
Привет Хабр! Это вторая часть перевода статьи про подсчет различных судоку.

В этой части мы погрузимся в теорию групп, начиная с самых основ, но затрагивая только то, что нам пригодится для ответа на вопрос: а сколько же есть действительно различных судоку — без всяких повторов в виде поворотов, отражений и т.п. Те, кто довольно хорошо знаком с теорией групп — вероятно, найдут тут мало что интересного. Для остальных же почитать очень даже полезно. На всякий случай: я себя специалистом по теории групп не считаю, при переводе статьи я сам по сути изучал ее почти с нуля. То есть, вполне могут быть косяки — пишите мне о них в личку. С другой стороны — я для большинства определений лазил в википедию, а все численные результаты подтвердил собственноручно написанной программой. Так что, по идее, количество косяков должно стремиться к нулю. Но мало ли.
Как обычно, мои комментарии выделены курсивом или спрятаны под спойлеры. Под спойлерами можно найти самое интересное — куски кода, которые верифицируют все числа, полученные в повествовании.
Итак, в предыдущей части статьи мы посчитали, что количество различных сеток судоку равно N=6670903752021072936960?6.671?1021. Но довольно часто мы можем получить одну сетку судоку из другой, применяя простые преобразования. Например, если у нас есть корректно заполненная сетку судоку, то, поворачивая ее на 90°, мы получаем другую сетку, которая отличается от исходной, но все еще остается корректной. На самом деле, мы можем рассматривать эти сетки как одинаковые, поскольку в результате преобразования наша сетка — все еще одно из решений судоку. Аналогично, если мы заменим все 3-ки в сетке на 4-ки, а все 4-ки на 3-ки, то мы получим другую корректную сетку. Мы также могли бы взять какую-нибудь сетку судоку, поменять местами пятую и шестую строки, и, в конце концов, все равно получить корректную сетку. Когда мы делаем такие преобразования, мы сохраняет такое свойство сетки, как ее корректность (В предыдущей части статьи мы делали что-то очень похожее, но только с частью сетки — первой полосой. Теперь же мы играемся со всей таблицей 9?9. Важное отличие в том, что сейчас мы рассматриваем только такие преобразования, которые можно применить к любой сетке (с сохранением корректности), т.е. рассмотренная ранее операция свапания углов прямоугольника внутри сетки судоку не подходит, так как к некоторым сеткам она применима, а к некоторым — нет.).
Операции такого вида называются симметриями. Симметрия объекта — это операция, которая сохраняет некоторое свойство объекта. Интересно отметить, что если мы применяем к объекту одну симметрию, и сразу после этого — другую симметрию, то итоговое преобразование будет еще одной симметрией. Операция, которая оставляет объект неизменным — это тоже одна из симметрий. Для любой симметрии существует другая симметрия, которая откатывает назад все изменения, сделанные первой. И наконец, если нам нужно применить одну симметрию, затем вторую, а затем третью, то мы можем сгруппировать либо первую и вторую симметрию вместе, либо вторую и третье — и в итоге получить одно и то же преобразование.
Все эти свойства говорят нам о том, что множество симметрий объекта формируют группу. Группа — это множество G, вместе с операцией ·, для которого выполняются следующие свойства:
Заметим, что в определениях выше мы используем мультипликативную нотацию для операции группы. Мы могли бы использовать аддитивную нотацию, и в этом случае обратный элемент для g обозначался бы -g. (Мультипликативная нотация — это как будто наша операция «умножить», а аддитивная — «прибавить»).
Упражнение Проверьте, что множество целых чисел Z с операцией сложения — группа. Для этого нужно проверить выполнение всех четырех свойств.
Группа целых чисел имеет еще одно очень интересное свойство: порядок сложения чисел совершенно не важен. То есть, для любых двух целых чисел a и b, a+b — это то же самое, что и b+a. Когда операция группы удовлетворяет этому свойству (это свойство называется коммутативность), группа называется абелевой.
Давайте рассмотрим пример группы симметрий, например, квадрат с пронумерованными углами:
Для этого геометрического объекта есть восемь преобразований, которые сохраняют тот факт, что это — квадрат. Другими словами, у квадрата восемь симметрий. Все они — различные повороты и отражения вместе с операцией композиции преобразований:
Упражнение Выберите какие-нибудь два преобразования из списка выше и проверьте, что применение одного из них, а затем другого — это тоже преобразование, которое уже есть в этом списке. Можете ли вы найти два таких преобразования, что приводят к различным результатам в зависимости от порядка их применения?
В отличие от группы целых чисел, группа симметрий квадрата неабелева.
Группа симметрий G корректной сетки судоку содержит все преобразования квадрата и, помимо этого, некоторые другие преобразования вроде перемещения блоков, строк и столбцов, а также композиция всех этих преобразований. Таким образом, группа симметрий порождается преобразованиями следующих видов:
Важное замечание: это не список всех элементов G! Это список различных симметрий группы, и комбинируя их всеми различными способами мы можем получить все остальные элементы группы. И конкретные преобразования всех описанных выше типов, и любая их композиция, которая отличается от этих конкретных «базовых» преобразований — все они включаются в группу симметрий G. Например, один из элементов G — это обмен первой и второй строк, конкретное преобразование типа (5). Пусть X — множество всех корректных сеток судоку. Мы знаем, что это множество из конечного числа элементов. Из того, что каждый элемент G — это некоторое соответствие, которое отображает одну из сеток на другую (на самом деле оно отображает все сетки на какие-то другие, т.е. это некоторая перестановка всех элементов из X), мы можем заключить, что G тоже включает в себя только конечное число элементов-симметрий.
Мы называем две сетки судоку эквивалентными, если мы можем преобразовать одну из них в другую применив одну или более симметрий из G. Если ни одна из последовательностей симметрий не преобразовывает одну из сеток в другую, то мы такие сетки называем существенно различными.
Это отношение действительно является отношением эквивалентности в формальном математическом смысле, поскольку оно удовлетворяет следующим трем свойствам:
Для любой корректной сетки судоку A мы можем рассматривать все сетки, эквивалентные A, как действительно точно такие же, как A. Если мы сгруппируем вместе все сетки, которые эквивалентны друг другу, то мы, на самом деле, разобьем множество всех сеток на непересекающиеся части: в самом деле, X будет разбито на такие подмножества, что никакие два из них не имеют общих элементов. Математики называют такие подмножества классами эквивалентности. Любые два элемента из одного класса эквивалентности эквивалентны друг другу по какой-нибудь симметрии из G. Множество классов эквивалентности обозначается как X/G и читается как «X по модулую G» или «X mod G» (еще математики называют X/G фактор-множеством).
В предыдущей части статьи мы задавались вопросом о количестве различных сеток судоку без всяких симметрий, и было бы интересно найти число существенно различных сеток. Согласно рассуждениям, изложенным выше, общее количество классов эквивалентности, или число элементов в X/G — это и есть ни что иное, как количество существенно различных сеток судоку. Далее мы рассмотрим метод, который в начале 2006 года использовали Эд Расселл (Ed Russell) и Фразер Джарвис (Frazer Jarvis) для вычисления этого числа.
Сначала мы немного обделим вниманием операцию переназначения чисел и рассмотрим только те симметрии, которые что-то делают именно с сеткой — со всей сеткой, с блоками или с отдельными ячейками. Рассмотрим эти симметрии — их типы (2)-(6) в списке выше — и их композиции. Эти симметрии дают нас группу H, в которой Расселл и Джарвис насчитали ровно 3359232 различных симметрий. Другими словами, H — это группа, которая порождается симметриями типов (2)-(6).
Теперь наше понятие эквивалентности двух сеток можно определить следующим образом: сетка A эквивалентна сетке B если мы можем сетку A преобразовать симметриями из группы H в некоторую сетку C, такую, что в C можно переназначить числа так, что в итоге получится сетка B. Мы можем сказать, что A H-эквивалентна C, а C эквиватентна B по переназначению. Заметим, что H-эквивалентность и эквивалентность по переназначению — это действительно отношения эквивалентности (они обе удовлетворяют трем свойствам из списка выше).
Мы считаем, что H действует на множество корректных сеток судоку X следующим образом: каждый элемент h из H представляет собой отображение X на X, то есть переводит каждую из сеток из X в другую (возможно ту же самую) сетку из X. Другими словами, h дает нам способ преобразования любой корректной сетки в другую корректную сетку, и каждый элемент h из H дает нам такое отображение.
Для любой симметрии из h из H мы можем рассмотреть те сетки, которые h оставляет на месте с точностью до переназначения. Мы имеем в виду все такие сетки A, что если мы применим к A симметрию h и получим сетку B, то B будет эквивалентна A по переназначению (Такие объекты еще называются неподвижными точками относительно элемента h). Так мы учитываем тот факт, что мы не учли переназначение в группе симметрий H.
Для того, чтобы посчитать количество существенно различных сеток судоку, нам нужна теорема из теории групп, под названием лемма Бернсайда.
Лемма Бернсайда Пусть G — конечная группа, которая действует на множестве X. Для каждого элемента g из G, пусть Xg обозначает множество элементов из X, которые элемент g оставляет на месте. Тогда количество элементов в множестве X/G равно |X/G|=1/|G|?g in G|Xg|, где |-| — количество элементов в множестве.
Упражнение Представьте квадрат, в котором каждое из ребер раскрашено в один из двух цветов — синий или зеленый. Две раскраски назовем существенно одинаковыми, если существует такая симметрия квадрата, что переводит первую из этих раскрасок во вторую. Используйте лемму Бернсайда для того, чтобы определить количество существенно различных раскрасок. (Для каждой из восьми симметрий квадрата посчитайте количество раскрасок, которые не меняются при применении симметрии. Для лучшего понимания происходящего можно нарисовать все 24=16 раскрасок квадрата и представить себе как они переходят друг в друга. Лемма Бернсайда говорит нам, что для получения ответа нужно сложить количество не изменяющихся раскрасок для каждой симметрии и затем разделить полученную сумму на количество симметрий.)
В нашем же случае, конечная группа H действует на множество X всевозможных корректных сеток судоку. Для каждого h из H, мы хотим найти количество таких элементов X, что они не изменяются при применении h с точностью до переназначения чисел. Затем нам нужно сложить все эти числа и разделить их на число элементов в H. И в итоге получится ответ — количество существенно различных суток судоку. То есть, нам нужно взять среднее арифметическое от количеств неизменных сеток (с точностью до переназначения) по всем элементам H.
Например, следующая корректная сетка судоку является неподвижной точкой для поворота на 90° по часовой стрелке (опять же, с точностью до переназначения чисел):

Упражнение Определите как переназначить числа в повернутой сетке выше так, чтобы она совпала с изначальной. Выпишите все числа от 1 до 9 и посмотрите куда переходит число 1, затем куда переходит число 2, затем 3, ну и так далее. В общем, удостоверьтесь, что данная сетка — неподвижная точка для данной симметрии поворота.
Для того, чтобы применить лемму Бернсайда (чтобы вычислить количество существенно различных сеток), мы могли бы вычислить количество неподвижных точек для каждого из 3359232 элементов H. Но, оказывается, некоторые из этих 3359232 преобразований имеют одно и то же число неизменяемых сеток! Расселл и Джарвис использовали специальную программу GAP и определили, что все элементы H распадаются на 275 классов симметрий таких, что любые две симметрии из одного класса имеют одно и то же число неизменных сеток, и каждая симметрия из H имеет столько же неподвижных точек, сколько элемент одного из этих классов (знакомый процесс, не правда ли?). Поэтому нам нужно просто посчитать количество фиксированных точек только для одной симметрии из каждого из 275 классов. Зная сколько симметрий находится в каждом из классов, мы потом сможем узнать среднее, как в лемме Бернсайда.
Упражнение Рассмотрите отражение сетки судоку относительно горизонтальной оси, проходящей через центр сетки, то бишь через пятую строку. Заметим, что пятая строка после отражения останется неизменной. Можете ли вы переназначить числа в отраженной сетке так, чтобы она совпала с изначальной? И что можно сказать о неподвижных точках для отражения отосительно горизонтальной оси? Тут вообще есть сетки, которые не изменяются? (Вспомните тот факт, что мы сейчас рассматриваем какую-то корректную сетку судоку, и в пятой строке находятся все девять чисел).
Как можно видеть из упражнения выше, в H бывают такие симметрии, для которых нет неподвижных точек. Расселл и Джарвис с удивлением обнаружили, что на самом деле аж 248 классов из 275 содержат симметрии, для которых нет ни одной фиксированной точки. Так что им осталось только посчитать количество неизменных сеток для симметрий из 27 оставшихся классов и найти сколько симметрий содержится в каждом из этих классов перед тем, как использовать лемму Бернсайда. Они написали программу, которая делает последние вычисления и в результате получили число 5472730538?5.473?109 — количество существенно различных сеток судоку.
Давайте посмотрим на судоку порядка 2, или сетку судоку размера 4?4, для того, чтобы лучше понять идеи, которые были рассмотрены выше (и в предыдущей части тоже).
Для того, чтобы посчитать количество сеток судоку 4?4, мы начнем — как и в случае с случаем 9?9 — с заполнения левого верхнего блока стандартным способом. Это делит количество различных сеток судоку на 4!, поскольку у нас есть ровно 4! переназначить числа в этом блоке.
Когда мы сделаем это, 1 и 2 окажутся на первых двух позициях первой строки, а 3 и 4 — на следующих двух позициях. Для каждой из 4! расстановок, у нас есть два способа вставить 3 и 4, и это влияет на общее число различных сеток. С другой стороны, если мы ходим посчитать лишь количество существенно различных сеток, порядок следования 3 и 4 не имеет значения, поскольку мы можем поменять местами третий и четвертый столбцы и получить все еще корректную сетку. Так что мы можем полагать, что 3 находится в третьей ячейке первой строки, а 4 — в четвертой.
Так как 1 и 3 уже имеются в первом столбце, 2 и 4 должны быть вставлены в третью и четвертую ячейку в этом столбце. Так как у нас два способа сделать это, наше количество различных сеток теперь считается сразу пачками по 4!?2?2 штук. Для подсчета количества существенно различных сеток, мы отмечаем, что обмен местами третьей и четвертой строк — это одна из симметрий сетки, так что мы можем считать, что 2 находится в третьей ячейке первого столбца, а 4 — в четвертой. К текущему моменту наша сетка имеет следующий вид:
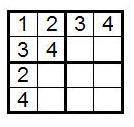
Поскольку в третьей строке есть 2, а в третьем столбце есть 3, в ячейку (3,3) мы можем вставить либо 1, либо 4.
Упражнение Покажите, что если в позицию (3,3) вставить 1, то это в конечном итоге приведет к нарушению Главного Правила.
Таким образом, в позиции (3,3) обязано находиться число 4. В четвертой строке, четвертом столбце, да еще и в правом нижнем блоке — во всех них у нас есть только 4, поэтому в ячейку (4,4) мы можем вставить любое из чисел 1, 2 и 3. Это дает нам следующие три сетки, то есть для каждой из 4!?2?2, которые мы насчитали ранее, есть ровно 3 способа поставить следующее число в позицию (4,4) (а дальше сетки заполняются однозначным образом). Таким образом, число различных сеток судоку 4?4 равно 4!?2?2?3=288.
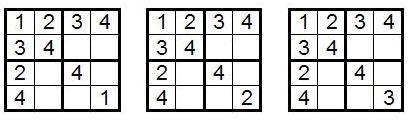
Упражнение Заполните до конца все три сетки. После этого проверьте, что вторая и третья сетки на самом деле эквивалентны — можно отразить третью сетку по диагонали (какой из двух?) после чего переназначить числа 2 и 3.
То есть, в конечном итоге, у нас остается всего две существенно различные сетки судоку 4?4.
Правильно составленная головоломку судоку должна иметь единственное решение. В общем случае, судоку может иметь несколько решений, но в этом случае логических приемов, которые мы обсуждали в главе про подходы к решению, может оказаться недостаточно. Известен пример судоку порядка 3 с 17 числами, данными изначально, который правильно составлен. Минимальное же число подсказок для правильно составленного судоку порядка 3 — неизвестно (на самом деле, уже известно).
Упражнение Можете ли вы привести пример судоку, который не является правильно составленным?
Другой интересны вопрос (который мог прийти вам в голову, когда вы решали предыдущее упражнение): как много различных чисел может быть использовано для того, чтобы головоломка была правильно составленной? Оказывается, что для судоку порядка n, для получения единственного решения, необходимо использовать минимум n2-1 различных чисел. Если мы для головоломки порядка n используем только n2-2 различных чисел, то перестановка тех чисел, которых нет в подсказках, в одном из решений даст нам другое решение. В частности, для обычной судоку порядка 3, нужно использовать не менее 32-1=8 различных чисел, чтобы получить правильно составленную головоломку. Иначе пазл будет иметь более одного решения (или ни одного?).
Факт, описанный в предыдущем абзаце, можно переформулировать следующим образом: если судоку порядка n правильно составлена, то в ней должно содержаться как минимум n2-1 различных чисел в самом начале. Важно отметить, что это не то же самое, что если судоку порядка n имеет n2-1 различных чисел, то она правильно составлена. Вспомните, что если из A следует B, то из B не обязательно следует A. Следующее упражнение иллюстрирует этот момент специальным примером.
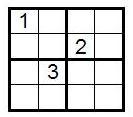
Упражнение Следующая судоку порядка 2 имеет 22-1=3 различных чисел. Найдите два различных решения.
Для судоку 4?4, анализ всех (двух) случаев существенно различных сеток доказывает, что правильно составленная головоломка должна иметь как минимум четыре начальных подсказки.
Наконец, нельзя не отметить, что хотя компьютерные программы в мгновение ока решают судоку порядка 3, используя метод перебора с возвратом, решение судоку произвольного порядка n — гораздо более сложная задача. В то время как порядок судоку изменяется с n на n+1 (всего на единицу), время, нужное для решения, вырастает на порядки. Доказано, что задача решения судоку порядка n входит в класс NP-полных задач. Задача называется NP-полной, если для нее выполняются следующие два свойства:
Хотя и проверить правильность решения NP-полных задач — быстро и легко, пока неизвестно алгоритма, который бы быстро находил это решение. Для алгоритмов, известных на текущий момент, время выполнения растет слишком быстро с ростом размера входных данных.
И на этой грустной ноте статья подходит к концу, как и ее перевод. Я лично в процессе перевода (а особенно написания комментариев) узнал и понял много нового. Надеюсь, вы тоже.
Список литературы оригинальной статьи можно посмотреть тут.
Спасибо всем, кто осилил до конца.
В этой части мы погрузимся в теорию групп, начиная с самых основ, но затрагивая только то, что нам пригодится для ответа на вопрос: а сколько же есть действительно различных судоку — без всяких повторов в виде поворотов, отражений и т.п. Те, кто довольно хорошо знаком с теорией групп — вероятно, найдут тут мало что интересного. Для остальных же почитать очень даже полезно. На всякий случай: я себя специалистом по теории групп не считаю, при переводе статьи я сам по сути изучал ее почти с нуля. То есть, вполне могут быть косяки — пишите мне о них в личку. С другой стороны — я для большинства определений лазил в википедию, а все численные результаты подтвердил собственноручно написанной программой. Так что, по идее, количество косяков должно стремиться к нулю. Но мало ли.
Как обычно, мои комментарии выделены курсивом или спрятаны под спойлеры. Под спойлерами можно найти самое интересное — куски кода, которые верифицируют все числа, полученные в повествовании.
Симметрии
Итак, в предыдущей части статьи мы посчитали, что количество различных сеток судоку равно N=6670903752021072936960?6.671?1021. Но довольно часто мы можем получить одну сетку судоку из другой, применяя простые преобразования. Например, если у нас есть корректно заполненная сетку судоку, то, поворачивая ее на 90°, мы получаем другую сетку, которая отличается от исходной, но все еще остается корректной. На самом деле, мы можем рассматривать эти сетки как одинаковые, поскольку в результате преобразования наша сетка — все еще одно из решений судоку. Аналогично, если мы заменим все 3-ки в сетке на 4-ки, а все 4-ки на 3-ки, то мы получим другую корректную сетку. Мы также могли бы взять какую-нибудь сетку судоку, поменять местами пятую и шестую строки, и, в конце концов, все равно получить корректную сетку. Когда мы делаем такие преобразования, мы сохраняет такое свойство сетки, как ее корректность (В предыдущей части статьи мы делали что-то очень похожее, но только с частью сетки — первой полосой. Теперь же мы играемся со всей таблицей 9?9. Важное отличие в том, что сейчас мы рассматриваем только такие преобразования, которые можно применить к любой сетке (с сохранением корректности), т.е. рассмотренная ранее операция свапания углов прямоугольника внутри сетки судоку не подходит, так как к некоторым сеткам она применима, а к некоторым — нет.).
Операции такого вида называются симметриями. Симметрия объекта — это операция, которая сохраняет некоторое свойство объекта. Интересно отметить, что если мы применяем к объекту одну симметрию, и сразу после этого — другую симметрию, то итоговое преобразование будет еще одной симметрией. Операция, которая оставляет объект неизменным — это тоже одна из симметрий. Для любой симметрии существует другая симметрия, которая откатывает назад все изменения, сделанные первой. И наконец, если нам нужно применить одну симметрию, затем вторую, а затем третью, то мы можем сгруппировать либо первую и вторую симметрию вместе, либо вторую и третье — и в итоге получить одно и то же преобразование.
Все эти свойства говорят нам о том, что множество симметрий объекта формируют группу. Группа — это множество G, вместе с операцией ·, для которого выполняются следующие свойства:
- Если g и h — элементы G, то и g·h — тоже элемент G (Математики говорят, что G замкнуто относительно операции ·).
- Если g, h и k — элементы G, то g·(h·k)=(g·h)·k (Это свойство операции группы называется ассоциативностью).
- Существует элемент e в G такой, что g·e=e·g=g для всех g из G (Этот элемент e называется нейтральным элементом группы G, так как он оставляет каждый элемент G неизменным относительно операции).
- Для каждого элемента g из G существует другой элемент h из G такой, что g·h=h·g=e, где e — нейтральный элемент (Элемент h называется обратным элементом к g, обозначается как g-1).
Заметим, что в определениях выше мы используем мультипликативную нотацию для операции группы. Мы могли бы использовать аддитивную нотацию, и в этом случае обратный элемент для g обозначался бы -g. (Мультипликативная нотация — это как будто наша операция «умножить», а аддитивная — «прибавить»).
Упражнение Проверьте, что множество целых чисел Z с операцией сложения — группа. Для этого нужно проверить выполнение всех четырех свойств.
Группа целых чисел имеет еще одно очень интересное свойство: порядок сложения чисел совершенно не важен. То есть, для любых двух целых чисел a и b, a+b — это то же самое, что и b+a. Когда операция группы удовлетворяет этому свойству (это свойство называется коммутативность), группа называется абелевой.
Давайте рассмотрим пример группы симметрий, например, квадрат с пронумерованными углами:
Для этого геометрического объекта есть восемь преобразований, которые сохраняют тот факт, что это — квадрат. Другими словами, у квадрата восемь симметрий. Все они — различные повороты и отражения вместе с операцией композиции преобразований:
- Поворот на 0 градусов (нейтральный элемент).
- Поворот на часовой стрелке на 90 градусов.
- Поворот на часовой стрелке на 180 градусов.
- Поворот на часовой стрелке на 270 градусов.
- Отражение относительно горизонтальной оси (которая проходит через центр квадрата).
- Отражение относительно вертикальной оси (которая тоже проходит через центр квадрата).
- Отражение по-диагонали из левого нижнего угла в правый верхний.
- Отражение по-диагонали из левого верхнего угла в правый нижний.
Упражнение Выберите какие-нибудь два преобразования из списка выше и проверьте, что применение одного из них, а затем другого — это тоже преобразование, которое уже есть в этом списке. Можете ли вы найти два таких преобразования, что приводят к различным результатам в зависимости от порядка их применения?
В отличие от группы целых чисел, группа симметрий квадрата неабелева.
Группа симметрий G корректной сетки судоку содержит все преобразования квадрата и, помимо этого, некоторые другие преобразования вроде перемещения блоков, строк и столбцов, а также композиция всех этих преобразований. Таким образом, группа симметрий порождается преобразованиями следующих видов:
- Переназначение девяти цифр.
- Перестановка трех стеков.
- Перестановка трех полос.
- Перестановка трех столбцов в каком-либо стеке.
- Перестановки трех строк в какой-либо полосе.
- Всякие отражения и повороты (из списка симметрий квадрата).
Важное замечание: это не список всех элементов G! Это список различных симметрий группы, и комбинируя их всеми различными способами мы можем получить все остальные элементы группы. И конкретные преобразования всех описанных выше типов, и любая их композиция, которая отличается от этих конкретных «базовых» преобразований — все они включаются в группу симметрий G. Например, один из элементов G — это обмен первой и второй строк, конкретное преобразование типа (5). Пусть X — множество всех корректных сеток судоку. Мы знаем, что это множество из конечного числа элементов. Из того, что каждый элемент G — это некоторое соответствие, которое отображает одну из сеток на другую (на самом деле оно отображает все сетки на какие-то другие, т.е. это некоторая перестановка всех элементов из X), мы можем заключить, что G тоже включает в себя только конечное число элементов-симметрий.
Мы называем две сетки судоку эквивалентными, если мы можем преобразовать одну из них в другую применив одну или более симметрий из G. Если ни одна из последовательностей симметрий не преобразовывает одну из сеток в другую, то мы такие сетки называем существенно различными.
Это отношение действительно является отношением эквивалентности в формальном математическом смысле, поскольку оно удовлетворяет следующим трем свойствам:
- Сетка A эквивалентна самой себе (это свойство называется рефлексивностью).
- Если A эквивалентна B, то B эквивалента A (это свойство называется симметричностью).
- Если A эквивалентна B, а B эквивалентна C, то A эквивалентна C (это свойство называется транзитивностью).
Для любой корректной сетки судоку A мы можем рассматривать все сетки, эквивалентные A, как действительно точно такие же, как A. Если мы сгруппируем вместе все сетки, которые эквивалентны друг другу, то мы, на самом деле, разобьем множество всех сеток на непересекающиеся части: в самом деле, X будет разбито на такие подмножества, что никакие два из них не имеют общих элементов. Математики называют такие подмножества классами эквивалентности. Любые два элемента из одного класса эквивалентности эквивалентны друг другу по какой-нибудь симметрии из G. Множество классов эквивалентности обозначается как X/G и читается как «X по модулую G» или «X mod G» (еще математики называют X/G фактор-множеством).
В предыдущей части статьи мы задавались вопросом о количестве различных сеток судоку без всяких симметрий, и было бы интересно найти число существенно различных сеток. Согласно рассуждениям, изложенным выше, общее количество классов эквивалентности, или число элементов в X/G — это и есть ни что иное, как количество существенно различных сеток судоку. Далее мы рассмотрим метод, который в начале 2006 года использовали Эд Расселл (Ed Russell) и Фразер Джарвис (Frazer Jarvis) для вычисления этого числа.
Сначала мы немного обделим вниманием операцию переназначения чисел и рассмотрим только те симметрии, которые что-то делают именно с сеткой — со всей сеткой, с блоками или с отдельными ячейками. Рассмотрим эти симметрии — их типы (2)-(6) в списке выше — и их композиции. Эти симметрии дают нас группу H, в которой Расселл и Джарвис насчитали ровно 3359232 различных симметрий. Другими словами, H — это группа, которая порождается симметриями типов (2)-(6).
Комментарий
В любой непонятной ситуации начинай варить мет писать код. Вот и сейчас совершенно непонятно откуда берется число 3359232. Поэтому давайте начнем писать код для того, чтобы проверить, что у группы H ровно 3359232 различных симметрий.
Начнем со структуры, которая описывает симметрии группы. По теореме Кэли, любая конечная группа изоморфна подгруппе некоторой симметрической группы. Если говорить понятным языком, то любую конечную группу можно представить в виде некоторой системы перестановок. Вот и для группы H мы используем перестановку длины 81 — по одному элементу перестановки на каждую ячейку судоку.
Т.е. в каждой позиции таблицы 9x9 мы храним номер позиции, в которую перейдет элемент на текущей позиции после применения симметрии. Обратите внимание — симметрия ничего не знает о том, какие числа в судоку сейчас находятся. В приведенном выше коде прописаны создание таких симметрий, как нейтральный элемент, перестановка стеков, перестановка столбцов и поворот на 90 градусов.
Упражнение Покажите, что все симметрии типов (2)-(6) можно получить композицией тех симметрий, которые мы реализовали в коде.
Далее в коде идет реализация композиции или умножения симметрий. В конце добавлена реализация нахождения обратного элемента (она нам пока не нужна, но понадобится позже).
Теперь на основе имеющихся симметрий давайте породим всю группу H:
Операторы для сравнения и определения какой элемент меньше нужны чисто для того, чтобы set мог корректно выполнять свои операции (а иначе он даже откажется компилироваться). Далее, мы реализуем обход группы симметрий H при помощи обхода в ширину (можно было бы использовать и обход в глубину, но он съедает слишком много памяти на стеке рекурсии).
Более детально: сначала мы помещаем в очередь Q нейтральную симметрию. После этого извлекаем и обрабатываем симметрии, пока они в очереди не закончатся. Обработки идет следующим образом: мы только что извлеченную из очереди симметрию умножаем на все доступные нам «базовые» симметрии. Множество Set выполняет роль массива флагов и хранит в себе все полученные на текущий момент симметрии. Если после умножения мы получили новую симметрию — такую, что ее нет в Set — то мы ее запоминаем в множестве Set и помещаем в конец очереди Q. Если после умножения мы обнаруживаем, что новая симметрия на самом деле уже есть в Set — мы ничего не делаем, так как мы уже обрабатывали эту симметрию ранее.
В итоге в конце выполнения алгоритма в Set скопятся все симметрии из группы H (вообще, если говорить строго — там скопятся все перестановки некой группы P, которая изоморфна группе H, но мы не будем сейчас занудствовать по этому поводу). Запуск кода подтверждает, что в H действительно ровно 3359232 элементов.
Кстати, в структуре SYMMETRY у каждого элемента перестановки не зря выбран тип unsigned char. В процессе вычисления мы храним в множестве Set и в очереди Q миллионы объектов (которые «весят» по 80 байт), поэтому нужно быть готовым к тому, что программа будет потреблять около 450Мб памяти в процессе вычислений и около 300Мб в конце, когда очередь опустеет.
Начнем со структуры, которая описывает симметрии группы. По теореме Кэли, любая конечная группа изоморфна подгруппе некоторой симметрической группы. Если говорить понятным языком, то любую конечную группу можно представить в виде некоторой системы перестановок. Вот и для группы H мы используем перестановку длины 81 — по одному элементу перестановки на каждую ячейку судоку.
struct SYMMETRY
{
unsigned char m[9][9];
void print()
{
for (int i=0; i<9; i++)
{
for (int j=0; j<9; j++)
printf( "%2d ", (int)m[i][j] );
printf( "\n" );
}
printf( "\n" );
}
static SYMMETRY E()
{
SYMMETRY re;
unsigned char t = 0;
for (int i=0; i<9; i++)
for (int j=0; j<9; j++)
re.m[i][j] = t++;
return re;
}
static SYMMETRY swap_stacks( int i, int j )
{
SYMMETRY re = SYMMETRY::E();
for (int a=0; a<9; a++)
for (int b=0; b<3; b++)
swap( re.m[a][i*3+b], re.m[a][j*3+b] );
return re;
}
static SYMMETRY swap_columns( int s, int i, int j )
{
SYMMETRY re = SYMMETRY::E();
for (int a=0; a<9; a++)
swap( re.m[a][s*3+i], re.m[a][s*3+j] );
return re;
}
static SYMMETRY rotate()
{
SYMMETRY re = SYMMETRY::E();
for (int a=0; a<5; a++)
for (int b=0; b<4; b++)
{
unsigned char tmp = re.m[a][b];
re.m[a][b] = re.m[8-b][a];
re.m[8-b][a] = re.m[8-a][8-b];
re.m[8-a][8-b] = re.m[b][8-a];
re.m[b][8-a] = tmp;
}
return re;
}
SYMMETRY multiply( SYMMETRY g )
{
SYMMETRY re;
for (int i=0; i<9; i++)
for (int j=0; j<9; j++)
re.m[i][j] = g.m[m[i][j]/9][m[i][j]%9];
return re;
}
SYMMETRY inverse()
{
SYMMETRY re;
for (int i=0; i<9; i++)
for (int j=0; j<9; j++)
re.m[m[i][j]/9][m[i][j]%9] = i*9+j;
return re;
}
};
Т.е. в каждой позиции таблицы 9x9 мы храним номер позиции, в которую перейдет элемент на текущей позиции после применения симметрии. Обратите внимание — симметрия ничего не знает о том, какие числа в судоку сейчас находятся. В приведенном выше коде прописаны создание таких симметрий, как нейтральный элемент, перестановка стеков, перестановка столбцов и поворот на 90 градусов.
Упражнение Покажите, что все симметрии типов (2)-(6) можно получить композицией тех симметрий, которые мы реализовали в коде.
Далее в коде идет реализация композиции или умножения симметрий. В конце добавлена реализация нахождения обратного элемента (она нам пока не нужна, но понадобится позже).
Теперь на основе имеющихся симметрий давайте породим всю группу H:
bool operator== (const SYMMETRY & A, const SYMMETRY & B)
{
for (int a=0; a<9; a++)
for (int b=0; b<9; b++)
if (A.m[a][b] != B.m[a][b])
return false;
return true;
}
bool operator< (const SYMMETRY & A, const SYMMETRY & B)
{
for (int a=0; a<9; a++)
for (int b=0; b<9; b++)
if (A.m[a][b] != B.m[a][b])
return A.m[a][b] < B.m[a][b];
return false;
}
set< SYMMETRY > Set;
queue< SYMMETRY > Q;
void bfs_push( SYMMETRY G )
{
if (Set.find( G ) != Set.end()) return;
Set.insert( G );
Q.push( G );
if (Set.size()%100000==0) fprintf( stderr, "G.sz=%d\n", (int)Set.size() );
}
void find_all_elements_of_group()
{
Q.push( SYMMETRY::E() );
Set.insert( SYMMETRY::E() );
while (Q.size()>0)
{
SYMMETRY G = Q.front();
Q.pop();
bfs_push( G.multiply( SYMMETRY::rotate() ) );
for (int i=0; i<3; i++)
for (int j=i+1; j<3; j++)
{
bfs_push( G.multiply( SYMMETRY::swap_stacks(i,j) ) );
for (int k=0; k<3; k++)
bfs_push( G.multiply( SYMMETRY::swap_columns(k,i,j) ) );
}
}
printf( "sudoku group size %d\n", (int)Set.size() );
fprintf( stderr, "sudoku group size %d\n", (int)Set.size() );
}Операторы для сравнения и определения какой элемент меньше нужны чисто для того, чтобы set мог корректно выполнять свои операции (а иначе он даже откажется компилироваться). Далее, мы реализуем обход группы симметрий H при помощи обхода в ширину (можно было бы использовать и обход в глубину, но он съедает слишком много памяти на стеке рекурсии).
Более детально: сначала мы помещаем в очередь Q нейтральную симметрию. После этого извлекаем и обрабатываем симметрии, пока они в очереди не закончатся. Обработки идет следующим образом: мы только что извлеченную из очереди симметрию умножаем на все доступные нам «базовые» симметрии. Множество Set выполняет роль массива флагов и хранит в себе все полученные на текущий момент симметрии. Если после умножения мы получили новую симметрию — такую, что ее нет в Set — то мы ее запоминаем в множестве Set и помещаем в конец очереди Q. Если после умножения мы обнаруживаем, что новая симметрия на самом деле уже есть в Set — мы ничего не делаем, так как мы уже обрабатывали эту симметрию ранее.
В итоге в конце выполнения алгоритма в Set скопятся все симметрии из группы H (вообще, если говорить строго — там скопятся все перестановки некой группы P, которая изоморфна группе H, но мы не будем сейчас занудствовать по этому поводу). Запуск кода подтверждает, что в H действительно ровно 3359232 элементов.
Кстати, в структуре SYMMETRY у каждого элемента перестановки не зря выбран тип unsigned char. В процессе вычисления мы храним в множестве Set и в очереди Q миллионы объектов (которые «весят» по 80 байт), поэтому нужно быть готовым к тому, что программа будет потреблять около 450Мб памяти в процессе вычислений и около 300Мб в конце, когда очередь опустеет.
Комментарий
Кстати, а как можно представить себе в виде группы перестановок группу, которая порождается симметриями всех типов (1)-(6)? Перестановки — они же глупые, они не смотрят на то, какие числа записаны в судоку. Они тупо перемешивают элементы не вникая в суть.
Для того, чтобы учесть симметрии типа (1), мы немного трансформируем сетку судоку. А именно: переведем ее в 3D (как бы странно это не звучало). Представьте себе куб 9x9x9, на который сверху спроецирована наша сетка судоку. То есть, на каждую ячейку судоку приходится столбец из 9 единичных кубиков в большом кубе. Ну и теперь для каждого столбца мы делаем следующее: если в соответствующей ячейке судоку находится число i, то мы красим i-ый (считая сверху) кубик столбца в черный цвет, а все остальные кубики — в белый. В итоге мы получим куб, каждый из 729 кубиков которого покрашен в один из двух цветов (черный или белый), причем в каждом столбце в черный цвет покрашен ровно один кубик. Ну и теперь все симметрии типов (2)-(6) — это перемешивание столбцов куба, в то время как симметрии типа (1) — это перемешивание горизонтальных слоев этого куба.
Вуаля — мы выразили группу симметрий, порождаемую симметриями типов (1)-(6) через подгруппу группы перестановок порядка 729.
Для того, чтобы учесть симметрии типа (1), мы немного трансформируем сетку судоку. А именно: переведем ее в 3D (как бы странно это не звучало). Представьте себе куб 9x9x9, на который сверху спроецирована наша сетка судоку. То есть, на каждую ячейку судоку приходится столбец из 9 единичных кубиков в большом кубе. Ну и теперь для каждого столбца мы делаем следующее: если в соответствующей ячейке судоку находится число i, то мы красим i-ый (считая сверху) кубик столбца в черный цвет, а все остальные кубики — в белый. В итоге мы получим куб, каждый из 729 кубиков которого покрашен в один из двух цветов (черный или белый), причем в каждом столбце в черный цвет покрашен ровно один кубик. Ну и теперь все симметрии типов (2)-(6) — это перемешивание столбцов куба, в то время как симметрии типа (1) — это перемешивание горизонтальных слоев этого куба.
Вуаля — мы выразили группу симметрий, порождаемую симметриями типов (1)-(6) через подгруппу группы перестановок порядка 729.
Теперь наше понятие эквивалентности двух сеток можно определить следующим образом: сетка A эквивалентна сетке B если мы можем сетку A преобразовать симметриями из группы H в некоторую сетку C, такую, что в C можно переназначить числа так, что в итоге получится сетка B. Мы можем сказать, что A H-эквивалентна C, а C эквиватентна B по переназначению. Заметим, что H-эквивалентность и эквивалентность по переназначению — это действительно отношения эквивалентности (они обе удовлетворяют трем свойствам из списка выше).
Мы считаем, что H действует на множество корректных сеток судоку X следующим образом: каждый элемент h из H представляет собой отображение X на X, то есть переводит каждую из сеток из X в другую (возможно ту же самую) сетку из X. Другими словами, h дает нам способ преобразования любой корректной сетки в другую корректную сетку, и каждый элемент h из H дает нам такое отображение.
Для любой симметрии из h из H мы можем рассмотреть те сетки, которые h оставляет на месте с точностью до переназначения. Мы имеем в виду все такие сетки A, что если мы применим к A симметрию h и получим сетку B, то B будет эквивалентна A по переназначению (Такие объекты еще называются неподвижными точками относительно элемента h). Так мы учитываем тот факт, что мы не учли переназначение в группе симметрий H.
Комментарий
Для лучшего понимания сути выражения «с точностью до переназначения» следует принять тот факт, что иногда множество объектов, на которых мы применяем всякие симметрии, могут после применения симметрии дополнительно самоподкручиваться до какого-то нормального вида.
Еще один вариант для улучшения понимания: лучше вместо множества X всех сеток судоку рассмотреть множество Y — множество всех классов эквивалентности X относительно эквивалентности по переназначению. Т.е. каждый элемент в Y — это множество из 9! сеток судоку, которые переходят друг в друга при переназначении чисел (я вообще каждый из этих элементов представляю себе как прозрачную сферу, в которой плавают 9! отдельных бумажных сеток судоку). И когда мы применяем к элементу y из Y элемент h из H — мы трансформируем сразу все сетки судоку внутри y в соответствии с симметрией h. И в итоге получаем новое множество сеток y' (а множества, как вы знаете, сравниваются без учета порядка элементов в них).
Следует отметить, что самоподкручивание не противоречит теореме Кэли — она для самой группы, а не для множества, на которое мы пытаемся этой группой действовать. Мы можем действовать группой на очень разные множества: даже на множества из одного или двух элементов, даже на другую группу. Главное, чтобы множество, на которое мы действуем, удовлетворяло небольшому списку свойств.
Еще один вариант для улучшения понимания: лучше вместо множества X всех сеток судоку рассмотреть множество Y — множество всех классов эквивалентности X относительно эквивалентности по переназначению. Т.е. каждый элемент в Y — это множество из 9! сеток судоку, которые переходят друг в друга при переназначении чисел (я вообще каждый из этих элементов представляю себе как прозрачную сферу, в которой плавают 9! отдельных бумажных сеток судоку). И когда мы применяем к элементу y из Y элемент h из H — мы трансформируем сразу все сетки судоку внутри y в соответствии с симметрией h. И в итоге получаем новое множество сеток y' (а множества, как вы знаете, сравниваются без учета порядка элементов в них).
Следует отметить, что самоподкручивание не противоречит теореме Кэли — она для самой группы, а не для множества, на которое мы пытаемся этой группой действовать. Мы можем действовать группой на очень разные множества: даже на множества из одного или двух элементов, даже на другую группу. Главное, чтобы множество, на которое мы действуем, удовлетворяло небольшому списку свойств.
Для того, чтобы посчитать количество существенно различных сеток судоку, нам нужна теорема из теории групп, под названием лемма Бернсайда.
Лемма Бернсайда Пусть G — конечная группа, которая действует на множестве X. Для каждого элемента g из G, пусть Xg обозначает множество элементов из X, которые элемент g оставляет на месте. Тогда количество элементов в множестве X/G равно |X/G|=1/|G|?g in G|Xg|, где |-| — количество элементов в множестве.
Упражнение Представьте квадрат, в котором каждое из ребер раскрашено в один из двух цветов — синий или зеленый. Две раскраски назовем существенно одинаковыми, если существует такая симметрия квадрата, что переводит первую из этих раскрасок во вторую. Используйте лемму Бернсайда для того, чтобы определить количество существенно различных раскрасок. (Для каждой из восьми симметрий квадрата посчитайте количество раскрасок, которые не меняются при применении симметрии. Для лучшего понимания происходящего можно нарисовать все 24=16 раскрасок квадрата и представить себе как они переходят друг в друга. Лемма Бернсайда говорит нам, что для получения ответа нужно сложить количество не изменяющихся раскрасок для каждой симметрии и затем разделить полученную сумму на количество симметрий.)
В нашем же случае, конечная группа H действует на множество X всевозможных корректных сеток судоку. Для каждого h из H, мы хотим найти количество таких элементов X, что они не изменяются при применении h с точностью до переназначения чисел. Затем нам нужно сложить все эти числа и разделить их на число элементов в H. И в итоге получится ответ — количество существенно различных суток судоку. То есть, нам нужно взять среднее арифметическое от количеств неизменных сеток (с точностью до переназначения) по всем элементам H.
Например, следующая корректная сетка судоку является неподвижной точкой для поворота на 90° по часовой стрелке (опять же, с точностью до переназначения чисел):
Упражнение Определите как переназначить числа в повернутой сетке выше так, чтобы она совпала с изначальной. Выпишите все числа от 1 до 9 и посмотрите куда переходит число 1, затем куда переходит число 2, затем 3, ну и так далее. В общем, удостоверьтесь, что данная сетка — неподвижная точка для данной симметрии поворота.
Для того, чтобы применить лемму Бернсайда (чтобы вычислить количество существенно различных сеток), мы могли бы вычислить количество неподвижных точек для каждого из 3359232 элементов H. Но, оказывается, некоторые из этих 3359232 преобразований имеют одно и то же число неизменяемых сеток! Расселл и Джарвис использовали специальную программу GAP и определили, что все элементы H распадаются на 275 классов симметрий таких, что любые две симметрии из одного класса имеют одно и то же число неизменных сеток, и каждая симметрия из H имеет столько же неподвижных точек, сколько элемент одного из этих классов (знакомый процесс, не правда ли?). Поэтому нам нужно просто посчитать количество фиксированных точек только для одной симметрии из каждого из 275 классов. Зная сколько симметрий находится в каждом из классов, мы потом сможем узнать среднее, как в лемме Бернсайда.
Комментарий
Из абзаца выше совершенно не ясно, как Расселл и Джарвис получили 275 классов. И вообще, что за классы вообще? Но, если углубиться в их оригинальную статью (а не тот научпоп, перевод которого вы читаете), то можно понять, что речь идет о классах сопряженности.
Информация из википедии: элементы g1 и g2 группы G называются сопряженными, если существует элемент h из G, для которого h·g1·h-1 = g2.
Упражнение Покажите, что отношение сопряженности является отношением эквивалентности (три свойства из определения эквивалентности по тексту выше вам в помощь).
Упражнение Покажите, что если два элемента g1 и g2 группы G сопряжены (причем h·g1·h-1 = g2 для некоторого h из H), то у них одинаковое количество неподвижных точек. Указание: покажите, что для любой неподвижной точки x из X для g1 объект y=x·h-1 (тоже из X) является неподвижной точкой для g2, а для каждой неподвижной точки y из X для g2 объект x=y·h из X — неподвижная точка для g1. В результате между неподвижными точками обеих симметрий построится биекция.
Итак, с теорией разобрались, теперь нужно разобраться с практикой. А с ней не все так просто. Нам, по сути, надо для каждого элемента g из H перебрать другой элемент h из H, после чего построить связь между g и h·g·h-1. А в конце посмотреть на компоненты связности. Только вот порядок группы H у нас под 3 миллиона и в лоб мы будем строить связи до скончания веков (ну, по крайней мере, до конца этого года точно). Поэтому мы поступим хитрее.
Давайте для начала в качестве h брать не все симметрии, а только очень небольшое их подмножество. Например, множество симметрий, из которых мы в одном из прошлых спойлеров порождаем группу H. В итоге все элементы H сгруппируются в частичные классы эквивалентности, их станет гораздо меньше, и мы уже дообъединяем их по-хорошему.
Ассоциативный массив classes хранит представителя каждого класса, а также количество элементов в каждом классе. Множество Set2 — это массив флагов, наподобие множества Set, который мы используем для нужд текущего перебора, а в самом конце очищаем. Генерация классов происходит следующим образом: сначала мы все «базовые» симметрии складываем в массив ops, после чего, начиная с еще не рассмотренного элемента, рекурсивно ходим по графу сопряженностей с помощью обхода в глубину и строим класс сопряженности. После этого мы берем следующую еще не рассмотренную симметрию, находим класс для него, и так далее.
Данный код (вместе с предыдущим) уже потребляет на пике порядка 900Мб памяти, из которых около 256Мб приходится на стек рекурсии (можно было бы опять этот момент реализовать как обход в ширину, но в данном случае обход в глубину оказался не настолько прожорливым по памяти — так что терпимо). И… в результате выполнения мы получаем искомые 275 классов.
Везение? Мы же еще недообработали наш результат. На самом деле, дообрабатывать ничего не надо и мы действительно получили верное разбиение на классы (это можно было бы доказать еще до запуска). Рассуждения о корректности нашего алгоритма выглядят примерно следующим образом:
Рассмотрим какие-нибудь сопряженные симметрии g1 и g2, тогда существует симметрия h, для которой g2 = h·g1·h-1. При этом, h можно представить в виде композиции симметрий, скажем h = a·b·c, где a,b,c — это какие-то «базовые» симметрии. Тогда g2 = h·g1·h-1 = (a·b·c)·g1·(a·b·c)-1 = a·b·c·g1·c-1·b-1·a-1 = (a·(b·(c·g1·c-1)·b-1)·a-1). То есть, из симметрии g1 мы бы в нашем алгоритме перешли к симметрии p1=c·g1·c-1, от p1 — к p2=b·g1·b-1, а от p2 — к a·g1·a-1=g2. Отсюда получаем, что алгоритм корректен.
Информация из википедии: элементы g1 и g2 группы G называются сопряженными, если существует элемент h из G, для которого h·g1·h-1 = g2.
Упражнение Покажите, что отношение сопряженности является отношением эквивалентности (три свойства из определения эквивалентности по тексту выше вам в помощь).
Упражнение Покажите, что если два элемента g1 и g2 группы G сопряжены (причем h·g1·h-1 = g2 для некоторого h из H), то у них одинаковое количество неподвижных точек. Указание: покажите, что для любой неподвижной точки x из X для g1 объект y=x·h-1 (тоже из X) является неподвижной точкой для g2, а для каждой неподвижной точки y из X для g2 объект x=y·h из X — неподвижная точка для g1. В результате между неподвижными точками обеих симметрий построится биекция.
Итак, с теорией разобрались, теперь нужно разобраться с практикой. А с ней не все так просто. Нам, по сути, надо для каждого элемента g из H перебрать другой элемент h из H, после чего построить связь между g и h·g·h-1. А в конце посмотреть на компоненты связности. Только вот порядок группы H у нас под 3 миллиона и в лоб мы будем строить связи до скончания веков (ну, по крайней мере, до конца этого года точно). Поэтому мы поступим хитрее.
Давайте для начала в качестве h брать не все симметрии, а только очень небольшое их подмножество. Например, множество симметрий, из которых мы в одном из прошлых спойлеров порождаем группу H. В итоге все элементы H сгруппируются в частичные классы эквивалентности, их станет гораздо меньше, и мы уже дообъединяем их по-хорошему.
map< SYMMETRY, int > classes;
SYMMETRY cur_g;
set< SYMMETRY > Set2;
void dfs1( SYMMETRY g, vector< SYMMETRY > & ops )
{
if (Set2.find( g ) != Set2.end()) return;
Set2.insert( g );
classes[cur_g]++;
for (int i=0; i<(int)ops.size(); i++)
dfs1( ops[i].multiply(g).multiply( ops[i].inverse() ), ops );
}
void find_conjugacy_classes()
{
vector< SYMMETRY > ops;
ops.push_back( SYMMETRY::rotate() );
for (int i=0; i<3; i++)
for (int j=i+1; j<3; j++)
{
ops.push_back( SYMMETRY::swap_stacks(i,j) );
for (int k=0; k<3; k++)
ops.push_back( SYMMETRY::swap_columns(k,i,j) );
}
int ind = 0;
for (set< SYMMETRY >::iterator it = Set.begin(); it != Set.end(); it++)
if (Set2.find( *it ) == Set2.end())
{
cur_g = *it;
dfs1( *it, ops );
printf( "M[%d]=%d\n", ind, classes[cur_g] );
fprintf( stderr, "M[%d]=%d\n", ind, classes[cur_g] );
ind++;
}
Set2.clear();
printf( "number of classes after step 1 %d\n", (int)classes.size() );
fprintf( stderr, "number of classes after step 1 %d\n", (int)classes.size() );
}
Ассоциативный массив classes хранит представителя каждого класса, а также количество элементов в каждом классе. Множество Set2 — это массив флагов, наподобие множества Set, который мы используем для нужд текущего перебора, а в самом конце очищаем. Генерация классов происходит следующим образом: сначала мы все «базовые» симметрии складываем в массив ops, после чего, начиная с еще не рассмотренного элемента, рекурсивно ходим по графу сопряженностей с помощью обхода в глубину и строим класс сопряженности. После этого мы берем следующую еще не рассмотренную симметрию, находим класс для него, и так далее.
Данный код (вместе с предыдущим) уже потребляет на пике порядка 900Мб памяти, из которых около 256Мб приходится на стек рекурсии (можно было бы опять этот момент реализовать как обход в ширину, но в данном случае обход в глубину оказался не настолько прожорливым по памяти — так что терпимо). И… в результате выполнения мы получаем искомые 275 классов.
Везение? Мы же еще недообработали наш результат. На самом деле, дообрабатывать ничего не надо и мы действительно получили верное разбиение на классы (это можно было бы доказать еще до запуска). Рассуждения о корректности нашего алгоритма выглядят примерно следующим образом:
Рассмотрим какие-нибудь сопряженные симметрии g1 и g2, тогда существует симметрия h, для которой g2 = h·g1·h-1. При этом, h можно представить в виде композиции симметрий, скажем h = a·b·c, где a,b,c — это какие-то «базовые» симметрии. Тогда g2 = h·g1·h-1 = (a·b·c)·g1·(a·b·c)-1 = a·b·c·g1·c-1·b-1·a-1 = (a·(b·(c·g1·c-1)·b-1)·a-1). То есть, из симметрии g1 мы бы в нашем алгоритме перешли к симметрии p1=c·g1·c-1, от p1 — к p2=b·g1·b-1, а от p2 — к a·g1·a-1=g2. Отсюда получаем, что алгоритм корректен.
Упражнение Рассмотрите отражение сетки судоку относительно горизонтальной оси, проходящей через центр сетки, то бишь через пятую строку. Заметим, что пятая строка после отражения останется неизменной. Можете ли вы переназначить числа в отраженной сетке так, чтобы она совпала с изначальной? И что можно сказать о неподвижных точках для отражения отосительно горизонтальной оси? Тут вообще есть сетки, которые не изменяются? (Вспомните тот факт, что мы сейчас рассматриваем какую-то корректную сетку судоку, и в пятой строке находятся все девять чисел).
Как можно видеть из упражнения выше, в H бывают такие симметрии, для которых нет неподвижных точек. Расселл и Джарвис с удивлением обнаружили, что на самом деле аж 248 классов из 275 содержат симметрии, для которых нет ни одной фиксированной точки. Так что им осталось только посчитать количество неизменных сеток для симметрий из 27 оставшихся классов и найти сколько симметрий содержится в каждом из этих классов перед тем, как использовать лемму Бернсайда. Они написали программу, которая делает последние вычисления и в результате получили число 5472730538?5.473?109 — количество существенно различных сеток судоку.
Комментарий
Мы приближаемся к самому сложному участку кода — коду подсчета количества неподвижных точек для каждого из 275 классов симметрий. И много сложности вносит именно тот факт, что мы рассматриваем объекты, эквивалентные по переназначению чисел — этакие обобщенные полностью заполненные сетки судоку. Всего их 6670903752021072936960/9! = 18383222420692992 (это то самое число всех сеток судоку, деленное на число вариантов, которые получаются путем переназначения чисел). Обозначим множество таких обобщенных сеток как Y.
Итак, подзадача для решения: нам нужно по некоторой симметрии g посчитать количество неподвижных точек из множества Y (всего таких подзадач 275). Что происходит с каждой неподвижной точкой при применении g? Числа в сетке судоку меняются местами в соответствии с некоторой перестановкой, затем идет переназначение чисел, и после этого мы получаем изначальную сетку. И тот факт, что числа как-то переназначаются, создает сложность при построении перебора. Однако, заметим, что если какая-то сетка является неподвижной точкой для какого-то одного переназначения, то для всех остальных переназначений она неподвижной точкой не является. Поэтому мы можем перебрать всевозможные переназначения, найти для каждого из них число неподвижных точек, а затем все сложить.
Получается теперь нам надо решать такую подподзадачу: даны симметрия g и переназначение чисел h, нужно для них посчитать число неподвижных точек из Y. Теперь рассмотрим какую-нибудь неподвижную точку y из Y, а конкретно — число p в какой-нибудь ячейке (i,j). При применении g к y, (i,j) переходит в некоторую позицию (i',j')=(i,j)·g, в которой, согласно переназначению h, будет число q=p·h. Так как конечная сетка равна изначальной, то число q должно стоять в изначальной сетке в позиции (i',j').
То есть, происходит следующее. g — это некоторая перестановка ячеек сетки судоку, которую можно разбить на циклы. Например, при симметрии поворота на 90 градусов, в этой перестановке будет находиться цикл (1,1)->(1,9)->(9,9)->(9,1)->(1,1) длины 4. h — это тоже некоторая перестановка, но уже просто из 9 чисел. И там тоже все распадается на циклы. Например, там может быть цикл 2->3->2 длины 2. И теперь, если мы хотим в позицию (1,1) поставить 2, то в (1,9) мы обязаны поставить 3, в (9,9) — 2, а в (9,1) — 3. Далее цикл замыкается. Заметим, что если длина цикла в сетке судоку не делится на длину цикла в переназначении — то мы не можем в данный цикл в судоку записать ни одно число из цикла переназначения, поскольку в самом конце у нас цикл «не замкнется».
Теперь нам нужно просто реализовать перебор, в котором операция присваивания числа ячейке сетки судоку дополнительно нужным образом расставляет нужные числа по всему циклу (ну и параллельно проверяет, что нигде не нарушилось Главное Правило).
Давайте начнем со структуры, которая инициализирует себя и для каждого элемента сетки просчитывает длину цикла, в который этот элемент входит (ну и еще считает кое-какие вещи по мелочи):
Процедура init() сохраняет в структуру текущую симметрию, и находит для нее все циклы. Кроме того, init() сбрасывает текущее переназначение до нейтрального. Процедура next_perm() позволяет перечислить всевозможные переназначения и для каждого из них находит все циклы в переназначении. Процедура clear() очищает все ячейке в сетке T, которую мы пытаемя построить.
Теперь добавим нашей структуре методы для того, чтобы можно было записывать и удалять числа:
Процедура set_num() пытается присвоить нужные значения по всему циклу, в случае неудачи — все изменения откатываются. unset_num() же откатывает изменения. Отметим, что set_num() в случае неудачи использует unset_num() для отмены изменений, используя «скрытый» параметр, чтобы отменить изменения не по всему циклу, а только по измененной его части.
В принципе, уже можно было бы начать писать сам перебор, но, забегая вперед, скажу, что он будет тормознутый и в него надо будет добавить немного отсечений. Каких? Давайте вспомним последнее упражнение прямо перед этим спойлером. Там рассматривались симметрии, которые не меняли что-нибудь в сетке: строку, столбец или блок. Если же в сетке что-то из этого списка не меняется, то единственное переназначение чисел, которое к данной сетке можно применить — это нейтральное переназначение, то есть то, которые не перемешивает числа. Для этого переназначения можно добавить следующую эвристику: если в перестановке ячеек сетки какая-нибудь из ячеек переходит в другую ячейку в том же столбце или блоке или той же строке, то тогда для этого случая общее число неподвижных точек равно нулю.
Так что давайте добавим к нашей структуре еще и эти две эвристики:
Названия этих методов не самые удачные, но is_immovable() означает, что для данной симметрии «двигать» перестановку переназначений смысла нет, а has_bad_cycle() — что для нейтральной перестановки переназначений нет смысла делать перебор.
А вот, собственно, сам перебор:
В процедуре process_class() мы обрабатываем каждый класс следующим образом. Если симметрия из данного класса ничего не меняет — то ответ для нее мы уже знаем из прошлой части статьи. Иначе инициализируем нашу структуру и натравливаем на нее эвристики. Если повезло — ничего перебирать не надо. Иначе все-таки придется перебирать. В начале перебора мы подготавливаем структуру и заполняем первый блок стандартным образом. После этого запускаем сам перебор поиском в глубину dfs2().
Общее время работы всей программы вместе с этим кодом на моей машине составляет около 50 минут. Листинг вывода (из которого я удалил строки, в которых число неподвижных точек равно 0), выглядит следующим образом:
Ответ совпадает с тем, что получили Расселл и Джарвис. Количество неподвижных точек из листинга можно сравнить с их рассчетами тут.
Весь код нашей программы можно найти тут.
Итак, подзадача для решения: нам нужно по некоторой симметрии g посчитать количество неподвижных точек из множества Y (всего таких подзадач 275). Что происходит с каждой неподвижной точкой при применении g? Числа в сетке судоку меняются местами в соответствии с некоторой перестановкой, затем идет переназначение чисел, и после этого мы получаем изначальную сетку. И тот факт, что числа как-то переназначаются, создает сложность при построении перебора. Однако, заметим, что если какая-то сетка является неподвижной точкой для какого-то одного переназначения, то для всех остальных переназначений она неподвижной точкой не является. Поэтому мы можем перебрать всевозможные переназначения, найти для каждого из них число неподвижных точек, а затем все сложить.
Получается теперь нам надо решать такую подподзадачу: даны симметрия g и переназначение чисел h, нужно для них посчитать число неподвижных точек из Y. Теперь рассмотрим какую-нибудь неподвижную точку y из Y, а конкретно — число p в какой-нибудь ячейке (i,j). При применении g к y, (i,j) переходит в некоторую позицию (i',j')=(i,j)·g, в которой, согласно переназначению h, будет число q=p·h. Так как конечная сетка равна изначальной, то число q должно стоять в изначальной сетке в позиции (i',j').
То есть, происходит следующее. g — это некоторая перестановка ячеек сетки судоку, которую можно разбить на циклы. Например, при симметрии поворота на 90 градусов, в этой перестановке будет находиться цикл (1,1)->(1,9)->(9,9)->(9,1)->(1,1) длины 4. h — это тоже некоторая перестановка, но уже просто из 9 чисел. И там тоже все распадается на циклы. Например, там может быть цикл 2->3->2 длины 2. И теперь, если мы хотим в позицию (1,1) поставить 2, то в (1,9) мы обязаны поставить 3, в (9,9) — 2, а в (9,1) — 3. Далее цикл замыкается. Заметим, что если длина цикла в сетке судоку не делится на длину цикла в переназначении — то мы не можем в данный цикл в судоку записать ни одно число из цикла переназначения, поскольку в самом конце у нас цикл «не замкнется».
Теперь нам нужно просто реализовать перебор, в котором операция присваивания числа ячейке сетки судоку дополнительно нужным образом расставляет нужные числа по всему циклу (ну и параллельно проверяет, что нигде не нарушилось Главное Правило).
Давайте начнем со структуры, которая инициализирует себя и для каждого элемента сетки просчитывает длину цикла, в который этот элемент входит (ну и еще считает кое-какие вещи по мелочи):
struct MEGAGRID
{
int T[9][9];
bool R[9][10], C[9][10], B[9][10];
int S[9][9]; // symmetry permutation
int s_cycle[9][9]; // length of cycle for every element
int M[10]; // mapping permutation
int m_cycle[10]; // length of cycle for every element
void init( SYMMETRY sym )
{
for (int a=0; a<9; a++)
for (int b=0; b<9; b++)
S[a][b] = sym.m[a][b];
memset( s_cycle, 0, sizeof( s_cycle ) );
for (int a=0; a<9; a++)
for (int b=0; b<9; b++)
if (s_cycle[a][b] == 0)
{
int cycle_len = 0;
int i = a, j = b;
while(1)
{
int tmp = S[i][j];
i = tmp/9;
j = tmp%9;
cycle_len++;
if (i==a && j==b) break;
}
while(1)
{
s_cycle[i][j] = cycle_len;
int tmp = S[i][j];
i = tmp/9;
j = tmp%9;
if (i==a && j==b) break;
}
}
for (int a=1; a<10; a++)
M[a] = a;
for (int a=1; a<10; a++)
m_cycle[a] = 1;
}
bool next_perm()
{
if (!next_permutation( M+1, M+10 )) return false;
memset( m_cycle, 0, sizeof( m_cycle ) );
for (int a=1; a<=9; a++)
if (m_cycle[a] == 0)
{
int cycle_len = 0;
int i = a;
while(1)
{
i = M[i];
cycle_len++;
if (i==a) break;
}
while(1)
{
m_cycle[i] = cycle_len;
i = M[i];
if (i==a) break;
}
}
return true;
}
void clear()
{
memset( T, 0, sizeof( T ) );
memset( R, 0, sizeof( R ) );
memset( C, 0, sizeof( C ) );
memset( B, 0, sizeof( B ) );
}
} G;
Процедура init() сохраняет в структуру текущую симметрию, и находит для нее все циклы. Кроме того, init() сбрасывает текущее переназначение до нейтрального. Процедура next_perm() позволяет перечислить всевозможные переназначения и для каждого из них находит все циклы в переназначении. Процедура clear() очищает все ячейке в сетке T, которую мы пытаемя построить.
Теперь добавим нашей структуре методы для того, чтобы можно было записывать и удалять числа:
struct MEGAGRID
{
/* old code */
bool set_num( int num, int x, int y )
{
int n0=num, x0=x, y0=y;
if (s_cycle[x][y] % m_cycle[num] != 0) return false;
int L = s_cycle[x][y];
for (int a=0; a<L; a++)
{
if (R[x][num] || C[y][num] || B[(x/3)*3+(y/3)][num])
{
if (a>0) unset_num( n0, x0, y0, a ); // undo changes
return false;
}
T[x][y] = num;
R[x][num] = true;
C[y][num] = true;
B[(x/3)*3+(y/3)][num] = true;
int tmp = S[x][y];
x = tmp/9;
y = tmp%9;
num = M[num];
}
return true;
}
void unset_num( int num, int x, int y, int sz=0 )
{
int L = s_cycle[x][y];
if (sz!=0) L = sz;
for (int a=0; a<L; a++)
{
T[x][y] = 0;
R[x][num] = false;
C[y][num] = false;
B[(x/3)*3+(y/3)][num] = false;
int tmp = S[x][y];
x = tmp/9;
y = tmp%9;
num = M[num];
}
}
} G;
Процедура set_num() пытается присвоить нужные значения по всему циклу, в случае неудачи — все изменения откатываются. unset_num() же откатывает изменения. Отметим, что set_num() в случае неудачи использует unset_num() для отмены изменений, используя «скрытый» параметр, чтобы отменить изменения не по всему циклу, а только по измененной его части.
В принципе, уже можно было бы начать писать сам перебор, но, забегая вперед, скажу, что он будет тормознутый и в него надо будет добавить немного отсечений. Каких? Давайте вспомним последнее упражнение прямо перед этим спойлером. Там рассматривались симметрии, которые не меняли что-нибудь в сетке: строку, столбец или блок. Если же в сетке что-то из этого списка не меняется, то единственное переназначение чисел, которое к данной сетке можно применить — это нейтральное переназначение, то есть то, которые не перемешивает числа. Для этого переназначения можно добавить следующую эвристику: если в перестановке ячеек сетки какая-нибудь из ячеек переходит в другую ячейку в том же столбце или блоке или той же строке, то тогда для этого случая общее число неподвижных точек равно нулю.
Так что давайте добавим к нашей структуре еще и эти две эвристики:
struct MEGAGRID
{
/* old code */
bool is_immovable()
{
for (int a=0; a<9; a++)
{
bool flag = true;
for (int b=0; b<9; b++)
if (S[a][b] != a*9+b)
flag = false;
if (flag) return true;
}
for (int b=0; b<9; b++)
{
bool flag = true;
for (int a=0; a<9; a++)
if (S[a][b] != a*9+b)
flag = false;
if (flag) return true;
}
for (int a=0; a<3; a++)
for (int b=0; b<3; b++)
{
bool flag = true;
for (int i=0; i<3; i++)
for (int j=0; j<3; j++)
if (S[a*3+i][b*3+j] != (a*3+i)*9+b*3+j)
flag = false;
if (flag) return true;
}
return false;
}
bool has_bad_cycle()
{
for (int a=0; a<9; a++)
for (int b=0; b<9; b++)
{
int x = S[a][b]/9, y = S[a][b]%9;
if (!(x==a && y==b))
if (x==a || y==b || (x/3)*3+(y/3)==(a/3)*3+(b/3))
return true;
}
return false;
}
} G;
Названия этих методов не самые удачные, но is_immovable() означает, что для данной симметрии «двигать» перестановку переназначений смысла нет, а has_bad_cycle() — что для нейтральной перестановки переназначений нет смысла делать перебор.
А вот, собственно, сам перебор:
long long sudoku_count;
void dfs2( int x, int y )
{
while(1) // find next empty cell
{
y++;
if (y==9) { y=0; x++; }
if (x==9) // no empty cell
{
sudoku_count++;
return;
}
if (G.T[x][y]==0) break;
}
for (int a=1; a<=9; a++)
if (G.set_num( a, x, y ))
{
dfs2( x, y );
G.unset_num( a, x, y );
}
}
long long process_class( SYMMETRY s )
{
if (s==SYMMETRY::E()) return 18383222420692992L;
long long re = 0;
G.init( s );
bool imm = G.is_immovable();
bool hbc = G.has_bad_cycle();
if (imm && hbc) return re;
if (hbc) G.next_perm();
int ind = 0;
do
{
ind++;
if (ind%1000==0) fprintf( stderr, "." );
G.clear();
bool flag = true;
for (int a=1; a<=9; a++)
{
int x = (a-1)/3, y = (a-1)%3;
if (G.T[x][y]>0 && G.T[x][y]!=a) { flag = false; break; }
if (G.T[x][y]==0 && !G.set_num( a, x, y )) { flag = false; break; }
}
if (flag)
{
sudoku_count = 0;
dfs2( 0, 0 );
re += sudoku_count;
}
if (imm) break;
}
while (G.next_perm());
return re;
}
void process_all_classes()
{
long long answer = 0;
long long sum = 0;
int i = 0;
for (map< SYMMETRY, int >::iterator it = classes.begin(); it != classes.end(); it++)
{
fprintf( stderr, "class %3d", i );
long long tmp = process_class( it->first );
printf( "class %3d %6d x %17lld\n", i, it->second, tmp );
fprintf( stderr, " %6d x %17lld\n", it->second, tmp );
i++;
answer += tmp * it->second;
sum += it->second;
}
printf( "total sum %lld\n", answer );
printf( "essentialy different sudoku grids %lld\n", answer/sum );
}
В процедуре process_class() мы обрабатываем каждый класс следующим образом. Если симметрия из данного класса ничего не меняет — то ответ для нее мы уже знаем из прошлой части статьи. Иначе инициализируем нашу структуру и натравливаем на нее эвристики. Если повезло — ничего перебирать не надо. Иначе все-таки придется перебирать. В начале перебора мы подготавливаем структуру и заполняем первый блок стандартным образом. После этого запускаем сам перебор поиском в глубину dfs2().
Общее время работы всей программы вместе с этим кодом на моей машине составляет около 50 минут. Листинг вывода (из которого я удалил строки, в которых число неподвижных точек равно 0), выглядит следующим образом:
number of classes 275
class 0 1 x 18383222420692992
class 78 972 x 449445888
class 114 2916 x 155492352
class 120 1296 x 30258432
class 132 69984 x 13056
class 135 16 x 107495424
class 137 96 x 21233664
class 140 192 x 4204224
class 189 3888 x 27648
class 195 10368 x 1854
class 199 144 x 14837760
class 201 864 x 2085120
class 204 1728 x 294912
class 220 7776 x 13824
class 222 15552 x 1728
class 229 288 x 5184
class 231 1728 x 2592
class 234 3456 x 1296
class 244 93312 x 288
class 247 64 x 2508084
class 257 1152 x 6342480
class 262 15552 x 3456
class 264 31104 x 6480
class 265 2304 x 648
class 269 5184 x 323928
class 271 20736 x 288
class 274 20736 x 162
total sum 18384171550626816
essentialy different sudoku grids 5472730538
total time 3013 sec
Ответ совпадает с тем, что получили Расселл и Джарвис. Количество неподвижных точек из листинга можно сравнить с их рассчетами тут.
Весь код нашей программы можно найти тут.
Случай 4x4
Давайте посмотрим на судоку порядка 2, или сетку судоку размера 4?4, для того, чтобы лучше понять идеи, которые были рассмотрены выше (и в предыдущей части тоже).
Для того, чтобы посчитать количество сеток судоку 4?4, мы начнем — как и в случае с случаем 9?9 — с заполнения левого верхнего блока стандартным способом. Это делит количество различных сеток судоку на 4!, поскольку у нас есть ровно 4! переназначить числа в этом блоке.
Когда мы сделаем это, 1 и 2 окажутся на первых двух позициях первой строки, а 3 и 4 — на следующих двух позициях. Для каждой из 4! расстановок, у нас есть два способа вставить 3 и 4, и это влияет на общее число различных сеток. С другой стороны, если мы ходим посчитать лишь количество существенно различных сеток, порядок следования 3 и 4 не имеет значения, поскольку мы можем поменять местами третий и четвертый столбцы и получить все еще корректную сетку. Так что мы можем полагать, что 3 находится в третьей ячейке первой строки, а 4 — в четвертой.
Так как 1 и 3 уже имеются в первом столбце, 2 и 4 должны быть вставлены в третью и четвертую ячейку в этом столбце. Так как у нас два способа сделать это, наше количество различных сеток теперь считается сразу пачками по 4!?2?2 штук. Для подсчета количества существенно различных сеток, мы отмечаем, что обмен местами третьей и четвертой строк — это одна из симметрий сетки, так что мы можем считать, что 2 находится в третьей ячейке первого столбца, а 4 — в четвертой. К текущему моменту наша сетка имеет следующий вид:
Поскольку в третьей строке есть 2, а в третьем столбце есть 3, в ячейку (3,3) мы можем вставить либо 1, либо 4.
Упражнение Покажите, что если в позицию (3,3) вставить 1, то это в конечном итоге приведет к нарушению Главного Правила.
Таким образом, в позиции (3,3) обязано находиться число 4. В четвертой строке, четвертом столбце, да еще и в правом нижнем блоке — во всех них у нас есть только 4, поэтому в ячейку (4,4) мы можем вставить любое из чисел 1, 2 и 3. Это дает нам следующие три сетки, то есть для каждой из 4!?2?2, которые мы насчитали ранее, есть ровно 3 способа поставить следующее число в позицию (4,4) (а дальше сетки заполняются однозначным образом). Таким образом, число различных сеток судоку 4?4 равно 4!?2?2?3=288.
Упражнение Заполните до конца все три сетки. После этого проверьте, что вторая и третья сетки на самом деле эквивалентны — можно отразить третью сетку по диагонали (какой из двух?) после чего переназначить числа 2 и 3.
То есть, в конечном итоге, у нас остается всего две существенно различные сетки судоку 4?4.
Еще немного интересных фактов
Правильно составленная головоломку судоку должна иметь единственное решение. В общем случае, судоку может иметь несколько решений, но в этом случае логических приемов, которые мы обсуждали в главе про подходы к решению, может оказаться недостаточно. Известен пример судоку порядка 3 с 17 числами, данными изначально, который правильно составлен. Минимальное же число подсказок для правильно составленного судоку порядка 3 — неизвестно (на самом деле, уже известно).
Упражнение Можете ли вы привести пример судоку, который не является правильно составленным?
Другой интересны вопрос (который мог прийти вам в голову, когда вы решали предыдущее упражнение): как много различных чисел может быть использовано для того, чтобы головоломка была правильно составленной? Оказывается, что для судоку порядка n, для получения единственного решения, необходимо использовать минимум n2-1 различных чисел. Если мы для головоломки порядка n используем только n2-2 различных чисел, то перестановка тех чисел, которых нет в подсказках, в одном из решений даст нам другое решение. В частности, для обычной судоку порядка 3, нужно использовать не менее 32-1=8 различных чисел, чтобы получить правильно составленную головоломку. Иначе пазл будет иметь более одного решения (или ни одного?).
Факт, описанный в предыдущем абзаце, можно переформулировать следующим образом: если судоку порядка n правильно составлена, то в ней должно содержаться как минимум n2-1 различных чисел в самом начале. Важно отметить, что это не то же самое, что если судоку порядка n имеет n2-1 различных чисел, то она правильно составлена. Вспомните, что если из A следует B, то из B не обязательно следует A. Следующее упражнение иллюстрирует этот момент специальным примером.
Упражнение Следующая судоку порядка 2 имеет 22-1=3 различных чисел. Найдите два различных решения.
Для судоку 4?4, анализ всех (двух) случаев существенно различных сеток доказывает, что правильно составленная головоломка должна иметь как минимум четыре начальных подсказки.
Наконец, нельзя не отметить, что хотя компьютерные программы в мгновение ока решают судоку порядка 3, используя метод перебора с возвратом, решение судоку произвольного порядка n — гораздо более сложная задача. В то время как порядок судоку изменяется с n на n+1 (всего на единицу), время, нужное для решения, вырастает на порядки. Доказано, что задача решения судоку порядка n входит в класс NP-полных задач. Задача называется NP-полной, если для нее выполняются следующие два свойства:
- Решение любой такой задачи можно проверить относительно быстро, т.е. за полиномиальное время.
- Если хоть одна из таких задач может быть решена относительно быстро, то тогда относительно быстро можно решить и все задачи, удовлетворяющих свойству (1).
Хотя и проверить правильность решения NP-полных задач — быстро и легко, пока неизвестно алгоритма, который бы быстро находил это решение. Для алгоритмов, известных на текущий момент, время выполнения растет слишком быстро с ростом размера входных данных.
Вместо заключения
И на этой грустной ноте статья подходит к концу, как и ее перевод. Я лично в процессе перевода (а особенно написания комментариев) узнал и понял много нового. Надеюсь, вы тоже.
Список литературы оригинальной статьи можно посмотреть тут.
Спасибо всем, кто осилил до конца.
Поделиться с друзьями
Комментарии (6)

LoadRunner
16.11.2016 14:31+1Спасибо большое за перевод. Голова пухнет от попыток понять всё, что написано, особенно код, но в целом стало понятно, как они всё подсчитали. Только пока сам не проверю и не приду к таким же результатам — не поверю :)
EndUser
Меня позабавило, то, что когда минимальное количество подсказок хотели брутфорснуть распределёнными вычислениями, написали BOINC приложение, подключили публику — пришёл один математик и строго доказал, что это число равно 17 — задолго до того, как должен был завершиться полный перебор.
ripatti
А можно ссылку на пруф этого утверждения? А то мне известна только ссылка на доказательство оптимизированным брутфорсом (она есть в тексте перевода). И считали они там 7 миллионов ядролет (!) на кластере из 300 серверных машин (через MPI, а не BOINC). Причем программа была написана на ассемблере.
EndUser
http://www.distributedcomputing.info/ap-puzzles.html#sudoku
ripatti
Интересно. К сожалению, больше информации по этому проекту нагуглить не могу.
Зато я нагуглил информацию по другому проекту. Они другим алгоритмом через BOINC подтвердили результаты, которые я привел в тексте перевода. Вот ссылки: раз два.
ripatti
Впрочем, я припоминаю подобную историю с проверкой нулей зета-функции Римана. Вроде из-за этого закрыли проект ZetaGrid, поскольку они там всей толпой распределенными вычислениями проверили меньше нулей, чем один математик на своем десктопе…