
Однако в большинстве статистических тестов, используемых для проверки гипотез, (например, t-тест, регрессионный анализ, дисперсионный анализ) рядом с p-value всегда соседствует такой показатель как число степеней свободы, он же degrees of freedom или просто сокращенно df, о нем мы сегодня и поговорим.

Степени свободы, о чем речь?
По моему мнению, понятие степеней свободы в статистике примечательно тем, что оно одновременно является и одним из самым важных в прикладной статистике (нам необходимо знать df для расчета p-value в озвученных тестах), но вместе с тем и одним из самых сложных для понимания определений для студентов-нематематиков, изучающих статистику.
Давайте рассмотрим пример небольшого статистического исследования, чтобы понять, зачем нам нужен показатель df, и в чем же с ним такая проблема. Допустим, мы решили проверить гипотезу о том, что средний рост жителей Санкт-Петербурга равняется 170 сантиметрам. Для этих целей мы набрали выборку из 16 человек и получили следующие результаты: средний рост по выборке оказался равен 173 при стандартном отклонении равном 4. Для проверки нашей гипотезы можно использовать одновыборочный t-критерий Стьюдента, позволяющий оценить, как сильно выборочное среднее отклонилось от предполагаемого среднего в генеральной совокупности в единицах стандартной ошибки:
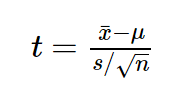
Проведем необходимые расчеты и получим, что значение t-критерия равняется 3, отлично, осталось рассчитать p-value и задача решена. Однако, ознакомившись с особенностями t-распределения мы выясним, что его форма различается в зависимости от числа степеней свобод, рассчитываемых по формуле n-1, где n — это число наблюдений в выборке:
Сама по себе формула для расчета df выглядит весьма дружелюбной, подставили число наблюдений, вычли единичку и ответ готов: осталось рассчитать значение p-value, которое в нашем случае равняется 0.004.
Но почему n минус один?
Когда я впервые в жизни на лекции по статистике столкнулся с этой процедурой, у меня как и у многих студентов возник законный вопрос: а почему мы вычитаем единицу? Почему мы не вычитаем двойку, например? И почему мы вообще должны что-то вычитать из числа наблюдений в нашей выборке?
В учебнике я прочитал следующее объяснение, которое еще не раз в дальнейшем встречал в качестве ответа на данный вопрос:
“Допустим мы знаем, чему равняется выборочное среднее, тогда нам необходимо знать только n-1 элементов выборки, чтобы безошибочно определить чему равняется оставшейся n элемент”. Звучит разумно, однако такое объяснение скорее описывает некоторый математический прием, чем объясняет зачем нам понадобилось его применять при расчете t-критерия. Следующее распространенное объяснение звучит следующим образом: число степеней свободы — это разность числа наблюдений и числа оцененных параметров. При использовании одновыборочного t-критерия мы оценили один параметр — среднее значение в генеральной совокупности, используя n элементов выборки, значит df = n-1.
Однако ни первое, ни второе объяснение так и не помогает понять, зачем же именно нам потребовалось вычитать число оцененных параметров из числа наблюдений?
Причем тут распределение Хи-квадрат Пирсона?
Давайте двинемся чуть дальше в поисках ответа. Сначала обратимся к определению t-распределения, очевидно, что все ответы скрыты именно в нем. Итак случайная величина:
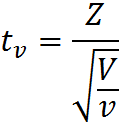
имеет t-распределение с df = ?, при условии, что Z – случайная величина со стандартным нормальным распределением N(0; 1), V – случайная величина с распределением Хи-квадрат, с ? числом степеней свобод, случайные величины Z и V независимы. Это уже серьезный шаг вперед, оказывается, за число степеней свободы ответственна случайная величина с распределением Хи-квадрат в знаменателе нашей формулы.
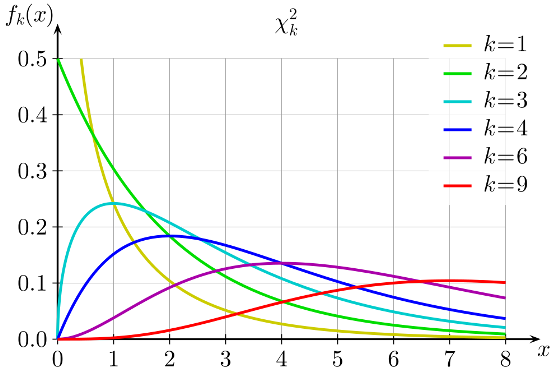
Давайте тогда изучим определение распределения Хи-квадрат. Распределение Хи-квадрат с k степенями свободы — это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Кажется, мы уже совсем у цели, по крайней мере, теперь мы точно знаем, что такое число степеней свободы у распределения Хи-квадрат — это просто число независимых случайных величин с нормальным стандартным распределением, которые мы суммируем. Но все еще остается неясным, на каком этапе и зачем нам потребовалось вычитать единицу из этого значения?
Давайте рассмотрим небольшой пример, который наглядно иллюстрирует данную необходимость. Допустим, мы очень любим принимать важные жизненные решения, основываясь на результате подбрасывания монетки. Однако, последнее время, мы заподозрили нашу монетку в том, что у нее слишком часто выпадает орел. Чтобы попытаться отклонить гипотезу о том, что наша монетка на самом деле является честной, мы зафиксировали результаты 100 бросков и получили следующий результат: 60 раз выпал орел и только 40 раз выпала решка. Достаточно ли у нас оснований отклонить гипотезу о том, что монетка честная? В этом нам и поможет распределение Хи-квадрат Пирсона. Ведь если бы монетка была по настоящему честной, то ожидаемые, теоретические частоты выпадания орла и решки были бы одинаковыми, то есть 50 и 50. Легко рассчитать насколько сильно наблюдаемые частоты отклоняются от ожидаемых. Для этого рассчитаем расстояние Хи-квадрат Пирсона по, я думаю, знакомой большинству читателей формуле:
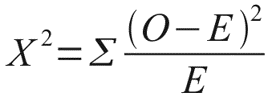
Где O — наблюдаемые, E — ожидаемые частоты.
Дело в том, что если верна нулевая гипотеза, то при многократном повторении нашего эксперимента распределение разности наблюдаемых и ожидаемых частот, деленная на корень из наблюдаемой частоты, может быть описано при помощи нормального стандартного распределения, а сумма квадратов k таких случайных нормальных величин это и будет по определению случайная величина, имеющая распределение Хи-квадрат.
Давайте проиллюстрируем этот тезис графически, допустим у нас есть две случайные, независимые величины, имеющих стандартное нормальное распределение. Тогда их совместное распределение будет выглядеть следующим образом:
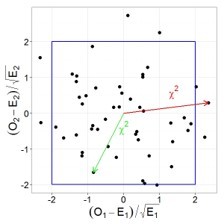
При этом квадрат расстояния от нуля до каждой точки это и будет случайная величина, имеющая распределение Хи-квадрат с двумя степенями свободы. Вспомнив теорему Пифагора, легко убедиться, что данное расстояние и есть сумма квадратов значений обеих величин.
Пришло время вычесть единичку!
Ну а теперь кульминация нашего повествования. Возвращаемся к нашей формуле расчета расстояния Хи-квадрат для проверки честности монетки, подставим имеющиеся данные в формулу и получим, что расстояние Хи-квадрат Пирсона равняется 4. Однако для определения p-value нам необходимо знать число степеней свободы, ведь форма распределения Хи-квадрат зависит от этого параметра, соответственно и критическое значение также будет различаться в зависимости от этого параметра.
Теперь самое интересное. Предположим, что мы решили многократно повторять 100 бросков, и каждый раз мы записывали наблюдаемые частоты орлов и решек, рассчитывали требуемые показатели (разность наблюдаемых и ожидаемых частот, деленная на корень из ожидаемой частоты) и как и в предыдущем примере наносили их на график.
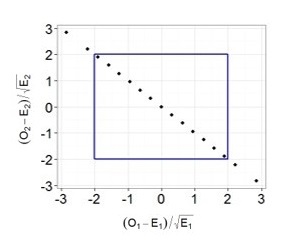
Легко заметить, что теперь все точки выстраиваются в одну линию. Все дело в том, что в случае с монеткой наши слагаемые не являются независимыми, зная общее число бросков и число решек, мы всегда можем точно определить выпавшее число орлов и наоборот, поэтому мы не можем сказать, что два наших слагаемых — это две независимые случайные величины. Также вы можете убедиться, что все точки действительно всегда будут лежать на одной прямой: если у нас выпало 30 орлов, значит решек было 70, если орлов 70, то решек 30 и т.д. Таким образом, несмотря на то, что в нашей формуле было два слагаемых, для расчета p-value мы будем использовать распределение Хи-квадрат с одной степенью свободы! Вот мы наконец-то добрались до момента, когда нам потребовалось вычесть единицу. Если бы мы проверяли гипотезу о том, что наша игральная кость с шестью гранями является честной, то мы бы использовали распределение Хи-квадрат с 5 степенями свободы. Ведь зная общее число бросков и наблюдаемые частоты выпадения любых пяти граней, мы всегда можем точно определить, чему равняется число выпадений шестой грани.
Все становится на свои места
Теперь, вооружившись этими знаниями, вернемся к t-тесту:
в знаменателе у нас находится стандартная ошибка, которая представляет собой выборочное стандартное отклонение, делённое на корень из объёма выборки. В расчет стандартного отклонения входит сумма квадратов отклонений наблюдаемых значений от их среднего значения — то есть сумма нескольких случайных положительных величин. А мы уже знаем, что сумма квадратов n случайных величин может быть описана при помощи распределения хи-квадрат. Однако, несмотря на то, что у нас n слагаемых, у данного распределения будет n-1 степень свободы, так как зная выборочное среднее и n-1 элементов выборки, мы всегда можем точно задать последний элемент (отсюда и берется это объяснение про среднее и n-1 элементов необходимых для однозначного определения n элемента)! Получается, в знаменателе t-статистики у нас спрятано распределение хи-квадрат c n-1 степенями свободы, которое используется для описания распределения выборочного стандартного отклонения! Таким образом, степени свободы в t-распределении на самом деле берутся из распределения хи-квадрат, которое спрятано в формуле t-статистики. Кстати, важно отметить, что все приведенные выше рассуждения справедливы, если исследуемый признак имеет нормальное распределение в генеральной совокупности (или размер выборки достаточно велик), и если бы у нас действительно стояла цель проверить гипотезу о среднем значении роста в популяции, возможно, было бы разумнее использовать непараметрический критерий.
Схожая логика расчета числа степеней свободы сохраняется и при работе с другими тестами, например, в регрессионном или дисперсионном анализе, все дело в случайных величинах с распределением Хи-квадрат, которые присутствуют в формулах для расчета соответствующих критериев.
Таким образом, чтобы правильно интерпретировать результаты статистических исследований и разбираться, откуда возникают все показатели, которые мы получаем при использовании даже такого простого критерия как одновыборочный t-тест, любому исследователю необходимо хорошо понимать, какие математические идеи лежат в основании статистических методов.
Онлайн курсы по статистике: объясняем сложные темы простым языком
Основываясь на опыте преподавания статистики в Институте биоинформатики , у нас возникла идея создать серию онлайн курсов, посвященных анализу данных, в которых в доступной для каждого форме будут объясняться наиболее важные темы, понимание которых необходимо для уверенного использования методов статистики при решении различного рода задача. В 2015 году мы запустили курс Основы статистики, на который к сегодняшнему дню записалось около 17 тысяч человек, три тысячи слушателей уже получили сертификат о его успешном завершении, а сам курс был награждён премией EdCrunch Awards и признан лучшим техническим курсом. В этом году на платформе stepik.org стартовало продолжение курса Основы статистики. Часть два, в котором мы продолжаем знакомство с основными методами статистики и разбираем наиболее сложные теоретические вопросы. Кстати, одной из главных тем курса является роль распределения Хи — квадрат Пирсона при проверке статистических гипотез. Так что если у вас все еще остались вопросы о том, зачем мы вычитаем единицу из общего числа наблюдений, ждем вас на курсе!
Стоит также отметить, что теоретические знания в области статистики будут определенно полезны не только тем, кто применяет статистику в академических целях, но и для тех, кто использует анализ данных в прикладных областях. Базовые знания в области статистики просто необходимы для освоения более сложных методов и подходов, которые используются в области машинного обучения и Data Mining. Таким образом, успешное прохождение наших курсов по введению в статистику — хороший старт в области анализа данных. Ну а если вы всерьез задумались о приобретении навыков работы с данными, думаем, вас может заинтересовать наша онлайн — программа по анализу данных, о которой мы подробнее писали здесь. Упомянутые курсы по статистике являются частью этой программы и позволят вам плавно погрузиться в мир статистики и машинного обучения. Однако пройти эти курсы без дедлайнов могут все желающие и вне контекста программы по анализу данных.
Комментарии (18)

asl
30.09.2016 01:23Никакой «магии» в степенях свободы нет, и никакого физического смысла это название не несет. Просто такое название, ага.
Ну и использовать t-критерий для проверки гипотезы о росте нельзя, т.к. ключевое предположение t-критерия о том, что у нас выборка из нормального распределения, не выполняется. Поэтому вероятность ошибки первого рода такого критерия будет отличаться от заданного уровня значимости, мощность будет непонятно какой, а полученным p-значениями верить нельзя. Разница будет особенно заметна на малых объемах выборки, ага.
Anatoliy_Karpov
30.09.2016 01:47Да, согласен конечно, если подходить к задаче с ростом серьезно разумеется и выборка нужна больше и проверка допущений теста, тут просто для пример привел эту задачу.
kxx
30.09.2016 14:31А по какому закону распределен рост человека? В медикобиологических исследованиях часто по умолчанию подразумевают нормальное распределение (я не утверждаю, что это правильно). Даже тот же же Гланц любит приводить примеры с ростом.
Другой аспект связан с тем, что на практике t-критерий весьма робастен, и его все же используют даже со слегка асимметричными распределениями.asl
30.09.2016 14:50Подразумевать можно все, что угодно. Весь вопрос в том, можем ли мы предъявить вероятность нашей ошибки (и ошибочных выводов) при подобного рода заблуждениях. Если можем, то все хорошо, если нет… то вылезают всевозможного рода эффекты.
t-критерий как раз очень сильно «неробастен». При маленьких объемах выборки и толстых хвостах / несимметричных распределениях распределение нулевой гипотезы может очень сильно отличаться от распределения Стьюдента. Ну и говорить о «робастности» применительно к критерию с простой гипотезой как-то вообще странно. Он был бы «робастным», если бы сохранял вероятность ошибки первого рода при отклонении распределения от нормального. А это не так. Применения на практике обычно обосновываются тем, что «ну давайте получим доверительные интервалы пошире», естественно сильно проигрывая в мощности за счет занижения вероятности ошибки первого рода критерия.
Все начинает быть не так грустно, когда объем выборки становится сколько-нибудь нетривиальным (say, n > 50), и тогда в силу ЦПТ критерий становится асимптотическим (возможно, именно это Анатолий и имел в виду под неизвестным мне «z-распределением» выше, которое там на самом деле стандартное нормально).
И как бы на самом деле нас не интересует распределение роста. Нас интересует гипотеза относительно значения среднего. Зачем нам тогда точный критерий с дополнительными (сильными) предположениями? Может быть лучше рассмотреть выборку побольше, взять асимптотический критерий и получить то, что надо. Если же у нас только 10 человек, то надо правильно выбирать инструмент — можно, например, попробовать непараметрические тесты (правда, тогда гипотеза будет о медиане) или же воспользоваться перестановочным критерием и вычислить распределение статистики критерия явно.

zolkko
30.09.2016 15:34Некоторое время назад на реддите встретил такое обяснение почему n-1
"In statistical terms the degrees of freedom relate to the number of observations that are free to vary. If we take a sample of four observations from a population, then these four scores are free to vary in any way (they can be any value). However, if we then use this sample of four observations to calculate the mean squared error in the population, we have to use the mean of the sample as an estimate of the populations mean. Thus we hold one parameter constant. Say that the mean of the sample was 10; then we assume that the population mean is 10 also and we keep this value constant. With this parameter fixed, can all four score from our sample vary? The answer is no, because to ensure that the population mean is 10 only three values are free to vary. For example, if the values in the sample were 8, 9, 11, 12 (mean = 10) and we changed three of these values to 7, 15, and 8, then the final value must be 10 so that the mean is also 10. Therefore, if we hold one parameter constant then the degrees of freedom must be one less than the number of scores used to calculate that parameter. This fact explains why when we use a sample to estimate the mean squared error (or indeed the standard deviation) of a population, we divide the sums of squares by N — 1 rather than N alone" --Andy Field, Discovering Statistics Using IBM SPSS Statistics
Anatoliy_Karpov
30.09.2016 15:42This fact explains why when we use a sample to estimate the mean squared error (or indeed the standard deviation) of a population, we divide the sums of squares by N — 1 rather than N alone" --Andy Field, Discovering Statistics Using IBM SPSS Statistics
Это довольно странно, N — 1 в выборочном стандартном отклонении возникает в результате нашей борьбы со смещенностью.
GeMir
Очень много опечаток: тире вместо дефисов, «статика» вместо «статистики» и так далее. Утверждение «если эти случайные величины не являются независимыми» — не верно. Случайные величины как раз должны быть iid (independent and identically distributed) — независимыми и имеющими одинаковое распределение. Увы, не знаком с русскоязычной терминологией.
Anatoliy_Karpov
ну да, но в случае с монеткой или выборкой в t — тесте, это требование как и раз не выполняется.
GeMir
Броски идеальной «честной» монетки независимы в используемой модели. Кстати, для подобных случаев (два возможных исхода) существуют биномиальные тесты. t-тест используется для проверки гипотез относительно среднего значения при наличии iid случайных величин имеющих нормальное распределение с неизвестной дисперсией.
Anatoliy_Karpov
не независимыми являются рассчитанные отклонения от ожидаемых частот для орла и решки
GeMir
Гипотезу, что монетка честная вы тестом проверить не можете, поэтому вы будете пытаться найти статистическое подтверждение тому, что она не честная («орёл» выпадает с вероятностью, отличной от 0,5) и в случае не отклонения нулевой гипотезы тестом станете считать, что у вас нет данных, подтверждающих нечестность монеты (что вовсе не равнозначно с её «честностью»). Так что же вам мешает взять точный биномиальный тест, который оптимально подходит для описываемой ситуации (100 iid бросков — это совершенно точно не «достаточно большое» количество) и что вы хотите сказать утверждением о «зависимости расчитанных отклонений» (языковой барьер, извиняюсь)?
Anatoliy_Karpov
Тут Вы конечно же правы, искать будем подтверждение именно альтернативной гипотезе! Собственно ничего не мешает, но это же пост не про оптимальный критерий работы с нечестными монетками, просто взял ее для примера, т.к. на двух исходах можно наглядно показать, почему несмотря на два слагаемых в формуле критерия мы используем распределение Хи — квадрат с df = 1.
GeMir
t-распределение Студента, если мне не изменяет память, по определению, распределение частного, в котором в числителе величина, имеющая стандартное нормальное распределение а в знаменателе — квадратный корень из величины, имеющей хи-квадрат-распределение с n степенями свободы, поделённой на число степеней свободы. В модели с нормальным распределением с неизвестным стандартным отклонением мы используем несмещённую (unbiased) оценку (да простят меня за TeX) $\hat{\sigma} = \sqrt{\frac{1}{n-1}\sum_{i=0}^{n}{\big(X_i-\overline{X}\big)^2}}$ (версия, в которой n вместо n-1 — не является не смещённой) потому и она имеет t-распределение с n-1 степеней свободы. Могу ошибаться, но по-моему, так.
Anatoliy_Karpov
Хорошее замечание! Действительно в знаменателе стоит выборочная sd, распределение которой может быть описано:

Но в процессе доказательства этого факта, мы сталкиваемся с n слагаемыми — для каждого наблюдения в выборке мы рассчитываем его квадрат отклонения от выборочного среднего. Но распределение этой суммы n слагаемых мы опишем распределение хи — квадрат с n — 1 степенью свободы.
asl
Это верно только для выборки из нормального распределения. И если у нас выборка из нормального распределения, то можно показать, что выборочное среднее и выборочная дисперсия будут независимыми, а выборочная дисперсия будет иметь \chi^2 распределение с n-1 степенью свободы.
asl
И, кстати, ровно поэтому формула (\bar(x) — \mu) / sd / \sqrt(n) выше не верна. Т.к. нам нужно или же чтобы тут было не обычное стандартное отклонение, а корень из несмещенной оценки дисперсии («подправленное стандартное отклонение»), или же sqrt(n-1).
Anatoliy_Karpov
Да, конечно, должна быть выборочная оценка.
Anatoliy_Karpov
Я собственно в тексте об этом и говорю, просто неудачное обозначение ввел, подправил.