
Предисловие
В данной статье будут разобраны основные регламентные работы с базой данных информационной системы 24x7 (т е у которой нет простоя) и подходы к их выполнению в MS SQL Server. Также прошу заметить, что эта статья будет кратким обзором, т е не все работы будут достаточно детализированы. Однако, данной информации достаточно, чтобы при необходимости изучить более детально ту или иную регламентную работу.
Буду очень признателен, если в комментариях появятся поправки и дополнения к этой статье.
Регламентные работы
Выделяют следующие основные регламентные работы с базой данных:
1) Плановое создание резервных копий с последующей проверкой без восстановления
2) Плановое восстановление ранее созданных резервных копий с целью полной проверки их работоспособности
3) Анализ носителей информации, на которых расположены системные и все необходимые базы данных
4) Плановая проверка работы необходимых служб
5) Плановая оптимизация производительности системы
6) Плановая проверка целостности данных
7) Плановая проверка корректности данных
Первые три пункта самые критичные, так как обеспечивают восстановление системы после различных сбоев. Однако, и последние три пункта необходимо планово выполнять, чтобы и пользователям было комфортно работать (все запросы выполнялись быстро или за приемлемое время), и данные были корректными в различных отчетных системах.
Для автоматизации регламентных работ можно части этих работ оформить в задачи Агента или Планировщика Windows.
П.6 основан на команде CHECKDB.
П.7 реализуется относительно предметной области, которая применяется в информационной системе.
Пункты 6 и 7 подробно разбирать не будем.
Теперь разберем первые пять пунктов подробнее.
Плановое создание резервных копий с последующей проверкой без восстановления
На эту тему писалось достаточно статей (см. источники), поэтому отметим лишь то, что эту регламентную работу нужно делать постоянно желательно на резервном, а не на основном сервере. На таком резервном сервере должны быть актуальные данные (например, с помощью репликаций). Также необходимо делать резервные копии всех системных баз данных (кроме tempdb) на каждом экземпляре сервера MS SQL Server.
При неудачном создании резервной копии (или проверка резервной копии выявила проблему), данную информацию необходимо сообщить администраторам. Например, на почту (Настройка почтовых уведомлений в MS SQL Server).
Важно определить стратегию резервирования, которая отвечала бы в том числе и на следующие вопросы:
1) как часто и когда делать резервную копию (полную, разностную, журнала транзакций)
2) как долго и когда удалять резервные копии.
Плановое восстановление ранее созданных резервных копий с целью полной проверки их работоспособности
Данную процедуру лучше также выполнять на резервном сервере с помощью сторонних утилит или команды RESTORE.
При неудачном восстановлении резервной копии, данную информацию необходимо сообщить администраторам. Например, на почту (Настройка почтовых уведомлений в MS SQL Server).
Также в качестве проверки необходимо восстанавливать и резервные копии системных баз данных. Для этого достаточно их восстановить как обычную пользовательскую базу данных с именем, отличной от имен системных баз данных.
Анализ носителей информации, на которых расположены системные и все необходимые базы данных
Здесь необходимо анализировать сколько места занимает каждая база данных, как изменяются размеры файлов, а также как изменяются размеры свободного места всего носителя целиком (например, часть этого задания можно сделать с помощью Автосбор данных о файлах баз данных и логических дисках операционной системы в MS SQL Server).
Такую проверку можно делать каждый день и отправлять результаты. Например, на почту (Настройка почтовых уведомлений в MS SQL Server).
Необходимо также следить и за системными базами данных. Если этого не делать, то может произойти, например, это.
Также важно протестировать и сами носители на предмет износа или ошибочных секторов. Важно, что в момент такого тестирования, носитель необходимо вывести из работы, а данные переместить на другой носитель, т к проверка подобного рода сильно нагружает носитель.
Данная задача является уже чисто задачей системного администратора, и поэтому ее подробно рассматривать не будем. Для полного контроля лучше договориться с системным администратором об автоматической отправке отчета о результатах тестов на почту.
Данную проверку лучше выполнять раз в год.
Плановая проверка работы необходимых служб
Вообще говоря, службы никогда не должны падать. Для этого и предназначен резервный сервер, который в случае сбоя основного сервера, станет основным. Но просматривать логи необходимо периодически. Также можно продумать автоматический сбор информации с последующим уведомлением администраторов. Например, отправив результаты на почту (Настройка почтовых уведомлений в MS SQL Server).
Необходимо проверять и сами задания Агента (или Планировщика заданий Windows). Например, автоматизировать проверку заданий Агента можно с помощью автосбора данных о выполненных заданиях в MS SQL Server.
Плановая оптимизация производительности системы
Сюда входят следующие компоненты:
1) Автоматизация дефрагментации индексов в базе данных MS SQL Server
2) Автосбор данных об изменениях схем баз данных в MS SQL Server (чтобы можно было восстановить нужную резервную копию и сравнить изменения, например, с помощью dbForge)
3) Автоматическое удаление зависших процессов в MS SQL Server
4) Чистка процедурного кэша (здесь важно определить когда и что именно чистить)
5) Реализация индикатора производительности
6) Разработка и изменение индексов (Повесть о кластеризованном индексе)
Не будем подробно описывать каждый пункт, а остановимся на пунктах 5-6.
В пункте 5 необходимо создать систему, которая бы показывала быстродействие работы базы данных. Также это можно сделать и так.
Также в большинстве случаев советую в параметрах базы данных отключить параметр AUTO_CLOSE.
Еще немного поговорим об оптимизации самих запросов.
Иногда по разным причинам (а порой и не понятным) оптимизатор решает распараллелить запрос. И не всегда он это делает оптимально.
Есть общая рекомендация:
1) Если данных много будет в итоге обработки (выборка, изменение), то параллелизм оставить
2) Если данных немного будет в итоге обработки (выборка, изменение), то параллелизм в большинстве случаев не оптимально строит план.
За параллелизм отвечают два параметра в настройках экземпляра сервера MS SQL Server:
1) Максимальная степень параллелизма (max degree of parallelism) (чтобы выключить параллелизм, выставите значение в «1», т е будет всегда только один процессор задействован в выполнении плана запроса)
2) Стоимостный порог для параллелизма (cost threshold for parallelism) (в большинстве случаев его лучше оставить по умолчанию)
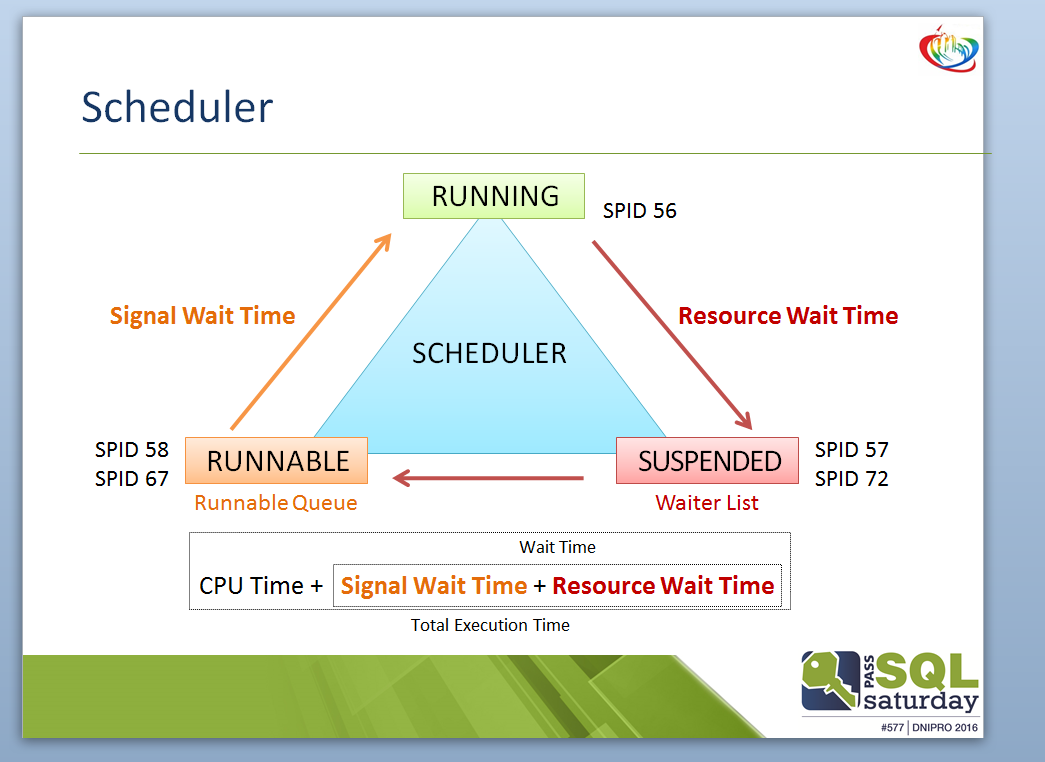
Выделяют две основные очереди:
1) На ожидание процессорного времени (очередь QCPU) – это когда процесс запроса уже был запущен и ожидает процессор на выполнение (например, другой процесс вытеснил процесс запроса)
2) На ожидание ресурсов (очередь QR) – это когда процесс ждет освобождение ресурсов для своего выполнения или продолжения выполнения (диски, оперативная память и др.)
Все время выполнения запроса T определяется следующей формулой:
T=TP+TQR+TCPU+TQCPU, где:
1) TP – время компиляции плана
2) TQR – время ожидания на ресурсы (время пребывания процесса в очереди QR)
3) TQCPU – время ожидания на освобождение необходимых процессоров (время пребывания процесса в очереди QCPU)
4) TCPU – время выполнения запроса (суммируется все время по всем процессорам)
В системных представлениях sys.dm_exec_query_stats и аналогичных:
1) total_worket_time = TP+TCPU+TQCPU
2) total_elapsed_time = TQR+TCPU
Из этого следует, что по встроенным средствам невозможно точно сказать сколько же на самом деле выполнялся запрос. Но в большинстве случаев с помощью total_elapsed_time можно получить время, которое близко к времени выполнения самого запроса. Более точно определить время выполнения запроса можно либо с помощью трассировки, либо с помощью самой информационной системы, если начало и конец вызова запроса как-то логируется в таблицу логов в базу данных. Но любая трассировка нагружает систему, поэтому ее лучше проводить также на резервном сервере, а собирать данные из основного сервера. Тогда нагрузка будет только на сеть.
Во время распараллеливания запросу выделяется n процессов (в выпуске Standart n<=4). И каждый процесс такой потребует процессорное время для выполнения (не всегда 1 процесс будет выполняться на каждом ядре). Чем больше процессов, тем больше вероятность того, что один или несколько процессов будут вытесняться другими процессами, что в свою очередь приведет к увеличению TQCPU.
Запрос может выполняться медленнее при распараллеливании в следующих случаях:
1) если у системы очень слабая пропускная способность дисковых подсистем, тогда при анализе запроса, его декомпозиция может выполняться дольше, чем без параллелизма.
2) возможен перекос данных или блокировки диапазонов данных для процесса, порождённые другим, используемым параллельно и запущенным позже процессом, и т.д.
3) если отсутствует индекс для предиката, что приводит к сканированию таблицы. Параллельная операция в рамках запроса может скрыть тот факт, что запрос выполнился бы намного быстрее с последовательным планом исполнения и с правильным индексом.
Рекомендации:
Запретить распараллеливание запросов на серверах, где нет большой выборки (показатель total_worket_time должен уменьшиться из-за возможного уменьшения TCPU и TQCPU особенно последнего, т к первый может примерно не измениться в виду того, что все процессы превратятся в один линейный процесс). Для этого необходимо параметр Максимальная степень параллелизма (max degree of parallelism) выставить в 1, чтобы всегда только один процессор был задействован в выполнении плана запроса.
Также можно использовать и другие готовые решения для построения системы, которая определяет быстродействие базы данных. Важно четко понимать как эти решения работают и правильно интерпретировать полученные числа.
По п.6 тоже достаточно много исчерпывающей информации в Интернете. Главное-понимать как логически устроен индекс и как он работает.
Напомню лишь о том, что первичный ключ и кластерный индекс-это не одно и тоже:
Первичный ключ-это поле или набор полей, которые делают уникальным запись в таблице (для него можно построить либо уникальный кластерный индекс, либо уникальный некластерный индекс). Его используют в других таблицах как внешний ключ для обеспечения целостности данных.
Кластерный индекс-это по сути B-дерево (или его модификация), в листьях которых содержатся сами данные (строки), а в узлах-то, что было определено в качестве кластерного индекса (поле или группа полей). Данное определение дано грубо относительно того, что содержится в листьях и в узлах B-дерева, но такое определение необходимо для понимания процесса поиска и вставки в это дерево. При этом кластерный индекс может быть и неуникальным, но лучше стараться делать его уникальным.
Напомню, что B-дерево-это структура, которая хранит данные в отсортированном виде по кластерному индексу. Поэтому также важно, чтобы поля, выбранные в качестве кластерного индекса, по порядку либо возрастали, либо уменьшались. Т. е. для кластерного индекса отлично подойдут поля типа целого числа (identity), а также дата и время (т к данные будут записываться всегда в конец дерева), но плохо подойдут поля типа uniqueidentifier, т к последние будут приводить к постоянным перестройкам B-дерева, что в свою очередь увеличит количество чтений и записей на носитель информации, где расположена база данных.
К сожалению, данный факт порой забывают даже ведущие разработчики программного обеспечения, т к в свободных ресурсах об этом явно не освещают, но зато разбирают сами индексы и как они устроены. И из этого делается уже вывод о том, что можно делать кластерным индексом, а что лучше не делать.
Также необходимо убедиться, что индекс используется с помощью системного представления sys.dm_db_index_usage_stats
P.S.: Также необходимо постоянно проверять, что на резервном сервере данные актуальны, а также саму систему, которая эти данные синхронизирует (например, репликации).
Источники:
» CHECKDB
» Настройка почтовых уведомлений в MS SQL Server
» RESTORE
» Автосбор данных о файлах баз данных и логических дисках операционной системы в MS SQL Server
» Тестирование производительности баз данных при помощи tSQLt и SQLQueryStress
» AUTO_CLOSE
» История про msdb размером в 42 Гб
» TOP (10) бесплатных плагинов для SSMS
» План обслуживания «на каждый день» – Часть 1: Автоматическая дефрагментация индексов
» План обслуживания «на каждый день» – Часть 2: Автоматическое обновление статистики
» План обслуживания «на каждый день» – Часть 3: Автоматическое создание бекапов
» Автосбор данных о выполненных заданиях в MS SQL Server
» Автоматизация дефрагментации индексов в базе данных MS SQL Server
» Автосбор данных об изменениях схем баз данных в MS SQL Server
» Полезные возможности dbForge для администрирования баз данных MS SQL Server)
» Автоматическое удаление зависших процессов в MS SQL Server
» Чистка процедурного кэша
» Реализация индикатора производительности запросов, хранимых процедур и триггеров в MS SQL Server. Автотрассировка
» Степени параллелизма и степени неопределенности в Microsoft SQL Server
» Презентация ожидания
» Схема выполнения запроса
» Степень параллелизма
» Исследуем базы данных с помощью T-SQL
» Повесть о кластеризованном индексе
» sys.dm_db_index_usage_stats
Комментарии (21)

kolu4iy
22.02.2017 23:35+1… еще не вижу рекомендаций о горизонтальном масштабировании: как правило, 50-80% нагрузки — это чтение данных, при этом совершенно не обязательно они должны быть актуальны до милисекунды. А с ms sql 2012 появился совершенно прекрасный high avalaibility кластер, в котором существую замечательные read-only реплики. Перенос, например, генерации аналитических отчётов на данные реплики позволяет очень существенно разгрузить основную ноду.

jobgemws
23.02.2017 10:53Спасибо за дополнение
Также прошу Вас раскрыть данную тематику или привести ссылки на источникиkolu4iy
23.02.2017 13:13+1Собственно, источник сокровенного знания, как обычно, в MSDN
Вкратце: в SQL Server 2008 был новый механизм переноса данных на другие сервера — кроме trnsaction log shipping и репликации был добавлен mirroring. Для старта необходим один full backup БД + минимум один transaction log backup. На принимающей стороне данные бекапы восстанавливаются с опцией NORECOVERY. Что происходит в после включения mirroring: все транзакции, происходящие после LSN последнего transation log бекапа по сети едут на принимающий сервер. БД при этом остается в состоянии Recovery.
Существуют две модели переноса транзакций: синхронная и асинхронная. При синхронном переносе транзакций на сервере-источнике любая транзакция не считается законченой, пока сервер-приёмник не подтвердил её получание. При этом гарантируется целостность данных на обеих серверах, однако длительность каждой транзакции значительно увеличивается — кроме собственно времени вставки в БД к длительности добавляет латентность сетевого подключения, причем в две стороны. И, естественно, длительность собственно коммита транзакции на сервер-приёмник.
В случае асинхронного переноса транзакций длительность транзакций на сервере-источнике практически не увеличивается, но данные на сервере-приёмнике могут отставать на несколько миллисекунд. Кроме того, в случае аварии сервера-источника возможны потери нескольких последних транзакций на сервере-приёмнике. Для использования БД на сервере-приёмнике необходимо было перевести БД из состояния RECOVERY в консистентное состояние, однако после данной процедуры зеркалирование по понятным причинам останавливалось.
Начиная с SQL Server 2012 данная технология была развита в Always On Availability Groups. Для работы always on группы необходимо стандартными средствами ОС создать кластер, в который необходимо включить оба (три, четыре) сервера MS Sql. Это сделано для того, чтобы при аварии одного из серверов обеспечить доступность данных в любом случае. Кроме того, теперь сервер-приёмник называется secondary replica, а для каждого сервера в группе можно настроить поддерживаемые им виды подключений — нормальный, read-only (применим на вторичных репликах) и вообще запретить клиентам к ним подключаться. Также у always on группы возможно понятия listener. При создании listener-а группы клиентам не надо подключаться к конкретному серверу, а надо подключаться к доменному имени listener-а. Почему: подключение к адресу listener-а приводит к автоматическому подключению клиента к работоспособной реплике — за этим следит кластерная служба. Кроме того, если софт не очень древний, то в момент подключения можно указать, что клиент собирается данные только читать, и тогда он будет подключен к read-only реплике. Временные таблицы на этих репликах безусловно создаются (tempdb не реплицируется), потому 90% хранимых процедур работают совершенно корректно без дополнительных ухищрений и на read-only репликах. Клиенты, которые изменяют данные (или не указывают свой тип подключения — read only или read-write), автоматически подключаются к первичной реплике.
Тонкостей в настройке достаточно много. Например, для того, чтобы failover происходил автоматически, мы обязаны использовать синхронный коммит транзакций. Возможность ручного failover существует при любом коммите, но управлять им можно только с первичной реплики. В случае выхода из строя именно первичной реплики, в случае ручного failover придётся переносить кластерную службу на другой узел с помощью оснастки windows failover clustering, однако больших проблем это не вызывает, и это просто надо знать.
В общем технология удобная, у нас в production работает уже два года, проблемы испытывали только в самом начале: оказалось что always on group достаточно чувствительна к быстрому разрешению имён серверов. Например, если отправить в перезагрузку по очереди два контроллера домена, то кластер обязательно развалится (правда, потом починится сам). В итоге, не добившись от наших коллег бесперебойной работы контроллеров домена, нам пришлось вручную заполнить файлик hosts на каждом из серверов кластера. Не могу сказать, что это соответствует best practices, но работа кластера стала стабильной.
Короче, извините, не мог, а на полноценную статью сейчас времени нет. Потому настоятельно рекомендую ознакомиться с данной темой на MSDN, построить макет, удивиться тому, насколько это удобно и попробовать ввести в production.jobgemws
23.02.2017 16:24Спасибо за подробное описание
Да, зеркалирование используется у нас, правда пока только в одном месте
pranas
23.02.2017 01:49Ну блин, ну да, дом надо строить, но почему обязательно топором? Програмисты постоянно пробуют новые инструменты и технологии, почему многие админы застряли на 15-летнем инструменте и делают вид что после этого ничего не было создано? Автор 5 раз дает ссылку «Настройка почтовых уведомлений в MS SQL Server». Ну не проще вместо того чтобы мучаться с этим устаревшим мусором потратить 5 минут на поиск современных инструментов которые и бэкап сделают и автоматом куда надо восстановят и письма пошлют после бэкапа или если SQL упадет, да и Health Check сделают? Да часто и бесплатно. Есть несколько софтин и сервисов, сами ищите что вам подходит, но главное не сидите на месте думая что после MS ничего лучше не придумано.
Надо отдать должное автору — он в основном говорит о том что нужно делать, а не как. По этому поводу можно придраться только к некоторой книжной абсолютности требований. Есть вещи критические (вроде бэкапа и отслеживания производительности) и вещи которые на практике часто можно и нужно (поскольку время не резиновое) игнорировать. И вот этой иерархии мне в статье не хватает. Сам бы написал, да критиковать проще :)jobgemws
23.02.2017 11:06Ну блин, ну да, дом надо строить, но почему обязательно топором? Програмисты постоянно пробуют новые инструменты и технологии, почему многие админы застряли на 15-летнем инструменте и делают вид что после этого ничего не было создано?
Потому что настроить стандартными средствами резервное копирование с проверкой, а также восстановление резервной копии и уведомление почтой, а также дефрагментацию индексов-это задача несложная для людей, на достаточном уровне знающих T-SQL и администрирование в MS SQL Server (достаточно уровня Middle).
Посложнее вопрос стоит в построении системы, которая бы показывала быстродействие базы данных.
Да, есть софтины и бесплатные, даже у самого скуля есть механизмы для этого, но понимает ли потребитель как именно работает эта утилита? От куда такие цифры? Мы наблюдали за системными представлениями, и можем смело утверждать, что в большинстве случаев приходится писать свою систему, подходящие по своим нуждам, а не систему уникальную для всех и собирающую лишнюю информацию+те, кто использует сторонние средства для регламентных работ, которые лучше написать самому или своей командой, зависят от производителей сторонних утилит (и опять же нужно хорошо понимать как эти утилиты работают). Другое дело обстоит с синхронизацией схем и самих данных. Написать собственную утилиту-уйдет много времени. Поэтому пока используем dbForge. Но опять же при первой возможности напишем свою утилиту.
Сторонние утилиты можно использовать для разработок, но для регламентных работ. Лучше взвесить-что можно самим написать и это будет работать оптимально для Ваших нужд, а не унифицировано для всего, а что лучше с помощью сторонних утилит. Пункты 1,2,5 регламентных работ можно полностью покрыть своими силами без сторонних утилит, а вот пункты 3,4,6,7 скорее всего в симбиозе с готовыми решениями.
Также, чтобы не быть голословным, прошу привести ссылки на бесплатные и хорошие по Вашему мнению ПО, которое позволяет работать с резервными копиями, восстанавливать их и отправлять на почту уведомления.
Есть вещи критические (вроде бэкапа и отслеживания производительности) и вещи которые на практике часто можно и нужно (поскольку время не резиновое) игнорировать. И вот этой иерархии мне в статье не хватает.
Да, согласен, тогда регламентные работы можно расположить по следующему принципу-в порядке убывания по значимости:
1) Плановое создание резервных копий с последующей проверкой без восстановления
2) Плановое восстановление ранее созданных резервных копий с целью полной проверки их работоспособности
3) Плановая оптимизация производительности системы
4) Плановая проверка работы необходимых служб
5) Анализ носителей информации, на которых расположены системные и все необходимые базы данных
6) Плановая проверка целостности данных
7) Плановая проверка корректности данных
Сам бы написал, да критиковать проще :)
Так пишите-делитесь информацией-с удовольствием почитаю)

{kind=link}

BalinTomsk
23.02.2017 20:10+1— но плохо подойдут поля типа uniqueidentifier, т к последние будут приводить к постоянным перестройкам B-дерева
На вставке я бы сказал разница не существенная, но геморой при использовании инкремента на распределенных базах с identity с лихвой перекрывает копеейчную экономию.
create table TestTable ( id int identity(1,1) not null primary key clustered, sequence int not null, data char(250) not null default ''); go declare @count int; set @count = 0; while @count < 500000 begin insert TestTable (sequence) values (@count); set @count = @count + 1; end; go
43 sec
create table TestTable2 ( id uniqueidentifier default newid() not null primary key clustered, sequence int not null, data char(250) not null default ''); go declare @count int; set @count = 0; while @count < 500000 begin insert TestTable2 (sequence) values (@count); set @count = @count + 1; end; go
48 secjobgemws
23.02.2017 20:20Подобные тесты я видел от ведущих разработчиков, которые почему-то на тестах пытаются понять плохо или хорошо использовать uniqueidentifier в качестве кластерного индекса. Это неправильный подход, т к можно поставить SSD-диски, увеличить оперативную память и будет все летать, НО! Погрузитесь в алгоритмы и типы данных и вспомните как работает B-дерево и только тогда станет понятно и без тестов, что uniqueidentifier-плохой кандидат для кластерного индекса. Но почему-то большинство выбирает тесты. А они невсегда покажут проблему.
jobgemws
23.02.2017 20:24Также не стоит забывать, что любой тест МОЖЕТ выявить проблему, а может и не выявить. Важно понимать базовые принципы. И порой этого достаточно и без тестов. Тесты нужны лишь для сравнения скоростей или для выявления проблем в сложнопонимаемой системе. Тесты также выявляют порой другую проблему (напр, мало ОЗУ и прочее), а не то, что на самом деле тестируем. Поэтому в данном случае тестирование не является лучшим решением для исследования кластерного индекса.
BalinTomsk
23.02.2017 21:53+1— А они невсегда покажут проблему.
Ну дак докажите что проблема существует.
Если выбрать sequential guid — скорость получется выше даже по сравнению с identity. Внутри sequential guid также растет монотонно. Мне кажется у вас упрощенное представление что такое b+ tree и как строится индекс и поиск внутри этого дерева.
Разработчики учитывают специфику этого типа данных.
create table TestTable3 ( id uniqueidentifier default newsequentialid() not null primary key clustered, sequence int not null, data char(250) not null default ''); go declare @count int; set @count = 0; while @count < 500000 begin insert TestTable3 (sequence) values (@count); set @count = @count + 1; end; go
41 sec.

AlanDenton
24.02.2017 08:05+1На самом деле скорость везде примерно одинакова и зависит от свободного места в файле (будет ли AutoGrowth), включен ли IFI, скорости дисковой подсистемы (не забываем про WRITELOG) и тд.
Если все эти факторы учесть, то вот мой тест:
SET NOCOUNT ON IF OBJECT_ID('t1', 'U') IS NOT NULL DROP TABLE t1 GO CREATE TABLE t1 ( id INT IDENTITY (1, 1) NOT NULL PRIMARY KEY CLUSTERED , d CHAR(250) NOT NULL DEFAULT '' ) GO DECLARE @count INT = 0 , @dt DATETIME = GETDATE() WHILE @count < 500000 BEGIN INSERT t1 DEFAULT VALUES SET @count += 1 END SELECT DATEDIFF(MILLISECOND, @dt, GETDATE()) -- 23 second GO CHECKPOINT IF OBJECT_ID('t2', 'U') IS NOT NULL DROP TABLE t2 GO CREATE TABLE t2 ( id UNIQUEIDENTIFIER DEFAULT NEWID() NOT NULL PRIMARY KEY CLUSTERED , d CHAR(250) NOT NULL DEFAULT '' ) GO DECLARE @count INT = 0 , @dt DATETIME = GETDATE() WHILE @count < 500000 BEGIN INSERT t2 DEFAULT VALUES SET @count += 1 END SELECT DATEDIFF(MILLISECOND, @dt, GETDATE()) -- 23 second GO CHECKPOINT IF OBJECT_ID('t3', 'U') IS NOT NULL DROP TABLE t3 GO CREATE TABLE t3 ( id UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() NOT NULL PRIMARY KEY CLUSTERED , d CHAR(250) NOT NULL DEFAULT '' ) GO DECLARE @count INT = 0 , @dt DATETIME = GETDATE() WHILE @count < 500000 BEGIN INSERT t3 DEFAULT VALUES SET @count += 1 END SELECT DATEDIFF(MILLISECOND, @dt, GETDATE()) -- 23 second GO CHECKPOINT GO SELECT t.[name] , size , s.avg_fragmentation_in_percent , s.avg_page_space_used_in_percent FROM sys.objects t JOIN ( SELECT p.[object_id] , size = SUM(a.total_pages) * 8. / 1024 FROM sys.partitions p JOIN sys.allocation_units a ON p.[partition_id] = a.container_id GROUP BY p.[object_id] ) i ON t.[object_id] = i.[object_id] CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), i.[object_id], NULL, NULL, 'DETAILED') s WHERE t.is_ms_shipped = 0 AND i.[object_id] > 255 AND t.[type] = 'U' AND s.index_level = 0
Скорость выполнения в миллисекундах:
-------- ----------- t1 24080 t2 24256 t3 22280
Ожидания:
name wait_type wait_time wait_resource wait_signal -------- ----------------------- ----------- ---------------- ------------ t1 WRITELOG 8.8480 6.7930 2.0550 t2 WRITELOG 8.9310 6.9120 2.0190 t3 WRITELOG 8.2180 6.2340 1.9840
И самое интересное (так в чем же различие):
name size avg_fragmentation_in_percent avg_page_space_used_in_percent -------- ------------- ---------------------------- ------------------------------ t1 130.757812 0,365992680146397 97,4529651593773 t2 197.320312 99,0648999243962 67,572658759575 t3 135.632812 0,666975988864401 98,5015196441809
А то, что в случае использования NEWID() у нас будут чаще происходить операции разбиения страниц, соответственно и фрагментация будет выше (оттого больше логических чтений при работе с этой таблицей).
Кроме того, в этот пост еще хорош для ознакомления Первичный ключ – GUID или автоинкремент?
Если короче, то в общем поддерживаю точку зрения BalinTomskjobgemws
24.02.2017 09:45Для тестов нужно брать не маленькие, а большие таблицы, где более чем 1 млн строк, т к чем меньше записей в таблице, тем больше прощается как в самих запросах, так и в проектировании этой таблицы.
А вообще лучше взять таблицу, где скажем 10 млрд записей и протестировать Вашими тестами.
jobgemws
24.02.2017 10:24А то, что в случае использования NEWID() у нас будут чаще происходить операции разбиения страниц, соответственно и фрагментация будет выше (оттого больше логических чтений при работе с этой таблицей).
В любом случае фрагментация будет зависеть от порядка назначения ключа. Тесты лучше делать на больших данных
jobgemws
24.02.2017 10:26Кроме того, в этот пост еще хорош для ознакомления Первичный ключ – GUID или автоинкремент?
В этой статье опять же рассматривали таблицу небольшую.
Чтобы увидеть как работает B-дерево, нужно много данных.
kolu4iy
Эм… А если у нас 20 ядер на каждой ноде — нам тоже выставлять max degree в 1?
Я просто очень часто встречаю данную рекомендацию, но реально её пришлось трогать только в системе, которая написана не очень понимающими механизм работы ms sql людьми, и потому мощно генерирующую некешируемые ad-hoc запросы… Кстати, на той системе всего 8 ядер, но 1 — это не то, что стоит советовать. Стенд из 20 клиентов-роботов генерировал нагрузку, а мы подбирали подходящую величину. Так вот: разумным компромисом между временем выполнения и нагрузкой на ядра хоста оказалась цифра 3.
jobgemws
Благодарю за Ваш описанный пример
Да, мы тоже проводили ряд исследований, и в статье написано когда лучше отключать параллелизм, а когда нет (это общая рекомендация, которая не говорит всегда выключать параллелизм, а только в определенных случаях). Тесты мы проводили на серверах, у которых свыше 12 ядер, но на которых стоят экземпляры MS SQL Server 2012-2014 Standart (т е больше 4-х ядер все равно не будет использовать). Но смысл был в том, что при исследовании было выявлено, что параллелизм может породить неэффективный план при хотя бы одном из 3-х условий, которые и описаны в статье. Однако, прошу заметить, что в статье не писалось о том, что всегда нужно запрещать параллелизм. В свое время обратил внимание на то, что при установке системы 1С этот параметр выставляется у скуля в 1, т е почему-то разработчики 1С считают, что в большинстве случаев лучше запрещать параллелизм. Но на самом деле это не всегда так.
Shaz
А можете раскрыть этот момент подробнее? То есть для этой редакции нету смысла использовать CPU с кол-вом ядер более 4-х?
jobgemws
Увы да-Standart более 4-х не использует
AlanDenton
Вообще-то для редакции Standart до 16 ядер SQL Server 2008-2014 видит. Для SQL Server 2016 этой же редакции увеличили до 24.
jobgemws
Спасибо за замечание, да имелось в виду не более 4-х процессоров и не более 16 ядер