
 Наша облачная платформа Voximplant — это не только телефонные и видео звонки. Это еще и набор «батареек», которые мы постоянно улучшаем и расширяем. Одна из самых популярных функций: возможность синтезировать речь, просто вызвав JavaScript метод say во время звонка. Разрабатывать свой синтезатор речи — на самая лучшая идея, мы все-таки специализируемся на телеком бэкенде, написанном на плюсах и способном обрабатывать тысячи одновременных звонков и снабжать каждый из них JavaScript логикой в реальном времени. Мы используем решения партнеров и внимательно следим за всем новым, что появляется в индустрии. Хочется через несколько лет отойти от мема «Железная Женщина» :) Статья, адаптированный перевод которой мы сделали за эти выходные, рассказывает про WaveNet, модель для генерации звука (звуковых волн). В ней мы рассмотрим как WaveNet может генерировать речь, которая похожа на голос любого человека, а также звучать гораздо натуральнее любых существующих Text-to-Speech систем, улучшив качество более чем на 50%.
Наша облачная платформа Voximplant — это не только телефонные и видео звонки. Это еще и набор «батареек», которые мы постоянно улучшаем и расширяем. Одна из самых популярных функций: возможность синтезировать речь, просто вызвав JavaScript метод say во время звонка. Разрабатывать свой синтезатор речи — на самая лучшая идея, мы все-таки специализируемся на телеком бэкенде, написанном на плюсах и способном обрабатывать тысячи одновременных звонков и снабжать каждый из них JavaScript логикой в реальном времени. Мы используем решения партнеров и внимательно следим за всем новым, что появляется в индустрии. Хочется через несколько лет отойти от мема «Железная Женщина» :) Статья, адаптированный перевод которой мы сделали за эти выходные, рассказывает про WaveNet, модель для генерации звука (звуковых волн). В ней мы рассмотрим как WaveNet может генерировать речь, которая похожа на голос любого человека, а также звучать гораздо натуральнее любых существующих Text-to-Speech систем, улучшив качество более чем на 50%.Мы также продемонстрируем, что та же самая сеть может использоваться для создания других звуков, включая музыку, и покажем несколько автоматически сгенерированных примеров музыкальных композиций (пианино).
Говорящие машины
Позволить людям и машинам общаться голосом — давняя мечта людей о взаимодействии между ними. Возможности компьютеров понимать человеческую речь существенно улучшились за последние несколько лет благодаря применению глубоких нейронных сетей (яркий пример — Google Voice Search). Тем не менее, генерация речи — процесс, который обычно называют синтезированием речи или text-to-speech (TTS) — все еще, основан на использовании так называемого concatenative TTS. В нем используется большая база данных коротких фрагментов речи, записанных одним человеком. Фрагменты потом комбинируются, чтобы образовывать фразы. При таком подходе сложно модифицировать голос без записи новой базы данных: например, изменить на голос другого человека, или добавить эмоциональную окраску.
Это привело к большому спросу на параметрический TTS, где вся информация, необходимая для создания речи, хранится в параметрах модели и характер речи может контролироваться через настройки модели. Тем не менее, до сих пор параметрический TTS звучит не так натурально как concatenative вариант, по крайней мере в случае таких языков, как английский. Существующие параметрические модели обычно генерируют звук, прогоняя выходной сигнал через специальные обработчики, называемые вокодерами.
WaveNet меняет парадигму, генерируя звуковой сигнал по семплам. Это не только приводит к более натуральному звучанию речи, но и позволяет создавать любые звуки, включая музыку.
WaveNets
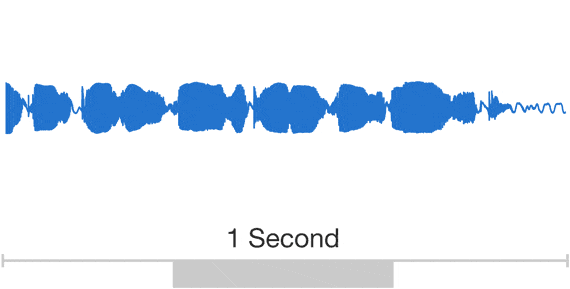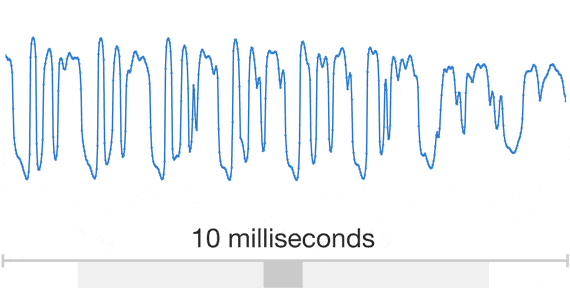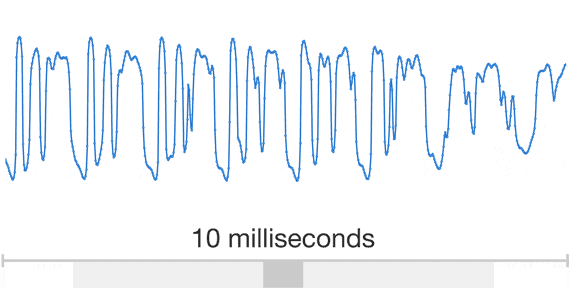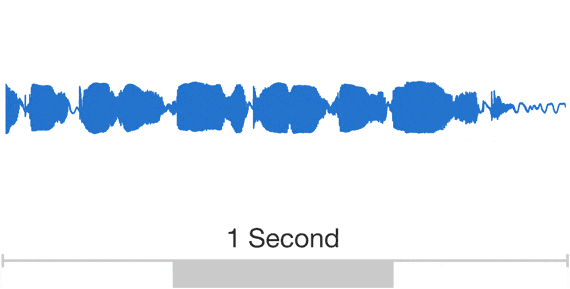
Обычно исследователи избегают моделирования аудио семплов, потому что их нужно генерировать очень много: до 16000 семплов в секунду или более, строго определенной формы в любых временных масштабах. Построение авторегрессионной модели, в которой каждый семпл зависит от всех предыдущих (in statistics-speak, each predictive distribution is conditioned on all previous observations) — это непростая задача.
Тем не менее, наши модели PixelRNN и PixelCNN, опубликованные ранее в этом году, показали, что возможно генерировать сложные естественные изображения не только по одному пикселю за момент времени, но и по одному цветовому каналу за момент времени, что требует тысячи предсказаний на изображение. Это вдохновило нас адаптировать 2х-мерные PixelNets в одномерную WaveNet.

Анимация выше показывает устройство WaveNet. Это сверточная нейронная сеть, где слои имеют разные факторы дилатации и позволяют ее рецептивному полю расти экспоненциально с глубиной и покрывать тысячи временных отрезков.
Во время обучения входящие последовательности представляют собой звуковые волны от примеров записи голоса. После тренировки можно с помощью сети генерировать синтетические фразы. На каждом шагу семплинга значение вычисляется из вероятностного распределения посчитанного сетью. Затем это значение возвращается на вход и делается новое предсказание для следующего шага. Создание семплов таким образом является достаточно ресурсоемкой задачей, но мы выяснили, что это необходимо для генерации сложных, реалистичных звуков.
Improving the State of the Art
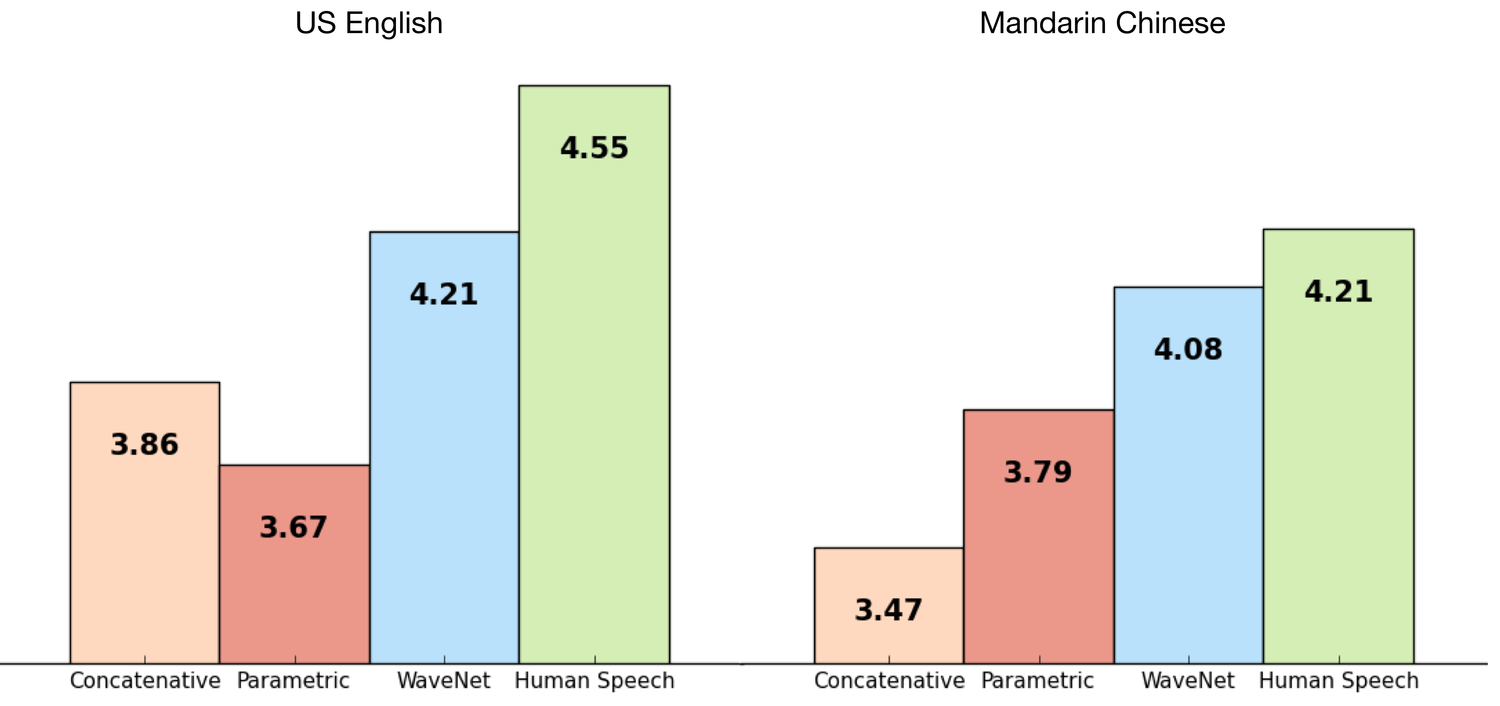
Мы натренировали WaveNet использовав наборы данных от TTS Google, таким образом мы смогли оценить качество ее работы. Следующие графики показывают качество по шкале от 1 до 5 в сравнении с лучшими TTS от Google (параметричским и concatenative) и в сравнении с настоящей речью живого человека, использовав MOS (Mean Opinion Scores). MOS — это стандартный способ делать субъективные тесты качества звука, в тесте были использованы 100 предложений и собрано 500 более оценок. Как мы видим, WaveNets значительно уменьшили разрыв между качеством синтезированной и реально речи для английского и китайского языков (разница с предыдущими методами синтеза более 50%).
Как для китайского, так и для английского, текущий TTS от Google считается одним из лучших в мире, поэтому такое значительное улучшение для обоих языков с помощью одной модели — это большое достижение.
Далее несколько примеров, чтобы вы могли послушать и сравнить:
Английский (US English)
Параметрический
Пример №1
Пример №2
Concatenative
Пример №1
Пример №2
WaveNet
Пример №1
Пример №2
Китайский (Mandarin Chinese)
Параметрический
Пример №1
Пример №2
Concatenative
Пример №1
Пример №2
WaveNet
Пример №1
Пример №2
Понимать что нужно говорить
Чтобы использовать WaveNet для преобразования текста в речь нужно разъяснить что из себя представляет текст. Мы делаем это, преобразовывая текст в последовательность лингвистических и фонетических характеристик (каждая содержит информацию о текущий фонеме, слоге, слове и т.д.) и отправляем их в WaveNet. Это значит, что предсказания сети зависят не только от предыдущих аудио семплов, но и от того текста, который мы хотим преобразовать в речь.
Если мы обучим сеть без текстовых данных, она все еще будет способна генерировать речь, но в таком случае ей нужно будет придумывать что сказать. Как можно увидеть из примеров ниже, это приводит к некоторому подобию болтовни, в которой реальные слова перемежаются со сгенерированными звуками похожими на слова:
Пример №1
Пример №2
Пример №3
Пример №4
Пример №5
Пример №6
Заметьте, что звуки не представляющие из себя речь, такие как дыхание и движения рта, тоже иногда генерируется WaveNet; это показывает большую гибкость модели генерации аудио данных.
Также как вы видите из этих примеров, одна WaveNet сеть способна изучить характеристики разных голосов, мужских и женских. Чтобы дать ей возможность выбирать нужный голос для каждого высказывания мы поставили сети условие использовать идентификацию говорящего человека. Что еще интересно, мы выяснили, что обучение на многих разных говорящих людях улучшает качество моделирование для одного конкретного голоса, по сравнению с обучением только с помощью голоса этого одного человека, что предполагает некоторую форму передачи знаний при обучении.
Изменяя личность говорящего, мы можем сделать так, чтобы сеть говорила одни и те же вещи разными голосами:
Пример №1
Пример №2
Пример №3
Пример №4
Похожим образом мы можем передавать на вход модели дополнительную информацию, например, про эмоции или акценты, чтобы сделать речь еще более разнообразной и интересной.
Создание музыки
Так как WaveNets могут быть использованы для моделирования любого аудио, то мы решили, что было бы интересно попробовать сгенерировать музыку. В отличие от сценария с TTS мы не настраивали сеть на проигрывание чего-то конкретного (по нотам), мы, наоборот, дали возможность сети сгенерировать то что она хочет. После тренировки сети на входных данных от классической фортепианной музыки она создала несколько очаровательных произведений:
Пример №1
Пример №2
Пример №3
Пример №4
Пример №5
Пример №6
WaveNets открывают много новых возможностей для TTS, автоматического создания музыки и моделирования аудио в целом. Тот факт что подход к созданию 16КГц аудио с помощью пошагового создания семплов, используя нейронную сеть, вообще работает уже удивителен, но оказалось, что этот подход позволил добиться результата превосходящего самые продвинутые современные TTS системы. Мы с воодушевлением смотрим на другие возможные области применения.
Для более детальной информации рекомендуем почитать нашу письменную работу на эту тему.
Картинка для привлечения внимания взята из фильма Ex Machina
Комментарии (20)

Andrey_Volk
12.09.2016 10:53Собственно, вопрос: а вы уже применяете данную технологию в своем облаке? Не увидел у вас на сайте подобного)

aylarov
12.09.2016 10:55+2У нас пока обычный text-to-speech, с которым ее сравнивают, WaveNet — это исследовательский проект, но думаю, что в течение какого-то времени он может пойти в продакшн того же Google Speech и станет доступен. Главное, чтобы ресурсоемкость была нормальная для коммерческой эксплуатации.

vladshow
12.09.2016 11:11Вопрос о структуре нейронной сети: сколько вам понадобилось нейронов и слоев для синтеза речи и создания музыки?
Хотелось бы представить мощность нейронной сети.
И еще вопрос о синтезе речи (возможно я плохо прочитал статью): если нейронная сеть фактически позволяет сгенерировать новый сэмпл по нескольким предыдущим, то как осуществить управление такой нейронной сетью, чтобы она говорила то, что нужно, т.е. фактически решала задачу text to speech?aylarov
12.09.2016 11:13Нейронную сеть делали не мы (мы только перевели), а коллеги из DeepMind, поэтому лучше вопросы им задать напрямую. В конце статьи есть ссылка на оригинал статьи, там, наверняка, есть контактные данные.
equand
12.09.2016 11:40Я полагаю на входе текст и преобразованный аудиофайл произнесенного текста с темпом, тембром и другим данными по голосу записывающего.
Так что это не просто закинул голос и сработало.
Еще много работы до прямого синтеза (когда в виртуальный эмулятор гортани подается виртуальных воздух с разным давлением).
equand
12.09.2016 11:41+1Честно говоря, оценки могут быть занижены потому что в оригинальных семплах отсутствуют высокие частоты. Интересно, как проводилось тестирование. Еще становится немного не по себе и даже дурно из-за отсутствия вдыхательных пауз.
nikitastaf1996
12.09.2016 13:45Этой штуке пару миллионов подкастов запихнуть.У google такие ресурсы есть.Вот это будет тема.
ehxo
А музыка, я извиняюсь,
какое-то дерьмоплохая.aylarov
Не удержался, простите :)

equand
Пардон, но музыка говно и какафония.
Каша из гамм, тонов и темпа с громкостью. Можно лучшего добиться с рандомом в пределах гамм.
С другой стороны требовать от него чего-то большего имхо рановато и то чего он добился значительно (переходы все-таки есть, но следуют какой-то синусоиде).
Для людей "спервадабейся" https://soundcloud.com/equand
aylarov
если вы внимательно прочитаете статью, то поймете почему это так. даю подсказку
при желании на вход сети можно было бы дать доп. инфо и она сделала бы и более осмысленную музыку, просто это не входило в рамки данного конкретного эксперимента.
equand
Повторюсь, я не говорю, что не может, факт есть факт, даже при таком входе выход был лучше чем большинство населения могло бы сделать.
eyeofhell
Сюрприз — это не музыка :) Это рандомный шум, который сгенерировала сеть.
equand
Тогда зачем писать "создание музыки"? Ясно же что вызовет баттхерт.
Это тоже самое что рандомные единички и нолики назвать программой.
Написали бы "сгенерировать шум из нот пиано".
eyeofhell
Любая статья на любую тему вызывает баттхерт у определенной части читателей. Это свойство человеческого мозга, в нем больше нейронов для работы с негативом. Эволюционно выработалось за сотни тысячь лет эволюции, чтобы тигр не скушал. Амигдала, гипоталамус, все дела. Мы потерпим, не переживайте :)
equand
Я думаю просто неверно называть "создание музыки" то, чем оно не является. Говорить, что это шум позже не оправдание. Либо в статье надо указать, что это шум, либо редифинировать термин "музыка". Иначе это просто частично инвалидирует статью и выводы команды deepmind.
bask
какофония.
Если хочется послушать нормальную музыку от генератора музыки на основе свёрточных нейросетей, то вот https://www.jukedeck.com/
firexonix
Извиняюсь, но, по-видимому, вы не знакомы с авангардными тенденциями в академической музыке. То, что сгенерировала сеть, еще очень даже мелодично и «слушабельно».
>> Можно лучшего добиться с рандомом в пределах гамм.
Дерзайте и делитесь результатами, будет очень интересно
ikbrain
Так это как в примерах с говорением, когда сетка сама придумывает, что говорить. Вот и получилось ыфлоывапchairщвпршаыцу.