
Функциональный язык программирования Elixir набирает популярность, а один из последних фреймворков для создания одностраничных приложений — Angular 2 — недавно вышел в релиз. Давайте познакомимся с ними в паре статей, создав с нуля полноценный back-end на Elixir и Phoenix Framework, снабжающий данными клиентское приложение-frontend на базе Angular 2.
Hello, world — не наш вариант, поэтому сделанное при необходимости можно будет применить в реальных проектах: весь представленный код выложен под лицензией MIT.
Объем статьи большой огромный! Надеюсь на столь же огромное количество комментариев — любых. Не раз замечал, что из комментариев получаешь не меньше, чем от основной статьи, а иногда и больше.
В первой статье будет несколько вступительных слов и работа над back-end. Поехали!
Введение
Несколько месяцев назад мне предложили в качестве субподрядчика реализовать в очень сжатые сроки прототип веб-приложения; из требований присутствовали только функционал, крайняя дата окончания и небходимость использования исключительно open source инструментов. "Отлично", — подумал я — "это прекрасный повод применить на практике связку Elixir/Phoenix Framework и Angular 2", благо последний незадолго до того вышел в релиз. Проект в результате был реализован вовремя, заказчик остался доволен, опыт пополнился реализацией новых задач.
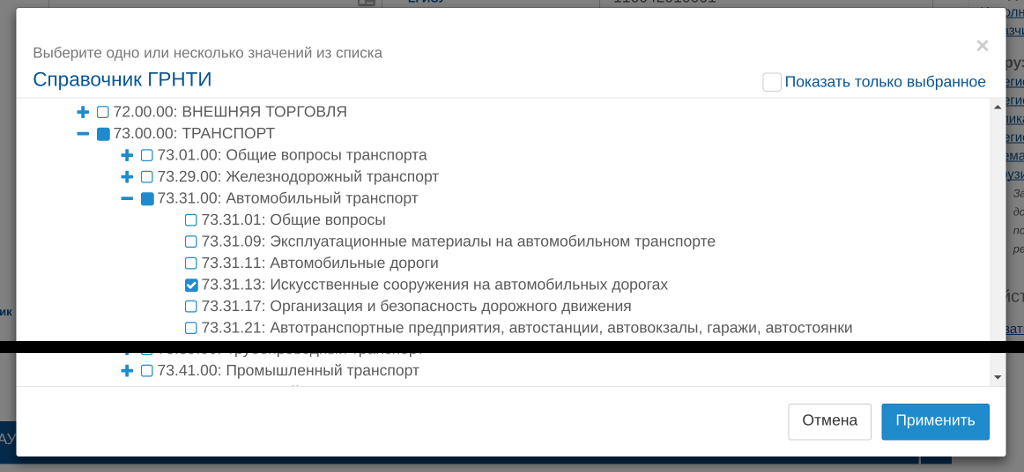
Одной из таких задач оказалась необходимость отображения справочников ГРНТИ и OECD FOS с возможностью выбора нескольких значений. Так как готовых решений для вывода древовидного справочника нормальной степени готовности не нашлось, пришлось изобретать свой велосипед. Кроме того, это дало тему для настоящего цикла "обучающих" статей для знакомства одновременно и с Elixir/Phoenix Framework, и с Angular 2.
Итак, по окончанию этого цикла у нас появится рабочий back-end на Elixir и Phoenix Framework, отдающий с помощью API содержание справочников ГРНТИ и OECD FOS на независимый front-end на Angular 2, на котором можно будет вызывать форму вывода полученных данных со множественным выбором разделов\подразделов, сохранить (получить за пределы окна выбора) и восстановить выбранное при открытии. Внешний вид нам обеспечит Twitter Bootstrap. Реализацию справочника на front-end мы оформим в виде отдельного модуля, который можно будет использовать в дальнейшем с любыми проектами.
Некоторые пояснения по реализации
Справочник ГРНТИ представляет из себя трёхуровневую (максимум) структуру, каждая запись которой имеет код в десятичной классификации, состоящий из трех групп чисел от 00 до 99, разделённых точкой, а так же название. Справочник на данный момент включает около 8 000 записей разделов и подразделов, объем в плоском текстовом виде — более 400 кб. С содержанием справочника можно ознакомиться на grnti.ru (не имею никакого отношения к этому ресурсу).
OECD FOS также имет трёхуровневую структуру с иерархическим кодом, разделённым точкой, однако, в отличие от предыдущего варианта, в данном случае последняя группа кода является сочетаением двух латинских букв. Записей в справочнике существенно меньше — чуть менее 300, а общий объем — около 8кб. К сожалению, в онлайне мне не удалось найти хоть насколько-то актуальных версий этого справочника, так что воспользуемся тем, что нашлось по другим каналам.
Из-за объёма справочника ГРНТИ при работе с ним мы будем запрашивать с back-end только те разделы, которые нам нужны в настоящий момент, а вот OECD FOS можно отдавать целиком и обрабатывать структуру уже на клиенте.
Сразу хочу уточнить: задача несколько вырожденная, она являлась лишь частью более широкого функционала. Естественно, если задача состоит только в выводе справочников (например, в информационных целях), то ни back-end, ни SPA не нужны.
Также нисколько не претендую на звание гуру, и если предложите более эффективную реализацию любой части, буду благодарен за науку: учиться я люблю.
Пожалуйста, обратите внимание: код, вывод утилит и некоторые расширенные пояснения спрятаны под спойлер с целью хоть как-то повысить удобство чтения и использования.
Выбор стека технологий
В наше время вертикальное наращивание мощности обходится всё дороже, и производительности добиваются не увеличением частоты, а горизонтально, путём добавления новых вычислительных ядер. Из-за этого всё больший интерес вызывают языки, специализирующиеся на конкурентных вычислениях (параллельном выполнении). При этом совместный доступ к общим данным становится серьёзной головной болью, значительно уменьшить которую могут функциональные языки программирования.
Elixir — довольно молодой, компилируемый в байт-код функциональный язык, написанный на Erlang и исполняющийся в его виртуальной машине Beam. Язык наследует все достоинства Erlang:
- функциональность,
- иммутабельность,
- "всё — процесс",
- процессы изолированы друг от друга,
- очень низкую стоимость создания и уничтожения процессов,
- каждый процесс имеет уникальный идентификатор (PID) и ему опционально может быть назначено уникальное имя,
- нет разделения ресурсов между процессами,
- можно отправить сообщение из любого процесса в любой процесс, если вы знаете его имя\идентификатор,
- обмен сообщениями — единственный способ межпроцессных коммуникаций,
- pattern matching (сопоставление с образцом),
- идеологию "делай то, что требуется, или просто умри",
- лёгкость создания распределённых систем;
и при этом имеет более простой синтаксис, в чём-то похожий на Ruby, полиморфизм через механизм протоколов, очень богатые возможности мета-программирования, возможности для лёгкого создания документации с Markdown-разметкой и реальным тестированием примеров (!!!) прямо в коде модулей. Важно, что все функции Erlang и написанных для него библиотек могут быть вызваны напрямую из кода Elixir без какой-либо потери производительности.
Язык просто провоцирует использовать многопроцессность и обмен сообщениями, благо на написание полноценного модуля процесса с обменом сообщениями нужно потратить буквально пару минут (надеюсь, к этому мы вернёмся в следующих публикациях, если реакция на этот цикл будет положительной).
Много значит и активное участие автора языка — Jose Valim — в жизни комьюнити. Он с удовольствием подробно отвечает на вопросы и при необходимости вносит недостающую функциональность в язык\библиотеки (к примеру, в Ecto, о которой пойдёт речь дальше — есть личный положительный опыт).
Phoenix Framework — наиболее популярный веб-фреймворк для Elixir, реализующий шаблон MVC и значительно упрощающий разработку веб-приложений. Кроме того, Phoenix имеет Channels — возможность realtime-коммуникаций с приложением через websockets, и это реально killer feature. Существует JavaScript-компонент для использования с браузерами, а так же реализации для некоторых других языков, например, для Java под Android.
Angular 2 — фреймворк для разработки клиентской части одностраничных (single page) веб-приложений, в основном поддерживаемый Google. Версия два была полностью переписана с учётом опыта, полученного во время разработки и эксплуатации AngularJS. Релиз был выпущен в сентябре 2016 года.
Back-end на Elixir и Phoenix Framework
Если вы до этого не сталкивались с Elixir, очень рекомендую начать с изучения языка. Планирую давать подробные объяснения используемым подходам и особенностям, но полноценно в рамках небольшого цикла статей охватить всё невозможно (это если не считать того, что и я сам постоянно нахожу что-то новое). Для изучения есть как базовое введение на сайте проекта, так и множество других ресурсов в Интернет. Очень полезен форум, где с огромным удовольствием отвечает и создатель языка. Кстати, отличный ответ-пример на вопрос "стоит ли сначала изучить Elixir или сразу броситься на амбразуру" можно увидеть в этом треде на Reddit. В качестве резюме могу сказать, что автор топика был разочарован незначительной разницей в производительности тестового примера, написанного на Ruby и "на Elixir" (как он считал). Код на Ruby выполнялся за 4.221 секунды, на Elixir — 5.923 cекунды. После того, как код переписали, используя особенности языка (а не просто портировав один-в-один с Ruby), он начал работать в три (!!!) раза быстрее.
Сказав правильные вещи, скажу и крамольное: сам так делаю редко, и обычно бросаюсь сразу в бой.
Установка инструментария и начало проекта
Для управления версиями Erlang, Elixir и node (который в дальнейшем понадобится для работы с front-end) я использую менеджер пакетов asdf. Существует прекрасный gist, в котором очень подробно описан процесс установки зависимостей под Fedora и Ubuntu, asdf, Erlang и Elixir, поэтому повторяться не буду. Он на английском, но там достаточно копипаста. Последние версии на момент написания статьи: Erlang — 19.2, Elixir — 1.4.1.
Так же вам понадобится PostgreSQL одной из последних версий (использую 9.6 на данный момент), который вы можете установить с помощью стандарных менеджеров пакетов вашего дистрибутива\ОС.
После установки Erlang и Elixir нужно установить Phoenix Framework.
В Elixir для создания, компиляции, тестирования проектов, а так же управления их зависимостями существует специальная утилита автоматизации — Mix (стоит обратить внимание ещё и на эту часть документации). Утилита mix — она как make, только удобнее.
Для начала с её помощью установим (очередной) менеджер пакетов Hex командой
$ mix local.hexа затем — архив Phoenix Framework:
$ mix archive.install https://github.com/phoenixframework/archives/raw/master/phoenix_new.ezДокументация упоминает о необходимости node.js, однако так как в данном случае Phoenix нам будет обеспечивать только API, то node нам понадобится позже, когда мы перейдём к Angular 2.
В момент написания статьи актуальным был Phoenix Framework версии 1.2.1.
Стоит сказать пару слов и о Hex. Существует единый репозиторий https://hex.pm, в котором публикуются библиотеки для Elixir/Erlang. По умолчанию все зависимости проектов на Elixir ищутся именно там.
Установив необходимое ПО, перейдём в нужную нам директорию и создадим новый проект Phoenix, запустив:
$ mix phoenix.new atv_api --no-brunch --no-html
* creating atv_api/config/config.exs
* creating atv_api/config/dev.exs
* creating atv_api/config/prod.exs
...
* creating atv_api/priv/static/images/phoenix.png
* creating atv_api/priv/static/favicon.ico
Fetch and install dependencies? [Yn] y
* running mix deps.get
We are all set! Run your Phoenix application:
$ cd atv_api
$ mix phoenix.server
You can also run your app inside IEx (Interactive Elixir) as:
$ iex -S mix phoenix.server
Before moving on, configure your database in config/dev.exs and run:
$ mix ecto.create
$Мы создаём новый проект без шаблонов html и без поддержки brunch, так как клиентская часть будет в отдельном проекте.
Советую сразу же изменить настройки подключения к базе данных в конфигурационных файлах config/prod.exs, config/dev.exs и config/test.exs для режимов production, разработки и тестирования соответственно.
Кроме того, если вы используете Elixir версии 1.4 и выше и текущая версия Phoenix всё ещё 1.2.1, я рекомендую несколько изменить файл mix.exs. Elixir 1.4 принёс несколько новых возможностей, в частности, упростил добавление зависимостей, имеющих собственные деревья процессов, требующих запуска при старте проекта. Если раньше такие зависимости (а их большинство) было необходимо добавить и в список зависимостей (deps), и в список приложений для запуска (applications), то сейчас достаточно только первого: mix сам разберётся, является ли зависимость приложением, и запустит его. Указывать необходимо только приложения, не перечисленные в зависимостях. Давайте приведём метод, возвращающией описание приложений, к следующему виду:
# mix.exs
...
# Configuration for the OTP application.
#
# Type `mix help compile.app` for more information.
def application do
[mod: {AtvApi, []},
extra_applications: [:logger]]
end
...Если вы сравните с тем, что было раньше, то увидите, что исчез список, имевший ключ :applications и добавился новый — :extra_applications, в котором остался только :logger, а всё, что перечислено в зависимостях — исключено.
Сделав это, запустите создание базы данных с помощью mix ecto.create. Окружение по-умолчанию — dev, соответственно, будет создана база данных для этой среды, стандартно называться которая будет atv_api_dev.
В любой момент вы сможете удалить базу данных, запустив задачу mix ecto.drop. При этом mix ecto.reset удалит базу данных, создаст новую, запустит миграции и выполнит содержимое seeds.exs для первоначального заполнения данных (подробнее о последнем далее).
Добавив перед mix переменную, инициализированную нужным значением — MIX_ENV=prod, MIX_ENV=dev (по-умолчанию) или MIX_ENV=test, — вы сможете выполнять требуемые задачи в соответствующей среде.
Справочник OECD FOS
Так как справочник OECD FOS более прост, начнём с него.
Для работы с данными в Phoenix используется библиотека Ecto. Ecto — это DSL для работы с таблицами баз данных через представления (модели) и для написания запросов к базе данных. Ecto, в отличие от Rails ActiveRecords, очень простой (берёт на себя минимум), но в то же время мощный инструмент.
Генераторы кода
В Phoenix Framework существуют генераторы кода разного вида, способные создать полный комплект из миграции, модели, контроллера, реализующего CRUD, модулей представления (view), генерирующих json, а так же базовых тестов. В случае обоих справочников нам не нужен полноценный CRUD, однако для OECD FOS можно начать со сгенерированного кода и убрать лишнее.
В таблице справочника OECD FOS у нас будет два поля: id и title, оба с типом text. (Почему text? Потому что если нет разницы, то зачем распыляться?)
Воспользуемся генератором и ведём:
$ mix phoenix.gen.json Fos fos title:text
* creating web/controllers/fos_controller.ex
* creating web/views/fos_view.ex
* creating test/controllers/fos_controller_test.exs
* creating web/views/changeset_view.ex
* creating web/models/fos.ex
* creating test/models/fos_test.exs
* creating priv/repo/migrations/20170215194144_create_fos.exs
Add the resource to your api scope in web/router.ex:
resources "/fos", FosController, except: [:new, :edit]
Remember to update your repository by running migrations:
$ mix ecto.migrateЗдесь phoenix.gen.json — это задача утилиты mix (mix task), Fos — название модели в единственном числе, fos — название для таблицы, по конвенции тут должно быть название модели с маленькой буквы во множественном числе, а далее идёт описание полей. В данном случае мы хотим видеть в модели поле с именем title и типом text (это тип данных PostgreSQL). По поводу поля id поговорим чуть позже. Список задач mix можно получить, запустив команду mix help, а подробнее о задачах phoenix расказано в документации.
После завершения выполнения команды нам будет предложено добавить строку resources "/fos", FosController, except: [:new, :edit] в файл web/router.ex. Давайте пока сделаем это (в дальнейшем мы это изменим):
defmodule AtvApi.Router do
use AtvApi.Web, :router
pipeline :api do
plug :accepts, ["json"]
end
scope "/api", AtvApi do
pipe_through :api
resources "/fos", FosController, except: [:new, :edit]
end
endТакже будет предложено запустить процесс миграции, но не стоит спешить. По-умолчанию Ecto генерирует модель и миграцию (скрипт для создания таблицы в базе данных) с автоинкрементным полем id типа integer в качестве первичного ключа, однако нам не нужно поле такого типа, так как в качестве ключа мы будем использовать код раздела. Изменим это поведение для нашей модели.
Начнём с файла миграции. Генератор моделей создаёт миграции в директории priv/repo/migrations. Откройте файл, который заканчивается на _create_fos.exs и приведите его к следующему виду:
defmodule AtvApi.Repo.Migrations.CreateFos do
use Ecto.Migration
def change do
create table(:fos, primary_key: false) do
add :id, :text, null: false, primary_key: true
add :title, :text
timestamps()
end
end
endКод в Elixir организован в виде модулей и функций. Каждый модуль определяется макросом defmodule, описание функций — макросом def или defp. Пока не обращайте внимание на use, мы вернёмся к этому позже. Данный модуль миграции имеет название AtvApi.Repo.Migrations.CreateFos, причём оно сформировано для удобства исходя из конвенции. Язык не заставляет давать именно такие названия, и язык не обязывает вас иметь всю цепочку с "родительскими" модулями типа AtvApi.Repo.Migrations и AtvApi.Repo.
Мы добавили опцию primary_key: false к макросу создания таблицы create/2. Этим мы отменяем создание стандартного поля id и ниже добавляем вручную поле с тем же именем, но c типом text, которое станет первичным ключом.
Поправим описание модели, расположеное в директории web/models:
defmodule AtvApi.Fos do
use AtvApi.Web, :model
@primary_key {:id, :string, autogenerate: false}
schema "fos" do
field :title, :string
timestamps()
end
@doc """
Builds a changeset based on the `struct` and `params`.
"""
def changeset(struct, params \\ %{}) do
struct
|> cast(params, [:id, :title])
|> validate_required([:id, :title])
end
endОбратите внимание, мы добавили константу @primary_key с описанием первичного ключа. Также мы добавили атом с именем поля :id в список разрешённых к изменению (см. описание функции cast/3, последний параметр allowed) — в противном случае мы не сможем добавить к набору изменений (changeset) поле с заданным нами кодом; этот же атом добавлен в список функции-валидатора validate_required/2, которая, как понятно из названия, проверяет наличие соответствующего поля в наборе изменений (changeset) и в случае его отсутствия помечает набор как ошибочный.
Стоит отметить вызов макроса timestamps/1, который добавляет в схему модели поля inserted_at и updated_at, имеющие тип timestamp. Первое поле инициализируется текущим временем в момент создания, второе — при каждом изменении записи функциями Ecto.
Здесь также нужно сказать пару слов о том, что же из себя представляет модель.
В Elixir существует понятие "структуры" (struct). Структура — это расширение ассоциативного массива (т.е. хранилища пар ключ-значение, стандартно обозначаемого как %{ key => value, ...}, а в случае, если ключ является атомом, то %{ key: value, ...}); структура имеет дополнительный ключ __struct__, значение которого содержит её имя, и ограничена только теми полями, которые заданы в коде на момент компиляции. При попытке добавить в структуру значение с ключом, не описанным в ней на момент компиляции, будет сгенерирована ошибка. Определяется структура с помощью конструкта defstruct и получает имя модуля, в котором описана:
iex> defmodule User do
...> defstruct title: "John", age: 27
...> endСписок ключевых слов, использованных с defstruct, определяет поля, которые может и будет содержать эта структура, вместе с их значениями по умолчанию. В примере выше структура получит имя %User{}.
Как было сказано, структура — это расширение ассоциативного массива, поэтому все функции модуля Map будут с ними работать. Однако при этом протокол Enumerable для структур не реализован, поэтому модуль Enum с ними работать не будет.
Остаётся добавить, что модель — это структура, получаемая с помощью мета-программирования (об этом ниже) из описания, заключённого в блок do ... end макроса scheme. Наша модель, описанная в модуле AtvApi.Fos, будет иметь тип %Fos{} и содержать поля-ключи :id (по умолчанию) и :title (определённый явно).
За более подробной информацией о структурах добро пожаловать в документацию.
Давайте запустим сгенерированные тесты модели, чтобы проверить правильность нашего кода:
$ mix test test/models/fos_test.exs
Compiling 7 files (.ex)
Generated atv_api app
1) test changeset with valid attributes (AtvApi.FosTest)
test/models/fos_test.exs:9
Expected truthy, got false
code: changeset.valid?()
stacktrace:
test/models/fos_test.exs:11: (test)
.
Finished in 0.05 seconds
2 tests, 1 failure
Randomized with seed 166025Если вы откроете файл с автоматически сгенерированным тестом test/models/fos_test.exs, то заметите, что константе под названием @valid_attrs соответствует ассоциативный массив, в котором отсутствует ключ id. Как мы помним, по-умолчанию поле id целочисленное автоинкрементное, и не должно изменяться программой. Однако не в нашем случае — не зря мы включили в модель проверку на его наличие. Давайте изменим константу следующим образом:
@valid_attrs %{title: "Humanities, multidisciplinary", id: "0605BQ"}и снова запустим тест:
$ mix test test/models/fos_test.exs
..
Finished in 0.04 seconds
2 tests, 0 failures
Randomized with seed 892257Убедишись на тестовой базе, что модель работает так, как нужно, можно запустить процесс миграции:
$ mix ecto.migrate
17:54:26.080 [info] == Running AtvApi.Repo.Migrations.CreateFos.change/0 forward
17:54:26.080 [info] create table fos
17:54:26.097 [info] == Migrated in 0.0sКстати, последнюю на данный момент времени выполненную миграцию можно откатить командой mix ecto.rollback.
Заполнение таблицы данными справочника
Создадим теперь функцию для первоначального заполнения таблицы. В дальнейшем в рамках этого цикла нам не придётся изменять данные в таблицах, так как справочники являются стандартными и заполняются при первоначальной инициализации базы данных.
Стандартно заполнение таблицы первоначальными данными происходит из файла priv/repo/seeds.exs. Скачайте текстовый файл oecd_fos.txt и файл grnti.txt (он пригодится нам позднее) со справочниками и поместите их в ту же директорию priv/repo. Теперь создадим код для парсинга и записи данных в базу. Добавьте после имеющихся в файле комментариев следующий код:
require Logger
alias AtvApi.Repo
import Ecto.Query
### OECD FOS dictionary ###
alias AtvApi.Fos
unless Repo.one!(from f in Fos, select: count(f.id)) > 0 do
multi = File.read!("priv/repo/oecd_fos.txt")
|> String.split("\n")
|> Enum.reject(fn(row) -> byte_size(row) < 1 end)
|> Enum.sort
|> Enum.dedup
|> Enum.reduce(Ecto.Multi.new, fn(row, multi) ->
[id, title] = row
|> String.trim
|> String.split(";")
changeset = Fos.changeset(%Fos{}, %{id: id, title: title})
Ecto.Multi.insert(multi, id, changeset)
end)
Repo.transaction(multi)
Logger.info "OECD FOS load complete"
end
### OECD FOS dictionary ###Давайте последовательно пройдёмся по коду. Для начала мы требуем (require) наличия модуля Logger в момент компиляции.
В Elixir макросы релизуют механизм мета-программирования (т.е. написания кода, который генерирует код). Макрос — это фрагмент кода, который выполняется и раскрывается (т.е. подменяется результатом исполнения) непосредственно перед компиляцией. Это означает, что чтобы воспользоваться макросами, необходимо гарантировать, что содержащий их модуль и реализация доступны в момент компиляции. Директива require служит именно для этого.
Директива alias позволяет сократить имя модуля, в данном случае использовать Repo вместо AtvApi.Repo. Следующая директива — import — добавляет в текущее пространство имён функции из соответствующего модуля (в нашем случае — Ecto.Query, что позволяет строить запросы к базе данных прямо в коде программы). При желании (а, согласно рекомендациям разработчиков, это желание должно возникать всегда) можно ограничить импортируемые функции, добавив only: [function_title: arity], например, так: import Ecto.Query, only: [from: 2] (arity — это число аргументов у функции). Предназначена эта возможность для удобства — если вы часто вызываете какую-то функцию другого модуля, в некоторых случаях удобно её импортировать. Обратите внимание — импортируются только определения (имена) функций, но не их реализация, она остаётся в импортируемом модуле, и все вызовы из импортированных функций будут осуществляться внутри модуля, в котором функции реализованы. Более подробно об этих и других директивах сказано в документации.
Чтобы не добавить данные ещё раз в случае повторного запуска seeds.exs, введём проверку на наличие записей в таблице. Для этого с помощью функци Repo.one!/2 получим результат запроса к базе данных, который должен транформироваться в SQL вида SELECT COUNT(f.id) FROM fos AS f, и если он не больше нуля, выполним блок кода.
Согласно конвенции, в языке зачастую принято иметь пару функций с [почти] одним именем, одна из которых выдаёт кортеж (tuple) типа {:ok, result} или {:error, description}, а вторая, оканчивающаяся восклицательным знаком, в случае успеха возвращает результат, а в случае ошибки вызывает исключение.
Например:
iex> File.read("file.txt")
{:ok, "file contents"}
iex> File.read("no_such_file.txt")
{:error, :enoent}
iex> File.read!("file.txt")
"file contents"
iex> File.read!("no_such_file.txt")
** (File.Error) could not read file no_such_file.txt: no such file or directoryДалее присутствует блок кода, использующий оператор конвейера (pipe operator). Этот оператор берёт результат выполнения предыдущей функции и передаёт его следующей функции в качестве первого аргумента. Например, записи (2) и (3) аналогичны, равно как и (4) и (5), при этом вторые варианты более читабельны:
iex(1)> some_map = %{one: 1}
%{one: 1}
iex(2)> Enum.count(some_map)
1
iex(3)> some_map |> Enum.count()
1
iex(4)> Enum.count(Map.put(some_map, :two, 2))
2
iex(5)> some_map |> Map.put(:two, 2) |> Enum.count()
2Таким образом, мы:
- читаем содержимое файла (
File.read!/1), получая строковое значение, - создаём из этого значения список (List) из элементов-строк с помощью функции
String.split/3, используя в качестве разделителя перевод строки\n, - убираем из списка элементы, размер которых меньше единицы, с помощью функции
Enum.reject/2, возвращающей новый список из элементов, для которых переданная в качестве второго параметра функция вернулаfalse, - сортируем список с помощью функции
Enum.sort/1, - убираем дубликаты повторяющихся элементов с помощью функции
Enum.dedup/1, - и, наконец, передаём отфильтрованный список функции
Enum.reduce/3, на которой остановимся подробнее.
Enum.reduce(enumerable, acc, fun), как и все функции модуля Enum, получает на вход элемент, реализующий протокол Enumerable (перечисляемое), и начальное значение аккумулятора, который будет собирать результаты работы функции, передаваемой третьим параметром. Эта функция в качестве параметров получает следующий элемент перечисляемого и текущее значение аккумулятора, совершает действия с элементом и аккумулятором и в конце возвращает новое состояние последнего. После перебора всех элементов списка Enum.reduce/3 возвращает конечное состояние аккумулятора.
В данном случае в качестве аккумулятора выступает инициализированная структура Ecto.Multi для объединения операций с базой данных.
В коде анонимной функции в правой части первого выражения значение полученного ей элемента подаётся через оператор конвейера в качестве первого параметра в функцию String.trim/1, удаляющую white-space из начала и окончания строки; результат её работы подаётся на вход функции String.split/3, о которой мы говорили чуть раньше. Файл oecd_fos.txt содержит строки с кодом и наименованием разделов, разделённые точкой с запятой. String.split/3 с такой строкой вернёт список, состоящий из двух элементов. Первый элемент этого списка благодаря сопоставлению с образцом (pattern matching) будет присвоен переменной id, второй — переменной title.
Сопоставление с образцом (pattern matching) — очень важная и полезная особенность Elixir. Примеры его использования мы ещё рассмотрим в дальнейшем, пока же следует знать, что = (знак равно) — не оператор присваивания, а оператор сопоставления (match operator). Единственная переменная слева может быть сопоставлена результату любого выражения в правой части, поэтому в этом случае он выступает аналогом оператора присваивания:
iex> x = 1
1
iex> x
1Однако если сделаем немного иначе, то получим ошибку:
iex> 1 = x
1
iex> 2 = x
** (MatchError) no match of right hand side value: 1В первом случае переменная x содержит 1, поэтому левая часть может быть успешно сопоставлена с правой.
Однако двойка не может быть сопоставлена с единицей, поэтому генерируется ошибка.
С помощью сопоставления с образцом можно деструктурировать более сложные объекты нужным нам образом:
iex> {a, b, c} = {:hello, "world", 42}
{:hello, "world", 42}
iex> a
:hello
iex> b
"world"Или более сложный вариант:
iex> {a, b, {d, e} = c} = {:hello, "world", {:grey, "hole"}}
{:hello, "world", {:grey, "hole"}}
iex> a
:hello
iex> b
"world"
iex> c
{:grey, "hole"}
iex> d
:grey
iex> e
"hole"При этом если части не соответствуют друг другу, будет сгенерирована ошибка. К примеру, если если кортежи имеют разные размеры:
iex> {a, b, c} = {:hello, "world"}
** (MatchError) no match of right hand side value: {:hello, "world"}То же самое произойдёт и в случае, если по разные стороны оператора соответствия мы поместим разные типы данных:
iex> {a, b, c} = [:hello, "world", 42]
** (MatchError) no match of right hand side value: [:hello, "world", 42]Однако ещё более интересным является то, что можно делать сопоставление с конкретным значением. В примере ниже левая часть будет соответствовать правой только в том случае, если первым элементом кортежа будет атом :ok :
iex> {:ok, result} = {:ok, 13}
{:ok, 13}
iex> result
13
iex> {:ok, result} = {:error, :oops}
** (MatchError) no match of right hand side value: {:error, :oops}Больше информации и примеров можно найти в документации, ссылка на которую есть выше.
Дополнительно пока стоит упомянуть только о наличии оператора-булавки (pin operator). Думаю, вы обратили внимание на то, что, в отличие от некоторых других функциональных языков, Elixir имеет локальные переменные, и их значения действительно могут меняться. Однако что же делать, если нам нужно провести операцию сопоставления со значением переменной в левой части выражения? Как раз тут и придёт на помощь pin operator:
iex> x = 1
1
iex> ^x = 2
** (MatchError) no match of right hand side value: 2
iex> {y, ^x} = {2, 1}
{2, 1}
iex> y
2
iex> {y, ^x} = {2, 2}
** (MatchError) no match of right hand side value: {2, 2}Так как мы присвоили переменной x значение 1, последний пример можно переписать так:
iex> {y, 1} = {2, 2}
** (MatchError) no match of right hand side value: {2, 2}Далее мы создаём набор изменений (changeset) с помощью функции AtvApi.Fos.changeset/2, которую для этого реализовали в модуле нашей модели таблицы справочника OECD FOS (точнее, сформировал её генератор, а мы поправили, добавив в списки полей :id). В результате выполнения этой функции будет получен результат с типом данных Ecto.Changeset.
Как можно понять из документации, модуль Ecto.Changeset позволяет произвести фильтрацию, преобразования, проверку на корректность (валидировать) и определить (описать) ограничения (constraints) при работе со структурами (а мы уже выяснили выше, что модели — это структуры). Результатом выполнения любой функции из модуля Ecto.Changeset будет являться "набор изменений", т.е. changeset. Для создания changeset обычно используются функция cast/3 и функция change/2. Первая служит для преобразования и проверки внешних параметров, таких, как данные, полученные из форм, через API, из коммандной строки и т.д., а вторая — для изменения данных непосредственно из приложения. Остальные функции модуля для валидации, проверки ограничений, управления ассоциациями (связями с другими моделями) служат для работы с наборами изменений.
Если мы посмотрим на функцию AtvApi.Fos.changeset/2, то увидим там ряд функций из модуля Ecto.Changeset, первая из которых — cast/3 — получает на вход структуру (struct), набор данных (params) и создаёт набор изменений, вставив из набора данных значения тех полей структуры, которые перечисленны в списке, переданном третьим параметром ([:id, :title]). Следующая функция проверяет, что набор изменений содержит значения для полей, пререданных вторым параметром (тот же список, что и выше). Результирующий набор изменений можно передать и далее, например, добавив проверку минимальной и длины поля :id:
|> validate_length(:id, min: 6)Обратите внимание, что функции валидации не генерируют исключение, они добавляют описание ошибки в набор изменений и выставляют значение ключа valid? в false. Ошибка будет выдана при попытке выполнить операцию добавления или изменения записи.
Например:
iex> valid = AtvApi.Fos.changeset(%AtvApi.Fos{}, %{id: "123", title: "Some title"})
#Ecto.Changeset<action: nil, changes: %{id: "123", title: "Some title"},
errors: [], data: #AtvApi.Fos<>, valid?: true>
iex> invalid = valid |> Ecto.Changeset.validate_length(:id, min: 6)
#Ecto.Changeset<action: nil, changes: %{id: "123", title: "Some title"},
errors: [id: {"should be at least %{count} character(s)",
[count: 6, validation: :length, min: 6]}], data: #AtvApi.Fos<>,
valid?: false>
iex> AtvApi.Repo.insert!(invalid) # "опасная" функция, ошибка времени исполнения
** (Ecto.InvalidChangesetError) could not perform insert because changeset is invalid.
Applied changes
%{id: "123", title: "Some title"}
Params
%{"id" => "123", "title" => "Some title"}
Errors
%{id: [{"should be at least %{count} character(s)",
[count: 6, validation: :length, min: 6]}]}
Changeset
#Ecto.Changeset<action: :insert, changes: %{id: "123", title: "Some title"},
errors: [id: {"should be at least %{count} character(s)",
[count: 6, validation: :length, min: 6]}], data: #AtvApi.Fos<>,
valid?: false>
(ecto) lib/ecto/repo/schema.ex:134: Ecto.Repo.Schema.insert!/4
iex> AtvApi.Repo.insert(invalid) # "безопасная" функция, возвращает кортеж {:error, description}
{:error,
#Ecto.Changeset<action: :insert, changes: %{id: "123", title: "Some title"},
errors: [id: {"should be at least %{count} character(s)",
[count: 6, validation: :length, min: 6]}], data: #AtvApi.Fos<>,
valid?: false>}Думаю, вы уже поняли, что для добавления или изменения записи в базе данных нужно создать набор изменений, что мы и сделали.
Непосредственно добавить записи можно одну за другой с помощью функций insert* модуля Ecto.Repo. Кстати, этот модуль используется (use) в модуле AtvApi.Repo вместе с параметрами базы данных, поэтому фактически в приложении мы будем пользоваться вызовами вроде AtvApi.Repo.insert ..., но описание этих функций находится по ссылке выше. Так вот, мы могли бы прямо из Enum.reduce/3 добавлять записи по одной (только тогда мы воспользовались бы чуть другой функцией — Enum.each/2), однако что, если где-нибудь в середине процесса возникнет ошибка? В этом случае мы бы остались с неполноценными (неконсистентными) данными. Чтобы этого избежать, можно обернуть процесс в транзакцию. Для этого есть функция Ecto.Repo.transaction/2, которая в качестве первого параметра принимает либо функцию, которая как раз и будет обёрнута в транзакцию, либо структуру Ecto.Multi, аккумулирующую операции. Так как в данном случае нам не требуется особой логики, проще воспользоваться Ecto.Multi, что мы и делаем последней строкой анонимной функции, переданной в Enum.reduce/3. Так как из любой функции в Elixir возвращается результат последнего действия (выражения) в ней, она вернёт новую версию структуры Ecto.Multi, которая поступит [как аккумулятор] на вход очередного вызова анонимной функции вместе с очередным элементом списка, либо будет использована в качестве результата работы функции Enum.reduce/3 и попадёт в переменную multi.
Ниже мы видим вызов Repo.transaction/2, действие которого описано выше (кстати, вы, наверное, обратили внимание, что arity — число аргументов — для используемых функций иногда меньше, чем в определении? это потому, что часть аргументов может быть опциональной, т.е. иметь значения по умолчанию). После этого выводим сообщение о завершении операции со справочником OECD FOS.
Останется запустить процесс первоначального заполнения:
$ mix run priv/repo/seeds.exs
[debug] QUERY OK source="fos" db=0.7ms
SELECT count(f0."id") FROM "fos" AS f0 []
[debug] QUERY OK db=0.1ms
begin []
[debug] QUERY OK db=1.4ms
INSERT INTO "fos" ("id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4) ["010000", "Natural Sciences", {{2017, 2, 21}, {11, 50, 38, 799789}}, {{2017, 2, 21}, {11, 50, 38, 804086}}]
[debug] QUERY OK db=0.3ms
...
INSERT INTO "fos" ("id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4) ["0605BQ", "Humanities, multidisciplinary", {{2017, 2, 21}, {11, 50, 38, 973021}}, {{2017, 2, 21}, {11, 50, 38, 973025}}]
[debug] QUERY OK db=5.8ms
commit []
[info] OECD FOS load completeКонтроллер FosController
Пора приступить к основной функциональности нашего back-end. Что делают правильные разработчики сначала? Правильно — пишут тесты (я разработчик не всегда правильный, но стараюсь исправиться)!
Вместе с моделью генератор подготовил нам стандартный CRUD-контроллер, представление (View), форматирующее сырые данные, подготовленные контроллером, а так же тесты к нему. Справочник OECD FOS будет отдаваться целиком, так что нам необходим будет один единственный метод — index, а так же тест. Можно было бы ограничиться проверкой получения количества записей (ведь мы знаем, сколько их должно быть), однако это не наш путь. Тем более, что в реальной жизни тесты понадобятся куда более сложные (и мы это подтвердим на практике, когда будем работать со справочником ГРНТИ).
Для удобства воспользуемся инструментом для создания тестовых данных ExMachina. Кроме того, крайне рекомендую расширение mix test.watch — оно позволит не запускать тесты вручную, а будет отслеживать изменения и перезапускать тесты заново самостоятельно.
Добавьте в список зависимостей в файле mix.exs новые:
# mix.exs
# ...
# Specifies your project dependencies.
#
# Type `mix help deps` for examples and options.
defp deps do
[{:phoenix, "~> 1.2.1"},
{:phoenix_pubsub, "~> 1.0"},
{:phoenix_ecto, "~> 3.0"},
{:postgrex, ">= 0.0.0"},
{:gettext, "~> 0.11"},
{:cowboy, "~> 1.0"},
# Ниже - текущие изменения
{:ex_machina, "~> 1.0", only: :test},
{:mix_test_watch, "~> 0.3", only: :dev, runtime: false}]
end
# ...Получим зависимости:
$ mix deps.get
Running dependency resolution...
Dependency resolution completed:
ex_machina 1.0.2
fs 2.12.0
mix_test_watch 0.3.3
* Getting ex_machina (Hex package)
Checking package (https://repo.hex.pm/tarballs/ex_machina-1.0.2.tar)
Using locally cached package
* Getting mix_test_watch (Hex package)
Checking package (https://repo.hex.pm/tarballs/mix_test_watch-0.3.3.tar)
Fetched package
* Getting fs (Hex package)
Checking package (https://repo.hex.pm/tarballs/fs-2.12.0.tar)
Fetched packageМожно приступать!
Для начала подготовим набор тестовых данных. Я взял записи из справочника и создал отдельный модуль, который рекомендую скачать и поместить в директорию test/support. Модуль представляет собой константу со списком ассоциативных массивов, каждый из которых содержит ключи :id и :title, и функцию AtvApi.FactoryFosList.fos_list/0, возвращающую содержимое этой константы. Текст модуля с небольшой частью данных:
defmodule AtvApi.FactoryFosList do
@fos_list [
%{id: "010000", title: "Natural Sciences"},
%{id: "020000", title: "Engineering and Technology"},
%{id: "030000", title: "Medical and Health Sciences"},
# ...
%{id: "0604YG", title: "Theater"},
%{id: "0605BQ", title: "Humanities, multidisciplinary"},
]
def fos_list, do: @fos_list
end Далее создадим модуль AtvApi.Factory, в котором мы опишем нашу фабрику данных. В дальнейшем в этом же модуле окажется и описание фабрики для справочника ГРНТИ:
defmodule AtvApi.Factory do
use ExMachina.Ecto, repo: AtvApi.Repo
import AtvApi.FactoryFosList, only: [fos_list: 0]
def fos_factory do
%AtvApi.Fos{
id: "0",
title: "Some science-technology name",
}
end
def build_all(factory_name, insert? \\ false) do
get_list(factory_name)
|> Enum.map(fn(rec) ->
case insert? do
true -> insert(factory_name, rec)
false -> build(factory_name, rec)
end
end)
end
def insert_all(factory_name) do
build_all(factory_name, true)
end
defp get_list(:fos) do
fos_list()
end
defp get_list(_) do
[]
end
endПервой строкой после определения модуля мы используем макрос use, который на этапе компиляции превращает строку use ExMachina.Ecto, repo: IasipApi.Repo в следующий код:
require ExMachina.Ecto
ExMachina.Ecto.__using__(repo: AtvApi.Repo)О require мы говорили чуть ранее, а макрос __using__/1, который должен быть определён в модуле, который мы хотим use, позволяет внедрить в текущий контекст (обычно модуль) некоторый код, реализующий требуемую нам функциональность.
Вообще, мета-программирование — это отдельная тема, которая требует не менее отдельного разговора. Желающие могут начать с "Quote and unquote", "Макросов" и "Domain Specific Languages" во введении в Elixir.
Я бы не рекомендовал читать то, что находится в рамках этого спойлера, до того, как станут понятны основные моменты языка, но...
… если готовы рискнуть — давайте в двух словах попробуем разобраться, что же происходит, когда обрабатывается строка use ExMachina.Ecto, .... Код модуля ExMachina.Ecto можно увидеть на GitHub. Напомню, что мы будем рассматривать происходящее на этапе компиляции, а не во время исполнения.
Препроцессор преобразует указанную строку во фрагмент, приведённый выше, т.е. проверяет наличие модуля ExMachina.Ecto (require ExMachina.Ecto) и запускает макрос ExMachina.Ecto.__using__/1, которому в качестве единственного параметра передаётся список пар ключ-значение (в нашем случае — repo: AtvApi.Repo; обратите внимание, в Elixir при передаче списка последним параметром можно не использовать квадратные скобки []). При запуске макрос проверяет наличие ключа :repo и в случае его наличия вставляет код, расположенный в блоке quote do ... end, в текущий модуль (т.е. в модуль AtvApi.FactoryFos), применяя при этом директивы quote и unquote (см. документацию по ссылке выше). Таким образом, в текущем модуле появляются функция params_for/2, функция string_params_for/2 и прочие. Так же появляются директивы use ExMachina и use ExMachine.EctoStrategy, ..., с которыми история повторяется — т.е. добавляются очередные функции и подключаются другие модули (вы можете почитать код и выяснить подробности самостоятельно).
В частности, появляются функции build/2 и build_list/3, с помощью которых можно сгенерировать один набор данных или целый список. Модуль ExMachina.Ecto также предоставляет нам функции insert/2 и insert_list/3, которые не просто возвращают результат, а ещё и добавляют получившуюся запись или записи в базу данных. Любопытно, что за наличие последней пары функции отвечает в конечном итоге модуль ExMachina.Strategy, который подключается из модуля ExMachina.EctoStrategy с помощью use ExMachine.Strategy, function_title: :insert. Фактически, функции insert/2 и insert_list/3 в момент написания кода отсутствуют — они будут созданы динамически на этапе перед компиляцией в макросе __using__/1 модулем ExMachina.Strategy из опции :function_name.
После того, как все макросы отработают и будут развёрнуты в окончательный код, произойдёт компиляция.
После импорта функции AtvApi.FactoryFosList.fos_list/0, которая возвращает список ассоциативных массивов с описаниями разделов, мы определяем функцию fos_factory/0.
Подключая модуль ExMachine.Ecto, мы получаем два набора функций: build/2 / build_list/3 и insert/2 / insert_list/3. Первая пара возвращает один набор данных (под набором тут подразумевается любой тип данных, от строки до ассоциативного массива или структуры модели таблицы базы данных) или список таких наборов, вторая пара эти данные дополнительно добавляет в базу данных. Параметры соответствующих функций из наборов идентичны. Функция build/2 вызывается как build(factory_name, attrs), build_list/3 как build_list(number_of_factories, factory_name, attrs). Чтобы создать набор данных, build/2 ожидает, что в текущем модуле имеется функция <factory_name>_factory/0. Т.е. если мы вызовем эту функцию как build(:fos, %{}), то она попытается получить базовый набор данных от функции fos_factory/0, которую мы и реализовали в рассматриваемом фрагменте.
Можно попытаться вызвать функцию AtvApi.Factory.build/2 из интерактивной оболочки Elixir:
$ MIX_ENV=test iex -S mix
Erlang/OTP 19 [erts-8.2] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.4.1) - press Ctrl+C to exit (type h() ENTER for help)
iex> AtvApi.Factory.build(:fos, %{id: "0103SY", title: "Optics"})
%AtvApi.Fos{__meta__: #Ecto.Schema.Metadata<:built, "fos">, id: "0103SY",
inserted_at: nil, title: "Optics", updated_at: nil}То же самое можно сделать и с функцией build_all/2, но вывод будет длинным.
Обратите внимание: стандартный конфиг mix.exs в Phoenix Framework указывает mix, что компилировать содержимое директории test/support нужно исключительно для тестового окружения. Поэтому наш модуль будет доступен только при явном задании нужного окружения с помощью MIX_ENV=test.
Далее мы определяем ещё две функции, которые либо создадут и вернут список моделей (build_all/2), либо ещё и добавят эти данные в базу (insert_all/1). Конечно, наибольший интерес представляет функция build_all/2, поскольку insert_all/1 — это вызов предыдущей функции с подолнительным параметром.
Однако перед этим обратите внимание на функцию get_list/1:
defp get_list(:fos) do
fos_list()
end
defp get_list(_) do
[]
endВы наверняка заметили, что начало описания функции имеет ключевое слово defp вместе def, которое мы использовали ранее. Оно означает, что данная функция будет приватной и доступна только из функций данного модуля (включая те, которые были интегрированы с помощью мета-программирования) и недоступна снаружи.
Далее, существует два тела функции. Благодаря механизму сопоставления с шаблоном первое тело будет выполнено при вызове get_list/1 с :fos в качестве параметра и вызовет, в свою очередь, AtvApi.FactoryFosList.fos_list/0; если помните, имя последней функции ранее было импортировано в текущее пространство имён. Второе тело будет вызвано при любом другом параметре, и вернёт пустой список. Это довольно простой пример использования сопоставления с шаблоном.
Вернёмся к build_all/2. Для начала получаем тестовый набор с помощью get_list/1, описанной выше. Полученный список передаётся в функцию Enum.map/2, которая отправляет каждый элемент списка в анонимную функцию и помещает результат её выполнения на ту же позицию в новом списке, который и возращает. В теле анонимной функции проверяется состояние параметра insert? и вызывается либо функция ExMachina.build/2, либо ExMachina.Ecto.insert/2 (напомню, что реализация этих функций с помощью механизмов мета-программирования добавлена прямо в текущий модуль). В результате работы функции AtvApi.FactoryFos.build_all/2 будет получен список с созданными на основании тестового списка структурами %Fos{}.
Как вы уже поняли ранее, тесты можно запускать вручную с помощью mix test. Кроме того, благодаря mix-test.watch можно запустить в отдельной консоли автоматический прогон тестов при каждом изменении. запустите mix test.watch в консоли и увидите нечто подобное следующему:
$ mix test.watch
Running tests...
.....
Finished in 0.05 seconds
5 tests, 0 failures
Randomized with seed 806690При каждом изменении любого файла в поддиректориях проекта тесты будут запущены автоматически. Чтобы прервать процесс, нажмите два раза Ctrl+C.
В Phoenix Framework тесты контроллеров лежат в директории test/controllers. Обратите внимание, что расширение у тестов — exs, что означает Elixir Script. Тесты не нужно компилировать до запуска, поэтому это удобно.
За тестирование в Elixir отвечает модуль ExUnit. Существуют и другие библиотеки для тестирования, однако стоит разобраться с возможностями стандартного модуля — уверен, в большинстве случаев он закроет все ваши потребности.
Далее смесь из документации и моих комментариев.
Основные шаги для работы с ExUnit приведены ниже:
# File: assertion_test.exs
# 1) Запустите ExUnit.
ExUnit.start
# 2) Создайте новый тестовый модуль (набор тестов, test case)
# и используйте (use) "ExUnit.Case".
defmodule AssertionTest do
# 3) Обратите внимание: мы передаём "async: true", опция
# запускает данный набор тестов параллельно с другими наборами.
# Тем не менее, каждый тест внутри набора тестов будет запущен
# по отдельности.
use ExUnit.Case, async: true
# 4) Для наглядности используйте макрос "test" вместо "def"
test "the truth" do
assert true
end
endЗапустить получившийся набор можно командой:
$ elixir assertion_test.exs
warning: this check/guard will always yield the same result
assertion_test.exs:17
.
Finished in 0.03 seconds (0.03s on load, 0.00s on tests)
1 test, 0 failures
Randomized with seed 598489При использовании тестов с Mix запуск модуля тестирования происходит из файла test/test_helper.exs. В нашем текущем проекте он тоже присутствует.
Подготовкой к запуску тестов занимается модуль ExUnit.Case. Единственная доступная опция модуля async описана выше.
Каждый тест в качестве аргумента получает контекст. Особенно полезен контекст для передачи тестам информации от обратных вызовов setup_all и setup (о последних ниже):
defmodule ExampleTest do
use ExUnit.Case
setup do
{:ok, [hello: :world]}
end
test "context contains key-value pairs", context do
assert context[:hello] == :world
end
endТак как контекст является ассоциативным массивом, для того, чтобы извлечь нужную информацию можно использовать сопоставление с шаблоном:
test "context is a map and pattern matching", %{hello: hello} do
assert hello == :world
endТакже есть возможность передачи информации от тестов к setup через механизм меток, можно исключать из запуска часть тестов и множество других возможностей — посмотрите документацию к модулю, лишним не будет.
Стоит отметить, что ExUnit.Case включает в себя все обратные вызовы (callbacks) модуля ExUnit.Callbacks. Таковые включают в себя setup_all и setup, а также механизм on_exit/2.
Обратные вызовы определяются через макросы и могут опционально получать контекст с метаданными. При необходимости эти данные можно изменять, передавая таким образом информацию к тестам (см. выше).
Вызовы setup_all запускаются один раз перед запуском тестов для настройки набора целиком. Вызовы всех setup происходят перед запуском каждого теста. Если тестов в наборе нет или они все отфильтрованы, setup_all и setup вызваны не будут.
on_exit/2 регистрируется по необходимости, обычно для отмены действий, произведённых в setup.
Если при завершении setup_all будет возращён кортеж {:ok, keywords}, то пары ключ-значение из keywords будут объединены с текущим контекстом и станут доступны всем последующим setup_all, setup и запускаемым тестам.
Возвращённые таким же образом значения из setup будут также объединены с контекстом и доступны всем последующим setup и тестам.
При возврате атома :ok контекст изменён не будет.
Если вернуть из setup_all что-либо кроме описанного выше, все тесты набора будут помечены как провалившиеся, в то время как в случае setup провалится только текущий тест.
Пример из документации:
defmodule AssertionTest do
use ExUnit.Case, async: true
# "setup_all" запускается один раз для настройки набора перез запуском тестов
setup_all do
IO.puts "Начинаем AssertionTest"
# No metadata
:ok
end
# "setup" запускается перед каждым тестом
setup do
IO.puts "Это обратный вызов 'setup'"
on_exit fn ->
IO.puts "Это будет вызвано после завершения теста"
end
# Возвращаются дополнительные метаданные для объединения с контекстом
[hello: "world"]
end
# Аналогично предыдущему, но получает контекст
# для текущего теста
setup context do
IO.puts "Настраиваем тест: #{context[:test]}"
:ok
end
# Также можно вызвать локальную или импортированную функцию
setup :invoke_local_or_imported_function
test "always pass" do
assert true
end
test "another one", context do
assert context[:hello] == "world"
end
defp invoke_local_or_imported_function(context) do
[from_named_setup: true]
end
endНепосредственно в тестах для проверки используются функции и обратные вызовы из модуля ExUnit.Assertions. Конечно, они так же импортируются с помощью ExUnit.Case, так что дополнительно делать это не нужно.
В подавляющем большинстве случаев вы будете использовать вызовы assert/1 для проверки утверждения на истинность и refute/1 с противоположной целью.
Остаётся добавить только, что так как названия тестов переводятся при запуске в атомы, в них нельзя использовать юникод, что исключает русский язык.
Из особенностей тестирования в Phoenix Framework стоит отметить, что работа с базой данных в тестах по-умолчанию происходит в режиме песочницы, т.е. все изменения, произведённые в рамках тестов, после их завершения откатываются.
Больше подробностей, как всегда, в документации.
Откройте файл с именем fos_controller_test.exs и приведите его к виду ниже:
defmodule AtvApi.FosControllerTest do
use AtvApi.ConnCase
import AtvApi.Factory
import AtvApi.FactoryFosList, only: [fos_list: 0]
setup %{conn: conn} do
insert_all(:fos)
fos = fos_list()
|> Enum.sort
|> Poison.encode!
|> Poison.decode!
{:ok, conn: put_req_header(conn, "accept", "application/json"), fos: fos}
end
test "lists all entries on index", %{conn: conn, fos: fos} do
conn = get conn, fos_path(conn, :index)
assert json_response(conn, 200)["data"] == fos
end
endПервой строкой мы используем (use) модуль AtvApi.ConnCase, который был сгенерирован при создании нового проекта Phoenix Framework. Этим мы в первую очередь интегрируем функции из модуля Phoenix.ConnTest, облегчающие тестирование всего, чем управляет роутер, а также необходимые блоки для настройки тестов; в частности, добавляется блок setup, настраивается взаимодействие с базой данных и в контекст под ключом conn помещается структура Plug.Conn, с помощью которой мы будем отправлять запросы к нашим контроллерам.
Далее мы импортируем функции из созданных ранее модулей AtvApi.Factory и AtvApi.FactoryFosList.
Затем идёт блок setup, в котором мы добавляем в полученную из контекста структуру conn новый заголовок с помощью функции Plug.Conn.put_req_header/3 и при выходе возвращаем её в контекст. Первой строкой блока вставляем тестовые данные в базу вызовом AtvApi.Factory.insert_all/1. Также мы получаем список с тестовыми данными с помощью AtvApi.FactoryFosList.fos_list/0, сортируем его функцией Enum.sort/1, а далее превращаем названия полей из атомов в строки путём использования функций библиотеки для работы с JSON под названием Poison (сериализируем список в JSON, а затем — обратно). Получившийся список помещаем в контекст вместе со структурой conn, чтобы в дальнейшем воспользоваться ими из тестов.
Во всём наборе у нас есть только один тест, который должен сравнивать полученные от контроллера FosController данные со списком fos, который мы создали в setup. Для этого нам понадобятся находящиеся в контексте структура conn и список fos, которые мы получим с помощью сопоставления с шаблоном.
Следующую строку стоит разобрать отдельно. Чтобы получить данные, нам нужно совершить HTTP GET-запрос к нужному контроллеру. Для отправки такого запроса существует макрос Phoenix.ConnTest.get/3, который ожидает получить первым паратром структуру conn, а вторым — часть URL, отвечающую за путь. Этот путь — "/api/fos" — можно указать вручную, но правильнее воспользоваться специальным помощником модуля Phoenix.Router, который автоматически создаётся на основании данных в web/router.ex. В данном случае функция-помощник будет носить имя fos_path/2.
После работы макроса Phoenix.ConnTest.get/3 мы получим новую версию структуры conn, содержащую ответ.
В ответ на запрос мы ожидаем получить строку с JSON-структурой вида:
{"data":
[
{"id": "010000", "title": "Natural Sciences"},
{"id": "020000", "title": "Engineering and Technology"},
...
]
}Фукция Phoenix.ConnTest.json_response/2 проверяет, что полученный код результата — 200 (т.е. HTTP_OK), что в ответе присутствует валидная JSON-структура и возвращает её в декодированном виде как ассоциативный массив. Таким образом, мы следующей строкой проверяем, что значение записи с ключом "data" в полученном ассоциативном массиве — т.е. список с идентификаторами и названиями разделов — равно сформированному списку fos.
Ранее мы добавили в файл web/router.ex строку resources "/fos", FosController, except: [:new, :edit]. Хотя она прекрасно подходит для полноценных CRUD-контроллеров, в нашем случае она избыточна. Проверим список маршрутов, имеющихся в настоящий момент:
$ mix phoenix.routes
fos_path GET /api/fos AtvApi.FosController :index
fos_path GET /api/fos/:id AtvApi.FosController :show
fos_path POST /api/fos AtvApi.FosController :create
fos_path PATCH /api/fos/:id AtvApi.FosController :update
PUT /api/fos/:id AtvApi.FosController :update
fos_path DELETE /api/fos/:id AtvApi.FosController :deleteОднако наш контроллер должен уметь возвращать только список — или индекс — всех ресурсов. Для этого нам достаточно одного маршрута — самого первого в списке выше. Поменяем строку resources "/fos", FosController, except: [:new, :edit] на get "/fos", FosController, :index и запустим mix phoenix.routes снова:
$ mix phoenix.routes
Compiling 6 files (.ex)
fos_path GET /api/fos AtvApi.FosController :indexКак видно, в списке маршрутов остался один — который на HTTP GET-запрос по адресу http://сервер:порт/api/fos/ будет запускать метод :index контроллера AtvApi.FosController.
Давайте запустим получившийся тест. Стоит напомнить, что у нас уже есть сформированный генератором контроллер, поэтому результат будет получен. Какой? Проверим:
$ mix test test/controllers/fos_controller_test.exs
Compiling 6 files (.ex)
1) test lists all entries on index (AtvApi.FosControllerTest)
test/controllers/fos_controller_test.exs:19
Assertion with == failed
code: json_response(conn, 200)["data"] == fos
left: [%{"id" => "010000", "title" => "Natural Sciences"},
%{"id" => "020000", "title" => "Engineering and Technology"},
%{"id" => "030000", "title" => "Medical and Health Sciences"},
...
%{"id" => "0101PO",
"title" => "Mathematics, interdisciplinary applications"},
%{"id" => "0101PQ", "title" => "Mathematics"},
%{"id" => "0101UR", ...}, %{...}, ...]
right: [%{"id" => "010000", "title" => "Natural Sciences"},
%{"id" => "010100", "title" => "Mathematics"},
%{"id" => "0101PN", "title" => "Mathematics, applied"},
...
%{"id" => "010600", "title" => "Biological sciences"},
%{"id" => "0106BD", "title" => "Biodiversity conservation"},
%{"id" => "0106CO", ...}, %{...}, ...]
stacktrace:
test/controllers/fos_controller_test.exs:21: (test)
Finished in 0.1 seconds
1 test, 1 failure
Randomized with seed 415134Я сократил вывод, однако видно, что тест был провален. Могу сказать, что хотя сгенерированный метод :index контроллера AtvApi.FosController совершенно корректно выводит все имеющиеся данные, сортировка этого вывода отличается от той, что мы ожидаем (вспомните функцию Enum.sort/1, которую мы применили к списку с тестовыми данными в блоке setup). Давайте изменим контроллер, удалив избыточные методы и изменив функцию AtvApi.FosController.index/2. Так будет выглядеть наш контроллер после изменений:
defmodule AtvApi.FosController do
use AtvApi.Web, :controller
alias AtvApi.Fos
import Ecto.Query
def index(conn, _params) do
fos = Repo.all(from f in Fos, order_by: f.id)
render(conn, "index.json", fos: fos)
end
endТут используется (use) модуль AtvApi.Web, причём вместо __using__/1 для интеграции запускается функция controller. Путь к модулю — web/web.ex, рекомендую открыть его и ознакомиться с содержимым.
Следующие две строки понятны, можно перейти сразу к функции index/2. Обратный вызов Ecto.Repo.all/2 получает на вход структуру с типом, реализующим протокол Ecto.Queryable, на основании неё осуществляет запрос к базе данных и возвращает список из всех записей базы, соответствующих запросу. В частности, любая модель данных реализует этот протокол, и мы могли бы оставить предыдущий вариант: Repo.all(Fos). Несмотря на то, что мы действительно получим все записи, в этом случае запрос будет выглядеть как-то так:
SELECT f0."id", f0."title", f0."inserted_at", f0."updated_at" FROM "fos" AS f0т.е. порядом вывода будет отдан на откуп СУБД, а это не очень хорошо. Поэтому мы напишем наш запрос, применяя DSL модуля Ecto.Query, в результате получим строку из новой версии контроллера Repo.all(from f in Fos, order_by: f.id), что сформирует следующий запрос:
SELECT f0."id", f0."title", f0."inserted_at", f0."updated_at" FROM "fos" AS f0 ORDER BY f0."id"Таким образом, мы помещаем в переменную fos список всех записей из таблицы fos, отсортированных по полю id.
Следующей строкой мы производим вызов функции Phoenix.Controller.render/3, которая формирует представление (View) на основании информации в conn (первый параметр), названии шаблона (второй параметр) и наборе данных для встраивания в шаблон (третий параметр). О том, что такое представление, мы подробнее поговорим во время работы над справочником ГРНТИ, который будем писать с нуля, без генераторов; пока же могу сказать, что по собственной конвенции Phoenix Framework предполагает наличие модуля с названием (в нашем случае) AtvApi.FosView, а также наличие в нём функции обратного вызова render/2, которая первым параметром ожидает строку "index.json", а вторым — ассоциативный массив, в котором есть ключ fos. По сути, наши view — это всего лишь функции, форматирующие переданные данные. Посмотрите на web/views/fos_view.ex — в модуле очень просто разобраться самостоятельно.
Запустим наш тест ещё раз:
$ mix test test/controllers/fos_controller_test.exs
Compiling 1 file (.ex)
.
Finished in 0.2 seconds
1 test, 0 failures
Randomized with seed 347227Как видите, в этот раз тест проходит успешно.
Давайте запустим наше приложение и попробуем сделать первый запрос (предполагаю, что вы уже создали базу данных, применили миграции и заполнили таблицу данными, выдав последовательно mix ecto.create, mix ecto.migrate и mix run priv/repo/seeds.exs):
$ mix phoenix.server
[info] Running AtvApi.Endpoint with Cowboy using http://localhost:4000Теперь откройте окно браузера и введите в адресную строку http://localhost:4000/api/fos/:
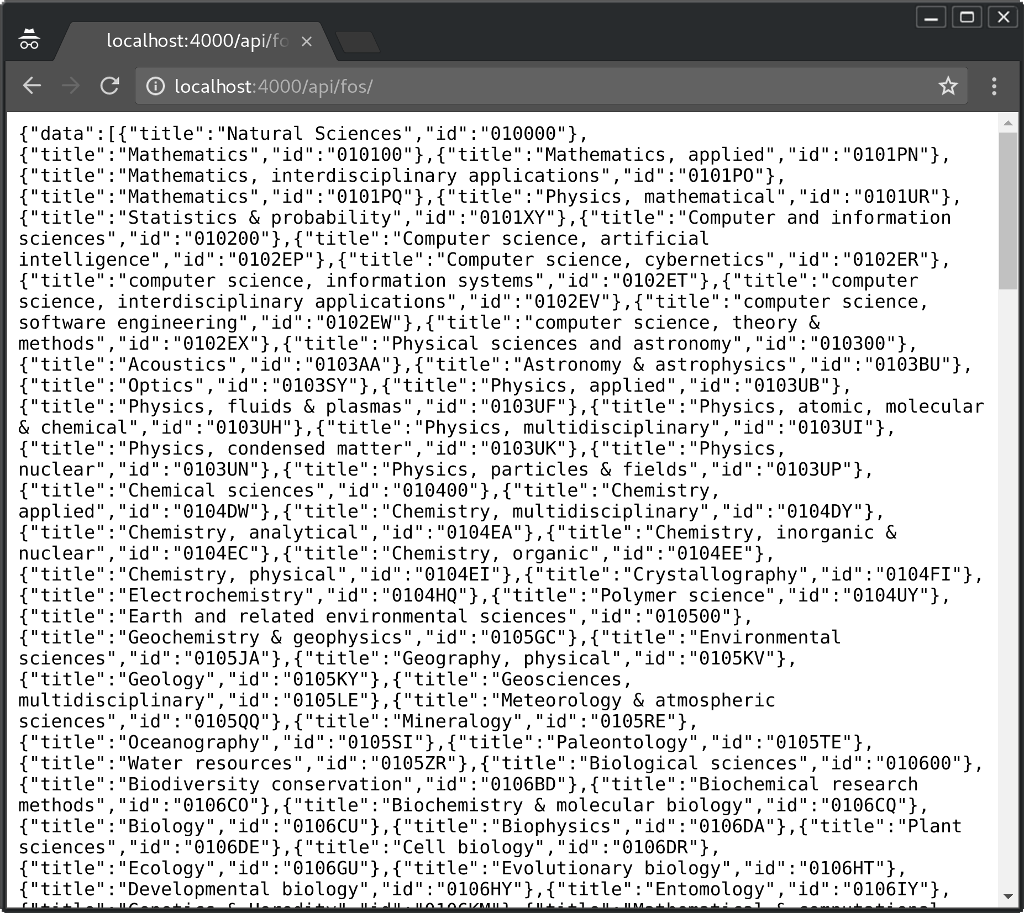
Как видите, в браузере появляется JSON-структура с нашим справочником. Поздравляю с первой полноценной функциональностью!
Справочник ГРНТИ
Окей, настало время перейти к более интересной задаче — реализации справочника ГРНТИ. В отличие от предыдущего, этот справочник будет выдаваться блоками, поэтому front-end'у необходимо больше сведений. Для каждой записи придётся предусмотреть новое поле has_children логического типа.
Генерация модели
В этот раз мы воспользуемся генератором только для того, чтобы создать миграцию, модель и тесты для модели:
$ mix phoenix.gen.model Grnti2 grnti2 title:text has_children:booleanВ этот раз список полей пополнился новым. Как и в прошлый раз, не стоит торопиться с запуском процесса миграции.
В реализации данного справочника мы используем целочисленный тип (integer) для хранения кода рубрики. Это даст нам существенную прибавку в скорости работы. Напомню, что поле id в Ecto по умолчанию автоинкрементное, а нам нужен простой integer.
И в этот раз начнём с миграции:
defmodule AtvApi.Repo.Migrations.CreateGrnti do
use Ecto.Migration
def change do
create table(:grnti, primary_key: false) do
add :id, :integer, null: false, primary_key: true
add :title, :text
add :has_children, :boolean, default: false, null: false
timestamps()
end
end
endКак видите, появилось поле :has_children со значением по-умолчанию.
И продолжим с моделью:
defmodule AtvApi.Grnti do
use AtvApi.Web, :model
schema "grnti" do
field :title, :string
field :has_children, :boolean, default: false
timestamps()
end
@doc """
Builds a changeset based on the `struct` and `params`.
"""
def changeset(struct, params \\ %{}) do
struct
|> cast(params, [:id, :title, :has_children])
|> validate_required([:id, :title, :has_children])
end
endТак как в данном случае почти никаких от предыдущих вариантов нет, то и описание повторять не буду. Разве что отмечу, что в схеме для упрощения мы не упоминаем id вообще, будут использоваться стандартные механизмы. Тем не менее, в changeset/2 изменения внести необходимо.
Запустим сгенерированные тесты, чтобы проверить правильность нашего кода:
$ mix test test/models/grnti_test.exs
.
1) test changeset with valid attributes (AtvApi.GrntiTest)
test/models/grnti_test.exs:9
Expected truthy, got false
code: changeset.valid?()
stacktrace:
test/models/grnti_test.exs:11: (test)
Finished in 0.05 seconds
2 tests, 1 failure
Randomized with seed 788882Также, как и в случае с предыдущим справочником, необходимо поправить константу в тесте модели, разве что id теперь целочисленное, поэтому кавычек быть не должно:
@valid_attrs %{title: "some content", has_children: true, id: 100001}Снова запустим тест:
$ mix test test/models/grnti_test.exs
..
Finished in 0.04 seconds
2 tests, 0 failures
Randomized with seed 692361и затем — процесс миграции:
$ mix ecto.migrate
17:54:26.080 [info] == Running AtvApi.Repo.Migrations.CreateGrnti.change/0 forward
17:54:26.080 [info] create table grnti
17:54:26.097 [info] == Migrated in 0.0sЗаполнение таблицы данными справочника
Продолжим работу по тому же сценарию и создадим функцию для первоначального заполнения таблицы. Добавьте в конец файла priv/repo/seeds.exs следующий код:
### Grnti dictionary ###
alias AtvApi.Grnti
unless Repo.one!(from g in Grnti, select: count(g.id)) > 0 do
multi = File.read!("priv/repo/grnti.txt")
|> String.split("\n")
|> Enum.reject(fn(row) -> byte_size(row) < 2 end)
|> Enum.reduce(%{}, fn(row, acc) ->
{id, parent_id, title} =
case <<String.trim(row)::binary>> do
<<a::binary-size(2), ".",
b::binary-size(2), ".",
c::binary-size(2), " ",
title::binary>> ->
{ String.to_integer("#{a}#{b}#{c}"), String.to_integer("#{a}#{b}00"), title }
<<a::binary-size(2), ".",
b::binary-size(2), " ",
title::binary>> ->
{ String.to_integer("#{a}#{b}00"), String.to_integer("#{a}0000"), title }
<<a::binary-size(2), " ",
title::binary>> ->
{ String.to_integer("#{a}0000"), -1, title }
end
parent =
case Map.get(acc, parent_id) do
nil -> {"", true}
{p_title, _} -> {p_title, true}
end
current =
case Map.get(acc, id) do
nil -> {title, false}
{_, has_children} -> {title, has_children}
end
acc
|> Map.put(id, current)
|> Map.put(parent_id, parent)
end)
|> Enum.reduce(Ecto.Multi.new, fn({id, {title, has_children}}, multi) ->
if id > -1 do
changeset = Grnti.changeset(%Grnti{}, %{id: id, title: String.trim(title), has_children: has_children})
Ecto.Multi.insert(multi, "#{id}", changeset)
else
multi
end
end)
Repo.transaction(multi)
Logger.info "GRNTI load complete"
end
### Grnti dictionary ###Здесь мы:
- читаем содержимое файла (
File.read!/1), получая строковое значение, - создаём из этого значения список (List) из элементов-строк с помощью функции
String.split/3, используя в качестве разделителя перевод строки\n, - убираем из списка элементы, размер которых меньше двух байт, с помощью функции
Enum.reject/2, - передаём отфильтрованный список функции
Enum.reduce/3в первый раз, - передаём полученный в результате ассоциативный массив второй функции
Enum.reduce/3.
Давайте пройдёмся по первой функции Enum.reduce/3. В качестве аккумулятора здесь выступает пустой ассоциативный массив %{}. Внутрь анонимной функции передаётся очередная строка row и текущее состояние аккумулятора acc. Чтоже происходит со строкой и аккумулятором внутри?
Вообще, строка может иметь одну из трёх форм, примеры:
- " 00 ОБЩЕСТВЕННЫЕ НАУКИ В ЦЕЛОМ"
- " 00.21 Организация научно-исследовательской работы в области общественных наук"
- " 02.01.39 Пропаганда и популяризация философских знаний"
Из этого нам нужно получить id в числовом виде и название раздела title. Кроме того, нам нужно выяснить, у каких разделов есть подразделы. Первым делом на ум приходит парсинг строки через регулярные выражения, затем перевод id в число и модификация его в "шестизнаковое", затем — следующей проход по всему списку для фильтрации (в исходном файле могут быть и фактически есть дубли), ещё один раз — для выяснения того, есть ли подразделы… я было по этому пути и пошёл, но затем решил всё слегка оптимизировать. Для этого мы воспользуемся двоичным сопоставлением с шаблоном.
В Elixir двоичное представление определяется угловыми скобками <<>>. Подробнее можно почитать во введении в язык и в документации.
С двоичными данными сопоставление с образцом работает прекрасно. В общем, это и неудивительно: Erlang родом из телекомов, где основные протоколы — бинарные, и с ними нужно работать, а Elixir беспардонно использует все его возможности.
Не останавливаясь надолго на этой теме — кому нужно, почитает документацию — приведу только один пример того, что может делать при помощи двоичного сопоставления с шаблоном:
defmodule ImageTyper
@png_signature <<137::size(8), 80::size(8), 78::size(8), 71::size(8),
13::size(8), 10::size(8), 26::size(8), 10::size(8)>>
@jpg_signature <<255::size(8), 216::size(8)>>
def type(<<@png_signature, rest::binary>>), do: :png
def type(<<@jpg_signature, rest::binary>>), do: :jpg
def type(_), do :unknown
endВызываем функцию ImageTyper.type/1, отправляем ей всю строку с изображением или первые несколько байт, получаем в ответ один из атомов: :png | :jpg | :unknown.
Я решил, что аккумулятор будет содержать пары ключ-значение, где ключом будет код раздела id, а значением — кортеж из названия раздела title и флага наличия подразделов has_children: %{id => {title, has_children}}.
Запомнив это, заглянем внутрь функции.
Левой части {id, parent_id, title} мы сопоставим результат выполнения оператора case, в котором в качестве образца мы используем двоичное представление текущей строки, лишённой начальных и замыкающих пробелов и непечатных символов с помощью String.trim/1. Этот образец будет по-очереди сопоставлен с тремя вариантами двоичных шаблонов.
В результате при совпадении с первым из них у нас окажутся переменные a, b и c, содержащие строки длиной два байта с соответствующими частями кода, и переменная title, в которой будет остаток строки после пробела. При совпадении с этим шаблоном мы вернём из оператора case кортеж из трёх элементов: кода текущего раздела, который получим преобразованием строки "#{a}#{b}#{c}" (#{} — это оператор для подстановки результата выполнения выражения в строку (для интерполяции)), кода родительского раздела, полученного таким же образом, но с заменой последних двух последних цифр нулями, и названия раздела. С каждым следующим шаблоном у нас будет исчезать и заменяться нулями сначала переменная c, затем — b. При этом в последнем случае — для корневых разделов — мы в качестве кода родительского раздела поставим -1. Полученные значения в результате окажутся в переменных id, parent_id и title.
Дальше всё просто. Для начала попытаемся с помощью функции Map.get/3 получить из аккумулятора значение по ключу с кодом родительского раздела. Эта функция в случае отсутствия заданного ключа по-умолчанию возвращает nil. Соответственно, если родительского раздела нет (в случае с текущим исходным файлом это невозможно, но предположим, что разделы перепутаны местами), мы его создаём с пустым названием, если есть — меняем has_children на true, а результат присваиваем переменной parent.
То же самое делаем и с id текущего раздела: если его нет — создаём, если есть — меняем на текущее только его название, поскольку статус наличия подразделов has_children мог быть установлен ранее.
В конце с помощью последовательных вызовов функции Map.put/3 мы добавляем\изменяем значение для кода текущего раздела и для кода родительского раздела.
Результирующее состояние аккумулятора возвращается на следующую итерацию или передаётся далее.
Получившийся ассоциативный массив со всеми разделами передаётся на вход следующему вызову Enum.reduce/3, где в качестве аккумулятора выступает структура Ecto.Multi, аналогично тому, что мы делали со справочником OECD FOS. После окончания работы этой функции результат оказывается в переменной multi, которая передаётся в Repo.transaction/2 и попадает в базу данных.
Запустим операцию:
$ mix run priv/repo/seeds.exs
[debug] QUERY OK source="fos" db=0.9ms queue=0.1ms
SELECT count(f0."id") FROM "fos" AS f0 []
[debug] QUERY OK source="grnti" db=3.6ms
SELECT count(g0."id") FROM "grnti" AS g0 []
[debug] QUERY OK db=0.1ms
begin []
[debug] QUERY OK db=2.1ms
INSERT INTO "grnti" ("has_children","id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4,$5) [false, 443135, "Промышленная теплоэнергетика и теплотехника", {{2017, 2, 22}, {16, 51, 9, 581608}}, {{2017, 2, 22}, {16, 51, 9, 585864}}]
[debug] QUERY OK db=0.3ms
INSERT INTO "grnti" ("has_children","id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4,$5) [false, 722335, "Автомобильные внешнеторговые перевозки", {{2017, 2, 22}, {16, 51, 9, 593526}}, {{2017, 2, 22}, {16, 51, 9, 593531}}]
[debug] QUERY OK db=0.1ms
INSERT INTO "grnti" ("has_children","id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4,$5) [true, 761300, "Медицинская техника", {{2017, 2, 22}, {16, 51, 9, 593995}}, {{2017, 2, 22}, {16, 51, 9, 594000}}]
...
[debug] QUERY OK db=0.4ms
INSERT INTO "grnti" ("has_children","id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4,$5) [false, 107161, "Адвокатура", {{2017, 2, 22}, {16, 51, 56, 376371}}, {{2017, 2, 22}, {16, 51, 56, 376375}}]
[debug] QUERY OK db=0.3ms
INSERT INTO "grnti" ("has_children","id","title","inserted_at","updated_at") VALUES ($1,$2,$3,$4,$5) [false, 292931, "Столкновения атомов и молекул с частицами", {{2017, 2, 22}, {16, 51, 56, 376969}}, {{2017, 2, 22}, {16, 51, 56, 376972}}]
[debug] QUERY OK db=5.0ms
commit []
[info] GRNTI load completeВидно, что в начале выполняются запросы на количество строк в таблицах fos (больше нуля, поэтому первый блок не будет запущен) и grnti. Далее начинается непосредственно процесс заполнения базы данных.
Контроллер GrntiController
Займёмся подготовкой тестовых данных.
В этот раз я взял лишь несколько десятков записей из справочника и создал модуль, который рекомендую скачать и поместить в директорию test/support. Как и в предыдущем случае, модуль представляет из себя константу со списком ассоциативных массивов, каждый из которых содержит ключи :id, :title и :has_children, и функцию AtvApi.FactoryGrntiList.grnti_list/0, возвращающую содержимое этой константы. Модуль с небольшой частью данных:
defmodule AtvApi.FactoryGrntiList do
@grnti_list [
%{id: 000000, has_children: true, title: "ОБЩЕСТВЕННЫЕ НАУКИ В ЦЕЛОМ"},
%{id: 000800, has_children: false, title: "Общественные науки и идеология"},
%{id: 000900, has_children: false, title: "История общественных наук"},
%{id: 001100, has_children: false, title: "Современное состояние общественных наук"},
# ...
%{id: 032323, has_children: false, title: "История России в древности ( до середины XII в.)"},
%{id: 032325, has_children: false, title: "История России в средние века (с середины XII в. до конца XVI в.)"},
]
def grnti_list, do: @grnti_list
end Также обновим наш модуль AtvApi.Factory:
defmodule AtvApi.Factory do
use ExMachina.Ecto, repo: AtvApi.Repo
import AtvApi.FactoryFosList, only: [fos_list: 0]
import AtvApi.FactoryGrntiList, only: [grnti_list: 0]
def fos_factory do
%AtvApi.Fos{
id: "0",
title: "Some science-technology name",
}
end
def grnti_factory do
%AtvApi.Grnti{
id: 0,
title: "Some grnti chapter name",
has_children: false,
}
end
def build_all(factory_name, insert? \\ false) do
get_list(factory_name)
|> Enum.map(fn(rec) ->
case insert? do
true -> insert(factory_name, rec)
false -> build(factory_name, rec)
end
end)
end
def insert_all(factory_name) do
build_all(factory_name, true)
end
defp get_list(:fos) do
fos_list()
end
defp get_list(:grnti) do
grnti_list()
end
defp get_list(_) do
[]
end
endОбратите внимание, мы включили импорт модуля с данными для тестов, создали новую фабрику grnti_factory/0 для работы функций build/2, build_list/3, insert/2 и insert_list/3, а также добавили ещё одно тело для функции get_list/1. Теперь мы можем вызывать функции build_all/1 и insert_all/1 и для модели grnti, не трогая код основной функции! Кстати, посмотрите: действие по-умолчанию (т.е. при любом параметре, кроме :fos и :grnti) осталось на последнем месте. Сопоставление с образцом идёт сверху вниз и останавливается на первом подошедшем варианте, а вариант get_list(_) может быть успешно сопоставлен с любым параметром, поэтому должен оказаться в конце вариантов для сравнения. Хотя компилятор выдаст предупреждение, если встретит такой код, стоит иметь это ввиду.
Вы можете заметить, что в данном случае не обязательно было реализовывать функцию именно таким образом, и будете абсолютно правы. Можно сделать более наглядно, например, так:
defp get_list(factory) do
case factory do
:fos -> fos_list()
:grnti -> grnti_list()
_ -> []
end
endОднако в случае, когда у вас одна и та же функция может иметь разное количество параметров или в зависимости от зачения параметра будет совершенно по-разному идти обработка, это удобно. Например, в одной из моих библиотек есть такой код, обрабатывающий ответ от внешнего API:
# ################################################### #
# proceed API request results #
# ################################################### #
# check for task
defp proceed_response(task_uuid, response, state) do
# could be rewriten inline, but this is for better code readability
task = Map.get(state, task_uuid)
proceed_response(task, task_uuid, response, state)
end
# no task with such uuid - do nothing
defp proceed_response(task, _task_uuid, _response, state) when is_nil(task) do
state
end
# Got a normal HTTP response
defp proceed_response(task, task_uuid, {:ok, %HTTPoison.Response{body: body, status_code: 200}} = _response, state) do
json_decode_result = Poison.decode(body)
proceed_response(task, task_uuid, json_decode_result, state)
end
# API task ID
defp proceed_response(task, task_uuid, {:ok, %{"errorId" => 0, "taskId" => api_task_id} = _json_body}, state) do
Process.send_after(self(), {:api_get_task_result, task_uuid}, task.result_request_interval)
put_in(state, [task_uuid, :api_task_id], api_task_id)
end
# Set a timer to try again if the task is still processing
defp proceed_response(task, task_uuid, {:ok, %{"errorId" => 0, "status" => "processing"} = _json_body}, state) do
Process.send_after(self(), {:api_get_task_result, task_uuid}, task.result_retry_interval)
state
end
# Deal with result if the task is done and task type is Image
# in case of push: true
defp proceed_response(
%{type: "ImageToTextTask"} = task, task_uuid,
{:ok, %{"errorId" => 0, "status" => "ready", "solution" => %{"text" => text}} = _json_body},
state) do
state
|> put_in([task_uuid, :result], %{text: text})
|> put_in([task_uuid, :status], :ready)
|> push_data(task, task_uuid, {:ready, task_uuid, %{text: text}})
end
# Any other - probably an error
defp proceed_response(_task, task_uuid, error, state) do
parse_error(task_uuid, error, state)
end В зависимости от входных параметров и их значений выполнение сразу может перейти на нужное место без моря if\else и без множества вложенных блоков.
Причём приведённый набор функций с одинаковым именем будет обрабатывать ответ на любой запрос. К примеру, в данном случае ответом может быть либо {"errorId" => 0, "taskId" => 12345}, если задача на внешнем API только размещена, либо {"errorId" => 0, "status" => "processing"}, если мы пытаемся получить результат выполнения задачи, но он ещё не готов, либо {"errorId" => 0, "status" => "ready", "solution" => {"text" => "some_text"}}. В случае, если завтра нам понадобится добавить обработку другого типа ответа, нужно будет всего лишь написать новую функцию, которая будет ожидать на входе, скажем, такой JSON {"errorId" => 0, "status" => "ready", "solution" => %{"image" => image_string}} (вернее, она будет ожидать ассоциативный массив, содержащий декодированный JSON, но суть вы поняли). При этом никаких изменений в код, отвечающий за обмен данными с внешним API вносить не нужно — он по-прежнему будет вызывать функцию proceed_response/3.
Отдельная история — хвостовая рекурсия. Например, если нужно вычислить сумму всех элементов списка:
$ iex
Erlang/OTP 19 [erts-8.2] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.4.1) - press Ctrl+C to exit (type h() ENTER for help)
iex> defmodule ListSum do
...> def list_sum(list), do: list_sum(list, 0)
...> def list_sum([head | tail], acc), do: list_sum(tail, acc + head)
...> def list_sum([], acc), do: acc
...> end
{:module, ListSum,
<<70, 79, 82, 49, 0, 0, 5, 180, 66, 69, 65, 77, 69, 120, 68, 99, 0, 0, 0, 223,
131, 104, 2, 100, 0, 14, 101, 108, 105, 120, 105, 114, 95, 100, 111, 99, 115,
95, 118, 49, 108, 0, 0, 0, 4, 104, 2, ...>>, {:list_sum, 2}}
iex> ListSum.list_sum([1, 5, 10, 20])
36Вернёмся к нашим тестам. В этот раз мы будем делать несколько итераций с добавлением функциональности, т.е. будем писать тесты, проверять, что они выдают ошибку, реализовывать проверяемый функционал, проверять работоспособность, и переходить к следующей — в общем, действовать как большие. Поэтому имеет смысл запустить в отдельном окне задачу mix test.watch, которая будет автоматически отслеживать изменения и перезапускать тесты.
Контроллер AtvApi.GrntiController должен будет уметь при обращении по пути "/api/grnti/<id>" вывести подразделы для раздела с данным <id>, если они есть, либо корневые разделы, если <id> равно -1.
Для начала добавим в файл с маршрутами строку get "/grnti/:id", GrntiController, :show:
defmodule AtvApi.Router do
use AtvApi.Web, :router
pipeline :api do
plug :accepts, ["json"]
end
scope "/api", AtvApi do
pipe_through :api
get "/fos", FosController, :index
get "/grnti/:id", GrntiController, :show
end
endПроверим получившиеся маршруты:
$ mix phoenix.routes
Compiling 6 files (.ex)
fos_path GET /api/fos AtvApi.FosController :index
grnti_path GET /api/grnti/:id AtvApi.GrntiController :showОтлично! Начнём с вывода корневого раздела.
Для начала добавим к нашему вспомогательному модулю с фабриками функцию-помощник, которая будут фильтровать наши тестовые данные и возвращать корневые разделы:
# ...
def get_descendants(:grnti, -1) do
grnti_list()
|> Enum.filter(fn(%{id: id}) ->
rem(id, 10000) == 0
end)
end
# ...Конечно, возникает вопрос — кто будет сторожить сторожей? В смысле, кто проверит тесты? А давайте сделаем это вручную! Запустите iex в тестовом окружении:
$ MIX_ENV=test iex -S mix
Erlang/OTP 19 [erts-8.2] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.4.1) - press Ctrl+C to exit (type h() ENTER for help)
iex> AtvApi.Factory.get_descendants(:grnti, -1)
[%{has_children: true, id: 0,
title: "ОБЩЕСТВЕННЫЕ НАУКИ В ЦЕЛОМ"},
%{has_children: true, id: 20000, title: "ФИЛОСОФИЯ"},
%{has_children: true, id: 30000,
title: "ИСТОРИЯ. ИСТОРИЧЕСКИЕ НАУКИ"}]Выглядит правильно.
Создайте файл test/controllers/grnti_controller_test.exs и приведите его к следующему виду:
defmodule AtvApi.GrntiControllerTest do
use AtvApi.ConnCase
import AtvApi.Factory
setup %{conn: conn} do
insert_all(:grnti)
{:ok, conn: put_req_header(conn, "accept", "application/json")}
end
test "the root level descendants", %{conn: conn} do
id = -1
grnti_subtree = get_descendants(:grnti, id)
conn = get conn, grnti_path(conn, :show, id)
assert json_response(conn, 200)["data"] == grnti_subtree |> Poison.encode! |> Poison.decode!
end
endЕсли вы сейчас обратите внимание на окно с запущенным процессом mix test.watch, то увидите, что тест не проходит с ошибкой ** (UndefinedFunctionError) function AtvApi.GrntiController.init/1 is undefined (module AtvApi.GrntiController is not available). Это естественно, так как сам контроллер у нас отсутствует. Давайте его создадим:
defmodule AtvApi.GrntiController do
use AtvApi.Web, :controller
alias AtvApi.Grnti
def show(conn, %{"id" => id}) do
conn
|> put_resp_content_type("text/plain")
|> send_resp(200, "request_ok")
end
endВ контроллере мы описали функцию show/2, которая ожидает в параметрах структуру conn и ассоциативный массив, имеющий ключ "id". В теле функции мы выставляем content-type ответа и отправляем код 200 и текстовое сообщение. Естественно, и это не то, что мы описали в тесте, поэтому тест опять будет неудачным. Займёмся реализацией нормальной функции.
Разработчики Elixir, Ecto и Phoenix Framework рекомендуют следовать идеологии "thin model, fat controller" — все операции с данными совершаются в контроллере и из функций контроллера, а запросы могут формироваться с помощью функций модели.
На данный момент нам необходимо получить из базы данных корневые разделы. Напишем функцию модели Grnti, которая будет формировать нужный запрос:
defmodule AtvApi.Grnti do
# ...
def descendants(parent_id) when parent_id == -1 do
from g in AtvApi.Grnti,
where: fragment("mod(?, ?)", g.id, 10000) == 0,
order_by: g.id
end
endОбратите внимание на использование ключевого слова when. Из Erlang Elixir унаследовал возможность использования guards: дополнительной проверки, осуществляемой уже после осуществления сопоставления с образцом, но до выполнения функции (или другого блока, поскольку guards можно использовать и в операторе case, и в прочих случаях). Не все операторы можно использовать в guards, список есть в документации. В данном случае функция выполнится только если параметр id будет равен -1. Можно было бы перенести значение прямо внутрь скобок, но в дальнейшем придётся более сложную логику организовать, и чтобы улучшить читабельность, сделаем так.
Содержимое самой функции — запрос на DSL модуля Ecto.Query. Из любопытного — использование в разделе where функции fragment/1 из модуля Ecto.Query.API. Она позволяет отправить базе данных любое выражение, не поддерживаемое в данный момент синтаксисом Ecto.Query. Эта функция в качестве аргумента принимает список, первый элемент которого — строка с фрагментом SQL-запроса, причём в этой строке знаками вопроса (?) отмечены места, в которые должны быть вставлены значения, представленные в списке далее. В данном случае нас интересует результат целочисленного деления id записи на 10000 — он должен быть равен нулю для корневых разделов.
Вернёмся к нашему контроллеру и перепишем функцию show/2 следующим образом:
defmodule AtvApi.GrntiController do
# ...
def show(conn, %{"id" => parent_id}) do
grnti = parent_id
|> Grnti.descendants
|> Repo.all
render(conn, "index.json", grnti: grnti)
end
endТеперь мы получаем ошибку ** (FunctionClauseError) no function clause matching in AtvApi.Grnti.descendants/1. Если вы посмотрите стек вызовов, показанный после ошибки, то обнаружите, что в функцию AtvApi.Grnti.descendants/1 передаётся строка "-1" вместо числа -1. И это понятно — параметр "id" берётся из URL GET-запроса, поэтому всегда будет строкой. Давайте добавим в модель ещё один вариант функции AtvApi.Grnti.descendants/1 перед имеющейся:
defmodule AtvApi.Grnti do
# ...
def descendants(parent_id) when is_binary(parent_id) do
parent_id
|> String.to_integer
|> descendants
end
def descendants(parent_id) when parent_id == -1 do
from g in AtvApi.Grnti,
where: fragment("mod(?, ?)", g.id, 10000) == 0,
order_by: g.id
end
endЕсли передаваемое значение — строка (функция is_binary/1 возвращает истину, если её аргумент — строковый), то мы переводим его в число и делаем вызов descendants/1 ещё раз, с новым значением.
Обратите внимание, сообщение об ошибке опять поменялось: ** (UndefinedFunctionError) function AtvApi.GrntiView.render/2 is undefined (module AtvApi.GrntiView is not available). Думаю, вы догадались, что ошибка вызвана тем, что у нас нет модуля представления (view). Создадим его:
defmodule AtvApi.GrntiView do
use AtvApi.Web, :view
def render("index.json", %{grnti: grnti}) do
%{data: render_many(grnti, AtvApi.GrntiView, "grnti.json")}
end
def render("grnti.json", %{grnti: grnti}) do
%{id: grnti.id,
title: grnti.title,
has_children: grnti.has_children}
end
end
Вообще, представления — это всего лишь набор функций, которые обрабатывают переданные данные и выдают модифицированную нужным образом версию. В частности, из нашего контроллера мы вызываем функцию Phoenix.Controller.render/3, которая, в свою очередь, попытается вызвать функцию Phoenix.View.render/2, описанную в соответствующем представлении, снабдив вторым (строкой или атомом) и третьим (данными) собственными параметрами. С помощью сопоставления с шаблоном из модуля представления будет выбрана нужная функция и исполнено её тело. Опять же, в данном случае будет вызвана функция, описанная как def render("index.json", %{grnti: grnti}). Эта функция вернёт ассоциативный массив с единственным ключом :data, значением которого окажется список, возвращаемый функцией render_many/3. Последняя функция принимает в качестве параметров данные, название модуля, в котором находится требуемый обработчик данных, и идентификатор — строка или атом (см. выше). Далее с каждым элементом переданных данных будет исполнена соответствующая функция обратного вызова Phoenix.View.render/2 и всё повторится до тех пор, пока все функции не вернут результаты своей работы, а сформированный список не будет передан в функцию, запущенную через render("index.json", %{grnti: grnti}), а результат её работы — запросившему страницу клиенту.
Собственно, если вы сейчас переключитесь на окно с тестами, то заметите, что все тесты — зелёные!
Прекрасно, одну задачу мы выполнили!
Теперь нам нужно реализовать получение подразделов второго уровня. Начнём, опять же, с функции-фильтра для тестовых данных. Добавим в модуль AtvApi.Factory новый вариант функции get_descendants/2:
defmodule AtvApi.Factory do
# ...
def get_descendants(:grnti, -1) do
grnti_list()
|> Enum.filter(fn(%{id: id}) ->
rem(id, 10000) == 0
end)
end
def get_descendants(:grnti, parent_id) when rem(parent_id, 10000) == 0 do
grnti_list()
|> Enum.filter(fn(%{id: id}) ->
rem(id, 100) == 0 and
id > parent_id and
id < parent_id + 10000
end)
end
defp get_list(:fos) do
# ..
endЗдесь мы также используем guard, разрешая выполнение нового тела только при остатке от целочисленного деления переданного параметра на 10000, равного нулю (т.е. все числа xx0000). В фильтре в теле функции мы проверяем, чтобы id был похож на xxxx00 и при этом был не менее id родителя и не более id следующего раздела уровня родителя.
Ручную проверку устройте сами, я убедился, что это работает.
Продолжим с тестами. Так как нас, по сути, нужно проверить, что тесты выводят правильные списки прямых подразделов, то тело каждого теста будет повторять друг друга практически дословно, за исключением кода родительского раздела. Но лучшие практики, включающие DRY, говорят нам, что повторяться — плохо. Поэтому прежде, чем копировать содержимое первого теста давайте воспользуемся механизмом передачи контекста ОТ тестов к setup и немного перепишем наш модуль для тестирования контроллера ГРНТИ:
defmodule AtvApi.GrntiControllerTest do
use AtvApi.ConnCase
import AtvApi.Factory
setup %{conn: conn, id: id} do
insert_all(:grnti)
conn = put_req_header(conn, "accept", "application/json")
descendants = :grnti
|> get_descendants(id)
|> Poison.encode!
|> Poison.decode!
conn = get conn, grnti_path(conn, :show, id)
{:ok, conn: conn, descendants: descendants}
end
@tag id: -1
test "shows chosen root level subtree", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
endВсю основную подготовительную логику мы перенесли в макрос setup, который, как мы помним, запускается перед каждым тестом. При этом в тесте осталась только непосредственно проверка результата. Для кастомизации тестов у нас есть метка @tag id: -1, встраивающая в контекст пару id: -1, которую мы и получаем в результате при входе в setup. Тест должен по-прежнему быть зелёным.
Чтож, настало время добавить ещё несколько тестов. Вставьте следующий текст после окончания описания первого теста:
# ...
@tag id: 000000
test "shows chosen second level subtree - id: 000000", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 020000
test "shows chosen second level subtree - id: 020000", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 030000
test "shows chosen second level subtree - id: 030000", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
#...Сейчас мы должны получить три проваленных теста, каждый из которых будет иметь ошибку ** (FunctionClauseError) no function clause matching in AtvApi.Grnti.descendants/1. И это логично — со стороны контроллера и модели у нас есть логика только для обработки кода родительского раздела, равного -1.
Замечательно, что мы написали наш контроллер таким образом, чтобы для внесения нового функционала потребуется изменить лишь поведение функции AtvApi.Grnti/descendants/1:
# ...
def descendants(parent_id) when parent_id == -1 do
from g in AtvApi.Grnti,
where: fragment("mod(?, ?)", g.id, 10000) == 0,
order_by: g.id
end
def descendants(parent_id) when rem(parent_id, 10000) == 0 do
from g in AtvApi.Grnti,
where: g.id > ^parent_id,
where: g.id < ^(parent_id + 10000),
where: fragment("mod(?, ?)", g.id, 100) == 0,
order_by: g.id
end
# ...Запрос, написанный с помощью Ecto, будет развёрнут в примерно следующий SQL-запрос:
SELECT g0."id", g0."title", g0."has_children", g0."inserted_at", g0."updated_at" FROM "grnti" AS g0 WHERE (g0."id" > $1) AND (g0."id" < $2) AND (mod(g0."id", 100) = 0) ORDER BY g0."id"где $1 — это код раздела, подразделы которого мы хотим получить, а $2 — код следующего раздела того же уровня.
Проверив окно с тестами, вы убедитесь, что они стали зелёными.
Осталось реализовать функциональность для вывода подразделов третьего уровня.
Фабрика:
defmodule AtvApi.Factory do
# ...
def get_descendants(:grnti, parent_id) when rem(parent_id, 10000) == 0 do
grnti_list()
|> Enum.filter(fn(%{id: id}) ->
rem(id, 100) == 0 and
id > parent_id and
id < parent_id + 10000
end)
end
def get_descendants(:grnti, parent_id) when rem(parent_id, 100) == 0 do
grnti_list()
|> Enum.filter(fn(%{id: id}) ->
id > parent_id and
id < parent_id + 100
end)
end
defp get_list(:fos) do
# ..
endТесты:
# ...
@tag id: 000900
test "shows chosen second level subtree - id: 000900", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 021500
test "shows chosen second level subtree - id: 021500", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 032300
test "shows chosen second level subtree - id: 032300", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
#...Сейчас 3 теста должны быть красными.
Реализация:
# ...
def descendants(parent_id) when rem(parent_id, 10000) == 0 do
from g in AtvApi.Grnti,
where: g.id > ^parent_id,
where: g.id < ^(parent_id + 10000),
where: fragment("mod(?, ?)", g.id, 100) == 0,
order_by: g.id
end
def descendants(parent_id) when rem(parent_id, 100) == 0 do
from g in AtvApi.Grnti,
where: g.id > ^parent_id,
where: g.id < ^(parent_id + 100),
order_by: g.id
end
# ...Все тесты стали красными!
Теоретически, на этом можно было бы закончить. Однако, если подумать, у нас остались сценарии, когда в качестве id будет приходить и вовсе не число, либо это число будет за пределами возможных кодов или указывать на раздел третьего уровня, у которого по определению задачи не может быть потомков.
Естественно, с такими ситуациями тоже нужно разобраться. При этом мы не можем просто добавить тест, который будет пытаться отправить символьную строку в качестве id — перед каждый тестом испольняется setup, в котором мы используем функцию AtvApi.Factory.descendants/2, совершенно не ожидающую строку на входе. Было бы очень удобно объединять тест в группы, верно?
Для таких целей в ExUnit.Case предусмотрен макрос describe/2. Он объединяет в себя несколько тестов и блоки setup для них. При этом setup, определённые внутри блока describe do ... end будут выполнятся только для тестов, включённых в этот же блок. Давайте добавим блок describe и вынесем общие моменты блока setup наружу:
defmodule AtvApi.GrntiControllerTest do
use AtvApi.ConnCase
import AtvApi.Factory
setup %{conn: conn, id: id} do
insert_all(:grnti)
conn = conn
|> put_req_header("accept", "application/json")
|> get(grnti_path(conn, :show, id))
{:ok, conn: conn}
end
describe "Controller must return descendants of" do
setup %{id: id} do
descendants = :grnti
|> get_descendants(id)
|> Poison.encode!
|> Poison.decode!
{:ok, descendants: descendants}
end
@tag id: -1
test "the root level", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 000000
test "the chapter with id: 000000", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 020000
test "the chapter with id: 020000", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 030000
test "the chapter with id: 030000", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 000900
test "the chapter with id: 000900", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 021500
test "the chapter with id: 021500", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
@tag id: 032300
test "the chapter with id: 032300", %{conn: conn, descendants: descendants} do
assert json_response(conn, 200)["data"] == descendants
end
end
endТесты после такого изменения должны остатья зелёными.
Добавим теперь тесты с проверкой некорректных значений id. Такими значениями должны быть:
- строки,
- числа меньше -1 и больше 999999,
- код разделов третьего уровня, т.е. имеющие остаток от целочисленного деления на 100, не равный нулю.
Добавьте ещё один блок describe/2 к нашим тестам:
defmodule AtvApi.GrntiControllerTest do
use AtvApi.ConnCase
# ...
describe "Request must be declined with status code 422 and appropriate JSON error message in case of" do
@tag id: "somestring"
test "id as a non-digit symbol string", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
@tag id: -2
test "id is less than -1 and equal -2", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
@tag id: -100
test "id is less than -1 and equal -100", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
@tag id: 1000000
test "id is greater than 999999 and equal 1000000", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
@tag id: 90000000
test "id is greater than 999999 and equal 90000000", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
@tag id: 030955
test "id is a third level section code and equal 030955", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
@tag id: 020129
test "id is a third level section code and equal 020129", %{conn: conn} do
assert json_response(conn, 422)["error"] == %{message: "Unprocessable Entity"}
end
end
endНачнём реализацию. Для начала нам придётся перенести в контроллер попытку конвертации id из строки в число. Причём так как String.to_integer/1 в случае ошибки генерирует исключение, нам нужна более безопасная функция. Такой функцией является Integer.parse/2. Второй параметр — основание системы счисления, представление числа в которой передаётся первым строковым параметром — по умолчанию 10, т.е. считается, что передаваемая строка содержит представление десятичного числа. Возвращает эта функция в случае успеха кортеж {integer, reminder_of_binary}или :error в противоположном случае.
Приведём контроллер к следующему виду:
defmodule AtvApi.GrntiController do
use AtvApi.Web, :controller
alias AtvApi.Grnti
def show(conn, %{"id" => parent_id}) do
case Integer.parse(parent_id) do
:error -> show(conn, :error)
{int, _} -> show(conn, int)
end
end
def show(conn, parent_id)
when is_integer(parent_id)
and parent_id > -2
and parent_id < 1000000
and (
rem(parent_id, 100) == 0 or parent_id == -1
)
do
grnti = parent_id
|> Grnti.descendants()
|> Repo.all()
render(conn, "index.json", grnti: grnti)
end
def show(conn, _parent_id) do
conn
|> put_resp_content_type("application/json")
|> send_resp(422, ~S({"error":{"message":"Unprocessable Entity"}}))
end
endПопробуйте самостоятельно разобраться в том, что тут происходит, а потом
Первый вариант функции show/2 запускается в случае, если в качестве второго параметра приходит ассоциативный массив, т.е. при корректном обращении по правильному URL. В ней производится попытка преобразовать в строку в число, а затем с результатом преобразования функцию show/2 запускается снова. В этот раз первый вариант не может быть сопоставлен с параметрами. В случае, если второй параметр удовлетворяет требованиям, перечисленным в guard второго варианта функции, мы осуществляется запрос к базе и действует ранее реализованный функционал. Во всех остальных случаях запускается третий вариант, который формирует ответ прямо в теле функции, выставляет заголовок ответа Content-Type: application/json и в качестве тела ответа помещает строку, сформированную с помощью значка (sigil) строки.
На этом мы получили требуемую функциональность нашего back-end. Конечно, полировать и совершенствовать можно долго (к примеру, тесты нашего контроллера GrntiController по-прежнему не удовлетворяют принципу DRY и так и просятся быть сформированными динамически). Более того, нынешний вид всё это приобрело как раз в процессе написания статьи, а в изначальном проекте из-за недостатка времени и отсутствия необходимости дальнейшей поддержки было реализовано несколько менее опрятно, качественно и продуманно.
Остаётся лишь запустить наш проект с помощью mix phoenix.server и с помощью браузера проверить результат:

С серверной частью закончили, в следующей статье мы с вами постараемся реализовать front-end приложение, которое будет отображать данные, передаваемые с сервера. Правда, статья ещё не написана, и её появление напрямую будет зависеть от реакции на эту публикацию.
Код back-end, полностью готовый для развёртывания, лежит на GitHub.
Критика, изменения и дополнения принимаются с огромным удовольствием. Хорошего дня!
Комментарии (10)

16433407
28.02.2017 17:45может кэш для справочника? В финиксе есть кэш из коробки?

heathen
28.02.2017 23:04Вы имеете ввиду кэширование обращений к базе (кэш данных) или кэш выдачи?
Вообще, своего нет ни того, ни другого. Но простейший кэш можно реализовать буквально несколькими строчками на Elixir:
несколько строк и результат использованияdefmodule Example.KeyValueStore do use GenServer # Client API def start_link(initial_state \\ %{}) do GenServer.start_link(__MODULE__, initial_state, name: __MODULE__) end def get(key) do GenServer.call(__MODULE__, {:get, key}) end def put(key, value) do GenServer.cast(__MODULE__, {:put, key, value}) end # Server API def handle_call({:get, key}, _from, state) do {:reply, Map.get(state, key), state} end def handle_cast({:put, key, value}, state) do {:noreply, Map.put(state, key, value)} end end
Для того, чтобы понять, что получилось, запустите интерактивную оболочку Elixir
iex, скопируйте сначала код выше (не забудьте завершающий перевод строки) и затем вводите следующее:
iex> alias Example.KeyValueStore, as: KVS Example.KeyValueStore iex> KVS.start_link {:ok, #PID<0.114.0>} iex> KVS.get(:one) nil iex> KVS.put(:one, "some text") :ok iex> KVS.put(:complex_structure, %{name: "test", title: "record"}) :ok iex> KVS.put(12345, "key can be any type") :ok iex> KVS.get(:one) "some text" iex> KVS.get(:complex_structure) %{name: "test", title: "record"} iex> KVS.get(12345) "key can be any type"
Source
01.03.2017 00:17+1Зачем свой велосипед пилить? Есть же ETS, но сути аналог memcached, только быстрее.
В качестве дополнительной обёртки можно ConCache использовать.heathen
01.03.2017 11:26А пилить вообще ничего не нужно никогда, тут я с вами согласен; поэтому и написал — простейший вариант. Кроме того, какая-никакая, но демонстрация GenServer, хоть и без пояснений.
Но, если уж об этом говорить, стоило бы мне, конечно, начать с того, что разработчики языка вообще не рекомендуют вводить кэширование до тщательного профилирования приложения и полной уверенности в том, что именно кэшированием узкое место будет исправлено. И — если более глобально — вообще не лезть в оптимизацию до того, как в этом возникнет реальная необходимость.
Кстати, решений для кэширования есть в ассортименте, одним ConCache дело не заканчивается.
zShift
чекнутые ботаники…
heathen
Да не переживайте вы так, и вы такую траву выращивать научитесь :)
zShift
Йо. Йо*ан* рот… Мне хватает знания PHP и чистого JS. Что еще из этого дерьма вы хоите притащить в индустрию и сделать это мейнстримом? Я в свободное время пью, курю и с девочками отдыхаю, а мне и не надо ваших Ангуляторов и Эликсиров. Это ничего хорошего. Я что-то типа этого имел ввиду. Может вы еще в мультикомбайн на понтах дела превратитесь и начнете пилить за всю команду в одно рыло?
Мне такая трава не нужна. Я свою работу знаю и умею, но такие как вы делают что-то уму невообразимое. Потому что начитаются и думают что это круто и начинают кривляться и подражать.
Прикол приколом, но пользы от такого…
develop7
Привет от Даннинга с Крюгером.
heathen
Всё-таки нервничаете… зря. Эдак вы все нервные клетки растеряете.
zShift
Я вас просто трахну вашими же собственными какашками через прослушку… Легко и просто… Ждите