
 В декабре 2016 года мы с товарищем начали заниматься новым проектом — системой сбора-индексации-поиска по документам. Система построена вокруг ElasticSearch (далее — ES), который мы используем как основной движок для полнотекстового поиска.
В декабре 2016 года мы с товарищем начали заниматься новым проектом — системой сбора-индексации-поиска по документам. Система построена вокруг ElasticSearch (далее — ES), который мы используем как основной движок для полнотекстового поиска.
Ценными данными, приобретенными в ходе работы над проектом мы бы хотели поделиться с читателями в цикле статей про ES. Начнём с основы любого поисковика — подсветки результатов поиска (далее — хайлайтинг).
Правильная подсветка результатов поиска едва ли не самый важный критерий эффективности поисковой системы для пользователя. Во-первых, видна логика включения документа в результаты поиска, а во-вторых, подсветка блока найденного текста даёт возможность быстро оценить контекст найденного попадания.
Одним из ключевых требований к нашей поисковой системе была возможность быстро и эффективно работать с большими файлами (более 100 Мб). В статье мы расскажем как добиться высокой производительности от ES при хайлайтинге больших полей документа.
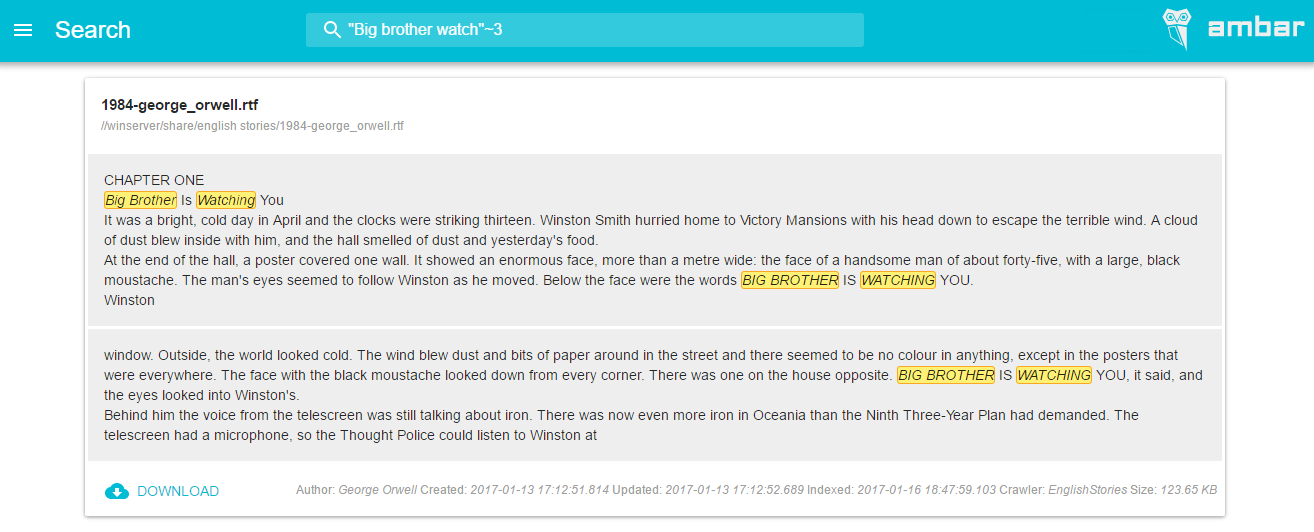
На скриншоте ниже показано как работает подсветка результатов поиска в нашем проекте.
Первый шаг или суть проблемы
Итак, ES мы используем для хранения и поиска в метаданных и распарсенном содержимом файлов. Пример документа, который мы храним в ES:
{
sha256: "1a4ad2c5469090928a318a4d9e4f3b21cf1451c7fdc602480e48678282ced02c",
meta: [
{
id: "21264f64460498d2d3a7ab4e1d8550e4b58c0469744005cd226d431d7a5828d0",
short_name: "quarter.pdf",
full_name: "//winserver/store/reports/quarter.pdf",
source_id: "crReports",
extension: ".pdf",
created_datetime: "2017-01-14 14:49:36.788",
updated_datetime: "2017-01-14 14:49:37.140",
extra: [],
indexed_datetime: "2017-01-16 18:32:03.712"
}
],
content: {
size: 112387192, /* Файл больше 100 Mb */
indexed_datetime: "2017-01-16 18:32:33.321",
author: "John Smith",
processed_datetime: "2017-01-16 18:32:33.321",
length: "",
language: "",
state: "processed",
title: "Quarter Report (Q4Y2016)",
type: "application/pdf",
text: ".... очень много текста здесь ...."
}
}Как вы уже догадались, это распарсеный контент pdf файла с финансовым отчётом размером немного более 100 Мб. Поле content.text я умышленно укоротил, очевидно, что его длина примерно равна тем самым 100 Мб.
Проведём простой эксперимент: возьмём 1000 таких документов и проиндексируем их ES'ом не используя каких-либо специальных настроек индекса или самого ES'а. Посмотрим насколько быстро будет работать поиск и хайлайт по этим документам.
Результаты:
- Поиск
match_phraseв полеcontent.text: от 5 до 30 секунд. - Формирование хайлайта для поля
content.textдля каждого из документов: более 10 секунд.
Такая производительность никуда не годится. Пользователь ожидает увидеть результаты мгновенно (< 200 мс), а не через десятки секунд. Давайте разберемся как решить проблему медленного формирования хайлайта. Проблему быстрого поиска по большим файлам рассмотрим в следующей статье цикла.
Выбираем алгоритм хайлайтинга
В ES есть возможность использовать три вида хайлайтеров. См. официальный мануал.
Для тех кому лень читать, на пальцах:
- Plain — вариант по умолчанию, самый медленный, но самый качественный (по словам ES, почти на 100% отражает алгоритм поиска Lucene, и это правда), для формирования хайлайта выгружает весь документ в память и повторно анализирует его.
- Postings — более быстрый хайлайтер, бьёт поле на предложения и вытаскивает для хайлайта уже не весь документ, а предложения где найден токен, ранжируя их по алгоритму BM25. Требует обогащения индекса позициями этих самых предложений.
- Fast Vector Highlighting (FVH) — позиционируется как самый быстрый хайлайтер, особенно для больших документов. Требует обогащения индекса данными о положениях всех токенов в исходном документе, благодаря этому формирует хайлайт почти за константное время, вне зависимости от размера документа.
Как описано выше, по умолчанию в ES используется Plain хайлайтер. Таким образом каждый раз для формирования хайлайтов ES выгружает в память все 100 мегабайт текста и из-за этого отвечает на запрос очень и очень медленно. Мы отказались от Plain хайлайтера и решили протестировать Postings и FVH. В итоге наш выбор пал на FVH по нескольким причинам:
- Документ размером в 100 Мб FVH в среднем хайлайтит около 10-20 мс, Postings на это тратит около секунды
- Postings не всегда корректно разбивает текст на предложения, поэтому размер полученного хайлайта довольно часто скачет (может вернуть 50 слов, а может и 300). С FVH такой проблемы замечено не было. Он возвращает заданное число токенов в обе стороны от попадания
- Postings хайлайтит токены независимо от их положения, поэтому подсветка фраз в этом случае работает некорректно. Например
simple_string_query"иванов иван"~5 захайлайтит не только случаи когда два токена "иванов" и "иван" будут на расстоянии не более 5 токенов друг от друга, но и все остальные токены "иванов" или "иван" в заданном поле документа, как будто это был простоboolзапрос наmatch"иванов" и "иван"
Подводные камни Fast Vector Highlighter
В процессе работы c FVH мы заметили следующую проблему: поисковый запрос match_phrase "иванов иван" находит вхождения "иванов иван" и "иван иванов", но FVH подсвечивает только попадания в порядке указанном в запросе. Данный нюанс не упоминается ни в одном мануале по ES, по нашему мнению данная ошибка возникает в результате того что FVH учитывает положения токенов для match_phrase запроса. Проблему мы решили обходным путем — добавляем в запрос поле highlight_query в котором перебираются все возможные положения токенов во фразе. Это единственный способ который позволял получить все хайлайты при этом сохранив производительность на должном уровне.
Итог
Хайлайтить большие документы ES действительно может, при этом быстро. Важно правильно настроить индекс, и учитывать особенности хайлайтера. Если вы решали похожую задачу и нашли, как вам кажется, более элегантное решение расскажите о нем в комментариях.

datacompboy
А баг зафайлили? Ибо это фейл.
fpd4444
Нет, ибо вопрос поднимался до наc несколько лет назад и ES'овцы (или Luceneо'вцы) до сих пор с этим ничего не сделали. Хотя взбодрить наверное не мешало бы…