
За последние несколько лет тема производительности сетевого стека Linux обрела особую актуальность. Это вполне понятно: объёмы передаваемых по сети данных и соответствующие нагрузки растут не по дням, а по часам.
И даже широкое распространение сетевых карт 10GE не решает проблемы: в самом ядре Linux имеется множество «узких мест», которые препятствуют быстрой обработке пакетов.
Предпринимаются многочисленные попытки эти «узкие места» обойти. Техники, используемые для обхода, так и называются — kernel bypass (с кратким обзором можно ознакомиться, например, здесь). Они позволяют полностью исключить сетевой стек Linux из процесса обработки пакетов и сделать так, чтобы приложение, работающее в пользовательском пространстве, взаимодействовало с сетевым устройством напрямую. Об одном из таких решений — DPDK (Data Plane Development Kit), разработанном компанией Intel — мы и хотели бы поговорить в сегодняшней статье.
О DPDK существует множество публикаций, в том числе и на русском языке (см., например: 1, 2 и 3). Среди этих публикаций есть и весьма неплохие, но они не отвечают на самый главный вопрос: как именно происходит обработка пакетов с использованием DPDK? Из каких этапов состоит путь пакета от сетевого устройства к пользователю?
Именно на эти вопросы мы и попытаемся ответить. Чтобы найти ответы, нам пришлось проделать огромную работу: так как в официальной документации мы всей нужной информации не нашли, то нам пришлось ознакомиться с массой дополнительных материалов и погрузиться в изучение исходников… Впрочем, обо всём по порядку. И прежде чем говорить о DPDK и о том, какие проблемы он помогает решить, нам нужно вспомнить, как осуществляется обработка пакетов в Linux. С этого мы и начнём.
Обработка пакетов в Linux: основные этапы
Итак, когда пакет поступает на сетевую карту, он копируется оттуда копируется в основную память с помощью механизма DMA — Direct Memory Access.
UPD. Уточнение: на новом «железе» пакет копируется в Last Level Cache того сокета, откуда был инициирован уже DMA, а оттуда уже оттуда в память. Спасибо izard.
После этого требуется сообщить системе о появлении нового пакета и передать данные дальше, в специально выделенный буфер (Linux выделяет такие буферы для каждого пакета). Для этой цели в Linux используется механизм прерываний: прерывание генерируется всякий раз, когда новый пакет поступает в систему. Затем пакет ещё нужно передать в пользовательское пространство.
Одно «узкое место» уже очевидно: чем больше пакетов приходится обрабатывать, тем больше на это уходит ресурсов, что отрицательно сказывается на работе системы в целом.
UPD. В современных сетевых картах используется технология interrupt moderation (на русский язык это выражение иногда переводят как «координация прерываний»), c помощью которой можно снизить количество прерываний и разгрузить процессор. За уточнение спасибо T0R.
Данные пакета, как уже было сказано выше, хранятся в специально выделенном буфере, или, говоря точнее — в структуре sk_buff. Эта структура выделяется для каждого пакета и освобождается, когда пакет попадает в пользовательское пространство. На эту операцию расходуется очень много циклов шины (т.е. циклов, передающих данные из CPU в основную память).
Со структурой sk_buff есть ещё один проблемный момент: сетевой стек Linux изначально старались сделать так, чтобы он был совместим с как можно большим количеством протоколов. Метаданные всех этих протоколов включены и в структуру sk_buff, но для обработки конкретного пакета они могут быть просто не нужны. Из-за чрезмерной сложности структуры обработка замедляется.
Ещё одним фактором, отрицательно влияющим на производительность, является переключение контекста. Когда приложению, запущенному в пользовательском пространстве, требуется принять или отправить пакет, оно делает системный вызов, и происходит переключение контекста в режим ядра, а затем — обратно в пользовательский режим. Это сопряжено с ощутимыми затратами системных ресурсов.
Чтобы решить часть описанных выше проблем, в ядро Linux начиная с версии ядра 2.6 был добавлен так называемый NAPI (New API), в котором метод прерываний сочетается с методом опроса. Рассмотрим вкратце, как это работает.
Сначала сетевая карта работает в режиме прерываний, но как только пакет поступает на сетевой интерфейс, она регистрирует себя в poll-списке и отключает прерывания. Система периодически проверяет список на наличие новых устройств и забирает пакеты для дальнейшей обработки. Как только пакеты обработаны, карта будет удалена из списка, а прерывания включатся снова.
Мы описали процесс обработки пакетов очень бегло. С более детальным описанием можно ознакомиться, например, в цикле статей в блоге компании Private Internet Access. Однако даже краткого рассмотрения достаточно, чтобы увидеть проблемы, из-за которых скорость обработки пакетов замедляется. В следующем разделе мы опишем, как эти проблемы решаются с помощью DPDK.
DPDK: как это работает
В общих чертах
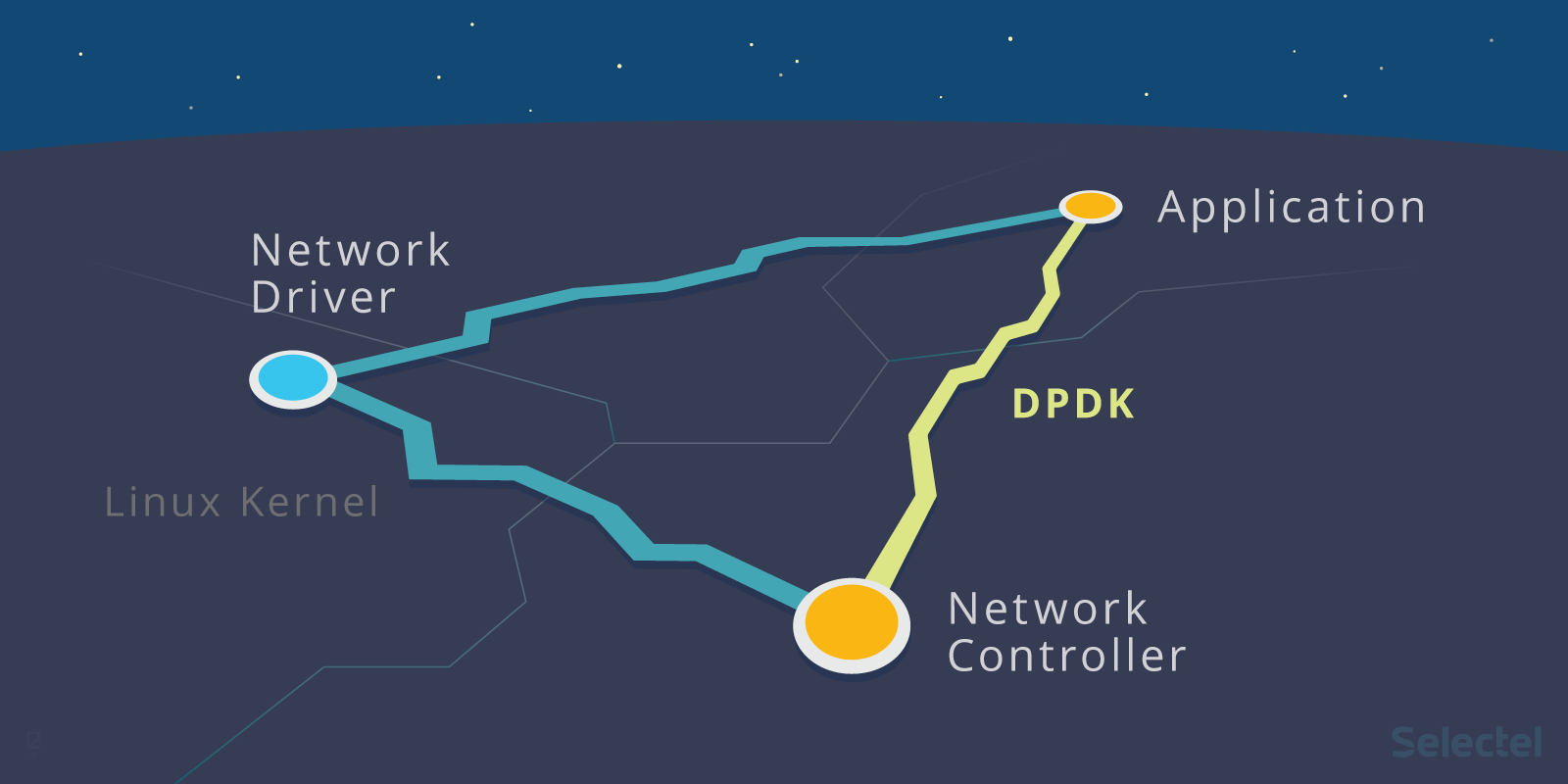
Рассмотрим следующую иллюстрацию:

Слева представлен процесс обработки пакетов «традиционным» способом, а справа — с использованием DPDK. Как видим, во втором случае ядро не задействовано вообще: взаимодействие с сетевой картой осуществляется через специализированные драйверы и библиотеки.
Если вы уже читали о DPDK или имеете хотя бы небольшой опыт работы с ним, то знаете, что порты сетевой карты, на которые будет поступать трафик, потребуется вообще вывести из-под управления Linux — это делается при помощи команды dpdk_nic_bind (или dpdk-devbind), а в более ранних версиях) — ./dpdk_nic_bind.py.
Как происходит передача портов под управление DPDK? У каждого драйвера в Linux есть так называемые bind- и unbind-файлы. Есть они и у драйвера сетевой карты:
ls /sys/bus/pci/drivers/ixgbe
bind module new_id remove_id uevent unbind
Чтобы открепить устройство от драйвера, нужно записать номер шины этого устройства в unbind-файл. Соответственно для передачи устройства под управление другого драйвера потребуется записать номер шины в его bind-файл. Более подробно об этом можно прочитать в этой статье.
В инструкциях по установке DPDK указывается, что порты нужно передать под управление драйвера vfio_pci, igb_uio или uio_pci_generic.
Все эти драйверы (подробно разбирать их особенности в рамках этой статьи мы не будем; заинтересованных читателей отсылаем к статьям на kernel.org: 1 и 2) делают возможным взаимодействие с устройствами в пользовательском пространстве. Конечно, в их состав входит и модуль ядра, но его функции сводятся к инициализации устройств и предоставлению PCI-интерфейса.
Всю дальнейшую работу по организации общения приложения с сетевой картой берёт на себя входящий в DPDK драйвер PMD (сокращение от poll mode driver). В DPDK имеются PMD-драйверы для всех поддерживаемых сетевых карт, а также для виртуальных устройств (за уточнение спасибо T0R).
Для работы с DPDK необходимо также настроить большие страницы памяти (hugepages). Это нужно, чтобы
снизить нагрузку на TLB.
Все нюансы мы более подробно обсудим ниже, а пока кратко опишем основные стадии обработки пакетов с использованием DPDK:
- Поступившие пакеты попадают в кольцевой буфер (его устройство мы разберём в следующем разделе). Приложение периодически проверяет этот буфер на наличие новых пакетов.
- Если в буфере имеются новые дескрипторы пакетов, приложение обращается к буферам пакетов DPDK, находящимся в специально выделенном пуле памяти, через указатели в дескрипторах пакетов.
- Если в кольцевом буфере нет никаких пакетов, то приложение опрашивает находящиеся под управлением DPDK сетевые устройства, а затем снова обращается к кольцу.
Рассмотрим внутреннее устройство DPDK более детально.
EAL: абстракция окружения
EAL (Environment Abstraction Layer, уровень абстракции окружения) — это центральное понятие DPDK.
EAL — это набор программных инструментов, которые обеспечивают работу DPDK в конкретном аппаратном окружении и под управлением конкретной операционной системы. В официальном репозитории DPDK библиотеки и драйверы, входящие в состав EAL, хранятся в директории rte_eal.
В этой директории хранятся драйверы и библиотеки для Linux и BSD-систем. Имеются также наборы заголовочных файлов для различных процессорных архитектур: ARM, x86, TILE64, PPC64.
К программам, входящим в EAL, мы обращаемся при сборке DPDK из исходного кода:
make config T=x86_64-native-linuxapp-gcc
В этой команде, как не трудно догадаться, мы указываем, что DPDK нужно собрать для архитектуры x86_84, OC Linux.
Именно EAL обеспечивает «привязку» DPDK к приложениям. Все приложения, использующие DPDK (см. примеры здесь), обязательно включают входящие в состав EAL заголовочные файлы.
Перечислим наиболее употребительные из них:
- rte_lcore.h — функции управления процессорными ядрами и сокетами;
- rte_memory.h — функции управления памятью;
- rte_pci.h — функции, обеспечивающие интерфейс доступа к адресному пространству PCI;
- rte_debug.h — функции трассировки и отладки (логгирование, dump_stack и другие);
- rte_interrupts.h — функции по обработке прерываний.
Более подробно об устройстве и функциях EAL можно прочитать в документации.
Управление очередями: библиотека rte_ring
Как мы уже говорили выше, пакет, поступивший на сетевую карту, попадает в приёмную очередь, которая представляет собой кольцевой буфер. В DPDK вновь прибывшие пакеты тоже помещаются в очередь, реализованную на базе библиотеки rte_ring. Все приводимые ниже описания этой библиотеки основаны на руководстве разработчика, а также на комментариях к исходному коду.
При разработке rte_ring за основу была взята реализация кольцевого буфера для FreeBSD.Если вы заглянете в исходники, то обратите внимание на такой комментарий: Derived from FreeBSD’s bufring.c.
Очередь представляет собой кольцевой буфер без блокировок, организованный по принципу FIFO (First In, First Out). Кольцевой буфер — это таблица указателей на хранимые в памяти объекты. Все указатели делятся на четыре типа: prod_tail, prod_head, cons_tail, cons_head.
Prod и cons — это сокращения от producer (производитель) и consumer(потребитель). Производителем (producer) называется процесс, который записывает данные в буфер в текущий момент, а потребителем — процесс, который в текущий момент данные из буфера забирает.
Хвостом (tail) называется место, куда в текущий момент осуществляется запись в кольцевой буфер. Место, откуда, в текущий момент осуществляется считывание из буфера, называется головой (head).
Смысл операции постановки в очередь и выведения из очереди заключается в следующем: при добавлении нового объекта в очередь в итоге всё должно получиться так, что указатель ring->prod_tail будет указывать на то место, куда ранее указывал ring->prod_head.
Здесь мы приводим лишь краткое описание; более подробно о сценариях работы кольцевого буфера можно прочитать в руководстве разработчика на сайте DPDK.
Из преимуществ такого подхода к управлению очередями следует выделить, во-первых, более высокую скорость записи в буфер. Во-вторых, при выполнении операций массовой постановки в очередь и массового выведения из очереди промахи кэша имеют место гораздо реже, потому что указатели хранятся в таблице.
Недостатком реализации кольцевого буфера в DPDK является фиксированный размер, который невозможно увеличить «на лету». Кроме того, на работу с кольцевой структурой расходуется гораздо больше памяти, чем на работу со связанным списком: в кольце всегда используется максимально возможное количество указателей.
Управление памятью: библиотека rte_mempool
Мы уже говорили выше, что для работы DPDK нужны большие страницы памяти (HugePages). В инструкциях по установке рекомендуется создавать HugePages размером по 2 мегабайта.
Эти страницы объединяются в сегменты, которые затем делятся на зоны. В зоны уже помещаются объекты, создаваемые приложениями или другими библиотеками — например, очереди и буферы пакетов.
К числу таких объектов принадлежат и пулы памяти, которые создаёт библиотека rte_mempool. Это пулы объектов фиксированного размера, которые используют rte_ring для хранения свободных объектов и могут быть идентифицированы по уникальному имени.
Для улучшения производительности могут использоваться техники выравнивания памяти.
Несмотря на то, что доступ к свободным объектам организован на базе кольцевого буфера без блокировок, затраты системных ресурсов могут быть очень большими. К кольцу имеют доступ несколько процессорных ядер и всякий раз, когда ядро обращается к кольцу, нужно осуществлять операцию сравнения с обменом (compare and set, CAS).
Чтобы кольцо не стало «узким местом», каждое ядро получает дополнительный локальный кэш в пуле памяти. Ядро имеет полный доступ к кэшу свободных объектов с помощью механизма блокировок. Когда кэш заполняется или освобождается полностью, пул памяти обменивается данными с кольцом. Таким образом обеспечивается доступ ядра к часто используемым объектам.
Управление буферами: библиотека rte_mbuf
В сетевом стеке Linux, как это уже было отмечено выше, для представления всех сетевых пакетов используется структура sk_buff. В DPDK для этой цели используется структура rte_mbuf, описанная в заголовочном файле rte_mbuf.h.
Подход к управлению буферами в DPDK во многом напоминает тот, что используется в FreeBSD: вместо одной большой структуры sk_buff — много буферов rte_mbuf небольшого размера. Буферы создаются до запуска приложения, использующего DPDK, и хранятся в пулах памяти (для выделения памяти используется библиотека rte_mempool).
Помимо собственно данных пакета каждый буфер содержит и метаданные (тип сообщения, длина, адрес начала сегмента данных). Буфер также содержит указатель на следующий буфер. Это нужно для работы с пакетами, содержащими большое количество данных — в этом случае пакеты можно объединять (так же, как это делается в FreeBSD — подробнее об этом можно прочитать, например, здесь).
Другие библиотеки: краткий обзор
В предыдущих разделах мы описали лишь самые основные библиотеки DPDK. Но есть ещё множество других библиотек, рассказать о которых в рамках одной статьи вряд ли возможно. Поэтому мы ограничимся лишь кратким обзором.
С помощью библиотеки LPM в DPDK реализуется алгоритм Longest Prefix Match (LPM), используемый для пересылки пакетов в зависимости от их IPv4-адреса. Основные функции этой библиотеки заключаются в добавлении и удалении IP-адресов, а также в поиске нового адреса с использованием LPM-алгоритма.
Для IPv6-адресов аналогичная функциональность реализована на базе библиотеки LPM6.
В других библиотеках похожая функциональность реализована с помощью хэш-функций. С помощью rte_hash можно осуществлять поиск по большому набору записей с использованием уникального ключа. Эту библиотеку можно использовать, например, для классификации и распределения пакетов.
Библиотека rte_timer обеспечивает асинхронное выполнение функций. Таймер может выполняться как один раз, так и периодически.
Заключение
В этой статье мы попытались рассказать о внутреннем устройстве и принципах работы DPDK. Попытались, но не рассказали до конца — тема эта настолько сложна и обширна, что одной статьи явно не хватит. Поэтому ждите продолжения: в следующей статье мы более подробно поговорим о практических аспектах использования DPDK.
В комментариях мы с удовольствием ответим на все ваши вопросы. А если у кого-то из вас есть опыт использования DPDK, то будем признательны за любые замечания и дополнения.
Для всех, кто хочет узнать больше, приводим полезные ссылки по теме:
- http://dpdk.org/doc/guides/prog_guide/ — детальное (хотя местами запутанное) описание всех библиотек DPDK;
- https://www.net.in.tum.de/fileadmin/TUM/NET/NET-2014-08-1/NET-2014-08-1_15.pdf — краткий обзор возможностей DPDK, сравнение с другими фреймворками аналогичного плана (netmap и PF_RING);
- http://www.slideshare.net/garyachy/dpdk-44585840 — презентация-введение в DPDK для начинающих;
- http://www.it-sobytie.ru/system/attachments/files/000/001/102/original/LinuxPiter-DPDK-2015.pdf — презентация с объяснениями устройства DPDK.
Если вы по каким-то причинам не можете оставлять комментарии здесь — добро пожаловать в наш корпоративный блог.
Комментарии (14)

router
20.10.2016 15:00+1
T0R
21.10.2016 19:12+1День добрый! Пожалуй поворчу немного, вы уж сильно не обижайтесь =)
Intel DPDK
Уже без Intel, просто DPDK
Они позволяют полностью исключить сетевой стек Linux из процесса обработки пакетов и сделать так, чтобы приложение, работающее в пользовательском пространстве, взаимодействовало с сетевым устройством напрямую
Необходимо понимать, что
DPDK is not a networking stack
по этому слинковать приложение, используюещее сокет апи с дпдк просто так в лоб не получится (на самом деле на сегодняшний день существует ряд TCP стеков поверх дпдк — rumptcp, mtcp(кстати от автора packetshader))
когда пакет поступает на сетевую карту, он сначала попадает в специальную кольцевую структуру, — приёмную очередь (receive queue или просто RX). Оттуда он копируется в основную память с помощью механизма DMA — Direct Memory Access.
На самом деле кольцевая структура — rx ring — это кольцо дескрипторов. В этой структуре не содержатся сами пакеты (они сперва попадают в fifo буфер NIC), там содержатся указатели на область памяти, куда делать DMA + ряд других полей, куда NIC пишет после успешного DMA (write back), например длина пакета, оффлоадинг флаги итд.
прерывание генерируется всякий раз, когда новый пакет поступает в систему
Современные сетевые умеют в interrupt moderation
Что касается sk_buff, да структура очень разрослась, к тому же поля расположены не лучшим образом.
входящий в DPDK драйвер PMD
На самом деле на данный момент в библиотеке целый скоп различных PMD для большинства современных сетевых карт + PMD виртуальных устройств + misc (af_packet, pcap, null etc...)
Для работы с DPDK необходимо также настроить большие страницы памяти (hugepages). Это нужно, чтобы выделять большие регионы памяти и записывать в них данные.
Это нужно для того, чтобы не вымывать дичайше TLB
Можно сказать, что hugepages в DPDK выполняют ту же роль, что механизм DMA в традиционной обработке пакетов.
Што?
заключается в том, чтобы поменять голову и хвост местами
Нет. Во-первых, то, что вы называете головой и хвостом в rte_ring.h называется prod.head и cons.head
Во-вторых, в случае enqueue CAS'ом апдейтится prod.head (увеличивается на кол-во вставляемых объектов)
__rte_ring_mp_do_enqueue()
, а в случае dequeue — cons.head.
__rte_ring_mc_do_dequeue()
во многом напоминает тот, что используется в FreeBSD: вместо одной большой структуры sk_buff — много буферов rte_mbuf небольшого размера.
Ничего не понятно что вы имели ввиду. С одной стороны — да, rte_mbuf сильно меньше sk_buff, но его нельзя сравнивать с так же разросшимся mbuf во FreeBSD. Более того, во Фре есть сами mbuf, которые могут нести короткие пакеты (если я не ошибаюсь до 128 байт) и mbuf_cluster — соответственно для больших.
Что же касается причин столь высокой производительности библиотек — их пишут довольно квалифицированные люди. На вскидку для ускорения обработки используются техники: выравнивание, батч обработка пакетов (+ векторизация), префетчинг (особенно полезен при пайплайнинге), поллинг (отказ от прерываний), использование hugepages (меньше трешим TLB), lockless fastpath (должны отсутствать блокировки в коде обработки пакетов), тред аффинити (меньше трешит кеши), итд.
Вот для примера Брюс Ричардсон несколько часов назад читал доклад, в котором показал один из кейсов поиска узкого места.
В любом случае — спасибо за популяризацию DPDK.
AndreiYemelianov
24.10.2016 10:33+1К сожалению, в течение последних двух дней был вдалеке от компьютера и Интернета, поэтому отвечаю только сейчас.
… вы уж сильно не обижайтесь =)
Обижаться и никто и не собирается =) Более того, моя реакция будет совершенно противоположной: я очень рад, что вы внимательно прочитали статью и благодарен вам за конструктивные замечания. Вообще, обижаться на критику, если она конструктивная — это не про меня. Я не боюсь признавать свои ошибки, а тот же Хабр считаю местом не для демонстрации собственной крутизны, а для дискуссий, взаимного обучения и обмена мнениями.
по этому слинковать приложение, используюещее сокет апи с дпдк просто так в лоб не получится (на самом деле на сегодняшний день существует ряд TCP стеков поверх дпдк — rumptcp, mtcp(кстати от автора packetshader))
Прекрасно понимаю и сейчас жалею, что ясно не выразил это в тексте.Спасибо за замечание. Про TCP-стеки поверх DPDK обязательно почитаю поподробнее (кстати, если знаете полезные ссылки по теме, буду очень признателен).
На самом деле кольцевая структура — rx ring — это кольцо дескрипторов. В этой структуре не содержатся сами пакеты (они сперва попадают в fifo буфер NIC), там содержатся указатели на область памяти, куда делать DMA + ряд других полей, куда NIC пишет после успешного DMA (write back), например длина пакета, оффлоадинг флаги итд.
Это я знаю; в тексте выразился не совсем удачно. Все указанные вами сомнительные и неудачные фразы я либо отредактировал, либо вообще убрал.
… то, что вы называете головой и хвостом в rte_ring.h называется prod.head и cons.head
Это я знаю. Там ещё prod.tail и cons.tail есть. И здесь мы уже из обсуждения чисто технических деталей смещаемся в плоскость терминологии и стилистики. Конечно, в тексте можно писать как в rte_ring.h — но это делает его более тяжеловесным и нечитабельным. Я не пурист, не против заимствования терминов из других языков (если в нашем языке таковых нет), но ералаша из русских и латинских букв в тексте не люблю. К тому же термины «голова» и «хвост» применительно к кольцевому буферу в русском языке можно считать общеупотребительными.
Ничего не понятно что вы имели ввиду. С одной стороны — да, rte_mbuf сильно меньше sk_buff, но его нельзя сравнивать с так же разросшимся mbuf во FreeBSD.
Насколько я понимаю, истоки идеи, лежащей в основе rte_mbuf, восходят к FreeBSD. Если в Linux для всех типов пакетов используется структура sk_buff (о недостатках такого подхода мы уже говорили выше), то в FreeBSD используются mbuf, которая гораздо меньше по размеру и которые для обработки больших пакетов могут объединяться друг с другом (как buffer chaining в DPDK). Когда я прочитал про rte_mbuf, мне это сразу напомнило «фряху».
Вот для примера Брюс Ричардсон несколько часов назад читал доклад, в котором показал один из кейсов поиска узкого места.
За ссылку на доклад огромное спасибо!
В заключение хочу ещё раз поблагодарить вас за все высказанные замечания, эта как раз так критика, которая помогает нам стать лучше =). Именно ваш комментарий оказался самым ценным из всех.
При работе над следующей статьёй многие ваши замечания я буду держать в уме.
И хотел бы спросить: а где вы так хорошо изучили DPDK? используете ли вы DPDK для решения каких-то практических задач? Заранее благодарю и надеюсь на продолжение диалога.
T0R
26.10.2016 15:05Ну, я бы не сказал что достаточно хорошо знаю DPDK, не смотря на то, что работаю с ним начиная с версии 1.2.3 и порой комичу. И да, использую его для решения своих практических задач.

Ivan_83
24.10.2016 04:11Фигня какая то, тянет на введение но сильно растянуто.
Весь профит в DPDK и netmap в том что оно zerocopy, которое реализуется так: приложение выделяет буфер и далее сетевухе даёт указание складывать туда поступившие пакеты. Сетевуха туда используя DMA заливает пакеты.
Далее на выбор остаётся использовать поллинг или прерывания для того чтобы понять что пакеты пришли. Вообще от поллинга отказались, ибо проц в холостую пашет, но зато задержки типа меньше.
И DPDK и netmap дают доступ к эзернет фреймам, те весь эзернет, IP и всё что выше надо самому или через какой то готовый стёк пускать.
DPDK вроде как прибит на гвозди к интелу.
netmap работает с кучей железа, там есть какие то минимальные требования к самим сетевухам, типа наличия DMA и колец дескрипторов.
Автор — Луиджи впилил поддержку в дрова реалтека, интела и пр.
Что касается mbuf во фре, то они не менялись со времён FreeBSD 7, вернее кажется там пара флагов добавилась, но место для них было и сама структура не поменялась.AndreiYemelianov
24.10.2016 11:00+1Вообще от поллинга отказались, ибо проц в холостую пашет, но зато задержки типа меньше.
Если честно, не понял, что вы имеете в виду. Попробуйте, пожалуйста, сформулировать эту мысль другими словами.
DPDK вроде как прибит на гвозди к интелу.
Да, DPDK был создан Intel для собственных сетевых карт. Драйверы для других карт (<a href=«http://dpdk.org/doc/guides/nics/mlx4.html» target="_blank" rel=«nofollow»">Mellanox, Emulex) есть, но с ними далеко не все гладко. Например, во время экспериментов с DPDK мы установили драйвер для Mellanox, но ничего не завелось, хотя всё делали точь-в-точь по инструкции. Зато все получилось сразу, как только мы заменили карту Mellanox на Intel.
netmap работает с кучей железа, там есть какие то минимальные требования к самим сетевухам, типа наличия DMA и колец дескрипторов.
Автор — Луиджи впилил поддержку в дрова реалтека, интела и пр.
Да, netmap гораздо менее «завендорлочен». Ну и тут есть свои подводные камни: например, полноценной поддержки карт Mellanox нет до сих пор (см. здесь).Ivan_83
26.10.2016 23:15Раньше во FreeBSD поллинг был по дефолту в ядре, потом его вынесли даже из генерика и теперь кому надо собирают ядро руками с нужной опцией.
Особого смысла в полинге нет, обычно сетевухи позволяют настроить прерывания хоть на каждый пакет.
Луиджи тоже не может всех делать счастливыми, нужна поддержка — запилите сами, не ждите маны небесной.
2 T0R
Да и пусть крутятся.
Уж не ограничение ли это самого дпдк?
Хз, может и не прибит. Я припоминаю что там какие то вещи в железе должны были быть, и вроде как они интельные были. Но я темой глубоко не интересовался, мне всегда хватало нетграфа во фре.
Я тоже за обычный Си, плюсы слишком перегружены, ИМХО.
T0R
26.10.2016 15:13Вообще от поллинга отказались
А кто отказался то? Если говорить про dpdk — там в основном все приложения крутятся в busy loop.
DPDK вроде как прибит на гвозди к интелу.
Нет, это абсолютно не так.
netmap работает с кучей железа
man netmap
…
netmap supports the following interfaces: em(4), ixgbe(4), re(4)
…
А про dpdk можно почитать прям на главной
It was designed to run on any processors. The first supported CPU was Intel x86 and it is now extended to IBM Power 8, EZchip TILE-Gx and ARM.
Список поддерживаемых сетевых карт
izard
>копируется в основную память с помощью механизма DMA — Direct Memory Access
На достаточно свежем железе, копируется в last level cache того сокета, откуда инициировали DMA. И уже оттуда в память.
Вообще, хороший tutorial, но у читателя может сложиться впечатление (так как имеется сравнение с сетевым стеком линукс), что в dpdk есть сетевой стек, и он, например, умеет работать с tcp — собирать tcp, устанавливать соединение и тд.
bormental
Есть смелые ребята, которые свой TCP написали поверх DPDK: http://www.seastar-project.org/
Пока лично руками не щупал, но в перспективе собираюсь...
izard
Подкрутить к DPDK user mode TCP стэк — обычный пример, но мощИ обычно хватает, если сначала в dpdk app смотреть на пакетик, и отдавать TCP стэку только избранные, редкие flow.
T0R
На систар не смотрел, он на плюсах, по мне так низкоуровневые сетевые вещи должны быть на чистом С (это не предмет для спора, считайте это предубеждениями).
На прошлой неделе в Дублине на dpdksummit в кулуарах общался на тему юзерспейс тсп стеков, узнал много ньюансов из первых рук. Попробую собрать тут по крупицам инфу. На данный момент дела обстоят так:
https://github.com/rumpkernel/drv-netif-dpdk — стек netbsd, как есть, не быстрый, проект не развивается
https://github.com/eunyoung14/mtcp — проект автора packetshader (KyoungSoo Park), так же не блещет скоростью. По словам KyoungSoo их главная цель не скорость, а стройный код и модульность.
https://github.com/scylladb/seastar — C++, больше о нем ничего не знаю
https://github.com/OpenFastPath/ofp — со слов коллег, вроде бы достаточно быстр (локи вычищены), опирается на ODP — абстракцию над DPDK (и не только), имеются проблемы со стабильностью.
https://github.com/opendp/dpdk-ans — закрытые исходники
https://wiki.fd.io/view/Project_Proposals/TLDK — проект, развиваемый в рамках VPP, интел ставит пока на него, правда нет публичной реализации ТСП (есть на данный момент внутри интела)
http://www.6wind.com/solutions/tcp/ — закрытый, коммерческий, но вроде как быстрый
bormental
Спасибо за отличный список и пояснения!
Видно, что многие сейчас работают над быстрым user-level TCP стеком. Что-то явно назревает в лабораториях :)
В идеале хотелось бы получить что-то работающее с boost.asio с минимумом переделок в прикладном коде. Но пока — увы...