
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Зачем понадобился Юникод?
До появления Юникода, почти повсеместно использовались однобайтные кодировки, в которых граница между самими символами, их представлением в памяти компьютера и отображением на экране была довольно условной. Если вы работали с тем или иным национальным языком, то в вашей системе были установлены соответствующие шрифты-кодировки, которые позволяли отрисовывать байты с диска на экране таким образом, чтобы они представляли смысл для пользователя.
Если вы распечатывали на принтере текстовый файл и на бумажной странице видели набор непонятных кракозябр, это означало, что в печатающее устройство не загружены соответствующие шрифты и оно интерпретирует байты не так, как вам бы этого хотелось.
У такого подхода в целом и однобайтовых кодировок в частности был ряд существенных недостатков:
- Можно было одновременно работать лишь с 256 символами, причём первые 128 были зарезервированы под латинские и управляющие символы, а во второй половине кроме символов национального алфавита нужно было найти место для символов псевдографики (г ¬).
- Шрифты были привязаны к конкретной кодировке.
- Каждая кодировка представляла свой набор символов и конвертация из одной в другую была возможна только с частичными потерями, когда отсутствующие символы заменялись на графически похожие.
- Перенос файлов между устройствами под управлением разных операционных систем был затруднителен. Нужно было либо иметь программу-конвертер, либо таскать вместе с файлом дополнительные шрифты. Существование Интернета каким мы его знаем было невозможным.
- В мире существуют неалфавитные системы письма (иероглифическая письменность), которые в однобайтной кодировке непредставимы в принципе.
Основные принципы Юникода
Все мы прекрасно понимаем, что компьютер ни о каких идеальных сущностях знать не знает, а оперирует битами и байтами. Но компьютерные системы пока создают люди, а не машины, и для нас с вами иногда бывает удобнее оперировать умозрительными концепциями, а затем уже переходить от абстрактного к конкретному.
Важно! Одном из центральных принципов в философии Юникода является чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
Вводится понятие абстрактного юникод-символа, существующего исключительно в виде умозрительной концепции и договорённости между людьми, закреплённой стандартом. Каждому юникод-символу поставлено в соответствие неотрицательное целое число, именуемое его кодовой позицией (code point).
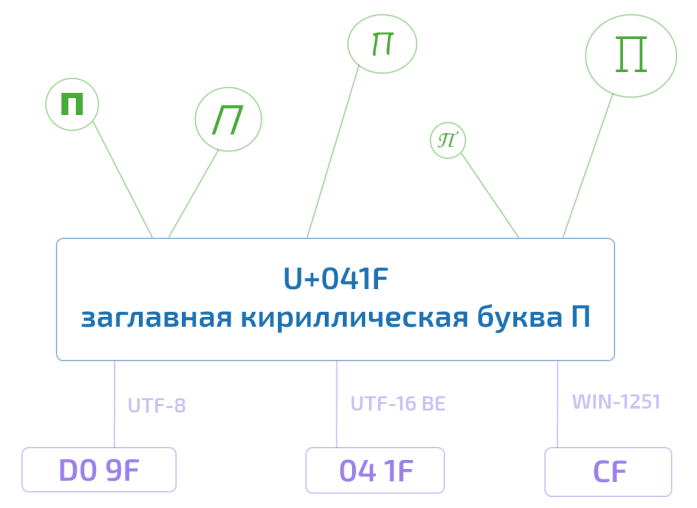
Так, например, юникод-символ U+041F — это заглавная кириллическая буква П. Существует несколько возможностей представления данного символа в памяти компьютера, ровно как и несколько тысяч способов отображения его на экране монитора. Но при этом П, оно и в Африке будет П или U+041F.
Это хорошо нам знакомая инкапсуляция или отделение интерфейса от реализации — концепция, отлично зарекомендовавшая себя в программировании.
Получается, что руководствуясь стандартом, любой текст можно закодировать в виде последовательности юникод-символов
Привет
U+041F U+0440 U+0438 U+0432 U+0435 U+0442
записать на листочке, упаковать в конверт и переслать в любой конец Земли. Если там знают о существовании Юникода, то текст будет воспринят ими ровно так же, как и нами с вами. У них не будет ни малейших сомнений, что предпоследний символ — это именно кириллическая строчная е (U+0435), а не скажем латинская маленькая e (U+0065). Обратите внимание, что мы ни слова не сказали о байтовом представлении.
Хотя юникод-символы и называются символами, они далеко не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу. (Подробнее смотри под спойлером.)
- U+0000: нулевой символ;
- U+D800–U+DFFF: младшие и старшие суррогаты для технического представления кодовых позиций в диапазоне от 10000 до 10FFFF (читай: за пределами БМЯП/BMP) в семействе кодировок UTF-16;
- и т.д.
Существуют пунктуационные маркеры, например U+200F: маркер смены направления письма справа-налево.
Существует целая когорта пробелов различной ширины и назначения (см. отличную хабра-статью: всё (или почти всё) о пробеле):
- U+0020 (пробел);
- U+00A0 (неразрывный пробел, в HTML);
- U+2002 (полукруглая шпация или En Space);
- U+2003 (круглая шпация или Em Space);
- и т.д.
Существуют комбинируемые диакритические знаки (сombining diacritical marks) — всевозможные штрихи, точки, тильды и т.д., которые меняют/уточняют значение предыдущего знака и его начертание. Например:
- U+0300 и U+0301: знаки основного (острого) и второстепенного (слабого) ударений;
- U+0306: кратка (надстрочная дуга), как в й;
- U+0303: надстрочная тильда;
- и т.д.
Существует даже такая экзотика, как языковые тэги (U+E0001, U+E0020–U+E007E, и U+E007F), которые сейчас находятся в подвешенном состоянии. Они задумывались как возможность маркировать определённые участки текста как относящиеся к тому или иному варианту языку (скажем американский и британский вариант английского), что могло влиять на детали отображения текста.
Что такое символ, чем отличается графемный кластер (читай: воспринимаемое как единое целое изображение символа) от юникод-символа и от кодового кванта мы расскажем в следующий раз.
Кодовое пространство Юникода
Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF. Из них к девятой версии стандарта значения присвоены лишь 128 237. Часть пространства зарезервирована для частного использования и консорциум Юникода обещает никогда не присваивать значения позициям из этих специальный областей.
Ради удобства всё пространство поделено на 17 плоскостей (сейчас задействовано шесть их них). До недавнего времени было принято говорить, что скорее всего вам придётся столкнуться только с базовой многоязыковой плоскостью (Basic Multilingual Plane, BMP), включающей в себя юникод-символы от U+0000 до U+FFFF. (Забегая немного вперёд: символы из BMP представляются в UTF-16 двумя байтами, а не четырьмя). В 2016 году этот тезис уже вызывает сомнения. Так, например, популярные символы Эмодзи вполне могут встретиться в пользовательском сообщении и нужно уметь их корректно обрабатывать.
Кодировки
Если мы хотим переслать текст через Интернет, то нам потребуется закодировать последовательность юникод-символов в виде последовательности байтов.
Стандарт Юникода включает в себя описание ряда юникод-кодировок, например UTF-8 и UTF-16BE/UTF-16LE, которые позволяют кодировать всё пространство кодовых позиций. Конвертация между этими кодировками может свободно осуществляться без потерь информации.
Также никто не отменял однобайтные кодировки, но они позволяют закодировать свой индивидуальный и очень узкий кусочек юникод-спектра — 256 или менее кодовых позиций. Для таких кодировок существуют и доступны всем желающим таблицы, где каждому значению единственного байта сопоставлен юникод-символ (см. например CP1251.TXT). Несмотря на ограничения, однобайтные кодировки оказываются весьма практичными, если речь идёт о работе с большим массивом моноязыковой текстовой информации.
Из юникод-кодировок самой распространённой в Интернете является UTF-8 (она завоевала пальму первенства в 2008 году), главным образом благодаря её экономичности и прозрачной совместимости с семибитной ASCII. Латинские и служебные символы, основные знаки препинания и цифры — т.е. все символы семибитной ASCII — кодируются в UTF-8 одним байтом, тем же, что и в ASCII. Символы многих основных письменностей, не считая некоторых более редких иероглифических знаков, представлены в ней двумя или тремя байтами. Самая большая из определённых стандартом кодовых позиций — 10FFFF — кодируется четырьмя байтами.
Обратите внимание, что UTF-8 — это кодировка с переменной длиной кода. Каждый юникод-символ в ней представляется последовательностью кодовых квантов с минимальной длиной в один квант. Число 8 означает битовую длину кодового кванта (code unit) — 8 бит. Для семейства кодировок UTF-16 размер кодового кванта составляет, соответственно, 16 бит. Для UTF-32 — 32 бита.
Если вы пересылаете по сети HTML-страницу с кириллическим текстом, то UTF-8 может дать весьма ощутимый выигрыш, т.к. вся разметка, а также JavaScript и CSS блоки будут эффективно кодироваться одним байтом. К примеру главная страница Хабра в UTF-8 занимает 139Кб, а в UTF-16 уже 256Кб. Для сравнения, если использовать win-1251 с потерей возможности сохранять некоторые символы, то размер, по сравнению с UTF-8, сократится всего на 11Кб до 128Кб.
Для хранения строковой информации в приложениях часто используются 16-битные юникод-кодировки в силу их простоты, а так же того факта, что символы основных мировых систем письма кодируются одним шестнадцатибитовым квантом. Так, например, Java для внутреннего представления строк успешно применяет UTF-16. Операционная система Windows внутри себя также использует UTF-16.
В любом случае, пока мы остаёмся в пространстве Юникода, не так уж и важно, как хранится строковая информация в рамках отдельного приложения. Если внутренний формат хранения позволяет корректно кодировать все миллион с лишним кодовых позиций и на границе приложения, например при чтении из файла или копировании в буфер обмена, не происходит потерь информации, то всё хорошо.
Для корректной интерпретации текста, прочитанного с диска или из сетевого сокета, необходимо сначала определить его кодировку. Это делается либо с использованием метаинформации, предоставленной пользователем, записанной в тексте или рядом с ним, либо определяется эвристически.
В сухом остатке
Информации много и имеет смысл привести краткую выжимку всего, что было написано выше:
- Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
- Юникод-символы не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу.
- Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF.
- Базовая многоязыковая плоскость включает в себя юникод-символы от U+0000 до U+FFFF, которые кодируются в UTF-16 двумя байтами.
- Любая юникод-кодировка позволяет закодировать всё пространство кодовых позиций Юникода и конвертация между различными такими кодировками осуществляется без потерь информации.
- Однобайтные кодировки позволяют закодировать лишь небольшую часть юникод-спектра, но могут оказаться полезными при работе с большим объёмом моноязыковой информации.
- Кодировки UTF-8 и UTF-16 обладают переменной длиной кода. В UTF-8 каждый юникод-символ может быть закодирован одним, двумя, тремя или четырьмя байтами. В UTF-16 — двумя или четырьмя байтами.
- Внутренний формат хранения текстовой информации в рамках отдельного приложения может быть произвольным при условии корректной работы со всем пространством кодовых позиций Юникода и отсутствии потерь при трансграничной передаче данных.
Краткое замечание про кодирование
С термином кодирование может произойти некоторая путаница. В рамках Юникода кодирование происходит дважды. Первый раз кодируется набор символов Юникода (character set), в том смысле, что каждому юникод-символу ставится с соответствие кодовая позиция. В рамках этого процесса набор символов Юникода превращается в кодированный набор символов (coded character set). Второй раз последовательность юникод-символов преобразуется в строку байтов и этот процесс также называется кодирование.
В англоязычной терминологии существуют два разных глагола to code и to encode, но даже носители языка зачастую в них путаются. К тому же термин набор символов (character set или charset) используется в качестве синонима к термину кодированный набор символов (coded character set).
Всё это мы говорим к тому, что имеет смысл обращать внимание на контекст и различать ситуации, когда речь идёт о кодовой позиции абстрактного юникод-символа и когда речь идёт о его байтовом представлении.
В заключение
В Юникоде так много различных аспектов, что осветить всё в рамках одной статьи невозможно. Да и ненужно. Приведённой выше информации вполне достаточно, чтобы не путаться в основных принципах и работать с текстом в большинстве повседневных задач (читай: не выходя за рамки BMP). В следующих статьях мы расскажем о нормализации, дадим более полный исторический обзор развития кодировок, побеседуем о проблемах русскоязычной юникод-терминологии, а также сделаем материал о практических аспектах использования UTF-8 и UTF-16.
Комментарии (52)

Saffron
13.10.2016 22:13+4Есть ещё такая полезная вещь в юникоде — это группы. Они классифицируют символы по значению. Проверив вхождение в группу можно узнать, является ли символ буквой какого-нибудь алфавита или знаком препинания, например. Бывают случаи, когда символы из разных групп выглядят похоже — но при этом принадлежат разным группам, а значит между ними есть большая семантическая разница. Иногда это разница существенна — например, когда мы хотим распарсить текст программы, для чего нужно разделять символы и операторы между ними.
Bozaro
13.10.2016 22:39+1Важная особенность UTF-8 и UTF-16LE: при побайтовом сравнении Unicode-строки не меняют свой порядок.

NeoCode
14.10.2016 00:17+2Если честно то не распарсил:) Порядок чего? И что вообще может меняться при сравнении, которое как известно не модифицирующая операция?

Googolplex
14.10.2016 01:20+9При использовании UTF-8 и UTF-16BE (здесь, кажется, Bozaro немного ошибся) последовательности code unit'ов, если их представить в виде чисел, возрастают согласно unicode scalar value'ам, которые они представляют. В UTF-16LE же это не так.
К примеру, возьмём символ U+10FF. В UTF-16BE он будет представлен как число 10FF, или как два байта со значениями 16 и 255. В UTF-16LE он будет представлен как FF10, или два байта со значениями 255 и 16. А теперь возьмём символ U+1100, следующий по номеру за U+10FF. В UTF-16BE он будет представлен как 1100, или 17 и 0. А в UTF-16LE он будет представлен как 0011, или 0 и 17. Получается такое:
| BE | LE | U+10FF | 16 255 | 255 16 | U+1100 | 17 0 | 0 17 |
Если сравнивать эти последовательности побайтно, то получается, что в UTF16-LE символ с кодом U+1100 будет "меньше" символа с кодом U+10FF, что противоречит порядку возрастания номеров символов в юникоде. Из-за этого наивная побайтовая, и даже пословная (по 2 байтам) сортировка будет давать весьма странные результаты при использовании UTF-16LE. Представления символов в UTF-8 я писать выше не стал, но там ситуация аналогична UTF-16BE — десятичные представления code point'ов возрастают согласно таблице юникода.
Bozaro
14.10.2016 09:45Да, я постоянно путаю LE и BE :(
Порядок сортировки сохраняется для UTF-8 и UTF-16BE.shadovv76
02.02.2017 10:34обычно (старых квартирах) в выключателях два провода.
ранее, когда системы заземления не были обязательны в жилых помещениях, проводку делали двужильным проводом, что позволяло с коробки в выключатель привезти только два провода, которые выключатель и замыкал.
в качестве одного провода как правило фаза, второй от люстры, ноль же с соединительной коробки сразу шел на люстру не заходя в выключатель.
таким образом нельзя запитать полноценно устройство, размещаемое в выключателе.
пока были лампы накаливания в разрыв выключателя можно было поставить малопотребляющее устройство которое работало на токе утечки через лампу накаливания не зажигая её.
с появлением малопотребляющих светодиодных ламп они стали зажигаться и мигать.

user4000
14.10.2016 11:53т.е. имеется ввиду, что такая кодировка сохраняет «отношение упорядоченности»?
т.е. для любых A и B таких что A < B
выполняется F(A) < F(B)sasha1024
14.10.2016 14:15+1Как бы, да.
Если Unicode-строки (т.е. последовательности code point'ов — номеров символов, например: U+434, U+31, U+10024 (>2байт), U+11003 (>2байт), U+2019) A и B таковы, что лексигографически A<B, то…
… и их UTF-8- и U?T?F?-?1?6?B?E?UTF-32BE-представления (в виде последовательностей байт, например: 0xD0, 0xB4, 0x31, 0xF0, 0x90, 0x80, 0xA4, 0xF0, 0x91, 0x80, 0x83, 0xE2, 0x80, 0x99) f(A) и f(B) таковы, что лексигографически f(A)<f(B).
Однако:
1. Во-первых, это не до конца верно для UTF-16BE. Символы U+E000..U+FFFF очевидно имеют бо?льшие номера, чем коды, используемые в UTF-16 для суррогатных пар — таким образом, U+FB20<U+10024, но (0xFB, 0x20)>(0xD8, 0x00, 0xDC). Естественно, это совершенно неверно и для любых UTF-*LE-представлений (UTF-16LE, UTF-32LE).
2. Во-вторых, при сравнении строк операцией меньше-больше правильно использовать collations. Collation зависит от локали; одна и та же пара букв у разных народов может считаться упорядоченной по-разному. Если же мы упорядочиваем с техническими целями (например, для помещения в бинарное дерево), то нам абсолютно не важно, соответствует ли упорядочивание цепочек символов упорядочиванию цепочек байт.
Googolplex
14.10.2016 00:59+2Строго говоря, в Java и в винде используется UCS-2, а не UTF-16. В частности, в Java
char— это 16-битное число, которого, очевидно, недостаточно для представления всех символов юникода. В UTF-16, чтобы обойти эту проблему с недостаточным размером code unit'а, вводятся так называемые суррогатные пары, к которым в общем случае в Java/WinAPI доступ предоставляется раздельно. Ну то есть, нет ограничителей, которые не позволяли бы работать с отдельными code unit'ами. Из-за этого, если писать программы неаккуратно, можно получить проблемы с символами вне BMP.
Вот ещё очень хороший и правильный сайт, который объясняет почему UTF-8 это лучшее из представлений юникода: http://utf8everywhere.org/

cypok
14.10.2016 05:37+3Подождите-подождите. В Java полный UTF-16, 1 code point = 1 или 2
char. Для получения честных code point вStringесть нужные методы. То есть Java и не пытается говорить, чтоchar– это представление любого символа, это ваша личная придумка.kdenisk
14.10.2016 09:48+4То есть Java и не пытается говорить, что char – это представление любого символа, это ваша личная придумка.
Я бы не был так категоричен. Ява появилась за несколько лет до появления суррогатных пар и на первых порах использовала UCS-2. В то время char действительно позволял представить любой существующий символ.
Потом появилась необходимость кодировать символы вне МЯП/BMP и, начиная с версии 1.5, Ява стала поддерживать UTF-16 и суррогатные пары. Тем не менее, в силу исторических причин, мы имеем возможность оперировать с внутренностями UTF-16 и создавать некорректные с её точки зрения последовательности кодовых квантов. Важно знать об этом и помнить; думаю Googolplex именно на это хотел обратить внимание всех читателей.khim
14.10.2016 20:48+2Собственно эти «исторические прчиины» — это и есть единственный смысл существования UTF-16. Если вы задаёте себе вопрос: «а какую кодировку использовать», то ответ однозначен — UTF-8. В редких случаях — UCS-4. Использовать же UTF-16 нужно только и исключительно тогда, когда у вас нет выбора.
cypok
15.10.2016 11:08-1Ну ответ все-таки не абсолютно однозначен. У UTF-8 есть недостаток: доступ по индексу за O(N). Иногда это бывает важно, и на помощь приходит UTF-32.
kdenisk
15.10.2016 12:05+3Технологическому миру ещё предстоит пройти через переосмысление подхода к строкам и Юникоду, возможно даже не один раз.
Сейчас в мире Java существует негласный статус-кво, что большинство разработчиков существуют в рамках БМЯП/BMP и скорее всего если и слышали о существовании суррогатных пар, то не вдавались в подробности. И, по большому счёту, огромная масса кода, использующая стандартные методы для работы со строками в Java — корявая и дырявая. За примером далеко ходить не надо — буквально недавно использование Emoji для телеграм-бота разломало парсер в JetBrains PhpStorm и я в настоящий момент жду фикса.
В мире Java есть робкие попытки сдвинуть всё с мёртвой точки, например — JEP 254: Compact Strings, но это по-прежнему очень осторожное подлечивание определённых симптомов проблемы.
В мире Python, начиная с версии 3.3 и реализации PEP 393: Flexible String Representation, дела обстоят намного лучше. Например, такой код:
emojiStr = u"" # в кавычках эмоджа, Хабр режет print (str(len(emojiStr)) + ": " + str(bytes(emojiStr, 'utf-8')))
выдаст в ответ единицу и
1: b'\xf0\x9f\x98\x80'
Так что в каком-то смысле питонщикам везёт больше.
Как обстоят дела в мирах .NET и C/C++ я, к сожалению, ничего не знаю и буду рад, если кто-нибудь поделится информацией в комментариях.
khim
17.10.2016 16:33+4У UTF-8 есть недостаток: доступ по индексу за O(N). Иногда это бывает важно, и на помощь приходит UTF-32.
Я в это, теоретически, готов поверить, а практически — никогда не сталкивался.
Я слышал эту отговорку много раз, но ещё ни разу не сталкивался с тем, чтобы какая-либо задача требовала этого. Ещё раз: ни разу.
Вариантов, когда использование UTF-32 и обращение по индексу за O(1) позволяют красиво и неправильно решить задачу — видел много, да. Работающих вариантов — не видел.
Дело в том, что «один символ» в Unicode абсолютно бессмысленен. К нему могут быть добавлены разные умляуты и цедилы, он может быть развёрнут в другую cторону («a > b», но "? > ?") и т.д. и т.п.
А если вам нужно «просто распарсить разметку» (XML, HTML, etc) — так она обычно из ASCII приходит и побайтовый доступ отлично работает и в UTF-8.
Пример задачи, которая хорошо ложится на UTF-32 и плохо на UTF-8 — был бы хорош. Потому что всё, что я пока что видел сводилось примерно к подходу «это отлично работает для русского и английского, а арабы, евреи и монголы со своими заморочками — пусть идут куда хотят». Ну так в этом случае можно и windows-1251 или koi8-r использовать, проблем ещё меньше будет!kdenisk
17.10.2016 16:55+3В Rust так и сделано: строки в UTF-8, доступ по итератору. А поэлементный доступ… это что отдавать: графемный кластер? юникод-символ? байт?
Indexing is intended to be a constant-time operation, but UTF-8 encoding does not allow us to do this. Furtheremore, it's not clear what sort of thing the index should return: a byte, a codepoint, or a grapheme cluster. The as_bytes() and chars() methods return iterators over the first two, respectively.
Отсюда: https://doc.rust-lang.org/std/string/struct.String.html#utf-8
Googolplex
18.10.2016 01:41+2Советую почитать сайт, на который я уже давал ссылку выше: http://utf8everywhere.org/. Вопреки распространённому представлению, случаи, когда доступ по индексу (что, вообще говоря, требует отдельного определения — доступ по индексу чего?) важен, на практике исчезающе редки, и, как правило, встречаются в коде, автор которого работает с юникодом неправильно.
Saffron
18.10.2016 13:13Да что тут думать, мутации в генетическом алгоритме. Взять половину символов. Ну ладно, общую длину строки можно предвычислить, а как насчёт того, чтобы взять вторую половину? Первую-то легко.
khim
18.10.2016 22:51+1Да что тут думать, мутации в генетическом алгоритме. Взять половину символов.
Какую практическую задачу вы решаете? И почему вы используете строки, а не какие-нибудь trie деревья?
А то так можно договориться до того, что обращение по индексу отлично решает задачу обращения по индексу.
Googolplex
18.10.2016 01:39+1Важно знать об этом и помнить; думаю Googolplex именно на это хотел обратить внимание всех читателей.
Да, всё так и есть. По моему мнению, нельзя говорить что "в таком-то языке строки в UTF-16", если этот язык позволяет легко и походя сконструировать строку, которая валидной UTF-16-последовательностью не является. Даже если этот язык и предоставляет какие-то методы для работы с суррогатными парами и даже если, скажем, методы типа reverse() умеют работать с суррогатными парами.
Googolplex
18.10.2016 01:27+1Проблема здесь в том, что в джаве работа с "символами" предоставляется таким образом, как будто строки это просто массивы char'ов (собственно, внутри так и есть), что с точки зрения UTF-16 некорректно. Пример того, как аналогичная проблема решается правильно — в Rust, где используется UTF-8 (переменной длины), и при этом гарантируется корректность внутреннего представления строки.
kdenisk
14.10.2016 09:39+1В Java и в самом деле есть полная поддержка UTF-16 ровно в том смысле, что при работе со строками учитывается существование символов мне МЯП/BMP и наличие суррогатных пар. Но так было не всегда и до пятой версии Java использовала UCS-2.

При этом в Java, в силу исторических причин, мы работаем не с юникод-символами, а напрямую с кодовыми квантами UTF-16. Поэтому, как вы верно заметили, при неаккуратной работе со строками можно получить некорректную с точки зрения UTF-16 последовательность таких квантов.Googolplex
18.10.2016 01:32То, что в джаве есть методы, которые позволяют "исследовать" code point'ы UTF-16, не значит, что сами строки в ней представлены в UTF-16. Если бы в Java гарантировалась корректность того, что строка всегда валидная с точки зрения UTF-16, то тогда бы я согласился, но к сожалению это не так. Например, какой-нибудь substring() совершенно замечательно позволит распилить суррогатную пару пополам. А в Rust, например, аналогичная операция над UTF-8 строками невозможна, просто нет соответствующих методов. Если есть нужда в подобных операциях, строку всегда можно сконвертировать в срез байтов и работать с ним.
Googolplex
18.10.2016 01:42Вернее, в Rust методы есть (например, слайсинг строк типа
s[1..3]), но эти методы будут паниковать, если смещения указывают в середину code point'ов.
hdfan2
14.10.2016 09:43В Windows уже с Win2000 используется UTF-16. До этого, действительно, только UCS-2.

sasha1024
14.10.2016 04:12+10Важно ещё следующее: один символ Юникода — не значит визуально один элемент.
Во-первых, есть combining character'ы. Это символы, которые визуально меняют предшествующие символы (например, добавляют какую-то диактрику). Т.е. строка Юникода состоит из т.н. base character'ов («обычные» символы, например «е») и т.н. combining character sequence'ов, каждый из последних (в норме, иначе это invalid combining character sequence) состоит из base character'а и одного-или-более combining character'а (например, «е»+« ?»+« ?»=«е??»). Не путать это с суррогатными парами (суррогатная пара — это представление ОДНОГО символа несколькими двухбайтными словами в UTF-16).
Во-вторых, даже base character'ы (которые формально не относятся к combining character'ам) могут лепиться несколько штук в один визуальный элемент. Сюда относятся, например, корейские согласные/гласные/завершающие. Например, «?»+«?»+«?»=«???» (но «?я» или «я?» или «??» не слепляются). Это Hangul (корейский алфавит), возможно, существуют и другие письменности, которые лепят символы в один визуальный элемент.
Для визуального элемента существует отдельный термин (grapheme, что ли?).
P.S.: Рекомендую сервис http://qaz.wtf/u/show.cgi, чтобы увидеть из чего состоит строка. Например, вставляете «е??», а оно выдаёт.sasha1024
14.10.2016 04:37+4При этом некоторые визуальные элементы можно представить несколькими способами.
Например, «е»+« ?»+« ?»=«е??» и «е»+« ?»+« ?»=«е??».
Кроме того, есть символы, выглядящие аналогично какой-то последовательности символов (например, «ё» можно написать отдельным символом, а можно двумя: «е»+« ?»=«е?»).
Чтобы разобраться в этой каше, существуют операции канонической композиции (по возможности представить покороче) и канонической декомпозиции (по возможности представить подлинее) — при этом в тех местах, где порядок символов безразличен, он меняется на стандартный.
Envek
14.10.2016 21:35+3И вот тут, если вы пользуетесь и Mac OS X и Linux (или разрабатываете программу, которая должна пересылать файлы с одного на другое), то вы должны знать о существовании композиции и декомпозиции, потому что файл, названный по русски (по крайней мере с буквами Ё и Й в названии) нельзя просто так взять и перенести с одной системы в другую. Его имя нужно перекодировать. Из UTF-8 в UTF-8. Да, из одной и той же кодировки в ту же самую. Только OS X хранит имя файла в декомпозированном виде (UTF-8 NFD), т.е. Й хранится как И и следом за ней комбинирующий символ, а Linux — в композированном (UTF-8 NFC).
Поэтому на OS X нужно ставить свежий rsync из brew (потому что Apple традиционно кладёт в дистрибутив тухлые версии системного софта) и использовать ключик
--iconv=UTF-8-MAC,UTF-8всегда. Такие дела.
См. http://serverfault.com/a/627567/135595 и http://askubuntu.com/q/533690/167201
ZyXI
16.10.2016 16:01+2В linux большинство ФС не требует хранения UTF-8 NFC, а просто хранят последовательность байт без учёта кодировки вообще, за исключением работы с ФС, которым есть до этого какое?то дело (т.е. в случае с ФС, используемыми в Windows и Mac OS). Нет никаких проблем с тем, чтобы использовать UTF-8 NFD на linux, кроме того, что при наборе «й» на клавиатуре вы получите один символ (и, соответственно, у вас будут проблемы с набором имён файлов).
kdenisk
14.10.2016 09:56+1Абсолютно верное замечание. Я намерено не стал включать такие подробности в статью, т.к. тут есть о чём поговорить на отдельный материал.
Единица, воспринимаемая пользователем как единый символ, называется графемным кластером.

splatt
14.10.2016 05:52+3Единственное, чего я не могу понять — зачем нужно было добавлять в юникод Эмодзи.
Как по мне, так это полный бред. Во-первых, нужно отделять мух от котлет, и не засорять пространство юникода де-факто картинками. А во-вторых, непонятно как их отображать — стандарта нет, никаких правил нет. Если для обычного текста существуют хоть какие-то правила, сформулированные в современной калиграфии и типографике (высота строки, выносные элементы, моноширинность итд + правила начертания для каждого отдельного языка), и этим правилам подчиняются создатели шрифтов, то что делать с эмодзи — вообще непонятно.
В результате имеем что имеем — в очередной раз, каждый производитель лепит свой собственный набор эмодзи, стандартизированного набора шрифтов или начертаний нет, в результате вы на андроиде имели ввиду одно, а ваша бабушка с айфоном приняла это за другое. Приехали.hdfan2
14.10.2016 09:49+3Хотя я тоже не люблю эти эмодзи, но причину их включения в юникод в принципе понимаю. Это универсальный стандарт для их передачи. Раньше лепили кто во что горазд, типа :-). Из-за этого, кстати, возникает сильно бесящая проблема со всякими скайпами, которые преобразуют все похожие последовательности в эти дебильные смайлики, особенно куски кода (скажем, присылают тебе стектрейс, где есть что-то типа «Class::Property», а там все :P заменены на смайлик с высунутым языком. Хочется взять и… сделать что-нибудь нехорошее. К счатью, это отключается). С эмодзи в юникоде такой проблемы нет.
molnij
14.10.2016 18:22+2На мой вкус, смайлы куда более универсальный стандарт.
:), :-), ^-^, O_O — одинаково распознаются в любой программе и шрифте. В отличие от миллиарда эмодзи, неизвестно присутствующих в очередной программе\шрифте или нет. Вопрос автозамены — вопрос к мессенджерам (у известных мне была опция отключения)sasha1024
14.10.2016 19:47Ой не универсальный.
1. Вам никогда не приходили %), %|, :-*, :-P и др.?
2. Даже если брать стандартный :), что это: насмешка, смущённая улыбка или радость?
3. По факту, автозамена происходит. Отключить — иногда даже хуже, не отключив, ты хоть знаешь, когда собеседнику пришло покорёженное, а так полная угадайка. Особый шик, когда люди пользуются разными клиентами, и тебе приходит что-то типа «*STOP*» (угадайте что этоЭто девушка прощалась. Смайл *STOP* выглядел в её клиенте как поднятая вверх ладонь руки. Она интерпретировала этот жест как помахать на прощание.molnij
16.10.2016 23:00+21. Два крейзи-смайла, крайне редко встречались вне иконизированных мессенджеров. :-* — поцелуй, :-P — высунутый язык. Где сложность?
2. Это улыбка. Трактуется, как и обычная улыбка в контексте. Беседы и собеседника. Может быть всеми тремя и еще пачкой других.
3. Отключить — это если у вас есть регулярное перекидывание исходников, где оно напрягает. Да и то, обычно копипаст из мессенджера в любой блокнот спасает. Не знаю. У меня года полтора было отключено автораспознавание — остальное время как-то справлялся.
Эмодзи… это унылая попытка стандартизировать мимику и жесты. Безумно раздувающая размер шрифтов (мне где-то попадалась жалоба, что если включить шрифт с полным набором этой дряни, то программа автоматически тяжелеет едва ли не на пару десятков мегабайт).
Те же смайлы за все время их существования успешно развивались в рамках того небольшого набора символов который уже существовал. Сначала пришло редуцирование носа :-) => :), потом появились горизонтальные смайлы О_О и т.п. Эмодзи — это путь в никуда. Вы не отрисуете все эмоции, вы не отрисуете все флаги, вы не отрисуете все-что-только-можно придумать. Это по сути попытка засунуть в шрифт все клипарты на все темы — идея заведомо не имеющая смысла.

a-motion
14.10.2016 09:47-2А что из всего этого входит в «необходимый практический минимум»?
Как отличить, и вообще что делать с «n» и «n?» (это совершенно разные последовательности символов, в них даже количество использованных байт отличается)? Как использовать в регулярках? Что делать, если в каком-нибудь прикладном языке мы получаем ошибку кодирования в utf-8 (вот это — абсолютный чемпион по количеству вопросов на SO)? Как правильно сравнивать строки? Реализация в разных языках? Почему умер UCS2 и чем плох UTF-16? Может быть, хоть что-то практическое?
> Приведённой выше информации вполне достаточно, чтобы не путаться
> в основных принципах и работать с текстом в большинстве повседневных задач
Да, если повседневные задачи у вас сводятся к чтению текста с экрана монитора. На гиктаймс вас что, не пускают?
kdenisk
14.10.2016 10:05+4Верный способ сделать плохую статью — напихать в неё всё и сразу. Это будет много воды для людей, хорошо разбирающихся в теме, и слишком много букв для только начинающих в ней осваиваться. Если пойти от частого к редкому, то больше шансов сделать полезный всем материал, что я и собираюсь сделать в будущих статьях.
Спасибо за подсказку по вопросам, о которых стоит рассказать.a-motion
14.10.2016 11:20-5Серьезно? Спасибо? Сиречь, вы начали «цикл статей» вот этой бессмысленной водой, даже не имея представления о том, о чем действительно нужно рассказать?
И ваше «спасибо» блестяще смотрится на фоне того, что вы поленились вывести из «засеренного» мой комментарий, хотя в нем практической информации больше, чем во всех 100500 знаках вашей записи.
Если в мире в 2016 существует программист, который не в курсе, чем UTF-8 отличается от UTF-16, и что не так с однобайтными кодировками, то он и так неплохо зарабатывает на допиливании COBOL-монстров в Кремниевой долине.

snuk182
14.10.2016 10:32+2Ожидал увидеть перевод блестящего опуса Спольски
kdenisk
14.10.2016 11:05+4Перевод уже есть на Хабре: Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом + часть 2
Я, конечно, статью Спольски читал и вдохновился её простой. Но хорошего материала по Unicode на русском языке объективно мало, а поговорить есть о чём. Так что, уверен, моя статья не будет лишней, а цель на будущее — сделать качественный материал по всем основным аспектам Юникода.
fantomius
15.10.2016 12:06+4Спасибо, отличная статья! Я бы порекомендовал Вам сделать акцент на том, что Unicode решает проблемы отображения текста, но не решает проблемы при работе с ним. Например, без знания локали невозможно сделать Uppercase. Буква i может перейти как в I (английский) так и в I (турецкий).
khim
17.10.2016 16:54+2Там много чего есть. Начнём с того, что кроме uppercase и lowercase есть ещё и titlecase! Но один взгляд на три символа для которых titlecase != uppercase вам всё прояснит:
?
А есть много заморочек где всё не так просто…
?
?

akzhan
BTW, "Windows uses UTF-16 internally"
Можно дополнить к Java, ибо распространенная платформа. Речь о ядре Win32/Win64. про Win16 не помню уже.
kdenisk
Всё верно. Обязательно добавлю.
Bozaro
Windows, к примеру, позволяет создавать файлы, которые могут содержать не корректную UTF-16 последовательность.
Из-за этого, в частности, родилось надмножество над UTF-8 для кодирования таких последовательностей с замечательным названием WTF-8: https://simonsapin.github.io/wtf-8/
kdenisk
Интересно, не знал раньше об этом.