
Известный интернет-активист Алексей Шипилёв недавно затвитил следующее:
«Why don't we implement no-GC in HotSpot, and win every single 5-second latency benchmark. 100 GB heap is enough to survive for 10 secs.»
Круто, отличная шутка — подумали мы и пошли есть. А вернувшись с кухни, подавились сразу всеми плюшками, потому что там появились скриншоты!
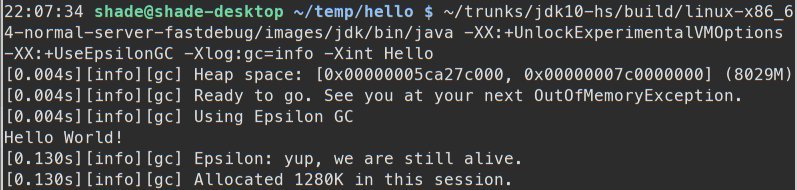
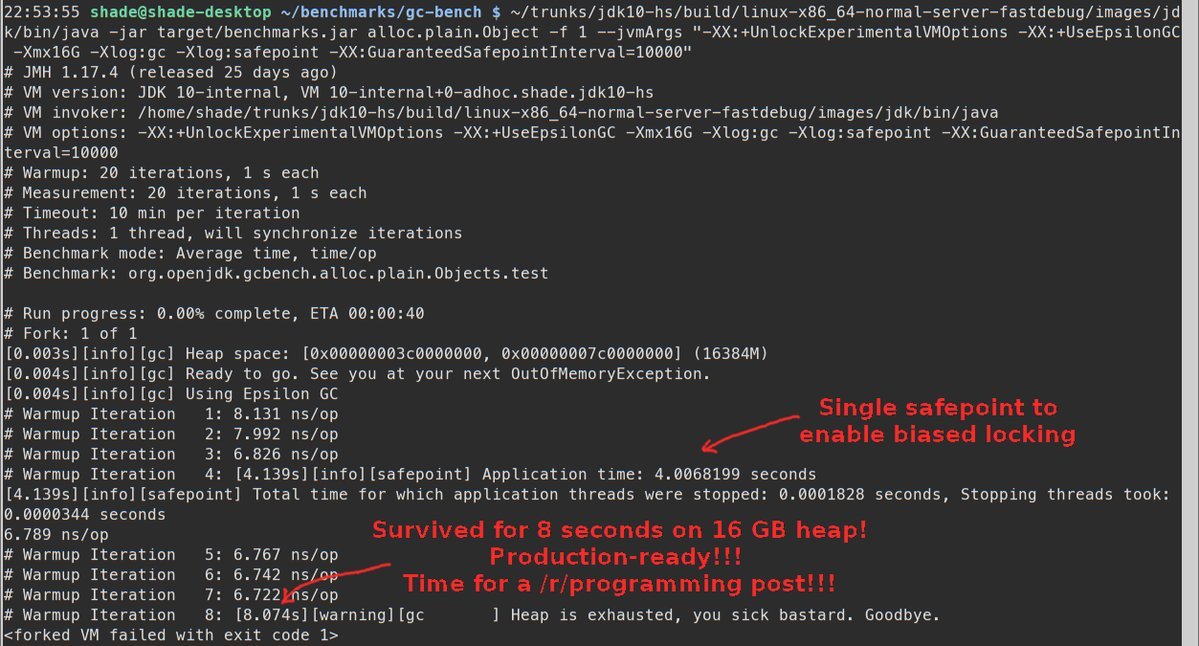
Ну ладно, мы же все умеем фотошопить, верно?
А потом
появился код
, и дело начало принимать крутой оборот. Вы понимаете, когда Шипилёв что-то выкладывает в паблик, то через месяц об этом уже положено спрашивать на собеседовании.Дрожащими пальцами мы открываем джаванет, и видим…
JEP: Epsilon GC: The Arbitrarily Low Overhead Garbage (Non-)Collector
Далее перескажу кратенько, что там написано. Мне было лень делать точный перевод, грамматические воители могут пройти и прочитать оригинал :)
О б-же, что это, Бэрримор?
Фича заключается в том, что GC заботится только об аллокации новой памяти, а на умные стратегии сборки мусора можно забить. Как только доступная куча заканчивается, начинается процедура остановки JVM.
Цели
Предоставить полностью пассивную реализацию GC с ограниченным объемом памяти, которую можно выделит. В замен получаем нижайший оверхед на производительность такого GC. Реализация не должна затрагивать другие GC или сильно что-то менять в JVM.
Мотивация
На правах сочинителя топика для хабра, немного поспекулирую. Действительно, ведь не каждая компания — Google. Кому-то хочется просто сделать минимальный работающий продукт, и только потом заботиться о его развитии. Возможно, в будущем всё придется переписать на более продвинутой платформе. Возможно, у разработчиков раньше закончатся деньги. Для этого не нужно тащить в проект сразу огромные ынтерпрайзные штуки типа G1.
Окей, шутки в сторону, идем дальше по тексту! Предполагается, что существует как минимум 4 кейса, где такая штука как Эпсилон может реально пригодиться.
Во-первых, с Epsilon можно сравнивать какой-нибудь другой более продвинутый GC, что поможет в его разработке и вылавливании багов, привнесенных самим механизмом сборки.
Во-вторых, для истинно байтоебских (это термин, а не ругательство!) приложений на Java, такой GC просто незаменим. Представим, что вы пишете прошивку для очередного чайника или умного унитаза, и сам факт сборки мусора считается багом в приложении: вместо того, чтобы собирать мусор лучше упасть, а умные балансировщики разбалансируют нагрузку по другим нодам/VM. К чему должны готовить унитаз, используя сеть сбалансированных VM, замнем для ясности. Кроме того, использование Epsilon позволит отделаться от лишних барьеров — изюминка на торте идеального перфоманса.
В-третьих, для тестирования самого OpenJDK неплохо иметь средство ограничения выделяемой памяти, чтобы тестировать инварианты нагрузки на эту самую память. Сейчас такие данные берутся из MXBeans или даже парсятся по логам GC. Если GC будет поддерживать только ограниченное количество аллокаций, это реально упростит тестирование разработчикам OpenJDK. (Скорей всего, читатели этой статьи — не разработчики OpenJDK, но теперь можно попробовать сойти за разраба OpenJDK на очередном собеседовании.)
В-четвертых, это поможет установить абсолютный минимум для интерфейса VM-GC, и может служить доказательством корректности его работы. Что полезно, например для JDK-8163329 («GC interface») (По ссылке стена текста, желающие могут перевести на Хабр).
Подробности
Для пользователя, Epsilon выглядит как любой другой GC для OpenJDK, подключенный с помощью -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC.
Epsilon линейно выделяет память в одном-единственном последовательном куске памяти. Это позволяет использовать простейший код для lock-free TLAB (thread-local allocation buffers), который может переиспользовать уже существующий код из VM. Выдача TLABов помогает поддерживать резидентную память процесса в количестве, которое было реально выделено. Поскольку при таком раскладе и выделение больших кусков памяти, и TLABов, не сильно отличается, они обрабатываются одним и тем же кодом.
Сет барьеров, использующихся Epsilon, полностью пуст, поскольку Epsilon не делает никаких настоящих циклов сборки, и следовательно ему совершенно наплевать на граф объектов, пометки объектов, копирование объектов, и весь остальной ненужный хлам. Только хардкор, только перфоманс!
Так как единственно важная часть рантайм интерфейса — та, где Epsilon выдает TLABы, его перфоманс в основном зависит от размера TLABов. Имея произвольно большие TLABы и произвольно большую кучу, оверхед производительности — произвольно маленькое положительное число, отсюда и берется название Epsilon. Авторы и пользователи golang могут начинать зеленеть от зависти и рвать волосы на дженериках.
Как только хип весь закончился, выдать TLAB уже нельзя, восстановиться никак нельзя, остается только сдаться и распечатать отчет об ошибке. Тут можно сделать что-то похожее на то, что делают другие GC:
- Бросить OutOfMemoryError с увесистым описанием
- Сдампить кучу (как всегда, включается через -XX:+HeapDumpOnOutOfMemoryError
- Жестко уронить JVM, и опционально выполнить какое-то внешнее действие (как обычно, -XX:OnError=...), например запустить отладчик, оповестить систему мониторинга, или хотя бы написать письмо в Спортлото
Прототип был проверен на небольших нагрузках, и планово падал на повышенных нагрузках.
Код всё еще лежит здесь, пока его не забрало НЛО: http://cr.openjdk.java.net/~shade/epsilon/
Альтернативы
Альтернатив нет. По крайней мере таких, чтобы вырубали все барьеры. Серьезно.
Надеюсь, что наша радость и эйфория от встречи с действительно уникальным GC, в чем-то похожа на эйфорию от тех препаратов, которые употребляет автор Epsilon, создавая подобную годноту.
В любом случае, если барьеры — не проблема, то Serial или Parallel (old) GC могут дать похожий профиль производительности — если вы, конечно, сможете их так настроить, чтобы сборка мусора никогда не запускалась (например, выставляя огромные значения young gen, выключая адаптивную эвристику, итп). Учитывая как много там опций, трудно гарантировать, что это выйдет.
Дальнейшие улучшения в современных GC, таких как Shenandoah, могут привести к снижению оверхеда до уровня, пренебрежительно малого по сравнению с полностью no-op GC. Если/кода это произойдет, Эпсилон всё еще можно будет использовать для внутреннего функционального/нагрузочного тестирования (если на пенсии вы всё еще будете хотеть заниматься внутренним тестированием GC).
А это вообще работает? А это вообще легально?
Обычные тесты нафиг не нужны, и не годятся для Эпсилона. Большинство из них считают, что можно разбрасывать произвольное количество мусора. Поэтому для тестирования Эпсилона придется делать новые тесты — нужно проверить что он работает на задачах с низким выделением памяти, а при исчерпании кучи падает не абы как, а предсказуемо. Для проверки корректности хватит новых jtreg тестов, лежащих в hotspot/gc/epsilon.
Одноразовой проверки, произведенной во время разработки Epsilon, вполне достаточно, чтобы предположить характеристики производительности на интерпретаторе, C1 и C2. Дальнейшее тестирование нафиг не нужно, так как текущая реализация с самого начала разработки была стабильней и железобетонней сталинских бункеров.
Риски и предположения
Полезность супротив стоимости поддержки. Можно предположить, что эта реализация не стоит свеч, потому что всё равно никому не нужна. С другой стороны, исходя из опыта, многие игроки джава-экосистемы экспериментировали с выбрасыванием GC из собственных кастомных JVM. Значит, если у нас будет готовый no-op GC, это поможет данной части сообщества. Ну или по крайней мере, позволит гордиться, что мы использовали no-op GC, когда это еще не было мэйстримом. Учитывая общую дешевизну реализации, риски минимальны.
Публичные ожидания. Учитывая, что этот мусоросборщик на самом деле не собирает никакой мусор, кто-то мог бы воспринять это как опасную практику. Включи ненароком Эпсилон на продакшене, и сразу же после переполнения кучи, деятелей ждут пренеприятнейшие известия. Автор предполагает, что никакого реально риска нет, пока фича проходит под флагом experimental, т.е требует включения -XX:+UnlockExperimentalVMOptions.
Сложность реализации. Можно представить ситуацию, когда в общем c другими подсистемами коде придется поменять больше, чем изначально предполагалось — например, в компиляторе, или в бэкендах конкретных платформ. С другой стороны, по прототипу видно, что все такие изменения с самого начала были жестко изолированы. Если это окажется реальным риском, то может помочь JDK-8163329 («GC interface»), о котором уже упоминалось выше.
Зависимости
В целях уменьшения количества изменений во внешнем коде, эта работа зависит от JDK-8163329 («GC Interface»). Если изменения в общем коде минимальны, то оно не должно требовать изменений в интерфейсе GC.
Заключение
Честно, я весьма устал всё это писать. Поэтому просто оставлю это здесь. Да пребудет с вами сила! Она вам понадобится в новом светлом будущем, с Java без сборки мусора.
P.S.: у Шипилёва есть ссылка на этот пост, и он следит за тобой, юзернейм
Комментарии (96)

Alexsandr_SE
15.02.2017 00:17Тяжело представить распространение ПО которое или работает или нет, в зависимости от погоды на Луне. Иные джава со сборщиками мусора больше суток других не живут без перезапуска.
KYKYH
15.02.2017 05:26+4По-моему тут как раз смысл в том, чтобы оно чётко вырубалось, а не тормозило по пол-года перед окончательным падением. Скорее всего, как автор и указал, в продакшне это годно только для вот тех самых специфичных умных унитазов, которым нужно произвести CTD+restart в кратчайшие сроки, в погоне не за стабильностью аптайма, а за суммой тактовых сигналов, потраченных на непосредственно исполнение рабочей задачи. Как вы справедливо заметили, джава и стабильность не очень сочетаются.
Scf
15.02.2017 10:20+3-XX:ExitOnOutOfMemoryError
http://www.oracle.com/technetwork/java/javase/8u92-relnotes-2949471.html

webkumo
15.02.2017 11:58+4Как вы справедливо заметили, джава и стабильность не очень сочетаются.
Что-то у меня есть подозрение, что это в немалой степени зависит от того, что вы делаете и как вы делаете. Java действительно не для всего подходит, но если не мудрить с динамической загрузкой а-ля apache servicemix — работает программа предсказуемо и надёжно...
@Scf
-XX:ExitOnOutOfMemoryError
http://www.oracle.com/technetwork/java/javase/8u92-relnotes-2949471.htmlА что делать со старыми версиями? И вы уверены, что GC не будет пытаться прочистить (и тормозить систему), а сразу отдаст OOME? Здесь-то речь именно о fail-fast — даже не пытаться прочистить, а сразу падать.

olegchir
15.02.2017 15:31Если вы имеете в виду старые версии JVM, то тут двух решений быть не может — все они дружным строем отправляются на свалку истории. Нужно всегда поддерживать свой софт совместимым с текущей версией JDK, и заранее тестировать и готовиться к переходу на новые версии.

vladimir_dolzhenko
15.02.2017 23:32+1Java 8:
public class Boo { public static void main(String[] args) { List list = new ArrayList(); while (true) { list.add(new Object()); } } }
и для наглядности можно ограничить кучу хоть до 10 Мб
$ javac Boo.java && java -Xms10m -Xmx10m Boo
Ожидания одни — а на деле всё совсем по иному

sshikov
18.02.2017 14:15Что не так с servicemix? У нас он давно в prod, работает месяцами, никаких таких проблем не припомню.
webkumo
18.02.2017 22:23Или у вас его готовить умеет кто-то или просто повезло. Чуть что-то неожиданное хочешь сделать и возникает проблема — становится непонятно куда копать и что ковырять.
sshikov
19.02.2017 13:41Кто-то умеет? У нас этих кто-то человек 10 наберется.
Конечно же, OSGI это не самый простой случай для GC и вообще, хотя бы потому, что это контейнер, и там могут быть внутри приложения с разными паттернами потребления памяти.
Но никакой магии там в общем-то нет. Совершенно. Не больше чем в любом другом контейнере. Я бы сказал, что единственная проблема servicemix — в том что там баги поздно фиксятся по сравнению с теми оригинальными компонентами, из которых он состоит (т.е. karaf, camel, и прочая).webkumo
19.02.2017 14:58У нас этих кто-то человек 10 наберется.
Ну вот это вас сильно выручает… а у нас — начали ковыряться а опыта ни у кого нет… в итоге — фича не встаёт толком, не обновляется и сидишь недоумеваешь над документацией… которой особо нет, в дебаге, который показывает странное бесконечное циклирование на поиске зависимости для этой фичи… при этом в список каким-то образом пробралась сама эта фича… я так и не разобрался как такую беду пождать...
sshikov
20.02.2017 15:27Судя по проблемам вы говорите явно не о GC. А о чем-то типа разрешения зависимостей при установке фич.
Могу тут только посоветовать пообщаться на форумах, возможно даже не servicemix, а просто karaf — там народ вполне отзывчивый, мне неоднократно помогали советами.
И кроме шуток — поставьте веб консоль. hawtio или хотя бы родную от карафа. Сильно помогает одним взглядом окинуть, что там на самом деле стоит, и в каком состоянии, и что с чем может конфликтовать. Меня тоже не раз выручало.
uelkfr
15.02.2017 15:26+4Мне всегда казалось наоборот, что Java (JVM) — это самая стабильная технология, которая никогда не падает, а всегда выбрасывает исключение. Не поймал исключение — сам виноват.
KYKYH
15.02.2017 18:09+1Что касается исключений, то это чистая правда, стабильность приложения как такового всецело в руках самого разработчика. И я думаю именно оттого родилось описанное в статье решение: разработчику в некоторых проектах выгоднее стабильно ронять приложение, чем распространяться в десяти томах мемуаров об исключениях. А это решение позволяет очень чётко рамки этой стабильности падения определить. С точки зрения традиций, это скорее хак, но полезный в своей нише.
А вот что касается стабильности платформы, то я полагаю некоторые деятели из каких-нибудь больших данных и распределённых вычислений с вами бы поспорили. Впрочем даже такие споры в конце концов сведутся не к самой платформе, а к требованиям самого процесса разработки, ибо любая платформа стабильна, если она зависит от измеримых показателей и статистически постоянна.
LionZXY
16.02.2017 13:31+2Пока никаких четких аргументов в сторону не стабильности Java не было. Не могли бы вы привести парочку?
KYKYH
19.02.2017 08:11-2За примерами далеко ходить не надо, к примеру тот же outofmemoryerror, для которого во многом и сделан данный топик. Дело в том что в джаве эта ошибка не всегда означает реальное истощение памяти, и появляется в том числе при попытке выделения. В этом случае память ещё не занята, но выделить память для обработки у вас уже не получится, и в результате придётся причинять нестабильность к приложению или полагаться на рестарт после вылета. Нестабильность в приложении можно сделать, к примеру, выкинув контекст текущей задачи и извинившись перед пользователем в стиле «Звёзды так сошлись, и что-то случилось неправильно, может результаты твоей задачи есть частично, может она развалилась по дороге, и у тебя в окружении теперь в неизвестном месте валяется половина пепелаца.» В то же время, есть платформы, которые делают outofmemory значительно реже, чем insufficientmemory (который имеется и в джаве, но почему-то не используется во всех подходящих для неё случаях.
А вот примеров нестабильности не связанных с памятью я не знаю. Может просто потому, что я ещё не всех монстров повидал. Наверняка есть сырые платформы которые и работают ещё кое-как, но я ими не пользуюсь.
AndreyRubankov
19.02.2017 10:24+2В этом случае память ещё не занята, но выделить память для обработки у вас уже не получится
Это присутствует, но вы не сказали самого важного: перед тем как бросить OOM будет произведен FullGC 2-3 раза, и если после этого не будет свободной памяти — вылетит OOM (но это еще не конец жизни jvm).
Есть ли подход более правильным с вашей точки зрения? Если есть, думаю, это было бы полезно узнать всем.KYKYH
19.02.2017 17:57Я не вижу причин, чтобы кидать outofmemory прежде, чем insufficientmemory. Надо иметь возможность обработать ошибку/исключение прежде, чем программа войдёт в условно нерабочее состояние. Платформа должна знать, хватит ли ресурсов на предстоящую загрузку, а исключениями могут стать только уж совсем маргинальные случаи, когда ни памяти, ни кэша не хватает даже на оценку предстоящей задачи.
AndreyRubankov
19.02.2017 18:41+1Во-первых, хотелось бы узнать откуда вы взяли «insufficientmemory»? В java, на сколько я знаю, такого нету. Если из .NET, то insufficient memory exception — это наследник ООМ.
Во-вторых, что мешает перехватить OOM и освободить ресурсы или корректно завершить работу того участка, в котором возникла эта ошибка и возможно даже спасти всю программу?
jvm позволяет перехватывать ООМ и «спасать» от падения, вопрос — стоит ли это усилий? Если да — без проблем: перехватывай, спасай от смерти! :)
вот только если не хватает памяти, то тут скорее всего утечка памяти, и спасать по большей части нету смысла — все равно упадет, а потом снова и снова и снова, будет жить в конвульсиях: и сделать ничего не сделает и не упадет / не перезапустится.
По этому никто и не перехватывает ООМ.
rPman
16.02.2017 00:01+1Вы действительно корректно сами обрабатываете outofmemoryerror и будете как то обрабатывать outofheapmemoryerror?
не в том смысле что вы ловите и в catch выводите ошибку на экран, а именно обрабатываете, запускаете выгрузку каких то своих данных и запускаете повтор сфейлившейся операции?
vanxant
16.02.2017 00:18+1… ага, и всё это без возможности создать хоть какой-нибудь вшивенький объект в куче.
Я не уверен, в этой ситуации хотя бы тупо сдампить всю память процесса на диск можно, не создавая новых объектов в куче?
grossws
16.02.2017 03:23+1Можно держать baloon и освобождать его, когда память начинает заканчиваться, как вариант. Или, ещё лучше, заранее выделить все необходимые для обработки ошибки объекты.
vanxant
16.02.2017 04:03+2Ага. А ещё можно вообще всю память распределить на этапе компиляции или запуска. И запустить в ней конструкторы опять же на том же этапе. И никаких проблем не то что с GC, вообще с памятью в принципе, если вы понимаете о чём я.
И это не шутки, а стандартный путь для всяких встроенных «пылесосов» и всего такого. Тут ещё такой момент, что это решает большинство проблем с ДДОСом. Ваш пакет не лезет в буфер? Ну, получите стандартный TCP-отлуп. Но на работе девайса это не скажется.grossws
16.02.2017 10:38+1Память да, конструкторы — нет, т. к. в них могут захватываться другие ресурсы. Но ограниченные буфферы, количество примитивов ОС (если она есть) и отсутствие malloc'а в embedded мире вполне понятная практика.
mayorovp
16.02.2017 11:10+1В Java Card конструкторы вызываются при установке приложения. Как и в персистентных ОС.
grossws
16.02.2017 11:48+1Согласен, это пример managed окружения, где объект является единицей деплоя и почти вся память персистентна. Апплет стартует сразу, при установке, так что это тоже укладывается в озвученное vanxant.
Я скорее подразумевал не такое управляемое окружение, а bare metal C/C++ с выделение глобальных статических структур на этапе компиляции: всяких структур описания потоков, mutex/semaphore/condition, буферов данных, сетевых буферов, предпосчитанных заголовков и тому подобных разлечений, чтобы не тащить динамическое управление памятью и его проблемы во встроенное ПО.
olegchir
16.02.2017 23:35-1можно выставить аппаратный флаг, который позволит внешнему аппаратному балансировщику переложить нагрузку на другое железо


sheknitrtch
15.02.2017 00:22+6Разработчики Instagram уже проделали нечто подобное с Python: Dismissing Python Garbage Collection at Instagram. В их случае это дало 10% выигрыш в производительности.
vagran
15.02.2017 19:19+2В Python есть reference counting, сборщик мусора нужен только для островов с циклическими ссылками, которые не так уж часто возникают, или по крайней мере можно специально писать код так, чтоб этого избежать. Странно, что в Java до такого не додумались.
sheknitrtch
16.02.2017 12:34+2Можете поискать в Интернете сравнения «reference counting» и «tracing garbage collection» подходов. Например Я нашёл развёрнутый ответ на quora: How do reference counting and garbage collection compare?. Проблемы с Reference Counting следующие:
- Циклические ссылки всё равно нужно искать путём сканирования всех объектов в памяти;
- Увеличение/уменьшение счётчика ссылок происходит очень часто, что приводит к частым cach miss даже если поля объекта не менялись;
- В многопоточной среде могут возникнуть race condition из-за того, что операция инкремента/декремента не атомарная. В Python это решено с помощью GIL. Замена на атомарный инкремент/декремент сильно ухудшает общую производительность;
- При уничтожении объекта могут использоваться деструкторы. А так как объект может быть уничтожет в любой момент, то и паузы вызванные деструктором совершенно непредсказуемы;
Ну и самое главное: нельзя просто так поменять один тип управления памятью на другой. Это повлияет на все аспекты работы виртуальной машины. Поэтому в Java не появится Reference counting, а Python врядли перейдёт на Tracing garbage collection.vagran
16.02.2017 12:51+1Про циклические ссылки я написал, это главная причина, зачем вообще нужен GC. IMHO, aтомарный инкремент/декремент на современных процессорах достаточно быстро делается. Деструкторы в языках с GC и недетерминированным временем жизни объекта — это сам по себе хак. И если они есть, то как правило ставятся в очередь на выполнение в отдельном потоке и вообще портят жизнь GC своим наличием.
mayorovp
16.02.2017 12:58+3Проблема атомарного инкремента — не в том, что он делается медленно, а в том, что он требует эксклюзивного доступа. Если не выделить ему отдельную кеш-линию — он будет мешать общему доступу на чтение к другим полям объекта.
А кеш-линия — это, вообще-то, целых 64 байта...
sheknitrtch
16.02.2017 13:25+2IMHO, aтомарный инкремент/декремент на современных процессорах достаточно быстро делается.
Я попытался найти нормальный benchmark для сравнения производительности (ведь сам А. Шипилёв говорил, что нельзя верить бенчмаркам :), нашёл два:
- Comparing the performance of atomic, spinlock and mutex — статья 2012 года, в которой Atomic тест проигрывает No synchronization тесту в 5 раз.
- Comparison: Lockless programming with atomics in C++ 11 vs. mutex and RW-locks — более развёрнутая статья 2015 года, в которой тест #4: Atomic Read & Write проигрывает тесту #0: Unlocked в полтора раза.
А во вторых, хочу обратить ваше внимание на проект Gilectomy, в рамках которого программист Larry Hastings пытается избавиться от Python GIL. Вот его выступление на PyCon 2016: Larry Hastings — The Gilectomy. Чтобы не тратить время, перемотайте на сравнение производительности 25 мин 46 сек. Графики показывают что на текущий момент Python с вырезанным GIL работает в 10-18 раз хуже (в зависимости от количества ядер CPU) чем стандартный Python. И львиная доля падения производительности связанна именно с cache miss-ами.

Siemargl
15.02.2017 00:56+6// topic mode on
Отлично, теперь ява может выживать 24/7/362 на терабайтном суперсервере!
// topic mode off
Как будто это новость.
Halt
15.02.2017 08:28+2А в самом деле, что нового? Несобирающие one-shot memory manager-ы уже давно существуют в Ruby и других динамических языках. Плюсы и минусы такого решения должны быть более-менее понятны.
Действительно, интереснее было бы узнать, что выгоднее: перезапускать всю JVM или сделать полную сборку на гигантской куче обычным GC.
TheKnight
15.02.2017 09:47+1Кто то уже считал — выгодней перезапускать JVM. Правда куча действительно была большая и FullGC был в районе 12 часов.


TargetSan
15.02.2017 01:32+9Ждём когда появится JEP на внедрение RAII, типов-смартпоинтеров и отделения ссылочности от типа :)
pohab
15.02.2017 05:25+5Все очень интересно, только я не понял, чем это лучше обычного ParallelGC с кучей 100Гб и только Full-GC сборками. Ведь в этом случае все тоже самое, только приложение продолжает работать. А вопрос, что отнимает больше ресурсов, Full GC или перезапустить с нуля приложение (старт VM, инициализацию и прогрев приложения) так и остался открытым.
ggrnd0
15.02.2017 12:18Чем больше куча, тем выше шанс на большую среднюю скорость при перезапуске.
Прогрев остывших кешей — может в среднем оказаться более дорогой операцией, чем GC.
Думаю, будет больший толк в создании pci-e платы расширения, которая эффективно и паралельно основному ПО будет помечать дохлые объекты. А дефрагментацию памяти можно уже с остановкой jvm сделать.
Но пока такой платы нет, мой выбор — балансировка между десятками/сотнями VM с предсказуемым latency.
ggrnd0
15.02.2017 12:27+1Прогрев остывших кешей — может в среднем оказаться более дорогой операцией, чем GC.
Но прогрев остывших кешей — может в среднем оказаться более дорогой операцией, чем GC.
Так что зависит от особенностей приложения.
Например, если весь кеш хранится снаружи jvm (inmemory-db), то каждое чтение из кеша порождает создание новых объектов и перезапуск будет более выгодным.
Если кеш хранится внутри jvm (Hibernate 1L/2L caches), то перезапуск будет менее выгодным, так как требует прогрев кешей с 0.

Mendel
15.02.2017 12:32+4Ой. Выделить терабайт под своп и весь мусор плавненько сложится в своп по таймауту.
Там где аптайм не критичен а важнее отзывчивость — вполне себе решение.
А так то забавно конечно. ПХП учится не умирать и уже вполне стабильно может жить в виде демона, а java учится умирать).
The535
15.02.2017 05:25+8Не знаю, как вы, господа разработчики будущего, а я лично человек очень консервативный. Не успел еще привыкнуть к лямбдам и всей этой функционалщине, новости о каком-то непонятном проекте Jigsaw, так тут еще и сборщик мусора забирают. Скоро в util еще появится класс для работы с памятью, с единственной функцией malloc. К черту освобождение памяти, если что, грохнем VM.
alxt
15.02.2017 08:46+3Интересно сделать (официальный, велосипеды есть в т.ч. в production) сборщик yang-only.
Т.е. пока в OldGen есть место- живём.
Кончилось вместо fullGC- рестарт.

OLDRihard
15.02.2017 08:46+24Rust заменяет GC своей хитрой архитектурой, которая помогает определить момент очистки памяти в самом коде. Когда читаешь такой кричащий заголовок с сравнением java и rust, ожидаешь нечто более умное и пафосное, чем банальное отключение GC. Не надо так, вступление уж больно желтое.

sshikov
15.02.2017 09:20+1>Учитывая как много там опций, трудно гарантировать, что это выйдет.
Ну почему же? У многих выходило. Понятно что платой за это обычно будет тупо перерасход памяти, но отключить GC настройками, если вы примерно представляете потребление памяти в своем приложении — не такой уж сложный фокус.
ZurgInq
15.02.2017 09:48-9Слишком кричащий заголовок, много восклицательных предложений, транслит вместо нормального русского языка (перфоманс, хип) — текст трудно воспринимается. Не надо так.
Я не java программист и думал, что придумали что то новое, ждал технических подробностей, а в итоге вся статья укладывается в предложение — «в java теперь можно GC, но она будет падать».

Akon32
15.02.2017 10:43+4Не разделяю такого оптимизма по поводу отключения GC.
За 10 секунд работы даже JIT как следует не прогреется.
Почти все (если не все) программы на java написаны так, что постоянно выделяют мелкие объекты. Работа со строками вообще основана на таком частом выделении памяти. Чтобы по-нормальному использовать этот EpsilonGC, нужно всё переписывать (на массивы символов вместо строк?). Не говоря уже о том, что перемещающий сборщик мусора, который позволяет
невозбранножрать гигабайты памяти кусками хоть по гигабайту, (почти) не беспокоясь о фрагментации свободной памяти, — полезная в ряде случаев фича. В общем, отключили самое вкусное.
Полагаю, работа с отключенным GC подходит только для скриптов и тому подобного (ну и для научного интереса, естественно). Ещё для использования этого режима нужна уверенность, что тех выделенных N гигабайт памяти будет достаточно для выполнения задачи (если не хватит — задача вообще не выполнится, а с GC выполнилась бы, но медленнее).
Во-вторых, для истинно байтоебских (это термин, а не ругательство!) приложений на Java, такой GC просто незаменим. Представим, что вы пишете прошивку для очередного чайника или умного унитаза, и сам факт сборки мусора считается багом в приложении: вместо того, чтобы собирать мусор лучше упасть, а умные балансировщики разбалансируют нагрузку по другим нодам/VM.
Пример повеселил. Кластер в чайнике — это уже не байтоёбство, а несколько другой вид развлечений.
Scf
15.02.2017 10:48+1В принципе, этим gc могут еще банки заинтересоваться с их low-latency системами. Тем более что все необходимые безмусорные библиотеки у них уже есть — от коллекций до io.

AndreyRubankov
15.02.2017 12:36+1Забыли про HFT, который тоже некоторые ребята делают на Java (DevExperts с Романом Елизаровым, если не ошибаюсь). В этой сфере GC — это злейший враг. А приложение не обязано жить больше нескольких часов.
А так же непосредственно для разработки библиотек, которые не мусорят — будет проще находить точки генерации мусора.
Но самое главное — это для того, чтобы бенчмарки гонять xDScf
15.02.2017 12:56+1С точки зрения аналитики и т.п. в джаве всё уже есть — java mission control позволяет смотреть подробнейшую статистику по аллокациям. Вот если оно меньше памяти потребляет или быстрее работает...
AndreyRubankov
15.02.2017 16:06+2Только вот он дофига платный, хоть и идет с OracleJDK сразу.
grossws
16.02.2017 03:45+1Насколько помню, при разработке лицензия разрешает его использовать:
The Java Flight Recorder (JFR) is a commercial feature. You can use it for free on developer desktops/laptops, and for evaluation purposes in test, development, and production environments. However, to enable JFR on a production server, you require a commercial license. Using JMC UI for other purposes on the JDK does not require a commercial license.
https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr002.html
AndreyRubankov
16.02.2017 10:04+1Спасибо за уточнение! Но я лишь напомнил, что это все же платный тул и если не знаешь лицензии — лучше не рисковать использовать его.
grossws
16.02.2017 10:45+1Там
-XX:+UnlockCommercialFeatures -XX:+FlightRecorderдовольно ясно намекают, что это коммерческая фича.
Ещё народ старательно накалывается с их msi-установщиком (Java SE Enterprise MSI installer), который очень удобно раскатывать через доменные политики. У него тоже в названии "Enterprise", но народ это не останавливало, пока не приходили добрые люди от Oracle.

Losted
15.02.2017 13:18+4Ух, так и вижу деплоймент архитектуру типа «Память кончилась — помечаем инстанс дохлым — Scaling Group стартует новый». Прям рефересная реализация Мерседеса и переполненной пепельницы.

SBKarr
15.02.2017 13:51+2В мире C есть, например, Apache Portable Runtime с пулами памяти. С таким подходом очень удобно делать, например, обработчики для веб-запросов. Создал пул, обработал, убил пул. Пула не хватило — вернул 500. Удобно, быстро, можно не думать о памяти. Описанная здесь штуковина даёт что-то подобное для Java?
ggrnd0
15.02.2017 14:31+2Да:
1) jvm запрашивает пул
2) когда пул заканчивается, jvm убивает себяSBKarr
15.02.2017 14:38+1Но jvm убивается целиком, или каким-то образом можно сделать кусочное освобождение? Или, например, несколько инстансов jvm на приложение, которые можно убивать и перезапускать?
ggrnd0
15.02.2017 14:40+1Убивает себя, но при этом может что нибудь еще сделать.
Как только хип весь закончился, выдать TLAB уже нельзя, восстановиться никак нельзя, остается только сдаться и распечатать отчет об ошибке. Тут можно сделать что-то похожее на то, что делают другие GC:
Бросить OutOfMemoryError с увесистым описанием
Сдампить кучу (как всегда, включается через -XX:+HeapDumpOnOutOfMemoryError
Жестко уронить JVM, и опционально выполнить какое-то внешнее действие (как обычно, -XX:OnError=...), например запустить отладчик, оповестить систему мониторинга, или хотя бы написать письмо в СпортлотоМожно за балансировщиком расположить несколько jvm.
Но это совсем от jvm не зависит.
chabapok
15.02.2017 15:08+1В жаве подобный принцип — составная часть gc, называется young gen.
SBKarr
15.02.2017 20:06-1Ключевая разница — наличие GC Stop. В случае с пулами памяти никакой остановки на сборку мусора не происходит. Да и вообще, вместо сборки мусора просто обнуляется одна переменная. Не нужны и дополнительные затраты памяти на регистрацию аллокаций.
chabapok
15.02.2017 21:39-1Так и в java если не плодить долгоживущих обьектов — остановок не будет. Все умрет в young gen обнулением счетчика. Все как вы и описали, причем оно даже лучше malloc работает. Единственная разница — что нельзя руками положить объект сразу не в young gen, а куда-то выше, или в другой young gen пул. Тут — да, недостаток.
Но Надо помнить, что суть gc stop заключается в дефрагментации памяти. В языках, где подобной фичи нет — никто никогда память вообще не двигает: нате вам OOM — и гудбай. Не нравится — втыкай еще памяти, или оптимизируй задачу.
Разрабы java заморочились и для этого придумали full gc, который все останавливает на время работы. Сделали они это, вероятно, потому что оно и так много памяти ело. Типа, чтобы на них сильно не кричали. Но люди начали считать эту фичу штатным средством. На самом деле, это не штатное средство, а палочка-выручалочка, дающая то, чтобы оно хоть как-то работало, пока ты побежал в магазин докупать память. Если до него дошло дело, это лишь значит, что для реализации данного алгоритма мало памяти, и по хорошему ты должен сказать спасибо, что оно не ooэмнулось а хоть как-то худо-бедно отработало.
Хотя в некоторых задача — да, лучше бы оно ооэмалось.
chabapok
15.02.2017 15:05+1Насколько понимаю, если GC только выделяет память, но никогда не чистит ее — в некоторых приложениях это может оказаться дольше, потому, что там будут при аллокации практически всегда L3 cache miss, ведь это каждый раз новая память. Т.е., наиболее долгая форма. Поэтому, скорей всего, new будет довольно медленным.
Другое дело, что актуально ли это на задачах, для которых он нужен.
binkaminka
15.02.2017 15:26-3К примеру Go тоже умеет работать с выключенной сборкой мусора.
Это у него штатная возможность, которую кто-то поди использует — говорят, еще быстрее работает.


snuk182
15.02.2017 17:45+1Я бы назвал этот GC — Kenny. Тупо убить процесс, чтобы создать новый с нуля в следующей
сериисессии…

amarao
15.02.2017 17:47+5Хочу пожелать программистам java использовать редактор и браузер с такой моделью выделения памяти. Вместо того, чтобы тупить и тормозить — чётко и жёстко падать. А что там комментарий на хабре недо
snuk182
15.02.2017 17:52+2Нишевое применение же. Вопросы скорее к самой статье, которая желтая и хайповая.
Scf
15.02.2017 17:53+1Это для серверных приложений — Представьте себе n машин, на которых периодически жестко падают процессы, а перед ними — балансер, который умеет делать перезапрос при ошибке.
amarao
15.02.2017 19:40+4В тот момент, когда падение приложение становится штатным режимом работы приложения, вся конфигурация теряет один уровень устойчивости.
Представьте себе, что балансер тоже работает по такому же принципу: падает каждые 10000 запросов.Scf
15.02.2017 19:47+1Именно! В этом и смысл облака — что балансер тоже может упасть, поэтому балансеров должно быть два, а поиск балансеров должен работать через другую отказоустойчивую систему… DNS к примеру.
amarao
15.02.2017 20:00+1Но dns-сервера тоже работают по этому алгоритму — они падают каждые 1000 запросов, потому что у них заканчивается непрерывный кусок памяти, и падение dns-сервера является штатным его режимом работы.
Отвечая на вопрос: и dns-ресолверы ведут себя так же.
Представьте себе мир, в котором всё построено на софте, разработчики решили, что падать из-за того, что закончилась write-once память — это норма. А GC — это для лохов.Mendel
16.02.2017 22:00-1Ну ДНС для этого не используется, а скорее hearbeat на отдельном интерфейсе.
orcy
15.02.2017 20:40+2> Кажется, мир Java развился до такой степени, что то ли мы теперь можем спокойно использовать Rust вместо Java, то ли Java вместо Rust
Что-то совсем не похоже.
vladimir_dolzhenko
16.02.2017 00:51+2Столько комментариев — и ни одного — а где патч для java 8 или хотя бы для java 9?
olegchir
16.02.2017 23:44Патч находится в тексте поста.
Дублирую еще раз: http://cr.openjdk.java.net/~shade/epsilon/vladimir_dolzhenko
17.02.2017 12:11Пробовали ли вы сами применить данный патч для java 8 или java 9?
Этот патч для java 10 — и для 10ки он успешно применяется и работает, для 9ки, например нет файла hotspot/src/share/vm/services/memoryManager.cpp
Throwable
16.02.2017 14:33+2Практическая полезность была бы кстати, если бы JVM умела бы делать быстрый hot-restart: прибиваются все треды, освобождаются все системные ресурсы, но при этом оставлялся бы PermGen с классами, сгенеренной статистикой выполнения и предкомпилированным кодом.
Предлагаю следующий этап эволюции GC и архитектуры приложений: не собирать мусор, пока не заполнится вся память, затем вызвать специальный OutOfMemory-хандлер у тредов, у которых он зарегистрирован, после чего начать полную сборку мусора.
Что это даст? Процессинговые треды, имеющие OutOfMemory хандлер смогут обработать ситуацию: закрыть ресурсы, вернуть ошибку клиенту, сообщить в кластер, что нода отвалилась, и при необходимости рестартнуть после сборки мусора. Чтобы при вызове хандлеров не было повторного OutOfMemory вся аллокация ведется в отдельно зарезервированной области.
Таким образом можно реализовать быстрый перезапуск процессинга без реальной необходимости перезапуска системы.
AndreyRubankov
16.02.2017 18:19+3Практическая полезность была бы кстати, если бы JVM умела бы делать быстрый hot-restart: прибиваются все треды, освобождаются все системные ресурсы, но при этом оставлялся бы PermGen с классами, сгенеренной статистикой выполнения и предкомпилированным кодом.
Дык, AOT в Java9 будет, и в некоторых кейсах пермгены и все прочее можно будет выкинуть.
AOT + GC Epsilon + не плодить мусор = хардкор для эмбеддед.
olegchir
16.02.2017 23:48Насколько помню профиль систем с предыдущих N проектов, почти весь этап загрузки происходит прогрузка спринговых бинов, так что пока GC не научится в Спринг — ничего сильно не изменится :-)

speakingfish
18.02.2017 11:54-1А можно сделать так: Прогреваем со стандартным GC, врубаем NoGC и дальше форкаем и держим на готове пул форков?

homm
Вроде не хватает главного: замера производительности какого-нибудь быстроиграющего, но интенсивного консольного приложения с обычным сборщиком и Эпсилоном. Ну, например YUI Compressor.