> params // script params
) {
return new AbstractDoubleSearchScript() {
/*
* called for every filtered document
*/
@Override
public double runAsDouble() {
// extract document ID
final String id = docFieldStrings("_uid").getValue();
// extract some other document`s field
final String field = docFieldStrings("someField").getValue();
// calc score by ID and some other field
return service.calcScore(id, field);
}
};
}
}
}
Что делает этот плагин?
- регистрирует скрипт сортировки в функции onModule;
- реализует фабрику скриптов в классе MyScriptFactory, который имплементит интерфейс NativeScriptFactory;
- создает сам класс сортировки, наследуясь от абстрактного класса: AbstractDoubleSearchScript;
- класс сортировки реализует функцию runAsDouble (предполагается, что возвращаемая вычисленная score будет double);
- функция runAsDouble вызывается для каждого документа, который попал в выборку запроса. Доступ к содержимому документа обеспечивает функция абстрактного класса AbstractDoubleSearchScript.docFieldStrings;
- в коде плагина вы также видите сервис MyScoreService(), который, собственно, и отвечает за присвоение новых score документам. Этот сервис и ходит в Redis за значениями количества голосов. В вашем случае это может быть любой другой сервис, который ходит куда угодно.
Схема, поясняющая решение:
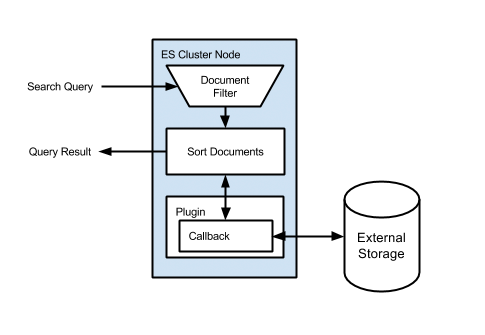
Как видно, сначала исполняется любой стандартный запрос ElastiSearch, затем для каждого документа исполняется скрипт Custom Score. Вот как выглядит запрос:
{
"function_score": {
"boost_mode": "replace", // to ignore score
"query": ..., // some query
"script_score": {
"lang": "native",
"script": "myScore" // script name
"params": { // script params(optional)
"param1": 3.14,
"param2": "foo"
},
},
}
}
Проблемы
Вроде бы, все довольно просто. Запрос пришел на одну из нод ES, ушел на шарды и другие ноды. Каждый шард посчитал и выполнил запрос, сбегал за дополнительными данными в Redis и вернул результаты ноде инициатору. Но есть подводные камни. Обратим внимание на «для каждого документа исполняется скрипт Custom Score». Что это значит? Например, ваш query в Elasticsearch нашел один миллион документов. После этого для каждого такого документа надо сходить в Redis и взять оттуда количество голосов. Даже если мы успеваем обернуться за 1ms, получается 16 минут. На самом деле, конечно, меньше, потому что запрос пошел параллельно с нескольких шардов, но все равно цифра будет внушительная.
Решение проблемы
Для каждого случая решение этой проблемы будет своим. Например, если речь идет о кастомной сортировке и выдаче для конкретного пользователя, то получив единожды всю мета-информацию о пользователе, для каждого следующего документа мы уже берем ее из памяти локально. Это будет работать очень быстро.
Но в нашем случае для каждого документа есть своя мета-информация (количество голосов). Здесь сработает подход, когда мы разносим горячие и холодные данные. Горячие данные хранятся в Redis, холодные сбрасываются в ES. Вот как это работает: по прошествии 3 суток в с момента публикации статья практически перестает получать голоса, и их можно сбросить в ES и переиндексировать документ со значением накопившихся голосов. А для свежих статей мы берем голоса из Redis.
При этом если старый документ все же получает новые голоса, они не теряются, а накапливаются в кеше и периодически все равно уходят на индексацию в ES. В этой схеме существует небольшой момент времени, когда старые документы сортируются с необновленными голосами, но нас это устраивает.
Также если вы смотрели код плагина для расчета score, то обратили внимание, что он синхронный, и выполняется по одному документу (нельзя сформировать batch запрос в redis). Однако есть довольно сложные техники, когда можно считать score батчами, и делать запрос в redis не на каждый документ, а формируя пакеты, например, по 1000 документов.
Выводы
Описанное решение, конечно, гораздо сложнее того, что можно получить одним запросом к MySQL. Однако мы используем Elasticsearch в качестве основного хранилища из-за необходимого функционала поиска и больших масштабов, и в таком случае подобные подходы оправданы и работают.
Посмотреть, как работает система, можно здесь:
https://play.google.com/store/apps/details?id=com.indxreader
Комментарии (16)

AlexanderYastrebov
19.05.2015 19:28Есть ощущение что задачу теоретически можно также решить через DocValues
shaierera.blogspot.com/2014/04/updatable-docvalues-under-hood.htmlAlexanderYastrebov
19.05.2015 19:39Гугление показало что в Solr кто-то решал
github.com/safarijv/ifpress-solr-plugin/blob/master/src/main/java/com/ifactory/press/db/solr/processor/UpdateDocValuesProcessor.java


SantyagoSeaman
20.05.2015 17:11+1У меня был похожий кейс на одном из проектов. Требовалось сохранить 10+ миллиардов туристических предложений. В качестве основного хранилища был выбран Solr. Почему именно он — вопрос второй. Суть в том, что помимо сохранения информации, нужно было вести историю изменения цен (редкие апдейты) и актуализировать наличие авиарейсов по каждому из миллиардов предложений в момент запроса для фильтрации и аналитики.
В итоге, апдейты цен с историей делались через самописанный модуль к Solr. Операция была тяжёлая из-за append-only архитектуры, но требования позволяли. Актуализация авиарейсов — это был крайне интересный хардкор. Рейсы хранились в кластере Redis. Информация по наличию мест и их количеству обновлялась практически в реалтайме. Чтобы это всё жило, я запилил несколько кастомных типов данных, которые использовались в схеме и просчитывались в реалтайме. При старте нод Solr делался прогрев внутреннего кеша инфой из Редиса. Памяти было много, можно было себе позволить.
Особый треш был в том, что всё это должно было работать на 100 шардах помноженных на коэффициент репликации. Плюс круглосуточный входной поток данных.

sergey_novikov
30.05.2015 10:56Однако есть довольно сложные техники, когда можно считать score батчами, и делать запрос в redis не на каждый документ, а формируя пакеты, например, по 1000 документов.
Какие?
shodan
Статья небезынтересная, но блин, вызывает мощнейший когнитивный диссонанс.
С одной стороны «хотите отсортировать выдачу по количеству просмотров документа», с другой «записывать каждый просмотр в Elasticsearch». Эээ, что?! Окей, быстрых обновлений атрибутивки нету, это тоскливо, когда её таки надо обновлять. Но сырые неагрегированные данные-то совать в поиск, которому нужны только подокументные агрегаты — ууух, по-моему, такое не должно возникать даже в формате заведомо нерабочей идеи :)
С одной стороны «десятки миллионов документов», с другой «большие масштабы» и как бы противопоставление реляционным СУБД. Эээ, что?! Извините, но уж 10M веб-документов отлично поместятся что в MySQL, что Postgres на 1 (одном) умеренно толстом сервере. Собственно, даже 100M при среднем размере 5K/документ можно полностью в 512 GB памяти запихать, и всё ещё на одном сервере. Да, конечно, встроенный поиск у них типично будет дрянной, но это другая история. Причем, полагаю, с простенькими выборкам по отдельным ключевикам должен более-менее справиться и он.
С одной стороны «очень быстрое хранилище Redis», с другой 1 ms на запрос, то есть типа 1K rps. Эээ, что?! Даже РСУБД, не говоря уже о специализированных KV хранилках типа memcached, давно пробили 100K rps с одного сервера, а в лабораторных условиях 1M rps. Вот, первый результат в гугле, 400K rps и это 5 лет назад: yoshinorimatsunobu.blogspot.ru/2010/10/using-mysql-as-nosql-story-for.html
В общем, или каких-то важных ключевых чисел про мега-масштабы в статье решительно не хватает, или они, числа, действительно не сходятся.
upd: поправил опечатки.
fl00r
связь между временем ожидания ответа (1ms) и количеством rps (посчитанная как 1к) работает не так, как вы думает
Cher Автор
поддерживаю. «100K rps с одного сервера» — redis стоит не на тех же машинах где и ElasticSearch. И плагин custom score работает по одному документу последовательно
fl00r
я имел ввиду, что если 1 клиент получает ответ на запрос через 1мс, это лишь значит, что в секунду этот клиент сможет сделать 1000 запросов, а эластик может одновременно обслуживать десятки таких клиентов. рпс эластика при этом будет значительно больше 1000.
shodan
Специально не стал раписывать подробнее слово «типа», ждал подобного комментария, и вот он прям сразу :)
Я отлично знаю, что latency может вообще никак быть не связана с bandwidth.
Однако во-первых, автор топика отчего-то использовал для своих расчетов именно эти самые 1 ms.
И во-вторых, что главнее, 1 ms латентности это тоже немало.
nsinreal
Судя по всему вам не хватает понимания, что elastic изначально был заточен под full text search и все с этим связанное. А любая реляционная бд этого либо не поддерживает, либо работает все через одно место.
Cher Автор
да, речь идет именно о этом. Чтобы делать описанные вещи надо чтобы поисковый функционал лежал в основе приложения, а не наоборот — притянули за уши ElasticSearch потому что модно
shodan
Реализации поиска в БД и их возможности это отдельный интересный разговор. Там сегодня не так все уже плохо, как ни странно. Но это совершенно нерелевантно. Выбор Эластика как первичного хранилища и вот эти вот вытекающие проблемы и решение — никто ведь не оспаривает (для этого в посте принципе недостаточно данных).
Меня удивляет другое: порядок 10М документов с намеками, что это как бы нечто неподъемное для РСУБД; отклик 1 msec, используемый для прикидок общего времени исполнения (?!!!); вот это все. Математика не сходится!
Cher Автор
не надо делать HabraHabr на ElasticSearch. Речь идет именно о задачах когда поиск лежит в основе функционала. Примеров когда врезаться в стандартную формулу подсчета _score множество. И все эти примеры делятся на 2 категории:
смотря какие задачи. Аггергационный фреймоврк позволяет например такой подход — писать буквально каждый пук в ES (просмотры, голосования, все отдельными записями), потом быстро считать суммы. Но опять же «быстро» будет относительно.
shodan
Ох. Речь вообще не про то, на чем что «надо» делать. Когнитивный диссонас вызывают математика и прилагательные!