
Чтобы оценить масштаб бедствия, мы решили провести простой эксперимент — создать 100 миллионов пустых строк в Яве и посмотреть, сколько придётся заплатить за них оперативной памяти.
Внимание: В конце статьи приведён опрос. Будет интересно, если вы попробуете ответить на него до прочтения статьи, для самоконтроля.
Правилом хорошего тона при проведении любых замеров считается опубликовать версию виртуальной машины и параметры запуска теста:
> java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
Сжатие указателей включено (читай: размер кучи меньше 32 Гб):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:+UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment
Сжатие указателей выключено (читай: размер кучи больше 32 Гб):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:-UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment
Исходный код самого теста:
package ru.habrahabr.experiment;
import org.apache.commons.lang3.time.StopWatch;
import java.util.ArrayList;
import java.util.List;
public class HundredMillionEmptyStringsExperiment {
public static void main(String[] args) throws InterruptedException {
List<String> lines = new ArrayList<>();
StopWatch sw = new StopWatch();
sw.start();
for (int i = 0; i < 100_000_000L; i++) {
lines.add(new String(new char[0]));
}
sw.stop();
System.out.println("Created 100M empty strings: " + sw.getTime() + " millis");
// чтобы не сохранять лишнего и было проще анализировать снимок кучи
System.gc();
// защита от оптимизаций
while (true) {
System.out.println("Line count: " + lines.size());
Thread.sleep(10000);
}
}
}
Процесс
Ищем идентификатор процесса с помощью утилиты jps и делаем снимок кучи (heap dump) с помощью jmap:
> jps
12777 HundredMillionEmptyStringsExperiment
> jmap -dump:format=b,file=HundredMillionEmptyStringsExperiment.bin 12777
Dumping heap to E:\jdump\HundredMillionEmptyStringsExperiment.bin ...
Heap dump file created
Анализируем снимок кучи, используя Eclipse Memory Analyzer (MAT):
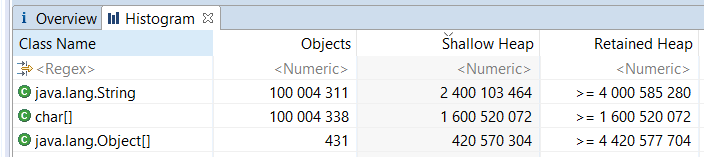

Для второго теста с выключенным сжатием указателей снимки не приводим, но мы честно провели эксперимент и просим поверить на слово (оптимально: воспроизвести тест и убедиться самим).
Выводы
- 2.4 Гб занимает обвязка объектов класса String + указатели на массивы символов + хэши.
- 1.6 Гб занимает обвязка массивов символов.
- 400 Мб занимают указатели на строки.
Если вы работаете с размером кучи больше 32Гб (сжатие указателей выключено), то указатели будут стоить ещё дороже. Соответственно будут такие результаты:
- 3.2 Гб занимает обвязка объектов класса String + указатели на массивы символов + хэши.
- 2.4 Гб занимает обвязка массивов символов.
- 800 Мб занимают указатели на строки.
Итого, за каждую строку вы дополнительно к размеру массива символов платите 44 байта (64 байта без сжатия указателей). Если средняя длина строк составляет 15 символов, то получается почти 5 байт на каждый символ. Запретительно дорого, если речь идёт о домашнем железе.
Как бороться
Существуют две основные стратегии для экономии ресурсов:
- Для большого количества дублирующихся строк можно использовать интернирование (string interning) или дедупликацию (string deduplication). Суть механизма такая: поскольку строки в Яве неизменяемые, то можно хранить их в отдельном пуле и при повторе ссылаться на существующий объект вместо создания новой строки. Такой подход не бесплатен — он стоит и памяти и процессорного времени для хранения структуры пула и поиска в нём.
Чем отличается интернирование от дедупликации, какие есть вариации последней, и чем чревато использование метода String.intern() смотрите в замечательном докладе Алексея Шипилёва (ссылка), начиная с 31:52.
- Если, как в нашем случае, строки уникальные — не остаётся ничего другого как использовать различные алгоритмические трюки. Мини-анонс: как мы работаем с сотней миллионов биграмм (читай: слово + слово или 15 символов) в наших задачах расскажем в самое ближайшее время.
К сожалению встроенных механизмов, чтобы более компактно хранить каждую отдельную строку, в Яве нет. В будущем ситуация может немного улучшиться для отдельных сценариев: см. JEP 254.
На посмотреть
Горячо рекомендуем посмотреть доклад Алексея Шипилёва из Oracle под громким названием «Катехизис java.lang.String» (спасибо periskop за наводку). Там он говорит по проблеме статьи на 4:26 и про интернирование/дедупликацию строк, начиная с 31:52.
В заключение
Решение любой проблемы начинается с оценки её масштабов. Теперь вы эти масштабы знаете и можете учитывать накладные расходы при работе с большим количеством строк в своих проектах.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (85)

byme
15.10.2016 16:25+2Я конечно понимаю, что в тегах только Java, но первая мысль какая пришла мне в голову это сравнить с .Net-том. Итого стандартное консольное приложение созданое при помощи студии с copy-past-fix_syntax_errors кодом занимает 528 МБ, что в свою очередь ~5 раз меньше. Как-то уж больно большой оверхед получается для тех кому нужны базы данных, где строки на входе и на выходе.
kdenisk
15.10.2016 16:28+1Было бы очень интересно посмотреть на похожий тест в .NET, Python и Rust. Просто я не так хорошо разбираюсь во внутренних механизмах этих платформ, чтобы провести его максимально честно.
Это будет бесценный материал для принятия взвешенного решения, какую платформу использовать в похожих сценариях (если есть такой выбор).splav_asv
16.10.2016 00:03Rust 1.12 Linux 4.7.5 x86_64
extern crate heapsize; use heapsize::heap_size_of; use std::os::raw::c_void; use std::mem::size_of_val; fn main() { let n = 100_000_000; let mut vec: Vec<String> = Vec::with_capacity(n); for _ in 0..n { vec.push(String::from("")); } let self_size = unsafe { heap_size_of(vec.as_ptr() as *const c_void) }; let string = String::from(""); let string_size = size_of_val::<String>(&string); print!("Heap size: one string: {}B, vec: {}B\n", string_size, self_size); }
Heap size: one string: 24B, vec: 2684354560B
Итого размер строки по умолчанию 24 байта. + 271МБ(~10%) рискну предположить что пропало в недрах jemalloc. Независимо от количества элементов эти 10% остаются десятью процентами.
byme
15.10.2016 16:33Я тут еще немного подумал и понял, что это никак не связано со строками. Подобная проблема будет во всем где есть куча, ссылки и т.д., то есть везде.
kdenisk
15.10.2016 16:36Наверное так и есть. Другое дело, сколько занимают обвязки объектов и ссылки на других платформах? Этого я не знаю.

CyboMan
15.10.2016 17:19node.js 4.6.0, linux kernel 4.7.2 x86_64
const util = require('util'); const process = require('process'); var A=new Array(); for (var i=0; i<10000000; i++) A.push(new String("/u0000")); console.log(util.inspect(process.memoryUsage()));
~$ nodejs x.js
{ rss: 496259072, heapTotal: 474601056, heapUsed: 470572400 }
До кучи:
... for (var i=0; i<10000000; i++) A.push(new String((10000000+i).toString())); // Длинна строки всегда 8 символов ...
{ rss: 821313536, heapTotal: 794501216, heapUsed: 790837096 }
CyboMan
15.10.2016 17:37+1Слеш не тот :)
... for (var i=0; i<10000000; i++) A.push(new String("\u0000")); ...
{ rss: 496185344, heapTotal: 474601056, heapUsed: 470573552 }
Принципиально картинка не поменялась. И да, тут 10 млн строк.kdenisk
15.10.2016 17:42Спасибо за тест. В JavaScript под капотом тот же UTF-16, судя по всему и остальные вещи похожим образом сделаны.

Shatun
15.10.2016 17:23Для большого количества дублирующихся строк можно использовать интернирование (string interning). Суть механизма такая: поскольку строки в Яве неизменяемые, то можно хранить их в отдельном пуле и при повторе ссылаться на существующий объект вместо создания новой строки. Такой подход не бесплатен — он стоит и памяти и процессорного времени для хранения структуры пула и поиска в нём.
Но строки в джаве и так хранятся в отдельном пуле и, если такая строка существует в пуле, то будет ссылаться на нее
Prototik
15.10.2016 17:28+2Это вы про константные строки говорите (которые в кавычках в самом java файле). Если создавать строку именно как new String() — то никакого пула не будет, пока не вызовем метод .intern() у строки.
kdenisk
15.10.2016 17:38Здесь стоит быть аккуратнее. Java сама складывает в пул только строковые литералы. Т.е. те строки, которые были в вашем исходном коде к моменту компиляции программы.
Остальные строки можно сложить в пул (интернировать) применив к ним метод .intern(). Попробуйте запустить следующий код:
package ru.habrahabr.experiment; public class StringEqualityExperiment { public static void main(String[] args) { String x = "abc"; String y = "abc"; System.out.println(x == y); x = new String("abc"); y = new String("abc"); System.out.println(x == y); x = new String("abc").intern(); y = new String("abc").intern(); System.out.println(x == y); x = new String("abc").intern(); y = new String("abc"); System.out.println(x == y); } }
Он выдаст: true false true false.
Пул, начиная с Java 7, можно использовать (до этого были серьёзные архитектурные проблемы). Но стоит подкручивать его под конкретный сценарий настроечкой -XX:StringTableSize и заранее оценивать, стоит ли в принципе овчинка выделки. В нашем случае, при работе с уникальными строками, использование пула начисто лишено всякого смысла.Shatun
15.10.2016 17:40+2Да, вы правы, но в статье сказано
К сожалению в Яве не существует встроенных механизмов, чтобы напрямую сократить потребление памяти при работе со строками.
и далее расказывается про пул строк и интернирование, поэтому я и уточнил данный момент
lany
16.10.2016 13:27+5Пул, начиная с Java 7, можно использовать
Вот как вы можете ссылаться на презентацию Шипилёва и тут же говорить, что интернирование можно использовать? Шипилёв кучу раз со свойственной ему выразительностью говорил, что интернирование использовать нельзя. Вот в том самом видео, на которое вы ссылку вставили, с 32-й минуты про это же и говорит. Это низкоуровневая штука, нужная самой JVM и библиотекам, использующим JNI. Это не для пользователей. Если вам нужна дедупликация, напишите свой собственный пул, это 15 строчек кода. Не пользуйтесь String.intern(), если вы просто хотите снизить расход памяти! Он для других целей.
kdenisk
16.10.2016 14:24Остаётся молча согласиться и пойти поправить в статье. Спасибо, что обратили на это моё внимание.

h31
15.10.2016 18:01+6Не очень понимаю один момент. Почему бы не сложить слова в один большой массив, а фразы представлять в виде двух индексов — первого и второго слова? Более того, можно брать не массив строк, а один большой массив символов, где слова разделены спецсимволов.
Тут, конечно, всё зависит от того, как вы потом эти фразы используете.kdenisk
15.10.2016 18:07Мы ровно так и сделали! Просто любой велосипед стоит человеческих ресурсов и нужно уметь быстро оценить есть ли возможность решить задачу встроенными средствами, перед тем как начать прикручивать педали и руль к проекту.
h31
16.10.2016 00:58+1О, я угадал :)
У меня почему-то эта мысль появилась в самом начале поста, ещё на формулировке задачи. Я бы, конечно, тоже проверил вариант со строками, но уже потом, типа «может и не стоило так усложнять?».
periskop
15.10.2016 21:15+2Использовать intern для дедупликации данных не стоит: чревато потерей производительности, причем проседать может в 10 раз на миллионах строк. Об этом рассказывал Алексей Шипилев в докладе «Катехизис java.lang.String». Вот часть про intern: https://youtu.be/SZFe3m1DV1A?t=1912
kdenisk
15.10.2016 21:21Спасибо за ссылку на доклад. Смотрел его когда-то, но замылилось в памяти. Доклад очень полезный, добавлю его в статью.
По теме — Алексей немного лукавит. Если использовать подстроечный параметр -XX:StringTableSize, то просадка по скорости не такая ужасающая получается. Но сам посыл очень грамотный: если используешь встроенную магию в приложениях чувствительных к производительности, будь добр разобраться как она работает.
Особенно это касается встроенного интернирования, с которым ещё в шестёрке были адовы проблемы с забиванием PermGen.periskop
16.10.2016 09:14Спасибо за XX:StringTableSize, походу дела нашел еще интересную статью: http://java-performance.info/string-intern-in-java-6-7-8/. Там, например, сказано, что размер StringTableSize должен быть простым числом, чтобы увеличить производительность. Обсуждается это на http://stackoverflow.com/questions/1145217/why-should-hash-functions-use-a-prime-number-modulus.
Может быть, проверите на реальных данных, как влияет простота размера таблицы со строками на количество коллизий в HashMap-е?

vladimir_dolzhenko
15.10.2016 21:59+1В String, как и в любом другом объекте есть заголовок — system hash code, lock биты и т.п. Переход на ValueType позволит его несколько облегчить.
На данный момет, при таком масштабе — 100 млн строк — будет ещё просадка и от GC — обход такого графа не дешёвое удовольствие (и когда они в молодом поколении, и когда будут перенесены в старое). В общем-то схожие проблемы возникают при подобных масштабах при любых объектах — и пока один выход — уходить в offheap.
kdenisk
16.10.2016 11:13+1ValueType давно уже напрашиваются и на различных конференциях по Яве регулярно всплывают подстольные реализации лёгких объектов. Но это в светлом будущем, а нам эффективный код сегодня писать :)
vladimir_dolzhenko
16.10.2016 12:20Вот мы у себя условно вчера решили через offheap, храним utf-8 — ибо в 98% наших случаев это именно latin1, offheap sort и прочие рутины.

svboobnov
16.10.2016 03:15+1Возможно, я сейчас глупость ляпну, но всё же: А почему при таких объёмах слов и словосочетаний не закодировать их в виде чисел? В тип int количество словосочетаний должно поместиться. К примеру: положительные -> слова, а отрицательные -> словосочетания. Тогда текст у нас будет представлен как
.int[] textCodes;
Вот только надо подумать об устройстве достаточно осмысленной и при этом быстрой хэш-функции…hdfan2
16.10.2016 07:12+1Ну закодировали вы строки числами, а дальше-то что? Как отсортировать все строки по алфавиту? Или, например, найти все биграммы, где первое слово одной является вторым словом другой? А распечатать их потом обратно в виде слов как?

fzn7
16.10.2016 11:43О чем спор? У вас всегда «два путя». Либо жертвуем вычислительным ресурсом, либо памятью. Выбирайте.
kdenisk
16.10.2016 11:52Не, у нас не так. Есть три ресурса: память, процессор и инженерный ресурс. Последний — самый дорогой. Но используя его можно иногда экономить первые два одновременно.
fzn7
16.10.2016 14:30-1С какой целью вы контекст меняете с «приложения» на «юр. лицо»? У вас инженерный ресурс на хабр потек, будьте аккуратны
kdenisk
16.10.2016 11:05Глупость ляпнуть вы никак не можете, мы же не на экзамене. А в самых безумных предложениях часто скрываются самые лучшие идеи, потому как всплывают они из подсознания и ещё не осознаны, а уже на языке.
Более того ваше направление мысли абсолютно верное. Именно так мы и поступили, но об этом отдельная статья.

echo_mont
16.10.2016 11:05-2это все всерьез вами написано?
не разделяю пафоса статьи.
Что это за тупая задача — создать под копирку миллионы разных объектов?
М.б. вы недостаточно хорошо понимаете стоящую перед вами задачу??
Да, есть такие задачи, на понимание условий которых уходит немало времени.kdenisk
16.10.2016 11:07+1Эксперимент в статье только для иллюстрации, как предельный случай задачи со строками. Данных-то 0, но 4 гигабайта из собственного кармана мы уже заплатили.

UbuRus
16.10.2016 11:14Как не грустно есть еще разработчики которые верят в System.gc() :sad:
kdenisk
16.10.2016 11:17+2А что не так с вызовом System.gc()? В боевом коде — это серьёзный косяк, но в расчётных задачах на конкретной версии виртуальной машины — отличная штука.

Borz
16.10.2016 12:56-1может в том, что он выполняется не как "очисть мне сейчас", а "по возможности очисть раньше чем планировал"
kdenisk
16.10.2016 13:59+2Ну не совсем так. Это по спецификации System.gc() вам ничего ровным счётом не должен, вплоть до того, что его виртуальная машина может полностью проигнорировать. Поэтому затачивать на это боевой код, мягко говоря, не стоит. А для вычислений или экспериментов, которые вы ставите на конкретной версии виртуальной машины и точно знаете, что произойдёт при вызове данного метода — почему бы и нет.
Можно использовать всё что угодно и как угодно, просто в этом случае вы берёте на себя ответственность за последствия.
kdenisk
16.10.2016 14:06+1P.S. Не зря в jvisualvm и прочих профайлерах есть кнопочка Force GC:
Которая дёргает тот же самый метод. И не зря есть подстроечный параметр -XX:+DisableExplicitGC, который защищает ваш боевой код от отчаянных разработчиков сторонних библиотек, которые вопреки всем советам дёргают рубильник.
sergey-b
16.10.2016 16:33В 8-й яве System.gc() никаких видимых изменений в куче не производит. По крайней мере в тех экспериментах, которые я сам проводил. Единственный надежный способ выполнить полную сборку мусора — это сделать дамп кучи только с живыми объектами.
kdenisk
16.10.2016 16:54Тесты, описанные выше, проводились на Java 8 и System.gc() там прекрасно работал. Чей и какую версию JDK используете?
sergey-b
16.10.2016 16:58Сейчас вот такую. Эксперименты ставил на более ранней версии восьмерки.
java version «1.8.0_102»
Java(TM) SE Runtime Environment (build 1.8.0_102-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.102-b14, mixed mode)kdenisk
16.10.2016 17:07Не умею диагностировать по фото, но странно это. Флажочек -XX:+DisableExplicitGC не стоит нигде?
lany
16.10.2016 18:48Поделитесь вашими экспериментами.
sergey-b
16.10.2016 18:54-1Очень простые. Я проверял, как работает мой метод finalize(). В 7-й яве он у меня вызывался после System.gc(). В 8-й яве уже не вызывался. Специальных настроек GC я не включал намеренно, потому что интересовало именно поведение JVM по умолчанию. Тогда я заменил System.gc() на сброс дампа, и finalize() отработал во всех версиях явы.
lany
16.10.2016 18:59+3System.gc() не вызывает метод finalize(), а может добавить ваш объект в очередь финализации (если на него не осталось ссылок), которая разгребается отдельным потоком, не имеющим отношения к сборке мусора. В зависимости от того, что делает этот поток, финалайзер может не вызываться очень долго или никогда. Вообще выглядит так, будто вы какой-то магией занимаетесь без понимания происходящего. Код показать можете?
sergey-b
16.10.2016 19:08+1Вот, пожалуйста. Выгружаю JDBC-драйвер, загруженный из отдельного каталога. Пока он не выгружен, каталог в Windows не удаляется, так как файлы заняты. В семерке все удаляется сразу, а в восьмерке только после удара в бубен через JMX.
unload()public void unload() { try { if (driverManager != null) { DriverManagerProxy dmp = driverManager; this.driverManager = null; dmp.deregisterDriver(driver); } else { DriverManager.deregisterDriver(driver); } } catch (SQLException e) { e.printStackTrace(); } this.driver = null; if (classLoader != null) { ResourceBundle.clearCache(classLoader); try { cleanupThreadLocals(this.classLoader); } catch (ReflectiveOperationException e1) { e1.printStackTrace(); } try { this.classLoader.close(); } catch (IOException e) { e.printStackTrace(); } this.classLoader = null; System.gc(); System.runFinalization(); System.gc(); System.runFinalization(); } if (!delete(dir, false)) { dumpHeap(); delete(dir, false); } }lany
18.10.2016 07:19Сурово, спасибо. Яркий пример кода, который пошёл метастазами. Я честно с этой проблемой не сталкивался и, возможно, лучше действительно ничего не придумаешь (я сомневаюсь, но всякое бывает).

apangin
18.10.2016 15:31+2Принципиально сборки, вызванные через System.gc и через дамп хипа, не отличаются. Почему по-разному работает в Java 7 и Java 8 — не знаю. Может быть сотня причин; приведённого кода недостаточно, чтобы сказать, что именно. Могу сказать лишь одно — полагаться на вызов finalize точно не стоит. Очевидно, вы хотите закрыть ресурсы сразу при вызове unload — так и закройте их напрямую; может, даже явным вызовом finalize(), если другого способа нет.
sergey-b
18.10.2016 21:32Расскажите, пожалуйста, как напрямую выгрузить dll, которая была загружена через System.loadLibrary().
apangin
18.10.2016 23:28+1Да, это проблема. Через Reflection можно даже это сделать, но будет всё равно ужасно. Лучше, наверное, вообще избегать необходимости удаления каталога с загруженной dll.
Впрочем, речь была о другом: при настройках по умолчанию System.gc точно запускает сборку; проблема в чём-то ином. Есть ещё несколько способов вызвать GC: через DiagnosticCommandMBean или через JVMTI. Но дамп хипа — это имхо перебор.sergey-b
19.10.2016 00:49Я декомпилировал классы, чтобы разобраться, что делается через MBean. Выяснилось, что там такой же вызов Runtime.getRuntime().gc(), как и в System.gc(). Поэтому вполне достаточно использовать System.gc().
Что у меня получилось в итоге:
Библиотека выгружается вместе с класслоадером.
Класслоадер выгружается после полной сборки мусора, если нет ни одного живого объекта из загруженных им классов.
После первой полной сборки мусора все объекты очищаются, но пустой класслоадер с библиотекой остается. Поэтому приходится 2 раза подряд вызывать System.gc().
Сам класслоадер удаляется после 2-го System.gc() в Java 7 и не удаляется в Java 8.
А вот dumpHeap делает то, что требуется, и объекты подчищает, и класслоадер, и библиотеку выгружает, и файл освобождает. Поскольку это дорого, то к этому лекарству я прибегаю только тогда, когда больше ничего не помогло.
lany
16.10.2016 18:51+2Здесь он никак не мешает (и не помогает), потому что Eclipse MemoryAnalyzer практически во всех вьюшках показывает только достижимые объекты. То есть если в куче есть недостижимый, то неважно, собрал ли его GC или нет — в MemoryAnalyzer'е увидим одно и то же. А насчёт верят — ну разработчики JDK вон тоже верят. Тоже дураки?
kdenisk
16.10.2016 19:01Чисто для перестраховки, чтобы не снимать лишней информации из кучи и не анализировать её в МАТе. Можно было поставить флажочек -dump:live джимапу и он бы сам полную сборку вызвал.
vladimir_dolzhenko
16.10.2016 12:25+2Ещё интересно увидеть — так ради прикола — результаты с -XX:+UseG1GC -XX:+UseStringDeduplication
sergey-b
16.10.2016 16:35А в восьмерке разве не G1 по умолчанию?
vladimir_dolzhenko
16.10.2016 16:52+1нет. он будет по-умолчанию в 9ке
$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version | egrep "UseStringDe|UseG1GC" bool UseG1GC = false {product} bool UseStringDeduplication = false {product} java version "1.8.0_74" Java(TM) SE Runtime Environment (build 1.8.0_74-b02) Java HotSpot(TM) 64-Bit Server VM (build 25.74-b02, mixed mode)sergey-b
16.10.2016 17:00И правда. Оказывается в Eclipse, с которым я работаю, в конфиге прописаны параметры
-XX:+UseG1GC
-XX:+UseStringDeduplication
UbuRus
16.10.2016 21:45Судя по всему меньше (около 2500mb), т.к. на /usr/lib/jvm/java-9-oracle/bin/java -Xmx3g -Xms3g у меня успешно выполнился приведенный выше код.
kdenisk
16.10.2016 22:09С включенной дедупликацией интересно прогнать если строки уникализировать (положить туда число и добить нулями слева до длины в 15 символом). Иначе они схлопываются и получается вырожденный случай.
На восьмёрке у меня -XX:+UseG1GC -XX:-UseStringDeduplication отвратительно себя ведёт — зажирает процессор и в целом в реальных приложениях проседает производительность. Но я не разбирался с ним досконально, просто ушёл обратно на CMS.
sergey-b
16.10.2016 16:40-2Весь оверхед связан с необходимостью автоматической сборки мусора. Если ваши алгоритмы предполагают наличие 100 млн объектов с возможностью произвольного доступа, то имеет смысл задуматься о самостоятельном управлении памятью, которую они занимают. Все эти объекты должны существовать вместе и уничтожаться будут тоже все разом, поэтому нет необходимости гонять сборщик мусора над ними. Поэтому заведите большой массив с данными и обертку, которая их вынимает по различным запросам.

23derevo
17.10.2016 01:04+1Оверхед по памяти в данном случае — вообще ни разу не про сборку мусора. Оверхед у строк — это:
- заголовок объекта
- ссылка на массив char-ов
- hashcode (кэшируется)
- дырки (паддинги) для выравнивания полей
Это все можно было и без подобного теста узнатьkdenisk
17.10.2016 09:28Даже не подумаю верить теории, не увидев своими глазами в инспекторе снимка кучи. Теория — это хорошо для объяснения результатов эксперимента. Но не для принятия решений.
apangin
17.10.2016 09:53+2А почему вы думаете, что heap dump покажет вам реальное занимаемое место? Это же не дамп физической памяти, а очередной абстрактный формат, который разные тулы могут трактовать по-разному. Если уж и мерить размеры объектов, то с помощью правильных инструментов, см. JOL.
kdenisk
17.10.2016 10:15Спасибо за ссылки на альтернативные инструменты и альтернативные подходы. В общем и целом, есть конечно линейка, а есть и штангенциркуль. Всё от задачи зависит. В данном конкретном случае анализ снимка кучи даёт вполне наглядное и сходящееся с практикой знание.
apangin
17.10.2016 13:34+3Посмотрите, сколько в хипдампе занимают объекты
java.lang.Classпо мнению MAT.
40 байт вместо реальных 96! Или ещё:java.lang.invoke.MemberNameякобы занимает 32 байта, хотя на самом деле 56. И это пример не с потолка: я сталкивался с реальными утечками, связанными с MemberName: JDK-8152271.
А статья без какого-либо анализа основывается исключительно на инструменте, который в некоторых случаях врёт в 2 раза!lany
18.10.2016 07:18+1Ну ладно уж тебе :-) Для строк MAT обычно не врёт, ему эвристик хватает, чтобы разобраться. Хотя, конечно, если вопрос стоит не "куда у меня десять гигабайт кучи делось", а "сколько точно байт занимает X", то, конечно, JOL использовать логичнее.
apangin
18.10.2016 14:47Моя претензия вовсе не к использованию MAT, а к тому, что в статье напрочь отсутствует какой-либо анализ, а выводы основываются только на цифрах конкретного эксперимента. Это из той же серии, что написать самодельный бенчмарк, и на его основе утверждать, что Java в 500 раз медленнее C++.

smoligor
16.10.2016 20:26Ну вроде как понятное дело что и пустые строки будут занимать не хилое количество места в памяти. Они же объекты в джаве. Зато это упрощает работу с этими самыми стрингами. Но опять же было бы интересно сравнить с другими платформами, тогда можно какие то выводы делать.
doom369
Существуют. Вы можете работать с массивом байт вместо класса String. Как, например, это делают в проекте Netty (смотреть класс AsciiString). Так же в Java 9 на подходе JEP 254.
kdenisk
Не согласен.
1) Массив байт даёт выигрыш в 1 байт на символ (из пяти!). Просто по той причине, что если вы хотите использовать .hashCode и .equals, вам придётся положить массив в объект-контейнер, который будет отвечать за хэширование и сравнение.
2) Это ни разу не встроенный механизм, а свой велосипед.
3) JEP 254 — это хотя бы намёк на то, что разработчики знают о существовании проблемы. Но это опять же экономия в 1 байт для строк с латиницей. Для национальных языков выигрыш отсутствует.
Основной расход памяти здесь не на сами символы (в тесте их просто нет), а на дорогущие обвязки объектов и неспособность Java хранить объектные поля рядом с самим экземпляром. Есть подстольные решения для последнего, но это ещё более велосипед.
fzn7
Что мешает сбросить хэши от строк в другой байтмассив? Или вы собираетесь сравнивая строку сто миллионов раз с другой строкой каждый раз вычислять от нее хэш?
kdenisk
Я исключительно имею ввиду, что если использовать свою реализацию строк, то придётся обернуть её в контейнер для использования в любой структуре данных в качестве ключа. И выигрыш сводится к более компактному хранению массива символов, а это несущественная экономия.
Если использовать решение со складыванием содержимого всех строк в один большой массив — там уже начинаются варианты. Но это государство в государстве, по сути своя модель управления памятью.
fzn7
Все верно, своя модель и она должна быть своя, т.к. юзейс, под который писался класс String не подходит к вашей задаче. Вообще за критикой должны быть предложения и статья была-бы полезной в случае наличия в ней оных. С указанием на явные косяки реализации и возможных путей их исправления
kdenisk
Предложение описано в секции «Как бороться», пункт 2. Не использовать java.lang.String, по крайней мере в лоб, и искать алгоритмически более оптимальные варианты решения исходной задачи.
Цель статьи ни в коем случае не в критике Явы — она такая, какая есть и тому свои причины. Цель — наглядно показать, что строки стоят не 2 байта на символ, а существенно дороже в случае работы с короткими строками.
kdenisk
Вообще проблема такого рода низкоуровневого велосипеда, что из уютного и удобного мира Ява, в котором большинство задач решаются по щелчку пальцев, ты резко проваливаешься в тёмное страшное подземелье, где ты совершенно один на один с проблемой.
Соответственно очень-очень хочется этого избежать и каждый сценарий анализируешь вдоль и поперёк, а нельзя ли его решить внутри платформы.
doom369
Не согласны с тем что вместо класса String можно использовать массив байт? Ну ок…
Это лишь одна из возможных оптимизаций. Можно банально все в один массив сложить, или в коллекцию. Тут уже можно сэкономить в 2-3 раза. Совсем не обазательно массив байт оборачивать в класс. А если у вас все строки уникальны, то Вам даже и строки хранить не надо, тут уже от задачи зависит.
Масисив байтов не встроенный механизм? Ну ок…
Спс, кэп.
kdenisk
Единственное, чем String лучше char[] так это то, что у первого осмыслено работают методы .equals и .hashCode. Поэтому строковые объекты можно использовать в качестве ключей коллекций, а массивы символов, без предварительного интернирования, нет. За хэш мы платим 24 байта на строку. И хоть вы и сделаете свой ByteString, столкнётесь с той же дилеммой.
Все оптимизации в данном случае — это в той или иной степени свой механизм управления памятью. Работает? Конечно! Удобно? Ни разу.
fRoStBiT
Подозреваю, что в такой ситуации проще написать (или модифицировать существующий) контейнер, который будет по-особому выполнять equals и hashCode для массивов символов. Что-то вроде IdentityHashMap.
kdenisk
Была идея хранить строку в национальной кодировке как массив байт и первые четыре ячейки использовать под хэш. Если дописать свои структуры данных, то вариант выглядел как рабочий. До реализации не дошло — проще выкрутились.