

Известный всем тест Тьюринга говорит о том, что понять: мыслит машина или нет, можно по тому отличим ли мы ее в беседе от человека или нет. При этом подразумевается, что вестись будет не светская беседа, а, по сути, допрос с пристрастием в котором мы будем всячески пытаться загнать машину в тупик. Что мы при этом будем проверять? Только одно — понимает ли машина суть задаваемых нами вопросов. Пытается ли она, просто, формально манипулировать словами или она может правильно интерпретировать значения слов, используя при этом знания, полученные ранее в беседе, или, вообще, общеизвестные людям знания.
Пожалуй, во время теста не особо интересно спрашивать у машины: когда была Куликовская битва. Гораздо интереснее что она скажет, например, о том: зачем мы нажимаем сильнее на кнопки пульта, у которого садятся батарейки?
Различие человеческого мышления и большинства компьютерных алгоритмов связано с вопросом понимания смысла. Как правило, в компьютерную программу закладываются достаточно жесткие правила, которые определяют то, как программа воспринимает и интерпретирует входную информацию. С одной стороны, это ограничивает вольность общения с программой, но, с другой стороны, позволяет избежать ошибок, связанных с неправильной трактовкой нечетко сформулированных высказываний.
Глобально, проблема передачи смысла, неважно, от человека к человеку или от человека к компьютеру, или между компьютерами, выглядит так: чем четче и однозначнее мы хотим передать сообщение, тем более высокие требования накладываются на согласованность используемых терминов на передающей и принимающей стороне.
Если мы хотим, чтобы программа выполнялась одинаково на любом компьютере, мы создаем условия для однозначной интерпретации всех команд. Когда мы пишем математические формулы, их трактовка не зависит от желания собеседника. Занимаясь наукой, чтобы добиться взаимопонимания, мы используем, где только возможно, не слова обиходного языка, а четко определенные научные термины.
Порою, складывается ощущение, что четкий математико-алгоритмический подход – это более высокий уровень представления информации по сравнению с нечеткой семантикой естественного языка. Но при этом мы часто сталкиваемся с тем, что нам гораздо легче понять сложную мысль не тогда, когда она записана подробно и математически строго, а когда нам кратко и образно на естественном языке объяснят ее суть.
Далее я покажу, что кроется за нечеткими семантическими описаниями и в каком направлении, возможно, стоит двигаться компьютеру, чтобы пройти тест Тьюринга.
Криптография и смысл
Рассмотрим пример из области криптографии. Предположим, что у нас есть поток зашифрованных сообщений. Алгоритм шифрования строится на замене символов исходного сообщения другими символами того же алфавита по правилам, которые определяются шифрующим механизмом и ключом. С чем-то подобным имел дело Алан Тьюринг, взламывая код немецкой «Энигмы».

Предположим, что правила замены букв полностью определяются ключами. Допустим, что есть конечный набор ключей и для каждого ключа заданы правила замены, такие, что каждая буква имеет однозначное соответствие. Тогда, чтобы расшифровать какое-либо сообщение, необходимо перебрать все ключи, применить обратную перекодировку и попробовать понять, не встретится ли среди вариантов расшифровки какой-либо осмысленный.
Для определения осмысленности потребуется словарь со словами, которые могут встретится в раскодированном сообщении. Как только сообщение примет вид, в котором слова сообщения совпадут со словами из словаря, можно будет сказать, что мы нашли правильный ключ и получили расшифрованное сообщение.
Если мы захотим ускорить подбор ключа, то нам придется распараллелить процесс проверки. В идеале можно взять столько параллельных процессоров сколько может быть различных ключей. Распределить ключи по процессорам и выполнить на каждом процессоре раскодирование со своим ключом. Затем на каждом процессоре сделать проверку полученного результата на осмысленность. За один проход мы сможем проверить все возможные гипотезы относительно используемого кода и выяснить, какая из них наиболее подходит для расшифровки сообщения.
Для проверки осмысленности каждый из процессоров должен иметь доступ к словарю возможных в сообщении слов. Другой вариант – каждый из процессоров должен иметь свою копию словаря и обращаться к ней для осуществления проверки.
Теперь сделаем задачу интереснее. Предположим, что в начале нам известно всего несколько слов, которые составляют наш начальный словарь. При этом нам известны все ключи и правила перекодировки. Тогда в потоке сообщений мы сможем подобрать ключ только для тех сообщений, в которых будет хотя бы одно из известных нам слов.
Когда мы узнаем правильный код для немногих расшифрованных сообщений, мы получим правильное написание для других ранее неизвестных нам слов. Этими словами можно пополнить словарь того процессора, что нашел правильный ответ. Кроме того, новые слова можно передать всем остальным процессорам и пополнить и их локальные словари. По мере приобретения опыта мы будем расшифровывать все больший процент сообщений пока не получим полный словарь и близкую к ста процентам результативность расшифровки.
Возможны ситуации, когда сразу несколько ключей проявят в перекодированном сообщении слова, имеющиеся в словаре. В этом случае можно либо игнорировать такие сообщения, считая их нерасшифрованными, либо выбирать тот ключ, который дает большее количество совпадений слов из нашего словаря. Возможны и случайные появления осмысленных слов, тогда придется вводить для новых слов признак «предположительно» и менять его на признак «подтверждено», когда такое слово встретится в расшифрованных текстах неоднократно.
Получившаяся простая криптографическая система интересна тем, что позволяет ввести понятие «смысл», близкое по сути к тому, что мы обычно называем смыслом, и дать алгоритм, позволяющий с ним работать.
Результат раскодирования, полученный с неким ключом, можно назвать интерпретацией или трактовкой исходного кодированного текста в контексте этого ключа. Алгоритм определения криптографического смысла – это проверка всех возможных кодовых интерпретаций и выбор такой, которая выглядит наиболее правдоподобно с точки зрения памяти, которая хранит весь предыдущий опыт интерпретаций.
Смысл информации
Интерпретацию смысла и алгоритм его определения, введенные для криптографической задачи, можно расширить для более общего случая произвольных информационных сообщений, составленных из дискретных элементов.
Введем термин «понятие» – c (concept). Будем полагать, что всего нам доступно N понятий. Набор всех доступных понятий образует словарь
Будем называть информационным сообщением длины k набор понятий
Будем полагать, что сообщению может быть поставлена в соответствие его трактовка Iint (interpretation). Трактовка сообщения – это также информационное сообщение, состоящее из понятий множества C.
Введем правило получения трактовок. Будем полагать, что любая трактовка получается заменой каждого понятия исходного сообщения на некое другое понятие или на само себя. При этом первое понятие сообщения переходит в первое понятие трактовки и так далее.
Допустим, что в том, какие замены осуществляются при трактовке, есть определенная система, которая в общем случае нам неизвестна.
Введем понятие «субъект» S. Для субъекта определим его память, то есть персональный опыт как набор известной ему информации, получившей трактовку. Информация в купе с трактовкой может быть записана парой
Тогда память может быть записана как множество всех таких пар
Допустим, что есть учитель, который готов для каждого сообщения предоставить его правильную трактовку. Проведем стадию начального обучения, используя возможности учителя. Будем запоминать сообщения и трактовки данные учителем, как пары вида «сообщение – трактовка».
На основе памяти, сформированной с учителем, мы можем попытаться найти систему в сопоставлении понятий и их трактовок. Самое простое, что мы можем сделать — это для каждого понятия собрать все его возможные трактовки, что хранятся в памяти, и получить спектр возможных значений понятия. По частоте использования той или иной трактовки можно дать оценку вероятности соответствующего толкования.
Но чтобы, действительно, найти систему в сопоставлении нам необходимо каким-либо разумным методом решить задачу кластеризации и поделить объекты mi на классы по тому критерию, как происходит внутри класса трактовка одних и тех же понятий. Будем стараться сделать так, чтобы для всех объектов внутри одного класса действовали одни и те же правила трактовки входящих в них понятий. То есть, если для одного воспоминания, отнесенного к конкретному классу, некое понятие переходит в определенную трактовку, то в эту же трактовку оно будет переходить и во всех остальных воспоминаниях этого класса.
Обратите внимание, на особенность проводимой кластеризации. Расстояние между воспоминаниями вычисляется не по схожести исходных описаний или полученных трактовок, а по тому насколько похожие правила использовались при получении трактовки из исходного описания. То есть, объединяются в классы не воспоминания внешне похожие друг на друга, а воспоминания для которых оказались общими правила интерпретации, входящих в них понятий.
Будем называть классы, полученные в результате такой кластеризации, «контекстами» — Context.
Совокупность всех контекстов для субъекта S образует пространство контекстов
{Contexti| i=1...NContext}.
Для каждого i контекста можно задать набор правил трактовки понятий
Набор правил для контекста — это множество пар «исходное понятие — трактовка», описывающих все преобразования, свойственные контексту.
После завершения стадии первичного обучения можно ввести алгоритм, позволяющий трактовать новую информацию. Выделим из памяти M память Mint, состоящую исключительно из трактовок
Введем меру согласованности трактовки и памяти трактовок. В простейшем случае это может быть число совпадений трактовки и элементов памяти, то есть то, сколько раз именно такая трактовка встречается в памяти трактовок
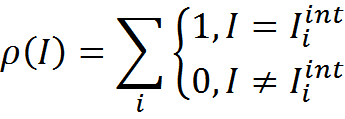
Теперь для любой новой информации I мы можем для каждого контекста Contextj получить трактовку Ijint, применив к исходной информации правила преобразования Rj. Далее для каждой получившейся трактовки можно определить ее согласованность с памятью трактовок
Схема вычислений для одного контекста показана на рисунке ниже.
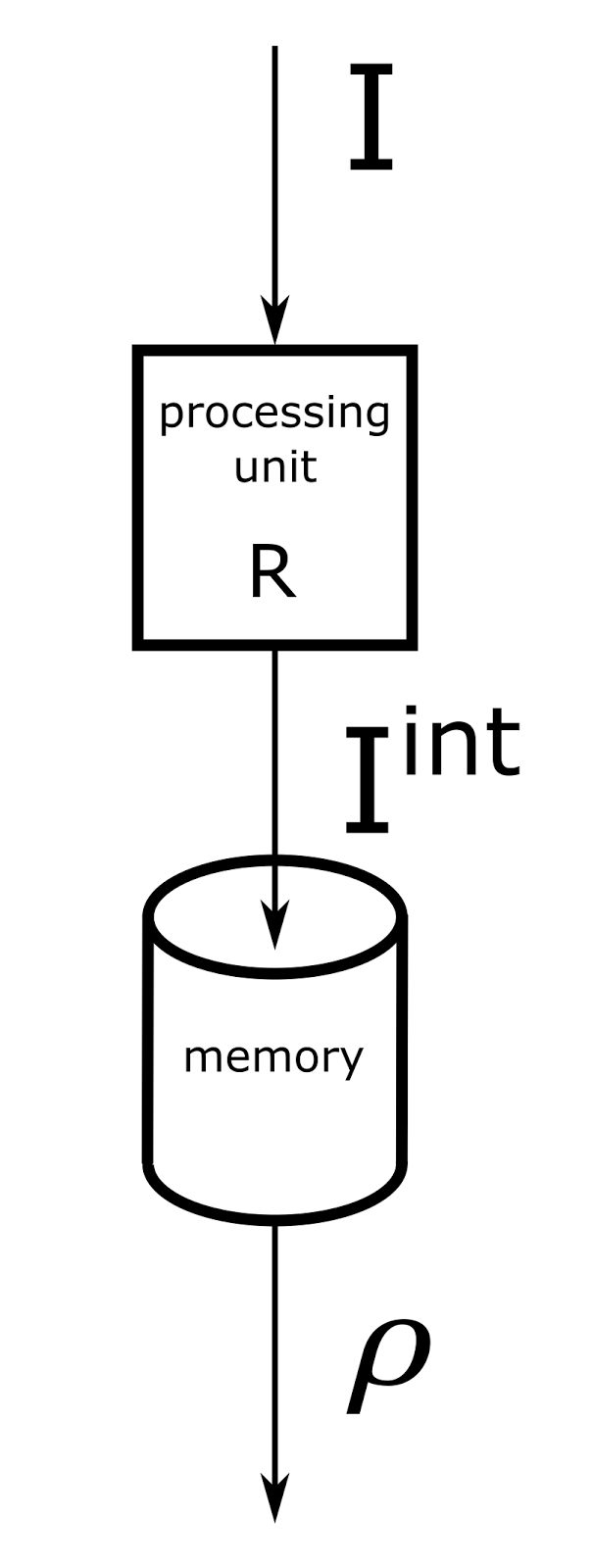
Вычислительная схема одного контекстного модуля
Введем вероятность трактовки информации в контексте j
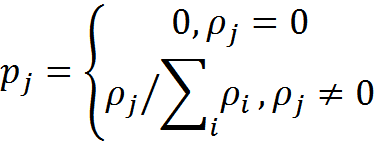
В результате мы получим трактовку информации I в каждом из K возможных контекстов и вероятность этой трактовки
Если все вероятности равны нулю, то мы констатируем, что информация субъектом не понята и не имеет для него смысла. Если же есть вероятности, отличные от нуля, то соответствующие им трактовки образуют множество возможных смыслов информации.
Если мы решим определиться с одной главной интерпретацией информации для данного субъекта, то можно воспользоваться контекстом с максимальным значением вероятности.
Как правило, информация содержит не один, а несколько смыслов. Дополнительные смыслы можно выделить, если взять отличные от главного контексты трактовки с ненулевой вероятностью. Но в этой процедуре есть свои подводные камни. При выборе надо учитывать возможную коррелированность контекстов. Позже мы рассмотрим это подробнее.
В итоге, понятие «смысл» можно описать следующим образом. Смыслом определенной информации для конкретного субъекта является набор трактовок, наиболее удачных в плане соответствия этих трактовок и памяти субъекта, полученных в результате анализа информации в различных контекстах, построенных, в свою очередь, на опыте этого субъекта.
Общая схема вычислений, связанных с определением смысла, может быть изображена как совокупность работающих параллельно контекстных вычислительных модулей (рисунок ниже). Каждый из модулей осуществляет трактовку исходного описания по своей системе правил преобразования. Память всех модулей одинакова по своему содержанию. Сравнение с памятью дает оценку соответствия трактовки и опыта. Исходя из вероятностей трактовок осуществляется выбор конкретного смысла. Процедура повторяется до тех пор пока не исчерпаются основные смысловые интерпретации информации.
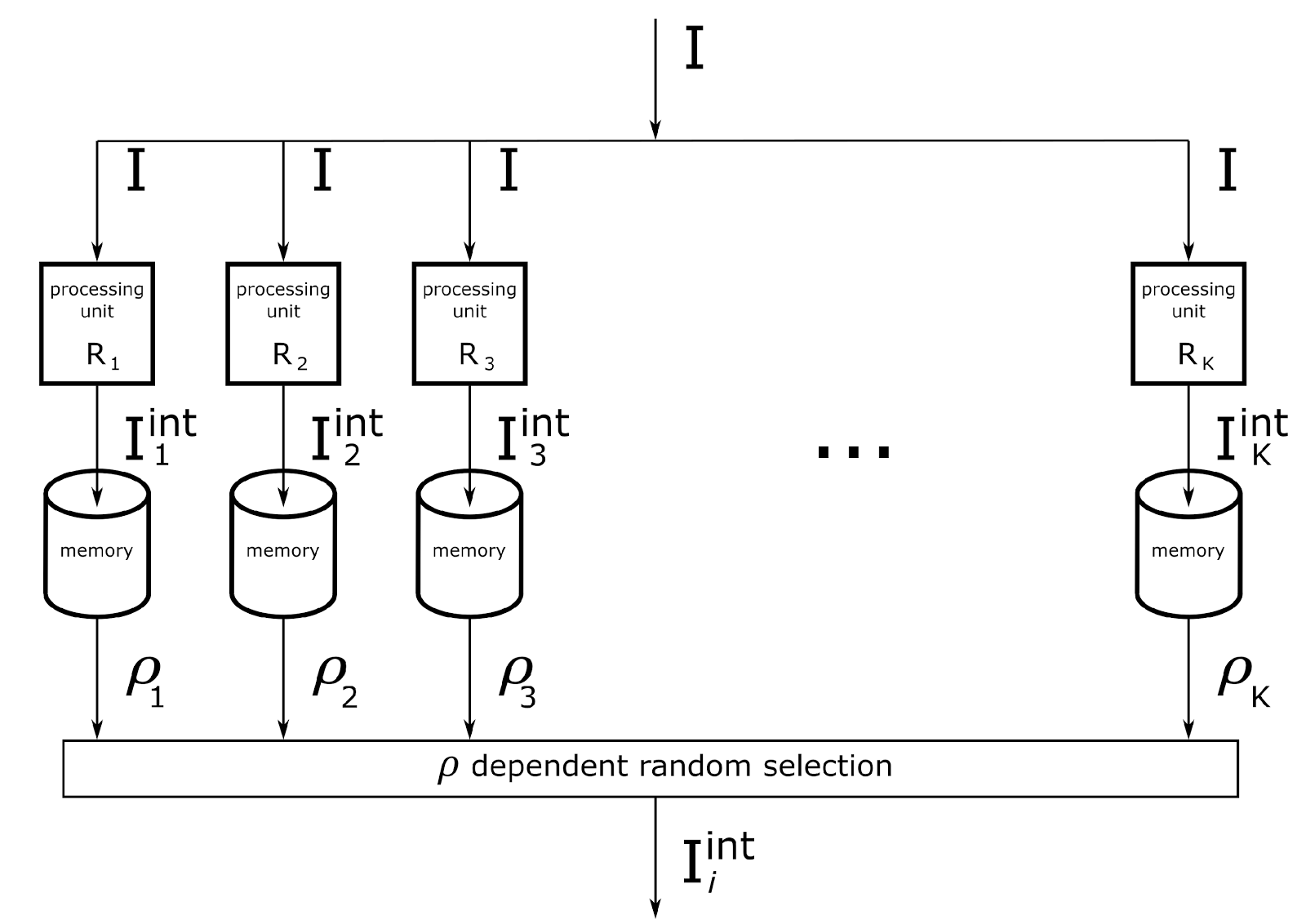
Вычислительная схема определения одного из смыслов в системе с K контекстами
После того, как определился смысл информации, можно дополнить память новым опытом. Этот новый опыт можно использовать для определения трактовки последующей информации и для уточнения пространства контекстов и правил преобразования. Таким образом можно не выделять отдельную стадию начального обучения, а просто накапливать опыт, улучшая при этом способность вычленения смысла.
Описанный подход, связывающий информацию и ее смысл, содержит несколько ключевых моментов:
- Информационные описания, к которым применим такой подход, строятся из дискретных (номинальных) понятий. Это определяется идеологией сопоставления понятий и их трактовок в определенном контексте.
- Опыт позволяет сформировать пространство контекстов и правила трактовки в этих контекстах. Соответственно, смысл может быть определен субъектом только при наличии определенного опыта.
- Поскольку опыт различных субъектов может быть различен, могут различаться и смыслы, полученные в результате восприятия одной и той же информации;
- Информация может быть специально подготовлена отправителем таким образом, чтобы максимизировать вероятность появления у получателя определенного смысла;
- Не стоит говорить о том, что информация содержит смысл независимо от воспринимающего субъекта. Смысл – это результат «измерения» информации, выполненный субъектом. До момента определения смысла, для конкретного субъекта информация содержит трактовки сразу во всех контекстах, для которых оказалась ненулевая вероятность этих трактовок. Каждое «измерение» позволяет увидеть один из возможных смыслов. Этот пункт, кстати, повторяет копенгагенскую трактовку состояния квантовой системы и момента измерения.
Проблема перебора
Описанный алгоритм определения смысла очень тесно связан с вопросом о равенстве классов P и NP, который так же известен как проблема перебора. Нестрого проблему перебора можно описать так: если есть вопрос и есть ответ на этот вопрос, и можно быстро проверить правильность этого ответа (за полиномиальное время), то можно ли так же быстро найти на этот вопрос правильный ответ (за полиномиальное время и используя полиномиальную память).
Например, допустим, что у нас есть таблица простых чисел, некое число и утверждение, что определенный набор простых чисел является разложением этого числа. Чтобы проверить это утверждение достаточно перемножить простые числа из предлагаемого набора и посмотреть, получится ли в результате наше число. Но если мы просто захотим найти разложение этого числа на простые множители, то столкнемся с необходимостью перебора всех простых сомножителей. С ростом разрядности исходного числа количество простых чисел, которые требуется перебрать, растет экспоненциально. Соответственно, решение, основанное на переборе, оказывается экспоненциально сложным по отношению к линейному росту сложности условия. Вопрос о равенстве классов P и NP — это вопрос о том, существует ли для этой и других сложных, основанных на переборе, задач алгоритмы, способные решать их за полиномиальное от сложности входных данных время и память. Если любую “сложную” задачу можно свести к “простой”, то классы равны.
На сегодня вопрос о равенстве классов открыт, но большинство математиков склоняется к тому, что эти классы все-таки не равны. Так как работа всех алгоритмов шифрования с открытым ключом основана на том, что есть нечто, что легко проверить, но трудно найти, то это значит, что по мнению большинства математиков криптография может быть надежной.
В нашем случае мы имеем набор понятий, описания составленные из этих понятий и некий опыт обучения, когда нам указываются правильные трактовки для некоторых описаний.
Исходя из данных обучения мы можем составить спектры возможных трактовок. То есть для каждого понятия посмотреть, какие трактовки оно принимало и предположить, что других трактовок для него не бывает.
Теперь можно попробовать дать трактовку какому-либо описанию. Предположим, что у нас есть огромный опыт и в используемой нами памяти есть все возможные корректные трактовки для любых описаний. Тогда можно составить из спектров трактовок, допустимых для понятий, входящих в описание, все возможные совместные комбинации и посмотреть, не окажется ли какая-нибудь из них похожа на содержимое памяти. Так как наша память огромна, то там обязательно найдется совпадение (если, конечно, исходная фраза корректна). Если оно будет единственным, то это и будет правильная трактовка исходного описания.
Количество комбинаций, которые потребуется перебрать, будет равно произведению размеров спектров всех понятий исходного описания. Например, для описания из 10 понятий при 10 возможных трактовках для каждого понятия мы получим 10 миллиардов вариантов. С ростом длины описания и количеством трактовок, имея экспоненциальный рост, мы получим так называемый комбинаторный взрыв.
Можно провести приблизительную аналогию с переводом с одного языка на другой. Имея образцы текстов и их переводов можно для каждого слова составить спектр его возможных переводов на другой язык. Условно правильным вариантом перевода (не будем брать в расчет ничего кроме перевода самих слов) будет одна из комбинаций, составленная из спектров возможных переводов отдельных слов. Для реального языка в большинстве случаев мы получим сотни миллионов, триллионы или более комбинаций. При этом потребуется база всех корректных предложений. Можете представить ее размер.
Контекстный подход позволяет значительно упростить вычисления за счет выделения закономерностей в системе трактовок. Если есть некие общие правила сопоставления понятий и их трактовок, то наблюдение за корректными примерами трактовки позволяет выделить эти правила. Области действия общих правил мы назвали контекстами. Для проверки гипотез о возможной трактовке входной информации теперь достаточно проверить только те интерпретации, что возникают в контекстах.
Количество необходимых контекстов определяется природой входной информации и той точностью понимания смысла, которую мы хотим получить. Для практических задач для получения хороших результатов почти всегда оказывается достаточно не более миллиона контекстов, при том, что общее число комбинаций может быть выше на много порядков.
Если продолжить пример с переводом, то контекстный подход говорит о том, что можно выделить фиксированное число смысловых контекстов, внутри которых перевод для многих слов окажется согласован между собой. Например, если удается определить, что текст носит научный характер, то из спектра возможных трактовок многих слов уйдут практически все варианты, кроме одного. Аналогично и с другими тематиками.
Определить то, какому контексту при переводе стоит отдать предпочтение, можно по тому, в каком контексте трактовка фразы выглядит правдоподобнее. В том числе исходя из того, насколько часто фразы с таким набором слов встречаются в этом контексте. В том, что описано, можно усмотреть много общего с теми методами, что используются в реальных системах перевода, что и неудивительно.
Фреймы
Описываемая контекстно-смысловая модель, во многом, решает те же задачи, что и концепция фреймов Марвина Минского («A Framework for Representing Knowledge», Marvin Minsky). Общие задачи, которые стоят перед моделями, неизбежно приводят к похожим реализациям. Описывая фреймы, Минский использует термин «микромиры», понимая под ним ситуации, в которых существует определенная согласованность описаний, правил и действий. Такие микромиры можно сопоставить с контекстами в нашем определении. Выбор наиболее удачного фрейма из памяти и его приспособление к реальной ситуации также может быть во многом сопоставлен с процедурой определения смысла.
При использовании фреймов для описания зрительных сцен, фреймы трактуются, как различные «точки зрения». При этом разные фреймы имеют общие терминали, что позволяет координировать информацию между фреймами. Это соответствует тому, как в разных контекстах правила трактовки могут привести разные исходные описания к одним и тем же описаниям-трактовкам.
Популярный в программировании объектно-ориентированный подход, непосредственно связанный с теорий фреймов, использует идею полиморфизма, когда один и тот же интерфейс при применении к объектам различных типов вызывает разные действия. Это достаточно близко к идее трактовки информации в соответствующем контексте.
При всей похожести подходов, связанной с необходимостью отвечать на одни и те же вопросы, контекстно-смысловой механизм существенно отличается от теории фреймов и, как будет видно дальше, не сводится к ней.
Особенность контекстно-смыслового подхода заключается в том, что он одинаково хорошо применим ко всем видам информации, с которыми сталкивается и оперирует мозг. Различные зоны коры реального мозга крайне похожи с точки зрения внутренней организации. Это заставляет думать, что все они используют один и тот же принцип обработки информации. Очень похоже, что на роль такого единого принципа может претендовать подход, связанный с выделением смысла. Попробуем на нескольких пимерах показать основыне идеи применения смыслового механизма.
Семантическая информация
Слова, из которых строятся фразы, могут быть по-разному истолкованы в зависимости от общего контекста повествования. Однако для каждого слова можно составить спектр значений, описанный в других словах. Если проследить за тем от чего зависит разная трактовки одних и тех же слов, то можно выделить тематические области трактовки. Внутри таких областей многие слова будут иметь однозначный определенный темой области смысл. Набор таких тематических областей и есть пространство контекстов. Контексты могут быть связаны с временем повествования, числом, родом, предметной областью, тематикой и так далее.
Похожая ситуация, связанная с выбором возможной трактовки для каждого из слов фразы, возникает при переводе с одного языка на другой. Возможные варианты перевода какого-либо слова наглядно показывают спектр возможных значений этого слова (рисунок ниже).
Пример спектра возможных трактовок, возникающих при переводе
Определение смысла фразы – это выбор такого контекста и получение таких трактовок слов, которые создают предложение наиболее правдоподобное, исходя из опыта того, кто этот смысл пытается понять.
Возможны ситуации, когда одна и та же фраза в разных контекстах создаст разные трактовки, но при этом эти трактовки будут допустимы, исходя из предыдущего опыта. Если стоит задача определить единственный смысл такой фразы, то можно выбрать ту трактовку, у которой выше совпадение с памятью и, соответственно, рассчитанная для нее вероятность. Если же фраза изначально составлена как двусмысленная, то уместно воспринять каждый из смыслов по отдельности и констатировать тот факт, что автору фразы вольно или невольно удалось их совместить в одном высказывании.
Естественный язык является мощным инструментом выражения и передачи смысла. Однако эта мощность достигается за счет нечеткости трактовок и их вероятностного характера, зависящего от опыта воспринимающего субъекта. В большинстве бытовых ситуаций этого вполне достаточно для краткой и достаточно точной передачи смысла.
Когда передаваемый смысл достаточно сложен, как это бывает достаточно часто, например, при обсуждении научных или юридических вопросов, имеет смысл переходить на использование специальных терминов. Переход на терминологию – это выбор собеседниками такого согласованного контекста, в котором слова-термины трактуются собеседниками одинаково и однозначно. Чтобы такой контекст оказался доступен обоим собеседникам, каждому из них необходим соответствующий опыт. Для одинакового понимания опыт должен быть схож, что достигается за счет соответствующего обучения.
Для естественного языка можно использовать меру согласованности контекста и памяти, основанную не только на полном совпадении описаний, но и на схожести описаний. Тогда становится доступно большее количество возможных смыслов и появляется возможность дополнительной трактовки фраз. Например, таким образом можно корректно трактовать фразы, содержащие ошибки или внутренние противоречия. Или сказанные образно, или в переносном смысле.
При определении смысла легко учитывать общий контекст повествования. Так, если фраза допускает толкования в разных контекстах, предпочтение стоит отдавать контекстам, которые были активны у предыдущих фраз и задавали общий контекст. Если же фраза допускает толкование только в контексте, отличном от основного повествования, то это стоит воспринимать, как переключение повествования на другую тему.
Аудиальная информация
Аналоговый звуковой сигнал легко преобразуется в дискретную форму. Для этого сначала выполняется дискретизация по времени, когда непрерывный сигнал заменяется замерами, выполненными с частотой дискретизации. Затем проделывается квантование амплитуды. При этом уровень сигнала заменяется на номер ближайшего уровня квантования.
Полученную запись сигнала можно разбить на временные интервалы и выполнить для каждого из них оконное преобразование Фурье. В результате получится запись звукового сигнала в виде последовательности спектральных замеров (рисунок ниже).
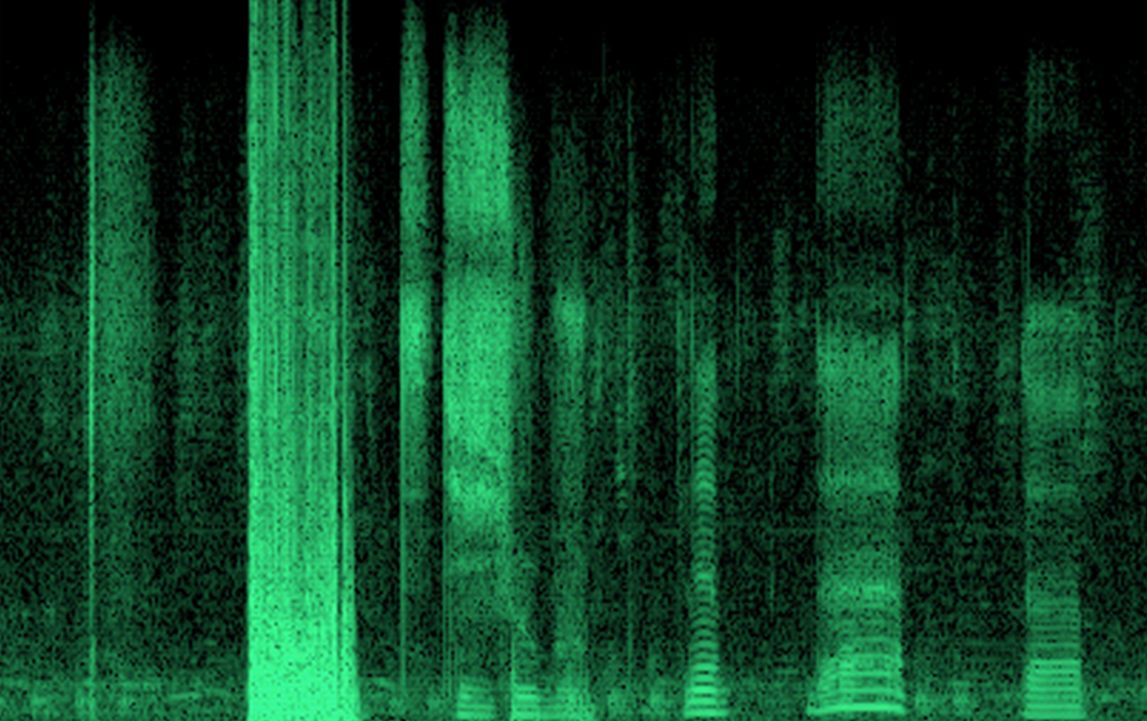
Пример временной развертки спектра речевого сигнала
Введем для временных интервалов кольцевой идентификатор с периодом NT. То есть занумеруем первые NT интервалов от 1 до NT. NT+1 интервал опять занумеруем 1 и так далее. В результате мы получим одинаковые номера через каждые NT интервалов.
Предположим, что преобразование Фурье содержало NF частотных интервалов. Это значит, что каждый спектральный замер будет содержать NF комплексных значений. Каждое комплексное значение заменим на его амплитуду и фазу и выполним их квантование. Амплитуду с NA уровнями квантования, фазу с NP уровнями.
Внутри диапазона из NT временных интервалов каждый элемент записи спектра можно описать сочетанием: код временного интервала, значение частоты, значение амплитуды, значение фазы. Ведем набор понятий C, позволяющий описать звук внутри интервала, заданного периодом кольцевого идентификатора. Это будут все возможные сочетания
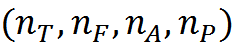
Всего таких понятий будет
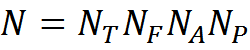
Соответственно, набор понятий C будет содержать N элементов
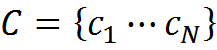
Любой звуковой сигнал продолжительностью не более NT временных интервалов можно записать как информацию через перечисление таких понятий.
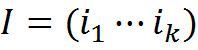 , где ij?C
, где ij?CС помощью этих же понятий можно записать и любую трактовку.
Если посмотреть на картинку с записью спектра речевого сигнала, то каждое из таких звуковых понятий — это точка с определенными координатами и яркостью. Есть еще фаза, но она на картинке не видна. Имея набор всех точек со всеми возможными цветами (амплитудами), мы, естественно, можем нарисовать любую картинку.
Задача распознавания звуковых образов требует узнавания одного и того же звукового образа при условии, что текущее звучание может быть трансформировано по отношению к тому, что хранится в памяти. Основные звуковые трансформации — это изменение громкости, изменение тональности звучания, изменение темпа звучания и сдвиг начала звучания.
Этим трансформациям соответствуют:
- Изменение амплитуды;
- Смещение по частоте;
- Линейное изменение временного масштаба;
- Сдвиг по временной шкале.
Введем пространство контекстов, покрывающее возможные сочетания трансформаций. Для каждого контекста можно создать правила переходов, то есть описать, как будет выглядеть каждое из исходных понятий в контексте соответствующего преобразования. Например, при контексте изменения частоты на одну позицию вверх все понятия получат трактовку, сдвигающую их на одну позицию вниз. Чистый тон на частоте 1 кГц – это то же, что и тон на частоте 900 Гц при контексте общего сдвига звучания вверх на 100 Гц. Аналогично с остальными видами трансформаций.
После описания правил переходов понятий в различных контекстах окажется возможным узнавать одни и те же звуковые образы независимо от их трансформаций. Момент произнесения, громкость, высота голоса и скорость речи не будут влиять на возможность сравнения текущей информации с той, что хранится в памяти. Текущее звучание будет преобразовано в различные трактовки во всех возможных контекстах. В том контексте, который соответствует искомой трансформации, описание примет трактовку, в которой можно легко узнать что-то уже слышанное ранее.
На практике при работе со сложными сигналами, например, с речью, оказывается невозможно обойтись одним этапом обработки. Сначала целесообразно ограничиться выделением простых фонем. Контексты при этом будут содержать правила трансформаций элементарных звуков, как описано выше. Затем составить описание, состоящее из фонем. При этом фонема будет достаточно сложным элементом, идентифицирующим не только звуковую форму, но и ее высоту, временное положение и скорость произнесения. Информация, составленная из фонем, в свою очередь, может быть подвергнута последующей обработке на новом пространстве контекстов.
Контексты можно усложнять, не ограничиваясь только простыми трансформациями. При этом само определение подходящего контекста создает дополнительную информацию. Например, для речи контекстами являются различные интонации и языковые акценты. Интонационные и акцентные контексты позволяют не только повысить точность распознавания, но и получить дополнительные знание о том, как именно сказана фраза.
Визуальная информация
Рассмотрим наиболее простые способы работы с изображением. Предположим, что у нас есть растровая картинка, состоящая из точек, для которых задан их цвет. Переведем изображение в черно-белое, оставив только значения яркости точек. Выполним выделение контура изображения (например, при помощи алгоритма Кэнни (JOHN CANNY, A Computational Approach to Edge Detection) (рисунок ниже)).


Результат выделения границы
Теперь разобьем изображение на небольшие квадратные области. В каждой небольшой области, через которую проходит линия границы, эта линия может быть аппроксимирована отрезком прямой. Зададимся числом квантования ориентации NO и определим соответствующие направления. Теперь для каждого квадрата, если он содержит границу, можно указать номер направления, наиболее точно соответствующего ориентации границы. Можно ввести и более сложные и, соответственно, более точные описания, но для примера нам подойдет и такая упрощенная модель.
Предположим, что размеры сетки, делящей изображение на области, NX на NY. Введем набор понятий C в который войдут понятия, соответствующие всем возможным сочетаниям
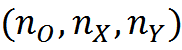
Таких понятий будет

Соответственно информационное описание изображения можно свести к перечислению соответствующих ему понятий
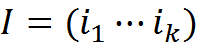 , где ij?C
, где ij?CТеперь нас будет интересовать задача инвариантного узнавания изображений. Зададимся набором трансформаций, по отношению к которым мы хотим добиться инвариантности. Наиболее распространенные на практики трансформации:
- горизонтальный сдвиг;
- вертикальный сдвиг;
- поворот;
- общее изменение масштаба;
- растяжение/сжатие по X;
- растяжение/сжатие по Y.
Эти преобразования наиболее интересны, так как соответствуют тому, как меняется проекция плоской фигуры при ее пространственных перемещениях и поворотах.
Теперь создадим пространство контекстов. Для этого осуществим квантование параметров трансформаций, то есть разобьем их на дискретные значения. И создадим столько контекстов, сколько возникнет возможных сочетаний этих параметров.
Для каждого контекста можно описать правила преобразования понятий. Так, вертикальная линия перейдет в горизонтальную при повороте на 90 градусов, вертикальная линия в позиции (0,0) станет вертикальной линией в позиции (10,0) при горизонтальном сдвиге на 10 позиций и так далее.
После задания правил трансформаций достаточно один раз увидеть и запомнить какой-либо образ, чтобы при предъявлении его в трансформированном виде определить и образ, и тип трансформации. Каждый контекст выполнит преобразование описания в трактовку, характерную для этого контекста, то есть совершит геометрическое преобразование описания, после чего сравнит с памятью на предмет поиска соответствия. Если такую проверку вести параллельно во всех контекстах, то за один такт можно найти смысл исходной информации. В данном случае это будет узнавание образа, если он нам был знаком, и определение его текущей трансформации.
Можно не ограничиваться описанными преобразованиями. Можно использовать, например, трансформацию «изгиба листа» и тому подобное. Но увеличение количества трансформации ведет к экспоненциальному росту количества контекстов. На практике задача обработки изображений описанным методом допускает очень сильные оптимизации, что позволяет производить расчеты в реальном времени. Основанные на таких идеях, но более продвинутые алгоритмы будут подробно описаны позже.
Основная идея описанного подхода заключается в том, что для получения инвариантного представления какого-либо объекта не обязательно проводить длительное обучение, показывая этот объект в различных ракурсах. Гораздо эффективнее научить систему правилам основных геометрических преобразований, свойственных этому миру и единых для всех объектов.
Частично описанный подход реализуется в хорошо себя зарекомендовавших сверточных сетях (Fukushima, 1980) (Y. LeCun and Y. Bengio, 1995). Для получения инвариантности к сдвигу в сверточных сетях ядро свертки, описывающее искомый образ, примеряется ко всем возможным позициям по горизонтали и вертикали. Такая процедура повторяется для всех знакомых сети образов с целью определения наиболее точного соответствия (рисунок ниже). По сути этот алгоритм декларирует «зашитое» в него априори знание о правилах трансформации при горизонтальном и вертикальном сдвиге. Используя эти знания, он формирует пространство возможных контекстов, реализуемое слоями простых искусственных нейронов. Определение максимального совпадения при свертке для различных ядер аналогично описанному нами определению смысла.

Рецептивные поля простых клеток, настроенных на поиск выбранного паттерна в разных позициях (Fukushima K., 2013)
Функция соответствия и условия выбора лучшего контекста
Функция соответствия трактовки и памяти служит для определения вероятности реализации контекста, соответствующего этой трактовке. По тому, как наш мозг выбирает смысл в реальных ситуациях, можно предположить, что алгоритмы определения соответствия могут быть достаточно сложны и не сводиться к одной простой формуле.
Ранее мы привели для примера «жесткую» функцию соответствия, основанную на точном совпадении описаний. Для памяти интерпретаций
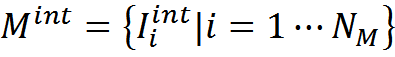
Функция соответствия
Введем меру сравнения описаний Q. Меру, основанную на точном совпадении можно записать
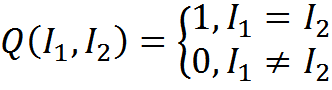
Функция соответствия примет вид

Соответствие, основанное на точном совпадении, позволяет определить смысл только в том случае, если хотя бы в одном контексте найдется интерпретация, уже хранящаяся в памяти. Но можно представить ситуацию, когда уместно найти наиболее подходящий контекст для трактовки описания, даже при отсутствии точных совпадений. В этом случае можно воспользоваться менее строгим сравнением описаний. Например, можно ввести меру схожести описаний, основанную на количестве общих для двух описаний понятий.
Ранее мы уже говорили о возможности кодирования описаний через сложение битовых массивов в фильтр Блума (Bloom, 1970). Сопоставим каждому понятию из словаря С его разряженный бинарный код длины m, содержащий k единиц.


Тогда каждому описанию I, состоящему из n понятий, можно сопоставить бинарный массив B, полученный от логического сложения кодов понятий, входящих в описание.

О похожести двух описаний можно судить по схожести их бинарных представлений. В нашем случае уместной выглядит мера сходства, основанная на их скалярном произведении.
Скалярное произведение двух бинарных массивов показывает сколько единиц совпало в этих двух массивах. Всегда есть вероятность того, что единицы в бинарных описаниях совпадут случайно. Ожидание количества случайно совпавших единиц M зависит от длины бинарного кода, количества единиц, кодирующих одно понятие, и количества понятий в описаниях. Чтобы избавиться от случайной составляющей, меру сходства можно скорректировать на величину случайного ожидания.

Такая мера может принимать отрицательные значения, которые сами по себе не имеют смысла. Но при сложении мер близости для всех элементов памяти они позволят компенсировать случайные положительные выбросы. Тогда функцию соответствия можно записать
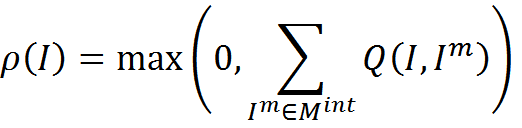
При «мягком» задании функции соответствия наша модель уходит в сторону статистической оценки вероятностей того или иного контекста и может быть сопоставлена с Байесовскими методами, скрытыми Марковскими моделями и методами нечеткой логики.
«Жесткий» и «мягкий» подходы имеют, как свои плюсы, так и свои минусы. Мягкий подход позволяет получить результат для информации, которая не имеет четкого аналога в памяти. Это может быть в случаях, когда само описание содержит неточности или ошибки. В таких случаях, определив предпочтительный контекст, можно в качестве трактовки использовать наиболее похожее корректное воспоминание.
Кроме того, мягкое сравнение дает результат, когда описания, хранящиеся в памяти, содержат несущественные для смысла подробности, которые можно считать информационным шумом. Однако жесткий подход может давать принципиально более качественный результат. В большинстве случаев попадание в редкую, но адекватную для описания трактовку, значительно предпочтительнее шаблонных трактовок, основанных на «внешнем» сходстве.
Еще один, пожалуй, самый интересный подход возможен, если в наборе всех описаний предварительно выделить факторы, отвечающие за некие сущности, общие для части описаний. Тогда можно строить функцию соответствия, как мягкое или жесткое сравнение с портретами факторов. Такой подход хорош тем, что позволяет однозначно или с определенной вероятностью определять присутствие факторов на фоне зашумленной другими описаниями информации.
Разумным видится комбинированный подход, использующий все виды оценок соответствия. Самое главное, что определение смысла не является замкнутой в себе операцией. Правильное определение смысла служит основой для последующих информационных операций, связанных с мышлением и поведением субъекта. Как будет показано дальше, алгоритмы поведения и мышления определяется механизмами обучения с подкреплением, которые позволяют сформировать наиболее адекватные к ситуации мыслительные ходы и поведенческие акты. Можно предположить, что и с определением смысла наилучшим результатом будет не некая жестко заданная стратегия расчета функции соответствия, а расчет на основе обучения с подкреплением, который будет оптимизировать функцию расчета, исходя из успешности опыта предыдущих оценок.
В следующей части я покажу, как, возможно, работает со смыслом реальный мозг и расскажу, как с помощью паттерно-волновая модели, голографической памяти и понимания роли миниколонок кортекса можно попробовать обосновать, как выглядит пространство контекстов, реализованное на биологических нейронах.
Алексей Редозубов
Логика сознания. Вступление
Логика сознания. Часть 1. Волны в клеточном автомате
Логика сознания. Часть 2. Дендритные волны
Логика сознания. Часть 3. Голографическая память в клеточном автомате
Логика сознания. Часть 4. Секрет памяти мозга
Логика сознания. Часть 5. Смысловой подход к анализу информации
Комментарии (82)

AlexeyR
11.09.2016 16:03Согласен. Исправил на такое:
«Если проследить за тем от чего зависит разная трактовки одних и тех же слов, то можно выделить тематические области трактовки. Внутри таких областей многие слова будут иметь однозначный определенный темой области смысл. Набор таких тематических областей и есть пространство контекстов».
Возможно, будет понятнее.
george3
11.09.2016 16:20«Набор таких тематических областей и есть пространство контекстов». Я вижу нарушение причины и следствия. Контекст — это то, что вне слова-понятия, а не внутри.А смысл, как возможная трактовка, вовсе не обязательно связан с внешним контекстом. Он может его расширять (т е быть параллельным или перпендикулярным), противоречить ему (юмор), или вообще вводить новый. Попробуйте написать программу, и сразу все станет ясно. " Теперь для каждого квадрата, если он содержит границу, можно указать номер направления, наиболее точно соответствующего ориентации границы. «и прочая отпадут сами собой.
AlexeyR
11.09.2016 16:45В той модели, что описывается смысл не существует сам по себе. Он возникает только как трактовка в одном из контекстов.
Да, все запрограммировано и работает. Возможно, когда буду описывать конкретные реализации станет понятнее.

mphys
11.09.2016 16:30+1Гораздо интереснее что она скажет, например, о том: зачем мы нажимаем сильнее на кнопки пульта, у которого садятся батарейки?
По моему плохой пример, ответ на этот вопрос формируется из опыта, а не из «возможности мыслить как человек». Если спросить об этом у человека, который никогда не пользовался пультом, либо у него за всю жизнь не бывало ситуации когда садились батарейки или сигнал с кнопки проходит не сразу, скорее всего он тоже не ответит.AlexeyR
11.09.2016 16:38+1Вопрос понимания смысла и есть вопрос правильного применения предыдущего опыта в ситуациях напрямую непохожих на сам опыт. Возможность опыт, полученный в одном контексте, использовать в другом контексте и есть суть описываемой модели. При этом текущее описание может никак не походить на старый опыт, которым мы хотим воспользоваться. Но после преобразования старого опыта в его смысловую трактовку и нахождения соответвующей трактовки нового опыта может оказаться, что у них есть общий смысл, который после всех этих преобразований для старого опыта и нового события выглядит одинаково.

AlekseiMorozov19730316Ru
11.09.2016 17:09>как с помощью паттерно-волновая модели,
>голографической памяти и понимания роли миниколонок кортекса
>можно попробовать обосновать,
>как выглядит пространство контекстов,
>реализованное на биологических нейронах
Дикорастущее дерево гипотез всё-таки должно давать хоть какие-то плоды. Пока их не видно. И съедобны ли они вообще.AlexeyR
11.09.2016 17:19+2Эйнштейн говорил: «Всё следует упрощать до тех пор, пока это возможно, но не более того». Мне кажется, что мозг не сводится к совсем уж простым правилам.
Определенная сложность модели заставляет меня объяснять ее последовательно, шаг за шагом. Если у вас не вырисовывается общей картины или непонятны отдельные части, то это, возможно, моя вина как рассказчика. Но, поверьте, я стараюсь как могу. Но не требуйте показать работающие программы до того момента пока я не буду в состоянии объяснить, как они работают. Наберитесь терпения, всему свое время.AlekseiMorozov19730316Ru
11.09.2016 17:36-1>… мозг не сводится к совсем уж простым правилам.
Но к «простым правилам» должен сводиться нейрон.
>… Определенная сложность модели…
Сама модель не сложна. Переусложнён «животворящий» «элемент автомата».
AlexeyR
11.09.2016 20:34+1Кому нейрон должен? Чтобы судить переусложнен нейрон или нет надо знать «правильный ответ», вы знаете?
AlekseiMorozov19730316Ru
11.09.2016 21:08-2Уже да. Думаю, что «Эфирный Поток Сознания» («Aether Stream of Consciousness») был самым крупным недостающим фрагментом пазла понимания работы мозга. Всё — в рамках классики. Модель — memoryless. Чудеса — отсутствуют.
shabanovd
12.09.2016 09:56Что можно почитать?
AlekseiMorozov19730316Ru
12.09.2016 11:10Ассоциативная Широковещательная Нейронная сеть (АШНС)
Associative Broadcast Neural Network (ABNN)
Ассоциативная Широковещательная Нейронная сеть (АШНС) — это искусственная нейронная сеть, которая использует широковещательное распространение выходных паттернов нейронов для обеспечения направленных ассоциативных связей между её нейронами. АШНС передаёт выходной паттерн активного нейрона одновременно на входы всех нейронов сети через мгновенную связь. Идея АШНС вдохновлена гипотезой о широковещательном распространении кода выходного паттерна активного нейрона в биологической нейронной сети посредством электрического сигнала в проводящей среде вокруг нейронов.
Ассоциативная Широковещательная Нейронная сеть (АШНС) — это подкласс рекуррентной нейронной сети (recurrent neural network (RNN)), основанный на мгновенном широковещательном распространении выходного паттерна активного нейрона. АШНС — нейронная сеть без памяти. После завершения обучения вся информация о входных образах сохранена в значениях коэффициентов связей между нейронами, и входные данные больше не нужны, то есть в системе отсутствует явное хранение любых представленных ей примеров. Ассоциативные связи между нейронами могут формировать направленный цикл.

Volutar
12.09.2016 13:29Я полагаю, это что-то сугубо из творчества самогo Алексея Морозова. По крайней мере, гугленье данной темы привело только в «БольшойФорум», где просто совсем какая-то полуэзотерическая тема.
При всём уважении, автору не стоит отвлекаться на подобные комментарии.
Кстати, в той теме был задет интересный момент насчёт «Закона Рибо», когда инволюция памяти происходит в обратном порядке, от свежих воспоминаний до глубоких детских воспоминаний и привычек. И правда создаётся впечатление, что дендритные деревья, вырастая, добавляют свежую и более детальную информацию на «кончиках». В этом смысле сами ветвления дендритных структур представляются как постоянно идущее уточнение вариантов полей значений/смыслов.AlexeyR
12.09.2016 13:31Я покажу основную биологию контекстов в следующей части. Несколько позже покажу алгоритмы пространственной организации, и тогда многое встанет на место.
AlekseiMorozov19730316Ru
12.09.2016 16:32>… это что-то сугубо из творчества самогo Алексея Морозова…
:) Однако меня уже обвиняют в плагиате.AlekseiMorozov19730316Ru
12.09.2016 18:33>… плагиат…
:) Пожалуй, расскажу развёрнуто, что и как «с паттернами». Алексей Редозубов уже несколько лет публикует научно-популярные статьи на темы о мозге. У него есть две или три книги на эти темы и даже научная статья от 2014 года под названием «Pattern-wave model of brain function. Mechanisms of information processing.» Году в 2012 после просмотра его восьмичасового видео на тему «Логика эмоций и мышления» мной впервые была выражена критика о том, что всё это — пустое, и что нужно заниматься тем, чем все занимаются — паттернами, а не логикой эмоций. Так или иначе, но его «Pattern-wave model» от 2014 года — это был шаг в верном направлении. Но, к сожалению, сделав это шаг, Алексей свернул не туда, куда нужно. В мозг зачем-то полезла голография. На данный момент, после, можно сказать, титанических усилий Алексей Редозубов вышел на публику с релизом его идеи: «Логика сознания. Волны в клеточном автомате. Дендритные волны. Голографическая память в клеточном автомате». Читая всю эту «логику» и пытаясь разобраться, что, зачем и почему, у меня в период с 31 августа 2016 года по 4 сентября 2016 года созрела альтернативная гипотеза, которую я и назвал «Широковещательное распространение паттернов нейронов мозга», и которая имеет совсем другие свойства, чем клеточный автомат. С чем Алексей Редозубов, в принципе, согласен. Гипотезе «широковещательного распространения паттернов нейронов мозга» нет и двух недель. Однако обвинять меня в плагиате, думаю, неуместно.
Морозов Алексей Александрович
Нижний Новгород
12 сентября 2016 годаAlexeyR
12.09.2016 18:45Вы как-то излишне агрессивно пытаетесь пиарить ваше абсолютное знание. Это несовсем уместно в этих комментариях. Напишите статью о ваших идеях и выразите себя. Удачи вам и интересного обсуждения ваших идей.
AlekseiMorozov19730316Ru
12.09.2016 19:20>… интересного обсуждения ваших идей…
:) Непременно. Спасибо.
Volutar
13.09.2016 07:04Не знаю, откуда Вы увидели обвинение в плагиате, я лишь отметил что упомянутый Вами «Эфирный Поток Сознания» («Aether Stream of Consciousness») — сугубо Ваша (@AlekseiMorozov19730316Ru) придумка, и ссылаться до более глубоких источников, в сущности, некуда.
AlekseiMorozov19730316Ru
13.09.2016 08:55:) Поясню для пользы дела. Феномен, который я назвал «Эфирный Поток Сознания» («Aether Stream of Consciousness») — это реальное трехмерное распространение кодов выходных паттернов активных нейронов в проводящей среде вокруг нейронов посредством электрических колебаний. Отмечу, что речь вовсе не о паттерне группы активных нейронов (у Алексея Редозубова, в его автомате есть паттерн группы активных элементов автомата), а о сумме электрических колебаний от кодов нескольких выходных паттернов (по одному выходному паттерну на каждый активный нейрон). Именно в этом причина гибкой мультиассоциативности нейронов в реальной биологической нейронной сети. Само название, разумеется, для красоты и популяризации гипотезы широковещательного распространения (выходных) паттернов нейронов мозга.
«One more thing...» Всегда скептически относился к приватизации идей и, тем более, направлений в исследованиях. Нет никакого смысла тормозить прогресс ради собственной выгоды, регалий и тому подобного. Поэтому и стараюсь «отправить в свободное плавание» появившуюся у меня идею.shabanovd
13.09.2016 09:44«о сумме электрических колебаний от кодов нескольких выходных паттернов»… т.е. электромагнитная волна, я правильно понял? Есть ли у нее гармоники?
AlekseiMorozov19730316Ru
13.09.2016 10:50>… электромагнитная волна, я правильно понял?
Нейроны находятся, по сути, внутри проводящей среды, то есть они как бы «опутаны» проводами. Скорее всего, пока уместнее всего говорить о колебаниях электрического тока. Если ЭМВ, то надо вводить в модель ещё и сущность «антенны». Это — пока лишнее.shabanovd
13.09.2016 10:58Значит, активность паттерна кодируется фазовыми характеристиками тока?
AlekseiMorozov19730316Ru
13.09.2016 11:28Всё «хуже» гораздо. Направленные трёхмерный «приёмник» и трёхмерный «передатчик» нейрона могут принимать трёхмерный электрический сигнал и посылать его. Распространяющиеся сигналы, разумеется, накладываются. В итоге эта каша образует «Эфирный Поток Сознания». Разобраться с этим сможет только кроссдисциплинарный проект. Для начала нужна примитивная модель с некими абстрактными «паттернами». Кроме обычного «кабельного» веса «кабельной» связи, необходимо добавить «эфирный» вес этой же «кабельной» связи. Вот и всё. Получаем этот самый «эфирный» паттерн — совокупность «эфирных» весов обычной «кабельной» связи. Далее — обучаем полученную таким образом Ассоциативную Широковещательную Нейронную сеть (АШНС), то есть
Associative Broadcast Neural Network (ABNN). АШНС(ABNN) ждёт своих «героев».Volutar
13.09.2016 12:21А есть хоть какие-то веские основания считать, что импульсы передаются электрическими сигналами помимо классической электростатической ионной деполяризации через мембрану?
Просто совершенно не ясно про какие провода/эфир вообще речь. Создаётся впечатление, что речь о какой-то эзотерике.AlekseiMorozov19730316Ru
13.09.2016 12:26>импульсы передаются
>электрическими сигналами
Вокруг нейронов находятся заряженные частицы. Это образует трёхмерную проводящую структуру. Куда деваться импульсам — естественно, они по ней распространяются.shabanovd
13.09.2016 12:32Куда деваться импульсам — естественно, они по ней распространяются
А это уже «распространения волны в среде» (причем в жутко неоднородной), Вы как-то определитесь, за белых или за красных -)AlekseiMorozov19730316Ru
13.09.2016 12:50Никто и не говорит, что гипотеза широковещательного распространения паттернов нейронов мозга — «не глубокая». Но это не «волны дендритов в клеточном автомате» Алексея Редозубова, если Вы на это намекаете. Вы же это, надеюсь, понимаете.

napa3um
13.09.2016 13:41Вы тоже открыли автоволны. Они бывают и трёхмерные, и восьмимерные, и перемещающиеся в виде зарядов, в виде концентрации нейромедиаторов, в виде подрыгиваний дендритов — т.е., просто в виде локальных событий активных однородных элементов, составляющих среду (причём, в одной кибернетической системе возможно рассмотрение нескольких автоволновых систем одновременно, на каждом уровне выделяя различные свойства среды — свойства дендритов, нейронов, кортикальных колонок, альянсов колонок и так вплоть до социальных и экономических агентов и групп агентов). Для моделирования интеллектуальных функций людей in silico не так важно, как работает конкретный биологический мозг, можно абстрагироваться от самой физики/биологии процесса, взяв только ключевые параметры типа скорости реакции элемента среды и его «ёмкость», имеющие смысл «на границах» рассматриваемого объекта (для мозга, к примеру, граничными могут быть свойства сигналов с моторных и сенсорных нейронов или обобщённые бихевиористские события типа «подопытный нажал красную кнопку»). Тот же самый перцептрон — это не просто инженерный поиск «методом тыка» с мотивом «сделать как в бионейроне, вдруг, начнёт проявлять какие-то необычные свойства», а математическая целесообразная абстракция о том, что важно и не важно для предсказания поведения обобщённого класса систем, называемых динамическими, нелинейными и открытыми в рамках решения конкретной задачи классификации сигналов, т.е., это математическое решение, проистекающее из одного из вариантов _формализации_задачи,_решаемой_реальным_мозгом. Спайковая нейросеть в самом своём обобщённом принципе — это и есть _исчерпывающая_ абстрактная модель мозга в условиях самой абстрактной постановки задачи — «описать мозг в терминах кибернетической системы», с точки зрения кибернетики чего-то ещё в мозгу нет и быть не может, все подробности являются лишь способом «реализации» в природе этой «предельной» кибернетической модели. Искать, какими пестиками и тычинками реализовывается функция мультиплексирования, к примеру, или ассоциирования сигналов, если мы саму эту функцию уже и так сформулировали, особого смысла нет — всё равно самые «предельные» виды биологической реализации этих функций не будут магическим образом выдавать новые математические принципы, любая «магия» для исследователя будет шумом из сигналов о том, о чём он и не пытался узнать из модели. В теме построения ИИ острее стоят задачи не об устройстве нейросети, а об организации процесса обучения, который и накладывает архитектурные ограничения на эту нейросеть. Проблема не в том, как соединить нейроны, а в том, как соединить эту кучку нейронов с реальностью, с полезными задачами и источниками неформализованных знаний (в пределе — как подключить ИИ к человеческой культуре, в которой у него сформируется то самое сознание с квалиями, о которых тут рассуждают так, будто это не культурные, лингвистические конструкты, а объективные элементы кибернетических систем). (Это, возможно, не персональный ответ именно вам, а вообще «мысли вслух» по поводу сложившейся в комментариях дискуссии.)
Volutar
13.09.2016 13:07Эти заряженные частицы — это ионы. Насколько я понимаю, они никакими _особыми_ проводящими свойствами по сравнению с другими молекулами (включая молекулы воды) не обладают. Это же обычный электролит. И любая проводящая структура в нашем мире трёхмерна. А импульс (спайк) — это следствие электростатического перемещения отдельных молекул-ионов, а не электронов, как в проводнике.
AlekseiMorozov19730316Ru
13.09.2016 18:00>… Эти заряженные частицы — это ионы.…
В мозге много всякой всячины. Кровь, например. Какая структура цепей работает при широковещательном распространении паттернов нейронов мозга — проще проверить, чем «вывести».
shabanovd
13.09.2016 12:23Разобраться с этим сможет только кроссдисциплинарный проект. Для начала нужна примитивная модель с некими абстрактными «паттернами».
Я правильно понял, что Вы еще с этим не разобрались? Т.е. Вы не знаете, как именно это работает.
Направленные трёхмерный
На ум приходит только фазированная антенная решётка, но и она не дает свойств, которые Вы описываете. Если нельзя подобрать некое «решения» которое уже реализовано, то либо это абстрактные фантазии не привязанные к физике нашего мира, либо Вы придумали прям революционное устройство и нужно держать все в тайне и патентовать как можно скорей.AlekseiMorozov19730316Ru
13.09.2016 12:31>Я правильно понял,
>что Вы еще с этим не разобрались?
>Т.е. Вы не знаете, как именно это работает.
:) Нет. Увы. Вы поняли неправильно.
>фазированная антенная решётка
наподобии, но только для электрического тока и обязательно «трёхмерная», а не «плоская».shabanovd
13.09.2016 12:34наподобии, но только для электрического тока и обязательно «трёхмерная», а не «плоская»
срочно патентовать!AlekseiMorozov19730316Ru
13.09.2016 12:36Вы мыслите «прошлым». В будущем — там же ИИ, и патенты — уже мусор.
vadimr
11.09.2016 21:04Это всё разумно, только тест Тьюринга на самом деле не имеет отношения к мышлению, и лучшие программы на сегодня его проходят. Тест Тьюринга показывает только возможность имитировать человеческую письменную речь.
Формально, тест Тьюринга опровергается мысленным экспериментом по построению таблицы человеческих ответов на все возможные комбинации входных символов в пределах заданной максимальной длины диалога. Программа, находящая входной текст в левом столбике и печатающая в ответ на него текст из правого столбика, пройдёт ТТ.AlexeyR
11.09.2016 21:49+2Тест Тьюринга не опровергается парадоксом китайской комнаты. Серл — философ. Он не учел того, что все ответы предусмотреть невозможно. Китайская комната не способна вести мало мальски длинную бесседу. Слишком быстро происходит комбинаторный взрыв.
Программ, способных пройти тест Тьюринга пока нет. Тот смысл, который вклажывал в этот тест сам Тьюринг был как раз в том, как отличить интеллект от попытки обмануть за счет манипуляции словами.vadimr
11.09.2016 22:22Парадокс китайской комнаты несколько глубже, он больше относится к проблеме философского зомби, чем к тесту Тьюринга. Я же здесь говорю только о том, что, рассматривая человека, как преобразователь входной цепочки символов в выходную, можно реализовать такое преобразование самыми разными путями, необязательно через анализ их смысла. Поэтому успешное прохождение теста Тьюринга само по себе никак не может убедить современного программиста в наличии разума с той стороны.
Собственно, и средний человек больше имитирует обработку смысла, чем в действительности производит её. В предельном случае, Вы мне говорите: “Добрый вечер!”, я Вам отвечаю: “Добрый вечер!”. Смысла ноль, чистое подражание обучающим примерам диалогов (на чём, кстати, построено преподавание иностранного языка в ряде методик).
Утверждение же о комбинаторном взрыве – это вообще не аргумент в принципиальном вопросе. На практике, разумеется, нет необходимости учитывать все комбинации бессмысленных символов, и можно сильно соптимизировать словарь, чем, собственно, и занимаются современные боты.
Тьюринг, при всём к нему уважении, всё-таки не мог предусмотреть развития науки и практики программирования и философии сознания за последующие 60 лет. Поэтому для своего времени его тест был выдающимся результатом, но на сегодня он, скорее, уводит в сторону.
Насколько мне известно, программа Веселова и Демченко официально прошла тест Тьюринга.AlexeyR
11.09.2016 22:54+2Насчет «официально прошла» это очень мягко говоря сильное преувеличение. Как вы првильно заметили, ответить на “Добрый вечер!” фразой “Добрый вечер!” не требует особого интеллекта. Тест Тьюринга нисколько не устарел. Стоит просто вкладывать в него правильный смысл. Программа должна не продержаться 3 минуты, обтекаемо уходя от ответов, а доказать в допросе с пристрастием свою состоятельность.
Насчет оптимизации весь вопрос в том как ее сделать. Чему собственно и посвящена эта часть.AlekseiMorozov19730316Ru
12.09.2016 06:50-3>… Насчет оптимизации…
Очередная ошибка в том, что Вы пытаетесь «впихнуть» выявленные закономерности сущностей высокого уровня в «чудесную» низкоуровневую модель, да ещё и «привязать» эту модель к реальной биологической нейронной сети.

buriy
12.09.2016 21:32Цитирую википедию: «Представим себе изолированную комнату, в которой находится Джон Сёрл, который не знает ни одного китайского иероглифа. Однако у него есть записанные в книге точные инструкции по манипуляции иероглифами вида «Возьмите такой-то иероглиф из корзинки номер один и поместите его рядом с таким-то иероглифом из корзинки номер два», но в этих инструкциях отсутствует информация о значении этих иероглифов и Сёрл просто следует этим инструкциям подобно компьютеру.» А вот английская википедия: " It takes Chinese characters as input and, by following the instructions of a computer program, produces other Chinese characters, which it presents as output. "
(В 1980м году — когда Сёрль описал Китайскую комнату — в использовании понятия «компьютерная программа» нет ничего необычного)
А поскольку там ничего не сказано про необходимость наличия «всех комбинаций символов» (и т.п.), то никакого комбинаторного взрыва нет.vadimr
12.09.2016 21:59+1Сёрл говорит о том, что, если разум алгоритмичен, то можно вести разумный диалог, не имея субъектности. Это само по себе никак не относится к предмету настоящего обсуждения, и, на мой взгляд, и так самоочевидно.
AlexeyR
12.09.2016 22:37Вы правы. Просто пример с китайской комнатой получил широкую известность и часто используется «не по прямому назначению».
Volutar
13.09.2016 07:16Субъективность — штука непростая. О наличии или отсутствии субъективности внешнему наблюдателю рассуждать практически невозможно. Проблема «китайской комнаты» — это достаточно классическая софистика, к сожалению очень распространившаяся. Зачем-то отдельным элементам системы (нейронам) пытаются навязать свойства всей системы (мышление). Это как ткнуть пальцем в коленчатый вал, и многозначительно провозгласить его несамодостаточность и неспособность к созданию целенаправленной тяги.
Гипотетический «философский зомби», в случае симуляции процессинга сигналов от рецепторов, перестаёт быть таковым, поскольку за счёт этого обретает свои квалии.vadimr
13.09.2016 08:36Из процессинга сигналов от рецепторов автоматически не следует появление квалиа. Обрабатывать сигналы может программа из десяти строк, но квалиа у неё нет. (Хотя элиминативисты могут сказать, что квалиа вообще нет).
Volutar
13.09.2016 09:27Так-то — да. Та же видеокамера хоть и «видит» — даже с не банальным процессингом квалию не образует.
Что такое квалиа? Это просто самый низкий уровень восприятия сигнала, идущего от рецепторов. И способность этот низкий уровень возбуждать через обратную связь (как минимум для работы механизма вызова и укрепления памяти). Для того чтобы это восприятие можно было назвать полноценной квалией, нужен «полный цикл» — от процессинга рецепторных сигналов, через низкоуровневые преобразователи (например, фурье-подобное разложение в кохлеарном органе), через фильтры-классификаторы разного уровня абстрагирования и динамические ассоциативные цепочки с обратными связями, и вплоть до моторики (цвет тоже перестаёт восприниматься без саккадной моторики).
«Философские зомби» в принципе не возможны без квалий (иначе они не будут иметь весь необходимый «изображаемый» опыт). А с квалиями это будут уже не зомби. Понятие «философский зомби» в этом смысле содержит врождённое противоречие, которое разрешается просто вычеркиванием этого понятия из списка вещей, достойных обсуждения.vadimr
13.09.2016 09:40Вы сейчас излагаете элиминативистскую позицию, стопроцентно аргументированно оспорить которую невозможно, так как дело касается субъективных ощущений. Но всё-таки большинство людей, знакомых с проблемой, признают существование квалиа в традиционном понимании. А именно, что субъективное ощущение красного цвета (называемое квалиа), отличается от представления о красном цвете.
Философскому зомби достаточно иметь представление о красном цвете, такое, как, например, имеет компьютер, кодирующий его тройкой чисел (255, 0, 0) или длиной волны 700 нм. Этого достаточно для приобретения всех внешних признаков опыта, связанного с восприятием красного цвета. Однако, человек не измеряет красный цвет, а непосредственно его ощущает в своём восприятии, что и называется квалиа.Volutar
13.09.2016 09:55А кто сказал Вам, что «непосредственное ощущение цвета в восприятии» — не есть ассоциативное тэгирования того самого триплета (255, 0, 0), который на самом деле от рецепторов и приходит (плюс-минус)? _Ощущение_ красного цвета затрагивает все уровни, вплоть до первичных зон, а «представление» (фантазирование) красного цвета до первичной зоны просто не добирается, оставаясь на ассоциациях хоть и низкого уровня, но всё же не первичного (иначе такое низкоуровневое воображение будет обладать свойством галлюцинации, и перекрывать реальное восприятие).
Квалия — это просто термин. Он означает вещи, которые при материалистической интерпретации вполне находят своё место. Я не вижу причины редцуирования словаря за счёт этого термина, как предлагают элиминтависты.

TimKruz
12.09.2016 22:26+1Он не учел того, что все ответы предусмотреть невозможно.
А все вопросы-ответы предусматривать и не нужно. Чтобы понимать человеческую речь на 95%, достаточно знать 3 тысячи слов (это если на английском), а количество комбинаций этих слов в предложения ограничено правилами языка и здравым смыслом, так что количество повседневных фраз и даже «вопросов с подковыркой» довольно ограниченное количество.
При этом нужно понимать, что поиск ответа на вопрос в правильной программе должен происходить не буква в букву. Нечёткий поиск (fuzzy search) превращает фразы «каг дила», «как у тебя дела», «как делишки», «дела-то как» и прочее в похожую по смыслу фразу «как дела», которой в БД соответствует ответ «всё хорошо».
Ещё некоторые боты используют маски для поиска — так, для фразы «как дела» маской будет "* ка? * д? л?* *" или что-то в этом роде. Но такие маски сложно составлять автоматически, так что такие боты обучаются вручную. А вот бот, использующий нечёткий поиск — может просто прочитать большую базу осмысленных диалогов и тут же научиться отвечать на любые сложные вопросы.
Китайская комната не способна вести мало мальски длинную бесседу.
Если использовать поиск с учётом контекста, можно вести сколь угодно длинные беседы, если они хотя бы частично похожи на те, что уже были в прошлом обучаемого чат-бота. Пример:
А1: Какие фильмы ты любишь?
Б1: Люблю Терминатор: Генезис.
А2: А кто твой любимый герой из этого фильма?
Б2: Конечно же Папс!
В данном случае ответ Б2 на вопрос А2 ищется с учётом контекста А1-Б1. В памяти чат-бота может быть сохранена ассоциативная цепочка А1->Б1->А2->Б2->..., у каждого узла которой свой контекст (nil (если это начало диалога), A1, А1-Б1, А1-Б1-А2 и т.д.).
Так что, в такого чат-бота достаточно загрузить базу длинных диалогов, чтобы он научился вести длинные беседы. При этом память экономится, потому что в базе ассоциаций хранятся только ссылки на записи базы текстовых фраз. Можно разделять каждую фразу на слова, а каждое слово на буквы, таким образом усложнив поиск ответов, но свойства такой системы мне пока неизвестны (я только планирую реализовать это в своём проекте).
Слишком быстро происходит комбинаторный взрыв.
Избежать КВ можно, если «свёртывать» («сворачивать») базу данных. Ведь в текстовой БД всегда есть группы похожих друг на друга слов/фраз. Можно обозначить эти группы одним похожим на все слова группы словом (скажем, это «общее» слово), и искать сначала по общим словам, а только найдя наиболее подходящее общее слово, искать среди его частных. Пример: база из 1000 слов, свёртываем до 100 групп, в каждой из которых 10 слов, и тогда нам нужно произвести 110 операций сравнения вместо 1000 — выигрыш по скорости поиска почти в 10 раз. Конечно, реальная БД может плохо свёртываться, тут уж как повезёт… Может, ещё что придумаю для ускорения…
Я, кстати, в данный момент разрабатываю систему, у которой некоторые из интеллект-ядер основаны на описанных выше механизмах. Не претендую на изобретение сильного ИИ, но полноценная универсальность моего проекта вполне достижима. Когда будет открытая бета-версия — обязательно напишу статью о ней на Хабр.
Тот смысл, который вклажывал в этот тест сам Тьюринг был как раз в том, как отличить интеллект от попытки обмануть за счет манипуляции словами.
Я думаю, Тьюринг хотел сказать нам, что отличить реальный интеллект от умелой имитации в принципе невозможно.
Но, с другой стороны, умелая имитация может оказаться ничуть не хуже реального интеллекта — тогда в чём разница?
И потом, ТТ даже не все люди могут пройти. Тут всё зависит от судей. С судьями-«кисами» и оригинальным ограничением в 5 минут (Тьюринг предлагал именно 5 минут) даже примитивный чат-бот наберёт больше 50%, потому что по уровню IQ и знаниям «киса» и чат-бот примерно равны, а, может, чат-бот даже начитаннее. С другой стороны, сама «киса» с дотошными судьями-программистами (или судьями-математиками, судьями-физиками и т.д., короче, любой «интеллектуально продвинутый» человек) вряд ли сможет набрать даже 30% — её просто примут за чат-бота, прикидывающегося дурочкой.
Программа должна не продержаться 3 минуты, обтекаемо уходя от ответов, а доказать в допросе с пристрастием свою состоятельность.
Боюсь, в «допросе с пристрастием» при умелом допрашивающем любого человека можно убедить в том, что он и не человек вовсе, а примитивный робот, и в результате отправить его в психушку сразу после такого «допроса». :)
ТТ нацелен на средний по уму класс людей, и подразумевает не допрос, а обычную беседу.
Если уж пытаться «вывести бота на чистую воду», то некоторые методы могут вывести совсем не того, кого нужно. Ведь обычный человек не знает сложных уравнений или китайских иероглифов, с трудом может прочитать |33t $p3@k (а времени на ответ мало) или быстро решить логическую задачку, и вряд ли помнит, кто президент в Нигерии или что там было в истории заснеженной и населённой пьяными медведями с балалайками древней Руси (про медведей и балалайки уж точно все знают). А ведь на ТТ в качестве противоположности ИИ набираются обычные люди, а не многократные победители «кто хочет стать миллионером».AlexeyR
12.09.2016 22:35Как всегда все дело в мелочах. Это только кажется, что имея около 5000 общеупоребимых слов легко перебрать все короткие беседы. Даже для одного предложения это триллионы вариантов. Но самое главное, что нельзя ограничивать размер той части бесседы, которую надо принимать в рачсет. Для людей весь жизненный опыт, а не только последние несколько предложений могут влиять на ответ. Если же усложнять чат бота что-бы он принимал во внимание весь полученный опыт и правильно определял контксты повествования, то это рано или поздно приведет к той схеме, что описана в статье.
buriy
12.09.2016 23:03А почему вы считаете, что нужно перебирать все беседы или что-то ограничивать?
Весь смысл в том, чтобы алгоритм сжимал беседы до компактного ядра, которое можно описать конечной программой, для этого даже не нужны «все беседы» (более того, живой человек тоже не умеет отвечать на все вопросы мира).
Также никто в китайской комнате не ограничивает возможность запоминания опыта.AlexeyR
12.09.2016 23:11«Сжимать беседы до компактного ядра». А как вы будете получать это ядро? Не захочется ли вам выделить главный смысл? Слова многозначны, как вы будете выбирать правильную интерпретацию, ведь от этого зависит ответ?
buriy
13.09.2016 09:34> А как вы будете получать это ядро?
Ну, например, нейросетями. Они же отличный аппроксиматор произвольных функций, в том числе, неплохо умеют сжимать информацию (по сути, строить сжимающее преобразование).
Можно подготовить обучающее множество с целью построить алгоритм сжатия. Те же word2vec и glove неплохо это делают для слов, потом с помощью обученных векторов слов процедура повторяется для фраз. Если же потом повторить процедуру для реплик вопрос-ответ (вместо фраз), то можно получить и модель, описанную в работах про Dynamic Memory Networks ( https://arxiv.org/abs/1506.07285 и др. ).
>Не захочется ли вам выделить главный смысл?
«Главного смысла» нет, в зависимости от целей и опыта, наиболее важной и полезной информацией может быть разная информация.
А правильное значение слов (если вы об этом) выбирается, исходя из темы разговора, знаний о мире и соседних слов. Это обучаемая вещь, но, в любом случае, я не понимаю, причём тут перебор всех возможных бесед, и особенно, во время работы программы.shabanovd
13.09.2016 10:10Я вижу противоречие — «это обучаемая вещь» и отсутствие «перебор всех возможных бесед». А на чем происходит обучение?
buriy
13.09.2016 16:09Обучение происходит на а) части предыдущих бесед
и б) происходит сохранение полученных в ходе бесед знаний — можно считать это видом обучения, если очень хочется.
Но я искренне не понимаю, зачем нужен перебор всех возможных бесед.AlexeyR
13.09.2016 16:17Чтобы воспользоваться беседой (фразой) для обучения ее надо предварительно правильно интерпретировать. Иначе одни и те же слова, использованные в разных фразах в разных смыслах, создадут огромную техническую сложность. Только когда информация приведена к контексту с ней можно начитнать что-то делать. Этот принцип хорошо прослеживается в сверточных сетях.
Переберать надо не все беседы, а все контексты.buriy
13.09.2016 16:35А выбор подходящего контекста с помощью нейросетевой классификации или регрессии вы не рассматриваете, только полный перебор?
AlexeyR
13.09.2016 23:39Это совсем разные вещи. Например, то что делает сверточная сеть не реализовать другими способами. А сверточная сеть — это частный случай контекстного подхода.
shabanovd
12.09.2016 23:35«сжимал беседы до компактного ядра» — это процедура изменяющая первичные данные (память). Если не сохранять первичное «воспоминание», то будут одни «иллюзии» (именно эти недостатки и были перечислены ниже)
buriy
13.09.2016 09:37А в чём проблема и сжимать беседы, и сохранять первичные воспоминания? (Китайская комната этого не запрещает)
shabanovd
13.09.2016 10:15В том, что про это не говорится явно. И если первоначальные воспоминания сохраняются, то зачем обманываться, говоря, что работаем с неким компактным представлением этих данных, а не с самими данными? Ведь в итого это «компактное ядро» будет постоянно пересчитываться от первичных данных, дабы убрать накапливаемую погрешность (ошибку).
buriy
13.09.2016 16:07>то зачем обманываться, говоря, что работаем с неким компактным представлением этих данных, а не с самими данными?
Ну, наверное, потому что мы действительно работаем с компактным представлением данных?
Данные не обязаны храниться, часть данных может храниться для последующего воспроизведения или доучивания.
>Ведь в итого это «компактное ядро» будет постоянно пересчитываться от первичных данных, дабы убрать накапливаемую погрешность (ошибку).
Нет, есть алгоритмы online learning, не требующие многократного воспроизведения данных.
А ошибки в основном возникают не от отсутствия оригинальных данных, а от неправильных обобщений.shabanovd
14.09.2016 11:25Мы спорим «в какой цвет будем красить стены» -)
Мне неизвестны иные механизмы борьбы с «дефектами» возникающими из-за последовательности подачи данных кроме полного перебора полученных данных. И я не говорю, что требуется постоянный перебор, возможны оптимизации, но они не исключают полностью потребность в полном переборе.
TimKruz
13.09.2016 16:18Это только кажется, что имея около 5000 общеупоребимых слов легко перебрать все короткие беседы. Даже для одного предложения это триллионы вариантов.
Не понял, зачем перебирать все возможные варианты комбинаций? Человек использует в речи очень ограниченный набор комбинаций даже из того множества комбинаций, что разрешены правилами языка и здравым смыслом. При этом многие используемые человеком комбинации сводятся к общим («у тебя дела как» -> «как дела» и т.п.), число которых ещё меньше.
Но самое главное, что нельзя ограничивать размер той части бесседы, которую надо принимать в рачсет. Для людей весь жизненный опыт, а не только последние несколько предложений могут влиять на ответ.
Человек может удерживать фокус на каком-то наборе информации только около 15 минут, потом он непроизвольно забывает, о чём думал, если эта информация не успела оставить след в постоянной памяти. Вот недавно на Хабре была статья про то, что нужно записывать всё, что обсуждается на совещаниях разработчиков — почему? Потому что даже за час совещания люди могут от 4 до 12 и более раз «потерять нить диалога», т.е. забыть, что обсуждалось только что. Так устроена наша кратковременная память. Вот и машине не нужно в подробностях помнить всё, что обсуждалось три часа назад.
А жизненный опыт — это такая ассоциативная память, воспоминания (образы) из которой вызываются, когда в диалоге было задействовано то или иное слово. Т.е., если усложнять модель чат-бота, в контексте фразы используются не только предыдущие сообщения диалога, но и вызванные из долговременной памяти образы.
Но нужно проверять на практике, стоит ли вообще такая игра свеч или нет. Может, можно сделать проще…AlexeyR
13.09.2016 16:21Как тогда смотреть фильмы, там полтора часа и надо следить за всеми деталями. С сериалами, вообще, — беда.
Число возможных вариантов беседы, даже, за 15 минут, даже со всеми ограничениями, много больше чем число шахматных парий.TimKruz
13.09.2016 16:36По собственному опыту сужу — в конце просмотра фильма я помню только общий смысл фильма и штук пять самых ярких сцен, въевшихся в долговременную память. Когда пересматриваю фильм второй раз — постоянно ощущение «о! а вот это я не помню вообще!», потому что фокус скачет по кадрам и выхватывает лишь что-то отдельное, а ещё меньше из этого выхваченного уходит в долговременную память…
С сериалами сложнее — если последнюю серию видел неделю назад, то обычно тяжело просто взять и вспомнить, чем дело кончилось — приходится открывать предыдущую серию и смотреть пару моментов ближе к концу, чтобы из долговременной памяти вышла сюжетная линия и была возможность её продолжить. Если не пересматривать предыдущую серию — чаще всего возникает ощущение типа «ой, а как они тут оказались?»…
Возможно, это лично у меня такая плохая память. :D
много больше чем число шахматных парий
Но в шахматах приходится рассчитывать каждый ход, а в непринуждённой беседе можно сменить тему или сослаться на лёгкую амнезию, и это нормально для человека. Конечно, ещё всё зависит от того, о чём беседа и с кем…AlexeyR
13.09.2016 23:42+1Сослаться на амнезию — это сойдет для чат бота, который хочет притвориться человеком. Мы помним все детали беседы и адекватно используем предыдущую информацию. То, что есть забывание — это естественно. Но это не амнезия.
vadimr
13.09.2016 08:32Я думаю, Тьюринг хотел сказать нам, что отличить реальный интеллект от умелой имитации в принципе невозможно.
Но, с другой стороны, умелая имитация может оказаться ничуть не хуже реального интеллекта — тогда в чём разница?
Разница в том, что реальный интеллект способен совершать интеллектуальную (или не очень) работу на основании общения, то есть как раз описываемое автором смысловое ядро преобразовывать в другое представление. О чём тест Тьюринга, проверяющий исключительно коммуникативную функцию, ничего не говорит.
Когда мы говорим компьютеру: “Сири, какая сейчас погода?” и он сообщает нам погоду, то это реальный искусственный интеллект, хотя, возможно, очень слабый. А когда, в ответ на вопрос, компьютер посылает нас в известном направлении, потому что у него депрессия, то это хороший результат по Тьюрингу, но совершенно не требующий анализа смысла речи и вообще интеллектуальных действий в традиционном понимании.Volutar
13.09.2016 09:43Тест Тьюринга, насколько я его понимаю, призван как раз выявить те границы познания мира субъектом. Он позволяет выявить ассоциативные рамки, способности к эмоциям и эмпатии, и к решению различных задач.
Не просто диалог, а скорее как «беседа с психологом», с очень обращением особого внимания на «когнитивные дыры» субъекта.
buriy
12.09.2016 22:28Алексей, написано познавательно, но несколько тяжеловато из-за абстрактности.
Был бы признателен за один или несколько простейших примеров для каждого определения. Сами же говорите, для понимания нужен одинаковый опыт. Примеры — простейший способ получения опыта.
Кроме того, они позволят понять, что вы ничего не упустили в определениях (например, см. п. 2 ниже про время).
Пришлось несколько раз перечитывать и мучительно согласовывать ваши термины с используемыми в области Machine Learning.
И вот что выяснилось:
1) То, что вы описали — это байесовский классификатор, осложнённый некоторым дополнительным обучением и вспомогательными алгоритмами преобразования.
Так что можно было описать всё намного компактнее, дать ссылки и использовать устоявшуюся терминологию.
У данного механизма известные проблемы:
— самовозбуждение при совмещении с unsupervised learning ( побеждающий класс накапливает ещё больше опыта и ещё чаще побеждает — впрочем, можно исправить бустингом, ценой небольшой потери в качестве и наличия дополнительного подстроечного параметра в формуле бустинга)
— невозможность несуществующего, она же «закрытость множества классов»: если интерпретации ещё не было, то вероятность её получения — ноль (можно исправить сглаживанием, но тоже ухудшает качество, особенно при «one-shot learning» — запоминании при однократном предъявлении)
— накопление ошибок со временем при совмещении с unsupervised learning (никто никогда не избавляется от возникших ошибок преобразования, наоборот, они со временем укрепляются — что с этим-то делать? это вопрос, терзающий всех в мире, пытающихся создать искусственный интеллект или хотя бы повторить естественный)
2) Понятие «концепт» и «последовательность концептов», описанные в начале статьи, не используются, как и временная связь — видимо, предполагается одновременное использование всех слов из последовательности концептов — но об этом ни слова в статье, ни подтверждения, не опровержения.
3) И самое главное. Вопрос, как выглядят «интерпретации» и контекстно-зависимый алгоритм преобразования — не раскрыт.
Ни слова также не сказано об обучении — а ведь, как я сказал выше, данная схема не работает сама по себе, без «интеллекта», находящемся где-то в другом месте.
По сути, описанное в статье — это лишь классификатор, который можно редуцировать до расчёта вероятностей вхождения в различные классы по числу упоминаний этих классов в памяти (и, в случае «мягкой классификации» — умноженной на вероятность данного класса в данной интерпретации).
Сами алгоритмы преобразования и вопросы их близости вы пока что обошли стороной.
Из плюсов — вы дали крайне занимательный «вид сбоку» на привычную машинерию.
P.S. Я бы ещё вместо слова «контекст» использовал что-то типа «группа алгоритмов» или «контекст применения алгоритмов», чтобы подчеркнуть то, что ваш контекст — это не сущность, а набор функций.
P.P.S. Кстати, у Джеффа Хокинса «spatial pooler» действует крайне похоже на ваш алгоритм.AlexeyR
12.09.2016 22:57Несколько позже я опишу конкретные реализации и постараюсь шаг за шагом описать, что и как происходит. Сейчас я попробовал дать только самое общее представление. Далее я покажу, что практически все методы, используемые в машинном обучении находят свое место в этой модели. Но есть и принципиальные различия между классическими подходами и тем, как выглядят их аналогии. Заимствование терминов и названий методов за которыми уже есть устоявшееся четкое понимание может сильно запутать. По ходу повествования я укажу на аналогии и проведу сравнение.
shabanovd
12.09.2016 23:21+1Ошибка закралась в понимании «контекста», это не функция, а некая закономерность в данных. Конечно можно назвать выделение фитч функцией преобразования, тогда и здесь «контекст» станет функцией.
Вот в примере с визуальной информацией контекстами являются аффинные преобразования. Они получен из входных данных, но важно понимать, что под входными данными понимается как информация с сетчатки глаза, так и «команды» мышцам глаз.buriy
13.09.2016 09:19Алексей написал, что «контекст» — это группа из множества всех используемых преобразований, которая попала в один класс.
Почему это нельзя рассматривать как функцию? Наоборот, мне неудобно было бы рассматривать это как сущность, потому что это уводит от смысла. Тогда уж назовите это «метаданные», ведь, исторически, контекстом называют несколько другое.
В целом, то, что вы описываете, я бы назвал joint learning: одновременное распознавания метаданных (аффинного преобразования системы координат) объекта и самого объекта. Не нужно этого стесняться :)
Посмотрим, куда это вас заведёт, а особенно интересно, как вы это вывернете для текстовой и другой последовательно подаваемой информации — ведь для визуальной информации всё это давно и успешно работает на тех же нейросетях и ничего принципиально нового здесь нет.shabanovd
13.09.2016 10:05О том, что контексты для зрения это аффинные преобразования говорится лишь потому, что можно избежать обучения, и задать эти контекста аналитически.
Такой подход позволяет увидев объект лишь раз распознать его в другом «ракурсе» (при условии что он приводится к первичному аффинными преобразованиями). Т.е. при распознавании получаем пару объект-контекст. Это не joint learning, так как выход один, а не несколько.buriy
13.09.2016 15:59Это не всегда позволяет распознать объект в другом ракурсе — т.к. объект с другого ракурса или с течением времени может выглядеть по-другому. С удовольствием погляжу на решение вами именно этой проблемы.
Т.е. контекст вы не получаете на выходе, а только сам объект перебором контекстов?AlexeyR
13.09.2016 16:18Получается пара «контекст-объект». Это можно интерпретировать как, например, «слева-сверху — квадрат»
shabanovd
14.09.2016 11:35при условии что он приводится к первичному аффинными преобразованиями
Это обязательно условие для 100% распознавая.
Объекты которые изменились должны иметь не изменившуюся часть по которой можно было бы выдвинуть гипотезу, иначе нет возможно их сопоставить.buriy
15.09.2016 14:30Эмм… ребенок старше трёх лет умеет узнавать игрушку, скрывшуюся из поля зрения и вернувшуюся обратно. Это же умеет и весьма несложный алгоритм под названием predator.
AlexeyR
15.09.2016 14:38Чтобы узнать, что вернулась таже игрушка, а не другая между ними должно быть что-то общее. Можно, конечно ориентироваться на траекторию движения игрушки и время, но это другая история.
buriy
15.09.2016 19:45Между ними есть общее — они выглядят похоже до и после операции :) Тот же самый это объект или нет — никто не знает, это философский вопрос :), а значит, это всегда вопрос веры больше, чем реального наблюдения — бывают подмены и предметов и людей, и невнимательность, мешающая осознать подмену.
То, что человек обладает этим навыком, это неоспоримый факт. И, мне кажется, это умение обязательно нужно при качественном анализе текста — а значит, этот тест вполне можно использовать как лакмусовую бумажку для проверки качества алгоритма анализа текста (в датасетах парафраз так и делается — заменой части фразы легко получить противоречие, которое программа должна обнаружить). Тот же самый тест можно делать и с картинками — если на фото женщина держит телефон в руке, а рядом идёт мужчина, то аннотация «мужчина с телефоном» будет неправильной. Текущие алгоритмы QA и photo captioning пока что крайне редко этот тест проходят — неплохо находя объекты, они не всегда их правильно объединяют. Посмотрим, что будет у вас.
CrzyDocTI
14.09.2016 11:49А тут мнение относительно молодого, не имеющего основательных знаний в этой области и недавно перенесшего инсульт(выражение мысли часто сумбурно), делайте поправку на восприятие:
Заголовок спойлераОтлично! Неплохо собранная информация в одной голове, это видимо был большой труд.
С основной идеей согласен. Контекст, фреймы — это все похоже на сферического коня в вакууме(т.е. мяч) — такое повествование подходит для диссертации или докторской, не для построения логической цепи в голове собеседника.
Восприятие информации, поиск смысла и разбор звука и визуальной — упрощайте все, все что только можно. Восприятие информации — для начала приведите пример как только что родившийся ребенок разберет что такое хорошо а что такое плохо. Вы пытаетесь представить модели действующие на уровне сформировавшегося индивидуума — зачем?
Одна мысль что не дает мне покоя — а есть ли вообще воспоминания? Это явно комплекс чего-то друго что нами воспринимается как целая сущность(иначе воспоминания невозможно было бы изменить, состояния только 1 или 0). На мой взгляд мозг хранит в себе лишь паттерны действий, а воспоминание — лишь обман восприятия работы самого себя.
По поводу искусственного интелекта — имхо, пока мы не наделим намишу инструментами доступными нам — не ждите того же интеллекта.
george3
Довольно сложно увязать все сказанное в кучу даже для специалиста в области семантического анализа.
«Согласованное изменение трактовки слов позволяет выделить пространство контекстов» ломает мой мозг. понятного мало, слов много.