
Коротко о статье
Инлайнинг методов – одна из наиболее важных оптимизаций в JIT-компиляторах (которые благодаря ей называются «основанными на методах» или «блочными»). Эта оптимизация расширяет область компиляции, позволяя оптимизировать несколько методов как единое целое, что повышает производительность приложений. Однако, если использовать инлайнинг методов слишком часто, время компиляции станет излишне большим, и будет сгенерировано слишком много машинного кода. И вот это скажется на производительность уже негативно.
Трассирующие JIT-компиляторы собирают не всё подряд, а только часто исполняемые пути, так называемые трейсы. С помощью этого можно получить более быструю компиляцию, уменьшить количество сгенерированного машинного кода, и улучшить его качество. В предыдущих наших работах, мы реализовали инфраструктуру для записи трейсов и трассирующий Java-компилятор, модифицируя код Java HotSpot VM. Основываясь на этой работе, мы посчитали, какой эффект инлайнинг трейсов оказывает на производительность и количество генерируемого кода.
По сравнению с инлайнингом методов, инлайнинг трейсов предоставляет несколько важных преимуществ. Во-первых, инлайнинг трейсов – более избирательный, потому что инлайнятся только часто исполняемые пути. Во-вторых, записанные трейсы могут содержать информацию о виртуальных вызовах, что упрощает инлайнинг. Третье преимущество в том, что информация трейса контекстно-зависима, так что различные части метода могут инлайниться в зависимости от конкретного места вызова. Эти преимущества позволяют агрессивнее инлайнить в тех случаях, когда количество генерированного кода всё еще находится в разумных пределах.
Мы проверили несколько эвристик инлайнинга, используя бенчмарки DaCapo 9.12 Bach, SPECjbb2005, SPECjvm2008, и показали, что наш трассирующий компилятор позволяет достичь на 51% больше пиковой производительности, чем блочный client compiler из HotSpot. Более того, мы показали, что расширение области компиляции в нашем трассирующем компиляторе оказало позитивный эффект на другие оптимизации, такие как свёртка констант и устранение проверок на null.
Замечания к переводу
Лицензия: CC BY 3.0 (Creative Commons Attribution 3.0 Unported)
Оставлены без перевода слова «трейс» и «инлайнинг», потому что эти слова слишком прочно вошли в русскую разговорную речь. При попытке обсудить с коллегой «встраивание трасс», можно оказаться непонятым.
Если один код вызывает другой, то вызывающая сторона называется отправителем (caller, sender), а вызываемая сторона называется получателем (callee, receiver). Эти слова притянуты за уши, но они короткие и общие, и, благодаря этому, не загромождают текст.
Основанные на инлайнинге методов компиляторы (method-based compiler) называются здесь «блочными компиляторами». Этот неологизм введен также в целях понижения загромождения текста и устранения неоднозначностей в русском варианте.
Картинки и диаграммы не перерисованы, и содержат в себе надписи на английском языке. Сорри.
Перевод держится близко к тексту даже там, где это доставляет неиллюзорную боль переводчику. В частности, бесконечные самоповторения, «введения», по объему превышающие содержание статьи, сто раз сложноподчиненные предложения – частый спутник всевозможных исследовательских работ по Java. Если у вас уже появилось желание набить кому-нибудь лицо, то обращайтесь с этими желаниями к авторам.
Замечания к переводу: целевая аудитория
На днях мы парились в баньке, и в чаде кутежа прозвучала мысль, что когда-нибудь историю софта будут изучать так же, как сейчас – историю России. Специальные софтовые археологи будут выкапывать диковины из глубин древних репозиториев, бережно отряхивать от пыли и пытаться собирать.
Вернувшись домой я обнаружил, что половина документов из папочки «must read» состоят из документов 5+ летней давности, что по нашим временам уже «давным-давно, в далёкой-далёкой галактике». То есть, раскопки можно начинать уже прямо сейчас, зачем ждать.
Поэтому сложно дать какую-то рекомендацию, стоит ли читать эту статью и следующие.
Иногда в грязи можно выкопать алмаз, а иногда мусор – это просто мусор.
В среднем, текст предназначен для энтузиастов в области разработки виртуальных машин.
Краткие сведения об авторах текста и переводчике даны в самом конце статьи.
А сейчас мы переносимся в 2013 год, весна, апрель, птички поют, на лавочке сидят дедушки Christian Haubl, Christian Wimmer и Hanspeter Mossenbock, и рассказывают нам о контекстно-зависимом инлайнинге трейсов.
1. Введение
Основанные на инлайнинге методов JIT-компиляторы (в дальнейшем — «блочные компиляторы»), транслируют методы целиком, превращая их в оптимизированный машинный код. Трассирующие компиляторы в качестве блока компиляции используют часто исполняемые пути [1]. Это повышает пиковую производительность, одновременно с этим понижая количество сгенерированного машинного кода. Рисунок 1 показывает граф потока управления (control flow graph, CFG) для трех методов и трех путей по ним. Начало трейса называется якорем (trace anchor), который представлен блоком 1 для всех трейсов в этом примере. Какие именно блоки станут якорями, сильно зависит от конкретной реализации системы записи трейсов.
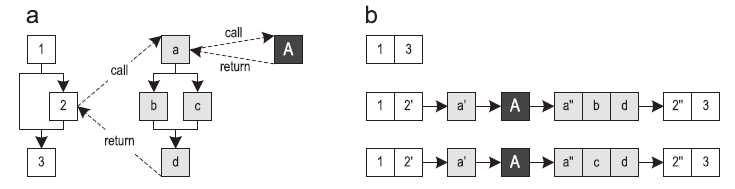
Рисунок 1. Трейсы, проходящие по трем методам: (а) граф потока управления (b) возможные трейсы
В виртуальной машине трейсы можно записывать, инструментируя выполнение байткода. Потом эти трейсы скомпилируются в оптимизированный машинный код. Если исполняется часть метода, которая еще не скомпилирована, обычно система возвращается в режим интерпретатора.
Большинство существующих сейчас реализаций записи трейсов позволяют трейсам пересекать границы методов. [1, 2, 10, 12, 18]. Это может привести к появлению больших трейсов, которые должны компилироваться совместно.
В предыдущей работе [14, 15] мы реализовали трассирующий JIT-компилятор, основанный на client compiler из Oracle Java HotSpot. Наша предыдущая статья для конференции [15] фокусировалась на инлайнинге трейсов и включала следующее:
- Описание того, как делать инлайнинг трейсов и обсуждение его преимущества перед инлайнингом методов
- Описание нескольких характеристик инлайнинга, реализованных на собственном трассирующем JIT-компиляторе
- Оценка влияния эвристик инлайнинга трейсов на время компиляции, пиковую производительность, и количество сгенерированного машинного кода для бенчмарка DaCapo 9.12 Bach [3].
Эта статья является расширенной версией описанного выше документа, и добавляет следующие новые аспекты:
- Более подробное описание записи и инлайнинга трейсов
- Описание того, почему компиляторные интринсики для native методов выигрывают от расширения области компиляции, получающегося в результате инлайнинга трейсов
- Оценка наших конкретных эвристик на бенчмарках SPECjbb2005 [23] and SPECjvm2008 [24].
Более того, мы сравниваем пиковую производительность наших лучших эвристик с серверным компилятором HotSpot. - Исследование того, какие высокоуровневые оптимизации в компиляторе получают преимущества от инлайнинга трейсов в результате расширения области компиляции.
Оставшаяся часть этой статьи организована так:
- обзорная часть 2 дает короткое введение в нашу трассирующую виртуальную машину
- в части 3 будет показана система записи трейсов,
- в части 4 мы расскажем, как делать инлайнинг
- часть 5 представляет вниманию читателя различные эвристики
- часть 6 посвящена обсуждению результатов бенчмарков
- в части 7 мы обсуждаем связанные работы
- а часть 8 завершает эту статью.
2. Беглый обзор
В предыдущей работе мы реализовали инфраструктуру для записи трейсов и трассирующий JIT-компилятор для Java [14,15]. Рисунок 2 показывает структуру нашей VM.
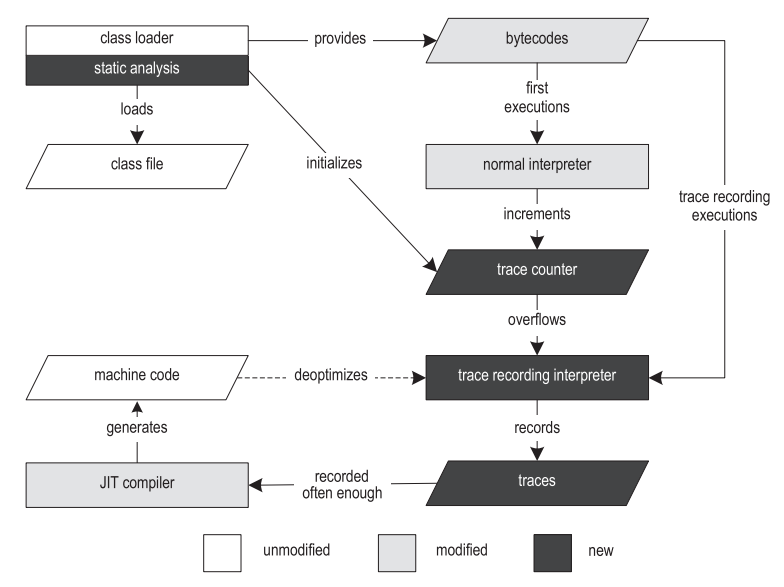
Рисунок 2. Структура трассирующей виртуальной машины
Выполнение начинается с загрузчика классов, который загружает, парсит и верифицирует класс-файлы. Загрузчик классов предоставляет рантайм-структуры данных, такие как Constant Pool и Method Object, ссылающиеся на другие части VM. После загрузки класса выполняется шаг предварительной обработки байткода, он позволяет находить циклы и создает структуры данных, специфичные для процедуры трассирования.
Для записи трейсов мы сдублировали у себя Template Interpreter из HotSpot [13], и инструментировали его. В результате у нас получился и обычный интерпретатор, и интерпретатор с записью трейсов. Обычный интерпретатор исполняет байткод с примерно той же скоростью, что и немодифицированная VM, и используется для первоначальных выполнений. Когда обычный интерпретатор натыкается на якорь трейса, он берет счетчик вызовов этого якоря, и увеличивает его на единицу. Когда счетчик переполняется, якорь помечается как «горячий», и выполнение переключается на интерпретатор с записью трейсов (в дальнейшем – «записывающий интерпретатор»). Текущая реализация поддерживает два разных вида трейсов: трейсы циклов с якорем на заголовке цикла, и трейсы методов с якорем на вхождении метода.
HotSpot предоставляет два разных JIT-компилятора, которые сообща пользуются большей частью инфраструктуры VM. Клиентский компилятор (client compiler) создан для обеспечения высокой производительности запуска и реализует самые базовые оптимизации, тем не менее вполне достаточные для достижения достойной производительности [19]. Во время компиляции, компилятор генерирует высокоуровневое промежуточное предоставление (high level intermediate representation, HIR), приведенное к форме SSA (static single assignment) [7], которое представляет собой граф потока управления (CFG). И в ходе, и после построения HIR, применяются такие оптимизации как свёртка констант, устранение проверок на null и инлайнинг методов. Оптимизированный HIR транслируется в низкоуровневое промежуточное представление (low-level intermediate representation, LIR), которое очень близко к машинному коду, но всё еще, в основном, не зависит от платформы. Затем, LIR используется для распределения регистров линейным сканированием [27] и кодогенерации.
Серверный компилятор (server compiler) выполняет значительно больше оптимизаций, чем клиентский, и производит высокоэффективный код, который может выдавать максимально возможную пиковую производительность [21]. Он предназначен для долгоживущих серверных приложений, таких, что изначальная JIT-компиляция вносит лишь небольшой оверхед по сравнению с общим временем выполнения. Серверный компилятор проходит по следующим фазам компиляции: парсинг, независимые от платформы оптимизации, отбор инструкций, глобальные перемещения кода и планирование, распределение регистров покраской графа, peephole-оптимизация и кодогенерация. Серверный компилятор может применять еще несколько дополнительных оптимизаций, таких как loop-invariant code motion (вытягивание из цикла), разворачивание циклов и escape-анализ.
Наш собственный трассирующий JIT-компилятор основан на клиентском компиляторе из HotSpot. Несмотря на то, что наши техники достаточно обобщенные, чтобы быть применимы в том числе и к серверному компилятору, его сложная структура гораздо хуже подходит для модификаций, которые нужны для трассирующей компиляции, в особенности в контексте исследовательского проекта. Поэтому мы решили использовать в качестве основы именно клиентский компилятор.
Когда трейсы начинают создаваться достаточно часто, наш компилятор сперва сливает их в граф трейсов. Эта структура – гибрид между графом потока управления (CFG) и деревом трейсов [10], и в ней, даже при наличии точек слияния, некоторые пути могут дублироваться, если это дает какое-то преимущество. На этом уровне мы делаем общие и специфичные для трассирования оптимизации, такие как свёртка констант, агрессивный инлайнинг трейсов и явное дублирование потока управления. Сгенерированный при этом машинный код впоследствии напрямую вызывается или интерпретатором, или другими скомпилированными трейсами.
Если предусловие агрессивной оптимизации было нарушено в ходе выполнения, наша система деоптимизируется [18] до записывающего интерпретатора. Деоптимизация вначале сохраняет все значения, которые живы в текущем скомпилированном фрейме, и затем заменяет этот скомпилированный фрейм на один и более интерпретируемых фреймов. Конкретное количество созданных интерпретируемых фреймов зависит от глубины инлайнинга инструкции, выполняемой в текущий момент. Затем интерпретируемые фреймы наполняются сохраненными ранее значениями, и выполнение продолжается в записывающем интерпретаторе.
Кода в права вступает записывающий интерпретатор, вместо использования якоря основного трейса, он может записать частичный трейс, который начинается непосредственно с точки деоптимизации. Чтобы заметить слишком частые деоптимизации скомпилированного кода, счетчик увеличивается каждый раз, когда случается деоптимизация. После достижения порога, скомпилированный машинный код выбрасывается, и запускается новая компиляция, которая использует как изначально записанные трейсы, так и все частичные трейсы. Это позволяет предпринять что-то, что уменьшит частоту деоптимизаций – например, можно увеличить покрытие методов или выключить какие-то конкретные агрессивные оптимизации.
3. Запись трейсов
Наш подход к записи трейсов, ограничивает трейс границами одного метода [14]. В момент, когда мы обнаружили, что якорь стал исполняться достаточно часто, выполнение переключается с обычного на записывающий интерпретатор. Для записи трейса, каждый тред несет на себе стек трейсов, который хранит все трейсы, который сейчас пишутся. Информация об инструкциях, которые могут модифицировать граф управления, хранится в самом верхнем трейсе на стеке, и стек модифицируется соответствующим образом, чтобы поддерживать это правило.
Когда в ходе записи трейса происходит вызов метода, вызов записывается в трейсе источника вызова. Для вызова виртуальных методов, в дополнение к этому записывается еще и принимающий класс. При входе в вызываемый метод, новый трейс метода кладется на стек, и запись продолжается дальше.
Когда вызываемый метод вернулся, соответствующий трейс забирается из стека и сохраняется в репозитории трейсов. Дальше вызывающий и вызываемый трейс связываются с помощью сохранения указателя на вызываемый в вызывающем трейсе, и дальнейшая запись идет уже в вызывающий трейс. Эта связь сохраняет контекстно-зависимую информацию о вызове через границы метода, что приводит к появлению структуры данных, аналогичной динамическому графу вызовов.
Когда уже сохраненный трейс снова записывается, вместо того, чтобы записывать его полностью по новой, происходит простое увеличение счетчика. Мы считаем, что трейсы различаются, если они пошли по разным путям, или если они взывают различные трейсы внутри вызываемых методов. Поэтому связывание трейсов позволяет нам получить точную информацию о вызове для каждого выполненного пути, проходящего по любой части приложения. Для уменьшения количества записанных трейсов до разумного значения, мы не связываем с родительским трейсом трейсы циклов и рекурсивных методов. Сразу после того, как запись трейса будет определенное количество раз выполнена для одного и того же якоря, делается предположение, что все важные трейсы для этого якоря уже записаны, и производится их компиляция в оптимизированный машинный код.
Рисунок 3 показывает пример записи трейса, в котором запись началась для метода addData.
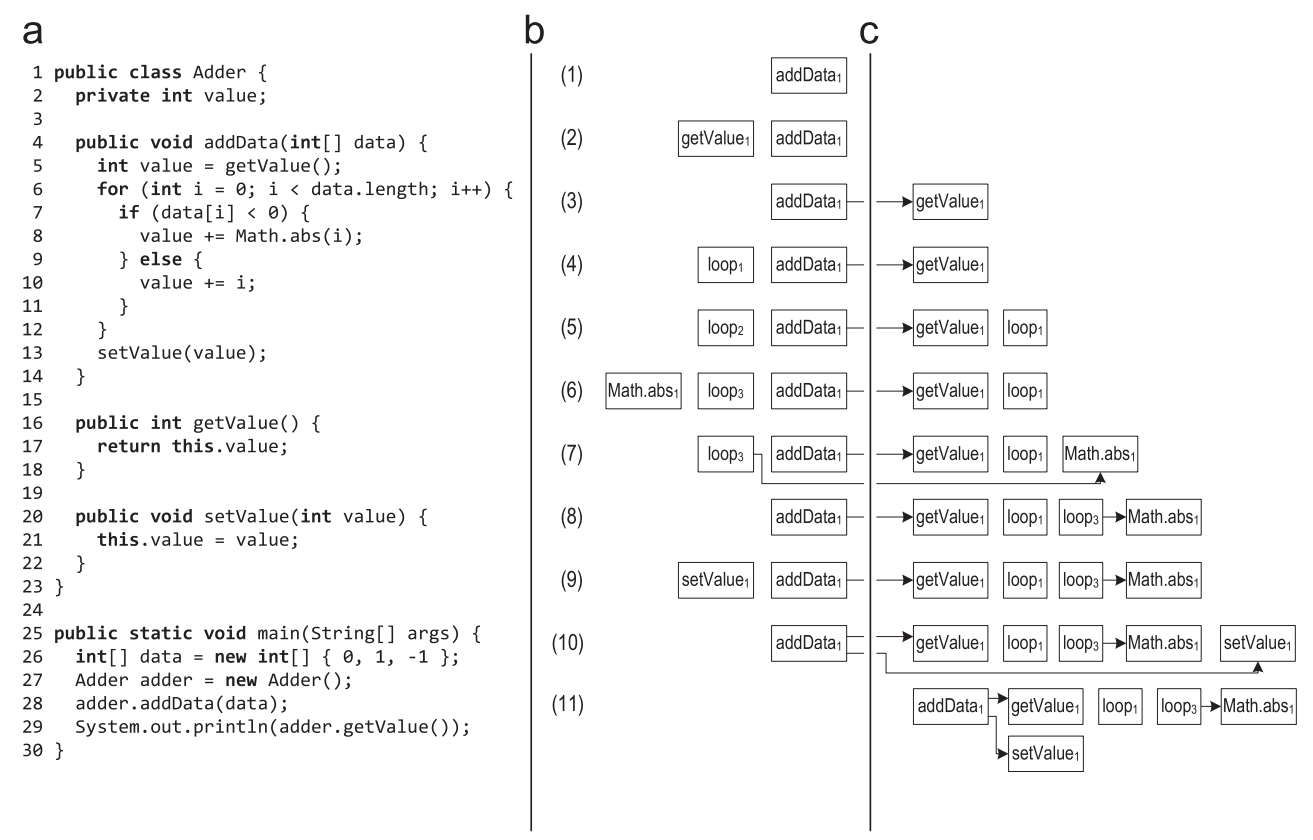
Рисунок 3. Стек трейсов в ходе записи трейса: (a) исходный код (b) стек трейсов ( c ) трейсы, сохраненные в хранилище
- Когда якорь метода addData() помечен как горячий, выполнение переключается на записывающий интерпретатор, и трейс метода кладется на стек трейсов. Метод выполняется с самого начала и до вызова виртуального метода getValue(). При выполнении виртуального вызова, вызывающий класс и принимающий класс сохраняются в вызывающем трейсе.
- При входе в метод getValue(), новый трейс метода кладется на стек трейсов, и запись продолжается в нем.
- Когда getValue() возвращается, соответствующий трейс берется со стека и сохраняется в хранилище трейсов. После этого трейсы связываются с помощью сохранения указателя на трейс getValue() в трейсе getData(). Выполнение и запись продолжаются для addData(), и достигает заголовка цикла.
- Для записи цикла, новый трейс цикла кладется на стек.
- После первой итерации цикла, когда выполнение возвращается на заголовок цикла, трейс этого цикла берется со стека и сохраняется. Для следующей итерации цикла, на стек кладется новый трейс цикла. Вторая итерация выполняется по тому же пути, что и первая, поэтому система понимает, что такой трейс уже был записан, и не сохраняет его по новой, а только увеличивает счетчик в старом сохраненном трейсе.
- Третья итерация цикла идет по другому пути, вызывается метод Math.abs(), и для него на стек кладется новый трейс метода.
- Когда Math.abs() возвращается, соответствующий трейс сохраняется и связывается с вызывающим трейсом.
- После этого выполнение достигает заголовка цикла, и цикл завершается. Трейс цикла берется со стека и сохраняется.
- После выхода из цикла, вызывается виртуальный метод setValue(). Вызывающий и принимающий классы сохраняются в вызывающем трейсе, и новый трейс метода кладется на стек в момент входа в setValue().
- Когда setValue() возвращается, соответствующий трейс берется со стека, сохраняется, и связывается с вызывающим трейсом.
- В конце концов, возвращается и метод addData(), он тоже достается со стека и сохраняется.
- После этого, стек оказывается пуст и выполнение переключается назад на обычный интерпретатор.
В этом примере мы подразумевали, что для вызываемых методов и цикла трейсы не компилировались. Если трейсы для метода getValue() заранее скомпилированы, то вызов getValue() привел бы к выполнению скомпилированного машинного кода вместо интерпретации метода. Записывающий интерпретатор не смог бы положить новый трейс метода на стек, и не смогу бы записывать поток управления для вызываемых методов. В этом случае наш подход к записи трейса не смог бы обеспечить сохранение конкретной информации о потоке управления при пересечении границ методов. Можно было бы не вызывать скомпилированный код, и вместо этого хотя бы один раз форсировать выполнение этого кода в записывающем интерпретаторе, получив всю необходимую информацию. Однако это радикально понизило бы производительность запуска, потому что приложение интерпретировалось бы существенно дольше.
Для наилучшей производительности записи, все часто исполняемые операции (такие как запись информации о конкретных инструкциях) напрямую реализуются в записывающем интерпретаторе в виде ассемблерных шаблонов. Более сложные операции, такие как сохранение записанных трейсов, реализованы в рантайме интерпретатора, написанном на Си. Наша инфраструктура для записи трейсов также поддерживает и эффективную многопоточность, поэтому любой тред в Java может независимо переключаться между обычным и записывающим интерпретатором. Каждый тред использует thread-local буфер для записи трейса, чтобы достичь наилучшей производительности записи.
В ходе записи, несколько тредов одновременно могут работать над структурами данных, которые хранят в себе записанные трейсы. Мы заметили, что для большинства якорей записывается весьма небольшое количество трейсов, поэтому сохранение нового трейса требуется редко, а вот увеличение счетчика выполнений требуется постоянно. Поэтому мы храним сохраненные трейсы в структурах данных, которые при чтении используют минимальное количество блокировок и атомарных инструкций. Когда системе кажется, что найдет новый трейс, мы блокируем эту структуру данных для других записывающих тредов, и под блокировкой перепроверяем, действительно ли этот трейс является новым, и только после этого добавляем в хранилище. Таким нехитрым методом, для наиболее частого случая мы избегаем синхронизации и атомарных машинных инструкций, что значительно увеличивает производительность записи в многопоточных приложениях.
4. Инлайнинг трейсов
Инлайнинг методов заменяет вызовы методов копиями реального исполняемого кода. Эвристики инлайнинга можно условно разделить на статические и динамические.
Клиентский компилятор HotSpot использует простую статическую эвристику инлайнинга методов, в которой размер метода сравнивается с фиксированным лимитом. Виртуальные методы инлайнятся с использованием статического анализа иерархии классов (class hierarchy analysis, CHA) [8]. Этот анализ определят, был ли метод перекрыт (override) каким-либо из загруженных подклассов, и в этом случае его можно оптимистично заинлайнить. Если потом будет загружен еще один подкласс, который перекрывает оптимистично заинлайненный метод, сгенерированный машинный код выбрасывается. В противоположность этому, динамические эвристики инлайнинга используют информацию из профиля, и на основе нее принимают решение, стоит ли метод инлайнить.
Наш трассирующий JIT-компилятор поддерживает одновременно оба вида эвристик, используя для этого записанную информацию о трейсах. Так же как и при инлайнинге методов, инлайнинг трейсов заменяет вызовы копиями реального исполняемого кода. Это увеличивает область компиляции и может повысить производительность.
4.1. Преимущества инлайнинга трейсов
Инлайнинг трейсов имеет несколько преимуществ перед инлайнингом методов:
- Инлайнинг трейсов обрабатывает только часто выполняемые трейсы, а не методы целиком. Блочные компиляторы пытаются использовать информацию из профиля чтобы избежать компиляции редко используемых частей методов [9,25,26]. Это позволяет достичь похожего на инлайнинг трейсов эффекта, но является всего лишь добавочным второстепенным подходом.
- Записанные трейсы содержат контекстно-зависимую информацию о том, какие части методов используются, и кем именно. Эта информация сохраняется при пересечении границ методов и может использоваться для того, чтобы не инлайнить те части методов, которые в целом используются очень часто, но не нужны прямо сейчас конкретному отправителю.
- Трейсы содержат информацию о получателе виртуального вызова, и в результате связывания трейсов, эта информация также является контекстно-зависимой. Может оказаться, что определенное место вызова зовет только методы, имеющие вполне конкретный тип получателя. Эта информация может быть использована для агрессивного инлайнинга виртуальных методов. Блочные компиляторы также используют информацию из профиля для агрессивного инлайнинга виртуальных вызовов, но в большинстве компиляторов эта информация не является контекстно-зависимой.
4.2. Реализация
Инлайнинг начинается с вычисления максимального размера трейса, который нужно заинлайнить на текущем месте вызова (call site). В основном это зависит от релевантности этому месту вызова (см. часть 5.1). Затем используется эвристика, решающая, стоит ли инлайнить вызываемые трейсы в этом месте вызова. В большой степени, все зависит от размера этих трейсов, потому что слишком больше трейсы приводят к раздуванию кода.
Инлайнинг трейсов похож на инлайнинг методов за исключением того, что трейсы обычно не покрывают весь байткод получателя. Мы берем трейсы, которые нужно заинлайнить, строим из них граф, и заменяем вызовы методов содержимым этого графа. Затем все операции return, расположенные внутри заинлайненного байткода, заменяются прямыми джампами на инструкцию, следующую за инструкцией вызова, а инструкции выбрасывания исключений связываются с обработчиками исключений, находящимися в трейсе отправителя.
Рисунок 4(a) показывает граф потока управления для двух методов. Два трейса, проходящие по этим методам, показаны на рисунке 4(b). После того, как запись трейса стала выполняться достаточно часто, записанные трейсы отправляются на компиляцию. Результирующий граф, получившийся после инлайнинга трейсов (но без явного дублирования графа управления) показан на рисунке 4( c ). Затем граф трейсов компилируется в оптимизированный машинный код. Если один из удаленных блоков в дальнейшем всё-таки должен быть исполнен, скомпилированный код деоптимизуется до интерпретатора.
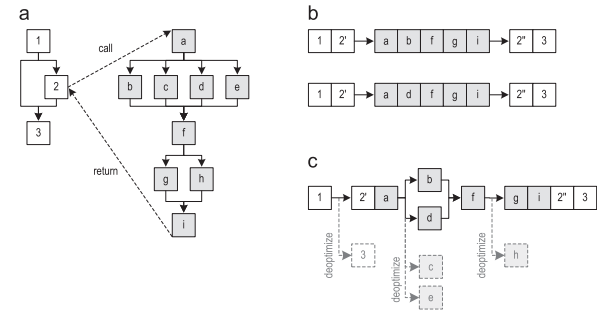
Рисунок 4. Инлайнинг трейса метода: (a) граф потока управления (b) записанные трейсы ( c ) граф трейсов после инлайнинга
Еще интересно, что мы убрали ребро, идущее из блока 1 в блок 3, даже несмотря на тот факт, что граф трейсов не содержит блока 3. Это отличная идея, потому что позволяет избежать слияния потоков управления. Если бы слияние делалось, это ограничило бы возможные компиляторные оптимизации. Удаление неисполняемых ребер приводит к более оптимизированному машинному коду.
В большинстве случаев мы инлайним только те трейсы, которые вызываются текущим отправителем. Тем не менее, если трейсы получателя скомпилированы перед тем, как запись трейса включалась для отправителя, этот отправитель ничего не знает о том, какие же скомпилированные трейсы ему нужны. В этих случаях, мы консервативно считаем, что все трейсы получателя подходят для инлайнинга, кроме тех, для которых мы можем доказать, что их нельзя вызвать текущим отправителем, по причине использования определенных параметров, которые отправитель передает получателю. За этим стоит технология, похожая на удаление мёртвого кода (dead code elimination, DCE) в блочных компиляторах, но она позволяет удалять целые трейсы вместо базовых блоков. Чтобы в дальнейшем уменьшить количество заинлайненных трейсов, мы также отфильтровываем редко исполняющиеся трейсы (см. часть 4.5).
Для вызова виртуальных методов, информация о записанном трейсе комбинируется с CHA из клиентского компилятора HotSpot, что позволяет определить конкретный класс получателя для текущего места вызова. Если CHA определяет один конкретный целевой метод, трейсы вызванного метода инлайнятся таким же способом, как клиентский компилятор инлайнит методы. Если CHA находит несколько возможных целевых методов, мы пытаемся использовать записанные классы отправителя, чтобы агрессивно заинлайнить трейсы методов. Для этого мы добавляем рантайм проверку, которая сравнивает реальный тип получателя с ожидаемым типом и деоптимизирует в интерпретатор, если типы не совпадают. Комбинируя CHA и контекстно-зависимую информацию о трейсе, мы можем инлайнить виртуальные методы чаще, чем большинство блочных компиляторов, создавая рантайм-проверки только когда это действительно необходимо.
В дополнение к инлайнингу трейсов методов, мы стали поддерживать инлайнинг циклических трейсов. Рисунок 5(а) показывает граф трейсов, построенный для трейсов метода, который вызывал циклический трейс. Циклические трейсы еще не заинлайнены, поэтому цикл представлен как черный ящик, который всё еще неизвестен компилятору. На следующем шаге строится отдельный граф трейсов, только для циклических трейсов – рисунок 5(b). Дальше инлайнинг заменяет черный ящик в графе отправителя на граф цикла, и связывает все выходы из цикла с их правильными блоками-продолжениями, используя джамп-инструкции. В этом примере блок b связан с блоком e, и блок c связан с блоком d, что приводит графу трейсов, показанному на рисунке 5( c ).

Рисунок 5. Инлайнинг трейса цикла: (a) граф трейса метода (b) граф трейса цикла ( c ) состояние после инлайнинга цикла
В ходе инлайнинга циклических трейсов, мы считаем, что все трейсы, записанные для конкретного цикла, являются кандидатами на инлайнинг. Это необходимо потому, что циклические трейсы никогда напрямую не связываются с их вызывающим трейсом, и поэтому не доступно никакой контекстно-специфичной информации о вызове. Однако, мы используем информацию о параметрах и локальных переменных, которые входят в этот цикл, и благодаря им удаляем те трейсы, для которых возможно доказать, что они не могут быть вызваны текущим отправителем. Более того, мы также удаляем трейсы, которые не исполняются достаточно часто.
Более сложный случай бывает, когда заинлайненный цикл имеет выход, продолжения которого не существует в графе отправителя. На рисунке 5(a), блок d может исчезнуть, к примеру, потому, что он никогда не записывался. Несмотря на это, оба выхода из цикла могут быть представлены в записанных циклических трейсах, как показано на рисунке 5(b). Один из способов, как это может произойти: циклические трейсы были скомпилированы до того, как началась запись трейса метода. Изначально [15] мы обходили эту проблему, явно добавляя точки деоптимизации на все выходы из циклов, которые нельзя связать с продолжением, и выполнение деоптимизировалось каждый раз, когда цикл завершался по этому пути. Сейчас мы просто удаляем циклические трейсы, которые заканчиваются выходом из цикла, который неизвестен текущему отправителю. Это снижает количество кандидатов на инлайнинг и уменьшает количество сгенерированного машинного кода.
4.3. Зависимость от контекста
Наша записывающая инфраструктура ограничивает размер трейса фиксированной глубиной в 1 метод, поэтому трассирующий компилятор очень сильно полагается на агрессивный инлайнинг трейсов [15]. Механизм записи трейсов сохраняет контекстно-зависимую информацию при переходе границы метода, поэтому каждый отправитель знает, какие части получателя ему следует заинлайнить. Это помогает компилятору избежать инлайнинга тех частей метода, которые в целом исполняются довольно часто, но не релевантны для текущего отправителя. Это уменьшает количество сгенерированного машинного кода и уменьшает количество точек слияния, что в общем позитивно сказывается на пиковой производительности.
Блочные компиляторы тоже используют информацию из профиля для удаления кода, который никогда не выполняется. Однако, информация в их профилях обычно не является контекстно-зависимой, отчего они не могут решить, какие именно части метода нужны какому конкретно отправителю. Контекстно-зависимая информация в профиле, в принципе, может быть записана и для блочного компилятора, но мы верим, что запись трейсов и трассирующий компилятор значительно упрощают этот процесс.
Рисунок 6 показывает метод indexOf() для класса ArrayList из JDK.

Рисунок 6. Метод ArrayList.indexOf()
Первая часть метода обрабатывает редкий случай поиска null, вторая часть ищет список объектов, не являющихся null. Большинству отправителей требуется только вторая часть метода. Однако, если в приложении появится хоть один отправитель, который исполняет первую часть метода, информация в профиле блочного компилятора покажет, что первая часть также была исполнена. Поэтому каждый раз, когда блочный компилятор инлайнит метод indexOf(), он также инлайнит и этот редко исполняемый кусок кода. Мы же имеем контекстно-зависимую информацию, и наш трассирующий компилятор может избежать вышеописанной проблемы, когда отправителю не нужна какая-то часть метода.
Так как инлайнинг более разборчив в том, что он собирается инлайнить, наш трассирующий компилятор может использовать более агрессивную политику инлайнинга, например, он может инлайнить трейсы, проходящие по методам которые по объему слишком большим, чтобы их можно было заинлайнить целиком. Это увеличивает область компиляции без необходимости инлайнить больший объем Java-байткода, чем это делает блочный компилятор. В особенности, для сложных приложений это приводит к более оптимизированному машинному коду, и имеет положительный эффект на пиковую производительность.
Рисунок 7(а) показывает класс LineBuilder, который оборачивает Appendable и предоставляет метод appendLine().
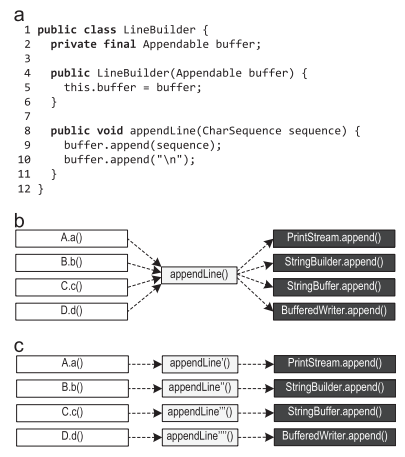
Рисунок 7. Контекстно-зависимая информация: (a) паттерн (b) возможные вызовы метода ( c ) предпочтительный инлайнинг
Если несколько объектов LineBuilder используются для обертывания экземпляров различных классов, таких как PrintStream, StringBuilder, StringBuffer и BufferedWriter, тогда вызовы append() на строках 9 и 10 станут полиморфными вызовами, которые так просто не заинлайнить, как показано на рисунке 7(b).
Если диспетчеризация в appendLine() зависит от места вызова, например, потому что различные объекты LineBuilder используются на различных местах вызова, предпочтителен инлайнинг, изображенный на рисунке 7( c ). Наша контекстно-зависимая информация о трейсе в том числе хранит и получателя виртуальных вызовов. Поэтому наш трассирующий компилятор может делать именно этот предпочтительный инлайнинг с рисунка 7( c ), используя имеющуюся контекстно-зависимую информацию для агрессивного инлайнинга виртуальных вызовов. Если компилятор не записывает в профиль контекстно-зависимую информацию, а просто собирает все обнаруженные типы (такие как PrintStream, StringBuilder, StringBuffer и BufferedReader при buffer.append()), он не найдет достаточно информации чтобы заинлайнить такие виртуальные вызовы.
В предыдущей версии нашего трассирующего компилятора, в тех случаях, когда запись трейсов показывала, что вызываемый метод всегда принадлежит одному и тому же типу получателя, мы использовали только информацию о типах. Такие заинлайненные трейсы охраняются «гардом типа» (type guard), который сравнивает реальный тип получателя с ожидаемым типом, и деоптимизирует до интерпретатора в случае, если типы не совпадают. В этой статье, мы расширили инлайнинг трейсов следующими способами:
- Если с места вызова всегда вызывается один и тот же метод, но он выполняется на различных типах получателя, то ранее было невозможно заинлайнить такой метод. Однако, в реальности данная ситуация происходит довольно часто, например, если абстрактный базовый класс реализует метод, который не перекрывается (override) в подклассе. Мы смогли создать такой вид инлайнинга, используя так называемый «гард метода» (method guard), который обращается к виртуальной таблице методов реального получателя и сравнивает вызываемый метод с ожидаемым методом. Если методы не совпадают, мы деоптимизируемся до интерпретатора.
- Если с места вызова всегда вызывается один и тот же метод, но делает это на получателе интерфейсного типа, мы расширяем «гард типа» до структуры, похожей на switch, так что он может проверять сразу несколько типов получателей. Это дешевле, чем поиск по интерфейсам, и позволяет нам инлайнить вызовы интерфейсных методов в довольно приличном количестве случаев. Если реальный тип получателя не совпадает ни с одним из ожидаемых типов, мы деоптимизируемся до интерпретатора.
- Еще одно улучшение – инлайнинг полиморфных вызовов. На рисунке 8(a) изображен метод, в котором виртуальные вызовы могут вызывать два различных метода. Поскольку эти методы достаточно малы, имеет смысл заинлайнить оба. Это приводит к потоку управления, изображенному на рисунке 8(b), на котором блок 2’ перекидывает/диспетчеризует поток до одного из заинлайненных методов, в зависимости от настоящего типа получателя. Здесь мы тоже используем похожую на switch семантику, так что сразу несколько типов могут перекидывать на один и тот же заинлайненный метод. Если настоящий тип получателя не совпадает ни с одним из ожидаемых типов, мы деоптимизируемся до интерпретатора.
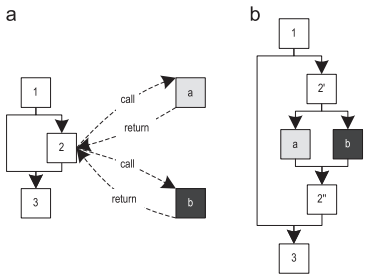
Рисунок 8. Полиморфный инлайнинг: (a) полиморфный вызов (b) полиморфный инлайнинг
Серверный компилятор HotSpot тоже инлайнит полиморфные вызовы, но ограничивает количество вызываемых методов максимум до двух, так как большое их количество легко может привести к раздуванию кода. Наш трассирующий компилятор инлайнит куски методов более избирательно, так как имеет контекстно-зависимую информацию о записанных трейсах. Поэтому мы можем избежать инлайнинга тех кусков метода, которые в целом выполнялись часто, но не нужны текущему отправителю. Более того, записанная информация о типах тоже является контекстно-зависимой, что уменьшает количество кандидатов на инлайнинг. Поэтому наш трассирующий компилятор не имеет лимита на количество заинлайненных методов, а вместо этого ограничивает общее количество всех заинлайненных методов, в зависимости от частоты выполнения конкретного места вызова. Для приложений с высоким количеством полиморфных вызовов, это приводит к значительно лучшему инлайнингу, и, следовательно, более высокой производительности, без проблем с излишним раздуванием кода.
4.4. Нативные методы
Java-код может звать нативные методы, используя Java Native Interface (JNI). Этот механизм в основном используется для реализации платформо-специфичных функций, которые не могут быть выражены в Java другим способом. Так как для этих методов не выполняется никакого Java-кода, запись их трейсов невозможна.
HotSpot использует интринсики компилятора для наиболее важных платформо-специфичных методов, поэтому JIT-компилятор может инлайнить такие методы. Если наш трассирующий JIT-компилятор компилирует граф трейсов, который содержит вызов нативного метода, реализованного как интринсика компилятора, мы делаем в точности тот же самый инлайнинг, что и блочный компилятор. Тем не менее, наш трассирующий компилятор всё еще имеет одно преимущество: трейсы меньше, чем методы, поэтому наш трассирующий компилятор может инлайнить трейсы более агрессивно, чем блочный компилятор инлайнит Java-методы. Это расширяет область компиляции, и код, вызывающий нативный метод, имеет точное знание о параметрах, которые в этот нативный метод уходят. JIT-компилятор может использовать эту информацию для агрессивной оптимизации заинлайненных компиляторных интринсиков.
Рисунок 9(a) показывает псевдокод для реализации нативного метода System.arraycopy(), который используется для копирования примитивных массивов.

Рисунок 9. Псевдокод метода System.arraycopy() для копирования примитивных массивов: (a) неоптимизированный код (b) оптимизированный код
В зависимости от того, какая информация о параметрах, переданных в System.arraycopy(), известна компилятору, он может оптимизировать интринсику. Рисунок 9(b) показывает оптимизированную версию метода, где компилятор может оптимально эксплуатировать значения параметров. Необходимая информация о параметрах, для этого конкретного примера становится доступна в том месте, когда исходный массив и целевой массив расположены в одной и той же области компиляции, в которой инлайнится System.arraycopy(). То есть, увеличение области компиляции может помочь нам увеличить производительность заинлайненных компиляторных интринсиков.
4.5 Фильтрация трейсов
Когда трейс уже записан, велики шансы, что этот трейс довольно важный, и будет часто исполняться. Тем не менее, иногда бывает и так, что записанные трейсы выполняются редко. Выбрасывая эти трейсы, мы можем гарантировать, что скомпилированными окажутся только важные пути. Рисунок 10(а) показывает граф трейсов после слияния всех записанных трейсов. Ребра графа аннотированы частотой выполнения.
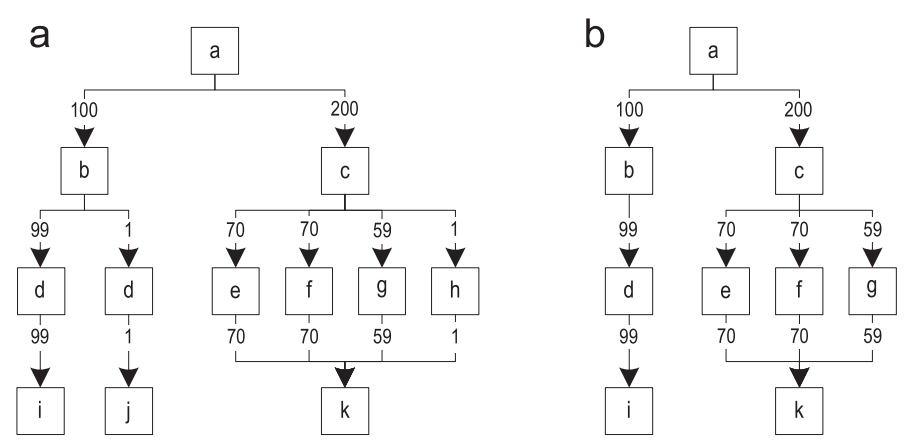
Рисунок 10. Фильтрация редко выполняемых трейсов: (a) оригинальный граф трейсов (b) граф трейсов после фильтрации
Для каждого блока мы определяем наиболее часто исполняемое исходящее ребро, и сравниваем эту частоту со всеми остальными исходящими ребрами того же блока. Затем, удаляем ребра с частотой, которая в сто раз меньше. После обработки всех блоков, удаляем из графа более не доступные блоки. Рисунок 10(b) показывает результирующий граф после фильтрации.
Записанная информация о трейсах сохраняет поведение программы, которое наблюдалось только в ходе конкретного временного окна. На более поздних этапах выполнения, редко выполнявшиеся (и поэтому удалённые) пути могут снова стать важными, т.к. поведение программы со временем меняется. Это приводит к частым деоптимизациям, поскольку начинают выполняться не скомпилированные заранее пути. Если обнаружена излишне частая деоптимизация, старый скомпилированный машинный код выбрасывается, и запускается новая компиляция. Эта компиляция избегает фильтрации трейсов для тех случаев, которые привели к частой деоптимизации.
У фильтрации трейсов есть несколько трудных случаев, о которых стоит позаботиться отдельно:
- Для большинства циклов, тело цикла выполняется значительно более часто, чем выход из этого цикла (см. рисунок 5( c )). Поэтому частота выходов из цикла должна сравниваться с частотой входа в цикл, но никак не с частотой предыдущего бранча. В противном случае, ребра выходов из цикла будут выброшены, и при выходе из цикла потребуется деоптимизация. Это увеличит частоту деоптимизаций и уменьшит область компиляции.
- Агрессивный инлайнинг трейсов может заинлайнить редко выполняемые трейсы. Эти трейсы не обязательно отражают обычное поведение, поэтому фильтрация может выбросить и важные трейсы тоже. Это опять приведет к частым деоптимизациям, поэтому фильтрации стоит избегать для методов с недостаточно большим количеством записей трейсов, и для циклов.
5. Эвристики инлайнинга трейсов
Все эвристики инлайнинга, представленные в этой части, похожи в том, что они вначале вычисляют релевантность места вызова, и затем используют значение релевантности для вычисления размера, который нужно инлайнить. Конкретное решение о необходимости инлайнинга – это простое сравнение максимального размера с реальным размером трейсов, которые мы решили инлайнить. Для оценки мы использовали сочетание нескольких эвристик с различными алгоритмами вычисления релевантности.
5.1. Релевантность места вызова (call site)
Релевантность места вызова определяется релевантностью блока в графе трейсов, в котором это место вызова расположено. Мы проверили три разных алгоритма вычисления релевантности и проиллюстрировали их поведение на двух примерах графов трейсов, A и B, показанных на рисунке 11.
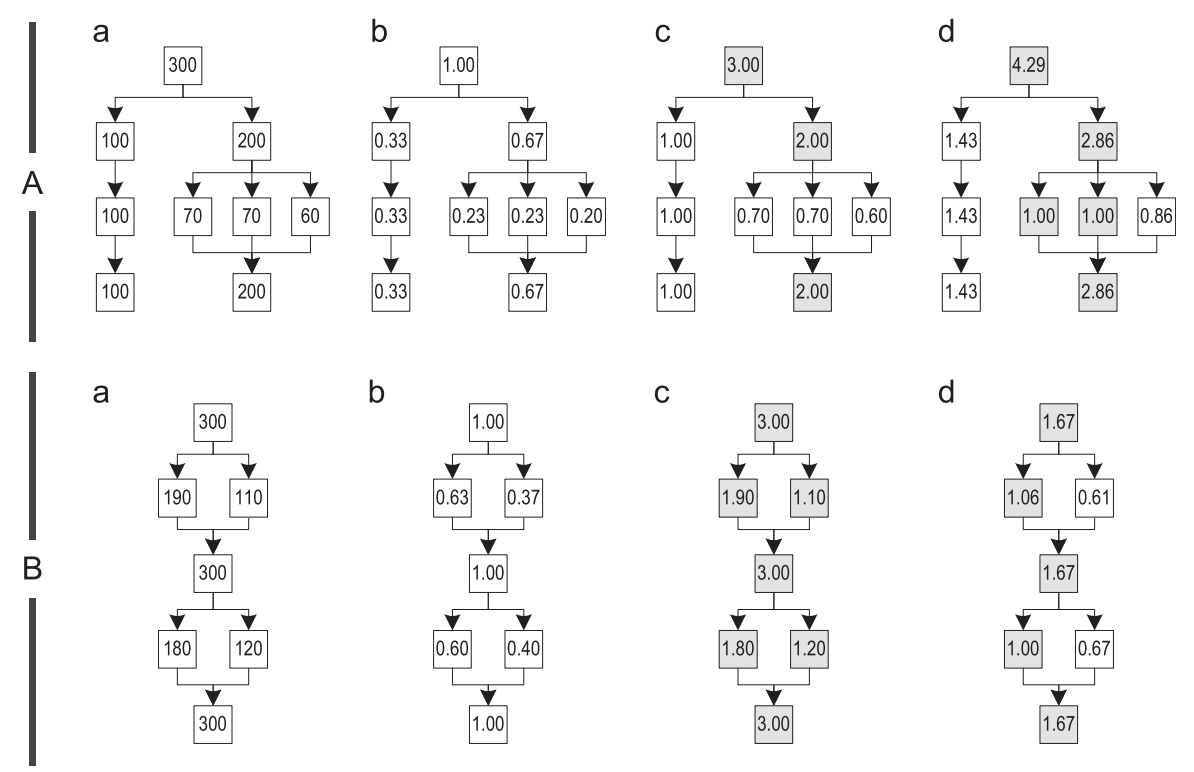
Рисунок 11. Различные алгоритмы вычисления релевантности: (a) подсчет количества выполнений (b) simple ( c ) most frequent trace (d) path-based
Пример А построен из четырех разных трейсов, которые вряд ли имеют какие-то одинаковые блоки. Пример B представляет граф, построенный из четырех трейсов, но каждый блок в них является общим хотя бы для еще одного трейса.
Для вычисления релевантности блоков, вначале мы определяем, как часто записанные трейсы выполняют каждый из блоков. Рисунок 11(а) показывает графы, в которых каждый блок аннотирован соответствующей частотой выполнений. Затем, мы вычисляем релевантность каждого блока делением его частоты выполнений на некое изначальное значение. В зависимости от этого значения, релевантность масштабируется по-разному. Используется один из следующих алгоритмов для выбора изначального значения:
- Simple: Простейший способ вычисления релевантности блока – это поделить частоту выполнений на общую частоту выполнения всех трейсов, объединенных в один общий граф. Результирующее значение находится в диапазоне ]0,1], а высокая релевантность выставляется для тех блоков, в которых инлайнинг хорошо влияет на большинстве выполнений, как показано на рисунке 11(b).
- Most frequent trace: Другой способ заключается в том, чтобы поделить частоту выполнения блока на частоту наиболее часто исполняемого трейса, когда-либо вливавшегося в граф. Поскольку трейсы слиты, все блоки, которые принадлежат сразу нескольким трейсам, получают большее число исполнений, чем они имели до слияния. Таким образом, эта метрика устанавливает высокую релевантность для тех мест вызова, которые относятся к этим общим блокам, и ставит в соответствие значение в промежутке ]0,1] для мест вызова, которые содержатся только принадлежат лишь одному трейсу. На рисунке 11( c ), закрашенные блоки относятся сразу к нескольким графам, и иногда так получается, что каждый блок графе может иметь релевантность больше 1, как в примере B.
- Path-based: Наш третий подход вычисляет варианты наиболее часто выполняющихся путей по графу трейсов. Начинаем с корневого блока графа и определяем наиболее часто выполняемое продолжение. Затем мы отмечаем этот блок как «посещенный» и продолжаем работать с этим блоком рекурсивно, до тех пор по либо не найдем блок без продолжений, либо не вернемся к заголовку цикла. Все посещенные блоки согласно этому алгоритму раскрашиваются (см. рисунок 11(d)). Затем мы используем наименьшую частоту выполнений из всех посещенных блоков, чтобы вычислить релевантность всех остальных блоков в графе. Это дает нам некое преимущество в том, что важные места вызова, например, те, которые находятся на этом пути, и на часто выполняемых точках слияния и разделения, имеют значения в промежутке [1; ?], в то время как менее важные вызовы имеют значение в промежутке ]0,1[.
5.2. Конфигурации
Мы начали с 15 эвристик инлайнинга, как статических, так и динамических. Для каждой эвристики мы выполнили систематический поиск хороших параметров. В ходе этой оценки, все динамические эвристики обогнали по производительности все статические, поэтому в этой статье мы не будем приводить детальные результаты для статических эвристик. Более того, мы опишем только те варианты динамических эвристик, которые показали хорошую пиковую производительность или небольшое количество сгенерированного машинного кода.
- Minimum code: Эта эвристика устанавливает размер инлайнинга в 35 байткодов, и этот размер изменяется в зависимости от релевантности месту вызова. Релевантность ниже 1 уменьшает размер инлайнинга, а релевантность больше 1 – увеличивает. Если использовать эту эвристику вместе с алгоритмом вычисления релевантности «path-based», получается довольно неплохая пиковая производительность одновременно с небольшим количеством машинного кода. Мы попробовали комбинировать её с алгоритмом релевантности «simple», однако, это оказало значительный негативный эффект на пиковую производительность, хотя и сгенерировало немного меньше машинного кода. Поэтому мы опускаем детализированные результаты по второму варианту.
- Balanced: Эта эвристика увеличивает размер инлайнинга до 40 байткодов, и этот размер изменяется, основываясь на релевантности месту вызова. Релевантность ниже 1 не изменяет размер инлайнинга, а релевантность больше 1 увеличивает размер. Так что, уменьшение предварительно заданного размера явным образом запрещено, что делает более вероятным инлайнинг важных мест вызова. Мы использовали эту эвристику с «path-based» алгоритмом релевантности, что привело к достижению баланса между пиковой производительностью и количеством сгенерированного машинного кода.
- Performance: Эта эвристика использует большой размер инлайнинга – 150 байткодов, и уменьшает его для тех мест вызова, релевантность которых меньше 1. Увеличение размера инлайнинга дальше предопределенного значения явным образом запрещено. Для вычисления релевантности этих мест вызова, мы снова используем алгоритм «path-based». Эта эвристика оптимизирована для получения максимальной пиковой производительности, тем не менее, удерживая количество сгенерированного машинного кода в приемлемых пределах.
- Greedy: Так же как в предыдущей конфигурации, эта эвристика использует очень большой размер инлайнинга – 250 байткодов, и уменьшает его только для мест вызова с релевантностью ниже 1. Чтобы гарантировать, что вызванные трейсы действительно инлайнятся жадным образом, мы скомбинировали эту эвристику с алгоритмом вычисления релевантности «most frequent trace». Вследствие наличия предопределенного максимального значения, даже эта эвристика избегает инлайнинга слишком больших трейсов. Эта эвристика хорошо показывает, какие из бенчмарков, описанных в части 6, могут использовать преимущества очень агрессивного инлайнинга трейсов. Мы экспериментировали и с более агрессивными эвристиками инлайнинга, но они не смогли еще сильнее улучшить пиковую производительность, при этом генерировуя существенно больше машинного кода.
Так же, как и в блочных компиляторах, все наши эвристики проверяют, что небольшие методы, такие как геттеры-сеттеры, инлайнятся вообще всегда. Это имеет смысл, поскольку вызов небольших трейсов может потребовать больше машинного кода, чем собственно инлайнинг. Другая стратегия, которая используется в серверном компиляторе HotSpot, заключается в том, что нужно избегать инлайнинга методов, если получатель уже отдельно откомпилирован, или если компиляция приведет к большому количеству сгенерированного машинного кода. Тут подразумевается, что достаточно широкая область компиляции уже имеет достаточно информации для хороших компиляторных оптимизаций, так что увеличение области компиляции далее определенных границ не целесообразно. Мы используем эту технику и для всех наших инлайнинговых эвристик, потому что это уменьшает количество сгенерированного машинного кода без измеримого удара по производительности.
Для уменьшения вероятности инлайнинга вложенных трейсов, мы проверяем, что заинлайненные трейсы наследуют релевантность от родительского места вызова. Для этого мы умножаем релевантность каждого вызываемого блока на релевантность вызывающего блока. Однако, мы ограничиваем максимальную наследуемую релевантность до 1, так как в противном случае релевантность может подняться вместе с уровнем инлайнинга. Опять же, наследование релевантности уменьшает количество сгенерированного машинного кода без измеримого негативного влияния на производительность, поэтому оно используется всеми нашими эвристиками.
6. Тестирование и оценка
Мы реализовали наш трассирующий JIT-компилятор для архитектуры IA-32 для HotSpot VM, используя early access версию b12 находящегося в разработке JDK8 [20] (дело происходит в 2013 году – прим. переводчика). Для тестирования эвристик инлайнинга, мы выбрали SPECjbb2005 [23], SPECjvm2008 [24], и DaCapo 9.12 Bach [3], поскольку они покрывают большое количество различных проверок. Стенд, на котором запускались бенчмарки, имеет следующую конфигурацию: процессор Intel Core-i5 с 4 ядрами на частоте 2.66 GHz, 4n256 kb L2 кэша, 8 MB разделяемого L3 кэша, 8 GB основной памяти, и Windows 7 Professional вместо операционной системы.
Результаты представлены относительно немодифицированного блочного клиентского компилятора HotSpot, который принят за 100%. Для трассирующего JIT-компилятора, количество сгенерированного машинного кода также включает данные, специфичные для трассирующей компиляции, такие как дополнительная информация о деоптимизациях, необходимых для проваливания в интерпретатор. Каждый из указанных выше бенчмарков выполнялся 10 раз – в результатах указано среднее от этих результатов с 95% доверительным интервалом.
6.1. SPECjbb2005
Этот бенчмарк симулирует клиент-серверное бизнес-приложение, в котором все операции производятся на in-memory базе данных, которая разделена на так называемые склады (warehouses). Бенчмарк исполняется с различным количеством складов, и каждый склад обрабатывается отдельным тредом. Мы использовали стенд с 4 ядрами, так что официальная пропускная способность SPECjbb2005, измеряющаяся в бизнес-операциях в секунду (business operations per second, bops), и определяется как среднее геометрическое от производительности складов 4-8. Для всех измерений был использован хип размером 1200MB.
Рисунок 12 показывает пиковую производительность, сгенерированный машинный код и время компиляции для SPECjbb2005. Все наши варианты трассирующего компилятора оказались значительно быстрее клиентского компилятора в смысле пиковой скорости. Более агрессивный инлайнинг трейсов привел к большей пиковой производительности, но это привело и к увеличению количества сгенерированного машинного кода и заняло больше времени на компиляцию, так как при этом получились блоки компиляции очень большего размера. Пиковая производительность SPECjbb2005 явно улучшается от конфигурации «performance» из-за повышенной агрессивности инлайнинга трейсов. Конфигурация «greedy» подняла пиковую производительность, но очень незначительно, сгенерировав сильно больше машинного кода. В терминах времени компиляции и количества сгенерированного машинного кода, конфигурация «minimum code» оказалась особо эффективной, одновременно предоставляя достойную пиковую производительность.
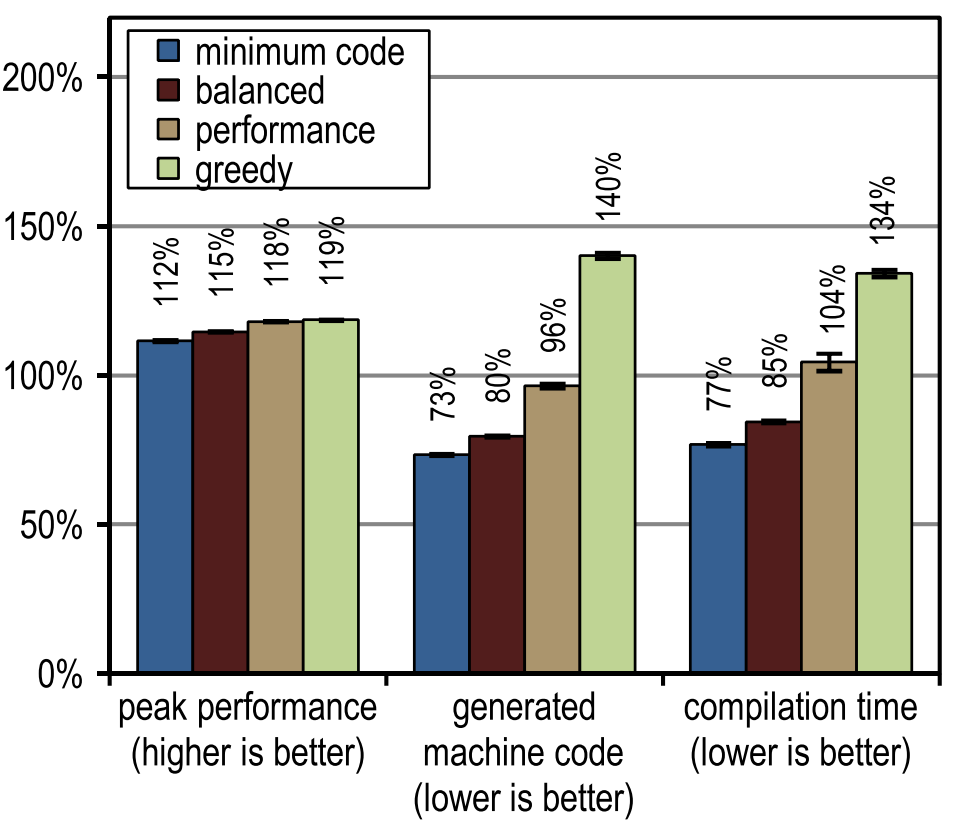
Рисунок 12. Результаты SPECjbb2005
Рисунок 13 отражает пиковую производительность SPECjbb2005 для различного количества складов и разных эвристик инлайнинга. Максимальная пиковая производительность достигнута на 4 складах, так как каждый склад обрабатывается отдельным тредом, а наш стенд имеет как раз 4 ядра. Рисунок показывает, что наша конфигурация обгоняет блочный клиентский компилятор вне зависимости от количества складов.
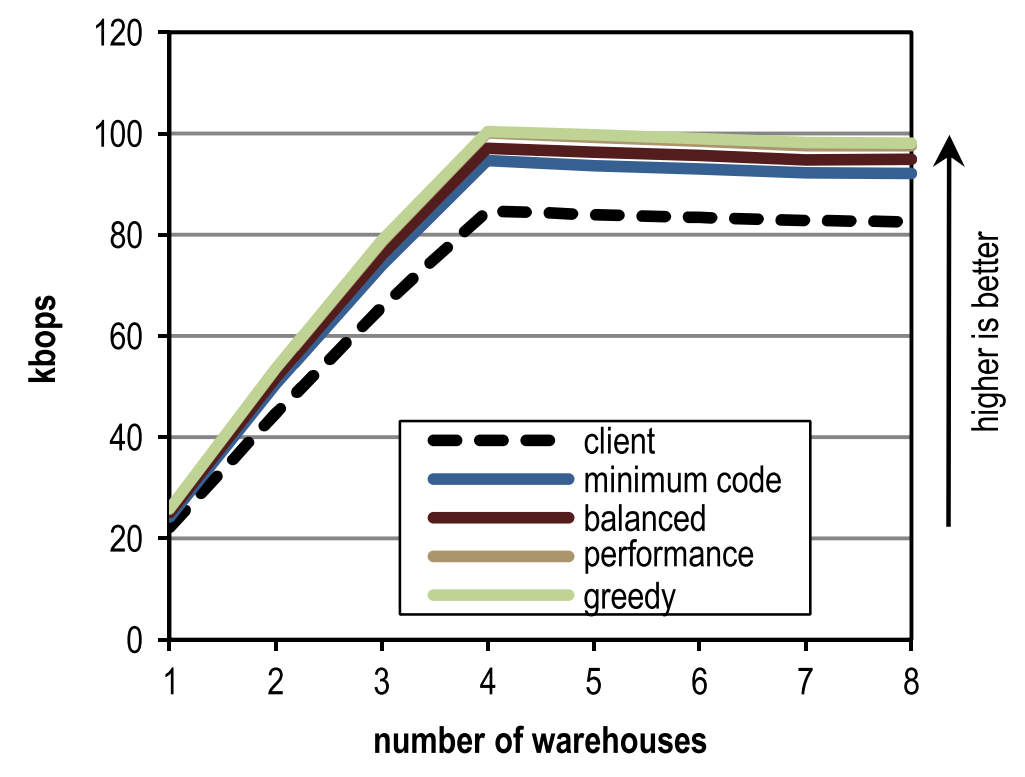
Рисунок 13. Пиковая производительность для различного числа складов в SPECjbb2005
6.2. SPECjvm2008
SPECjvm2008 состоит из 9 категорий тестов, которые измеряют пиковую производительность. Сразу за индивидуальными результатами тестов приведено геометрическое среднее всех результатов. Для всех тестов использовался хип размером 1024 MB.
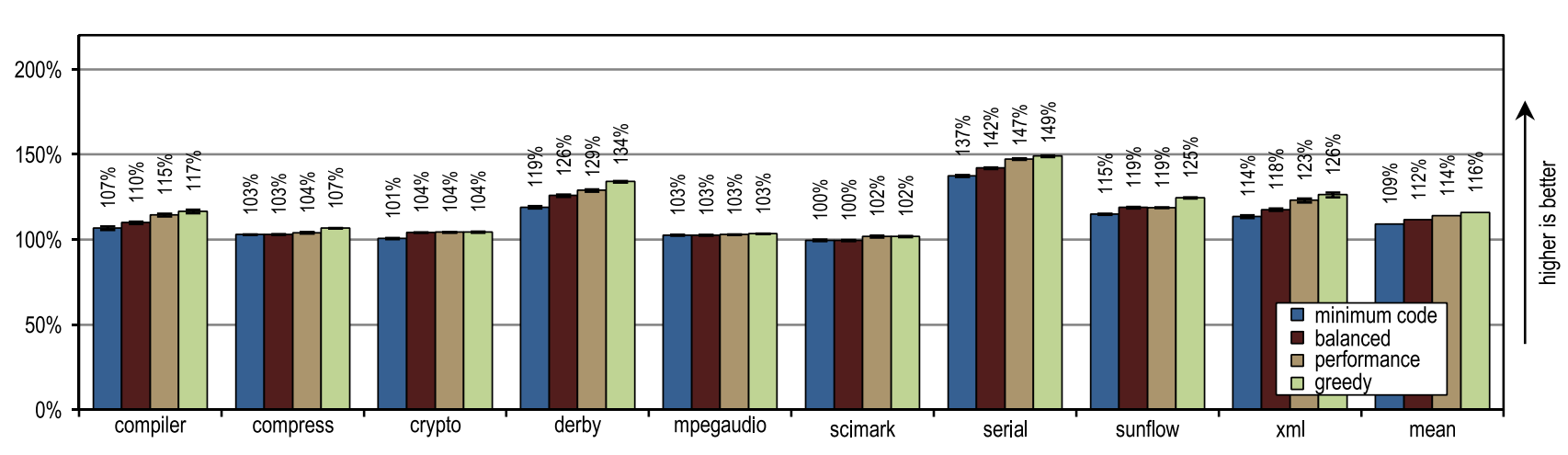
Рисунок 14. Пиковая производительность SPECjvm2008
Рисунок 14 показывает, что все наши конфигурации обогнали блочный клиентский компилятор HotSpot. Эти конфигурации показали максимальное ускорение на тестах derby и serial. На них инлайнинг трейсов позволил достичь большей области компиляции, чем инлайнинг методов, используемый в клиентском компиляторе HotSpot. Очень агрессивная политика инлайнинга трейсов, такая как в конфигурации «greedy», не привела к увеличению пиковой производительности, особенно для бенчмарков derby и sunflow. Причем, агрессивный инлайнинг трейсов увеличил и количество сгенерированного машинного кода, и время JIT-компиляции (см. рисукнки 15 и 16).
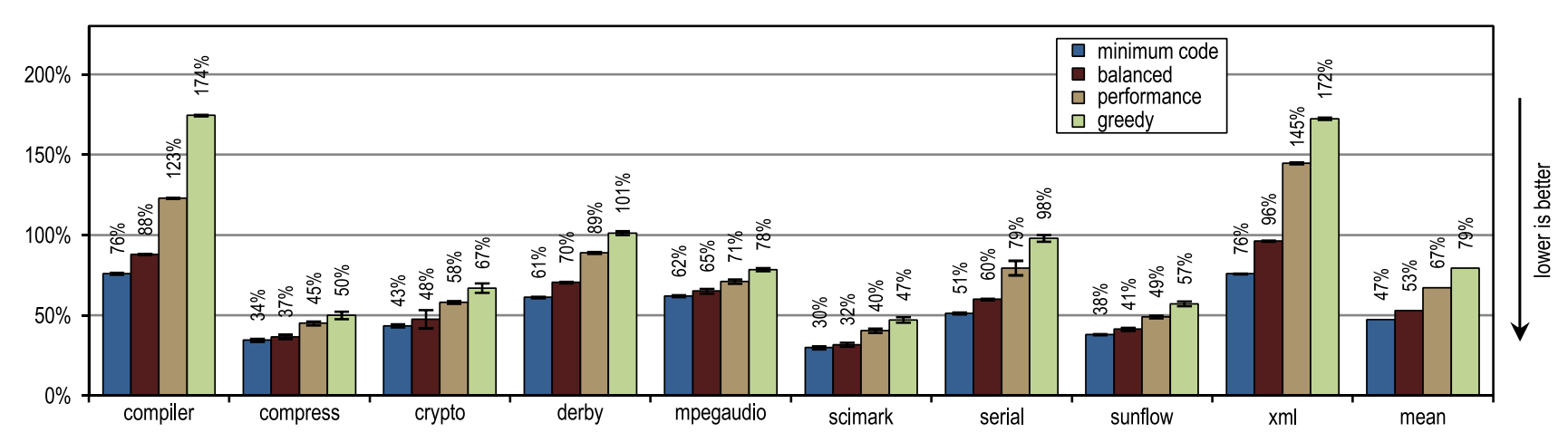
Рисунок 15. Количество сгенерированного машинного кода в SPECjvm2008
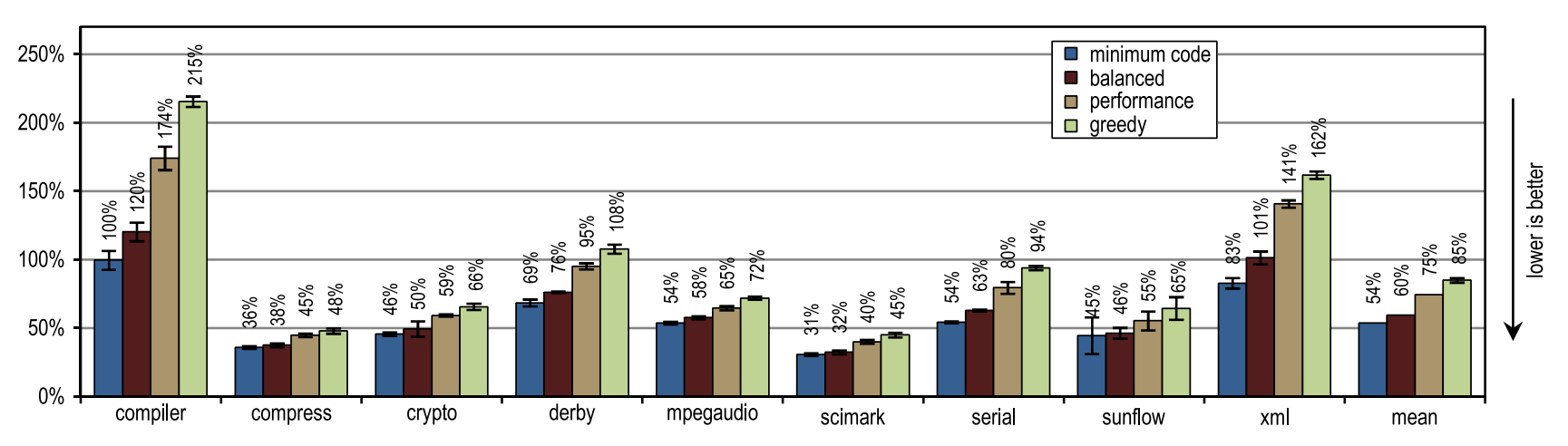
Рисунок 16. Время компиляции в SPECjvm2008
Небольшие тесты с интенсивным использованием циклов crypto, mpegaudio и scimark показали почти не увеличившуюся пиковую производительность, поскольку блочный клиентский компилятор HotSpot тоже смог заинлайнить все вызовы в критичных для производительности циклах. Вследствие небольшого размера этих тестов, наш трассирующий компилятор смог достичь лишь сравнимой по размеру области компиляции. Однако, наш трассирующий компилятор заинлайнил трейсы вместо всего содержимого методов, что привело к созданию значительно меньшего количества сгенерированного машинного кода и уменьшило время компиляции (см. рисунки 15 и 16).
Рисунок 15 показывает, что количество сгенерированного машинного кода зависит от размера инлайнинга, так что можно внезапно сгенерировать слишком много кода. Тем не менее, небольшие и интенсивно использующие циклы бенчмарки не показывают излишнего разрастания кода, даже когда используются наши наиболее агрессивные эвристики инлайнинга. На таких бенчмарках эвристики инлайнинга должны быть очень консервативны, и никогда не должны действовать излишне агрессивно.
6.3. DaCapo
DaCapo 9.12 Bach состоит из 14 приложений, написанных на Java. Используя размер данных по умолчанию, и размер хипа 1024 MB, каждый тест выполнялся в течение 20 итераций, поэтому время выполнения сходится. Мы показываем только наиболее быстрый запуск для каждого из тестов, и геометрическое среднее всех результатов. Для всех измерений использовался размер хипа 1024 MB.
Рисунок 17 иллюстрирует пиковую производительность DaCapo 9.12 Bach, а рисунок 18 показывает количество сгенерированного машинного кода. Эвристика инлайнинга «greedy» показала наилучшую пиковую производительность, но при этом сгенерировала больше машинного кода, чем немодифицированный клиентский компилятор HotSpot. В особенности, от использования «greedy» выиграли luindex, pmd и sunflow, поскольку он предоставляет максимальный размер инлайнинга. Однако, на некоторых тестах эта эвристика настолько агрессивна, что излишнее количество машинного кода генерируется без существенных изменений в пиковой производительности.
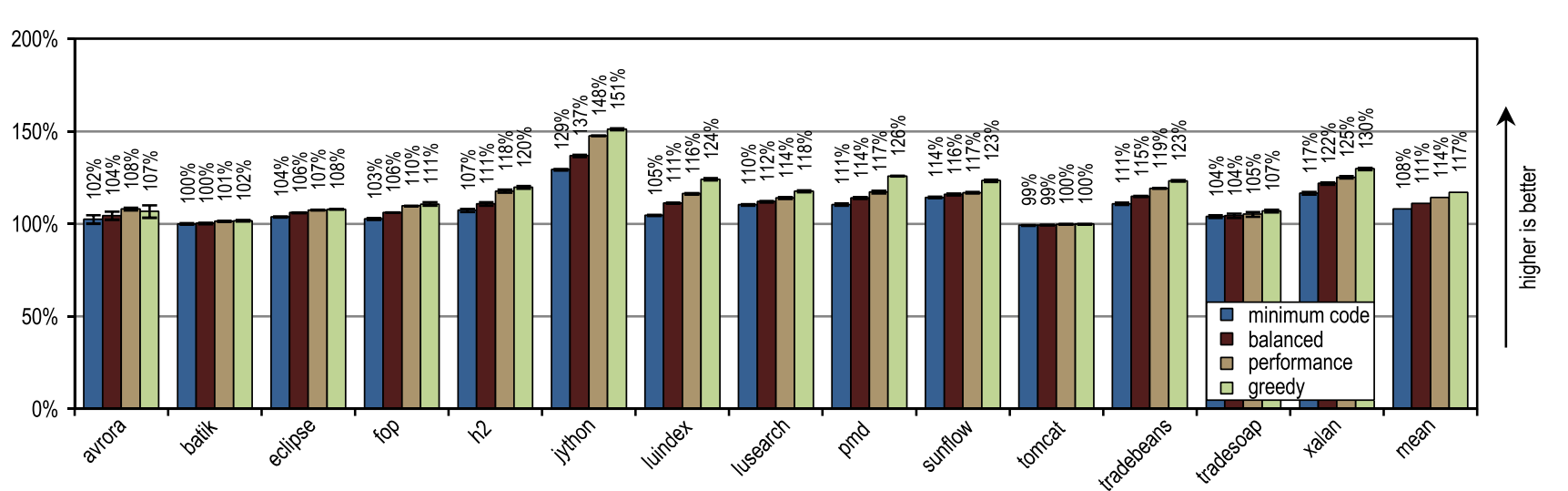
Рисунок 17. Пиковая производительность в DaCapo 9.12 Bach
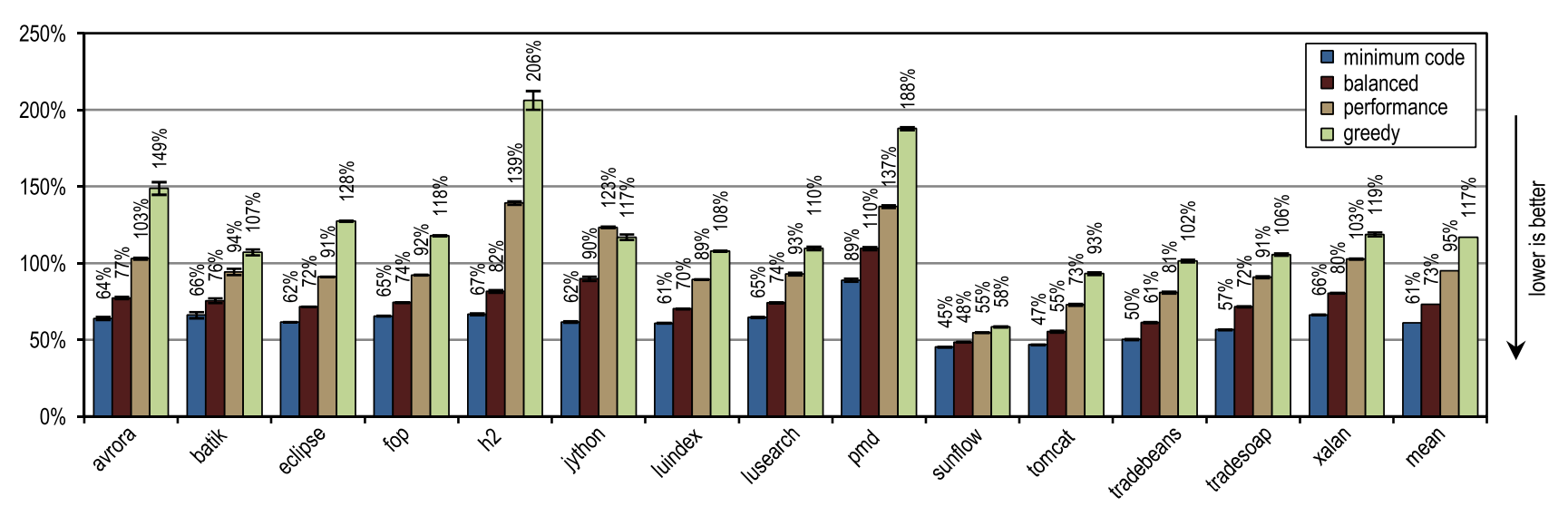
Рисунок 18. Количество сгенерированного машинного кода в DaCapo 9.12 Bach
Наши конфигурации получили наибольшее преимущество на тесте jython, который делает огромное количество виртуальных вызовов. Наш трассирующий компилятор использует записанную информацию о трейсе для агрессивного инлайнинга виртуальных методов. Здесь он получил увеличенную область компиляции, что привело к высокой пиковой производительности.
В среднем, все эвристики инлайнинга кроме «greedy», сгенерировали меньше машинного кода, чем блочный клиентский компилятор HotSpot, вместе с тем показывая более высокую среднюю пиковую производительность. Одна из статических эвристик, которая сравнивала размер трейсов с фиксированным максимальным значением, достигла почти той же пиковой производительности, что и конфигурация «minimum code», но сгенерировала больше машинного кода. Этот результат, весьма хороший для статической эвристики, был достигнут по той причине, что скомпилированные трейсы содержали только часто использованные пути, по определению. А ведь для методов без большого потока достаточно просто сравнить размер трейса с фиксированным пороговым значением. До тех пор, пока максимальный размер инлайнинга продолжает быть низким, эта статическая эвристика будет показывать достойные результаты, но как только максимальный размер инлайнинга увеличится, будет сгенерировано огромное количество машинного кода, без какого-то позитивного влияния на производительность.
В терминах времени, необходимого на JIT-компиляцию, рисунок 19 показывает, что наш трассирующий компилятор настолько высоко эффективен, что даже наиболее агрессивная конфигурация «greedy» в среднем требует лишь такого же времени компиляции, какое требуется блочному клиентскому компилятору HotSpot.
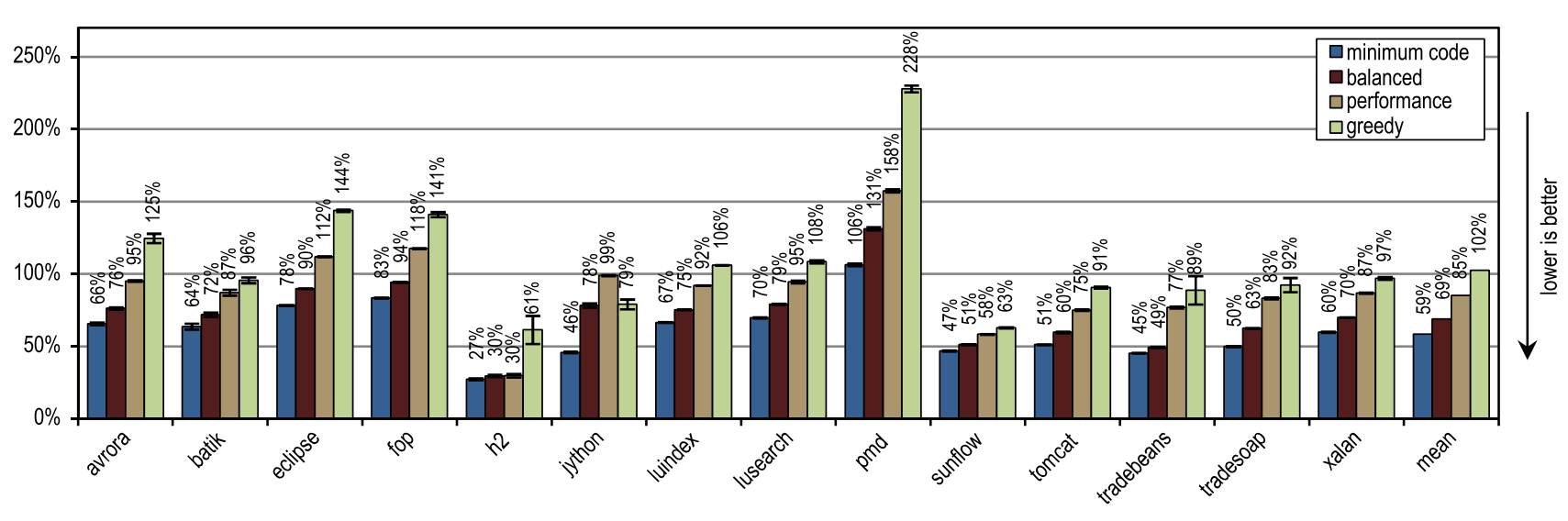
Рисунок 19. Время компиляции в DaCapo 9.12 Bach
6.4. Высокоуровневые оптимизации
Так же, как инлайнинг методов, инлайнинг трейсов – это оптимизация, которая производит положительное влияние на другие компиляторные оптимизации, поскольку увеличивает область компиляции. Рисунок 20 сравнивает вклад в пиковую производительность различных высокоуровневых оптимизаций, которые используются как в блочном клиентском компиляторе HotSpot, так и в нашем трассирующем компиляторе. Оптимизации, отмеченные как 1 являются локальными оптимизациями, которые применяются непосредственно в ходе парсинга байткода, а оптимизации, отмеченные как 2 – это глобальные оптимизации, которые выполняются в отдельную фазу после построения графа.
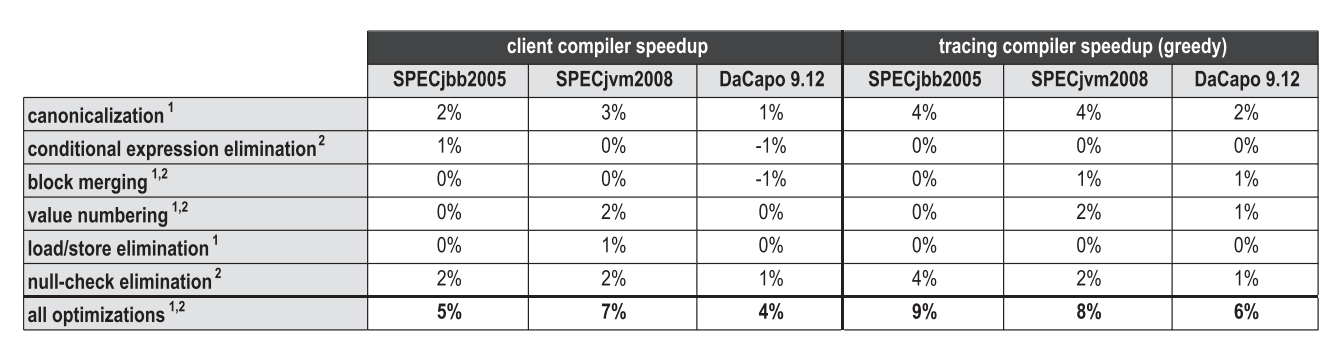
Рисунок 20. Влияние высокоуровневых оптимизаций на пиковую производительность
В целом, агрессивный инлайнинг трейсов увеличивает область компиляции, что позитивно сказывается на многих оптимизациях. Однако, в зависимости от бенчмарков и конкретных оптимизаций, при этом раскрываются совершенно разные стороны вопроса. Для SPECjbb2005, наш инлайнинг трейсов особенно увеличил эффективность теста canonicalization, а также при тестировании выполнения простых оптимизаций, таких как свёртка констант или удаление мёртвого кода. А вот SPECjvm2008 содержал уже слишком много маленьких и интенсивно использующих циклы тестов, в которых наш трассирующий компилятор не смог достичь значительно большей области компиляции. Поэтому, вряд ли высокоуровневые оптимизации получили там хоть какое-то преимущество. На DaCapo 9.12 Bach, производительность была размазана тонким слоем по всем перечисленным оптимизациям.
6.5. Серверный компилятор
HotSpot содержит два различных JIT-компилятора, которые вместе переиспользуют большую часть инфраструктуры виртуальной машины. Наш трассирующий компилятор построен на клиентском компиляторе (client compiler), который создан для наилучшего времени старта приложения, и реализует лишь самые базовые оптимизации, тем не менее выдавая достойную пиковую производительность. Серверный компилятор (server compiler) создан для долгоживущих серверных приложений, и выполняет значительно больше оптимизаций, приводящих к получению высокоэффективного кода. Серверный компилятор может применять еще несколько дополнительных оптимизаций, таких как удаление проверок границ массива, loop-invariant code motion (вытягивание из цикла), разворачивание циклов и escape-анализ. Поэтому сгенерированный им код отличается лучшей пиковой производительностью, но компилируется дольше в 6-31 раз (в среднем 13) на бенчмарках SPECjbb2005, SPECjvm2008 и DaCapo 9.12 Bach. Сервер выполняет в основном долгоживущие приложения, так что долгая компиляция вносит лишь небольшой оверхед по сравнению с общим временем выполнения.
Мы сравнили наилучшую пиковую производительность конфигурации «greedy» с серверным компилятором HotSpot, и результаты показаны на рисунке 21.
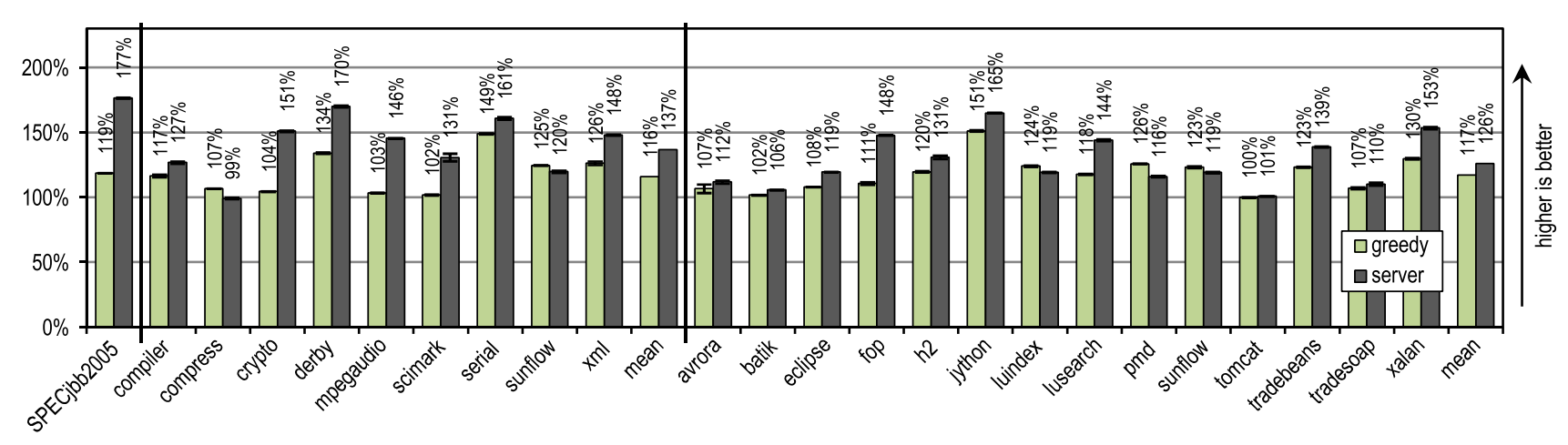
Рисунок 21. Пиковая производительность в SPECjbb2005, SPECjvm2008 и DaCapo 9.12 Bach
SPECjbb2005 получил сильное преимущество от некоторых оптимизаций, выполнение которых требует большого времени, и которые умеет производить серверный компилятор, так что наш трассирующий компилятор достиг лишь 67% производительности по отношению к нему.
Для SPECjvm2008 наша конфигурация «greedy» достигла в среднем 85% производительности серверного компилятора. Этот бенчмарк содержит много текстов, интенсивно использующих циклы, таких как crypto, mpegaudio и scimark, в которых серверный компилятор показывает значительно более высокую пиковую производительность, ведь он применяет удаление проверок на границы массива и использует умные оптимизации циклов. Тем не менее, в результате агрессивного инлайнинга трейсов, наш трассирующий компилятор обогнал серверный компилятор на бенчмарках compress и sunflow.
На DaCapo 9.12 Bach, который содержит значительно более сложные тесты, использующие гораздо меньше циклов [14], наш трассирующий компилятор достиг в среднем 93% пиковой производительности серверного компилятора. Несмотря на то, что наш трассирующий компилятор производил только самые базовые оптимизации, он превзошел пиковую производительность серверного компилятора на тестах luindex, pmd и sunflow. Это стало возможно благодаря агрессивному и контекстно-зависимому инлайнингу.
6.6. Скорость запуска
И клиентский компилятор HotSpot, и серверный, и наш трассирующий JIT-компилятор — все они разрабатывались с учетом многопоточной компиляции в фоновом режиме. Мы проверили производительность запуска на следующих сценариях:
- В первом сценарии выполнялся 1 поток приложения, в то время как VM использовала вплоть до 4 потоков JIT-компилятора. Поэтому на нашем 4-ядерном стенде, вплоть до 3 ядер были эксклюзивно заняты под JIT-компиляцию.
- Во втором сценарии, 4 потока приложения выполнялись одновременно с 4 потоками JIT-компилятора. На нашем 4-ядерном стенде, потоки JIT-компилятора начали конкурировать с потоками приложения. HotSpot VM назначает более высокий приоритет потокам с JIT-компилятором, потому что JIT-компиляция оказывает позитивное воздействие на скорость запуска.
Все представленные результаты нормализованы по производительности конфигурации «client» с одним потоком JIT-компиляции. Мы не показали никаких результатов скорости запуска для SPECjbb2005, т.к. этот бенчмарк создан для измерения пиковой производительности, показывая первые результаты только через 30 секунд, после которых все конфигурации приближаются к своей пиковой производительности.
Для SPECjvm2008 мы измерили скорость запуска, выполняя по одной операции для каждого теста. Рисунок 23 показывает, что и клиентский компилятор HotSpot, и наш трассирующий компилятор достигают хороших результатов на тех сценариях, где потоки приложения конкурируют с потоками компилятора, т.е. когда время компиляции имеет существенное значение.
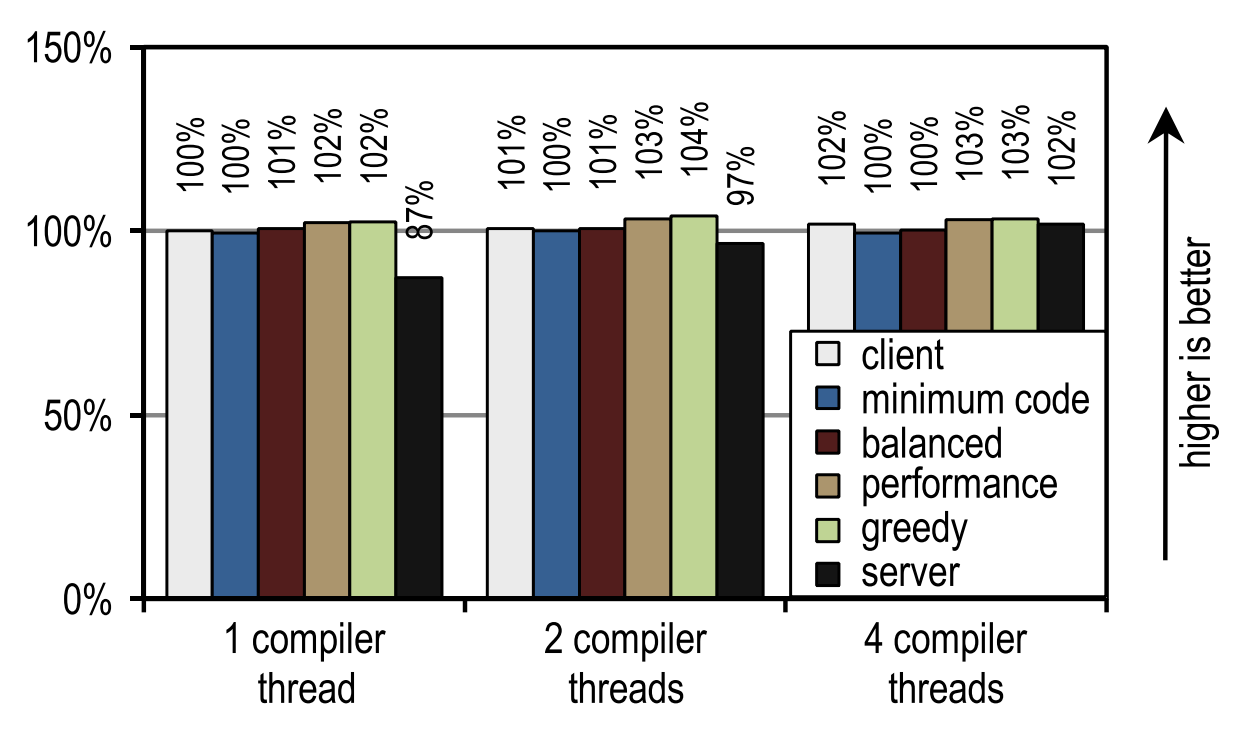
Рисунок 23. Время запуска SPECjvm2008 на 4 потоках приложения
Рисунок 22 показывает другой сценарий, в котором для JIT-компиляция можно задействовать ядра, которые в противном случае простаивали бы.
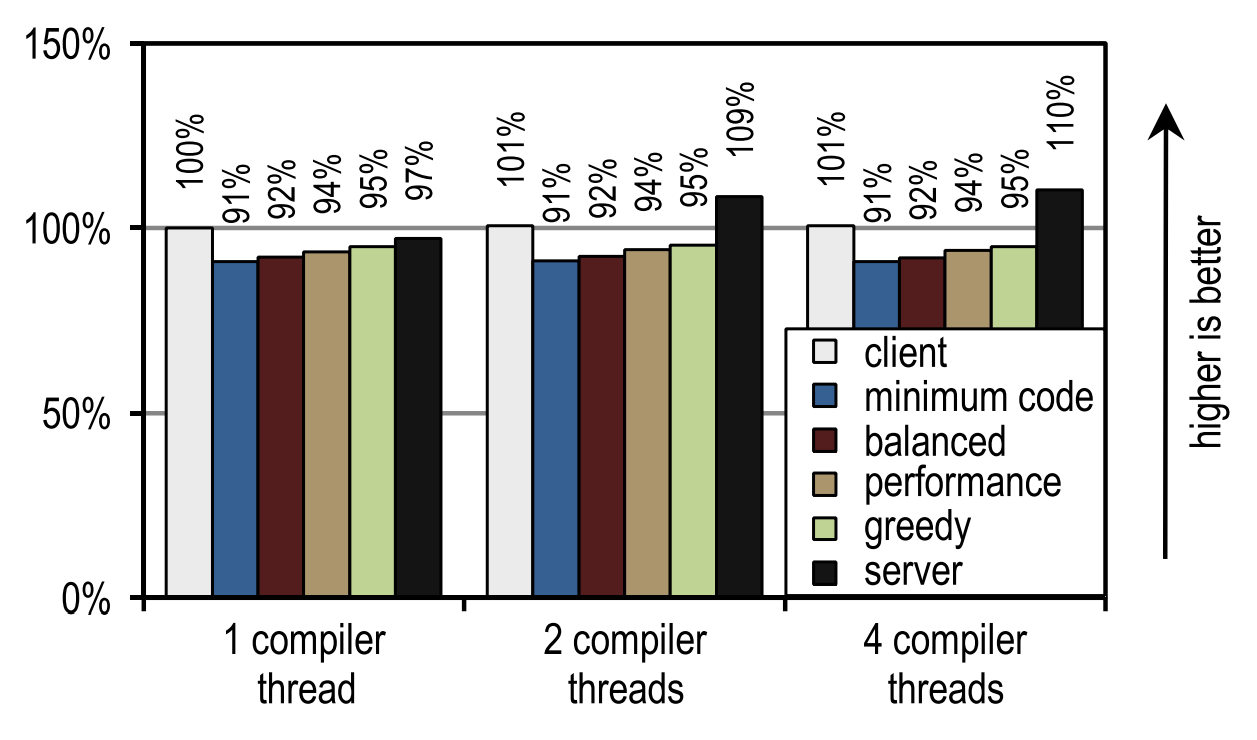
Рисунок 22. Время запуска SPECjvm2008 на 1 потоке приложения
В этом случае серверный компилятор HotSpot показывает наилучшую скорость запуска, поскольку SPECjvm2008 содержит несколько небольших тестов, в которых нужно совсем немного компилировать, и которые достигают своей пиковой производительности сразу же после компиляции самого глубокого цикла. Это — идеальный случай для серверного компилятора, который оптимизирует циклы особенно хорошо, и поэтому имеет преимущество в пиковой производительности, которая оказывает влияние на скорость запуска, если имеются простаивающие ядра, на которые можно переложить компиляцию.
Это изображение также показывает, что количество потоков компилятора не оказывает влияние ни на клиентский компилятор, ни на наш трассирующий компилятор, поскольку оба JIT-компилятора требуют сравнительное малое время на компиляцию. Серверный компилятор требует куда больше времени, и поэтому имеет сильное преимущество при наличии более чем одного потока компиляции, особенно если есть простаивающие ядра, которые можно использовать для этих целей.
Для DaCapo 9.12 Bach мы измерили скорость запуска, запуская по одной итерации для каждого теста. Результаты тестов показаны на рисунках 24 и 25.
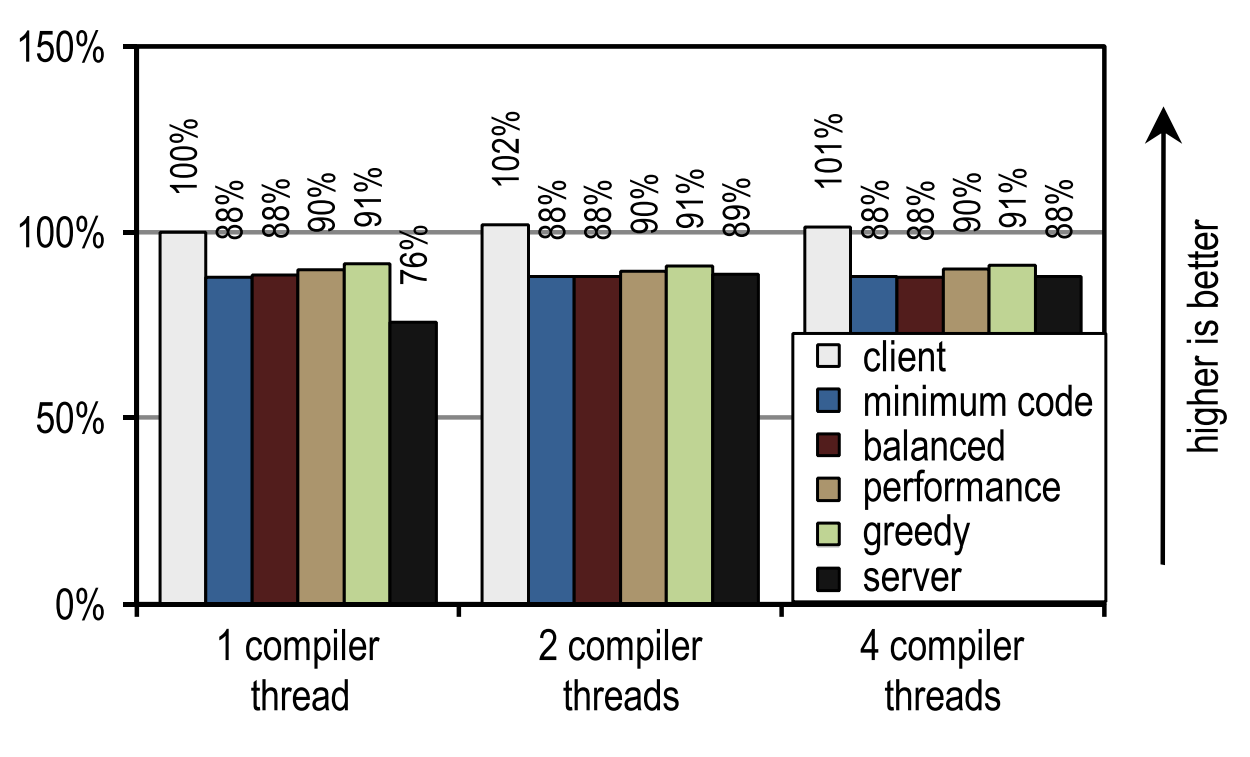
Рисунок 24. Время запуска DaCapo 9.12 Bach на 1 потоке приложения
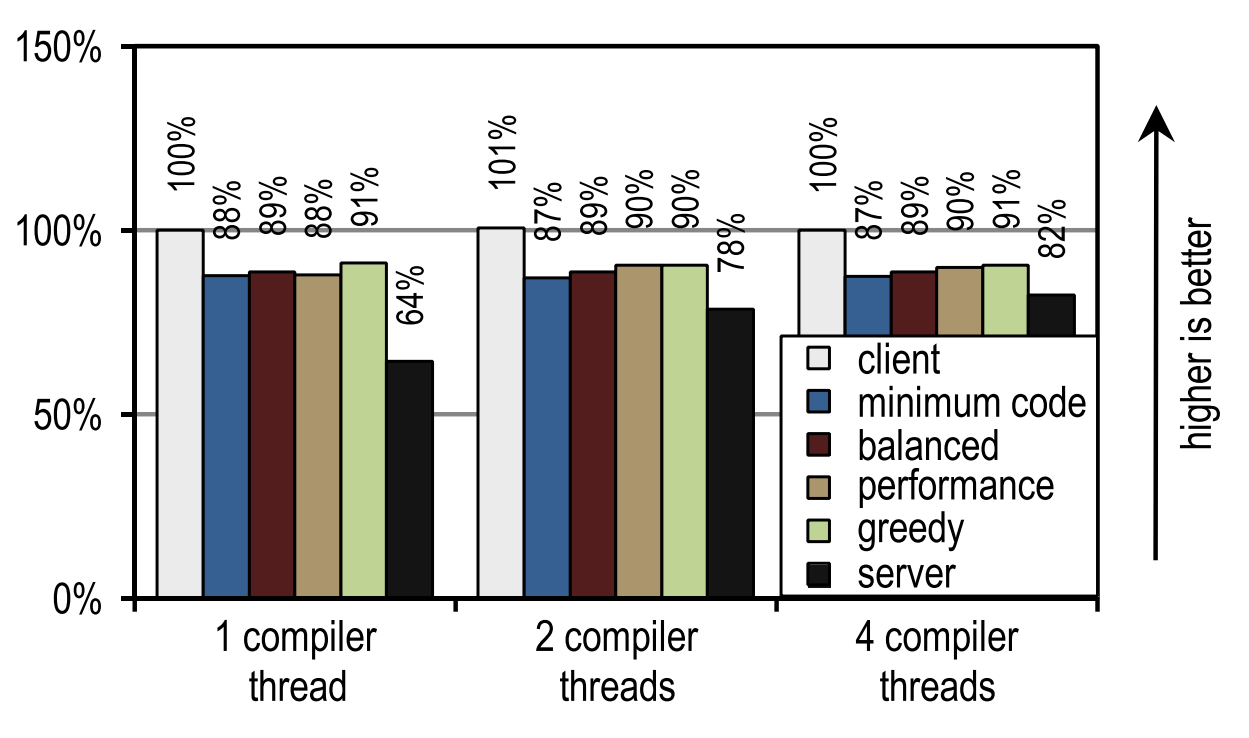
Рисунок 25. Время запуска DaCapo 9.12 Bach на 4 потоках приложения
И опять, количество потоков компиляции не оказало влияния ни на клиентский компилятор, ни наш трассирующий компилятор, поскольку они выполняют компиляцию быстро. В противоположность этому, серверный компилятор получает преимущество, когда для JIT-компиляции можно использовать более одного потока. Однако несколько наших конфигураций всегда быстрее серверного компилятора, даже если он использует все простаивающие ядра для JIT-компиляции. Это происходит потому, что DaCapo 9.12 Bach — значительно более сложный, чем тесты в SPECjvm2008 [14], так что скорость JIT-компиляции является доминирующим фактором для скорости запуска приложения.
На тестах из DaCapo 9.12 Bach наши трассирующие конфигурации показывают примерно на 10% более медленный запуск, чем на клиентском компиляторе HotSpot. Несмотря на то, что наш трассирующий компилятор обычно требует даже меньше времени на JIT-компиляцию, чем клиентский компилятор HotSpot, в данном случае он выдает меньшую скорость запуска, потому что вносит дополнительный оверхед на запись трейсов и деоптимизации, которые обычно происходят именно в момент запуска. Однако, этот недостаток перевешивается значительно более хорошей пиковой производительностью. В отличие от клиентского компилятора HotSpot, наш трассирующий компилятор не нуждается в простаивающих ядрах для достижения хорошей скорости запуска.
7. Связанные работы
Bala и др. [1] реализовали трассирующую компиляцию для свой системы Dynamo, для оптимизации потоков нативных инструкций. Горячие последовательности инструкций идентифицируются по запуску бинарного приложения под интерпретатором. Затем, эти трейсы компилируются, и сгенерированный по ним машинный код выполняется напрямую. Оверхед от интерпретации уменьшается при увеличении количества компилируемых трейсов, что рано или поздно приводит к ускорению. В противоположность им, мы идентифицируем подходящие якоря трейсов в байткоде, и для них мы используем статический анализ во время загрузки классов. Мы ограничиваем отдельные трейсы глубиной в один метод, связывая записанные трейсы для сохранения контекстно-зависимой информации при переходе через границу метода. Это позволяет нам отложить решение о необходимости инлайнинга до времени компиляции, вместо того чтобы делать это непосредственно во время записи.
Rogers [22] реализовал такой JIT-компилятор для Java, в котором часто исполняемые базовые блоки отмечаются и компилируются. Когда связанные блоки, могущие растягиваться на несколько методов, выполняются достаточно часто, они группируются и оптимизируются как одна сущность. В сравнении с блочной компиляцией, компилируется меньше байткода, вплоть до 18%. Наша же система записывает и компилирует трейсы, и использует контекстно-зависимый инлайнинг трейсов для увеличения пиковой производительности, одновременно генерируя весьма скромное количество машинного кода.
Следующий подход реализован во множестве вариантов трассирующей компиляции для Java [2,11,12,18]. Тем не менее, все эти подходы имеют общее – трейсы могут растягиваться на несколько методов, и поэтому инлайнинг обязан делаться во время записи трейсов. В противоположность этому, мы предполагаем, что один метод является максимально возможной областью захвата трейса, а для сохранения информации между трейсами используется связывание. Это позволяет отложить решение о необходимости инлайнинга вплоть до времени компиляции, то есть до момента, когда доступно куда больше полезной информации. Поэтому наш инлайнинг более разборчив, и использует простые эвристики, которые приводят к повышению пиковой производительности и меньшему количеству сгенерированного машинного кода.
Gal и др. [11,12] реализовали трассирующий компилятор на аппаратуре, ограниченной в ресурсах. Трейсы запускаются на часто выполняемых целях обратных бранчей, и на боковых выходах уже существующих трейсов. Любой трейс может растягиваться на несколько методов, поэтому инлайнинг происходит во время записи. После записи трейса, он компилируется в машинный код и связывается с остальными скомпилированными трейсами, формируя похожую на дерево структуру. Эта простая структура скомпилированных трейсов упрощает множество оптимизаций, но может привести к чрезмерному хвостовому дублированию и раздуванию кода. Похожий подход используется в Dalvik VM [4,6] в Android. В противоположность этому, мы перед компиляцией сливаем отдельные трейсы в граф трейсов, и таким образом избегаем излишнего дублирования.
Bebenita и др. [2] реализовал трассирующую компиляцию для Maxine VM. Maxine использует для изначальных выполнений базовый JIT-компилятор вместо интерпретатора. Этот базовый JIT-компилятор модифицирован для генерации инструментирования, использующегося для записи трейсов. Еще до начала JIT-компиляции, записанные трейсы сливаются в «регионы трейсов», которые имеют явный поток управления по точкам слияния. Это позволяет обойти излишнее хвостовое дублирование. В результате всевозможных оптимизаций циклов, JIT-компилятор достигает превосходного ускорения на тестах, интенсивно использующих циклы. Однако, он работает куда хуже на компиляции методов в тестах, где циклы используются реже. Наша работа является взаимодополняющей по отношению к их подходу, так как она концентрируется на сложных приложениях, которые редко используют циклы, такие как DaCapo 9.12 Bach jython. В нашем трассирующем компиляторе, мы достигли превосходного ускорения для этих приложений, но в то же время все тесты с циклами показали очень небольшое ускорение, ведь наш компилятор пока не выполняет никаких умных оптимизаций циклов.
Inoue и др. [18] добавили трассирующий JIT-компилятор в IBM J9/TR JVM, модифицировав блочный JIT-компилятор. Они записывают линейные и циклические трейсы без каких-либо внешних точек слияния, и компилируют их в оптимизированный машинный код. В терминах пиковой производительности, их трассирующий компилятор достигает производительности оптимизирующего аналогичным способом блочного JIT-компилятора. Wu и др. [28] расширили эту работу, избегая короткоживущих трейсов и ненужного их дублирования. Несмотря на то, что это не влияет на пиковую производительность, оно уменьшает и количество сгенерированного машинного кода, и время компиляции. Мы так же основываем свою работу на существующей JVM промышленного качества, но ограничиваем отдельные трейсы глубиной в один метод. Поэтому, мы можем отложить решение об инлайнинге до времени компиляции, что повышает пиковую производительность.
Bradel and Abdelrahman [5] использовали трейсы для инлайнинга методов в Jikes RVM. Трейсы записываются с использованием оффлайновой системы с учетом обратной связи. Затем, часто выполняющиеся места вызова идентифицируется в уже записанных трейсах, и эта информация используется для инлайнинга методов. Они провели тестирование на бенчмарках SPECjvm98 и Java Grande, которые показали не только 10% увеличение производительности, но и увеличение количества сгенерированного машинного кода на 47%. Наша система записывает трейсы в ходе выполнения на интерпретаторе, после чего компилирует и инлайнит только те части методов, сквозь которые прошли трейсы. Это увеличивает пиковую производительность и может уменьшить количество сгенерированного машинного кода.
Hazelwood and Grove [16] реализовали контекстно-зависимый инлайнинг в блочном компиляторе. Сэмплинг с использованием таймера и запись информации о вызове используется для решения об инлайнинге во время компиляции. Количество сгенерированного кода и время компиляции упало на 10% без изменений в производительности. В нашей системе, записанные трейсы содержат даже более детальную контекстно-зависимую информацию. В зависимости от эвристики инлайнинга, это увеличивает или пиковую производительность, или уменьшает количество сгенерированного машинного кода.
Инлайнинг методов является хорошо исследованным вопросом, который часто исследуется в соответствующей литературе. Соответственно, оставшаяся часть работы концентрируется на приемах инлайнинга отдельных участков методов вместо того, чтобы инлайнить их целиком, и это близко к нашей работе. Тем не менее, эти методы являются дополняющими к компиляции трейсов, т.к. у них части методов явным образом исключаются, а у нас количество сгенерированного машинного кода достигается с помощью записи трейса.
Частичная компиляция методов [9, 26] использует информацию из профиля для обнаружения редко выполняемых частей методов, для того чтобы выбросить их из компиляции. Это уменьшает время компиляции, увеличивает скорость запуска, и может также оказать положительное влияние на пиковую производительность. Наш подход даже более избирательный, т.к. мы записываем и компилируем только часто выполняемые трейсы. Более того, мы используем сэкономленные на компиляции ресурсы для обеспечения более агрессивного и контекстно-зависимого инлайнинга, который увеличивает пиковую производительность.
Suganuma и др. [25] реализовали компиляцию с регионами, при которой редко выполняющиеся части метода выбрасываются из компиляции, используя эвристики и информацию из профиля. Затем, используя тяжелые инлайнинги методов, часто выполняемый код группируется в один блок компиляции. Это уменьшает время компиляции более чем на 20% и увеличивает пиковую производительность на 5% в среднем случае на бенчмарках SPECjvm98 и SPECjbb2000. Мы же компилируем только часто выполняемые части методов, через которые проходят трейсы, а для увеличения производительности используем инлайнинг этих трейсов.
8. Заключение
В этой статье мы представили трассирующий Java-компилятор, который выполняет инлайнинг в ходе JIT-компиляции, вместо того, чтобы, как обычно, делать его во время записи трейса. Трейсы тут подходят лучше, потому что они захватывают только действительно выполняемые части методов. Откладывание решения об инлайнинге до момента JIT-компиляции позволяет проводить более избирательный инлайнинг трейсов, так как в этот момент доступно куда больше информации. Более того, все наши записанные трейсы являются контекстно-зависимыми, поэтому мы инлайним различные части методов исходя из конкретных мест вызова. Это позволяет делать более агрессивный инлайнинг трейсов, генерируя при этом разумное количество машинного кода. Дополнительно, мы предлагаем удалять редко выполняемые трейсы еще перед компиляцией, чтобы гарантировать, что только наиболее часто выполняемые трейсы превратятся в машинный код.
Тестирование на бенчмарках SPECjbb2005, SPECjvm2008 и DaCapo 9.12 Bach показало, что правильный инлайнинг трейсов может увеличить пиковую производительность, одновременно генерируя меньше машинного кода, чем инлайнинг методов. Кроме того, мы также показали, что инлайнинг трейсов расширяет область компиляции, увеличивая эффективность основных компиляторных оптимизаций, и со временем приводя к повышенной пиковой производительности.
Благодарности
При создании этой работы, авторам оказывал поддержку Austrian Science Fund (FWF): номер проекта P 22493-N18. Oracle и Java являются зарегистрированными торговыми марками Oracle и/или её филиалов. Все остальные названия также могут оказаться зарегистрированными торговыми марками соответствующих правообладателей.
Этот перевод никогда не был бы сделан без того душевного подъема, который на человека оказывает посещение конференций типа Joker и JPoint, которые организует команда JUG.RU. Однажды ты возвращается с конференции домой, и понимаешь, что тоже обязан что-то написать.
Ссылки
- Bala V, Duesterwald E, Banerjia S. Dynamo: a transparent dynamic optimization system. In: Proceedings of the ACM SIGPLAN conference on programming language design and implementation. ACM Press; 2000. p. 1–12.
- Bebenita M, Chang M, Wagner G, Gal A, Wimmer C, Franz M. Trace-based compilation in execution environments without interpreters. In: Proceedings of the international conference on the principles and practice of programming in Java. ACM Press; 2010. p. 59–68.
- Blackburn SM, Garner R, Hoffman C, Khan AM, McKinley KS, Bentzur R, et al. The DaCapo benchmarks: Java benchmarking development and analysis. In: Proceedings of the ACM SIGPLAN conference on object-oriented programming systems, languages, and applications. ACM Press; 2006. p. 169–90.
- Bornstein D. Dalvik VM Internals. Presented at the Google I/O developer conference, 2008. ?http://sites.google.com/site/io/dalvik-vm-internals?.
- Bradel BJ, Abdelrahman TS. The use of traces for inlining in Java programs. In: Proceedings of the international workshop on languages and compilers for parallel computing, 2004. p. 179–93.
- Cheng B, Buzbee B. A JIT compiler for Android's Dalvik VM. Presented at the Google I/O developer conference, 2010. ?http://www.google.com/events/ io/2010/sessions/jit-compiler-androids-dalvik-vm.html?.
- Cytron R, Ferrante J, Rosen BK, Wegman MN, Zadeck FK. Efficiently computing static single assignment form and the control dependence graph. ACM Transactions on Programming Languages and Systems 1991;13(4):451–90.
- Dean J, Grove D, Chambers C. Optimization of object-oriented programs using static class hierarchy analysis. In: Proceedings of the European conference on object-oriented programming. Springer-Verlag; 1995. p. 77–101.
- Fink S, Qian F. Design, implementation and evaluation of adaptive recompilation with on-stack replacement. In: Proceedings of the international symposium on code generation and optimization. IEEE Computer Society; 2003. p. 241–52.
- Gal A, Eich B, Shaver M, Anderson D, Mandelin D, Haghighat MR, et al. Trace-based just-in-time type specialization for dynamic languages. In: Proceedings of the ACM SIGPLAN conference on programming language design and implementation. ACM Press; 2009. p. 465–78
- Gal A, Franz M. Incremental dynamic code generation with trace trees. Technical Report. Irvine, USA: Donald Bren School of Information and Computer Science, University of California; 2006
- Gal A, Probst CW, Franz M. HotpathVM: an effective JIT compiler for resource-constrained devices. In: Proceedings of the international conference on virtual execution environments. ACM Press; 2006. p. 144–53.
- R. Griesemer, Generation of virtual machine code at startup. In: OOPSLA workshop on simplicity, performance, and portability in virtual machine design. Sun Microsystems, Inc.; 1999
- Haubl C, Mossenbock H. Trace-based compilation for the Java HotSpot virtual machine. In: Proceedings of the international conference on the principles and practice of programming in Java. ACM Press; 2011. p. 129–38.
- Haubl C, Wimmer C, Mossenbock H. Evaluation of trace inlining heuristics for Java. In: Proceedings of the ACM symposium on applied computing. ACM Press; 2012. p. 1871–6.
- Hazelwood K, Grove D. Adaptive online context-sensitive inlining. In: Proceedings of the international symposium on code generation and optimization. IEEE Computer Society; 2003. p. 253–64.
- Holzle U, Chambers C, Ungar D. Debugging optimized code with dynamic deoptimization. In: Proceedings of the ACM SIGPLAN conference on programming language design and implementation. ACM Press; 1992. p. 32–43
- Inoue H, Hayashizaki H, Wu P, Nakatani T. A trace-based Java JIT compiler retrofitted from a method-based compiler. In: Proceedings of the international symposium on code generation and optimization. IEEE Computer Society; 2011. p. 246–56
- Kotzmann T, Wimmer C, Mossenbock H, Rodriguez T, Russell K, Cox D. Design of the Java HotSpot client compiler for Java 6. ACM Transactions on Architecture and Code Optimization 2008;5(1):7.
- Oracle corporation. Java platform, standard edition 8 developer preview releases; 2011 ?http://jdk8.java.net/download.html?
- Paleczny M, Vick C, Click C. The Java HotSpot server compiler. In: Proceedings of the Java virtual machine research and technology symposium. USENIX, 2001. p. 1–12.
- Rogers I. Optimising Java programs through basic block dynamic compilation. PhD thesis. Department of Computer Science, University of Manchester; 2002.
- Standard Performance Evaluation Corporation. The SPECjbb2005 Benchmark; 2005 ?http://www.spec.org/jbb2005/?.
- Standard Performance Evaluation Corporation. The SPECjvm2008 benchmarks; 2008 ?http://www.spec.org/jvm2008/?.
- Suganuma T, Yasue T, Nakatani T. A region-based compilation technique for dynamic compilers. ACM Transactions on Programming Languages and Systems 2006;28:134–74.
- Whaley J. Partial method compilation using dynamic profile information. SIGPLAN Notices 2001;36:166–79
- Wimmer C, Mossenbock H. Optimized interval splitting in a linear scan register allocator. In: Proceedings of the ACM/USENIX international conference on virtual execution environments. ACM Press; 2005. p. 132–41.
- Wu P, Hayashizaki H, Inoue H, Nakatani T. Reducing trace selection footprint for large-scale java applications without performance loss. In: Proceedings of the ACM international conference on object oriented programming systems languages and applications. ACM Press; 2011. p. 789–804.
Авторы
Christian Haubl – PhD студент в Johannes Kepler University Linz в Австрии, работающий над трассирующими Java-компиляторами. Имеет степень Computer Science и Networks and Security, обе получены в Johannes Kepler University Linz. В исследованиях интересуется областями, связанными с компиляцией и виртуальными машинами, но иногда переключается на безопасность и веб-приложения.
Christian Wimmer — исследователь в Oracle Labs, работал над MaxineVM, над компилятором Graal, и на других проектах, которые связаны с динамической компиляцией и оптимизациями. Его исследовательские интересы связаны с компиляторами, виртуальными машинами и безопасными системами для компонентных программных архитектур. Он получил докторскую степень в Computer Science (руководитель: профессор Hanspeter Mossenbock) в Johannes Kepler University Linz. До работы в Oracle был докторантом в Department of Computer Science в University of California. Работал с профессором Michael Franz в Secure Systems and Software Laboratory над компиляторными оптимизациями, динамическими языками программирования и языковой безопасностью.
Hanspeter Mossenbock — профессор Computer Science в Johannes Kepler University Linz и глава Christian Doppler Laboratory for Automated Software Engineering. Он получил PhD CS в University of Linz в 1987 году, был доцентом в ETH Zurich с 1988 до 1994 года, работая с профессором Никлаусом Виртом над системой Oberon. Текущие исследовательские интересы включают языки программирования и компиляторы, а также объектно-ориентированное и компонентное программирование. Является автором нескольких книг по обучению программированию.
Переводчики
Олег Чирухин — на момент написания этого текста, работает архитектором в компании «Сбербанк-Технологии», занимается разработкой архитектуры систем автоматизированного управления бизнес-процессами. До перехода в Сбербанк-Технологии, принимал участие в разработке нескольких государственных информационных систем, включая Госуслуги и Электронную Медицинскую Карту, а также в разработке онлайн-игр. Текущие исследовательские интересы включают виртуальные машины, компиляторы и языки программирования.
Комментарии (11)

babylon
22.05.2017 12:08-1Что делает компилятор? Он парсит текст с кодом на каком-то языке в AST дерево. Для доступа к узлу которого нужен знать контекст. Далее идет траверсинг этого дерева с формированием контекстного словаря. Т.е. списка ссылок на содержимое объекта, которое представляет собой байт код. Что в этом байтоде лежит — код или часть кода cсопрограммы или данные не имеет значения. Его можно кэшировать и повторно использовать. И причём здесь "основанность на методах"? Поэтому само употребление этого термина излишне. Повторно используемый байткод — это самое правильное определение. Ну это с моей точки зрения. Хочу еще минусов.

olegchir
22.05.2017 12:58+2> не имеет значения
Для исследования нужно установить классификацию компиляторов относительно исследуемого признака. В данном случае исследуется разница между единицами компиляции — методами, и единциами компиляции — трейсами. Отличие трейсов в том, что их состав не следует напрямую из AST/IR, а постоянно меняется в зависимости от информации профиля и деоптимизаций с проваливанием в интерпретатор. Плюс среди трассирующих компиляторов есть свое деление (см. связанные работы, например, важен этап выполнения инлайнинга, который в данном случае зависит от длины трейса и его способа связывания). Для отражения этих тонкостей какие-то удобные слова, чтобы было о чем говорить.babylon
24.05.2017 18:32-1Отличие трейсов в том, что их состав не следует напрямую из AST/IR, а постоянно меняется в зависимости от информации профиля и деоптимизаций с проваливанием в интерпретатор. Плюс среди трассирующих компиляторов есть свое деление (см. связанные работы, например, важен этап выполнения инлайнинга, который в данном случае зависит от длины трейса и его способа связывания)
@olegchir с вашим комментарием целиком согласен. Так он и есть. Просто статья мне не зашла. Вообщем не важно. Это мелочи.
olegchir
24.05.2017 21:26ОК, понятно.
Будет время — притаскивай более подробную критику, чтобы можно было пообсуждать в комментах. В конце, концов, где еще это можно пообсуждать, кроме как здесь.

xhumanoid
22.05.2017 13:04+3для полноты картины стоит добавить, что в этом же самом университете и этими же самыми людьми сейчас идет разработка Graal =)
olegchir
22.05.2017 13:06+2да, про Грааль будет позднее, пока надо натащить археологии, чтобы при описании Грааля можно было ссылаться на связанные работы. Следующая статья будет про Maxine, наверное

Beholder
22.05.2017 19:19А широкая публика результаты этих оптимизаций где-нибудь увидеть может? В OpenJDK, там, например?
olegchir
24.05.2017 21:24Скорей всего, результаты этих исследований можно увидеть в Graal, но я пока не разобрался в теме достаточно хорошо, чтобы что-тол увтерждать.
Наверное, в мире дочерта интересных исследований, которые незаслуженно забыты и нигде не рализованы. Имхо, это повод читать все эти работы, реализовывать интересные ништяки в своих продуктах, и навариваться на этом!
babylon
Само употребление понятия "блочности" говорит о полном непонимании того, что они делают. Посмотрите в сторону NodeJS v8 JS engine. Пичалька, что топикастер популяризирует стремные подходы. В топку их.
olegchir
Не мог бы ты более подробно развернуть мысль?
Слово «блочное» тут выбрано чуть ли не рандомом, нельзя же раз за разом повторять «основанные на методах компиляторы», учитывая как часто это встречается в тексте. В английском языке «method-based» выглядит компактно, в русском — ой.
Если подберешь более подходящее слово, напиши его сюда. Герои «поиска и замены» работают быстро и беспощадно.