
Что-то в последнее время технические статьи о виртуализации (да и не только о виртуализации) скатываются к формату «в новой версии ожидается такая фича». Складывается ощущение, что разбор механизмов и описание опыта, проблем и решений интересны только зарубежным экспертам. С другой стороны, есть такая проблема у экспертов — если что-то изучил, оно становится элементарным и воспринимается само собой разумеющимся, настолько, что писать об этом как-то глупо. Особенно если уже было кем-то описано где-то. Когда-то. На каком-то языке. Ниженаписанное — плод консолидации личных заметок, сначала предназначавшийся для личного упорядочивания мыслей, но наупорядочив значительный объём текста, подумал, что кому-то может пригодиться.
Типовая проблема «виртуализаторов» — владелец сервиса, заказчик или пользователь жалуется, что у него «тормозит» виртуальная машина. Так как виртуализация предполагает консолидацию большого количества ВМ на базе одного комплекта аппаратных ресурсов, переподписку (overprovision — когда мы предполагаем, что серверы не затребуют одновременно максимум своих ресурсов, а значит, например, в 40 ГБ физической памяти мы можем натолкать не 10 серверов по 4 ГБ RAM, а 15, используя Dynamic Memory), а кроме того, серверы могут тормозить и из-за ошибок в программных компонентах и их настройках, то каждый раз приходится решать за что хвататься и куда смотреть в первую очередь. Особенно, если с таким ёмким описанием проблемы, как «тормозит машина» не предоставлено никакой диагностической информации, как чаще всего и бывает. Под катом небольшое руководство для этого случая.
Конечно, всё зависит от специфичности реализации конкретной инфраструктуры, но практика показывает, что в большинстве случаев имеет смысл следующая последовательность анализа подсистем ВМ:
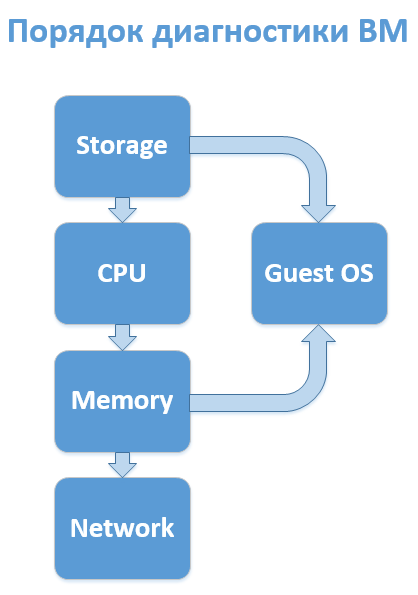
На практике, до 4-го этапа почти никогда не доходит, после третьего (а то и после первого) имеет смысл запускать (или запрашивать) параллельную диагностику гостевой ОС, но диски стоит проверить сразу — самая значительная часть инцидентов с жалобами на производительность связано с ними. Если, конечно, у вас не All-Flash массив.
А теперь чуть подробнее по каждому пункту.
Самый ключевой тут показатель — это Latency. Задержка времени отклика. Она складывается из большого количества промежуточных элементов и зависит от большого количества факторов. Сюда входит время отклика гипервизора, время прохождения сигнала по кабелям и промежуточным устройствам (коммутаторы, адаптеры и контроллеры), время нахождения в очередях на всех этих устройствах, если нагрузка на них превышает норму и ещё некоторые нюансы, такие как повреждения оборудования. Однако, оставив нюансы для расширенной диагностики, требуемой в редких случаях, можно выделить простой общий показатель — время задержки от ВМ до дисков.
Инструменты диагностики:
(закладка Perfomance в vSphere Client и счетчики производительности).
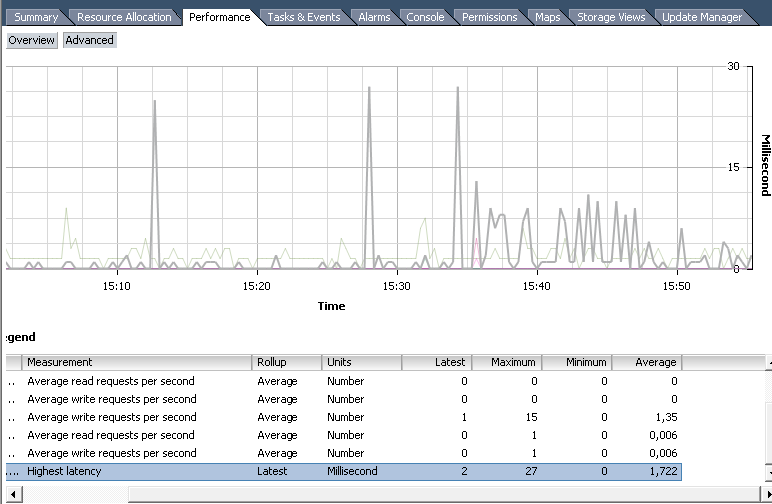
Наиболее часто используемые счётчики группы Disk:
Highest Latency — норма до 10-15 мс. Если регулярно выше, надо что-то менять, хотя разовые пики не страшны;
Average write requests per second;
Average read requests per second.
Наиболее часто используемые счётчики группы Virtual Disk:
Read/Write latency;
Average number of outstanding read/write requests — количество одновременных IO-запросов (если их число держится выше 30 в сумме на датастор или на сервер, это будет приводить к дополнительным задержкам);
Консольная утилита ESX/ESXi. Выдаёт целую кучу диагностической информации об отдельно взятом ESXi. Базовую информацию по использованию можно получить, нажав h после запуска утилиты.

В плане диагностики дисковой подсистемы будет полезен контекст виртуальных дисков (нажать v) и контекст HBA-адаптеров (нажать d). В последнем случае стоит обратить внимание на следующие показатели:
KAVG (Kernel Latency Avg) — время отклика гипервизора (норма — до 1 мс);
DAVG (Device Latency Avg) — время отклика от HBA до дисков (норма — 10-15мс);
GAVG (Guest Latency Avg) — время отклика для гостевой системы = сумма KAVG и DAVG
Кстати, в этой же области исследований стоит сразу проверить нет ли у ВМ снапшота. А то и нескольких. Они могут стать проблемой не только паденрия производительности, но и сбоев операций резервного копирования, клонирования и миграции.
Здесь аналогичный по важности дисковым задержкам показатель — CPU Ready. Также стоит обращать внимание на Used, Wait и Co-Stop. Мониторить можно также через Perfomance Tab или ESXtop.
CPU Ready (%RDY) — % времени, когда ВМ готова производить какие-то вычисления, но физические процессоры в данный момент заняты другими процессами (системными или другими ВМ) и vCPU виртуальной машины находятся в режиме ожидания. Нормой считается значение до 10%. При росте этого показателя выше 40% развивается высокая вероятность сбоев и зависаний гостевой ОС. Причиной вынужденного простоя может стать:
Wait (%WAIT) — % времени, в течение которого ВМ ждёт окончания какой-то активности VMkernel. Чаще всего это дисковая IO-активность. Высокие показатели этого счётчика могут говорить о недостаточно быстром отклике от датастора. Также проблему могут вызывать некорректная работа USB или COM-портов или виртуальный CD/DVD-приводы, в который замонтирован отсутствующий ныне ISO.
Used (%USED) — % времени, в течение которого машина реально работала. Если он около нуля, значит машина просто стоит или её пересайзили процессорами. Если он около 100 (на каждый vCPU), значит или недосайзили, или в ней что-то зациклилось (если она ещё и не откликается при этом), или сейчас там лопатится какой-то квартальный отчёт. Этот показатель стоит изучать при размышлении на тему «дать ли ВМ ещё процессоров, чтоб быстрее работала?». Если у неё 4 ядра и ни одно не задействовано более чем на 50%, то 8 ядер её скорее всего не ускорят. Возможно даже замедлят (см. CPU Ready).
Инструменты диагностики те же.
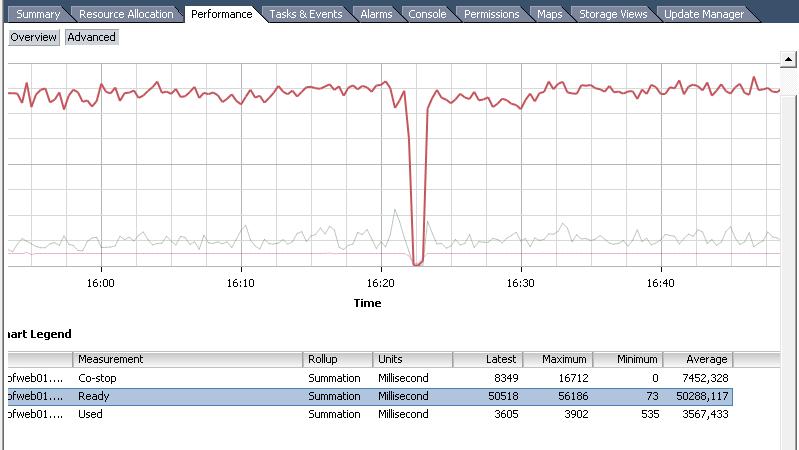
Удобно, что можно посмотреть данные не только по машине в целом, но и по каждому ядру. Кроме того, доступна статистика за период. Однако, информация предоставляется не в процентах, а в миллисекундах. Так как данные собираются не в real-time, а за определённый интервал, отображается, сколько именно mc процессор находился в том или ином состоянии. Перевести в проценты можно разделив значение на длину интервала и умножив на 100%.
Пример: на рисунке диаграмма с интервалом 20 секунд (real-time), то есть 20 000 мс. То есть среднее CPU Ready будет 50288 / 20000 * 100% = 251.44%. Так как у машины 4 ядра, а не одно, то результат делим на 4 и получаем почти 63%. Машина очень страдает. А всё потому, что лежит на третьем уровне вложенности Resource Pools с низкими shares на каждом.
Ещё раз, формула преобразования: <значение CPUReady> /<интервал статистики в мс> / <количество vCPU> * 100%. Получается 5% на 1000 мс для одного ядра.

Тут значение указано сразу в %. Только оно указано сразу в сумме для всех ядер, так что не стоит пугаться чисел больше 100. Делите на количество vCPU машины.
Базовая диагностика здесь простая — да или нет. Если есть факт balooning'а значит хосту не хватает памяти и процессы гостевых ОС страдают, потому что активно используется файл подкачки. Если есть факт свопинга на уровне гипервизора, надо срочно принимать меры — машина попавшая в своп впадает в кому в 100% случаев (по крайней мере моей практики). Вышеуказанные факты позволяют определить такие счётчики как
Balloon (MCTLSZ) — количество памяти, вытянутое baloon-драйвером из гостевых ОС.
Swapped (SWCUR) — количество памяти, помещённое в .vswp (то есть на жёский диск).
Чтобы проблемы были на уровне сети, в случае жалоб на отдельную виртуальную машину, я в своей практике помню только один случай — когда в VDI использовалась какая-то дешёвая веб-камера, гнавшая несжатый поток видео и забивавшая все 100 Мб/с.
Стоит мониторить такие счётчики:
Transmit Dropped Packets (%DRPTX) — количество (или процент в случае esxtop) отброшенных отправленных пакетов;
Receive Dropped Packets (%DRPRX) — количество (процент) отброшенных принятых пакетов.
Ненулевое их значение, возникающее на регулярной основе говорит о некорректной работе сетевых устройств или некорректной их настройке.
Для базовой диагностики, покрывающей более половины (пожалуй, до 90%) обращений или собственных потребностей при диагностике и тестировании, этого достаточно.
Типовая проблема «виртуализаторов» — владелец сервиса, заказчик или пользователь жалуется, что у него «тормозит» виртуальная машина. Так как виртуализация предполагает консолидацию большого количества ВМ на базе одного комплекта аппаратных ресурсов, переподписку (overprovision — когда мы предполагаем, что серверы не затребуют одновременно максимум своих ресурсов, а значит, например, в 40 ГБ физической памяти мы можем натолкать не 10 серверов по 4 ГБ RAM, а 15, используя Dynamic Memory), а кроме того, серверы могут тормозить и из-за ошибок в программных компонентах и их настройках, то каждый раз приходится решать за что хвататься и куда смотреть в первую очередь. Особенно, если с таким ёмким описанием проблемы, как «тормозит машина» не предоставлено никакой диагностической информации, как чаще всего и бывает. Под катом небольшое руководство для этого случая.
Конечно, всё зависит от специфичности реализации конкретной инфраструктуры, но практика показывает, что в большинстве случаев имеет смысл следующая последовательность анализа подсистем ВМ:
- Диски.
- Процессор.
- Оперативная память.
- Сеть
На практике, до 4-го этапа почти никогда не доходит, после третьего (а то и после первого) имеет смысл запускать (или запрашивать) параллельную диагностику гостевой ОС, но диски стоит проверить сразу — самая значительная часть инцидентов с жалобами на производительность связано с ними. Если, конечно, у вас не All-Flash массив.
А теперь чуть подробнее по каждому пункту.
1. Диски (подсистема хранения)
Самый ключевой тут показатель — это Latency. Задержка времени отклика. Она складывается из большого количества промежуточных элементов и зависит от большого количества факторов. Сюда входит время отклика гипервизора, время прохождения сигнала по кабелям и промежуточным устройствам (коммутаторы, адаптеры и контроллеры), время нахождения в очередях на всех этих устройствах, если нагрузка на них превышает норму и ещё некоторые нюансы, такие как повреждения оборудования. Однако, оставив нюансы для расширенной диагностики, требуемой в редких случаях, можно выделить простой общий показатель — время задержки от ВМ до дисков.
Инструменты диагностики:
Perfomance Tab
(закладка Perfomance в vSphere Client и счетчики производительности).
Наиболее часто используемые счётчики группы Disk:
Highest Latency — норма до 10-15 мс. Если регулярно выше, надо что-то менять, хотя разовые пики не страшны;
Average write requests per second;
Average read requests per second.
Наиболее часто используемые счётчики группы Virtual Disk:
Read/Write latency;
Average number of outstanding read/write requests — количество одновременных IO-запросов (если их число держится выше 30 в сумме на датастор или на сервер, это будет приводить к дополнительным задержкам);
ESXTop
Консольная утилита ESX/ESXi. Выдаёт целую кучу диагностической информации об отдельно взятом ESXi. Базовую информацию по использованию можно получить, нажав h после запуска утилиты.
В плане диагностики дисковой подсистемы будет полезен контекст виртуальных дисков (нажать v) и контекст HBA-адаптеров (нажать d). В последнем случае стоит обратить внимание на следующие показатели:
KAVG (Kernel Latency Avg) — время отклика гипервизора (норма — до 1 мс);
DAVG (Device Latency Avg) — время отклика от HBA до дисков (норма — 10-15мс);
GAVG (Guest Latency Avg) — время отклика для гостевой системы = сумма KAVG и DAVG
Кстати, в этой же области исследований стоит сразу проверить нет ли у ВМ снапшота. А то и нескольких. Они могут стать проблемой не только паденрия производительности, но и сбоев операций резервного копирования, клонирования и миграции.
2. Процессор
Здесь аналогичный по важности дисковым задержкам показатель — CPU Ready. Также стоит обращать внимание на Used, Wait и Co-Stop. Мониторить можно также через Perfomance Tab или ESXtop.
CPU Ready (%RDY) — % времени, когда ВМ готова производить какие-то вычисления, но физические процессоры в данный момент заняты другими процессами (системными или другими ВМ) и vCPU виртуальной машины находятся в режиме ожидания. Нормой считается значение до 10%. При росте этого показателя выше 40% развивается высокая вероятность сбоев и зависаний гостевой ОС. Причиной вынужденного простоя может стать:
- интенсивное потребление процессорных ресурсов большим количеством ВМ, причём суммарное количество vCPU существенно превышает количество логических ядер (переподписка).
- Наличие oversized ВМ (виртуальные машины с большим количеством недозагруженных vCPU, например если у машины 16 ядер, каждое из которых работает на 1-20% мощности). Проблема тут в том, что при большом количестве vCPU, планировщику гипервизора приходится синхронизировать их работу, что приводит к периодическому «замораживанию» некоторых ядер или даже всей машины, пока не освободится полное количество логических ядер, соответствующее количеству vCPU, необходимое для определённой операции. Механизм называется Co-Stop, и соответствующий счётчик будет расти в этом случае. Это главный аргумент против набивания виртуальной машины виртуальными процессорами «про запас» (второй аргумент — NUMA, но он уже за рамками статьи). Лучше 2 ядра, загруженных на 80%, чем восемь ядер по 20%. В большинстве случаев.
- Если использование CPU для виртуальной машины ограничено на уровне Resource Pool или самой машины. По достижению определённого порога, машина не получит процессорных ресурсов и будет накапливать CPU Ready. В этом случае будет увеличиваться значение счётчика Max-Limited (%ML).
Wait (%WAIT) — % времени, в течение которого ВМ ждёт окончания какой-то активности VMkernel. Чаще всего это дисковая IO-активность. Высокие показатели этого счётчика могут говорить о недостаточно быстром отклике от датастора. Также проблему могут вызывать некорректная работа USB или COM-портов или виртуальный CD/DVD-приводы, в который замонтирован отсутствующий ныне ISO.
Used (%USED) — % времени, в течение которого машина реально работала. Если он около нуля, значит машина просто стоит или её пересайзили процессорами. Если он около 100 (на каждый vCPU), значит или недосайзили, или в ней что-то зациклилось (если она ещё и не откликается при этом), или сейчас там лопатится какой-то квартальный отчёт. Этот показатель стоит изучать при размышлении на тему «дать ли ВМ ещё процессоров, чтоб быстрее работала?». Если у неё 4 ядра и ни одно не задействовано более чем на 50%, то 8 ядер её скорее всего не ускорят. Возможно даже замедлят (см. CPU Ready).
Инструменты диагностики те же.
Perfomance Tab
Удобно, что можно посмотреть данные не только по машине в целом, но и по каждому ядру. Кроме того, доступна статистика за период. Однако, информация предоставляется не в процентах, а в миллисекундах. Так как данные собираются не в real-time, а за определённый интервал, отображается, сколько именно mc процессор находился в том или ином состоянии. Перевести в проценты можно разделив значение на длину интервала и умножив на 100%.
Пример: на рисунке диаграмма с интервалом 20 секунд (real-time), то есть 20 000 мс. То есть среднее CPU Ready будет 50288 / 20000 * 100% = 251.44%. Так как у машины 4 ядра, а не одно, то результат делим на 4 и получаем почти 63%. Машина очень страдает. А всё потому, что лежит на третьем уровне вложенности Resource Pools с низкими shares на каждом.
Ещё раз, формула преобразования: <значение CPUReady> /<интервал статистики в мс> / <количество vCPU> * 100%. Получается 5% на 1000 мс для одного ядра.
ESXTop
Тут значение указано сразу в %. Только оно указано сразу в сумме для всех ядер, так что не стоит пугаться чисел больше 100. Делите на количество vCPU машины.
3. Оперативная память
Базовая диагностика здесь простая — да или нет. Если есть факт balooning'а значит хосту не хватает памяти и процессы гостевых ОС страдают, потому что активно используется файл подкачки. Если есть факт свопинга на уровне гипервизора, надо срочно принимать меры — машина попавшая в своп впадает в кому в 100% случаев (по крайней мере моей практики). Вышеуказанные факты позволяют определить такие счётчики как
Balloon (MCTLSZ) — количество памяти, вытянутое baloon-драйвером из гостевых ОС.
Swapped (SWCUR) — количество памяти, помещённое в .vswp (то есть на жёский диск).
4. Сеть
Чтобы проблемы были на уровне сети, в случае жалоб на отдельную виртуальную машину, я в своей практике помню только один случай — когда в VDI использовалась какая-то дешёвая веб-камера, гнавшая несжатый поток видео и забивавшая все 100 Мб/с.
Стоит мониторить такие счётчики:
Transmit Dropped Packets (%DRPTX) — количество (или процент в случае esxtop) отброшенных отправленных пакетов;
Receive Dropped Packets (%DRPRX) — количество (процент) отброшенных принятых пакетов.
Ненулевое их значение, возникающее на регулярной основе говорит о некорректной работе сетевых устройств или некорректной их настройке.
Для базовой диагностики, покрывающей более половины (пожалуй, до 90%) обращений или собственных потребностей при диагностике и тестировании, этого достаточно.
Комментарии (4)

Fanta
01.06.2015 00:44Поэтому разные небольшие заметки я публикую в личном блоге
Дайте линк!
kabal375 Автор
01.06.2015 07:57www.selfengineering.ru
Не сразу понял, что ссылки из профиля по умолчанию скрыты. И не сразу нашёл, где их открыть.
mureevms
А знаете, Вы правы. Пойду посмотрю черновики и, быть может, опубликую что-нибудь интересное.
С другой стороны, не каждая статья достойна Хабра и можно легко слить карму, впоследствии вообще перестав писать.
kabal375 Автор
Поэтому разные небольшие заметки я публикую в личном блоге. Там правда никакая посещаемость, поэтому, если статья нарастает в объёме и содержащуюся в ней информацию я оцениваю как «хорошо бы мне такая попалась в своё время», то переношу сюда. И если кому-то будет действительно полезно, то и хрен с ней кармой. В конце концов, смысл делиться опытом не в том, чтобы накопить больше виртуальных баллов, а в том, чтобы кто-то тратил меньше времени на уже известные вещи и больше — на что-то новое.