
 В предыдущих частях опуса (1, 2, 3) мы рассмотрели внутреннее строение lock-free map и убедились, что все основные операции — поиск, добавление и удаление ключа — могут быть выполнены без глобальных блокировок и даже в lock-free манере. Но стандартный
В предыдущих частях опуса (1, 2, 3) мы рассмотрели внутреннее строение lock-free map и убедились, что все основные операции — поиск, добавление и удаление ключа — могут быть выполнены без глобальных блокировок и даже в lock-free манере. Но стандартный std::map поддерживает ещё одну очень полезную абстракцию — итераторы. Возможно ли реализовать итерабельный lock-free map?Ответ на этот вопрос — под катом.
Ещё год назад я был уверен, что итераторы в принципе нереализуемы для lock-free контейнеров. Судите сами: итератор позволяет обойти все элементы контейнера; но в мире lock-free содержимое контейнера постоянно меняется, что же считать под «обойти все элементы»?
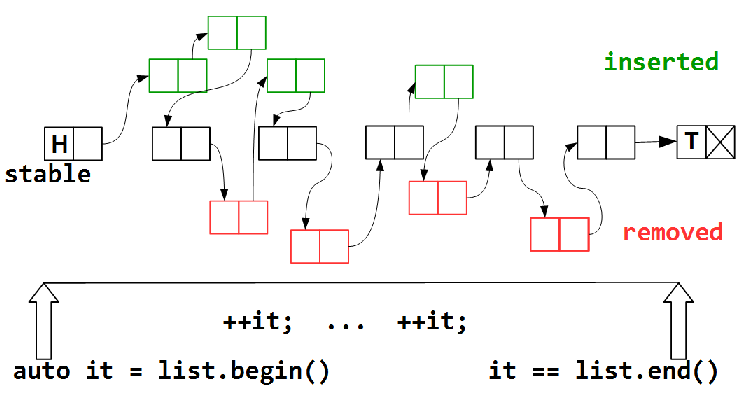
Итерирование — обход элементов контейнера — занимает некоторое время, за которое одни элементы будут удалены из контейнера, другие — добавлены, но должно существовать некоторое подмножество stable (возможно, пустое) элементов, которые присутствуют в контейнере за все время обхода — от
list.begin() до list.end(). Помимо них, мы можем посетить некоторые из добавленных элементов, как и некоторые из удаленных, — как карта ляжет. Очевидно, что задача посетить все элементы в lock-free map невыполнима, — мы не можем заморозить состояние нашего контейнера на все время обхода; такая заморозка фактически означает запрет другим потокам выполнять над контейнером модифицирующие операции, что равносильно блокировке.Другая техника — конкурентные контейнеры с поддержкой snapshot (мгновенных снимков контейнера). В чем-то она схожа с версионными контейнерами.
Обе эти техники предполагают повышенный расход памяти на хранение версий или снапшотов, равно как и дополнительные операции по поддержке своей внутренней структуры. Зачастую этот перерасход несуществен по сравнению с преимуществами, которые предоставляют такие техники.
В данной статье я хочу рассмотреть конкурентные ассоциативные контейнеры без применения подобных техник. То есть вопрос стоит так: можно ли построить такой конкурентный контейнер, который по самой своей внутренней структуре допускает безопасный обход элементов?
Итак, будем считать обходом конкурентного контейнера гарантированное посещение всех узлов из подмножества stable.
Кроме вопроса «что считать обходом конкурентного контейнера», существует две проблемы:
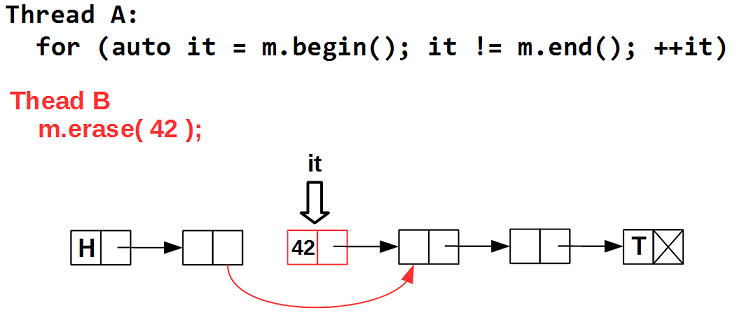
Проблема 1. Итератор — это по сути специализированный указатель на элемент контейнера. Используя итератор, мы получаем доступ к самому элементу. Но в конкурентном контейнере элемент, на котором позиционирован итератор, может быть в любой момент удален. То есть итератор может в любой момент стать невалидным, — указывать на удаленный элемент, то есть на мусор:
Решением данной проблемы в схеме Hazard Pointer является собственно hazard pointer. Вспомним, что схема HP гарантирует, что пока указатель объявлен как hazard, он (указатель) не может быть физически удален, то есть он не может превратиться в
guarded_ptr:template <typename T>
struct guarded_ptr {
hp_guard hp; // защищает элемент
T * ptr; // элемент контейнера
guarded_ptr(std::atomic<T *>& p)
{
ptr = hp.protect( p );
}
~guarded_ptr() { hp.clear(); }
T * operator ->() const { return ptr; }
explicit operator bool() const
{ return ptr != nullptr; }
};
Как видим,
guarded_ptr – это просто указатель с hazard pointer'ом. Hazard pointer hp защищает указатель на элемент ptr, предотвращая его физическое удаление. Теперь если даже некий поток B удалит элемент, на который позиционирован итератор, этот элемент будет исключен из контейнера, но физически не будет удален, пока hazard pointer итератора содержит ссылку на данный элемент.Таким образом, в схеме HP класс итератора будет выглядеть следующим образом:
template <typename T>
class iterator {
guarded_ptr<T> gp;
public:
T* operator ->() { return gp.ptr; }
T& operator *() { return *gp.ptr; }
iterator& operator++();
};
guarded_ptr нет, достаточно потребовать, чтобы итерирование (обход всех элементов контейнера) производилось в одной эпохе:urcu.lock(); // вход в эпоху
for ( auto it = m.begin(); it != m.end(); ++it ) {
// ...
}
urcu.unlock(); // выход из эпохи
Проблема 2: переход к следующему элементу.

Если некий поток B удалит элемент, следующий за тем, на который позиционирован итератор — в данном случае 42, — операция инкрементирования итератора приведет к обращению к удаленному элементу, то есть к мусору.
Эта проблема посложнее, чем первая, так как потоки ничего не знают о том, что мы обходим контейнер, и вольны удалять/добавлять любые элементы. Можно подумать о том, чтобы каким-то образом помечать элемент, на который указывает итератор, и при удалении элемента анализировать такой флаг, но это как минимум усложнит внутреннее строение контейнера (а как максимум — такие рассуждения ни к чему не приведут). Есть другой путь, который нам подскажет интересная структура данных — multi-level array.
Multi-level array
Эта структура данных предложена в 2013 году Стивом Фельдманом (Steve Feldman) и представляет собой ассоциативный контейнер, то есть hash map.
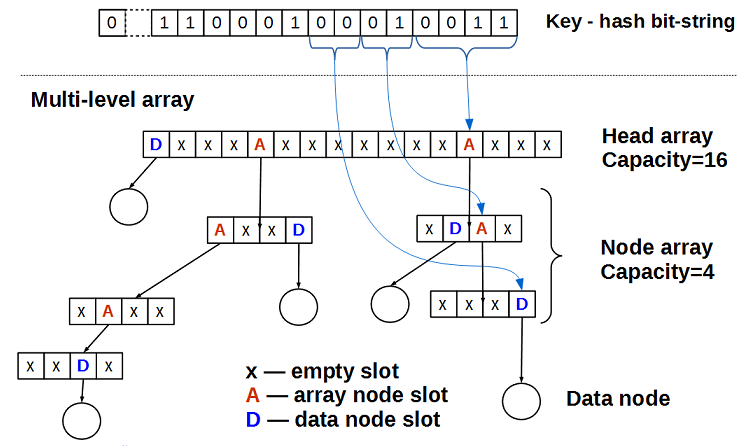
Представим, что хеш — это битовая строка постоянной длины. Будем рассматривать биты этой строки как индексы в многоуровневом массиве: первые M бит — это индекс в головном масиве head array (на рисунке M=4, то есть размер head array равен 2**4 = 16), следующие порции по N бит — это индексы в нижележащих массивах node array (на рисунке N = 2 и размерность node array равна 2**2 = 4). Элемент массива может быть:
- пуст
- указателем на данные
- указателем на массив следующего уровня
Пустой multi-level array состоит только из head array, у которого все ячейки — пустые.
Добавление данных
data с ключом key в multi-level array происходит по следующему алгоритму:- 1. вычисляем хеш ключа
h = hash( key ) - 2. Берем первые M бит хеша
h– это индексiячейки в head array - 3a. Если ячейка пуста (
head_array[i] == nullptr), то помещаем данные в неё:head_array[i].CAS( nullptr, &data )— и выходим. Так как у нас lock-free контейнер, мы используем атомарные операции, в данном случае — CAS (compare-and-swap, в терминах C++11 – этоstd::compare_exchange). - 3b. Если ячейка содержит данные (
head_array[i] = di), нужно её расщепить, то есть создать node array следующего уровня, поместить в негоdiи перейти к шагу 4. - 3c. Если ячейка содержит указатель на нижележащий node array – перейти к шагу 4.
- 4. Текущий array – некий node array. Берем следующие N бит хеша ключа
h, эти биты будут индексомiв текущем node array. Если все биты хеша исчерпаны — значит, в контейнере уже есть элемент с таким же хешем и вставка данныхdataзаканчивается неудачей. - 4a. Если ячейка пуста (
current_node_array[i] == nullptr), то помещаем данные в неё:current_node_array[i].CAS( nullptr, &data )— и выходим - 4b. Если ячейка содержит данные (
current_node_array[i] = di), нужно её расщепить, то есть создать node array следующего уровня, поместить в негоdiи перейти к шагу 4. - 4c. Если ячейка содержит указатель на нижележащий node array – перейти к шагу 4.
Как видим, алгоритм вставки очень прост и интуитивно понятен — его легче нарисовать, чем описывать словами. Алгоритм удаления ещё проще: рассматривая хеш-значение удаляемого ключа как битовую строку, выделяя биты и интерпретируя их как индексы в массивах, мы спускаемся по ссылкам до массива, ячейка которого либо пуста, либо содержит данные. Если ячейка пуста, — значит, нашего ключа (точнее, его хеша) нет в контейнере и удалять нечего. Если ячейка содержит данные и ключ этих данных есть искомый ключ — меняем значение ячейки на
nullptr с помощью атомарной операции CAS. Заметим, что при удалении мы просто обнуляем ячейку массива, сами node_array никогда не удаляются, — этот факт нам пригодится в дальнейшем.Остается открытым вопрос: как различить, что содержит ячейка массива — данные или указатель на массив следующего уровня. В обычном программировании мы бы поместили в каждый слот массива булевый признак:
struct array_slot {
union {
T* data;
node_array* array;
};
bool is_array; // признак, что содержит ячейка — data или array
};
Но у нас программирование необычное, и этот подход нам не подойдет. Необычность заключается в том, что мы должны оперировать атомарным примитивом CAS, который имеет ограничение на длину данных. То есть изменять значение ячейки и признака
is_array мы должны уметь атомарно, одним CAS'ом.Это не является проблемой, если вы читали предыдущую часть lock-free эпопеи и знаете, что есть такая вещь как marked pointer. Мы будем хранить признак
is_array в младшем бите указателя ячейки массива:template <typename T>
using array_slot = marked_ptr<T*, 3 >;
Таким образом, ячейка массива — это просто указатель, у которого мы используем последние 2 бита (маска 3 у
marked_ptr) для внутренних флагов: один бит для признака «ячейка содержит указатель на массив следующего уровня», плюс ещё один бит для… а для чего?..Посмотрим внимательно на алгоритм вставки. Шаги 3b и 4b говорят о расщеплении ячейки, то есть превращении её из ячейки, содержащей данные, в ячейку, содержащую указатель на нижележащий массив. Такое преобразование довольно длительно, так как требует:
- создания нового node_array;
- обнуления всех его элементов;
- поиска позиции в новом node_array для данных расщепляемой ячейки;
- записи в новый node_array в найденную позицию данных расщепляемой ячейки;
- и наконец, установки нового значения расщепляемой ячейки
Пока производятся все эти действия, расщепляемая ячейка находится в неопределенном состоянии. Именно это состояние мы и кодируем вторым младшим битом. Все операции над multi-level array, встретив флаг «ячейка расщепляется», ожидают окончания расщепления такой ячейки, используя активное ожидание (spinning) на этом флаге:
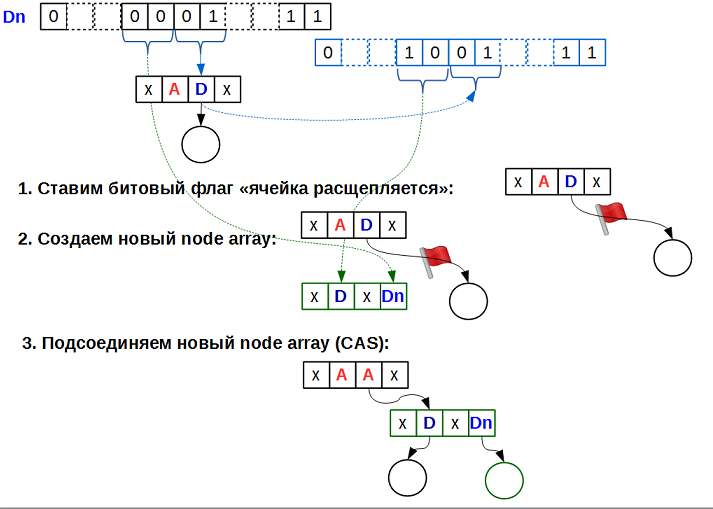
на рисунке черные данные — это добавляемый ключ
Dn, синие — существующий DРассмотрим по операциям. В общем, map поддерживает всего три операции (остальное — их разновидности): поиск, вставку и удаление ключа. Для поиска факт «ячейка находится в стадии расщепления» совершенно не важен: поиск должен посмотреть, что это за ячейка; если ячейка содержит указатель на данные — надо сравнить ключ данных с искомым (раз мы уперлись в ячейку с данными, значит, префикс битовой строки — хеша искомого ключа и данных в ячейке — совпадают и данные в ячейке могут быть искомыми). Если же ячейка — указатель на массив, мы должны просто перейти в этот массив и продолжить поиск в нем. Предположим, что искомый ключ — это именно те данные, ради которых расщепляется ячейка, то есть мы имеем ситуацию: один поток ищет ключ K, другой поток — добавляет данные с этим же ключом K, и это происходит одновременно. Раз это происходит одновременно, операция поиска будет правильной как в случае «ключ найден», так и в случае «ключ не найден». Получается, что для операции поиска флаг расщепления не нужен.
Операция вставки. Если вставка натыкается на расщепляемую ячейку, значит, другой поток добавляет данные с префиксом хеш-значения ключа тем же самым, что и текущий поток. В этом случае оба потока (обе операции вставки) могли бы «помочь» друг другу, создавая каждая node_array и пытаясь установить его в качестве значения расщепляемой ячейки. Так как значение ячейки устанавливается примитивом CAS, а node_array никогда не удаляются (то есть ABA-проблемы для указателей на node_array быть не может), только один из потоков вставки выйдет победителем (установит новое значение расщепляемой ячейки), второй поток обнаружит, что значение ячейки изменилось и надо удалить node_array, который он (этот второй поток) пытается создать, и использовать то значение расщепляемой ячейки, которое появилось. То есть для вставки флаг расщепления тоже не нужен.
Удаление. Прежде чем удалить, надо найти то, что нужно удалять, то есть удаление в этом смысле равносильно поиску и флаг расщепления не нужен.
Единственная операция, над которой надо подумать, — это update, обновление данных.
Если флаг расщепления ячейки устанавливает низкоприоритетный поток, а потом он вытесняется, это может быть очень болезненным для общей производительности контейнера, так как остальные потоки, более приоритетные, будут ожидать окончания выполнения расщепления, то есть ожидать, пока низкоприоритетный поток выполнит свою работу. В этом случае избавление от флага расщепления может быть очень полезным.
Структура данных multi-level array проста и интересна, но её особенностями (хотел написать «недостатками», но это все же особенности) являются:
- она требует идеального хеширования. Идеальная хеш-функция — это такая хеш-функция
h, которая для любых ключейk1иk2таких, чтоk1 != k2, дает разные хеш-значения:h(k1)!= h(k2). То есть multi-level array не допускает коллизий. - ключи (или хеш-значения ключей) разного размера не поддерживаются. То есть ключ
std::stringпеременной длины нельзя использовать как битовую строку.
Но если ваш ключ постоянного размера (или вы имеете идеальную хеш-функцию), multi-level array является очень хорошим lock-free контейнером, ИМХО.
В принципе, можно обобщить multi-level array, чтобы он поддерживал списки коллизий: для этого достаточно вместо данных использовать lock-free список в качестве списка коллизий. Другое обобщение для ключей переменной длины: считать, что у короткого ключа все остальные биты в битовой строке равны нулю.
push_back и pop_back можно сделать, если хранить в отдельной атомарной переменной текущий размер массива. Вот только если два потока одновременно выполняют push_back возможна ситуация, когда в массиве на некоторое время появится дыра: поток A инкрементирует счетчик, получает индекс j и вытесняется, а поток B получает индекс j+1 и успешно выполняет вставку по этому индексу. Здесь нам помогла бы операция 2-CAS (или её обобщение — multi-CAS, MCAS), которая может атомарно выполнять CAS над двумя (или M) несвязанными ячейками памяти.Но для целей данной статьи важно одно свойство multi-level array: однажды созданный node array никогда не удаляется. А из этого вытекает мощное следствие: multi-level array поддерживает thread-safe итераторы, более того, это bidirectional-итераторы. В самом деле, раз node array не удаляются, итератор есть указатель на node array плюс индекс в node array, что есть «указатель» на ячейку:
class iterator {
guarded_ptr<T> gp_;
node_array* node_;
int node_index_;
};
guarded_ptr здесь необходим, так как конкурентный поток может удалить данные, на которые позиционирован итератор; guarded_ptr препятствует физическому удалению. Получается, что итератор может указывать на элемент, который удален из контейнера — ещё одно неожиданное свойство lock-free структур данных. Но если хорошо подумать, такое свойство вполне объяснимо: в постоянно меняющемся мире, который представляют из себя конкурентные контейнеры, можно гарантировать только одно: на момент позиционирования итератора данная ячейка содержала валидные данные.Указатель
node_ на node_array и индекс в нем node_index_ необходимы в итераторе для перехода к следующему (или предыдущему) элементу контейнера, то есть они фактически определяют текущую позицию итератора в контейнере.Интересно отметить, что если у нас ключи постоянного размера, а не хеш-значения, то обход multi-level array является упорядоченным.
cds/intrusive/impl/feldman_hashset.h для HP-based SMR, cds/intrusive/feldman_hashset_rcu.h – для user-space RCU). Подводя итог, можно сказать: все же существуют конкурентные контейнеры, поддерживающие thread-safe итераторы, одним из таких контейнеров является multi-level array. Существуют ли другие?.. Можно ли создать итерируемый lock-free список, являющийся основой для многих интересных lock-free map?..
Подводя итог, можно сказать: все же существуют конкурентные контейнеры, поддерживающие thread-safe итераторы, одним из таких контейнеров является multi-level array. Существуют ли другие?.. Можно ли создать итерируемый lock-free список, являющийся основой для многих интересных lock-free map?.. Ответ на этот вопрос — в следующей статье.
Комментарии (16)

DaylightIsBurning
13.12.2016 16:56+1Не нашел имплементации lock-free vector в libcds. Есть какие-то сложности с его имплементацией? В других lock-free библиотеках тоже массивов нет обычно.

khizmax
13.12.2016 17:02Да, есть, мягко говоря, сложности…
Первая из них — а что такое lock-free vector? Каков его интерфейс?.. Если std::vector, — сложности экспоненциально увеличиваются.
Если lock-free vector — этоpush_back()/pop_back()+ итераторы — это чуть проще. Но что-то это стек напоминает…
Напишите, pls, что Вы ожидаете от lock-free vector!DaylightIsBurning
13.12.2016 17:28+1В идеале, конечно std::vector. Если по-минимуму — random-access assign/get, push_back, pop_back, size(). Resize() тоже не помешал бы. Итераторы очень желательно, но ещё неплохо бы что бы get/assign невалидных индексов не крашил, а установливал флаг ошибки. Мб в виде отдельных try_get/try_assign. Последнее было бы здорово т.к. на size() положиться нельзя будет же…
khizmax
13.12.2016 17:40+2Я бы тоже хотел lock-free std::vector… Пока не представляю, как его сделать.
random-access assign/get — это позволяет сделать Multi-level array «из коробки» (у меня пока такой коробки нет).
push_back() / pop_back() — с этим сложнее, как я писал: пока вижу решение только с 2-CAS, иначе возможны кратковременные дыры в векторе. Алгоритм 2-CAS (MCAS) сам по себе довольно тяжел и требует довольно нетривиальной инфраструктуры (внутренних дескрипторов), непонятно, будет ли выигрыш по сравнению с std::vector под мьютексом.
Resize()/reserve() — не покатит, это все же lock-free vector, единой непрерывной области памяти там не будет (кстати, часто это основное требование к вектору, — чтобы его данные можно было бы взять как непрерывный буфер и передать куда-нибудь в сишную либу).
В общем, запрос я услышал, тем более что сам периодически подумываю о векторах, но пока… увы

Randl
13.12.2016 17:57+1Читал о векторах, кажется, здесь. Насколько это актуально и применимо в реальной жизни — не знаю, я просто мимокрокодил
khizmax
13.12.2016 18:02Спасибо за ссылку!
Randl
13.12.2016 18:07+1Тогда вот вам еще парочку из загашника: A Wait-Free Stack, A Wait-free Queue as Fast as Fetch-and-Add, CRTurn Queue — The first MPMC memory-unbounded wait-free queue with memory reclamation
Randl
13.12.2016 19:45+1Вот еще парочка, про деревья в основном, эти правда совсем вскользь просмотрел: Concurrent Wait-Free Red Black Trees, Quadboost: A Scalable Concurrent Quadtree, ELB-Trees, An Efficient and Lock-free B-tree Derivative, Help-optimal and Language-portable Lock-free Concurrent Data Structures
Randl
А что скажете насчет wait-free map, описанного тут?
khizmax
К сожалению, «тут» ничего не описано, — дана лишь вводная часть статьи. Доступа к платным ресурсам у меня нет. Если Вы имеете оригинал — поделитесь.
Randl
Могу предложить воспользоваться http://sci-hub.cc/ или выслать PDF на почту
DaylightIsBurning
http://sci-hub.cc/10.1007/s10766-015-0376-3
khizmax
Скачано! Спасибо большое!!!
khizmax
В общем, просмотрел статью по диагонали, по-моему, это развитие Multi-level array первого анонса 2013 года. Подход весьма многообещающий, но опять я вижу perfect hashing и fixed-sized keys! О май гот (facepalm)!..
Им бы чуть-чуть ещё подумать за два года — и они бы получили полноценный map для ключей переменной длины (например, для std::string) без всякого perfect hashing.
Хотя это пока только мои задумки без доказательства в виде кода.