
Новый тип памяти призван обеспечить дальнейший рост производительности
 Как считает сама AMD, компания годами определяла новые типы памяти для графических ускорителей, а остальная индустрия выступала в роли догоняющего. Это давало продуктам AMD конкурентное преимущество, к примеру, в своё время нововведение в виде GDDR5 обеспечило Radeon HD 4870 лидерство по производительности. В итоге GDDR5 стала стандартом, но с момента её первого появления прошло уже семь лет, и каких-либо фундаментально новых изменений не происходило. Следующий прорыв должен обеспечить стандарт High Bandwidth Memory (память с высокой пропускной способностью). Первый видеоускоритель на его основе может выйти уже через несколько месяцев.
Как считает сама AMD, компания годами определяла новые типы памяти для графических ускорителей, а остальная индустрия выступала в роли догоняющего. Это давало продуктам AMD конкурентное преимущество, к примеру, в своё время нововведение в виде GDDR5 обеспечило Radeon HD 4870 лидерство по производительности. В итоге GDDR5 стала стандартом, но с момента её первого появления прошло уже семь лет, и каких-либо фундаментально новых изменений не происходило. Следующий прорыв должен обеспечить стандарт High Bandwidth Memory (память с высокой пропускной способностью). Первый видеоускоритель на его основе может выйти уже через несколько месяцев.Работа над HBM началась семь лет назад, то есть примерно тогда же, когда GDDR5 был полностью готов. Над технологией работали те же инженеры, рассказывает сотрудник AMD Джо Макри. Уже тогда их стал беспокоить факт растущей зависимости общей вычислительной мощи персональных компьютеров от памяти, и они начали подозревать, что энергопотребление постепенно станет сдерживающим фактором.
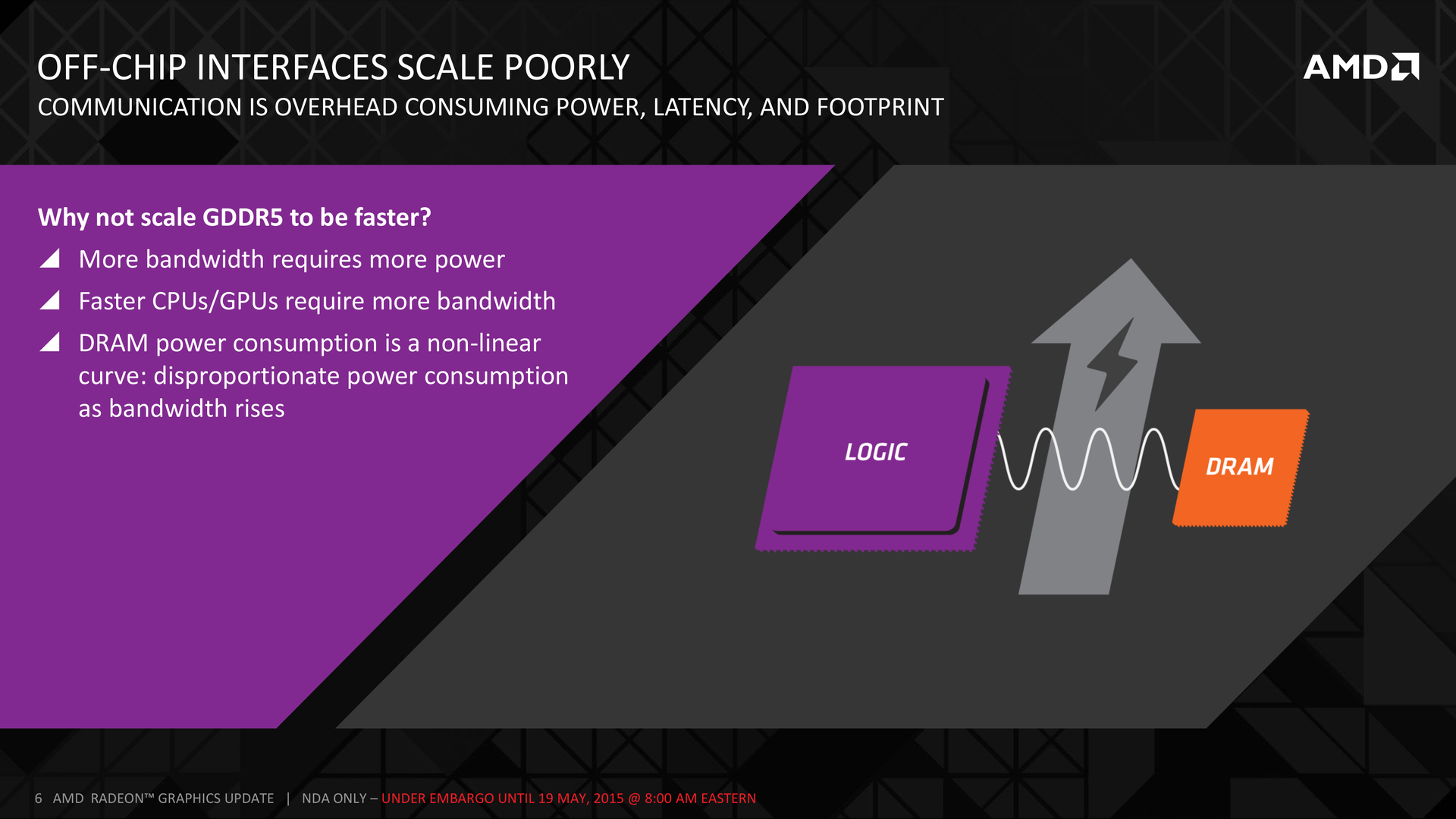
Сейчас из GDDR5 выжимают всё возможное. Для получения дополнительной пропускной способности приходится добавлять дополнительные чипы и каналы, которые отъедают пространство на плате и энергию. У всего есть свои пределы, и видеокарты последнего поколения демонстрируют их своими 512-битными интерфейсами. Обычное ускорение GDDR5 перестаёт работать — в этом году Samsung начала производство чипов на 8 ГБит/с, что является улучшением лишь на 14 % над предыдущим максимумом (7 Гбит/с). AMD уже начала испытывать проблемы с дальнейшим ускорением, поскольку повышение частоты означает резкий рост энергопотребления.

Одним из решений этой проблемы является то, чем производители занимались последние пару десятилетий для уменьшения стоимости и энергопотребления и увеличения производительности: интеграция. К примеру, центральные процессоры включили в свой состав множество элементов, от математических сопроцессоров до контроллеров памяти, и в каждом случае были свои плюсы.
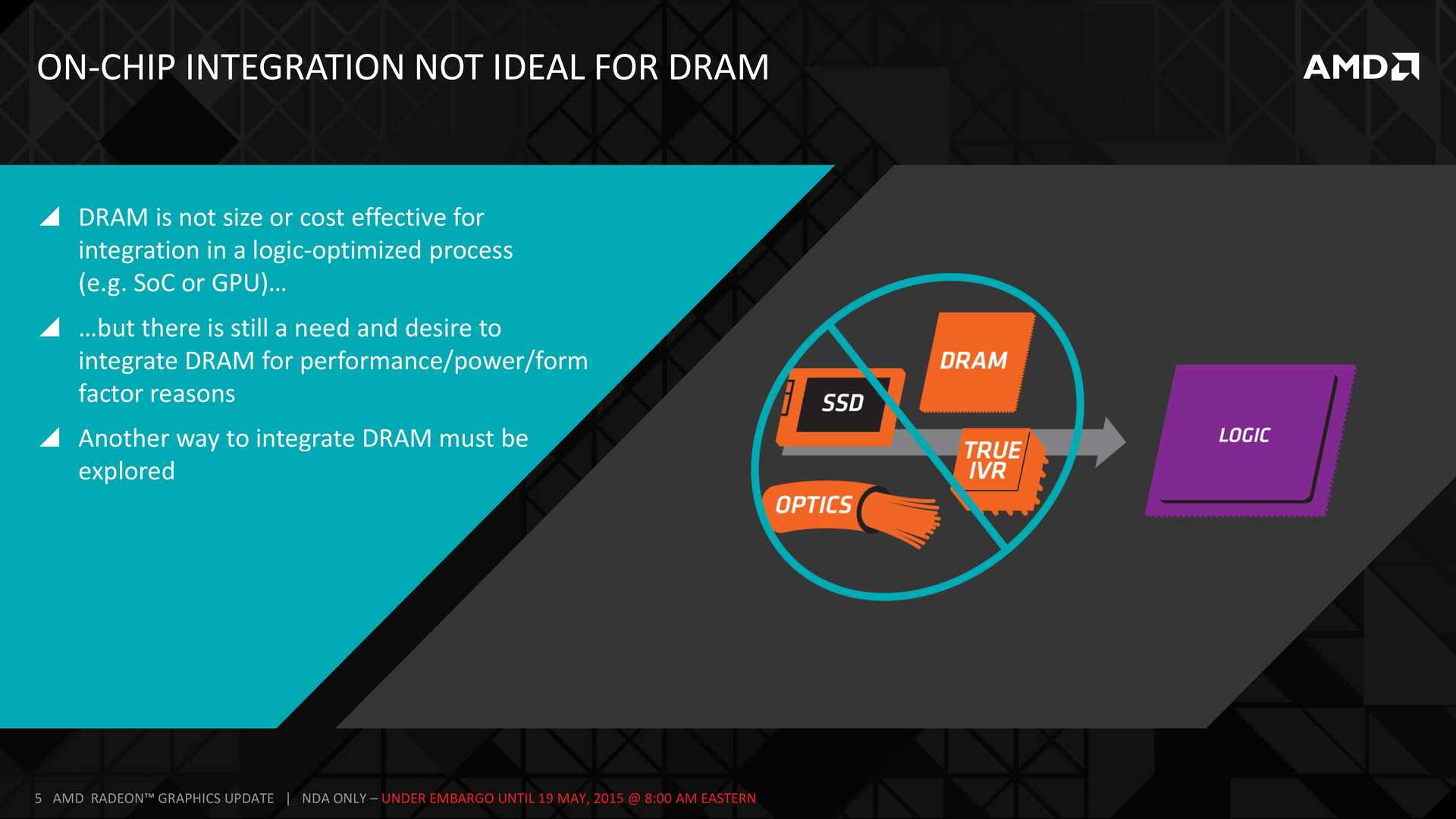
Но объединение памяти и графических процессоров — не такой простой процесс, объясняет Макри. Процессы их производства отличаются настолько, чтобы их объединение на одном чипе стало слишком дорогим. Решением является размещение памяти близко к графическому процессору, но на отдельном кристалле. HBM включает в себя размещение нескольких слоёв в 3D-конфигурации (или, если точнее, 2,5D).
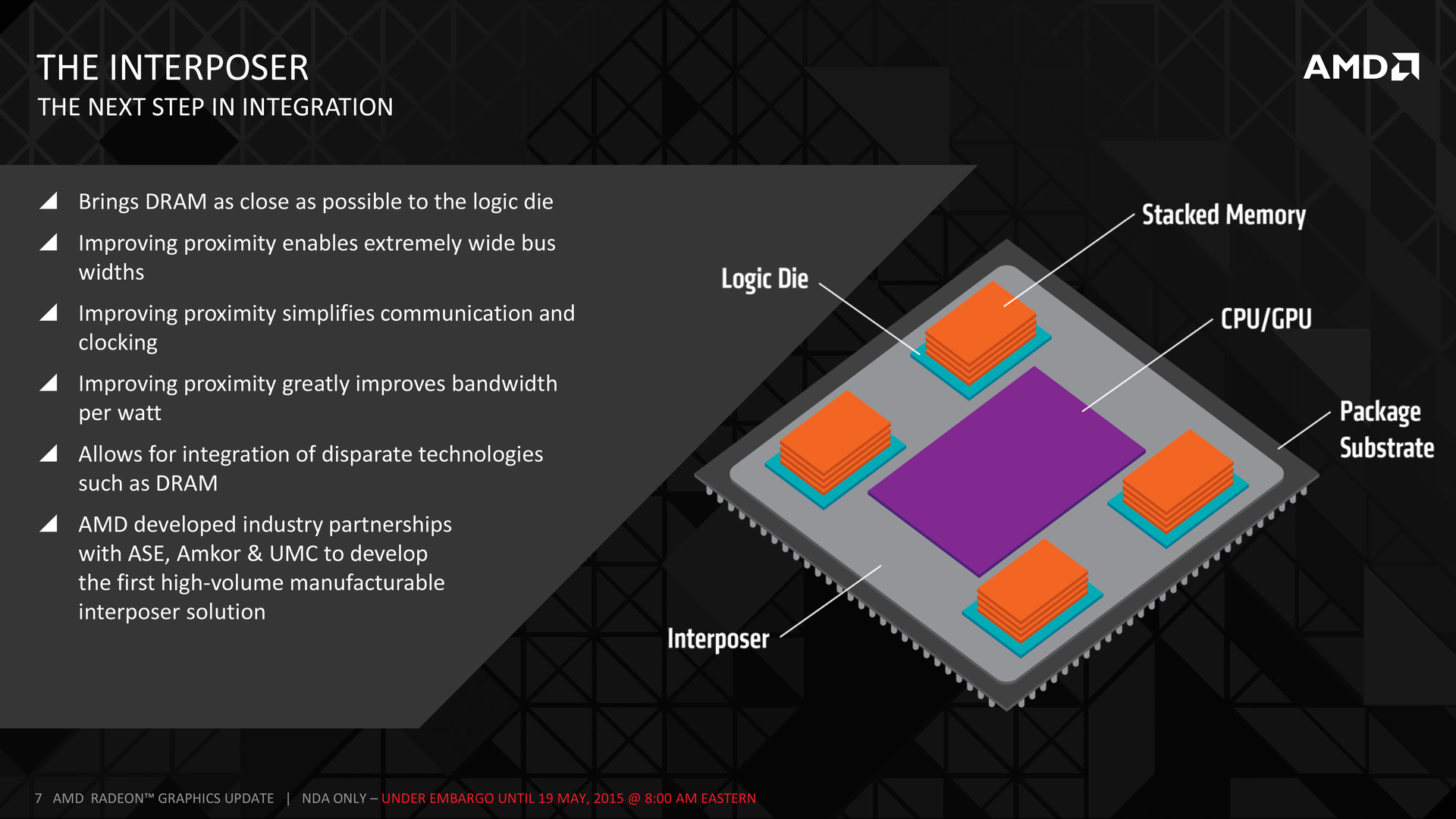
HBM состоит из трёх основных частей: это главный чип (CPU, GPU или система на кристалле), один или несколько столбиков памяти и кремниевый слой, на котором они расположены — interposer (посредник). Интерпозер — обычный кремниевый чип, на данный момент производимый по более старому техпроцессу 65 нм. Макри объяснил, что роль интерпозера полностью пассивна, у него нет активных элементов, поскольку его единственной задачей является электрическое соединение дорожек между памятью и процессором. Поскольку это кремниевый чип, он может соединять куда больше элементов, чем обычная плата. Именно интерпозер является ключевой деталью High Bandwidth Memory. Под интерпозером расположены другие традиционные элементы, но их задачей является обмен с шиной PCI Express, вывод на мониторы и другие интерфейсы. Всё общение между видеопроцессором и памятью происходит с помощью интерпозера.

Интерпозер вызывает большой интерес, но другой важной новинкой является расположенная слоями память. На контролирующий работу логический слой уложены четыре слоя собственно памяти. Пять слоёв подключены друг к другу с помощью межсоединений в кремниевой подложке (TSV). По словам Макри, эти слои очень тонкие, толщина достигает порядка 100 микрометров. Если взять один в руку, то он будет гнуться и развеваться как бумага.
И каждый из этих слоёв хранения содержит новый тип памяти, специально созданный для условий работы в HBM. Память использует относительно низкое напряжение — 1,3 вольта (у GDDR5 — 1,5), более низкие частоты работы (500 МГц вместо 1750) и имеет меньшую пропускную способность (1 ГБит/с вместо 7). Всё это компенсируется очень широким интерфейсом. В первой реализации HBM каждый слой памяти общается по двум 128-битным каналам, то есть каждая стопка имеет 1024-битную шину. В итоге получается массивная 4096-битная память с пропускной способностью порядка 128 ГБ/с.

High Bandwidth Memory не появился с нуля. В 2011 году AMD объявила о планах сотрудничества с производителем памяти Hynix (ныне SK Hynix) по разработке и реализации стандарта памяти нового поколения. AMD создала соединения, интерпозер и новый тип памяти. Hynix производит память, а первые образцы интерпозера создавались на мощностях United Microelectronics Corporation. Новый стандарт уже получил одобрение регулирующего индустрию памяти JEDEC. Это означает, что High Bandwidth Memory может получить широкую поддержку различными компаниями. С некоторым опозданием HBM попал и в планы Nvidia.
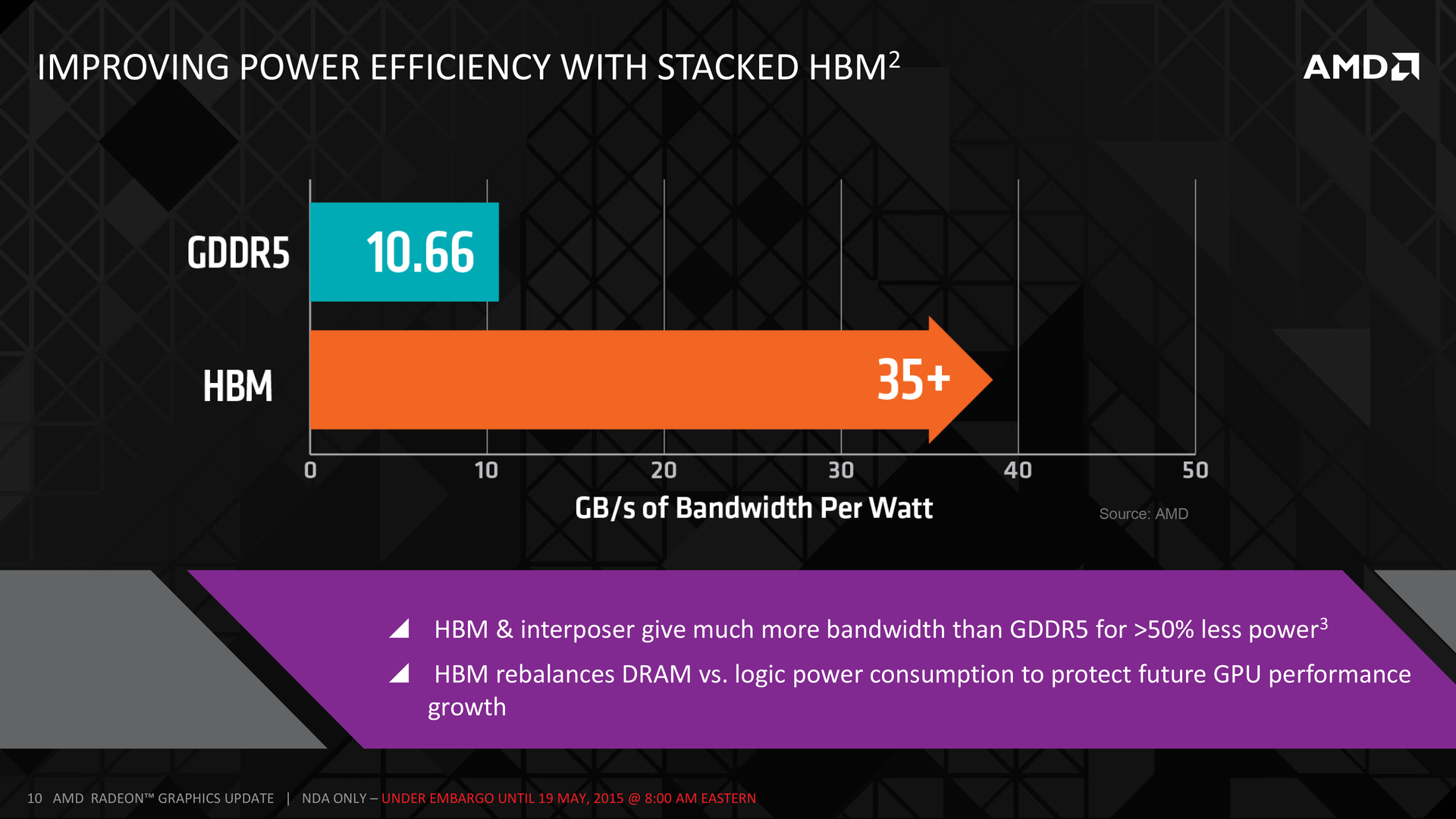
Даже у первого поколения реализации High Bandwidth Memory есть ряд преимуществ над GDDR5, и это не только пиковые пропускные способности. Как утверждает Макри, GDDR5 позволяет передавать 10,66 ГБ/с на ватт, а у HBM этот показатель равен 35. Энергоэффективность памяти — важный показатель, поскольку R9 290X тратит 15—20 % энергии именно на память. Переход на HBM понизит этот показатель более, чем в два раза.
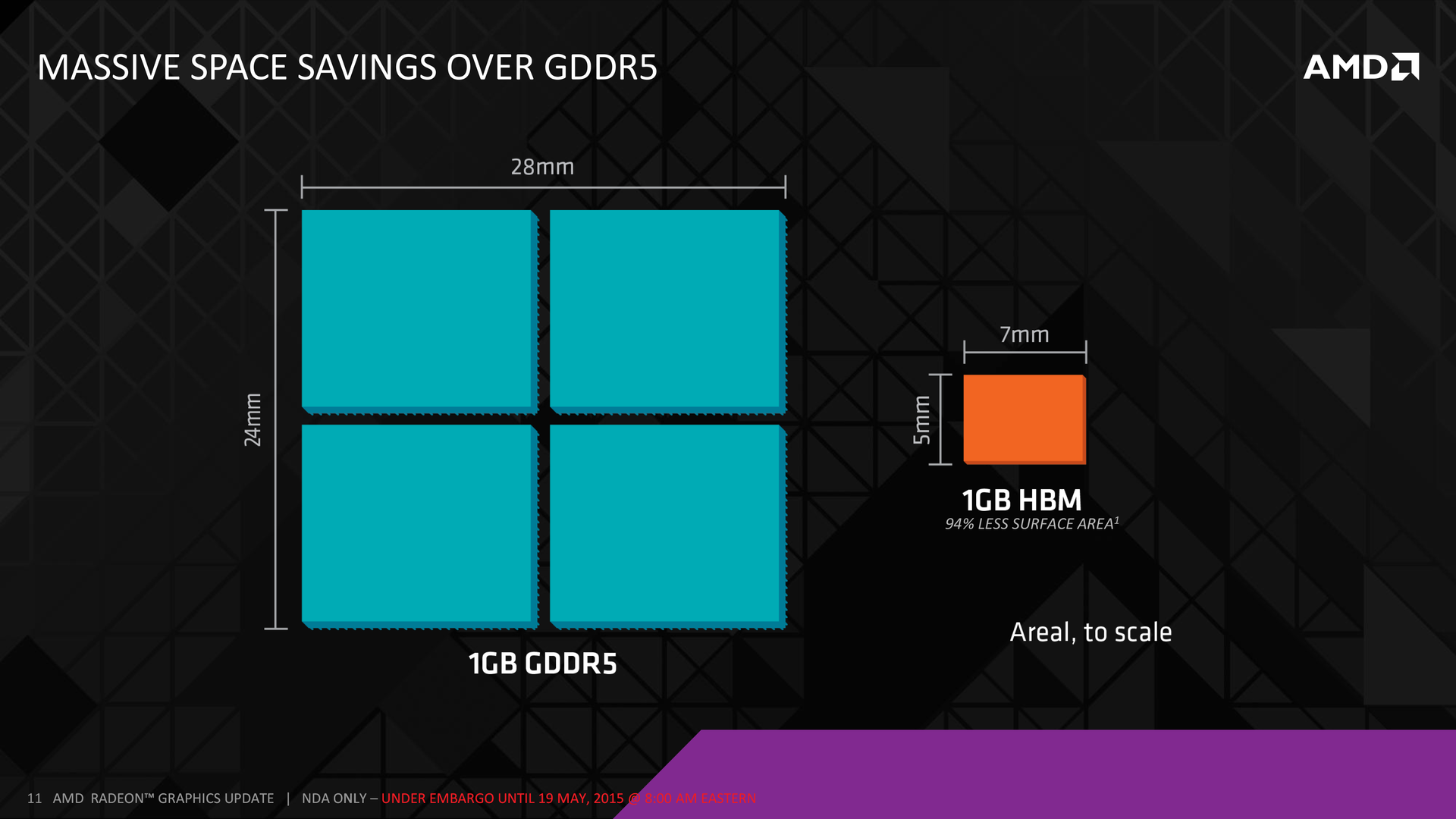
Память не только более энергоэффективная, она компактная. Гигабайт в HBM требует 35 мм?, а четыре чипа GDDR5 того же объёма занимают 672 мм? площади платы. Поэтому HBM позволит создавать более компактные устройства. Интерпозер организован очень эффективно, что позволяет сократить общий размер кристалла. Возможно даже улучшить поток данных внутри видеокарты. Суммарно потребуется примерно в два раза меньше площади платы, это упростит построение карт с двумя видеопроцессорами.

Память эпохи пост-GDDR изменит не только видеоускорители, но и APU. Большее количество каналов сулит меньшее время произвольного доступа. Упрощённая система клокинга и другие мелкие изменения означают потенциальное сокращение времени отклика. Макри ожидает, что HBM проникнет во многие области компьютерного рынка.
У первого поколения реализации HBM есть важный минус: общий размер памяти может достигать лишь 4 ГБ. Это немного, если вспомнить, что Titan X имеет в три раза больше, 12 ГБ памяти, а у текущего поколения R9 290X те же 4 ГБ. Даже флагманские пределы легко достичь при разрешении 4K. Но Макри уверяет, что AMD как-то справится с этим ограничением. По его мнению, видеокарты текущего поколения не слишком эффективно обращаются с памятью. Объёмы памяти быстро росли, поэтому в AMD до этого момента не сильно задумывались над их использованием.
У HBM есть и другие «детские» проблемы. К примеру, размер микросхем видеопроцессоров растёт, а интерпозер должен быть ещё крупнее, и стоимость его производства может достигать непозволительно высоких значений. Маленький размер HBM будет означать проблемы с охлаждением, которые уже были в некоторых ранних экземплярах R9 290X. По словам Макри, хотя иллюстрации говорят об обратном, стопки памяти имеют примерно ту же высоту, что и видеопроцессор, поэтому они увеличивают общую площадь отвода тепла. Наконец, новая технология должна окупиться, и для этого новые решения должны производиться и продаваться в больших объёмах.

Согласно утечкам, трёхсотая серия будет представлена 18 июня, а R9 390X покажут 24 июня. Утечки фотографий намекают на возможное жидкостное охлаждение.
Макри заявил, что уже сейчас разрабатывается вторая версия High Bandwidth Memory. Её пропускная способность в два раза выше, чем у первого поколения, а число слоёв памяти подскочит до восьми. За счёт использования нового техпроцесса объём возрастёт в четыре раза. Макри уверен, что когда-нибудь число слоёв памяти может вырасти до 16.
Впервые HBM появится в следующем поколении видеокарт AMD. Различные предположения о их будущих характеристиках дают некоторые возможные оценки.
| AMD Radeon R9 290X | Nvidia GeForce GTX Titan X | Будущий флагман — предположения СМИ | |
|---|---|---|---|
| Объём памяти | 4 ГБ | 12 ГБ | 4 ГБ |
| Пропускная способность на чип памяти | 5 Гбит/с | 7 Гбит/с | 1 Гбит/с |
| Количество чипов | 16 | 24 | 4 |
| Пропускная способность на чип | 20 ГБ/с | 14 ГБ/с | 128 ГБ/с |
| Шина памяти | 512-битная | 384-битная | 4096-битная |
| Общая пропускная способность | 320 ГБ/с | 336 ГБ/с | 512 ГБ/с |
| Оценочное потребление энергии памятью | 30 Вт | 31,5 Вт | 14,6 Вт |
По материалам Tech Report, ExtremeTech и AnandTech.
Комментарии (14)

Torvald3d
20.05.2015 15:31+3Хотелось бы увидеть подобную статью по будущей архитектуре Pascal у NVidia. Там вроде тоже какой то прорыв в сфере видеопамяти

Zeij
20.05.2015 17:50+2Согласно утечкам, трёхсотая серия будет представлена 18 июня, а R9 390X покажут 24 июня.
Наконец-то. Деньги уже карман жмут.

jar_ohty
20.05.2015 23:03Очень смущает огромный интерпозер, выход годных которого будет очень маленьким при такой площади, сравнимой уже не с традиционной микроэлектроникой, а с крупными сенсорами изображения.

a5b
21.05.2015 01:13+2Огромный пассивный интерпозер из проводов по отлаженному техпроцессу. Используются уже несколько лет (в очень дорогих продуктах, когда приходится собирать вместе несколько достаточно крупных чипов логики):
www.xilinx.com/innovation/research-labs/keynotes/3-D_Architectures.pdf
«Passive Silicon Interposer (65nm Generation… 65 nm Si Technology..): • 4 conventional metal layers connect micro bumps & TSVs • No transistors means low risk and no TSV induced performance degradation»
Есть вопросы по их тестированию, но производители обещают очень высокий выход годных:
www.evaluationengineering.com/articles/201202/addressing-interposer-and-tsv-quality-challenges.php
First, there is a big debate regarding whether passive interposers will need to be tested or whether the yield will be so high they won’t warrant testing. Second, what is necessary to adequately test a die that is 50-µm thick with 100,000 microbumps? Third, how will you power up and test a die that only has 2-µm diameter pads?..
As for interposers, Fleeman agreed with Strid at Cascade that there is a “huge concern in the industry over interposer yield.” However, Fleeman said, “Interposer suppliers plus tool providers like Applied Materials say the yield is virtually perfect” for the 65-nm three- or four-layer metal structures.
“Loss due to assembly or transport wouldn’t be caught in the interposer test anyway,” he continued. “For RDL [redistribution layer] and basic interposers, we don’t think there is a production [test] requirement. Line monitoring already is accomplished by very good picoamp DC testing and X-ray and optical inspection.
AMD о HBM — semiaccurate.com/2015/05/19/amd-finally-talks-hbm-memory
You can have either active or passive interposers, active have logic/transistors on them, passive have only metal layers. This is the long way of saying an active interposer is a very simple and large chip, a passive one skips the transistors and only prints metal layers aka wires. This again translates into active being fairly expensive and passive being very cheap. You can print as many metal layers as you want on an interposer but each layer dramatically ups the cost.
AMD went for passive interposers and did not say how many metal layers they used but SemiAccurate speculates they didn’t go above three if they even hit that many. They are made at UMC on an undisclosed process that was strongly hinted to be either a 40nm or 65nm process. In short it is on a very old and inexpensive process and has a very small number of steps at that. Interposers are dirt cheap per mm^2 of area compared to chips built on the same outdated process.

vvmk
Все новое — хорошо забытое старое?
Старые видеочипы такого формата были на редкость неудачные, те же 9000 по «бутербродной технологии» померли почти все, а которые с рядом стоящей памятью — многие живы до сих пор
vvmk
Nvidia тоже баловалась подобной технологией в мобильных чипах, так что запасаемся поп-кукурузой.

beeruser
Это обычные «однослойные» чипы, а не HBM.
Что до надёжности — такие чипы прекрасно работают в PS3.