
В этой публикации я хотел рассказать об интересной, но незаслуженно мало описанной на Хабре, системе управления контейнерами Kubernetes.

Kubernetes является проектом с открытым исходным кодом, предназначенным для управления кластером контейнеров Linux как единой системой. Kubernetes управляет и запускает контейнеры Docker на большом количестве хостов, а так же обеспечивает совместное размещение и репликацию большого количества контейнеров. Проект был начат Google и теперь поддерживается многими компаниями, среди которых Microsoft, RedHat, IBM и Docker.
Компания Google пользуется контейнерной технологией уже более десяти лет. Она начинала с запуска более 2 млрд контейнеров в течение одной недели. С помощью проекта Kubernetes компания делится своим опытом создания открытой платформы, предназначенной для масштабируемого запуска контейнеров.
Проект преследует две цели. Если вы пользуетесь контейнерами Docker, возникает следующий вопрос о том, как масштабировать и запускать контейнеры сразу на большом количестве хостов Docker, а также как выполнять их балансировку. В проекте предлагается высокоуровневый API, определяющее логическое группирование контейнеров, позволяющее определять пулы контейнеров, балансировать нагрузку, а также задавать их размещение.
Nodes (node.md): Нода это машина в кластере Kubernetes.
Pods (pods.md): Pod это группа контейнеров с общими разделами, запускаемых как единое целое.
Replication Controllers (replication-controller.md): replication controller гарантирует, что определенное количество «реплик» pod'ы будут запущены в любой момент времени.
Services (services.md): Сервис в Kubernetes это абстракция которая определяет логический объединённый набор pod и политику доступа к ним.
Volumes (volumes.md): Volume(раздел) это директория, возможно, с данными в ней, которая доступна в контейнере.
Labels (labels.md): Label'ы это пары ключ/значение которые прикрепляются к объектам, например pod'ам. Label'ы могут быть использованы для создания и выбора наборов объектов.
Kubectl Command Line Interface (kubectl.md): kubectl интерфейс командной строки для управления Kubernetes.
Работающий кластер Kubernetes включает в себя агента, запущенного на нодах (kubelet) и компоненты мастера (APIs, scheduler, etc), поверх решения с распределённым хранилищем. Приведённая схема показывает желаемое, в конечном итоге, состояние, хотя все ещё ведётся работа над некоторыми вещами, например: как сделать так, чтобы kubelet (все компоненты, на самом деле) самостоятельно запускался в контейнере, что сделает планировщик на 100% подключаемым.
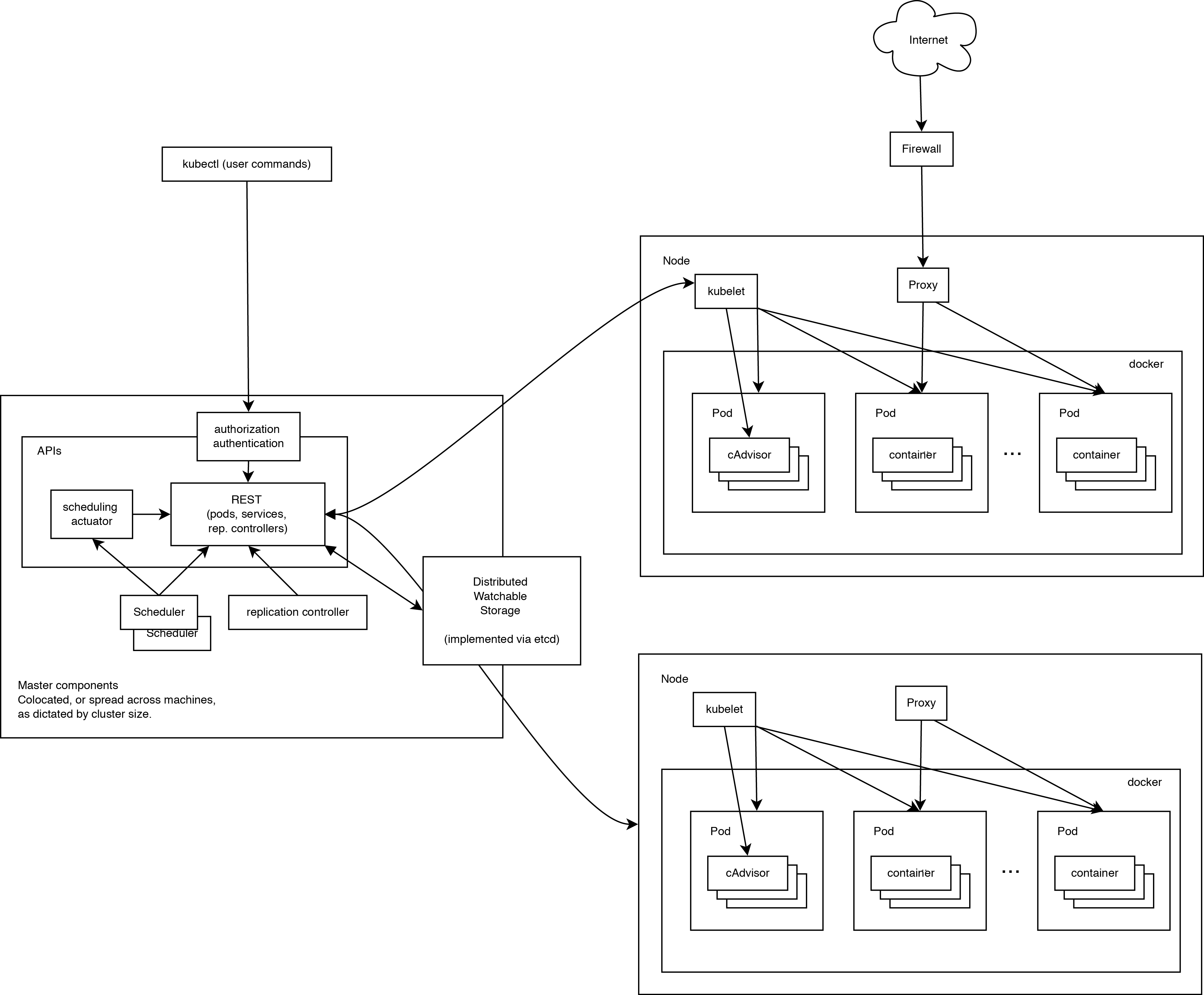
При взгляде на архитектуру системы мы можем разбить его на сервисы, которые работают на каждой ноде и сервисы уровня управления кластера. На каждой ноде Kubernetes запускаются сервисы, необходимые для управления нодой со стороны мастера и для запуска приложений. Конечно, на каждой ноде запускается Docker. Docker обеспечивает загрузку образов и запуск контейнеров.
Kubelet управляет pod'ами их контейнерами, образами, разделами, etc.
Также на каждой ноде запускается простой proxy-балансировщик. Этот сервис запускается на каждой ноде и настраивается в Kubernetes API. Kube-Proxy может выполнять простейшее перенаправление потоков TCP и UDP (round robin) между набором бэкендов.
Система управления Kubernetes разделена на несколько компонентов. В данный момент все они запускаются на мастер-ноде, но в скором времени это будет изменено для возможности создания отказоустойчивого кластера. Эти компоненты работают вместе, чтобы обеспечить единое представление кластера.
Состояние мастера хранится в экземпляре etcd. Это обеспечивает надёжное хранение конфигурационных данных и своевременное оповещение прочих компонентов об изменении состояния.
Kubernetes API обеспечивает работу api-сервера. Он предназначен для того, чтобы быть CRUD сервером со встроенной бизнес-логикой, реализованной в отдельных компонентах или в плагинах. Он, в основном, обрабатывает REST операции, проверяя их и обновляя соответствующие объекты в etcd (и событийно в других хранилищах).
Scheduler привязывает незапущенные pod'ы к нодам через вызов /binding API. Scheduler подключаем; планируется поддержка множественных scheduler'ов и пользовательских scheduler'ов.
Все остальные функции уровня кластера представлены в Controller Manager. Например, ноды обнаруживаются, управляются и контролируются средствами node controller. Эта сущность в итоге может быть разделена на отдельные компоненты, чтобы сделать их независимо подключаемыми.
ReplicationController — это механизм, основывающийся на pod API. В конечном счете планируется перевести её на общий механизм plug-in, когда он будет реализован.
В качестве платформы для примера настройки была выбрана Ubuntu-server 14.10 как наиболее простая для примера и, в то же время, позволяющая продемонстрировать основные параметры настройки кластера.
Для создания тестового кластера будут использованы три машины для создания нод и отдельная машина для проведения удалённой установки. Можно не выделять отдельную машину и производить установку с одной из нод.
Список используемых машин:
Установку Docker можно произвести по статье в официальных источниках:
Дополнительная настройка Docker после установки не нужна, т.к. будет произведена скриптом установки Kubernetes.
Установка bridge-utils:
Выполняем на машине, с которой будет запущен скрипт установки.
Если ключи ещё не созданы, создаём их:
Копируем ключи на удалённые машины, предварительно убедившись в наличии на них необходимого пользователя, в нашем случае core.
Далее мы займёмся установкой непосредственно Kubernetes. Для этого в первую очередь скачаем и распакуем последний доступный релиз с GitHub:
Настройка Kubernetes через стандартные скрипты примеров полностью производится перед установкой производится через конфигурационные файлы. При установке мы будем использовать скрипты папке ./cluster/ubuntu/.
В первую очередь изменим скрипт ./cluster/ubuntu/build.sh который скачивает и подготавливает необходимые для установки бинарники Kubernetes, etcd и flannel:
Для того, чтобы использовать последний, на момент написания статьи, релиз 0.17.0 необходимо заменить:
На:
И запустим:
Далее указываем параметры будущего кластера, для чего редактируем файл ./config-default.sh:
На этом настройка заканчивается и можно переходить к установке.
Первым делом необходимо сообщить системе про наш ssh-agent и используемый ssh-ключ для этого выполняем:
Далее переходим непосредственно к установке. Для этого используется скрипт ./kubernetes/cluster/kube-up.sh которому необходимо указать, что мы используем ubuntu.
В процессе установки скрипт потребует пароль sudo для каждой ноды. По окончанию установки проверит состояние кластера и выведет список нод и адреса Kubernetes api.
Посмотрим, какие ноды и сервисы присутствуют в новом кластере:
Видим список из установленных нод в состоянии Ready и два предустановленных сервиса kubernetes и kubernetes-ro — это прокси для непосредственного доступа к Kubernetes API. Как и к любому сервису Kubernetes к kubernetes и kubernetes-ro можно обратиться непосредственно по IP адресу с любой из нод.
Для запуска сервиса необходимо подготовить docker контейнер, на основе которого будет создан сервис. Дабы не усложнять, в примере будет использован общедоступный контейнер nginx. Обязательными составляющими сервиса являются Replication Controller, обеспечивающий запущенность необходимого набора контейнеров (точнее pod) и service, который определяет, на каких IP адресе и портах будет слушать сервис и правила распределения запросов между pod'ами.
Любой сервис можно запустить 2-я способами: вручную и с помощью конфиг-файла. Рассмотрим оба.
Начнём с создания Replication Controller'а:
Где:
Посмотрим, что у нас получилось:
Был создан Replication Controller с именем nginx и количеством реплик равным 6. Реплики в произвольном порядке запущены на нодах, местоположения каждой pod'ы указано в столбце HOST.
Вывод может отличаться от приведённого в некоторых случаях, например:
Далее создаём service который будет использовать наш Replication Controller как бекенд.
Для http:
И для https:
Где:
Проверяем результат:
Для проверки запущенности можно зайти на любую из нод и выполнить в консоли:
В выводе curl увидим стандартную приветственную страницу nginx. Готово, сервис запущен и доступен.
Для этого способа запуска необходимо создать конфиги для Replication Controller'а и service'а. Kubernetes принимает конфиги в форматах yaml и json. Мне ближе yaml поэтому будем использовать его.
Предварительно очистим наш кластер от предыдущего эксперимента:
nginx_rc.yaml
Применяем конфиг:
Проверяем результат:
Был создан Replication Controller с именем nginx и количеством реплик равным 6. Реплики в произвольном порядке запущены на нодах, местоположения каждой pod'ы указано в столбце HOST.
nginx_service.yaml
Можно заметить, что при использовании конфига за одним сервисом могут быть закреплены несколько портов.
Применяем конфиг:
Проверяем результат:
Для проверки запущенности можно зайти на любую из нод и выполнить в консоли:
В выводе curl увидим стандартную приветственную страницу nginx.
В качестве заключения хочу описать пару важных моментов, о которые уже пришлось запнуться при проектировании системы. Связаны они были с работой kube-proxy, того самого модуля, который позволяет превратить разрозненный набор элементов в сервис.
PORTAL_NET. Сущность сама по себе интересная, предлагаю ознакомиться с тем, как же это реализовано.
Недолгие раскопки привели меня к осознанию простой, но эффективной модели, заглянем в вывод iptables-save:
Все запросы к IP-адресу сервиса попавшие в iptables заворачиваются на порт на котором слушает kube-proxy. В связи с этим возникает одна проблема: Kubernetes, сам по себе, не решает проблему связи с пользователем. Поэтому придётся решать этот вопрос внешними средствами, например:
SOURCE IP Так же. при настройке сервиса nginx мне пришлось столкнуться с интересной проблемой. Она выглядела как строчка в мануале: «Using the kube-proxy obscures the source-IP of a packet accessing a Service». Дословно — при использовании kube-proxy скрывает адрес источника пакета, а это значит, что всю обработку построенную на основе source-IP придётся проводить до использования kube-proxy.
На этом всё, спасибо за внимание
К сожалению, всю информацию, которую хочется передать, не получается уместить в одну статью.
UPD. В связи с получением инвайта хотел спросить, что вы хотите увидеть в следующих статьях?
Что такое Kubernetes?
Kubernetes является проектом с открытым исходным кодом, предназначенным для управления кластером контейнеров Linux как единой системой. Kubernetes управляет и запускает контейнеры Docker на большом количестве хостов, а так же обеспечивает совместное размещение и репликацию большого количества контейнеров. Проект был начат Google и теперь поддерживается многими компаниями, среди которых Microsoft, RedHat, IBM и Docker.
Компания Google пользуется контейнерной технологией уже более десяти лет. Она начинала с запуска более 2 млрд контейнеров в течение одной недели. С помощью проекта Kubernetes компания делится своим опытом создания открытой платформы, предназначенной для масштабируемого запуска контейнеров.
Проект преследует две цели. Если вы пользуетесь контейнерами Docker, возникает следующий вопрос о том, как масштабировать и запускать контейнеры сразу на большом количестве хостов Docker, а также как выполнять их балансировку. В проекте предлагается высокоуровневый API, определяющее логическое группирование контейнеров, позволяющее определять пулы контейнеров, балансировать нагрузку, а также задавать их размещение.
Концепции Kubernetes
Nodes (node.md): Нода это машина в кластере Kubernetes.
Pods (pods.md): Pod это группа контейнеров с общими разделами, запускаемых как единое целое.
Replication Controllers (replication-controller.md): replication controller гарантирует, что определенное количество «реплик» pod'ы будут запущены в любой момент времени.
Services (services.md): Сервис в Kubernetes это абстракция которая определяет логический объединённый набор pod и политику доступа к ним.
Volumes (volumes.md): Volume(раздел) это директория, возможно, с данными в ней, которая доступна в контейнере.
Labels (labels.md): Label'ы это пары ключ/значение которые прикрепляются к объектам, например pod'ам. Label'ы могут быть использованы для создания и выбора наборов объектов.
Kubectl Command Line Interface (kubectl.md): kubectl интерфейс командной строки для управления Kubernetes.
Архитектура Kubernetes
Работающий кластер Kubernetes включает в себя агента, запущенного на нодах (kubelet) и компоненты мастера (APIs, scheduler, etc), поверх решения с распределённым хранилищем. Приведённая схема показывает желаемое, в конечном итоге, состояние, хотя все ещё ведётся работа над некоторыми вещами, например: как сделать так, чтобы kubelet (все компоненты, на самом деле) самостоятельно запускался в контейнере, что сделает планировщик на 100% подключаемым.
Нода Kubernetes
При взгляде на архитектуру системы мы можем разбить его на сервисы, которые работают на каждой ноде и сервисы уровня управления кластера. На каждой ноде Kubernetes запускаются сервисы, необходимые для управления нодой со стороны мастера и для запуска приложений. Конечно, на каждой ноде запускается Docker. Docker обеспечивает загрузку образов и запуск контейнеров.
Kubelet
Kubelet управляет pod'ами их контейнерами, образами, разделами, etc.
Kube-Proxy
Также на каждой ноде запускается простой proxy-балансировщик. Этот сервис запускается на каждой ноде и настраивается в Kubernetes API. Kube-Proxy может выполнять простейшее перенаправление потоков TCP и UDP (round robin) между набором бэкендов.
Компоненты управления Kubernetes
Система управления Kubernetes разделена на несколько компонентов. В данный момент все они запускаются на мастер-ноде, но в скором времени это будет изменено для возможности создания отказоустойчивого кластера. Эти компоненты работают вместе, чтобы обеспечить единое представление кластера.
etcd
Состояние мастера хранится в экземпляре etcd. Это обеспечивает надёжное хранение конфигурационных данных и своевременное оповещение прочих компонентов об изменении состояния.
Kubernetes API Server
Kubernetes API обеспечивает работу api-сервера. Он предназначен для того, чтобы быть CRUD сервером со встроенной бизнес-логикой, реализованной в отдельных компонентах или в плагинах. Он, в основном, обрабатывает REST операции, проверяя их и обновляя соответствующие объекты в etcd (и событийно в других хранилищах).
Scheduler
Scheduler привязывает незапущенные pod'ы к нодам через вызов /binding API. Scheduler подключаем; планируется поддержка множественных scheduler'ов и пользовательских scheduler'ов.
Kubernetes Controller Manager Server
Все остальные функции уровня кластера представлены в Controller Manager. Например, ноды обнаруживаются, управляются и контролируются средствами node controller. Эта сущность в итоге может быть разделена на отдельные компоненты, чтобы сделать их независимо подключаемыми.
ReplicationController — это механизм, основывающийся на pod API. В конечном счете планируется перевести её на общий механизм plug-in, когда он будет реализован.
Пример настройки кластера
В качестве платформы для примера настройки была выбрана Ubuntu-server 14.10 как наиболее простая для примера и, в то же время, позволяющая продемонстрировать основные параметры настройки кластера.
Для создания тестового кластера будут использованы три машины для создания нод и отдельная машина для проведения удалённой установки. Можно не выделять отдельную машину и производить установку с одной из нод.
Список используемых машин:
- Conf
- Node1: 192.168.0.10 — master, minion
- Node2: 192.168.0.11 — minion
- Node3: 192.168.0.12 — minion
Подготовка нод
Требования для запуска:
- На всех нодах установлен docker версии 1.2+ и bridge-utils
- Все машины связаны друг с другом, необходимости в доступе к интернету нет (в этом случае необходимо использовать локальный docker registry)
- На все ноды можно войти без ввода логина/пароля, с использованием ssh-ключей
Установка ПО на ноды
Установку Docker можно произвести по статье в официальных источниках:
node% sudo apt-get update $ sudo apt-get install wget
node% wget -qO- https://get.docker.com/ | sh
Дополнительная настройка Docker после установки не нужна, т.к. будет произведена скриптом установки Kubernetes.
Установка bridge-utils:
node% sudo apt-get install bridge-utils
Добавление ssh-ключей
Выполняем на машине, с которой будет запущен скрипт установки.
Если ключи ещё не созданы, создаём их:
conf% ssh-keygen
Копируем ключи на удалённые машины, предварительно убедившись в наличии на них необходимого пользователя, в нашем случае core.
conf% ssh-copy-id core@192.168.0.10
conf% ssh-copy-id core@192.168.0.11
conf% ssh-copy-id core@192.168.0.12
Установка Kubernetes
Далее мы займёмся установкой непосредственно Kubernetes. Для этого в первую очередь скачаем и распакуем последний доступный релиз с GitHub:
conf% wget https://github.com/GoogleCloudPlatform/kubernetes/releases/download/v0.17.0/kubernetes.tar.gz
conf% tar xzf ./kubernetes.tar.gz
conf% cd ./kubernetes
Настройка
Настройка Kubernetes через стандартные скрипты примеров полностью производится перед установкой производится через конфигурационные файлы. При установке мы будем использовать скрипты папке ./cluster/ubuntu/.
В первую очередь изменим скрипт ./cluster/ubuntu/build.sh который скачивает и подготавливает необходимые для установки бинарники Kubernetes, etcd и flannel:
conf% vim ./cluster/ubuntu/build.sh
Для того, чтобы использовать последний, на момент написания статьи, релиз 0.17.0 необходимо заменить:
# k8s
echo "Download kubernetes release ..."
K8S_VERSION="v0.15.0"
На:
# k8s
echo "Download kubernetes release ..."
K8S_VERSION="v0.17.0"
И запустим:
conf% cd ./cluster/ubuntu/
conf% ./build.sh #Данный скрипт важно запускать именно из той папки, где он лежит.
Далее указываем параметры будущего кластера, для чего редактируем файл ./config-default.sh:
## Contains configuration values for the Ubuntu cluster
# В данном пункте необходимо указать все ноды будущего кластера, MASTER-нода указывается первой
# Ноды указываются в формате <user_1@ip_1> <user_2@ip_2> <user_3@ip_3> разделитель - пробел
# В качестве пользователя указывается тот пользователь для которого по нодам разложены ssh-ключи
export nodes="core@192.168.0.10 core@192.168.0.10 core@192.168.0.10"
# Определяем роли нод : a(master) или i(minion) или ai(master и minion), указывается в том же порядке, что и ноды в списке выше.
export roles=("ai" "i" "i")
# Определяем количество миньонов
export NUM_MINIONS=${NUM_MINIONS:-3}
# Определяем IP-подсеть из которой, в последствии будут выделяться адреса для сервисов.
# Выделять необходимо серую подсеть, которая не будет пересекаться с имеющимися, т.к. эти адреса будут существовать только в пределах каждой ноды.
#Перенаправление на IP-адреса сервисов производится локальным iptables каждой ноды.
export PORTAL_NET=192.168.3.0/24
#Определяем подсеть из которой будут выделяться подсети для создания внутренней сети flannel.
#flannel по умолчанию выделяет подсеть с маской 24 на каждую ноду, из этих подсетей будут выделяться адреса для Docker-контейнеров.
#Подсеть не должна пересекаться с PORTAL_NET
export FLANNEL_NET=172.16.0.0/16
# Admission Controllers определяет политику доступа к объектам кластера.
ADMISSION_CONTROL=NamespaceLifecycle,NamespaceAutoProvision,LimitRanger,ResourceQuota
# Дополнительные параметры запуска Docker. Могут быть полезны для дополнительных настроек
# например установка --insecure-registry для локальных репозиториев.
DOCKER_OPTS=""
На этом настройка заканчивается и можно переходить к установке.
Установка
Первым делом необходимо сообщить системе про наш ssh-agent и используемый ssh-ключ для этого выполняем:
eval `ssh-agent -s`
ssh-add /путь/до/ключа
Далее переходим непосредственно к установке. Для этого используется скрипт ./kubernetes/cluster/kube-up.sh которому необходимо указать, что мы используем ubuntu.
conf% cd ../
conf% KUBERNETES_PROVIDER=ubuntu ./kube-up.sh
В процессе установки скрипт потребует пароль sudo для каждой ноды. По окончанию установки проверит состояние кластера и выведет список нод и адреса Kubernetes api.
Пример вывода скрипта
Starting cluster using provider: ubuntu
... calling verify-prereqs
... calling kube-up
Deploying master and minion on machine 192.168.0.10
<Список копируемых файлов>
[sudo] password to copy files and start node:
etcd start/running, process 16384
Connection to 192.168.0.10 closed.
Deploying minion on machine 192.168.0.11
<Список копируемых файлов>
[sudo] password to copy files and start minion:
etcd start/running, process 12325
Connection to 192.168.0.11 closed.
Deploying minion on machine 192.168.0.12
<Список копируемых файлов>
[sudo] password to copy files and start minion:
etcd start/running, process 10217
Connection to 192.168.0.12 closed.
Validating master
Validating core@192.168.0.10
Validating core@192.168.0.11
Validating core@192.168.0.12
Kubernetes cluster is running. The master is running at:
http://192.168.0.10
... calling validate-cluster
Found 3 nodes.
1 NAME LABELS STATUS
2 192.168.0.10 <none> Ready
3 192.168.0.11 <none> Ready
4 192.168.0.12 <none> Ready
Validate output:
NAME STATUS MESSAGE ERROR
etcd-0 Healthy {"action":"get","node":{"dir":true,"nodes":[{"key":"/coreos.com","dir":true,"modifiedIndex":11,"createdIndex":11},{"key":"/registry","dir":true,"modifiedIndex":5,"createdIndex":5}],"modifiedIndex":5,"createdIndex":5}}
nil
controller-manager Healthy ok nil
scheduler Healthy ok nil
Cluster validation succeeded
Done, listing cluster services:
Kubernetes master is running at http://192.168.0.10:8080
Посмотрим, какие ноды и сервисы присутствуют в новом кластере:
conf% cp ../kubernetes/platforms/linux/amd64/kubectl /opt/bin/
conf% /opt/bin/kubectl get services,minions -s "http://192.168.0.10:8080"
NAME LABELS SELECTOR IP PORT(S)
kubernetes component=apiserver,provider=kubernetes <none> 192.168.3.2 443/TCP
kubernetes-ro component=apiserver,provider=kubernetes <none> 192.168.3.1 80/TCP
NAME LABELS STATUS
192.168.0.10 <none> Ready
192.168.0.11 <none> Ready
192.168.0.12 <none> Ready
Видим список из установленных нод в состоянии Ready и два предустановленных сервиса kubernetes и kubernetes-ro — это прокси для непосредственного доступа к Kubernetes API. Как и к любому сервису Kubernetes к kubernetes и kubernetes-ro можно обратиться непосредственно по IP адресу с любой из нод.
Запуск тестового сервиса
Для запуска сервиса необходимо подготовить docker контейнер, на основе которого будет создан сервис. Дабы не усложнять, в примере будет использован общедоступный контейнер nginx. Обязательными составляющими сервиса являются Replication Controller, обеспечивающий запущенность необходимого набора контейнеров (точнее pod) и service, который определяет, на каких IP адресе и портах будет слушать сервис и правила распределения запросов между pod'ами.
Любой сервис можно запустить 2-я способами: вручную и с помощью конфиг-файла. Рассмотрим оба.
Запуск сервиса вручную
Начнём с создания Replication Controller'а:
conf% /opt/bin/kubectl run-container nginx --port=80 --port=443 --image=nginx --replicas=6 -s "http://192.168.0.10:8080"
Где:
- nginx — имя будущего rc
- --port — порты на которых будут слушать контейнеры rc
- --image — образ из которого будут запущены контейнеры
- --replicas=6 — количество реплик
Посмотрим, что у нас получилось:
/opt/bin/kubectl get pods,rc -s "http://192.168.0.10:8080"
Вывод
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
nginx-3gii4 172.16.58.4 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds
nginx nginx Running 9 seconds
nginx-3xudc 172.16.62.6 192.168.0.10/192.168.0.10 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-igpon 172.16.58.6 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-km78j 172.16.58.5 192.168.0.11/192.168.0.11 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-sjb39 172.16.83.4 192.168.0.12/192.168.0.12 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
nginx-zk1wv 172.16.62.7 192.168.0.10/192.168.0.10 run-container=nginx Running 9 seconds
nginx nginx Running 8 seconds
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx nginx nginx run-container=nginx 6
Был создан Replication Controller с именем nginx и количеством реплик равным 6. Реплики в произвольном порядке запущены на нодах, местоположения каждой pod'ы указано в столбце HOST.
Вывод может отличаться от приведённого в некоторых случаях, например:
- Часть pod находится в состоянии pending: это значит, что они ещё не запустились, необходимо немного подождать
- У pod не определён HOST: это значит, что scheduler ещё не назначил ноду на которой будет запущен pod
Далее создаём service который будет использовать наш Replication Controller как бекенд.
Для http:
conf% /opt/bin/kubectl expose rc nginx --port=80 --target-port=80 --service-name=nginx-http -s "http://192.168.0.10:8080"
И для https:
conf% /opt/bin/kubectl expose rc nginx --port=443 --target-port=443 --service-name=nginx-https -s "http://192.168.0.10:8080"
Где:
- rc nginx — тип и имя используемого ресурса (rc = Replication Controller)
- --port — порт на котором будет «слушать» сервис
- --target-port — порт контейнера на который будет производиться трансляция запросов
- --service-name — будущее имя сервиса
Проверяем результат:
/opt/bin/kubectl get rc,services -s "http://192.168.0.10:8080"
Вывод
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx nginx nginx run-container=nginx 6
NAME LABELS SELECTOR IP PORT(S)
kubernetes component=apiserver,provider=kubernetes <none> 192.168.3.2 443/TCP
kubernetes-ro component=apiserver,provider=kubernetes <none> 192.168.3.1 80/TCP
nginx-http <none> run-container=nginx 192.168.3.66 80/TCP
nginx-https <none> run-container=nginx 192.168.3.172 443/TCP
Для проверки запущенности можно зайти на любую из нод и выполнить в консоли:
node% curl http://192.168.3.66
В выводе curl увидим стандартную приветственную страницу nginx. Готово, сервис запущен и доступен.
Запуск сервиса с помощью конфигов
Для этого способа запуска необходимо создать конфиги для Replication Controller'а и service'а. Kubernetes принимает конфиги в форматах yaml и json. Мне ближе yaml поэтому будем использовать его.
Предварительно очистим наш кластер от предыдущего эксперимента:
conf% /opt/bin/kubectl delete services nginx-http nginx-https -s "http://192.168.0.10:8080"
conf% /opt/bin/kubectl stop rc nginx -s "http://192.168.0.10:8080"
Теперь приступим к написанию конфигов.
nginx_rc.yaml
содержимое
apiVersion: v1beta3
kind: ReplicationController
# Указываем имя ReplicationController
metadata:
name: nginx-controller
spec:
# Устанавливаем количество реплик
replicas: 6
selector:
name: nginx
template:
metadata:
labels:
name: nginx
spec:
containers:
#Описываем контейнер
- name: nginx
image: nginx
#Пробрасываем порты
ports:
- containerPort: 80
- containerPort: 443
livenessProbe:
# включаем проверку работоспособности
enabled: true
type: http
# Время ожидания после запуска pod'ы до момента начала проверок
initialDelaySeconds: 30
TimeoutSeconds: 5
# http проверка
httpGet:
path: /
port: 80
portals:
- destination: nginx
Применяем конфиг:
conf% /opt/bin/kubectl create -f ./nginx_rc.yaml -s "http://192.168.0.10:8080"
Проверяем результат:
conf% /opt/bin/kubectl get pods,rc -s "http://192.168.0.10:8080"
Вывод
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
nginx-controller-0wklg 172.16.58.7 192.168.0.11/192.168.0.11 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-2jynt 172.16.58.8 192.168.0.11/192.168.0.11 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-8ra6j 172.16.62.8 192.168.0.10/192.168.0.10 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-avmu8 172.16.58.9 192.168.0.11/192.168.0.11 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-ddr4y 172.16.83.7 192.168.0.12/192.168.0.12 name=nginx Running About a minute
nginx nginx Running About a minute
nginx-controller-qb2wb 172.16.83.5 192.168.0.12/192.168.0.12 name=nginx Running About a minute
nginx nginx Running About a minute
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx-controller nginx nginx name=nginx 6
Был создан Replication Controller с именем nginx и количеством реплик равным 6. Реплики в произвольном порядке запущены на нодах, местоположения каждой pod'ы указано в столбце HOST.
nginx_service.yaml
Содержимое
apiVersion: v1beta3
kind: Service
metadata:
name: nginx
spec:
publicIPs:
- 12.0.0.5 # IP который будет присвоен сервису помимо автоматически назначенного.
ports:
- name: http
port: 80 #порт на котором будет слушать сервис
targetPort: 80 порт контейнера на который будет производиться трансляция запросов
protocol: TCP
- name: https
port: 443
targetPort: 443
protocol: TCP
selector:
name: nginx # поле должно совпадать с аналогичным в конфиге ReplicationController
Можно заметить, что при использовании конфига за одним сервисом могут быть закреплены несколько портов.
Применяем конфиг:
conf% /opt/bin/kubectl create -f ./nginx_service.yaml -s "http://192.168.0.10:8080"
Проверяем результат:
/opt/bin/kubectl get rc,services -s "http://192.168.0.10:8080"
Вывод
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
nginx-controller nginx nginx name=nginx 6
NAME LABELS SELECTOR IP PORT(S)
kubernetes component=apiserver,provider=kubernetes <none> 192.168.3.2 443/TCP
kubernetes-ro component=apiserver,provider=kubernetes <none> 192.168.3.1 80/TCP
nginx <none> name=nginx 192.168.3.214 80/TCP
12.0.0.5 443/TCP
Для проверки запущенности можно зайти на любую из нод и выполнить в консоли:
node% curl http://192.168.3.214
node% curl http://12.0.0.5
В выводе curl увидим стандартную приветственную страницу nginx.
Заметки на полях
В качестве заключения хочу описать пару важных моментов, о которые уже пришлось запнуться при проектировании системы. Связаны они были с работой kube-proxy, того самого модуля, который позволяет превратить разрозненный набор элементов в сервис.
PORTAL_NET. Сущность сама по себе интересная, предлагаю ознакомиться с тем, как же это реализовано.
Недолгие раскопки привели меня к осознанию простой, но эффективной модели, заглянем в вывод iptables-save:
-A PREROUTING -j KUBE-PORTALS-CONTAINER
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT -j KUBE-PORTALS-HOST
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 10.0.42.0/24 ! -o docker0 -j MASQUERADE
-A KUBE-PORTALS-CONTAINER -d 10.0.0.2/32 -p tcp -m comment --comment "default/kubernetes:" -m tcp --dport 443 -j REDIRECT --to-ports 46041
-A KUBE-PORTALS-CONTAINER -d 10.0.0.1/32 -p tcp -m comment --comment "default/kubernetes-ro:" -m tcp --dport 80 -j REDIRECT --to-ports 58340
-A KUBE-PORTALS-HOST -d 10.0.0.2/32 -p tcp -m comment --comment "default/kubernetes:" -m tcp --dport 443 -j DNAT --to-destination 172.16.67.69:46041
-A KUBE-PORTALS-HOST -d 10.0.0.1/32 -p tcp -m comment --comment "default/kubernetes-ro:" -m tcp --dport 80 -j DNAT --to-destination 172.16.67.69:58340
Все запросы к IP-адресу сервиса попавшие в iptables заворачиваются на порт на котором слушает kube-proxy. В связи с этим возникает одна проблема: Kubernetes, сам по себе, не решает проблему связи с пользователем. Поэтому придётся решать этот вопрос внешними средствами, например:
- gcloud — платная разработка от Google
- bgp — с помощью анонсирования подсетей
- IPVS
- и прочие варианты, которых множество
SOURCE IP Так же. при настройке сервиса nginx мне пришлось столкнуться с интересной проблемой. Она выглядела как строчка в мануале: «Using the kube-proxy obscures the source-IP of a packet accessing a Service». Дословно — при использовании kube-proxy скрывает адрес источника пакета, а это значит, что всю обработку построенную на основе source-IP придётся проводить до использования kube-proxy.
На этом всё, спасибо за внимание
К сожалению, всю информацию, которую хочется передать, не получается уместить в одну статью.
Использование материалы:
- Архитектура Kubernetes
- Kubernetes user guide
- Kubernetes ubuntu cluster
- Scaling Docker with Kubernetes
- Kubernetes services
UPD. В связи с получением инвайта хотел спросить, что вы хотите увидеть в следующих статьях?
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (85)

fear86
25.05.2015 00:59Так же насколько мне известно не решен вопрос изоляции групы контейнеров (неймспейсов).
Все поды живут в одной сети.

fear86
Интересует вопрос миграции подов. Допустим система управления приняла решение разгрузить одну из нод, и должна выселить с ноды 30% подов. Как это возможно реализовать? Пока расматриваю 2 варианта:
aml
Мне решение #1 кажется наиболее подходящим к философии Kubernetes. Единственное, если вы хотите ограничить нагрузку на машину, чтобы она потребляла на 30% меньше ресурсов, а не отключить её совсем, то вместо unschedulable лучше уменьшить лимит CPU и RAM (поле Capacity).
fear86
Мы хотим оверселить ресурсы, и поймать момент когда пора скейлить инфраструктуру и переносить клиентов на новые ноды. Сразу предвидеть нагрузку нет возможности, так как все зависит от частного случая каждого клиента. А держать сервера в простое тоже не хочется.
aml
Я правильно понимаю, что вы хотите делать utilization based scheduling? Т.е. если нагрузка на конкретную ноду стала неприемлемо большой, то вы хотите раскидывать контейнеры на другие ноды?
fear86
Именно, так и хотим )
aml
Тогда всё гораздо проще делается. Когда ваша логика решает разгрузить машину, она просто отстреливает «лишние» поды на ней. Replication controller у вас должен быть настроен с политикой LeastRequestedPriority, чтобы новые поды направлялись на наименее загруженные машины.
fear86
А где можно прочесть про этот LeastRequestedPriority? Просто отстрелить их не получится, так как нужно без даунтайма это делать. Но если я правильно понял то и ролинг-апдейт тут подойдет.
aml
Если нужен graceful restart, то вместо отстрела, просто снимаете все лейблы с пода. Он ещё запущен, принимает запросы от пользователей, но для kube-proxy и для kube-scheduler он уже не видим. Первый снимет с него трафик, а второй запустит новый под где-нибудь. Через несколько секунд нагрузка на под упадёт до нуля, и его можно уже прибить. Собственно, rolling restart ровно это и делает. Только он делает это со всеми подами, которые у вас есть в кластере, а вы можете сделать это только с теми, которые вам нужно перенести на другие машины.
Про LeastRequestedPriority тут — github.com/GoogleCloudPlatform/kubernetes/blob/master/plugin/pkg/scheduler/algorithmprovider/defaults/defaults.go#L65
Документацию человеческую, насколько я знаю, не написали ещё.
fear86
У нас поды без трафика, это демоны которые крутятся все время. Но идея с лейблами годится, тогда контроллер поднимет новые, а уже потом можно из вне прибить старые.
Да исходники я уже тоже нашел и полез изучать ) Похоже все же надо будет ставить себе Го
Спасибо за наводку!
fear86
Если я правильно понял по коду, то он отталкивается от статических данных, а не от текущей нагрузке на ноду. Это не спасает когда у нас 10 подов на одной ноде жрет ресурсов больше чем 20 на другой. При равной конфигурации. Но в теории можно дописать туда своих алгоритмов ))
aml
Ага. Должно быть легко. Интерфейсы там очень простые :)