
Я довольно давно поставил себе цель научиться запоминать числа, в основном просто как задача для саморазвития, очевидной практической выгоды не нашел. Однако хочется запоминать телефонные номера, маршруты транспорта, даты. Мне было трудно найти и начать пользоваться готовым решением, зато захотелось поработать над своим.
Содержание статьи
- Предпосылки
- Как проверить, хороша ли система?
- Проверяем несколько систем
- Как создать систему лучше
- Ссылка на репозиторий и послесловие
Предпосылки
- Мнемоника — это способ запоминания с помощью цепочек ассоциаций. Удобнее всего запоминать цепочки слов, представляя себе каждое слово в виде образа и увязывая их вместе. Мозг легче запоминает такую графически-пространственную информацию. Например, можно запоминать ключевые слова из каждого тезиса к докладу. При этом важно верно выбирать образы, они должны быть одного порядка и не слишком абстрактными, иначе их взаимодействие не будет таким красочным и запомнить будет сложно.
- Для запоминания чисел используют кодирование цифр буквами — каждой цифре ставится в соответствие несколько гласных букв, обычно от 1 до 3. Двух- и трех- значные числа кодируются одним словом из, соответственно, двух и трех слогов. Или, если точнее, двух или трех вхождений гласных, слог может быть и один. Например, если 1 — это Д, 2 — это П, то 11 это дед, 12 это депо, а 22 это просто попа.
- Таким образом, для быстрого запоминания чисел необходимо знать наизусть какому числу какие буквы соответствуют и придумывать слова, увязывать их в цепочки.
- На практике, придумывать каждый раз слова медленно, поэтому нужно выучить 100 слов для чисел от 0 до 99. Профессионалы иногда знают слова до чисел до 999.
- При этом почему-то те мнемонические системы, которые я нашел, используют такие соответствия, что придумать слова сложно, запомнить тоже не очень. Они используют буквы, похожие на цифры по звучанию или написанию, чтобы было легче запомнить соответствие. Хотя легче не становится, т.к. 1-2 цифры такие не похожи, а вариантов "похожести" много.
- Отдельно отмечу, что использовать мнемоническую систему на английском языке я не взялся, ибо мне показалось, что знания языка не хватит, всё-таки думать быстро на нем не могу.
- Таким образом, встает вопрос, можно ли выбрать более удобные соответствия? Для выбора планировалось использовать полный перебор или методы машинного обучения.
Как проверить, хороша ли система?
Поскольку основным недостатком найденных систем я считаю сложность составления слов для некоторых чисел, то хотелось бы считать именно количество слов.
Вместо того, чтобы использовать какую-либо книгу, я использовал готовый частотный словарь. Словарь основан на национальном корпусе русского языка, который, в свою очередь, включает анализ многих книг, стихотворений разных жанров.
Частотный словарь доступен в виде csv-файла,, который я решил проанализировать. Ниже скриншоты из Jupyter Notebook, для желающих в конце статьи имеется ссылка на github.
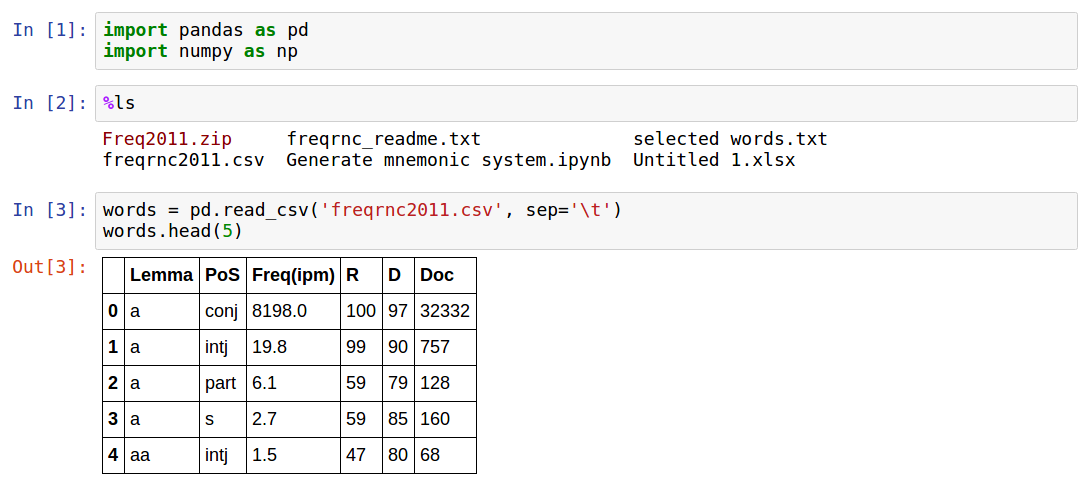
Как видно, данные содержат:
- само слово (лемму)
- обозначение части речи
- четыре метрики частоты, описанные во введнии к словарю
Я выбрал одну меритку часоты, поскольку мне важно только ранжирование. Методом проб и ошибок оказалось, что существительные — это "s".
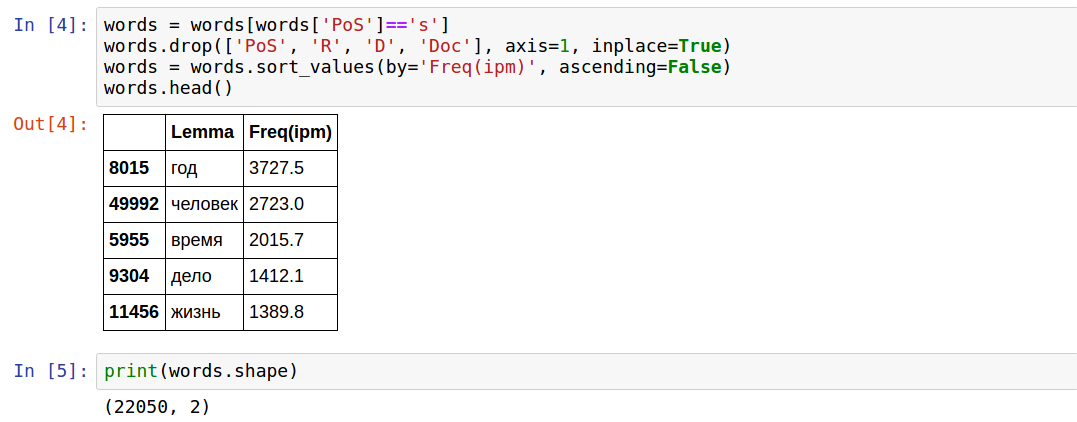
Таким образом, осталось два столбца и 22050 слов.
Однако среди этих слов есть много, которых я не знаю. Кроме того, я не хочу, чтобы основными в коде были "редкие" буквы, поэтому я решил отобрать слова, в которых таких редких букв нет. Как позже оказалось, идея не очень рабочая, но тем не менее.
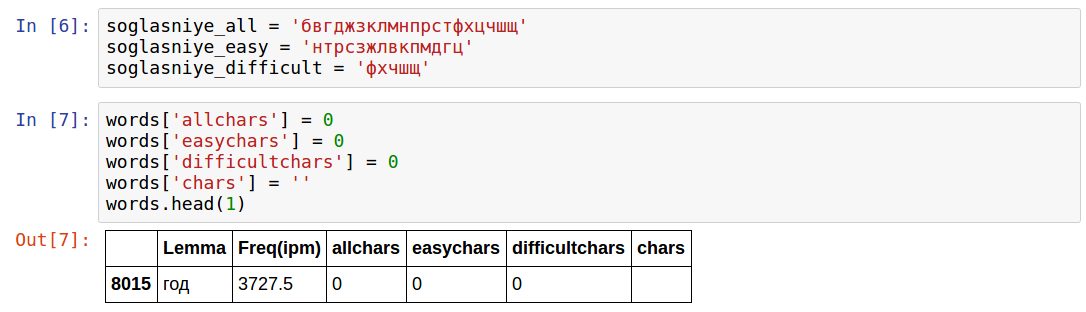
Выбрав "простые" и "сложные" буквы, посчитаем их количество. Кроме того, выведем общее количество согласных букв в слове.
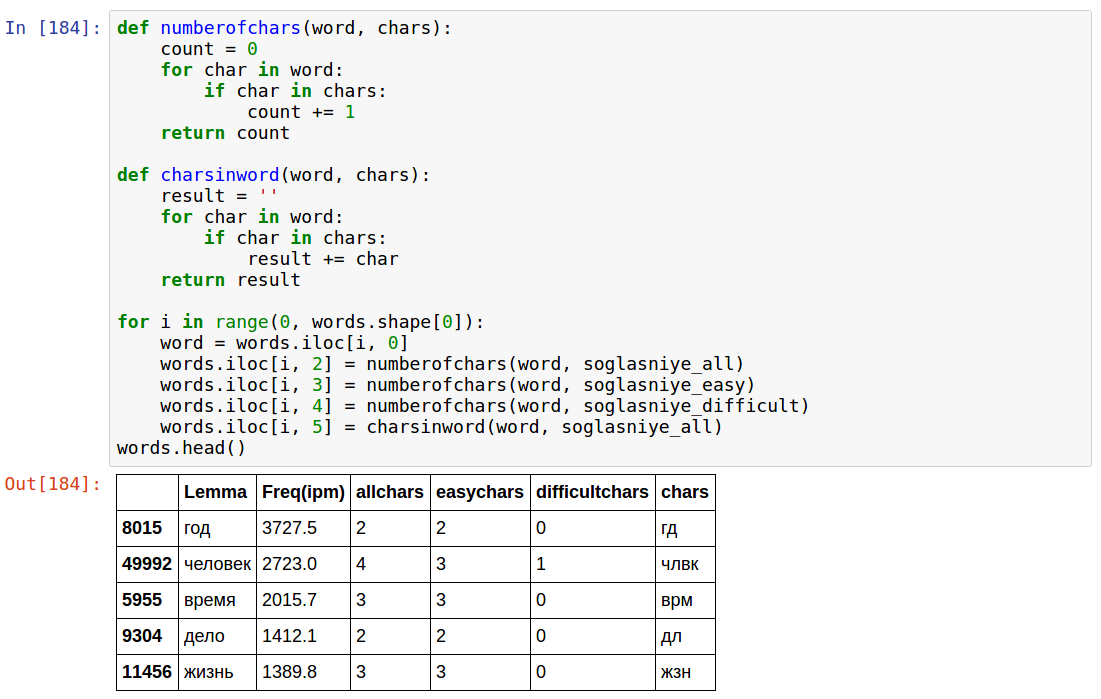
Отметим:
- allchars соответствует количеству цифр, которые можно зашифровать этим словом
- chars — это то, что можно напрямую соотнести с числом, если иметь соответствующее соответствие (я специально)
- этот код — единственный в данной статье, который работает не "моментально", а занимает около 10 секунд; я не стал думать, как сделать быстрее
Далее я подумал, что нужно отобрать слова с 2-3 согласными, без "сложных" букв, а также выбрать те, которые я знаю. Можно отрезать по своему усмотрению список отсортированный по частоте. Как позже я узнал, это идея тоже не очень, т.к. распределение слов неравномерное: всё-таки среди редких слов много известных.
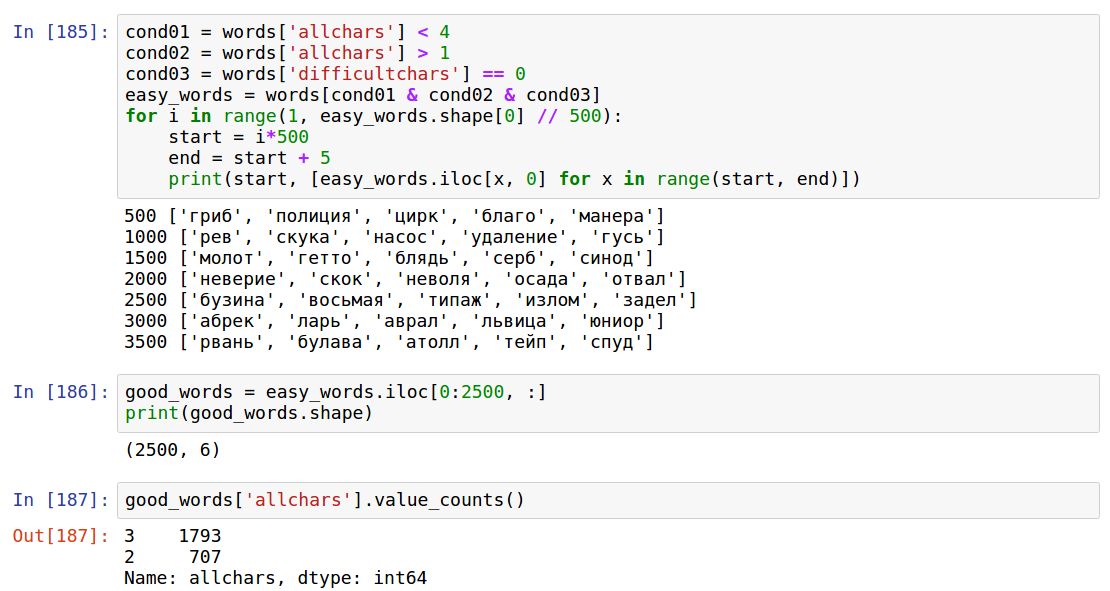
Так или иначе, в "хорошие" слова попало 2500 слов, поскольку я не знаю, что такое тейп и спуд. Из них 707 слов кодировали числа от 10 до 99 и 1793 числа от 100 до 999. Тут надо отметить, что 707 слов — это не так уж много для 90 чисел, меньше 10 слов на число, и это вместе с абстрактными и неизвестными.
Далее я задал следующие функции:
- getallcombos рекусрисвно считает все комбинации, которыми с помощью mapping (словарь число: буквы) можно закодировать число (ns — число в виде строки); возвращает список комбинаций
- testmaping проверяет сколькими словами из words_for_test (DataFrame с нашими столбцами, включая chars — только согласные) можно закодировать числа от 10 до 100 согласно предоставленному mapping; возварщает список с количеством слов для каждого числа
- testresult печатает некоторые статистики; учитывая опыт при подготовке, я для статьи оставил только строку с "0-5 words", которая показывает, сколько чисел удалось закодировать 0 словами, сколько лишь 1 словом и т.д.
Таким образом, для проверки любого мэппинга достаточно его задать и вызвать функцию тестирования.
Проверяем несколько систем
Первой мне попалась система Джордано. На ней основаны многие мобильые приложения для обучения мнемонике, она упоминается и в интернете, см., например, тут.
Именно она мне показалась сложной в работе. Попробуйте, например, придумать слова для 84 или 11. Отмечу, что в приложениях есть уже готовые образы для чисел, но тогда нужно запомнить именно их, сто штук. В этом случае есть еще вариант запомнить какие-то свои, себе близкие образы.
Так или иначе, результаты теста такие:
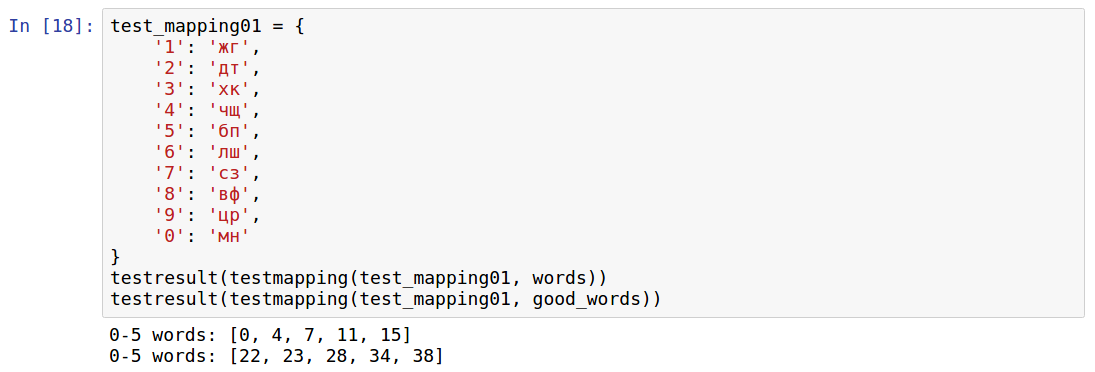
Результаты по всем словам трудно сходу проинтерпретировать, а для "простых" слов видно, что для 22 чисел вообще нет ни одного слова.
Другой мэппинг, основанный на том, с какой буквы начинается название цифры, приводится на одном сайте саморазвития. Проверим:
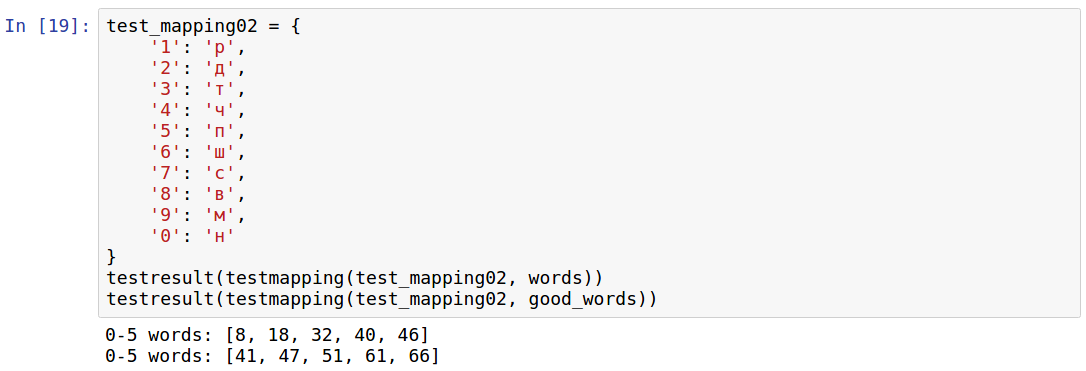
Как видно, стало сильно хуже, для 8 цифр вообще нет слов. Отмечу, что например мало слов где есть только две согласных буквы Р. Но и тем более плохая идея использовать для кода только редкие буквы вроде Ш и Ч.
Как создать систему лучше?
В процессе подбора системы получше были следующие этапы:
- [0, 4, 7, 11, 15] Наш бейзлайн из системы джордано
- Подумать над алгоритмом перебора или машинного обучения. Я не придумал и решил, что лучше подгонять на основе частоты встречаемости букв.
- [4, 8, 11, 15, 19] Сначала я взял все популярные буквы и закодировал ими. Буквы ФЧШЩ не использовал.
- [1, 1, 5, 5, 7] Добавил все буквы. Уже стало несколько лучше, но всё равно есть числа, которые нельзя закодировать, это недопустимое ухудшение.
- [1, 2, 5, 9, 16] Я до этого использовал частоту букв из интернета, а тут решил посчитать сам в корпусе, порасставлял буквы, лучше не стало.
- [0, 0, 1, 3, 5] И тут я понял теперь уже очевидную вещь. А вы догадались?
Я понял, что важна не частота встречания букв в слове в целом, а частота их нахождения на 1 и на 2 месте в слове (для кодирования двухзначных чисел). Нужно, чтобы для каждой цифры были такие буквы, чтобы вероятность найти одну из этих букв в начале или в конце слова была одинаковая.
Считаем частоты на 1 месте, на 2 месте и на 2 местах сразу:
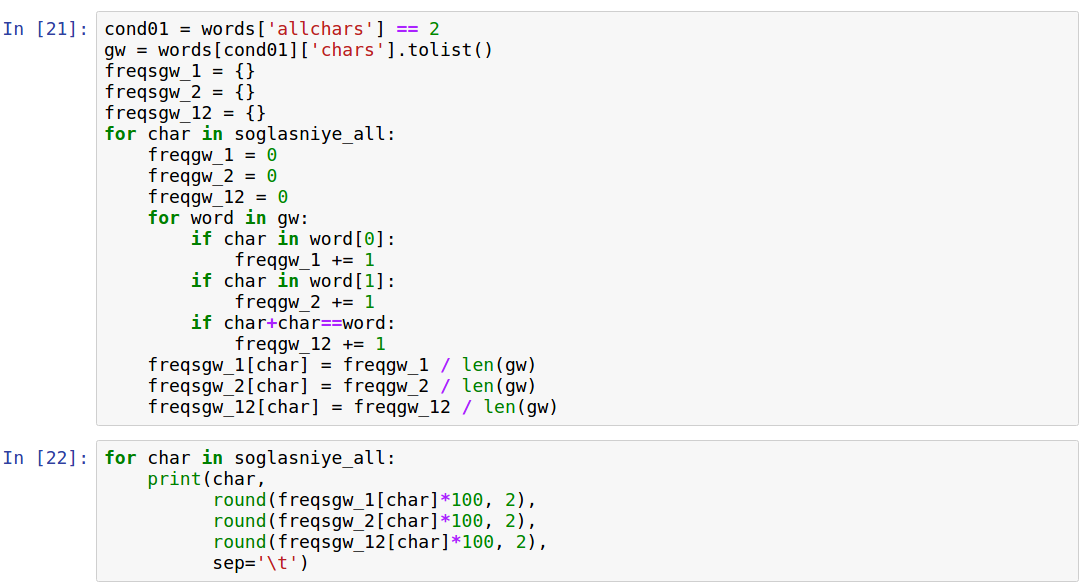
Мне далее показалось проще скопировать вывод в табличный редактор и подобрать шифр так, чтобы частоты были максимально равномерно распределены между кодируемыми цифрами.
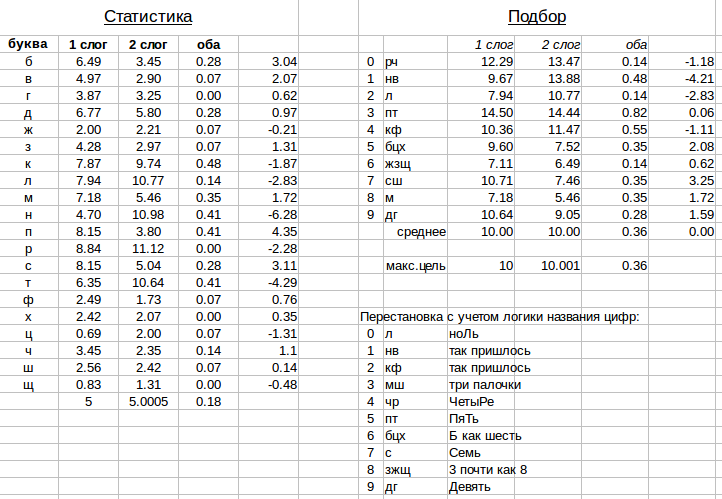
Посмотрим на результат:
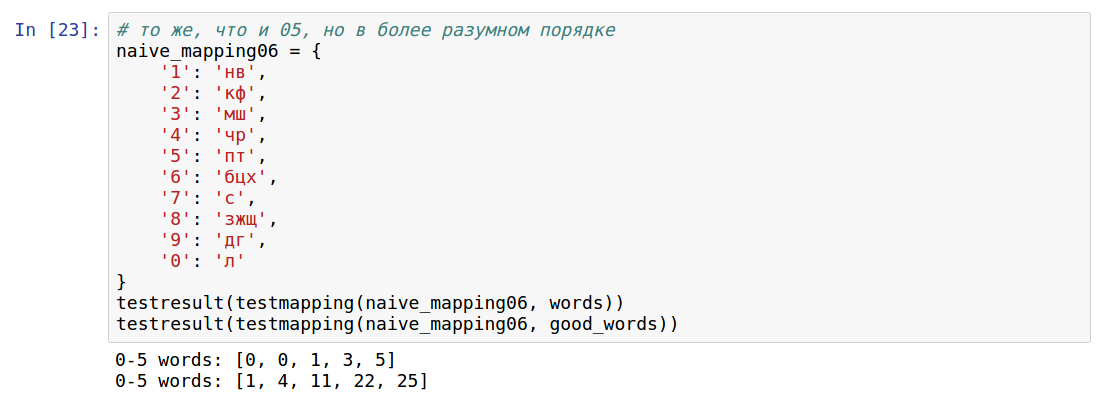
Как видно, для "простых" слов всё равно остались некодируемые буквы. Например, потому что никакое слово не содержит РР, а буквы Ч в "простых" словах не было. В итоге я решил, что правильнее считать по всем буквам.
Посмотрим на слова, которые вошли в итоговый список для некоторых чисел:
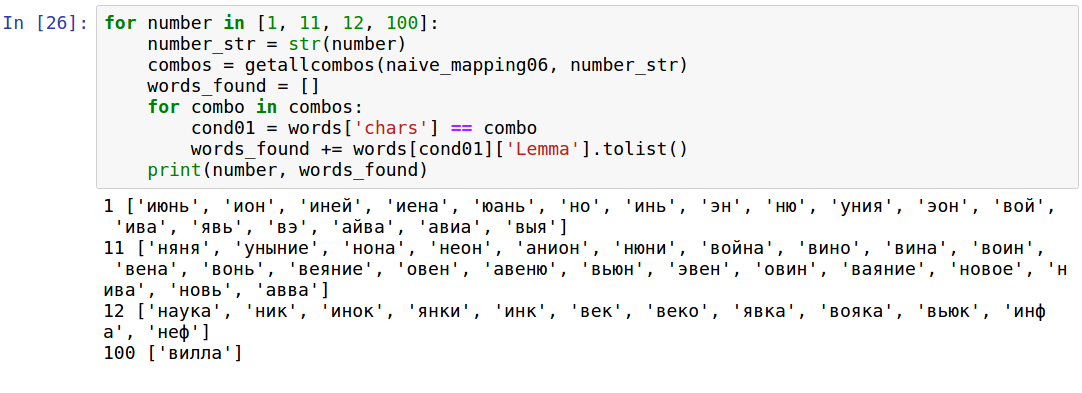
Как видно, по факту слов подходит несколько меньше. Мы не можем использовать уныние, войну, вину, вонь, веяние, новое, новь, а также слова, которых не знаем. Однако всё равно остается много хороших слов для всех чисел, в том числе трехзначных.
Ссылка на репозиторий и послесовие
Код ноутбука, данные и текст статьи лежат тут: Github
Надеюсь, вам понравилось, а также буду рад советам:
- а как вы запоминаете числа?
- как сделать полный перебор допустимых вариантов мэппинга?
- как быстро освоить метод?
- про опечатки и возможные улучшения оформления статьи прошу писать в личные сообщения
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (27)

WWolf
04.01.2017 08:16+1Честно говоря, так и не понял главного посыла — зачем это надо? Если для постоянного использования, то ставится вопрос об объемах. Работая в свое время в телекоме, постоянно держал в памяти несколько сот телефонов, не прилагая особых усилий по их запоминанию. Сейчас не работаю, многие уже не помню, но так они мне и не нужны уже. Связисты с одного повторения запоминают номер телефона, водители — автомобильные номера, продавцы — цены, провизоры — дозы. Если числа нужны в работе, то вы будете их помнить, даже если у вас не будет специальной системы для запоминания. Если они нужны просто так, то не факт, что система обеспечит долгое и надежное запоминание. Лучше, как мне кажется, стихи учить. :)

custos
04.01.2017 09:20+1Если они нужны просто так, то не факт, что система обеспечит долгое и надежное запоминание.
Тут, по сути, все необходимые ключевые. Мнемотехника это инструмент, требует время для освоения и имеет свою область применения. Она не только про запоминание, ещё помогает забывать не нужное. Это как шпаргалка, запомнить на необходимое время, затем надёжно забыть. Если необходимо запомнить на долго, то зубрить всё ещё нужно, но позволяет обойтись без носителя информации перед глазами, поскольку есть возможность надёжно припомнить и повторить. Удобно, когда процесс запоминания формализован, и всегда есть уверенность, что информация припомнилась достоверно… или нет, что тоже определяется однозначно.WWolf
04.01.2017 09:56+1Вот вопрос и возникает — зачем? Круг ситуаций, в которых необходимо запоминание как таковое довольно узок. В первую очередь на ум приходит обучение и подготовка к выступлениям.
Я (я только про себя говорю, если что) просто не могу себе представить, чтобы необходимую для работы информацию приходилось запоминать, заучивать, для того, чтобы она потом когда-то понадобилась.
Когда она нужна — она запоминается. Запоминается в комплексе, с необходимыми пояснениями, с расшифровкой. Например, если вы готовите выступление на конференции, то уже в процессе подготовки доклада вам не нужно будет специально запоминать десятки чисел, их последовательность или смысл. Если вы работаете с телефонными номерами, то автоматически будете запоминать номера коллег, абонентов, связанные с ними числа. Если вы занимаетесь разработкой, то половину ГОСТов, размеров, характеристик нужного вам оборудования будете тоже знать наизусть, даже не задумываясь о том, как именно вы их запомнили.
Старое правило — «если вы не можете запомнить „нужную“ вам информацию, значит, она вам не нужна» — работает до сих пор. Есть хорошее работающее решение — запишите ее. :)custos
04.01.2017 11:29+1Полагаю, что всё дело в методологии. Вы утверждаете, что необходимая информация запомнится сама неким «мистическим» образом. Да это работает, но такой подход не для всех является комфортным. Например, порядковый номер букв в алфавите. Обычно мало кто озадачивается этим, и ограничиваются примерной оценкой выше/ниже (запоминается само по себе). Мнемотехника же даёт вполне осмысленный инструмент для запоминания такого рода информации. В итоге это позволяет очень точно работать со словарём и организовывать информацию, в том числе и в памяти. Также кругом много «не нужной» информации такой как: номера заказов, список покупок, состояние стека при отладке, адреса входа в процедуры и т.п. и т.д. Всё это незачем держать в долговременной памяти, конечно что-то можно пометить, что-то записать. Очевидно, что если бы мнемотехника была универсальной и на много лучше других подходов, то вопрос «зачем?» давно бы уже отпал. А так, по себе могу сказать, что классическая зубрёжка мне никогда не нравилась, и светить записями перед публикой было не комфортно, поэтому попробовать данный подход было вполне логичным шагом, и по моему скромному мнению, результат оказался вполне достоин затраченного времени.
WWolf
04.01.2017 11:55+1Нет, конечно. Никаких мистических способов не бывает. Тут, скорее, мнемотехника покажется мистикой тому, кто ее не применяет.

u9925
04.01.2017 11:52+1> Когда она нужна — она запоминается
Мозг сам далеко не всегда верно определяет какую информацию стоит помнить, а какую нет.
И мозг запоминает не нужную информацию, а наиболее интересную/необычную (этот эффект используют техники мнемоники) или наиболее часто встречающуюся (этот эффект использует зубрёжка).WWolf
04.01.2017 11:58+1Мозг запоминает то, что ему нужно. Если вы с утра до вечера занимаетесь накладными, то номера накладных уже через пару недель станут вам нужны и будут запоминаться практически автоматически. Если вы общаетесь с абонентами, то их данные — номера и адреса — также в скором времени станут запоминаться без особых усилий. Я как-то, ради интереса, попросил водителя по его записной книжке вспомнить, сколько автомобильных номеров он помнит. Чуть меньше 200 человек в книжке, номера всех, у кого есть машины, он помнил. В том числе, если несколько машин — домашняя, служебная, отцовская…
u9925
04.01.2017 12:11+1Мне кажется ваш пример с номерами доказывает, что мозг запоминает то, что часто видит. Т.к. сомнительно, что мозгу нужно помнить номера — их всегда можно посмотреть в записной книжке.
WWolf
04.01.2017 12:53+1Не часто видит, а часто использует. Связист, если уж на то пошло, просто не в состоянии видеть, да еще часто, телефонные номера. Для него они часто абстракция, выраженная в парах, коробках, плинтах… А в данном случае, когда на дороге десятки машин, водителю бывает проще ориентироваться не только в марках, моделях, цветах, но и просто по номерам.

Desprit
04.01.2017 10:42+1Вокруг очень много числовых данных. Мнемотехника отлично может помочь с теми, которые мы используем чаще всего, например, номера кредиток, их пин-коды, телефонные номера, даты. Конечно, я не говорю, что она не поможет с другими, просто все дело в том, насколько часто мы обращаемся к информации. Лично я использую методы «Цепочка» и «Матрешка», коих мне с лихвой хватает, чтобы не забывать два длинных номер IBAN, номера и данные четырех кредитных карт, данные для доступа к двум онлайн банкингам. Кроме того, когда под рукой нет телефона или бумаги, но нужно запомнить что-то конкретное, мнемотехника может сильно выручить.
WWolf
04.01.2017 12:03+1А нас в школе еще учили, что номера и даты документов удобно помнить наизусть. Паспорт, комсомольский билет, военник, студенческий билет, профсоюзный билет… Хотя их уже помню смутно… :)
А сейчас номера карточек, пин-коды (в том числе и десятилетней давности), номер удостоверения, ИИН, банковские счета и карт-счета, пару десятков самых активных паролей, пару десятков паролей клиентов — все помнится. И для таких небольших объемов использовать специальные мнемотехники не вижу смысла.
Да еще и басни и стихи со школы и те, которые просто так учил, для себя, помнятся…
custos
04.01.2017 08:48+1unkinddragon у вас это упомянуто в начале, но судя по дальнейшему тексту, вы упускаете важную деталь — мнемотехника не про слова, а про образы. Например «чёрный лист» это один образ, хотя и для всех разный: лист A4, лист на дереве или лист фотобумаги и т.д. По этой причине нет проблем с кодированием чисел по любой схеме (стандартная 1-гж, вполне хороша). Однако для ускорения декодирования действительно желательны правила, например, не более двух согласных для двухзначных чисел, строго две согласные от прилагательного и т.п., но всё это индивидуально и нужно только при необходимости. Мнемотехника сильна условна, часто достаточно криво закодированного образа, чтобы было за что «зацепиться» не более.
igruh
04.01.2017 10:28+1К статье просится
ЭпиграфОдна знакомая просила Альберта Эйнштейна позвонить ей по телефону, но предупредила, что номер очень трудно запомнить: 24361. – И чего же тут трудного? – удивился Эйнштейн. – Две дюжины и 19 в квадрате…Dum_spiro_spero
04.01.2017 12:25Аналогично кстати — запоминаю числа именно таким образом. Или… просто запоминаю.
Я замечал, есть люди просто с хорошей памятью — они помнят много, и нужного и ненужного.
Есть условно с плохой — они и важное забывают если не записывают.
Первым мнемотехника обычно не нужна — ну или у них сформированы свои близкие методы, вторые — не доверяют своей памяти и соответственно не станут пользоваться — потому что например образ забудут вместе со словом/числом.
Занимался на курсах быстрого чтения — там учили разным методам запоминания. Не пригодилось ничего. Запоминать списки слов — где взять эти списки которые надо запоминать?
Номера паспорта, банковских карт, счетов, и т. п… я помню и так.
Так что поддерживаю товарища WWolf.
Но может просто у нас стало много внешних носителей? Бумажек, ручек, файлов «Новый текстовый документ.txt»? Не было бы — развивались бы методы запоминания.
— О люди! — с пафосом произнес Рыжий.-- Вместо того чтобы научиться считать, они изобретают счетную машинку! М. Кривич, О. Ольгин. Рыжий и полосатый
http://lib.ru/RUFANT/KRIWICH/ryzhij.txt_with-big-pictures.html

marysuon
05.01.2017 02:48Вот и у меня просится.
Зачем запоминать буквы к числам, если я на любую адекватно длинную цепочку чисел могу придумать такую ассоциацию?
pestilent
07.01.2017 18:39Странно, что никто не вспомнил Хармса.
Телефон у меня простой – 32-08. Запоминается легко: тридцать два зуба и восемь пальцев.
A-Stahl
04.01.2017 12:03+2Я во всяких мудрёных системах не разбираюсь и пользуюсь методом дедушки Швейка (сосиски с капустой я тоже люблю):
номер паровозаНа шестнадцатом пути стоит паровоз номер четыре тысячи двести шестьдесят восемь. Я знаю, у вас плохая память на цифры, а если вам записать номер на бумаге, то вы бумагу эту также потеряете. Если у вас такая плохая память на цифры, послушайте меня повнимательней. Я вам докажу, что очень легко запомнить какой угодно номер. Так слушайте: номер паровоза, который нужно увести в депо в Лысую-на-Лабе,-- четыре тысячи двести шестьдесят восемь. Слушайте внимательно. Первая цифра — четыре, вторая — два. Теперь вы уже помните сорок два, то есть дважды два — четыре, это первая цифра, которая, разделенная на два, равняется двум, и рядом получается четыре и два. Теперь не пугайтесь! Сколько будет дважды четыре^ Восемь, так ведь? Так запомните, что восьмерка в номере четыре тысячи двести шестьдесят восемь будет по порядку последней. После того как вы запомнили, что первая цифра — четыре, вторая — два, четвертая — восемь, нужно ухитриться и запомнить эту самую шестерку, которая стоит перед восьмеркой, а это очень просто. Первая цифра-- четыре, вторая-два. а четыре плюс два — шесть. Теперь вы уже точно знаете, что вторая цифра от конца — шесть; и теперь у вас этот порядок цифр никогда не вылетит из головы. У вас в памяти засел номер четыре тысячи двести шестьдесят восемь. Но вы можете прийти к этому же результату еще проще…GreenGoblin
04.01.2017 17:56+1Все эти системы бессмысленны. Нужно просто помучиться недельку и по-честному запомнить 100 любых образов. Любые костыли при их запоминании будут только мешать.
А вообще, мнемотехника на практике малоприменима, разве что повыпендриваться.kisskin
05.01.2017 19:57Для развития мозга мнемотехника вполне применима) Конечно, это не сильно востребовано, но есть мнение, что может спасти от болезни Альцгеймера)

john_galt
05.01.2017 02:48+1Господа, данный вопрос довольно подробно исследовал Козаренко. Есть у него Учебник мнемотехники, поищите. Мнемотехника — она больше даже не про образы, а про связи этих образов.
В современных условиях нет особого смысла запоминать числа, однако знаниние законов мнемотехники, а значит психики в целом, весьма полезно.
Мозг, подсознание, сознание отражают реальность по вполне определенным, универсальным принципам. И не важно, какая именно это реальность: числа, эти три слова, сл овокак обр азиз образов букв и связей между ними, язык в целом, авиадвигатель, политическая система Барбадоса, моя (или ваша?) личность, межличностные отношения или общество в целом.
Принцип всегда один.


Irwin1138
Использую систему Person Action Object. Поначалу нужно хорошо вложиться, но потом эта система рвет в клочья буквенные. А если использовать вместе с memory palace, то вообще никакого сравнения.
u9925
А можете свою PAO выложить?
У меня возникла проблема с поиском 100 глаголов, образы которых отличались друг от друга и которые подходили бы ко всем персонам и объектам.
Irwin1138
Системы PAO они довольно личные штуки, и не сколько потому что с другими неловко делиться, а сколько потому что образы придуманные самим, они основываются на личных ассоциациях и вспоминаются лучше чем придуманные кем-то другим. К тому же сам процесс придумывания образов сильнее их закрепляет в памяти.
Ваша же проблема возможно состоит в том что вы пытаетесь подобрать список несвязанных глаголов. Я когда составлял свою систему PAO, я придерживался указаний Доминика Обрайана (Dominic O'Brian, Dominic System), и он в примерах приводил не просто глаголы, а действия которые совершают именно эти личности. Если скажем 00 это Оззи Осборн, то он откусывает голову голубю. Если 16 это Арнольд Шварценеггер то и он делает что-то что может делать только Шварценеггер — скажем в сцене из Терминатора 2 выходит из лифта в косухе, очках и шотганом на плече и направляется в сторону Сары Коннор и все время на фоне играет музыка из Терминатора.
u9925
Какие у вас будут образы для 001600 и 160016?
Irwin1138
001600 — Два Оззи стоят по бокам от терминатора и по очереди откусывают от него голову, плечи итд
160016 — Терминатор выходит из лифта с Оззи подмышкой и стреляет из него в терминатора который в ужасе сидит на полу
Здесь надо заметить что я очень вольно использую объекты, иногда опускаю их вовсе так как а) объекты добавил сравнительно недавно и не все быстро вспоминаю и б) еще не привык их ввязывать в сцены, то есть сейчас у меня иногда быстрее приходит сцена без строгого использования объектов и я тогда использую ее.