
Микроклоны — это дублированные фрагменты кода очень малого размера — всего лишь несколько инструкций или строк. В этой статье мы рассмотрим «эффект последней строки» — явление, при котором последняя строка или инструкция в микроклоне с гораздо большей вероятностью содержит ошибку, чем предыдущие строки или инструкции. С этой целью мы изучили 219 открытых проектов и 263 предупреждения о дефектных микроклонах, а также опросили шестерых авторов реальных приложений, допускавших такие ошибки в своем коде. В нашей междисциплинарной работе также изучаются психологические механизмы, обуславливающие сравнительно тривиальные ошибки этого типа. Опираясь на результаты опросов и дальнейшего технического анализа, мы предполагаем, что в существовании эффекта последней строки ключевую роль играют так называемые «ошибки последовательности действий»: при копировании кода внимание разработчиков переключается на другие задачи из-за отвлекающих факторов и монотонной природы самой этой процедуры. Более того, все микроклоны, чье происхождение мы смогли установить, были обнаружены в непривычно больших коммитах. Знание о данном эффекте имеет два полезных следствия для программистов:
1) им будет легче распознавать ситуации, в которых особенно велика вероятность допустить ошибку в микроклонах;
2) они смогут использовать автоматический детектор микроклонов / PVS-Studio, что упростит обнаружение ошибок этого типа.
Микроклоны, клоны кода, обнаружение клонов кода, эффект последней строки, психология, междисциплинарное исследование.
Разработчикам программ часто приходится дублировать одну строку кода несколько раз подряд с небольшими изменениями, как в следующем примере из проекта TrinityCore:
Пример 1
TrinityCore
Пространственные координаты объекта other прибавляются к полям, соответствующим координатам x, y, z, но в последней строке этого фрагмента из трех однотипных строк содержится ошибка: y-координата прибавляется к z-координате. На самом деле последняя строка должна выглядеть так:
Следующий пример взят из популярного веб-браузера Chromium и демонстрирует проявление рассматриваемого эффекта в однотипных инструкциях в пределах одной строки:
Пример 2
Chromium
Вместо двойной проверки хоста (host) на равенство пустой строке вторая проверка должна выполняться для port_str:
Строки 1-3 из примера 1 похожи между собой, так же как и условия if-оператора в строке 3 примера 2. Такие исключительно короткие блоки кода, состоящие из почти идентичных повторяющихся строк или инструкций, мы будем называть микроклонами. Наш собственный опыт в разработке и консультировании по вопросам качества ПО подсказывал нам на интуитивном уровне, что последняя строка или инструкция в микроклоне с гораздо большей вероятностью содержит ошибку, чем предыдущие строки или инструкции. Цель этой работы состоит в проверке истинности нашего ощущения, и именно этой целью обусловлены два вопроса, поставленные в рамках настоящего исследования:
Поскольку копирование блоков кода при написании программ применяется в большинстве языков программирования, эффекту последней строки может быть подвержен практически каждый разработчик. Если нам удастся доказать, что последняя из нескольких идущих подряд однотипных инструкций больше подвержена ошибке, авторы и инспекторы кода будут знать, каким участкам следует уделять особое внимание, что поможет повысить качество программы за счет сокращения количества ошибок.
Копирование и вставка — один из естественных способов создания кода, подобного примерам 1 и 2. Проведя работу по определению происхождения кода среди дубликатов в отобранных нами примерах, мы пришли к выводу, что разработчики пользуются целым рядом механических приемов их создания, из которых самыми важными являются построчное копирование-вставка и «клонирование» участков кода. Эти методы — одни из самых распространенных идиом программирования (Kim и др. 2004), они требуют минимальных физических и временных затрат, а потому дешевы; кроме того, известно, что такой код работоспособен. Хотя копирование малых участков кода часто рассматривается как вредный прием (Kapser and Godfrey 2008), иногда это единственный способ, позволяющий реализовать желаемое поведение программы, как в рассмотренных выше примерах. Было разработано несколько инструментов для обнаружения и, по возможности, устранения микроклонов (Bellon и др. 2007; Roy и др. 2009). Несмотря на то что эти инструменты продемонстрировали впечатляющие результаты вплоть до уровня методов, они плохо приспособлены для распознавания микроклонов на практике из-за слишком большого количества ложных срабатываний.
После того как мы опубликовали статью об эффекте последней строки в научно-популярном блоге, ее быстро и с большим энтузиазмом стали цитировать на других форумах. Многие программисты соглашались с нашими наблюдениями и высказывали предположение, что за обсуждаемым эффектом стоят психологические причины. Отсюда проистекает наш третий, и последний, вопрос в рамках настоящего исследования:
Опираясь на результаты опросов разработчиков, тщательного технического анализа примеров и сотрудничества с психологом, мы попытаемся выяснить, влияют ли психологические аспекты — и если да, то какие — на проявление эффекта последней строки. Изучив явления, давно наблюдаемые когнитивной психологией, мы выясним, можно ли с их помощью объяснить эффект последней строки в микроклонах кода.
Взяв за основу проведенное нами ранее исследование эффекта последней строки (Beller и др. 2015), мы внесли в него следующие дополнения:
Наши наблюдения показывают, что последняя строка или инструкция в микроклонах, подобных тем, что представлены в примерах 1 и 2, с гораздо большей вероятностью содержат ошибку, чем любые из предшествующих строк или инструкций. Нам представляется, что существование этого явления обусловлено не технической сложностью микроклонов, а психологическими причинами, которые, в свою очередь, в основном сводятся к перегрузке кратковременной памяти программистов. Предварительное исследование на базе пяти проектов выявило, что все микроклоны с ошибками были написаны в аномально больших коммитах в нестандартное рабочее время. Знание этих особенностей и помощь нашего автоматизированного статического анализатора PVS-Studio могут способствовать сокращению количества тривиальных ошибок, связанных с эффектом последней строки, за счет автоматического их обнаружения.
Наша работа состоит из двух частей: эмпирических исследований C1 и C2. В данном разделе мы опишем порядок проведения исследований и их объекты.
В исследовании C1, состоящем из пяти легко воспроизводимых этапов, мы провели статистический анализ распространенности эффекта последней строки в микроклонах. Более того, в попытке пролить свет на процесс создания микроклонов мы проделали дополнительную работу по выявлению оригинальных участков кода и их копий.
Установив существование эффекта последней строки в исследовании C1, мы должны теперь попытаться выявить обуславливающие его причины (RQ 3). Для этого мы разработали начальную гипотезу, основываясь на результатах исследований в области когнитивной психологии, в чем нам помогал профессор когнитивной психологии Рольф Цваан. Для подтверждения нашей гипотезы, а также для сбора свидетельств из практики разработчиков мы опросили программистов, ответственных за создание микроклонов, обнаруженных в ходе исследования C1. Их замечания и наблюдения помогут нам разработать предварительную версию, объясняющую существование эффекта последней строки. Сужение круга опрашиваемых исключительно до лиц, чье авторство в отношении дефектных микроклонов точно установлено, позволяет нам: (1) сосредоточиться на конкретных примерах, к которым опрашиваемые имеют непосредственное отношение; (2) получить максимально полезные ответы, поскольку мы знаем наверняка, что именно эти разработчики были ответственны за написание обсуждаемых микроклонов.
На рис. 1 показан общий план нашего исследования. Основная задача состоит в том, чтобы установить контакт с авторами микроклонов (во многих случаях дефектный код отсутствует в последней версии проекта). План включает в себя четыре основных этапа:
Рис. 1 — План исследования C2
Чтобы облегчить воспроизведение нашей работы другими исследователями, мы отдали предпочтение хорошо известным проектам с открытым кодом. Среди 219 проектов, изученных нами в исследовании C1, ошибочные микроклоны были обнаружены в таких знаменитых проектах как аудиоредактор Audacity (1 пример), веб-браузеры Chromium (9) и Firefox (9), XML-библиотека libxml (1), базы данных MySQL (1) и MongoDB (1), компилятор языка C clang (14), FPS-шутеры Quake III (3) и Unreal 4 (25), пакет для создания компьютерной графики Blender (4), программа для трехмерного моделирования и визуализации VTK (8), сетевые протоколы Samba (4) и OpenSSL (2), видеоредактор VirtualDub (3), а также язык программирования PHP (1). Для исследования C2 мы отобрали 10 микроклонов из проектов Chromium, libjingle, Mesa 3D и LibreOffice.
Для облегчения работы других исследователей мы подготовили специальный пакет, куда вошли все исходные данные и диагностики. В него включены все неотфильтрованные сообщения PVS-Studio, сгруппированные по двум директориям: findings_old/, где содержатся старые данные, использованные в нашей статье для Международной конференции по обозримости программ (ICPC) (Beller и др. 2015), и findings_new/ с более свежими данными, использованными в настоящей статье. Кроме того, в пакет входят проанализированные нами и отсортированные по проектам микроклоны (analyzed_data.csv), электронная таблица с оценкой данных (evaluation.ods) и результаты анализа репозиториев из исследований C1 и C2. Мы также добавили скрипты на языке R для воспроизведения результатов и диаграмм из данной статьи. Наконец, в пакете содержится шаблон анкеты с вопросами для респондентов.
В данном разделе мы рассмотрим традиционные способы обнаружения дублированных фрагментов кода, объясним, почему они не подходят для поиска микроклонов, и покажем, каким образом мы смогли обойти эту проблему, используя наши собственные диагностики статического анализа. Кроме того, мы покажем, как определялись оригинальные участки и копии в микроклонах и как учитывались размеры коммитов.
Как показывают примеры 1 и 2, фрагменты кода, рассматриваемые в рамках этой статьи, либо полностью совпадают по тексту, либо содержат «клоны с одинаковой синтаксической структурой, отличающиеся только идентификаторами переменных, типов или функций» (Koschke 2007). По этой причине они представляют собой клоны 1 или 2 типа чрезвычайно малого размера (как правило, меньше 5 строк/инструкций) — именно их мы и называем микроклонами.
Традиционные методы обнаружения дублированного кода заключаются в сравнении токенов, строк кода, узлов абстрактного синтаксического дерева (АСД) или графов (Koschke 2007). Однако на практике в любом из этих подходов требуется определить минимальный размер клона в условных единицах измерения (будь то токены, инструкции, строки или узлы АСД) для снижения процента ложных срабатываний. Как правило, это значение берется в районе 5-10 единиц (Bellon и др. 2007; Juergens и др. 2009), что намного превосходит размер рассматриваемых нами микроклонов (2-5 единиц) и делает невозможным их поиск.
Так, в примере 1 строки 1-3 представляют собой класс микроклонов. Поскольку строк три, то данный класс представлен в этом примере в трех экземплярах. В свою очередь, каждый экземпляр состоит из переменной, операции присваивания, присваиваемого объекта и его поля и, таким образом, имеет длину 4 единицы.
Поскольку на практике традиционные методы поиска неспособны надежно обнаруживать микроклоны, мы использовали свой собственный подход. Наша задача состоит в обнаружении не любых микроклонов, а только тех, которые содержат ошибки. Учитывая это дополнительное ограничение, мы смогли разработать целый набор мощных диагностик, обнаруживающих микроклоны по признаку обычного посимвольного совпадения. Эти диагностики способны находить дефектные участки кода, которые с большой вероятностью появились в результате копирования малых фрагментов. В табл. 1 перечислены и описаны все двенадцать диагностик, которые позволили обнаружить ошибки в микроклонах в рамках этого исследования. В последнем столбце показано отношение числа одно- и многострочных клонов к общему количеству предупреждений данного типа. Например, диагностика V501 всего лишь определяет, являются ли идентичными операнды некоторых логических операторов. Если ответ положительный, то в лучшем случае это просто лишний код, который может затруднить поддержку программы в будущем, в худшем — настоящая ошибка. Другие диагностики не настолько узкоспециализированы по отношению к микроклонам, как V501. Мы изучили каждое из 526 предупреждений и отобрали для нашего исследования только 272 случая реальных микроклонов. Из табл. 1 можно также увидеть, что 78% микроклонов были обнаружены одной диагностикой (V501) с очень низким процентом ложных срабатываний — 3%. Другие диагностики с большей вероятностью могут срабатывать на участки кода, не являющиеся микроклонами.
Таблица 1 — Типы ошибок, обнаруживаемых PVS-Studio, и их распределение по 219 открытым проектам
Чтобы компетентно рассуждать о причинах существования эффекта последней строки, отвечая на вопрос RQ 3, мы также нашли в каждом классе микроклонов оригинальный экземпляр кода и экземпляр, который предположительно был скопирован с него. Хотя подобный эмпирический анализ не дает стопроцентную уверенность, что процедура копирования шла именно в таком направлении, у нас имеются достаточные свидетельства, что по крайней мере некоторые разработчики механически клонируют код именно таким образом (см. RQ 3). В большинстве случаев можно сразу определить, какой из двух экземпляров микроклона является оригиналом, а какой — копией. Так, в примере 1 строка 3, содержащая ошибку, включает в себя следы кода из строки 2, что подразумевает влияние строки 2 (оригинал) на строку 3 (копия). Подобный естественный порядок следования оригинальных строк и копий наблюдается в большинстве микроклонов — будь то лексикографический порядок, как, например, в последовательности переменных x, y, z в примере 1, или числовой:
Пример 3
Cmake
Даже в тех случаях, где естественный порядок расположения оригинального экземпляра и копии не выражен явно, как в примерах 1 и 3, его можно восстановить по контексту, как в примере 2: помещение port_str на первое место и host на второе в строке 3 противоречит порядку, в котором эти переменные были определены ранее, — значит, первая инструкция host != buzz::STR_EMPTY является оригиналом, а вторая — копией.
В процессе установления происхождения копии в рассматриваемых примерах мы сталкиваемся с двумя проблемами, а именно: 1) размер копируемого участка может варьировать; 2) микроклоны длиной свыше 4 дубликатов представлены меньшим числом примеров. Чтобы, тем не менее, иметь возможность обобщить данные для разных размеров микроклонов, для каждого микроклона i мы вычисляем , что дает нам степень удаленности
, что дает нам степень удаленности  .
.
Степень удаленности 1 говорит о копировании из непосредственно предшествующей строки/инструкции, как в примере 4. Значение 0: ошибка произошла в той же строке микроклона. Значение -1 указывает на обратный порядок копирования: из второй единцы — в первую:
Пример 4
UnrealEngine4
В этом примере в строке 1 естественно ожидать cx().isRelative вместо cy().isRelative, что говорит о возможном копировании из второй строки. Логика использования переменных с подобными именами, а также порядок следования строк 3 и 4 говорят о том, что копия должна начинаться с return cx().isRelative() в первой строке.
Отсюда получаем степень удаленности или
или  , что указывает на непосредственное соседство двух дубликатов либо в одной строке, либо на двух смежных, независимо от общего размера клонированного участка.
, что указывает на непосредственное соседство двух дубликатов либо в одной строке, либо на двух смежных, независимо от общего размера клонированного участка.
Чтобы вычислить и представить отношение размеров каждого из коммитов, содержащих дефектные микроклоны, к остальным коммитам, мы вначале вычисляем изменчивость для каждого коммита в репозитории. Для этого мы используем инструмент git log, который позволяет строить упорядоченные графы всех коммитов (исключая слияния) в репозитории, выявляя, таким образом, число добавленных и число удаленных строк кода в каждом коммите. Сумма этих чисел и дает общее количество измененных строк, т.е. величину изменчивости, для каждого коммита. Затем мы сравниваем изменчивость коммитов, содержащих дефектные микроклоны, с распределением этого параметра в остальных коммитах, а в особенности — с его медианой. Хотя наша выборка (десять примеров) слишком мала для надежного статистического анализа, этот подход все же позволяет нам сделать обоснованные выводы о возможной разнице в размерах коммитов. Мы используем медиану (а не среднее, например), потому что имеем дело с неправильными распределениями; медиана — самостоятельное, реальное значение, с которым мы сравниваем другие такие же значения.
В этом разделе мы более подробно исследуем дефектные микроклоны, изучив примеры и проведя статистическую оценку.
В табл. 2 собрана основная статистика по результатам исследования C2. На протяжении периода с середины 2011 года по июль 2015 года мы применяли полный набор диагностик PVS-Studio на выбранных нами 219 открытых проектах. Андрей Карпов, который специализируется на консультации по разработке ПО, выполнял анализ всех этих проектов, используя последние версии PVS-Studio, доступные на момент проверки каждого конкретного проекта. Он отфильтровал ложные срабатывания, в результате чего осталось 1 891 предупреждение, указывающее на потенциальные дефекты в коде. Эти предупреждения были сгруппированы по 162 диагностикам. Затем мы изучили каждое сообщение и обнаружили, что 272 из них были выданы двенадцатью диагностиками и имеют отношение к микроклонам. В девяти случаях сообщения дублировались, поэтому в итоге осталось 263 микроклона. Статистический анализ на уровне проектов показывает, что наши диагностики смогли распознать клоны с дефектами в половине из отобранных проектов. Почти все эти случаи (92%) содержат по меньшей мере один пример с эффектом последней строки.
Таблица 2 — Статистика по результатам исследования
Табл. 3 содержит сводку по обнаруженным ошибкам в 263 микроклонах. В общей сложности, 74% многострочных клонов содержат ошибку в последней строке и 90% однострочных клонов — в последней инструкции.
Таблица 3 — Сводка по результатам исследования
Для более полного понимания принципов работы диагностик, которые мы применили для обнаружения микроклонов, ниже мы рассмотрим некоторые наиболее показательные примеры из 263 предупреждений PVS-Studio, относящихся к микроклонам и выявляющих наиболее частые ошибки из табл. 1.
Как видно из табл. 1, большинство предупреждений о микроклонах были выданы диагностикой V501. Ниже показан типичный пример такой ошибки из браузера Chromium:
Пример 5
Chromium
Это однострочный микроклон, в котором второе и третье подвыражения полностью совпадают, но при этом соединяются логическим оператором ИЛИ (||), что делает выражение избыточным. На самом деле, оно должно было проверять фамилию (NAME_LAST) — так в этом блоке из трех единиц проявляется эффект последней строки.
Диагностика V517 обнаруживает одинаковые условия для двух веток if-оператора.
Пример 6
linux-3.18.1
Тело оператора else if после третьего микроклона на строке 9 является мертвым кодом, поскольку поток исполнения никогда не достигнет его. Случай, когда значение slot равно 0, будет обработан уже в первом условии.
Присваивание переменной двух значений подряд обычно является либо просто избыточной операцией (и, следовательно, создает проблемы при поддержке кода, затрудняя его понимание, так как первое присваивание оказывается недействительным), либо откровенной ошибкой, так как в качестве правого операнда должно было быть другое значение. В следующем примере из проекта MTASA переменной m_ucRed дважды присваивается значение, в то время как переменной m_ucBlue присвоить значение забыли.
Пример 7
MTASA
Диагностика V519 хорошо показала себя при обнаружении дефектов в большинстве «обычных» программ, однако следует с осторожностью подходить к анализу кода прошивок и прочего низкоуровневого кода, как показано в примере 8:
Пример 8
linux-3.18.10
Во второй строке переменной f->fmt.vbi.samples_per_line повторно присваивается значение, несмотря на то что строчкой выше ей уже было присвоено другое значение. Поскольку дальше в потоке управления в данном методе отсутствуют вызовы других методов, может показаться, что присваивание в строке 1 не дает никакого результата. Однако, поскольку это присваивание действует на протяжении по крайней мере одного такта, за это время присвоенное значение может быть прочитано из других потоков (например, сторожевым таймером, отслеживающим состояние буфера) или использоваться каким-либо другим способом. На всякий случай мы компилируем такой код в режиме Release: если компилятор в процессе оптимизации убирает первое присваивание, значит, это действительно ошибка.
Микроклоны в разных ветках if-оператора обычно можно упростить, оставив только один блок, как в следующем примере из Haiku:
Пример 9
Haiku
Более вероятно, однако, что в ветке else переменной mpa_size должно было быть присвоено какое-то другое значение. Контекст данного микроклона вызывает подозрения, так как в комментарии в строке 3 сказано, что «с компрессией тут все неправильно», а обнаруженный дефектный микроклон подходит под эту формулировку.
Две дублированные функции с одним и тем же телом очень подозрительны. В примере 10 в строке 5 должен быть вызов PerPtrBottomUp.clear(). Также это один из редких примеров, когда в микроклоне из двух дубликатов копия предшествует оригиналу .
.
Пример 10
Clang
Показательный пример диагностики V537, приведенный ниже, взят из Quake III. В этом случае PVS-Studio предупреждает о необходимости проверить использование rectf.X:
Пример 11
Quake III
Во второй (т.е. последней) строке данного клона y-координата прямоугольника ошибочно задается округленным значением rectf.X.
Диагностика V656 выявляет разные переменные, которые инициализируются одной и той же функцией. Однако мы вынуждены проявлять осторожность при анализе таких предупреждений, поскольку среди них потенциально может наблюдться много ложных срабатываний. В качестве подобного примера можно привести случай, когда две переменные инициализируются одним и тем же значением, но затем, ниже по коду, начинают различаться. Все микроклоны нашей выборки, относящиеся к диагностике V656, взяты из проекта LibreOffice.
Пример 12
LibreOffice
В этом случае переменной maSelection.Max() вместо максимального значения aSelection присваивается минимальное, что явно указывает на ошибку.
Как мы уже видели в примере 12, не во всех дефектных микроклонах ошибка локализуется в последней строке или инструкции. Следующий пример из Chromium — один из 12 случаев, когда ошибка проявляется во второй строке трехстрочного микроклона (см. табл. 4):
Пример 13
Chromium
В строке 2 ячейка data_[M02] вычитается сама из себя, хотя на самом деле подразумевалось следующее:
Таблица 4 — Распределение ошибок в микроклонах размером ?? 2 строк
В табл. 4 показано распределение ошибок по строкам для 158 многострочных микроклонов, а в табл. 5 — распределение ошибок по инструкциям внутри одной строки для 105 однострочных микроклонов. Ячейки с серым фоном не содержат значащих данных. Например, в микроклоне длиной 2 строки не может быть ошибок в третьей строке. Ячейки с желтым фоном, расположенные по диагонали, соответствуют ошибкам в последних строках или инструкциях.
Таблица 5 — Распределение ошибок в однострочных микроклонах
Для каждого столбца табл. 4 и 5 мы применили критерий согласия Пирсона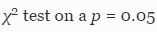 с уровнем значимости p = 0,05, чтобы определить, являются ли индивидуальные распределения неравномерными. Получившиеся в результате p-значения, приведенные в последней строке таблицы имеют смысл только для микроклонов таких размеров, в отношении которых мы располагаем достаточным количеством эмпирических данных. Такие случаи представлены в столбцах 2-6 табл. 4 и столбцах 2-4 табл. 5.
с уровнем значимости p = 0,05, чтобы определить, являются ли индивидуальные распределения неравномерными. Получившиеся в результате p-значения, приведенные в последней строке таблицы имеют смысл только для микроклонов таких размеров, в отношении которых мы располагаем достаточным количеством эмпирических данных. Такие случаи представлены в столбцах 2-6 табл. 4 и столбцах 2-4 табл. 5.
Отвечая на вопросы RQ1 и RQ2, мы получили статистически значимые p-значения для микроклонов длиной 2, 3, 4, 5 или 6 строк и для микроклонов из 2, 3 или 4 инструкций (p < 0,05). Эти результаты говорят о том, что нулевая гипотеза о равномерном распределении ошибок по строкам/инструкциям неверна и может быть отброшена. В реальности ошибки в гораздо большей степени концентрируются в последней строке или инструкции. Мы предполагаем, что в микроклонах большего размера будет наблюдаться такое же распределение, но подобных примеров в нашей выборке слишком мало, чтобы подтвердить это предположение статистически. Этим случаям соответствуют ячейки с серым фоном в последней строке табл. 4 и 5.
Распределения ошибок в микроклонах разной длины составляют две группы: «ошибка не в последней строке/инструкции» и «ошибка в последней строке/инструкции» (см. табл. 3). Подсчет абсолютных значений показывает, что в микроклонах, подобных примеру 1, вероятность ошибки в последней строке почти втрое больше, чем во всех предыдущих строках вместе взятых. Как видно из табл. 4, вероятность ошибки в последней строке в клонах длиной 2, 4 и 5 строк (самые многочисленные примеры) может достигать девятикратного значения по сравнению с остальными строками. Аналогичные показатели для дублированных инструкций в однострочных клонах, как в примере 2, еще выше: вероятность ошибки в последней инструкции в 9,5 раз выше, чем во всех остальных инструкциях вместе взятых. Фактически ошибка находилась в последней из двух инструкций во всех 72 случаях, кроме одного.
В целом, можно утверждать, что результаты нашего исследования подтверждают наличие заявленного эффекта последней строки/инструкции, что позволяет ответить утвердительно на вопросы RQ 1 и RQ 2.
Обнаружив большое количество предположительно тривиальных ошибок, связанных с микроклонами, в открытых проектах, мы поставили перед собой задачу выяснить причины существования этого явления. Вопрос RQ 3 нашего исследования звучит так:
В этом разделе мы сначала изучим происхождение микроклонов, а затем рассмотрим технические и психологические причины появления дефектных микроклонов.
В табл. 6 показано распределение оригинальных участков кода по номерам строк в зависимости от длины микроклона. В этом исследовании мы отбросили микроклоны, для которых не удалось достоверно установить порядок следования оригинала и копии. Таким образом, из 263 пар дубликатов осталось 245.
Таблица 6 — Длина клона (по горизонтали) и номер оригинальной строки (по вертикали)
На рис. 2 показаны диаграммы распределения оригинальных экземпляров по номерам строк в микроклоне. Как видно из рисунка, в 165 случаях из 245 (67%) исходной является первая строка. Затем наблюдается резкий спад на второй позиции — 18 %, а далее частота плавно уменьшается к третьей (9%) и четвертой позициям (3%). Лишь в оставшихся 4% случаев оригинал располагается после четвертой строки или инструкции. Такое распределение, по всей видимости, указывает на то, что первая строка оказывает наибольшее влияние на весь блок. Впрочем, многие наши примеры состоят из двух строк: вполне естественно, что в большинстве таких случаев исходной оказывается первая строка. Если исключить их из расчетов и рассматривать только оставшиеся 117 микроклонов из трех и более строк/инструкций, выясняется, что оригинальный код находится в первой строке только в 33 случаях (28%). Поскольку средняя длина примеров составляет 4,9 строк, мы ожидали, что первая строка будет исходной в 20% случаев, даже при равномерном распределении ошибок. Однако полученное значение 28% говорит о том, что первая строка оказывает лишь умеренное влияние на весь клон, если не учитывать двухстрочные клоны. Тем не менее, почти во всех микроклонах из двух строк исходной является первая строка, а не вторая.
Рис. 2 — Положение оригинальных экземпляров в микроклоне (слева) и удаленность оригинала и копии в пределах микроклона (справа)
На рис. 2 также показана диаграмма, отражающая степень удаленности между оригиналом и копией (см. раздел 3.3). Как видно, более 84% оригинальных экземпляров и копий являются непосредственными соседями (220 случаев из 245), т.е.
(см. раздел 3.3). Как видно, более 84% оригинальных экземпляров и копий являются непосредственными соседями (220 случаев из 245), т.е. 
Для 89% из них (195 из 220)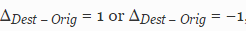 или . Это означает, что дубликат с ошибкой находится после оригинала в следующей строке или инструкции. Гораздо реже встречается обратный порядок, т.е.
или . Это означает, что дубликат с ошибкой находится после оригинала в следующей строке или инструкции. Гораздо реже встречается обратный порядок, т.е.  (3 случая из 220). Если исключить из расчетов клоны из двух строк или инструкций, в которых экземпляры естественным образом являются соседями, оказывается, что в 81% случаев дубликаты находятся непосредственно рядом друг с другом (66 из 81). Таким образом, результаты исследования можно обобщить в следующих выводах:
(3 случая из 220). Если исключить из расчетов клоны из двух строк или инструкций, в которых экземпляры естественным образом являются соседями, оказывается, что в 81% случаев дубликаты находятся непосредственно рядом друг с другом (66 из 81). Таким образом, результаты исследования можно обобщить в следующих выводах:
В рамках исследования C2 мы опросили десять разработчиков реальных приложений, которые в своей работе допускали ошибки в микроклонах. Респондентам предлагалось ознакомиться с микроклонами их авторства и дополнительной контекстуальной информацией. Опрашиваемым было предложено ответить, помнят ли они следующие подробности:
Табл. 7 содержит сводку по десяти примерам микроклонов и ответам семи респондентов, написавшим их. Опросы проводились независимо друг от друга по электронной почте и Skype. В таблице указаны названия отобранных проектов и версии коммитов, даты применения коммитов, медиана и индивидуальные размеры коммитов, выраженные через величину изменчивости, а также общее количество коммитов в проекте. В целях сохранения анонимности респондентов I1-I7 мы не указываем их ID-номера в коммитах и не раскрываем авторства представленных ниже примеров. В случаях, когда ответ не приходил в течение одной недели, мы отправляли респонденту однократное письмо-напоминание об участии в опросе. Далее в этом разделе мы обобщаем замечания и размышления респондентов. Опросы I1, I2, I4, I6 и I7 будут рассмотрены подробно. Поскольку полученная от этих респондентов информация оказалась исчерпывающей, результаты остальных опросов будут лишь обобщены в кратких выводах.
Таблица 7 — Результаты опросов разработчиков и анализа размеров коммитов отобранных репозиториев на 6.10.2016
Один из респондентов ответил, что он не заинтересован в участии в опросе. Еще один опрос пришлось прервать, поскольку респондент сообщил, что не помнит подробностей, так как коммит был сделан очень давно. В случае с коммитом 7b37fbb респондент I1 сообщил, что он лишь проводил его рефакторинг и не является автором (по этой причине в табл. 7 говорится о шести авторах), но дал нам контакты настоящего автора, и мы переадресовали письмо ему (6b7fcb4).
Респонденту I1 было предложено прокомментировать следующий микроклон:
Пример 14
Анонимный респондент I1
Он сообщил нам, что данная ошибка не связана с копированием-вставкой, а произошла потому, что он написал имя переменной !has_mic вместо !has_audio. По его наблюдениям, такое случается часто, когда приходится набирать одинаковые слова много раз. Он сообщил, что «не испытывал какого-либо сильного стресса во время написания кода», но отметил, что на практике «подобные огрехи гораздо чаще остаются незамеченными в тех случаях, когда приходится делать особо крупные правки». Респондент также добавил, что настоящей ошибкой считает отсутствие юнит-теста для данной строки и тот факт, что человек, проводивший обзор кода, не заметил странности выражения вида !a && !a.
Респондент I4 ответил, что не помнит конкретно тот код, который мы попросили его прокомментировать, но может предположить, каким образом он был создан:
Пример 15
Анонимный респондент I4
Создавая подобные микроклоны, этот респондент обычно пишет оригинал field.type == trans(«string») ||, а затем копирует и вставляет его несколько раз, что в итоге приводит к коду вида:
Пример 16
Анонимный респондент I4
Он сообщил, что «не подсчитывает точное количество повторений, а прикидывает на глаз». На последнем этапе правок респондент удаляет все лишние строки, но в данном случае он, видимо, забыл это сделать или отвлекся на что-то. Определяя исходную строку в этом коде (см. раздел 3.3), мы также обнаружили, что он два раза подвергался рефакторингу, однако ошибка так и не была исправлена. Это случилось потому, что разработчики полагались на автоматические правки и не вычитывали код с должной тщательностью. В заключение I4 сообщил, что часто пользуется этими приемами для создания микроклонов, «но редко забывает удалять лишние строки». Как и респондент I1, он заключил, что такие места должны выявляться обзором кода или тестами.
Респондент I6 ответил, что «с момента написания прошло много времени, но [...] этот код похож на ошибку копирования и вставки, что не является редкостью». Он также сообщил, что «то и дело сталкивается с этим приемом и сам пользуется им». Чтобы ускорить процесс разработки и лишний раз не писать код вручную, I6 создает микроклоны с помощью копирования-вставки, а затем вносит соответствующие правки в каждую из скопированных строк. «Последнюю строку я пропустил». Респондент объяснил, что забыл изменить последний дубликат в микроклоне потому, что «стал думать о менее автоматических задачах, и в результате качество выполнения именно автоматической задачи и пострадало». Хотя респондент I6 не смог вспомнить обстоятельства того дня, он утверждает, что в их компании разработчики «всегда стараются писать код быстро, чтобы сразу проявлялись улучшения программы». Он также сообщил, что сталкивается с микроклонами «постоянно», по меньшей мере с десяток раз за день. «Из этих десяти случаев примерно девять вылавливаются в процессе самостоятельного обзора кода или с помощью компилятора. Десятый же в основном обнаруживается другими программистами или юнит-тестами. Но иногда, примерно раз в месяц [...], ошибки такого рода проникают в релизные версии и проявляются у конечных пользователей».
Респонденту I7 принадлежит авторство следующего микроклона:
Пример 17
Анонимный респондент I7
По его воспоминаниям, он «просто набрал эту строку, не пользуясь копированием и вставкой», а ошибку пропустил потому, что, «видимо, торопился и невнимательно вычитывал код». Хотя респондент не смог вспомнить точную дату создания этого коммита, он отметил, что «работы почти всегда много».
Из результатов опросов можно сделать вывод, что размер коммитов является одним из факторов, из-за которого дефектный микроклон имеет больше шансов избежать обнаружения разнообразными средствами и механизмами защиты, упомянутыми респондентами. Если это предположение верно, то коммиты, несущие в себе такие микроклоны, должны быть аномально большими. Определение «аномально большой» указывает на относительную величину и имеет смысл только при сравнении коммитов в пределах репозитория. Учитывая это, мы сравнили размеры коммитов, имеющих дефектные микроклоны, с медианой размера коммита для каждого проекта, что отражено на рис. 3. Полученные данные показывают, что во всех случаях размеры коммитов с дефектными микроклонами на несколько порядков превышают медиану.
Рис. 3 — Медиана размера коммита для всей истории репозитория (голубая штриховая линия) и размер (выраженный величиной изменчивости в логарифмическом масштабе) коммитов с дефектными микроклонами (оранжевая пунктирная линия)
Обнаружив множество потенциальных ошибок в открытых проектах, мы захотели помочь сообществу разработчиков открытого ПО и проверить, считают ли авторы найденные нами ошибки достаточно значимыми, чтобы исправить их. Для этого мы выложили свои замечания в баг-трекеры проектов. В результате многие из наших сообщений были учтены и привели к повышению качества кода проектов. Так, была исправлена ошибка проверки в примере 2 (проект Chromium). Поисковый запрос pvs-studio bug | issue выдает сообщения о многочисленных правках в проектах Firefox, libxml, MySQL, Clang, samba и многих других, чему способствовали результаты нашего исследования. В качестве примера можно привести случай, когда 11 октября 2016 года в коммите caff670 нами был исправлен дефектный микроклон, существовавший в коде samba с 2005 года.
В этом разделе мы объединим собранные нами сведения о паттернах ошибок и данные о психологических механизмах, лежащих в их основе. В заключение мы рассмотрим возможные факторы, угрожающие валидности наших выводов.
В качестве возможной технической причины эффекта последней строки можно было бы заподозрить более высокую техническую сложность последней строки по сравнению с остальными строками и, как следствие, большую предрасположенность к ошибкам. Например, компилятор может пропускать последнюю строку при проверке или не успевать вовремя проверить ее, когда код пишется в окне интегрированной среды разработки (IDE) и последняя строка микроклона является также и последней строкой в текущем окне редактора кода. Однако эти соображения неверны по следующим причинам:
С другой стороны, включение в IDE и компиляторы диагностик для обнаружения микроклонов могло бы облегчить нахождение ошибок до того, как они попадут в коммит.
Другая техническая причина могла бы быть связана с тем, что в последовательности из нескольких инструкций последнюю из них сложнее сформулировать, чем остальные. Однако, как показывают примеры 1, 2, 5, 7 и 11, верно обратное: поскольку все дубликаты построены по одному шаблону, наибольшую сложность может представлять только самый первый из них, т.е. оригинал, тогда как все последующие являются лишь его копиями.
Поскольку сомнительно, что существование эффекта последней строки объясняется техническими причинами, следует рассмотреть психологические механизмы, которые могут лежать в его основе. За консультацией мы обратились к профессору когнитивной психологии (четвертый автор данной статьи) и представили ему свои наблюдения. На данном этапе наши выводы носят предварительный характер, так как более тщательное исследование потребовало бы проведения психологического эксперимента, где мы могли бы непосредственно наблюдать процесс совершения ошибок, который невозможно реконструировать по результатам анализа происхождения дефектных дубликатов (см. раздел 3.3) и воспоминаниям респондентов (см. раздел 4.5).
В когнитивной психологии ошибки последовательности действия — это такие ошибки, которые возникают при выполнении рутинных операций. Этот тип ошибок активно изучался специалистами (Anderson 1990). Типичный пример такой ошибки — ситуация, когда вы дважды добавляете молоко в кофе, вместо того чтобы один раз влить молока и затем положить сахар. Как показывают результаты анализа происхождения микроклонов, разработчики пользуются целым арсеналом разнообразных механических приемов и алгоритмов при копировании кода. Один из этих алгоритмов: "[написать оригинальный фрагмент], [скопировать оригинал], [скопировать оригинал], ..., [редактировать копию], [редактировать копию], ..." (см. опросы I4, I6). Наравне с ним применяется алгоритм: "[написать оригинальный фрагмент], [скопировать оригинал, редактировать копию], [скопировать оригинал, редактировать копию], ..." В некоторых предельных случаях в нашем наборе данных этот алгоритм, похоже, повторялся до 34 раз. Несмотря на то что при написании микроклонов используются разные методы, все они сводятся к последовательности действий с разным соотношением автоматических и сознательных операций. Таким образом, с точки зрения когнитивной психологии, ошибки, допускаемые разработчиками в микроклонах, являются типичными ошибками последовательности действий.
Несмотря на различия в частностях, все модели контроля последовательности действий согласны в том, что главной причиной ошибок такого рода, по-видимому, является когнитивный шум (Botvinick and Plaut 2004; Cooper and Shallice 2006; Trafton et al. 2011). Под шумом в данном случае подразумеваются любые не связанные с текущей задачей и отвлекающие на себя внимание программиста представления. Шум может порождаться стрессом, вызванным внешними причинами, например, ограничениями по срокам выполнения задачи, или внутренними, например, большими размерами коммитов. Модели контроля последовательности действий предоставляют полезную теоретическую базу, которая позволяет строить предположения о возможных психологических механизмах, лежащих в основе эффекта последней строки. На данном этапе мы располагаем только конкретными примерами микроклонов и сведениями об их расположении в коде, но не знаем подробностей их возникновения. Тем не менее, как показано в разделе 4.4, ответы опрошенных разработчиков и результаты анализа происхождения микроклонов позволяют нам сделать обоснованные выводы о том, как именно они появляются. Копирование и редактирование — это основные операции, выполняемые программистом при написании кода. Обратимся еще раз к примеру 1. Операция редактирования здесь состоит из двух более мелких шагов: правки имени переменной и правки значения.
Пример 1
TrinityCore
Ошибка находится в строке 3. По всей видимости, эта строка была создана копированием строки 2. Первая замена была выполнена успешно (имя переменной изменили с y на z), но второй шаг — правка значения — был пропущен, что привело к ошибке. Теоретически этот код мог быть создан с помощью двойного копирования строки 1 и последующей правки полученных дубликатов. Однако имя переменной y вместо x в строке 3 дает нам основание полагать, что скопирована была именно вторая строка. Как показано в разделе 4.4, в большинстве микроклонов длиной более двух строк копируется обычно предшествующая строка. Отсюда следует, что в таких случаях применялся алгоритм: "[копирование, правка, правка], [копирование, правка, правка], ..."
Согласно моделям контроля последовательности действий, ошибки этого типа происходят из-за когнитивного шума, который с наибольшей вероятностью возникает ближе к концу ряда однотипных операций, поскольку внимание программиста преждевременно переключается на следующую задачу, например, написание нового кода (см. опрос I6). Как уже было сказано, существует несколько незначительно отличающихся друг от друга версий, объясняющих причины возникновения когнитивного шума. В качестве примера приведем версию (Cooper and Shallice 2006), объясняющую эффект последней строки выбором неправильного плана действий (например, разработчик уже мысленно перешел к следующим строкам, вместо того чтобы сосредоточиться на завершении текущего фрагмента).
Хотя никто из опрошенных программистов не жаловался на чрезмерно высокий уровень стресса во время написания микроклонов, свидетельства респондентов I6 и I7 отличаются от остальных: они отметили высокую рабочую нагрузку в целом и желание быстрее продвигаться в написании кода. Анализ местного времени создания коммитов с дефектными микроклонами по табл. 7 показывает, что только два из них были созданы в обязательные рабочие часы, тогда как остальные программисты работали над кодом в неурочное время, хотя и делали это по долгу службы. Как известно, усталость снижает эффективность работы мозга и негативно влияет на кратковременную память (Kane et al. 2007). Возможно, именно усталость и спешка играют существенную роль в появлении дефектных микроклонов.
Кроме того, мы обнаружили, что все коммиты (в том числе и рефакторинг) с дефектными микроклонами отличаются исключительно большими размерами, на порядки превышающими стандартные размеры коммитов в своих репозиториях. Это наталкивает нас на мысль о том, что размер коммита является важным, если не ключевым фактором, провоцирующим когнитивный шум, из-за которого ошибки остаются незамеченными. Данный вывод хорошо согласуется с версией о перегрузке кратковременной памяти, а также с замечанием респондента I1 о том, что итоговый код очень сложно контролировать из-за большого объема.
Из результатов опросов следует, что короткоживущие дефектные микроклоны — широко распространенное явление в сфере разработки ПО, но они обычно выявляются на ранних этапах или, по крайней мере, в процессе обзора кода — проведенного самостоятельно или с помощью коллег (Beller и др. 2014). Таким образом, когнитивная ошибка, наблюдаемая в оставшихся, неисправленных, микроклонах, является не только ошибкой программирования, но и ошибкой рецензирования (Healy 1980) и состоит в том, что во время обзора кода разработчик не замечает дефект в последней и остальных строках. Фактически наши опросы показывают, что, по всей видимости, в микроклонах, оказавшихся в коммитах, такая ошибка допускалась дважды: один раз при обзоре кода его автором и как минимум еще раз — при вычитке коллегой. Появление ошибки в последней строке с большей вероятностью, чем в предыдущих, вероятно, связано, помимо прочего, с тем, что она является ошибкой последовательности действий. Человек мысленно переключается на следующую задачу (например, написание следующей части кода), не успев закончить текущую (обзор). Еще одно объяснение предполагает, что ошибка менее заметна из-за следующих подряд однотипных инструкций: последнюю из них рецензент прочитывает быстрее и потому менее внимательно. Более того, визуальное подобие оригинального экземпляра и копии может затруднять восприятие отдельных строк. Исследование проблем обзора кода показывает, что похожесть фрагментов (проявляющаяся в частоте повторения слов) приводит к тому, что рецензент тратит меньше времени на вычитку, а это негативно сказывается на его способности распознавать ошибки в тексте (Moravcsik and Healy 1995).
Все потенциальные факторы проявления эффекта последней строки связаны с повышенной вероятностью допущения ошибок такого рода в ситуациях, когда объем внимания программиста сокращается из-за когнитивного шума. Вероятные причины его возникновения, прежде всего, могут быть связаны с большими размерами коммитов, большой нагрузкой, стрессом, отвлекающими факторами и усталостью (O'Malley and Gallas 1977). И наоборот, наши наблюдения показывают, что способность разработчиков контролировать свою реакцию на посторонний шум (Fukuda и Vogel 2009), т.е. способность сосредотачиваться на задаче, в значительной степени влияет на вероятность появления микроклона с ошибкой последовательности действий.
В этом разделе мы рассмотрим внутренние и внешние угрозы валидности полученных нами результатов, а также покажем, каким образом мы свели их влияние к минимуму.
Один из основных внутренних факторов связан с тем, чтобы правильно определить, в какой строке находится ошибка. Так, в примере 2 любую из двух инструкций можно принять за копию. Однако чтение и написание кода обычно происходит сверху вниз и слева направо (Siegmund и др. 2014). Поэтому естественным и единственно правильным будет считать, что расположение ошибок в строках и инструкциях подчиняется этому же порядку: в примере 2 мы можем понять, что вторая инструкция является копией первой, только прочитав ее, поэтому мы помечаем вторую инструкцию как дефектную. Далее, во многих случаях, как и в этом примере, ближайший контекст микроклона (в примере 2 переменная host объявляется первой, а уже затем объявляется port_str) задает естественный порядок и для остального текста программы (сначала проверить host, затем — port_str в строке 3). Чтобы свести к минимуму потенциальное влияние предвзятости исследователей, полученные данные были распределены для независимой обработки между первыми двумя авторами, а спорные случаи обсуждались совместно. Если по какому-либо результату прийти к согласию не удавалось, он отбрасывался. В ходе работы мы также заново классифицировали все 202 результата более раннего исследования (Beller и др. 2015) и выяснили, что они почти полностью согласуются с предыдущими выводами. Поскольку процедура разметки дефектных строк в данных обстоятельствах подробно регламентирована, мы уверены в высокой степени взаимного соответствия оценок каждого из экспертов, что гарантирует воспроизводимость нашего исследования.
Возможно, что наши диагностики не обнаруживают все дефектные микроклоны. Этот фактор представляет лишь незначительную угрозу, так как мы не претендуем на обнаружение всех ошибок этого вида. Мы считаем, что смогли найти большую часть микроклонов, расширив количество диагностик до 12 (см. табл. 1). Подтверждением этому служит тот факт, что большинство ошибок были найдены всего несколькими ключевыми диагностиками: V501, V517, V519 и V537; а также то, что ван Тондер и Ле Гу нашли более 24 000 ошибочных микроклонов с помощью сокращенного набора наших диагностик (van Tonder and Le Goues 2016).
Несмотря на нашу уверенность в правильности определения оригинальных экземпляров и копий, мы не знаем, каким образом копии создавались и редактировались разработчиками. Эмпирический анализ репозитория опирается на порядок чтения блоков кода сверху вниз, а отдельных строк — слева направо. Нам известно, что разработчики «перескакивают» между разными участками кода в процессе его чтения и уделяют особое внимание только тем блокам, которые представляются актуальными для решения текущей задачи (Busjahn и др. 2015; Siegmund и др. 2014). Вместе с тем, понять небольшие логически связанные фрагменты, которыми являются микроклоны, можно только читая код в направлении движения потока управления, т.е. сверху вниз и слева направо. В частности, нас интересуют ответы на следующие вопросы: 1) Сколько раз была использована последовательность горячих клавиш «ctrl+c, ctrl+v»? 2) В каком именно порядке создаются микроклоны? 3) В каком порядке программисты читают и правят микроклоны в процессе поддержки кода? Чтобы ответить на эти вопросы, нам пришлось бы провести исследование, в котором мы могли бы наблюдать за работой программистов «в полевых условиях», подобно тому, как это делает плагин WatchDog (Beller и др. 2015, 2015, 2016). Для этой цели мы могли бы использовать отдельные компоненты инструмента CloneBoard, который регистрирует все операции по вырезке, копированию и вставке в Eclipse (de Wit и др. 2009).
С учетом этих ограничений наши выводы о психологической основе эффекта последней строки на данном этапе могут быть спорными. Более тщательный анализ требует проведения психологического эксперимента, в котором процесс создания ошибок можно было бы изучить в естественных условиях. В силу особенностей выбранных нами методов исследования есть риск, что мы упустили какие-то специфические этапы в создании микроклонов. Тем не менее, мы полагаем, что воспроизведение ситуации, в которой возможно появление дефектных микроклонов, в лабораторных условиях крайне проблематично, так как наши респонденты отмечали, что для создания относительно небольшого числа таких фрагментов требуется продолжительное время. Более того, искусственная природа подобного эксперимента, возможные ограничения по времени и достоверно установленная склонность испытуемых прилагать больше усилий в условиях эксперимента, чем в реальной жизни (Adair 1984), существует риск, что они не допустят ошибок в микроклонах вовсе. Поскольку результаты исследования, полученные целым рядом различных методов, согласуются друг с другом, мы считаем, что сумели с достаточной достоверностью установить причины существования дефектных микроклонов вообще и эффекта последней строки в частности.
К внешним угрозам валидности можно отнести тот факт, что инструмент PVS-Studio разработан специально для языков C и C++. C — один из наиболее широко используемых языков (Meyerovich and Rabkin 2013), поэтому даже если наши результаты нельзя применить к другим языкам, они, по крайней мере, принесут пользу крупным сообществам C и C++ программистов. С другой стороны, наше исследование касается конструкций, свойственных большинству языков программирования: присваиваний, if-операторов, Булевых выражений и массивов (см. примеры 1, 2, 5, 7 и 11). По этой причине мы ожидаем аналогичных результатов по крайней мере для тех языков, в основе которых лежит язык C: Java, JavaScript, C#, PHP, Ruby и Python. Несмотря на значительный объем базы найденных ошибок, в среднем в проекте содержится ?1,2 микроклонов, что весьма немного (см. табл. 2). Этот показатель можно было бы объяснить тем, что диагностики PVS-Studio, выявляющие дефектные микроклоны, находят не все ошибки, а также тем, что изученные нами проекты представляют собой стабильные, развивающиеся системы со зрелой базой исходного кода и отличаются сравнительно малым числом тривиальных ошибок. Однако опрошенные нами разработчики дали другое объяснение: интенсивное применение тестов и обзоры кода значительно сокращают количество дефектных микроклонов, успевающих дойти до релиза.
Дублированные или однотипные фрагменты кода широко известны под названием «клонов кода», однако за последние десять лет не было дано их четкого определения (Roy и др. 2014). Эта неопределенность отражена в таких дефинициях как: «клоны кода — это сегменты кода, сходство между которыми определяется по какому-либо критерию сходства» (Baxter и др. (1998)) и «клоны кода — [...] это фрагменты достаточной длины, отличающиеся незначительным сходством» (Basit and Jarzabek (2007)). Второе определение идентифицирует клоны как фрагменты кода достаточной длины, имеющие достаточно много общих черт, тогда как в первом определении размер клонов не учитывается. Широко используется определение, в котором клоны классифицируются по трем типам (Koschke 2007). Клоны 1 типа абсолютно идентичны, а клоны 2 типа совпадают по синтаксической структуре (но отличаются идентификаторами). Клоны 3 типа еще сильнее отличаются синтаксической структурой, а клоны 4 типа идентичны только с функциональной точки зрения (Roy и др. 2014). Вместе с тем, в этой классификации также не учитывается критерий длины. Со временем исследователи предложили целый ряд более специальных определений (Koschke 2007; Balazinska и др. 1999; Kapser and Godfrey 2003). В рамках данного исследования мы вводим собственную категорию клонов кода: короткие, но тесно связанные между собой клоны, чей размер меньше нижней границы «достаточной длины», при этом в пределах одного клона зачастую содержится не более двух дублированных инструкций. Такие клоны крайне малого размера мы называем микроклонами.
Далее мы сравним традиционные средства обнаружения клонов кода с нашими методами. В своем исследовании от 2007 года Беллон и другие авторы сравнивали и оценивали инструменты обнаружения клонов. Всего было изучено шесть инструментов для языков C и Java (Bellon и др. 2007). В зависимости от конкретного инструмента минимальная длина клонов должна была составлять шесть строк или 25 токенов. В 2014 году Свайленко и Рой провели похожее исследование, в котором они сравнили одиннадцать современных инструментов по способности распознавать паттерны клонов (Svajlenko and Roy 2014). Для этой работы отбирались клоны с минимальной длиной 50 токенов, 15 инструкций или 15 строк (Svajlenko and Roy 2014). Указанные пороговые значения слишком велики для обнаружения микроклонов. Впрочем, традиционным инструментам такие значения необходимы для того, чтобы отсеять многочисленные ложные срабатывания. Наш подход позволяет обойти эту проблему за счет обнаружения только дефектных микроклонов.
Сразу после нашего исследования (Beller и др. 2015) ван Тондер и Ле Гу осуществили крупномасштабный поиск микроклонов в 380 125 репозиториях проектов на языке Java (van Tonder and Le Goues 2016) и обнаружили 24 304 дефектных микроклона, тем самым подтвердив наше предположение, что микроклоны широко распространены в программах. Исследователи представили разработчикам 43 патча для исправления найденных ошибок, и все они были оперативно применены. Этот факт показывает, что разработчики считают важным устранять такие ошибки и что этот процесс может быть в значительной степени автоматизирован.
Эмпирические данные исследований с помощью традиционных детекторов клонов говорят о том, что их содержание в кодовой базе, как правило, составляет примерно от 9% до 17% (Zibran и др. 2011), учитывая клоны типов 1, 2 и 3 (Koschke 2007). Статистические выбросы так называемого «покрытия клонов» находятся на уровне ниже 5% (Roy and Cordy 2007) и выше 50% (Rieger и др. 2004; Roy и др. 2014). Эти данные не учитывают микроклоны, которые, как мы показали, часто являются источником ошибок во многих рассмотренных в нашей работе открытых проектах. Если при проверке кода учесть это влияние, общее количество обнаруживаемых клонов может значительно вырасти — по крайней мере, с точки зрения критерия «покрытия микроклонов». Считается, что высокий уровень покрытия клонов труднодостижим, поскольку многочисленные исследования показывают, что он положительно коррелирует с ошибками и противоречиями в коде. (Chatterji и др. 2011; Gode and Koschke 2011; Inoue и др. 2012; Xie и др. 2013).
В этом разделе мы опишем возможные направления для дальнейших исследований, а также озвучим выводы по проделанной работе.
Поскольку наше исследование посвящено именно дефектным микроклонам, мы не можем предсказать, каков процент содержания ошибок среди вообще всех микроклонов. Перспективным направлением дальнейшей работы представляется создание инструмента, который мог бы надежно выявлять все микроклоны, а затем распознавать среди них именно дефектные. Эта задача дает представление о масштабе стоящей перед нами проблемы. Как можно заключить из свидетельств респондентов, микроклоны создаются с заметной частотой, и поиск ошибок в них с помощью обзора и тестирования кода отнимает драгоценное время. Для раннего обнаружения микроклонов можно рекомендовать включить наши диагностики в IDE: реализация этого решения также имеет хорошие перспективы.
На основе нашего предварительного анализа психологических причин эффекта последней строки можно было бы осуществить более масштабный контролируемый эксперимент, в котором, однако, может присутствовать высокий, по нашему мнению, риск не получить достаточного количества дефектных микроклонов. Уже имеющийся инструментарий может упростить техническую сторону такого эксперимента.
Изучив 219 открытых проектов, мы обнаружили в них 263 микроклона с дефектами. Полученные данные показывают, что ошибки с высокой вероятностью появляются в последних строках и с еще большей вероятностью — в последней инструкции. Этот эффект мы и назвали эффектом последней строки. Фактически вероятность ошибки в последней строке микроклона в три раза выше, чем во всех предыдущих строках вместе взятых, а вероятность ошибки в последней инструкции — в девять раз выше, чем во всех предыдущих инструкциях вместе взятых.
Психологические причины этого явления, по всей видимости, связаны с ошибками последовательности действий, когда разработчики оказываются неспособны корректно выполнить последовательность простых повторяющихся операций из-за перегрузки кратковременной памяти, вызванной когнитивным шумом. Мы получили свидетельства того, что эффект последней строки во многом определяется используемыми разработчиками приемами копирования-вставки кода. Похоже, что в процессе написания кода программисты склонны преждевременно считать задачу по редактированию копированных фрагментов завершенной, из-за чего они пропускают последнюю операцию. Среди ключевых причин возникновения когнитивного шума можно, по-видимому, назвать аномально большие размеры коммитов, а также воздействие усталости и стресса.
Принимая во внимание все вышесказанное, мы советуем программистам быть особенно внимательными при чтении, исправлении, написании и обзоре последних строк и инструкций в микроклонах, особенно если они были написаны методом копирования и вставки. Более того, результаты нашего исследования показывают, что дефектные микроклоны присутствовали только в аномально больших коммитах, что говорит о необходимости сократить размеры загружаемых коммитов, чтобы облегчить их вычитку. Это знание может помочь разработчикам допускать меньше ошибок в клонированных фрагментах как при написании, так и при обзоре кода; распознавать ситуации, в которых они с большей вероятностью склонны допустить ошибку из-за перегрузки кратковременной памяти, и принять меры, чтобы избежать этого. С помощью PVS-Studio мы создаём автоматизированный инструмент, который поможет разработчикам находить проникшие в коммит ошибки до релиза, например, на этапе обзора кода.
Мы выражаем благодарность Диомидису Спинеллису за вдохновляющую беседу во время встречи на Международной конференции по разработке программного обеспечения ICSE'15 на «Mercato Centrale», а также Маурисио Анишу, Йозефу Хейдерупу и Можан Сольтани за рецензирование этой статьи.
Коллектив авторов, 2016
Открытый доступ
На данную статью распространяется действие лицензии Creative Commons Attribution 4.0 International, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии, что лицензиат указывает авторство и место размещения оригинального текста, а также предоставляет ссылку на лицензию Creative Commons и обозначает изменения, если таковые были сделаны.
1) им будет легче распознавать ситуации, в которых особенно велика вероятность допустить ошибку в микроклонах;
2) они смогут использовать автоматический детектор микроклонов / PVS-Studio, что упростит обнаружение ошибок этого типа.
Ключевые слова
Микроклоны, клоны кода, обнаружение клонов кода, эффект последней строки, психология, междисциплинарное исследование.
1 Введение
Разработчикам программ часто приходится дублировать одну строку кода несколько раз подряд с небольшими изменениями, как в следующем примере из проекта TrinityCore:
Пример 1
TrinityCore

Пространственные координаты объекта other прибавляются к полям, соответствующим координатам x, y, z, но в последней строке этого фрагмента из трех однотипных строк содержится ошибка: y-координата прибавляется к z-координате. На самом деле последняя строка должна выглядеть так:

Следующий пример взят из популярного веб-браузера Chromium и демонстрирует проявление рассматриваемого эффекта в однотипных инструкциях в пределах одной строки:
Пример 2
Chromium
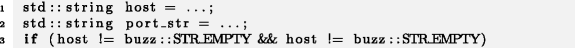
Вместо двойной проверки хоста (host) на равенство пустой строке вторая проверка должна выполняться для port_str:
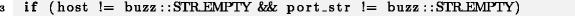
Строки 1-3 из примера 1 похожи между собой, так же как и условия if-оператора в строке 3 примера 2. Такие исключительно короткие блоки кода, состоящие из почти идентичных повторяющихся строк или инструкций, мы будем называть микроклонами. Наш собственный опыт в разработке и консультировании по вопросам качества ПО подсказывал нам на интуитивном уровне, что последняя строка или инструкция в микроклоне с гораздо большей вероятностью содержит ошибку, чем предыдущие строки или инструкции. Цель этой работы состоит в проверке истинности нашего ощущения, и именно этой целью обусловлены два вопроса, поставленные в рамках настоящего исследования:
- RQ 1 Верно ли, что последняя строка в микроклоне из нескольких строк с большей вероятностью будет содержать ошибку?
- RQ 2 Верно ли, что последняя инструкция в микроклоне длиной в одну строку с большей вероятностью будет содержать ошибку?
Поскольку копирование блоков кода при написании программ применяется в большинстве языков программирования, эффекту последней строки может быть подвержен практически каждый разработчик. Если нам удастся доказать, что последняя из нескольких идущих подряд однотипных инструкций больше подвержена ошибке, авторы и инспекторы кода будут знать, каким участкам следует уделять особое внимание, что поможет повысить качество программы за счет сокращения количества ошибок.
Копирование и вставка — один из естественных способов создания кода, подобного примерам 1 и 2. Проведя работу по определению происхождения кода среди дубликатов в отобранных нами примерах, мы пришли к выводу, что разработчики пользуются целым рядом механических приемов их создания, из которых самыми важными являются построчное копирование-вставка и «клонирование» участков кода. Эти методы — одни из самых распространенных идиом программирования (Kim и др. 2004), они требуют минимальных физических и временных затрат, а потому дешевы; кроме того, известно, что такой код работоспособен. Хотя копирование малых участков кода часто рассматривается как вредный прием (Kapser and Godfrey 2008), иногда это единственный способ, позволяющий реализовать желаемое поведение программы, как в рассмотренных выше примерах. Было разработано несколько инструментов для обнаружения и, по возможности, устранения микроклонов (Bellon и др. 2007; Roy и др. 2009). Несмотря на то что эти инструменты продемонстрировали впечатляющие результаты вплоть до уровня методов, они плохо приспособлены для распознавания микроклонов на практике из-за слишком большого количества ложных срабатываний.
После того как мы опубликовали статью об эффекте последней строки в научно-популярном блоге, ее быстро и с большим энтузиазмом стали цитировать на других форумах. Многие программисты соглашались с нашими наблюдениями и высказывали предположение, что за обсуждаемым эффектом стоят психологические причины. Отсюда проистекает наш третий, и последний, вопрос в рамках настоящего исследования:
- RQ 3 Каковы причины существования дефектных микроклонов вообще и эффекта последней строки в частности?
Опираясь на результаты опросов разработчиков, тщательного технического анализа примеров и сотрудничества с психологом, мы попытаемся выяснить, влияют ли психологические аспекты — и если да, то какие — на проявление эффекта последней строки. Изучив явления, давно наблюдаемые когнитивной психологией, мы выясним, можно ли с их помощью объяснить эффект последней строки в микроклонах кода.
Взяв за основу проведенное нами ранее исследование эффекта последней строки (Beller и др. 2015), мы внесли в него следующие дополнения:
- Ввели термин «микроклон» и дали ему определение.
- Представили используемые автоматическим инструментом статического анализа (Beller 2016) PVS-Studio диагностики для обнаружения дефектных микроклонов, которые не могут быть обнаружены традиционными способами.
- Отдельно изучили каждую ошибку во всех 263 микроклонах, отобранных из 219 популярных открытых проектов на основе 1 891 предупреждении анализатора.
- Провели предварительный анализ психологических механизмов, лежащих в основе эффекта последней строки.
- Опросили шестерых разработчиков реальных проектов, допускавших ошибки в микроклонах.
- Изучили репозитории четырех популярных открытых проектов по результатам опросов, которые указали на связь ошибок с аномально большими размерами коммитов.
Наши наблюдения показывают, что последняя строка или инструкция в микроклонах, подобных тем, что представлены в примерах 1 и 2, с гораздо большей вероятностью содержат ошибку, чем любые из предшествующих строк или инструкций. Нам представляется, что существование этого явления обусловлено не технической сложностью микроклонов, а психологическими причинами, которые, в свою очередь, в основном сводятся к перегрузке кратковременной памяти программистов. Предварительное исследование на базе пяти проектов выявило, что все микроклоны с ошибками были написаны в аномально больших коммитах в нестандартное рабочее время. Знание этих особенностей и помощь нашего автоматизированного статического анализатора PVS-Studio могут способствовать сокращению количества тривиальных ошибок, связанных с эффектом последней строки, за счет автоматического их обнаружения.
2 План исследования
Наша работа состоит из двух частей: эмпирических исследований C1 и C2. В данном разделе мы опишем порядок проведения исследований и их объекты.
2.1 План исследования C1: распространенность и преобладание эффекта последней строки в микроклонах
В исследовании C1, состоящем из пяти легко воспроизводимых этапов, мы провели статистический анализ распространенности эффекта последней строки в микроклонах. Более того, в попытке пролить свет на процесс создания микроклонов мы проделали дополнительную работу по выявлению оригинальных участков кода и их копий.
- Провести статический анализ объектов исследования с помощью инструмента PVS-Studio со всеми включенными диагностиками. PVS-Studio — это коммерческий статический анализатор, разработанный российской компанией «ООО Системы Программной Верификации» и включающий в себя десятки диагностических правил — от обнаружения клонированных блоков кода до антипаттернов программирования, использующих специфические библиотечные функции языка C. Желающие воспроизвести наше исследование могут воспользоваться находящейся в открытом доступе бесплатной демонстрационной версией PVS-Studio.
- Изучить отчет PVS-Studio и удалить ложные срабатывания, а также сообщения, не относящиеся к микроклонам.
- Для каждого дефектного микроклона подсчитать общее количество строк кода (RQ 1) или инструкций (RQ 2) и указать, в каких строках или инструкциях появляется ошибка. Если возможно, определить оригинальный участок кода и его копию (так, в примере 6 оригиналом является строка 2, а копией — строка 3).
- Приступая к исследованию, мы по умолчанию исходим из предположения, что в дефектном микроклоне длиной n строк вероятность ошибки для каждой строки равна 1/n независимо от ее номера внутри рассматриваемого фрагмента (нулевая гипотеза H0). Например, строки 1 и 2 в блоке из 2 строк имеют одинаковую вероятность ошибки 0,5. Однако, если на этапе (3) удастся показать, что распределение ошибок по строкам существенно отличается от равномерного распределения с уровнем значимости
 , мы откажемся от нулевой гипотезы и примем, что ошибки распределены неравномерно. Для каждой длины n строк используется критерий согласия Пирсона
, мы откажемся от нулевой гипотезы и примем, что ошибки распределены неравномерно. Для каждой длины n строк используется критерий согласия Пирсона 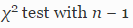 со степенью свободы n — 1 для установления соответствия между наблюдаемыми данными и нулевой гипотезой (распределение 1/n).
со степенью свободы n — 1 для установления соответствия между наблюдаемыми данными и нулевой гипотезой (распределение 1/n).
- Если на этапе (4) будет обнаружено значительное расхождение между предполагаемым и реальным распределениями, мы подсчитаем соотношение шансов между ними в качестве интуитивной меры интенсивности проявления эффекта последней строки (Bland and Altman (2000)).
2.2 План исследования C2: анализ причин эффекта последней строки
Установив существование эффекта последней строки в исследовании C1, мы должны теперь попытаться выявить обуславливающие его причины (RQ 3). Для этого мы разработали начальную гипотезу, основываясь на результатах исследований в области когнитивной психологии, в чем нам помогал профессор когнитивной психологии Рольф Цваан. Для подтверждения нашей гипотезы, а также для сбора свидетельств из практики разработчиков мы опросили программистов, ответственных за создание микроклонов, обнаруженных в ходе исследования C1. Их замечания и наблюдения помогут нам разработать предварительную версию, объясняющую существование эффекта последней строки. Сужение круга опрашиваемых исключительно до лиц, чье авторство в отношении дефектных микроклонов точно установлено, позволяет нам: (1) сосредоточиться на конкретных примерах, к которым опрашиваемые имеют непосредственное отношение; (2) получить максимально полезные ответы, поскольку мы знаем наверняка, что именно эти разработчики были ответственны за написание обсуждаемых микроклонов.
На рис. 1 показан общий план нашего исследования. Основная задача состоит в том, чтобы установить контакт с авторами микроклонов (во многих случаях дефектный код отсутствует в последней версии проекта). План включает в себя четыре основных этапа:
- Проекты и примеры микроклонов отбираются случайным образом, поскольку работа над исследованием C2 — трудоемкий процесс, подразумевающий установление контакта с авторами примеров и проведение индивидуальных опросов. Исходя из того что стандартная доля отвечающих на «холодные звонки» составляет 30%, мы можем рассчитывать на три успешных опроса, которые должны дать нам достаточно информации, чтобы сформулировать начальную гипотезу, объясняющую существование эффекта последней строки с точки зрения когнитивной психологии. При анализе каждого из микроклонов необходимо ознакомиться с принятыми в данном проекте правилами разработки и изучить репозиторий.
- Далее, мы определяем местоположение микроклона в дереве исходного кода проекта. Поскольку многие из ошибок были исправлены после публикации наших более ранних наблюдений и в текущей ветке отсутствуют, на этом этапе мы вынуждены применять различные стратегии поиска. Сначала мы изучаем репозиторий, датирующийся тем днем, когда проводилось исследование C1. В случае неудачи — например, если соседний с микроклоном код подвергся рефакторингу (или история изменений была перезаписана) — мы используем поиск по баг-трекеру проекта, чтобы найти коммит, в котором было внесено исправление. Если и этот шаг не приносит результата, мы прибегаем к полнотекстовому поиску (используя инструмент ag) по всем коммитам проекта.
- При обнаружении оригинального микроклона мы прослеживаем его историю с помощью инструмента git blame, чтобы получить сведения о внесенных исправлениях, а также установить авторство этого кода.
- Наконец, мы узнаем электронный адрес разработчика, используя команду git blame -e. Чтобы добиться более высокого процента ответивших, мы собираем дополнительные сведения о респондентах с помощью поиска в Интернете: это позволит нам определить актуальность адреса электронной почты. Чтобы добиться максимально честных ответов, мы гарантируем респондентам, что не будем раскрывать их личные данные. Затем мы посылаем каждому разработчику электронное письмо с текстом микроклона их авторства, историей его изменения/исправления, контекстом ошибки, а также объяснением причины проведения опроса и прилагаем анкету.
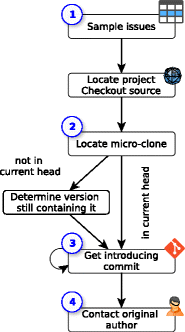
Рис. 1 — План исследования C2
2.3 Объекты исследования
Чтобы облегчить воспроизведение нашей работы другими исследователями, мы отдали предпочтение хорошо известным проектам с открытым кодом. Среди 219 проектов, изученных нами в исследовании C1, ошибочные микроклоны были обнаружены в таких знаменитых проектах как аудиоредактор Audacity (1 пример), веб-браузеры Chromium (9) и Firefox (9), XML-библиотека libxml (1), базы данных MySQL (1) и MongoDB (1), компилятор языка C clang (14), FPS-шутеры Quake III (3) и Unreal 4 (25), пакет для создания компьютерной графики Blender (4), программа для трехмерного моделирования и визуализации VTK (8), сетевые протоколы Samba (4) и OpenSSL (2), видеоредактор VirtualDub (3), а также язык программирования PHP (1). Для исследования C2 мы отобрали 10 микроклонов из проектов Chromium, libjingle, Mesa 3D и LibreOffice.
2.4 Замечания по воспроизведению исследования
Для облегчения работы других исследователей мы подготовили специальный пакет, куда вошли все исходные данные и диагностики. В него включены все неотфильтрованные сообщения PVS-Studio, сгруппированные по двум директориям: findings_old/, где содержатся старые данные, использованные в нашей статье для Международной конференции по обозримости программ (ICPC) (Beller и др. 2015), и findings_new/ с более свежими данными, использованными в настоящей статье. Кроме того, в пакет входят проанализированные нами и отсортированные по проектам микроклоны (analyzed_data.csv), электронная таблица с оценкой данных (evaluation.ods) и результаты анализа репозиториев из исследований C1 и C2. Мы также добавили скрипты на языке R для воспроизведения результатов и диаграмм из данной статьи. Наконец, в пакете содержится шаблон анкеты с вопросами для респондентов.
3 Способы обнаружения микроклонов
В данном разделе мы рассмотрим традиционные способы обнаружения дублированных фрагментов кода, объясним, почему они не подходят для поиска микроклонов, и покажем, каким образом мы смогли обойти эту проблему, используя наши собственные диагностики статического анализа. Кроме того, мы покажем, как определялись оригинальные участки и копии в микроклонах и как учитывались размеры коммитов.
3.1 Почему современные инструменты обнаружения клонов кода не подходят для нашей задачи
Как показывают примеры 1 и 2, фрагменты кода, рассматриваемые в рамках этой статьи, либо полностью совпадают по тексту, либо содержат «клоны с одинаковой синтаксической структурой, отличающиеся только идентификаторами переменных, типов или функций» (Koschke 2007). По этой причине они представляют собой клоны 1 или 2 типа чрезвычайно малого размера (как правило, меньше 5 строк/инструкций) — именно их мы и называем микроклонами.
Традиционные методы обнаружения дублированного кода заключаются в сравнении токенов, строк кода, узлов абстрактного синтаксического дерева (АСД) или графов (Koschke 2007). Однако на практике в любом из этих подходов требуется определить минимальный размер клона в условных единицах измерения (будь то токены, инструкции, строки или узлы АСД) для снижения процента ложных срабатываний. Как правило, это значение берется в районе 5-10 единиц (Bellon и др. 2007; Juergens и др. 2009), что намного превосходит размер рассматриваемых нами микроклонов (2-5 единиц) и делает невозможным их поиск.
Так, в примере 1 строки 1-3 представляют собой класс микроклонов. Поскольку строк три, то данный класс представлен в этом примере в трех экземплярах. В свою очередь, каждый экземпляр состоит из переменной, операции присваивания, присваиваемого объекта и его поля и, таким образом, имеет длину 4 единицы.
3.2 Используемые нами методы обнаружения дефектных микроклонов
Поскольку на практике традиционные методы поиска неспособны надежно обнаруживать микроклоны, мы использовали свой собственный подход. Наша задача состоит в обнаружении не любых микроклонов, а только тех, которые содержат ошибки. Учитывая это дополнительное ограничение, мы смогли разработать целый набор мощных диагностик, обнаруживающих микроклоны по признаку обычного посимвольного совпадения. Эти диагностики способны находить дефектные участки кода, которые с большой вероятностью появились в результате копирования малых фрагментов. В табл. 1 перечислены и описаны все двенадцать диагностик, которые позволили обнаружить ошибки в микроклонах в рамках этого исследования. В последнем столбце показано отношение числа одно- и многострочных клонов к общему количеству предупреждений данного типа. Например, диагностика V501 всего лишь определяет, являются ли идентичными операнды некоторых логических операторов. Если ответ положительный, то в лучшем случае это просто лишний код, который может затруднить поддержку программы в будущем, в худшем — настоящая ошибка. Другие диагностики не настолько узкоспециализированы по отношению к микроклонам, как V501. Мы изучили каждое из 526 предупреждений и отобрали для нашего исследования только 272 случая реальных микроклонов. Из табл. 1 можно также увидеть, что 78% микроклонов были обнаружены одной диагностикой (V501) с очень низким процентом ложных срабатываний — 3%. Другие диагностики с большей вероятностью могут срабатывать на участки кода, не являющиеся микроклонами.
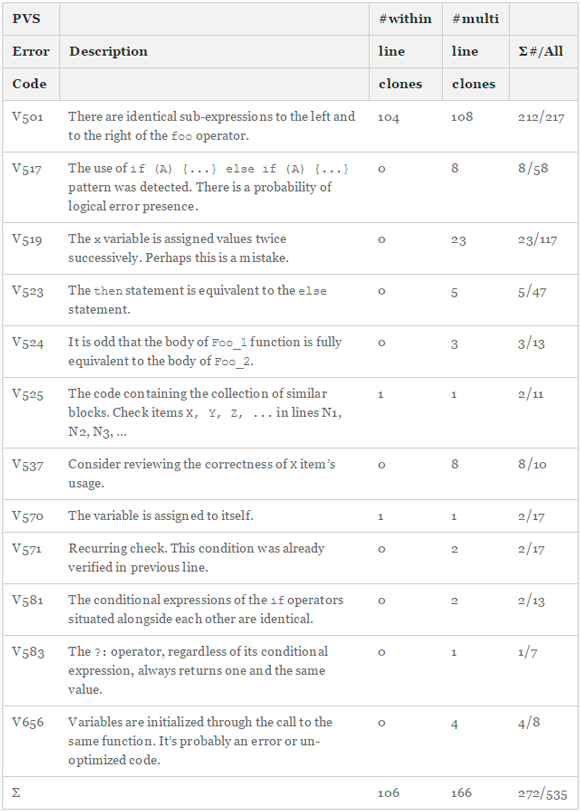
Таблица 1 — Типы ошибок, обнаруживаемых PVS-Studio, и их распределение по 219 открытым проектам
3.3 Как устанавливалось происхождение ошибочных микроклонов
Чтобы компетентно рассуждать о причинах существования эффекта последней строки, отвечая на вопрос RQ 3, мы также нашли в каждом классе микроклонов оригинальный экземпляр кода и экземпляр, который предположительно был скопирован с него. Хотя подобный эмпирический анализ не дает стопроцентную уверенность, что процедура копирования шла именно в таком направлении, у нас имеются достаточные свидетельства, что по крайней мере некоторые разработчики механически клонируют код именно таким образом (см. RQ 3). В большинстве случаев можно сразу определить, какой из двух экземпляров микроклона является оригиналом, а какой — копией. Так, в примере 1 строка 3, содержащая ошибку, включает в себя следы кода из строки 2, что подразумевает влияние строки 2 (оригинал) на строку 3 (копия). Подобный естественный порядок следования оригинальных строк и копий наблюдается в большинстве микроклонов — будь то лексикографический порядок, как, например, в последовательности переменных x, y, z в примере 1, или числовой:
Пример 3
Cmake

Даже в тех случаях, где естественный порядок расположения оригинального экземпляра и копии не выражен явно, как в примерах 1 и 3, его можно восстановить по контексту, как в примере 2: помещение port_str на первое место и host на второе в строке 3 противоречит порядку, в котором эти переменные были определены ранее, — значит, первая инструкция host != buzz::STR_EMPTY является оригиналом, а вторая — копией.
В процессе установления происхождения копии в рассматриваемых примерах мы сталкиваемся с двумя проблемами, а именно: 1) размер копируемого участка может варьировать; 2) микроклоны длиной свыше 4 дубликатов представлены меньшим числом примеров. Чтобы, тем не менее, иметь возможность обобщить данные для разных размеров микроклонов, для каждого микроклона i мы вычисляем
, что дает нам степень удаленности .Степень удаленности 1 говорит о копировании из непосредственно предшествующей строки/инструкции, как в примере 4. Значение 0: ошибка произошла в той же строке микроклона. Значение -1 указывает на обратный порядок копирования: из второй единцы — в первую:
Пример 4
UnrealEngine4

В этом примере в строке 1 естественно ожидать cx().isRelative вместо cy().isRelative, что говорит о возможном копировании из второй строки. Логика использования переменных с подобными именами, а также порядок следования строк 3 и 4 говорят о том, что копия должна начинаться с return cx().isRelative() в первой строке.
Отсюда получаем степень удаленности
или , что указывает на непосредственное соседство двух дубликатов либо в одной строке, либо на двух смежных, независимо от общего размера клонированного участка.3.4 Как учитываются размеры коммитов
Чтобы вычислить и представить отношение размеров каждого из коммитов, содержащих дефектные микроклоны, к остальным коммитам, мы вначале вычисляем изменчивость для каждого коммита в репозитории. Для этого мы используем инструмент git log, который позволяет строить упорядоченные графы всех коммитов (исключая слияния) в репозитории, выявляя, таким образом, число добавленных и число удаленных строк кода в каждом коммите. Сумма этих чисел и дает общее количество измененных строк, т.е. величину изменчивости, для каждого коммита. Затем мы сравниваем изменчивость коммитов, содержащих дефектные микроклоны, с распределением этого параметра в остальных коммитах, а в особенности — с его медианой. Хотя наша выборка (десять примеров) слишком мала для надежного статистического анализа, этот подход все же позволяет нам сделать обоснованные выводы о возможной разнице в размерах коммитов. Мы используем медиану (а не среднее, например), потому что имеем дело с неправильными распределениями; медиана — самостоятельное, реальное значение, с которым мы сравниваем другие такие же значения.
4 Результаты
В этом разделе мы более подробно исследуем дефектные микроклоны, изучив примеры и проведя статистическую оценку.
4.1 Общее описание результатов
В табл. 2 собрана основная статистика по результатам исследования C2. На протяжении периода с середины 2011 года по июль 2015 года мы применяли полный набор диагностик PVS-Studio на выбранных нами 219 открытых проектах. Андрей Карпов, который специализируется на консультации по разработке ПО, выполнял анализ всех этих проектов, используя последние версии PVS-Studio, доступные на момент проверки каждого конкретного проекта. Он отфильтровал ложные срабатывания, в результате чего осталось 1 891 предупреждение, указывающее на потенциальные дефекты в коде. Эти предупреждения были сгруппированы по 162 диагностикам. Затем мы изучили каждое сообщение и обнаружили, что 272 из них были выданы двенадцатью диагностиками и имеют отношение к микроклонам. В девяти случаях сообщения дублировались, поэтому в итоге осталось 263 микроклона. Статистический анализ на уровне проектов показывает, что наши диагностики смогли распознать клоны с дефектами в половине из отобранных проектов. Почти все эти случаи (92%) содержат по меньшей мере один пример с эффектом последней строки.

Таблица 2 — Статистика по результатам исследования
Табл. 3 содержит сводку по обнаруженным ошибкам в 263 микроклонах. В общей сложности, 74% многострочных клонов содержат ошибку в последней строке и 90% однострочных клонов — в последней инструкции.
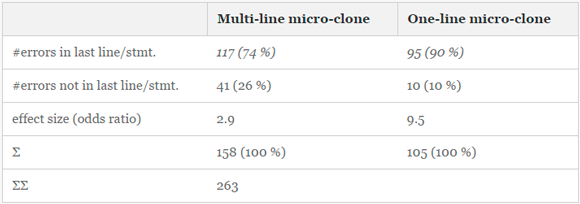
Таблица 3 — Сводка по результатам исследования
4.2 Подробный анализ результатов
Для более полного понимания принципов работы диагностик, которые мы применили для обнаружения микроклонов, ниже мы рассмотрим некоторые наиболее показательные примеры из 263 предупреждений PVS-Studio, относящихся к микроклонам и выявляющих наиболее частые ошибки из табл. 1.
4.2.1 V501 — Одинаковые подвыражения
Как видно из табл. 1, большинство предупреждений о микроклонах были выданы диагностикой V501. Ниже показан типичный пример такой ошибки из браузера Chromium:
Пример 5
Chromium

Это однострочный микроклон, в котором второе и третье подвыражения полностью совпадают, но при этом соединяются логическим оператором ИЛИ (||), что делает выражение избыточным. На самом деле, оно должно было проверять фамилию (NAME_LAST) — так в этом блоке из трех единиц проявляется эффект последней строки.
4.2.2 V517 — Одинаковые условные выражения
Диагностика V517 обнаруживает одинаковые условия для двух веток if-оператора.
Пример 6
linux-3.18.1

Тело оператора else if после третьего микроклона на строке 9 является мертвым кодом, поскольку поток исполнения никогда не достигнет его. Случай, когда значение slot равно 0, будет обработан уже в первом условии.
4.2.3 V519 — Присваивание одинаковых значений переменной
Присваивание переменной двух значений подряд обычно является либо просто избыточной операцией (и, следовательно, создает проблемы при поддержке кода, затрудняя его понимание, так как первое присваивание оказывается недействительным), либо откровенной ошибкой, так как в качестве правого операнда должно было быть другое значение. В следующем примере из проекта MTASA переменной m_ucRed дважды присваивается значение, в то время как переменной m_ucBlue присвоить значение забыли.
Пример 7
MTASA

Диагностика V519 хорошо показала себя при обнаружении дефектов в большинстве «обычных» программ, однако следует с осторожностью подходить к анализу кода прошивок и прочего низкоуровневого кода, как показано в примере 8:
Пример 8
linux-3.18.10
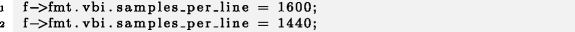
Во второй строке переменной f->fmt.vbi.samples_per_line повторно присваивается значение, несмотря на то что строчкой выше ей уже было присвоено другое значение. Поскольку дальше в потоке управления в данном методе отсутствуют вызовы других методов, может показаться, что присваивание в строке 1 не дает никакого результата. Однако, поскольку это присваивание действует на протяжении по крайней мере одного такта, за это время присвоенное значение может быть прочитано из других потоков (например, сторожевым таймером, отслеживающим состояние буфера) или использоваться каким-либо другим способом. На всякий случай мы компилируем такой код в режиме Release: если компилятор в процессе оптимизации убирает первое присваивание, значит, это действительно ошибка.
4.2.4 V523 — Одинаковое поведение в разных ветках
Микроклоны в разных ветках if-оператора обычно можно упростить, оставив только один блок, как в следующем примере из Haiku:
Пример 9
Haiku
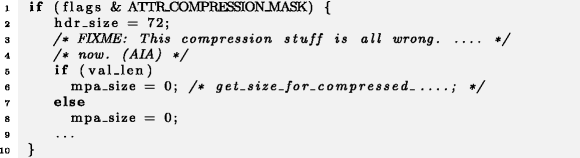
Более вероятно, однако, что в ветке else переменной mpa_size должно было быть присвоено какое-то другое значение. Контекст данного микроклона вызывает подозрения, так как в комментарии в строке 3 сказано, что «с компрессией тут все неправильно», а обнаруженный дефектный микроклон подходит под эту формулировку.
4.2.5 V524 — Одинаковые тела функций
Две дублированные функции с одним и тем же телом очень подозрительны. В примере 10 в строке 5 должен быть вызов PerPtrBottomUp.clear(). Также это один из редких примеров, когда в микроклоне из двух дубликатов копия предшествует оригиналу
.Пример 10
Clang

4.2.6 V537 — Подозрительное использование переменной или инструкции
Показательный пример диагностики V537, приведенный ниже, взят из Quake III. В этом случае PVS-Studio предупреждает о необходимости проверить использование rectf.X:
Пример 11
Quake III

Во второй (т.е. последней) строке данного клона y-координата прямоугольника ошибочно задается округленным значением rectf.X.
4.2.7 V656 — Две переменные с одинаковыми значениями
Диагностика V656 выявляет разные переменные, которые инициализируются одной и той же функцией. Однако мы вынуждены проявлять осторожность при анализе таких предупреждений, поскольку среди них потенциально может наблюдться много ложных срабатываний. В качестве подобного примера можно привести случай, когда две переменные инициализируются одним и тем же значением, но затем, ниже по коду, начинают различаться. Все микроклоны нашей выборки, относящиеся к диагностике V656, взяты из проекта LibreOffice.
Пример 12
LibreOffice

В этом случае переменной maSelection.Max() вместо максимального значения aSelection присваивается минимальное, что явно указывает на ошибку.
4.2.8 Контрпример
Как мы уже видели в примере 12, не во всех дефектных микроклонах ошибка локализуется в последней строке или инструкции. Следующий пример из Chromium — один из 12 случаев, когда ошибка проявляется во второй строке трехстрочного микроклона (см. табл. 4):
Пример 13
Chromium

В строке 2 ячейка data_[M02] вычитается сама из себя, хотя на самом деле подразумевалось следующее:
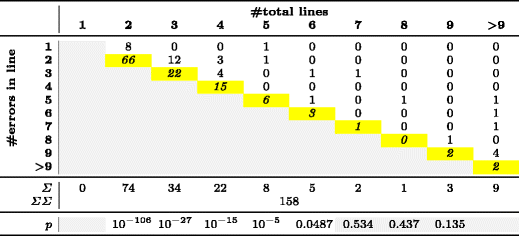
Таблица 4 — Распределение ошибок в микроклонах размером ?? 2 строк
4.3 Статистическая оценка
В табл. 4 показано распределение ошибок по строкам для 158 многострочных микроклонов, а в табл. 5 — распределение ошибок по инструкциям внутри одной строки для 105 однострочных микроклонов. Ячейки с серым фоном не содержат значащих данных. Например, в микроклоне длиной 2 строки не может быть ошибок в третьей строке. Ячейки с желтым фоном, расположенные по диагонали, соответствуют ошибкам в последних строках или инструкциях.
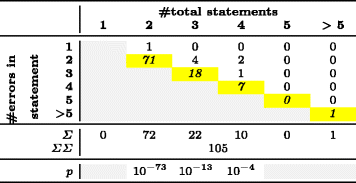
Таблица 5 — Распределение ошибок в однострочных микроклонах
Для каждого столбца табл. 4 и 5 мы применили критерий согласия Пирсона
с уровнем значимости p = 0,05, чтобы определить, являются ли индивидуальные распределения неравномерными. Получившиеся в результате p-значения, приведенные в последней строке таблицы имеют смысл только для микроклонов таких размеров, в отношении которых мы располагаем достаточным количеством эмпирических данных. Такие случаи представлены в столбцах 2-6 табл. 4 и столбцах 2-4 табл. 5.Отвечая на вопросы RQ1 и RQ2, мы получили статистически значимые p-значения для микроклонов длиной 2, 3, 4, 5 или 6 строк и для микроклонов из 2, 3 или 4 инструкций (p < 0,05). Эти результаты говорят о том, что нулевая гипотеза о равномерном распределении ошибок по строкам/инструкциям неверна и может быть отброшена. В реальности ошибки в гораздо большей степени концентрируются в последней строке или инструкции. Мы предполагаем, что в микроклонах большего размера будет наблюдаться такое же распределение, но подобных примеров в нашей выборке слишком мало, чтобы подтвердить это предположение статистически. Этим случаям соответствуют ячейки с серым фоном в последней строке табл. 4 и 5.
Распределения ошибок в микроклонах разной длины составляют две группы: «ошибка не в последней строке/инструкции» и «ошибка в последней строке/инструкции» (см. табл. 3). Подсчет абсолютных значений показывает, что в микроклонах, подобных примеру 1, вероятность ошибки в последней строке почти втрое больше, чем во всех предыдущих строках вместе взятых. Как видно из табл. 4, вероятность ошибки в последней строке в клонах длиной 2, 4 и 5 строк (самые многочисленные примеры) может достигать девятикратного значения по сравнению с остальными строками. Аналогичные показатели для дублированных инструкций в однострочных клонах, как в примере 2, еще выше: вероятность ошибки в последней инструкции в 9,5 раз выше, чем во всех остальных инструкциях вместе взятых. Фактически ошибка находилась в последней из двух инструкций во всех 72 случаях, кроме одного.
В целом, можно утверждать, что результаты нашего исследования подтверждают наличие заявленного эффекта последней строки/инструкции, что позволяет ответить утвердительно на вопросы RQ 1 и RQ 2.
4.4 Происхождение микроклонов
Обнаружив большое количество предположительно тривиальных ошибок, связанных с микроклонами, в открытых проектах, мы поставили перед собой задачу выяснить причины существования этого явления. Вопрос RQ 3 нашего исследования звучит так:
- RQ 3 Каковы причины существования ошибочных микроклонов вообще и эффекта последней строки в частности?
В этом разделе мы сначала изучим происхождение микроклонов, а затем рассмотрим технические и психологические причины появления дефектных микроклонов.
В табл. 6 показано распределение оригинальных участков кода по номерам строк в зависимости от длины микроклона. В этом исследовании мы отбросили микроклоны, для которых не удалось достоверно установить порядок следования оригинала и копии. Таким образом, из 263 пар дубликатов осталось 245.

Таблица 6 — Длина клона (по горизонтали) и номер оригинальной строки (по вертикали)
На рис. 2 показаны диаграммы распределения оригинальных экземпляров по номерам строк в микроклоне. Как видно из рисунка, в 165 случаях из 245 (67%) исходной является первая строка. Затем наблюдается резкий спад на второй позиции — 18 %, а далее частота плавно уменьшается к третьей (9%) и четвертой позициям (3%). Лишь в оставшихся 4% случаев оригинал располагается после четвертой строки или инструкции. Такое распределение, по всей видимости, указывает на то, что первая строка оказывает наибольшее влияние на весь блок. Впрочем, многие наши примеры состоят из двух строк: вполне естественно, что в большинстве таких случаев исходной оказывается первая строка. Если исключить их из расчетов и рассматривать только оставшиеся 117 микроклонов из трех и более строк/инструкций, выясняется, что оригинальный код находится в первой строке только в 33 случаях (28%). Поскольку средняя длина примеров составляет 4,9 строк, мы ожидали, что первая строка будет исходной в 20% случаев, даже при равномерном распределении ошибок. Однако полученное значение 28% говорит о том, что первая строка оказывает лишь умеренное влияние на весь клон, если не учитывать двухстрочные клоны. Тем не менее, почти во всех микроклонах из двух строк исходной является первая строка, а не вторая.
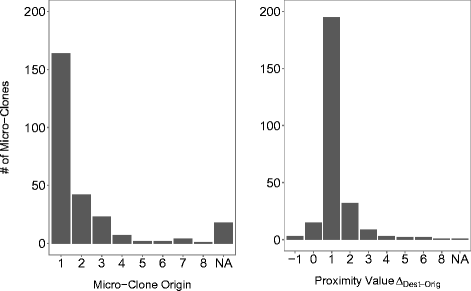
Рис. 2 — Положение оригинальных экземпляров в микроклоне (слева) и удаленность оригинала и копии в пределах микроклона (справа)
На рис. 2 также показана диаграмма, отражающая степень удаленности между оригиналом и копией
(см. раздел 3.3). Как видно, более 84% оригинальных экземпляров и копий являются непосредственными соседями (220 случаев из 245), т.е. Для 89% из них (195 из 220)
или . Это означает, что дубликат с ошибкой находится после оригинала в следующей строке или инструкции. Гораздо реже встречается обратный порядок, т.е. (3 случая из 220). Если исключить из расчетов клоны из двух строк или инструкций, в которых экземпляры естественным образом являются соседями, оказывается, что в 81% случаев дубликаты находятся непосредственно рядом друг с другом (66 из 81). Таким образом, результаты исследования можно обобщить в следующих выводах:- В микроклонах из двух строк первая строка почти всегда является исходной. Если же исключить из рассмотрения двухстрочные клоны, первая строка оказывает лишь умеренное влияние на весь блок кода.
- Напротив, в четырех из пяти случаев оригинал и копия с дефектом являются непосредственными соседями. Более того, в девяти случаях из десяти дефектная копия следует за оригиналом.
4.5 Опрос разработчиков
В рамках исследования C2 мы опросили десять разработчиков реальных приложений, которые в своей работе допускали ошибки в микроклонах. Респондентам предлагалось ознакомиться с микроклонами их авторства и дополнительной контекстуальной информацией. Опрашиваемым было предложено ответить, помнят ли они следующие подробности:
- как они пользовались механическими приемами копирования (т.е. методом копирования и вставки).
- как в код проникла обсуждаемая ошибка.
- обстоятельства создания коммита, включая местное время и дату коммита.
- на каких стадиях разработки и с какой частотой микроклоны обычно появляются на практике.
Табл. 7 содержит сводку по десяти примерам микроклонов и ответам семи респондентов, написавшим их. Опросы проводились независимо друг от друга по электронной почте и Skype. В таблице указаны названия отобранных проектов и версии коммитов, даты применения коммитов, медиана и индивидуальные размеры коммитов, выраженные через величину изменчивости, а также общее количество коммитов в проекте. В целях сохранения анонимности респондентов I1-I7 мы не указываем их ID-номера в коммитах и не раскрываем авторства представленных ниже примеров. В случаях, когда ответ не приходил в течение одной недели, мы отправляли респонденту однократное письмо-напоминание об участии в опросе. Далее в этом разделе мы обобщаем замечания и размышления респондентов. Опросы I1, I2, I4, I6 и I7 будут рассмотрены подробно. Поскольку полученная от этих респондентов информация оказалась исчерпывающей, результаты остальных опросов будут лишь обобщены в кратких выводах.
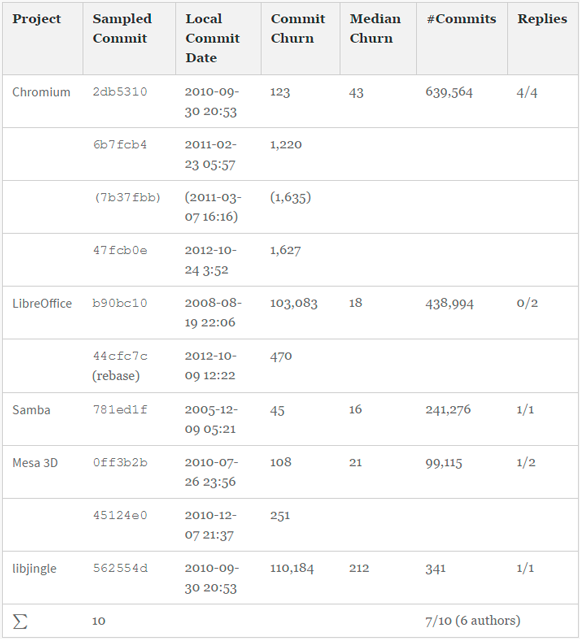
Таблица 7 — Результаты опросов разработчиков и анализа размеров коммитов отобранных репозиториев на 6.10.2016
Один из респондентов ответил, что он не заинтересован в участии в опросе. Еще один опрос пришлось прервать, поскольку респондент сообщил, что не помнит подробностей, так как коммит был сделан очень давно. В случае с коммитом 7b37fbb респондент I1 сообщил, что он лишь проводил его рефакторинг и не является автором (по этой причине в табл. 7 говорится о шести авторах), но дал нам контакты настоящего автора, и мы переадресовали письмо ему (6b7fcb4).
Респонденту I1 было предложено прокомментировать следующий микроклон:
Пример 14
Анонимный респондент I1

Он сообщил нам, что данная ошибка не связана с копированием-вставкой, а произошла потому, что он написал имя переменной !has_mic вместо !has_audio. По его наблюдениям, такое случается часто, когда приходится набирать одинаковые слова много раз. Он сообщил, что «не испытывал какого-либо сильного стресса во время написания кода», но отметил, что на практике «подобные огрехи гораздо чаще остаются незамеченными в тех случаях, когда приходится делать особо крупные правки». Респондент также добавил, что настоящей ошибкой считает отсутствие юнит-теста для данной строки и тот факт, что человек, проводивший обзор кода, не заметил странности выражения вида !a && !a.
Респондент I4 ответил, что не помнит конкретно тот код, который мы попросили его прокомментировать, но может предположить, каким образом он был создан:
Пример 15
Анонимный респондент I4

Создавая подобные микроклоны, этот респондент обычно пишет оригинал field.type == trans(«string») ||, а затем копирует и вставляет его несколько раз, что в итоге приводит к коду вида:
Пример 16
Анонимный респондент I4

Он сообщил, что «не подсчитывает точное количество повторений, а прикидывает на глаз». На последнем этапе правок респондент удаляет все лишние строки, но в данном случае он, видимо, забыл это сделать или отвлекся на что-то. Определяя исходную строку в этом коде (см. раздел 3.3), мы также обнаружили, что он два раза подвергался рефакторингу, однако ошибка так и не была исправлена. Это случилось потому, что разработчики полагались на автоматические правки и не вычитывали код с должной тщательностью. В заключение I4 сообщил, что часто пользуется этими приемами для создания микроклонов, «но редко забывает удалять лишние строки». Как и респондент I1, он заключил, что такие места должны выявляться обзором кода или тестами.
Респондент I6 ответил, что «с момента написания прошло много времени, но [...] этот код похож на ошибку копирования и вставки, что не является редкостью». Он также сообщил, что «то и дело сталкивается с этим приемом и сам пользуется им». Чтобы ускорить процесс разработки и лишний раз не писать код вручную, I6 создает микроклоны с помощью копирования-вставки, а затем вносит соответствующие правки в каждую из скопированных строк. «Последнюю строку я пропустил». Респондент объяснил, что забыл изменить последний дубликат в микроклоне потому, что «стал думать о менее автоматических задачах, и в результате качество выполнения именно автоматической задачи и пострадало». Хотя респондент I6 не смог вспомнить обстоятельства того дня, он утверждает, что в их компании разработчики «всегда стараются писать код быстро, чтобы сразу проявлялись улучшения программы». Он также сообщил, что сталкивается с микроклонами «постоянно», по меньшей мере с десяток раз за день. «Из этих десяти случаев примерно девять вылавливаются в процессе самостоятельного обзора кода или с помощью компилятора. Десятый же в основном обнаруживается другими программистами или юнит-тестами. Но иногда, примерно раз в месяц [...], ошибки такого рода проникают в релизные версии и проявляются у конечных пользователей».
Респонденту I7 принадлежит авторство следующего микроклона:
Пример 17
Анонимный респондент I7
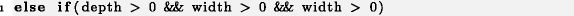
По его воспоминаниям, он «просто набрал эту строку, не пользуясь копированием и вставкой», а ошибку пропустил потому, что, «видимо, торопился и невнимательно вычитывал код». Хотя респондент не смог вспомнить точную дату создания этого коммита, он отметил, что «работы почти всегда много».
Из результатов опросов можно сделать вывод, что размер коммитов является одним из факторов, из-за которого дефектный микроклон имеет больше шансов избежать обнаружения разнообразными средствами и механизмами защиты, упомянутыми респондентами. Если это предположение верно, то коммиты, несущие в себе такие микроклоны, должны быть аномально большими. Определение «аномально большой» указывает на относительную величину и имеет смысл только при сравнении коммитов в пределах репозитория. Учитывая это, мы сравнили размеры коммитов, имеющих дефектные микроклоны, с медианой размера коммита для каждого проекта, что отражено на рис. 3. Полученные данные показывают, что во всех случаях размеры коммитов с дефектными микроклонами на несколько порядков превышают медиану.
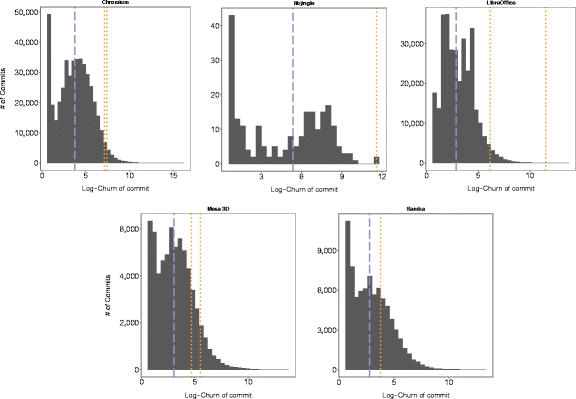
Рис. 3 — Медиана размера коммита для всей истории репозитория (голубая штриховая линия) и размер (выраженный величиной изменчивости в логарифмическом масштабе) коммитов с дефектными микроклонами (оранжевая пунктирная линия)
4.6 Полезность результатов
Обнаружив множество потенциальных ошибок в открытых проектах, мы захотели помочь сообществу разработчиков открытого ПО и проверить, считают ли авторы найденные нами ошибки достаточно значимыми, чтобы исправить их. Для этого мы выложили свои замечания в баг-трекеры проектов. В результате многие из наших сообщений были учтены и привели к повышению качества кода проектов. Так, была исправлена ошибка проверки в примере 2 (проект Chromium). Поисковый запрос pvs-studio bug | issue выдает сообщения о многочисленных правках в проектах Firefox, libxml, MySQL, Clang, samba и многих других, чему способствовали результаты нашего исследования. В качестве примера можно привести случай, когда 11 октября 2016 года в коммите caff670 нами был исправлен дефектный микроклон, существовавший в коде samba с 2005 года.
5 Анализ результатов исследования
В этом разделе мы объединим собранные нами сведения о паттернах ошибок и данные о психологических механизмах, лежащих в их основе. В заключение мы рассмотрим возможные факторы, угрожающие валидности наших выводов.
5.1 Техническая сложность и другие технические причины эффекта последней строки
В качестве возможной технической причины эффекта последней строки можно было бы заподозрить более высокую техническую сложность последней строки по сравнению с остальными строками и, как следствие, большую предрасположенность к ошибкам. Например, компилятор может пропускать последнюю строку при проверке или не успевать вовремя проверить ее, когда код пишется в окне интегрированной среды разработки (IDE) и последняя строка микроклона является также и последней строкой в текущем окне редактора кода. Однако эти соображения неверны по следующим причинам:
- Современным IDE, как правило, не свойственны задержки при проверке синтаксиса.
- Последняя строка или инструкция в микроклоне корректны с точки зрения синтаксиса, т.е. компилятор не может выдать предупреждение, которое бы привлекло внимание программиста к проблеме.
С другой стороны, включение в IDE и компиляторы диагностик для обнаружения микроклонов могло бы облегчить нахождение ошибок до того, как они попадут в коммит.
Другая техническая причина могла бы быть связана с тем, что в последовательности из нескольких инструкций последнюю из них сложнее сформулировать, чем остальные. Однако, как показывают примеры 1, 2, 5, 7 и 11, верно обратное: поскольку все дубликаты построены по одному шаблону, наибольшую сложность может представлять только самый первый из них, т.е. оригинал, тогда как все последующие являются лишь его копиями.
5.2 Психологические механизмы и причины
Поскольку сомнительно, что существование эффекта последней строки объясняется техническими причинами, следует рассмотреть психологические механизмы, которые могут лежать в его основе. За консультацией мы обратились к профессору когнитивной психологии (четвертый автор данной статьи) и представили ему свои наблюдения. На данном этапе наши выводы носят предварительный характер, так как более тщательное исследование потребовало бы проведения психологического эксперимента, где мы могли бы непосредственно наблюдать процесс совершения ошибок, который невозможно реконструировать по результатам анализа происхождения дефектных дубликатов (см. раздел 3.3) и воспоминаниям респондентов (см. раздел 4.5).
В когнитивной психологии ошибки последовательности действия — это такие ошибки, которые возникают при выполнении рутинных операций. Этот тип ошибок активно изучался специалистами (Anderson 1990). Типичный пример такой ошибки — ситуация, когда вы дважды добавляете молоко в кофе, вместо того чтобы один раз влить молока и затем положить сахар. Как показывают результаты анализа происхождения микроклонов, разработчики пользуются целым арсеналом разнообразных механических приемов и алгоритмов при копировании кода. Один из этих алгоритмов: "[написать оригинальный фрагмент], [скопировать оригинал], [скопировать оригинал], ..., [редактировать копию], [редактировать копию], ..." (см. опросы I4, I6). Наравне с ним применяется алгоритм: "[написать оригинальный фрагмент], [скопировать оригинал, редактировать копию], [скопировать оригинал, редактировать копию], ..." В некоторых предельных случаях в нашем наборе данных этот алгоритм, похоже, повторялся до 34 раз. Несмотря на то что при написании микроклонов используются разные методы, все они сводятся к последовательности действий с разным соотношением автоматических и сознательных операций. Таким образом, с точки зрения когнитивной психологии, ошибки, допускаемые разработчиками в микроклонах, являются типичными ошибками последовательности действий.
Несмотря на различия в частностях, все модели контроля последовательности действий согласны в том, что главной причиной ошибок такого рода, по-видимому, является когнитивный шум (Botvinick and Plaut 2004; Cooper and Shallice 2006; Trafton et al. 2011). Под шумом в данном случае подразумеваются любые не связанные с текущей задачей и отвлекающие на себя внимание программиста представления. Шум может порождаться стрессом, вызванным внешними причинами, например, ограничениями по срокам выполнения задачи, или внутренними, например, большими размерами коммитов. Модели контроля последовательности действий предоставляют полезную теоретическую базу, которая позволяет строить предположения о возможных психологических механизмах, лежащих в основе эффекта последней строки. На данном этапе мы располагаем только конкретными примерами микроклонов и сведениями об их расположении в коде, но не знаем подробностей их возникновения. Тем не менее, как показано в разделе 4.4, ответы опрошенных разработчиков и результаты анализа происхождения микроклонов позволяют нам сделать обоснованные выводы о том, как именно они появляются. Копирование и редактирование — это основные операции, выполняемые программистом при написании кода. Обратимся еще раз к примеру 1. Операция редактирования здесь состоит из двух более мелких шагов: правки имени переменной и правки значения.
Пример 1
TrinityCore
Ошибка находится в строке 3. По всей видимости, эта строка была создана копированием строки 2. Первая замена была выполнена успешно (имя переменной изменили с y на z), но второй шаг — правка значения — был пропущен, что привело к ошибке. Теоретически этот код мог быть создан с помощью двойного копирования строки 1 и последующей правки полученных дубликатов. Однако имя переменной y вместо x в строке 3 дает нам основание полагать, что скопирована была именно вторая строка. Как показано в разделе 4.4, в большинстве микроклонов длиной более двух строк копируется обычно предшествующая строка. Отсюда следует, что в таких случаях применялся алгоритм: "[копирование, правка, правка], [копирование, правка, правка], ..."
Согласно моделям контроля последовательности действий, ошибки этого типа происходят из-за когнитивного шума, который с наибольшей вероятностью возникает ближе к концу ряда однотипных операций, поскольку внимание программиста преждевременно переключается на следующую задачу, например, написание нового кода (см. опрос I6). Как уже было сказано, существует несколько незначительно отличающихся друг от друга версий, объясняющих причины возникновения когнитивного шума. В качестве примера приведем версию (Cooper and Shallice 2006), объясняющую эффект последней строки выбором неправильного плана действий (например, разработчик уже мысленно перешел к следующим строкам, вместо того чтобы сосредоточиться на завершении текущего фрагмента).
Хотя никто из опрошенных программистов не жаловался на чрезмерно высокий уровень стресса во время написания микроклонов, свидетельства респондентов I6 и I7 отличаются от остальных: они отметили высокую рабочую нагрузку в целом и желание быстрее продвигаться в написании кода. Анализ местного времени создания коммитов с дефектными микроклонами по табл. 7 показывает, что только два из них были созданы в обязательные рабочие часы, тогда как остальные программисты работали над кодом в неурочное время, хотя и делали это по долгу службы. Как известно, усталость снижает эффективность работы мозга и негативно влияет на кратковременную память (Kane et al. 2007). Возможно, именно усталость и спешка играют существенную роль в появлении дефектных микроклонов.
Кроме того, мы обнаружили, что все коммиты (в том числе и рефакторинг) с дефектными микроклонами отличаются исключительно большими размерами, на порядки превышающими стандартные размеры коммитов в своих репозиториях. Это наталкивает нас на мысль о том, что размер коммита является важным, если не ключевым фактором, провоцирующим когнитивный шум, из-за которого ошибки остаются незамеченными. Данный вывод хорошо согласуется с версией о перегрузке кратковременной памяти, а также с замечанием респондента I1 о том, что итоговый код очень сложно контролировать из-за большого объема.
Из результатов опросов следует, что короткоживущие дефектные микроклоны — широко распространенное явление в сфере разработки ПО, но они обычно выявляются на ранних этапах или, по крайней мере, в процессе обзора кода — проведенного самостоятельно или с помощью коллег (Beller и др. 2014). Таким образом, когнитивная ошибка, наблюдаемая в оставшихся, неисправленных, микроклонах, является не только ошибкой программирования, но и ошибкой рецензирования (Healy 1980) и состоит в том, что во время обзора кода разработчик не замечает дефект в последней и остальных строках. Фактически наши опросы показывают, что, по всей видимости, в микроклонах, оказавшихся в коммитах, такая ошибка допускалась дважды: один раз при обзоре кода его автором и как минимум еще раз — при вычитке коллегой. Появление ошибки в последней строке с большей вероятностью, чем в предыдущих, вероятно, связано, помимо прочего, с тем, что она является ошибкой последовательности действий. Человек мысленно переключается на следующую задачу (например, написание следующей части кода), не успев закончить текущую (обзор). Еще одно объяснение предполагает, что ошибка менее заметна из-за следующих подряд однотипных инструкций: последнюю из них рецензент прочитывает быстрее и потому менее внимательно. Более того, визуальное подобие оригинального экземпляра и копии может затруднять восприятие отдельных строк. Исследование проблем обзора кода показывает, что похожесть фрагментов (проявляющаяся в частоте повторения слов) приводит к тому, что рецензент тратит меньше времени на вычитку, а это негативно сказывается на его способности распознавать ошибки в тексте (Moravcsik and Healy 1995).
Все потенциальные факторы проявления эффекта последней строки связаны с повышенной вероятностью допущения ошибок такого рода в ситуациях, когда объем внимания программиста сокращается из-за когнитивного шума. Вероятные причины его возникновения, прежде всего, могут быть связаны с большими размерами коммитов, большой нагрузкой, стрессом, отвлекающими факторами и усталостью (O'Malley and Gallas 1977). И наоборот, наши наблюдения показывают, что способность разработчиков контролировать свою реакцию на посторонний шум (Fukuda и Vogel 2009), т.е. способность сосредотачиваться на задаче, в значительной степени влияет на вероятность появления микроклона с ошибкой последовательности действий.
5.3 Факторы, угрожающие валидности результатов исследования
В этом разделе мы рассмотрим внутренние и внешние угрозы валидности полученных нами результатов, а также покажем, каким образом мы свели их влияние к минимуму.
5.3.1 Внутренние факторы
Один из основных внутренних факторов связан с тем, чтобы правильно определить, в какой строке находится ошибка. Так, в примере 2 любую из двух инструкций можно принять за копию. Однако чтение и написание кода обычно происходит сверху вниз и слева направо (Siegmund и др. 2014). Поэтому естественным и единственно правильным будет считать, что расположение ошибок в строках и инструкциях подчиняется этому же порядку: в примере 2 мы можем понять, что вторая инструкция является копией первой, только прочитав ее, поэтому мы помечаем вторую инструкцию как дефектную. Далее, во многих случаях, как и в этом примере, ближайший контекст микроклона (в примере 2 переменная host объявляется первой, а уже затем объявляется port_str) задает естественный порядок и для остального текста программы (сначала проверить host, затем — port_str в строке 3). Чтобы свести к минимуму потенциальное влияние предвзятости исследователей, полученные данные были распределены для независимой обработки между первыми двумя авторами, а спорные случаи обсуждались совместно. Если по какому-либо результату прийти к согласию не удавалось, он отбрасывался. В ходе работы мы также заново классифицировали все 202 результата более раннего исследования (Beller и др. 2015) и выяснили, что они почти полностью согласуются с предыдущими выводами. Поскольку процедура разметки дефектных строк в данных обстоятельствах подробно регламентирована, мы уверены в высокой степени взаимного соответствия оценок каждого из экспертов, что гарантирует воспроизводимость нашего исследования.
Возможно, что наши диагностики не обнаруживают все дефектные микроклоны. Этот фактор представляет лишь незначительную угрозу, так как мы не претендуем на обнаружение всех ошибок этого вида. Мы считаем, что смогли найти большую часть микроклонов, расширив количество диагностик до 12 (см. табл. 1). Подтверждением этому служит тот факт, что большинство ошибок были найдены всего несколькими ключевыми диагностиками: V501, V517, V519 и V537; а также то, что ван Тондер и Ле Гу нашли более 24 000 ошибочных микроклонов с помощью сокращенного набора наших диагностик (van Tonder and Le Goues 2016).
Несмотря на нашу уверенность в правильности определения оригинальных экземпляров и копий, мы не знаем, каким образом копии создавались и редактировались разработчиками. Эмпирический анализ репозитория опирается на порядок чтения блоков кода сверху вниз, а отдельных строк — слева направо. Нам известно, что разработчики «перескакивают» между разными участками кода в процессе его чтения и уделяют особое внимание только тем блокам, которые представляются актуальными для решения текущей задачи (Busjahn и др. 2015; Siegmund и др. 2014). Вместе с тем, понять небольшие логически связанные фрагменты, которыми являются микроклоны, можно только читая код в направлении движения потока управления, т.е. сверху вниз и слева направо. В частности, нас интересуют ответы на следующие вопросы: 1) Сколько раз была использована последовательность горячих клавиш «ctrl+c, ctrl+v»? 2) В каком именно порядке создаются микроклоны? 3) В каком порядке программисты читают и правят микроклоны в процессе поддержки кода? Чтобы ответить на эти вопросы, нам пришлось бы провести исследование, в котором мы могли бы наблюдать за работой программистов «в полевых условиях», подобно тому, как это делает плагин WatchDog (Beller и др. 2015, 2015, 2016). Для этой цели мы могли бы использовать отдельные компоненты инструмента CloneBoard, который регистрирует все операции по вырезке, копированию и вставке в Eclipse (de Wit и др. 2009).
С учетом этих ограничений наши выводы о психологической основе эффекта последней строки на данном этапе могут быть спорными. Более тщательный анализ требует проведения психологического эксперимента, в котором процесс создания ошибок можно было бы изучить в естественных условиях. В силу особенностей выбранных нами методов исследования есть риск, что мы упустили какие-то специфические этапы в создании микроклонов. Тем не менее, мы полагаем, что воспроизведение ситуации, в которой возможно появление дефектных микроклонов, в лабораторных условиях крайне проблематично, так как наши респонденты отмечали, что для создания относительно небольшого числа таких фрагментов требуется продолжительное время. Более того, искусственная природа подобного эксперимента, возможные ограничения по времени и достоверно установленная склонность испытуемых прилагать больше усилий в условиях эксперимента, чем в реальной жизни (Adair 1984), существует риск, что они не допустят ошибок в микроклонах вовсе. Поскольку результаты исследования, полученные целым рядом различных методов, согласуются друг с другом, мы считаем, что сумели с достаточной достоверностью установить причины существования дефектных микроклонов вообще и эффекта последней строки в частности.
5.3.2 Внешние факторы
К внешним угрозам валидности можно отнести тот факт, что инструмент PVS-Studio разработан специально для языков C и C++. C — один из наиболее широко используемых языков (Meyerovich and Rabkin 2013), поэтому даже если наши результаты нельзя применить к другим языкам, они, по крайней мере, принесут пользу крупным сообществам C и C++ программистов. С другой стороны, наше исследование касается конструкций, свойственных большинству языков программирования: присваиваний, if-операторов, Булевых выражений и массивов (см. примеры 1, 2, 5, 7 и 11). По этой причине мы ожидаем аналогичных результатов по крайней мере для тех языков, в основе которых лежит язык C: Java, JavaScript, C#, PHP, Ruby и Python. Несмотря на значительный объем базы найденных ошибок, в среднем в проекте содержится ?1,2 микроклонов, что весьма немного (см. табл. 2). Этот показатель можно было бы объяснить тем, что диагностики PVS-Studio, выявляющие дефектные микроклоны, находят не все ошибки, а также тем, что изученные нами проекты представляют собой стабильные, развивающиеся системы со зрелой базой исходного кода и отличаются сравнительно малым числом тривиальных ошибок. Однако опрошенные нами разработчики дали другое объяснение: интенсивное применение тестов и обзоры кода значительно сокращают количество дефектных микроклонов, успевающих дойти до релиза.
6 Другие исследования по теме
Дублированные или однотипные фрагменты кода широко известны под названием «клонов кода», однако за последние десять лет не было дано их четкого определения (Roy и др. 2014). Эта неопределенность отражена в таких дефинициях как: «клоны кода — это сегменты кода, сходство между которыми определяется по какому-либо критерию сходства» (Baxter и др. (1998)) и «клоны кода — [...] это фрагменты достаточной длины, отличающиеся незначительным сходством» (Basit and Jarzabek (2007)). Второе определение идентифицирует клоны как фрагменты кода достаточной длины, имеющие достаточно много общих черт, тогда как в первом определении размер клонов не учитывается. Широко используется определение, в котором клоны классифицируются по трем типам (Koschke 2007). Клоны 1 типа абсолютно идентичны, а клоны 2 типа совпадают по синтаксической структуре (но отличаются идентификаторами). Клоны 3 типа еще сильнее отличаются синтаксической структурой, а клоны 4 типа идентичны только с функциональной точки зрения (Roy и др. 2014). Вместе с тем, в этой классификации также не учитывается критерий длины. Со временем исследователи предложили целый ряд более специальных определений (Koschke 2007; Balazinska и др. 1999; Kapser and Godfrey 2003). В рамках данного исследования мы вводим собственную категорию клонов кода: короткие, но тесно связанные между собой клоны, чей размер меньше нижней границы «достаточной длины», при этом в пределах одного клона зачастую содержится не более двух дублированных инструкций. Такие клоны крайне малого размера мы называем микроклонами.
Далее мы сравним традиционные средства обнаружения клонов кода с нашими методами. В своем исследовании от 2007 года Беллон и другие авторы сравнивали и оценивали инструменты обнаружения клонов. Всего было изучено шесть инструментов для языков C и Java (Bellon и др. 2007). В зависимости от конкретного инструмента минимальная длина клонов должна была составлять шесть строк или 25 токенов. В 2014 году Свайленко и Рой провели похожее исследование, в котором они сравнили одиннадцать современных инструментов по способности распознавать паттерны клонов (Svajlenko and Roy 2014). Для этой работы отбирались клоны с минимальной длиной 50 токенов, 15 инструкций или 15 строк (Svajlenko and Roy 2014). Указанные пороговые значения слишком велики для обнаружения микроклонов. Впрочем, традиционным инструментам такие значения необходимы для того, чтобы отсеять многочисленные ложные срабатывания. Наш подход позволяет обойти эту проблему за счет обнаружения только дефектных микроклонов.
Сразу после нашего исследования (Beller и др. 2015) ван Тондер и Ле Гу осуществили крупномасштабный поиск микроклонов в 380 125 репозиториях проектов на языке Java (van Tonder and Le Goues 2016) и обнаружили 24 304 дефектных микроклона, тем самым подтвердив наше предположение, что микроклоны широко распространены в программах. Исследователи представили разработчикам 43 патча для исправления найденных ошибок, и все они были оперативно применены. Этот факт показывает, что разработчики считают важным устранять такие ошибки и что этот процесс может быть в значительной степени автоматизирован.
Эмпирические данные исследований с помощью традиционных детекторов клонов говорят о том, что их содержание в кодовой базе, как правило, составляет примерно от 9% до 17% (Zibran и др. 2011), учитывая клоны типов 1, 2 и 3 (Koschke 2007). Статистические выбросы так называемого «покрытия клонов» находятся на уровне ниже 5% (Roy and Cordy 2007) и выше 50% (Rieger и др. 2004; Roy и др. 2014). Эти данные не учитывают микроклоны, которые, как мы показали, часто являются источником ошибок во многих рассмотренных в нашей работе открытых проектах. Если при проверке кода учесть это влияние, общее количество обнаруживаемых клонов может значительно вырасти — по крайней мере, с точки зрения критерия «покрытия микроклонов». Считается, что высокий уровень покрытия клонов труднодостижим, поскольку многочисленные исследования показывают, что он положительно коррелирует с ошибками и противоречиями в коде. (Chatterji и др. 2011; Gode and Koschke 2011; Inoue и др. 2012; Xie и др. 2013).
7 Дальнейшая работа и выводы
В этом разделе мы опишем возможные направления для дальнейших исследований, а также озвучим выводы по проделанной работе.
Поскольку наше исследование посвящено именно дефектным микроклонам, мы не можем предсказать, каков процент содержания ошибок среди вообще всех микроклонов. Перспективным направлением дальнейшей работы представляется создание инструмента, который мог бы надежно выявлять все микроклоны, а затем распознавать среди них именно дефектные. Эта задача дает представление о масштабе стоящей перед нами проблемы. Как можно заключить из свидетельств респондентов, микроклоны создаются с заметной частотой, и поиск ошибок в них с помощью обзора и тестирования кода отнимает драгоценное время. Для раннего обнаружения микроклонов можно рекомендовать включить наши диагностики в IDE: реализация этого решения также имеет хорошие перспективы.
На основе нашего предварительного анализа психологических причин эффекта последней строки можно было бы осуществить более масштабный контролируемый эксперимент, в котором, однако, может присутствовать высокий, по нашему мнению, риск не получить достаточного количества дефектных микроклонов. Уже имеющийся инструментарий может упростить техническую сторону такого эксперимента.
Изучив 219 открытых проектов, мы обнаружили в них 263 микроклона с дефектами. Полученные данные показывают, что ошибки с высокой вероятностью появляются в последних строках и с еще большей вероятностью — в последней инструкции. Этот эффект мы и назвали эффектом последней строки. Фактически вероятность ошибки в последней строке микроклона в три раза выше, чем во всех предыдущих строках вместе взятых, а вероятность ошибки в последней инструкции — в девять раз выше, чем во всех предыдущих инструкциях вместе взятых.
Психологические причины этого явления, по всей видимости, связаны с ошибками последовательности действий, когда разработчики оказываются неспособны корректно выполнить последовательность простых повторяющихся операций из-за перегрузки кратковременной памяти, вызванной когнитивным шумом. Мы получили свидетельства того, что эффект последней строки во многом определяется используемыми разработчиками приемами копирования-вставки кода. Похоже, что в процессе написания кода программисты склонны преждевременно считать задачу по редактированию копированных фрагментов завершенной, из-за чего они пропускают последнюю операцию. Среди ключевых причин возникновения когнитивного шума можно, по-видимому, назвать аномально большие размеры коммитов, а также воздействие усталости и стресса.
Принимая во внимание все вышесказанное, мы советуем программистам быть особенно внимательными при чтении, исправлении, написании и обзоре последних строк и инструкций в микроклонах, особенно если они были написаны методом копирования и вставки. Более того, результаты нашего исследования показывают, что дефектные микроклоны присутствовали только в аномально больших коммитах, что говорит о необходимости сократить размеры загружаемых коммитов, чтобы облегчить их вычитку. Это знание может помочь разработчикам допускать меньше ошибок в клонированных фрагментах как при написании, так и при обзоре кода; распознавать ситуации, в которых они с большей вероятностью склонны допустить ошибку из-за перегрузки кратковременной памяти, и принять меры, чтобы избежать этого. С помощью PVS-Studio мы создаём автоматизированный инструмент, который поможет разработчикам находить проникшие в коммит ошибки до релиза, например, на этапе обзора кода.
Примечания
- TrinityCore — популярная платформа с открытым кодом для создания массовых многопользовательских онлайн-игр (MMOG), www.trinitycore.org.
- Chromium — открытая часть Google Chrome, www.chromium.org.
- http://www.viva64.com/ru/b/0260
- www.reddit.com/r/programming/comments/270orx/the_last_line_effect
- http://www.viva64.com/ru/pvs-studio-download
- 10.6084/m9.figshare.1313697
- Некоторые инструменты для обнаружения клонов считают присваиваемый объект и ссылку на его поле за одну единицу. С точки зрения этого подхода, длина кода составляет три единицы.
- Более подробное описание диагностик: http://viva64.com/ru/d/0368/.
- https://codereview.chromium.org/7031055
- www.google.com/search?q=pvs-studio+bug+|+issue
- https://bugzilla.samba.org/show_bug.cgi?id=12373
- В Clang начали использовать предложенные нами диагностики. Подробнее: https://llvm.org/bugs/show_bug.cgi?id=9952.
Благодарности
Мы выражаем благодарность Диомидису Спинеллису за вдохновляющую беседу во время встречи на Международной конференции по разработке программного обеспечения ICSE'15 на «Mercato Centrale», а также Маурисио Анишу, Йозефу Хейдерупу и Можан Сольтани за рецензирование этой статьи.
Список литературы
Adair JG (1984) The Hawthorne effect: a reconsideration of the methodological artifact. J Appl Psychol 69(2):334-345 CrossRef Google Scholar
Anderson JR (1990) Cognitive psychology and its implications. WH Freeman/Times Books/Henry Holt & Co
Balazinska M, Merlo E, Dagenais M, Lague B, Kontogiannis K (1999) Measuring clone based reengineering opportunities. In: Proceedings of the international software metrics symposium (METRICS). IEEE, pp 292-303
Basit HA, Jarzabek S (2007) Efficient token based clone detection with flexible tokenization. In: Proceedings of the 6th joint meeting of the European software engineering conference and the ACM SIGSOFT international symposium on foundations of software engineering (ESEC/FSE). ACM, pp 513-516
Baxter ID, Yahin A, de Moura LM, Sant'Anna M, Bier L (1998) Clone detection using abstract syntax trees. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 368-377
Beller M, Bacchelli A, Zaidman A, Juergens E (2014) Modern code reviews in open-source projects: Which problems do they fix? In: Proceedings of the 11th working conference on mining software repositories. ACM, pp 202-211
Beller M, Bholanath R, McIntosh S, Zaidman A (2016) Analyzing the state of static analysis: a large-scale evaluation in open source software. In: Proceedings of the 23rd IEEE international conference on software analysis, evolution, and reengineering. IEEE, pp 470-481
Beller M, Gousios G, Panichella A, Zaidman A (2015) When, how, and why developers (do not) test in their IDEs. In: Proceedings of the 10th joint meeting of the european software engineering conference and the ACM SIGSOFT symposium on the foundations of software engineering (ESEC/FSE). ACM
Beller M, Gousios G, Zaidman A (2015) How (much) do developers test? In: 37th International conference on software engineering (ICSE). ACM, pp 559-562
Beller M, Levaja I, Panichella A, Gousios G, Zaidman A (2016) How to catch 'em all: watchdog, a family of ide plug-ins to assess testing. In: 3rd International workshop on software engineering research and industrial practice (SER&IP 2016). IEEE, pp 53-56
Beller M, Zaidman A, Karpov A (2015) The last line effect. In: 23rd International conference on program comprehension (ICPC). ACM, pp 240-243
Bellon S, Koschke R, Antoniol G, Krinke J, Merlo E (2007) Comparison and evaluation of clone detection tools. IEEE Trans Softw Eng 33(9):577-591 CrossRef Google Scholar
Bland JM, Altman DG (2000) The odds ratio. Bmj 320(7247):1468 CrossRef Google Scholar
Botvinick M, Plaut DC (2004) Doing without schema hierarchies: a recurrent connectionist approach to routine sequential action and its pathologies 111:395-429
Busjahn T, Bednarik R, Begel A, Crosby M, Paterson JH, Schulte C, Sharif B, Tamm S (2015) Eye movements in code reading: relaxing the linear order. In: Proceedings of the international conference on program comprehension (ICPC). ACM, pp 255-265
Chatterji D, Carver JC, Massengil B, Oslin J, Kraft N et al (2011) Measuring the efficacy of code clone information in a bug localization task: an empirical study. In: Proceedings of the international symposium on empirical software engineering and measurement (ESEM). IEEE, pp 20-29
Cooper R, Shallice T (2006) Hierarchical schemas and goals in the control of sequential behaviour, vol 113
de Wit M, Zaidman A, van Deursen A (2009) Managing code clones using dynamic change tracking and resolution. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 169-178
Fukuda K, Vogel EK (2009) Human variation in overriding attentional capture. J Neurosci 29(27):8726- 8733CrossRef Google Scholar
Gode N, Koschke R (2011) Frequency and risks of changes to clones. In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 311-320
Healy AF (1980) Proofreading errors on the word the: new evidence on reading units. J Exper Psychol Human Percep Perform 6(1):45CrossRef Google Scholar
Inoue K, Higo Y, Yoshida N, Choi E, Kusumoto S, Kim K, Park W, Lee E (2012) Experience of finding inconsistently-changed bugs in code clones of mobile software. In: Proceedings of the international workshop on software clones (IWSC). IEEE, pp 94-95
Juergens E, Deissenboeck F, Hummel B, Wagner S (2009) Do code clones matter? In: Proceedings of the international conference on software engineering (ICSE). IEEE, pp 485-495
Kane MJ, Brown LH, McVay JC, Silvia PJ, Myin-Germeys I, Kwapil TR (2007) For whom the mind wanders, and when an experience-sampling study of working memory and executive control in daily life. Psychol Sci 18(7):614-621CrossRef Google Scholar
Kapser C, Godfrey M (2003) A taxonomy of clones in source code: the re-engineers most wanted list. In: 2nd International workshop on detection of software clones (IWDSC-03), vol 13
Kapser CJ, Godfrey MW (2008) Cloning considered harmful-considered harmful: patterns of cloning in software. Emp Softw Eng 13(6):645-692CrossRef Google Scholar
Kim M, Bergman L, Lau T, Notkin D (2004) An ethnographic study of copy and paste programming practices in oopl. In: Proc. International symposium on empirical software engineering (ISESE). IEEE, pp 83-92
Koschke R (2007) Survey of research on software clones. In: Koschke R, Merlo E, Walenstein A (eds) Duplication, redundancy, and similarity in software, no. 06301 in Dagstuhl seminar proceedings. Internationales Begegnungs- und Forschungszentrum fur Informatik (IBFI). https://web.archive.org/web/20161024110147/http://drops.dagstuhl.de/opus/volltexte/2007/962/. Schloss Dagstuhl, Dagstuhl
Meyerovich L, Rabkin A (2013) Empirical analysis of programming language adoption. In: ACM SIGPLAN notices, vol 48. ACM, pp 1-18
Moravcsik JE, Healy AF (1995) Effect of meaning on letter detection. J Exper Psychol Learn Memory Cogn 21(1):82CrossRefGoogle Scholar
O'Malley JJ, Gallas J (1977) Noise and attention span. Percep Motor Skills 44(3):919-922CrossRef Google Scholar
Rieger M, Ducasse S, Lanza M (2004) Insights into system-wide code duplication. In: Proceedings of the working conference on reverse engineering (WCRE). IEEE, pp 100-109
Roy C, Cordy J, Koschke R (2009) Comparison and evaluation of code clone detection techniques and tools: a qualitative approach. Sci Comput Program 74 (7):470-495 MathSciNet CrossRef MATH Google Scholar
Roy CK, Cordy JR (2007) A survey on software clone detection research. Tech. Rep. TR 2007-541. Queens University
Roy CK, Zibran MF, Koschke R (2014) The vision of software clone management: past, present, and future (keynote paper). In: 2014 Software evolution week — IEEE conference on software maintenance, reengineering, and reverse engineering, (CSMR-WCRE). IEEE, pp 18-33
Siegmund J, Kastner C, Apel S, Parnin C, Bethmann A, Leich T, Saake G, Brechmann A (2014) Understanding understanding source code with functional magnetic resonance imaging. In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 378-389
Svajlenko J, Roy CK (2014) Evaluating modern clone detection tools. In: 30th IEEE International conference on software maintenance and evolution (ICSME). IEEE, pp 321-330
van Tonder R, Le Goues C (2016) Defending against the attack of the micro-clones. In: 2016 IEEE 24th International conference on program comprehension (ICPC). IEEE, pp 1-4
Trafton JG, Altmann EM, Ratwani RM (2011) A memory for goals model of sequence errors. Cogn Syst Res 12:134-143 CrossRef Google Scholar
Xie S, Khomh F, Zou Y (2013) An empirical study of the fault-proneness of clone mutation and clone migration. In: Proceedings of the 10th working conference on mining software repositories (MSR). IEEE
Zibran MF, Saha RK, Asaduzzaman M, Roy CK (2011) Analyzing and forecasting near-miss clones in evolving software: an empirical study. In: Proceedings of the international conference on engineering of complex computer systems (ICECCS). IEEE, pp 295-304
Anderson JR (1990) Cognitive psychology and its implications. WH Freeman/Times Books/Henry Holt & Co
Balazinska M, Merlo E, Dagenais M, Lague B, Kontogiannis K (1999) Measuring clone based reengineering opportunities. In: Proceedings of the international software metrics symposium (METRICS). IEEE, pp 292-303
Basit HA, Jarzabek S (2007) Efficient token based clone detection with flexible tokenization. In: Proceedings of the 6th joint meeting of the European software engineering conference and the ACM SIGSOFT international symposium on foundations of software engineering (ESEC/FSE). ACM, pp 513-516
Baxter ID, Yahin A, de Moura LM, Sant'Anna M, Bier L (1998) Clone detection using abstract syntax trees. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 368-377
Beller M, Bacchelli A, Zaidman A, Juergens E (2014) Modern code reviews in open-source projects: Which problems do they fix? In: Proceedings of the 11th working conference on mining software repositories. ACM, pp 202-211
Beller M, Bholanath R, McIntosh S, Zaidman A (2016) Analyzing the state of static analysis: a large-scale evaluation in open source software. In: Proceedings of the 23rd IEEE international conference on software analysis, evolution, and reengineering. IEEE, pp 470-481
Beller M, Gousios G, Panichella A, Zaidman A (2015) When, how, and why developers (do not) test in their IDEs. In: Proceedings of the 10th joint meeting of the european software engineering conference and the ACM SIGSOFT symposium on the foundations of software engineering (ESEC/FSE). ACM
Beller M, Gousios G, Zaidman A (2015) How (much) do developers test? In: 37th International conference on software engineering (ICSE). ACM, pp 559-562
Beller M, Levaja I, Panichella A, Gousios G, Zaidman A (2016) How to catch 'em all: watchdog, a family of ide plug-ins to assess testing. In: 3rd International workshop on software engineering research and industrial practice (SER&IP 2016). IEEE, pp 53-56
Beller M, Zaidman A, Karpov A (2015) The last line effect. In: 23rd International conference on program comprehension (ICPC). ACM, pp 240-243
Bellon S, Koschke R, Antoniol G, Krinke J, Merlo E (2007) Comparison and evaluation of clone detection tools. IEEE Trans Softw Eng 33(9):577-591 CrossRef Google Scholar
Bland JM, Altman DG (2000) The odds ratio. Bmj 320(7247):1468 CrossRef Google Scholar
Botvinick M, Plaut DC (2004) Doing without schema hierarchies: a recurrent connectionist approach to routine sequential action and its pathologies 111:395-429
Busjahn T, Bednarik R, Begel A, Crosby M, Paterson JH, Schulte C, Sharif B, Tamm S (2015) Eye movements in code reading: relaxing the linear order. In: Proceedings of the international conference on program comprehension (ICPC). ACM, pp 255-265
Chatterji D, Carver JC, Massengil B, Oslin J, Kraft N et al (2011) Measuring the efficacy of code clone information in a bug localization task: an empirical study. In: Proceedings of the international symposium on empirical software engineering and measurement (ESEM). IEEE, pp 20-29
Cooper R, Shallice T (2006) Hierarchical schemas and goals in the control of sequential behaviour, vol 113
de Wit M, Zaidman A, van Deursen A (2009) Managing code clones using dynamic change tracking and resolution. In: Proceedings of the international conference on software maintenance (ICSM). IEEE, pp 169-178
Fukuda K, Vogel EK (2009) Human variation in overriding attentional capture. J Neurosci 29(27):8726- 8733CrossRef Google Scholar
Gode N, Koschke R (2011) Frequency and risks of changes to clones. In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 311-320
Healy AF (1980) Proofreading errors on the word the: new evidence on reading units. J Exper Psychol Human Percep Perform 6(1):45CrossRef Google Scholar
Inoue K, Higo Y, Yoshida N, Choi E, Kusumoto S, Kim K, Park W, Lee E (2012) Experience of finding inconsistently-changed bugs in code clones of mobile software. In: Proceedings of the international workshop on software clones (IWSC). IEEE, pp 94-95
Juergens E, Deissenboeck F, Hummel B, Wagner S (2009) Do code clones matter? In: Proceedings of the international conference on software engineering (ICSE). IEEE, pp 485-495
Kane MJ, Brown LH, McVay JC, Silvia PJ, Myin-Germeys I, Kwapil TR (2007) For whom the mind wanders, and when an experience-sampling study of working memory and executive control in daily life. Psychol Sci 18(7):614-621CrossRef Google Scholar
Kapser C, Godfrey M (2003) A taxonomy of clones in source code: the re-engineers most wanted list. In: 2nd International workshop on detection of software clones (IWDSC-03), vol 13
Kapser CJ, Godfrey MW (2008) Cloning considered harmful-considered harmful: patterns of cloning in software. Emp Softw Eng 13(6):645-692CrossRef Google Scholar
Kim M, Bergman L, Lau T, Notkin D (2004) An ethnographic study of copy and paste programming practices in oopl. In: Proc. International symposium on empirical software engineering (ISESE). IEEE, pp 83-92
Koschke R (2007) Survey of research on software clones. In: Koschke R, Merlo E, Walenstein A (eds) Duplication, redundancy, and similarity in software, no. 06301 in Dagstuhl seminar proceedings. Internationales Begegnungs- und Forschungszentrum fur Informatik (IBFI). https://web.archive.org/web/20161024110147/http://drops.dagstuhl.de/opus/volltexte/2007/962/. Schloss Dagstuhl, Dagstuhl
Meyerovich L, Rabkin A (2013) Empirical analysis of programming language adoption. In: ACM SIGPLAN notices, vol 48. ACM, pp 1-18
Moravcsik JE, Healy AF (1995) Effect of meaning on letter detection. J Exper Psychol Learn Memory Cogn 21(1):82CrossRefGoogle Scholar
O'Malley JJ, Gallas J (1977) Noise and attention span. Percep Motor Skills 44(3):919-922CrossRef Google Scholar
Rieger M, Ducasse S, Lanza M (2004) Insights into system-wide code duplication. In: Proceedings of the working conference on reverse engineering (WCRE). IEEE, pp 100-109
Roy C, Cordy J, Koschke R (2009) Comparison and evaluation of code clone detection techniques and tools: a qualitative approach. Sci Comput Program 74 (7):470-495 MathSciNet CrossRef MATH Google Scholar
Roy CK, Cordy JR (2007) A survey on software clone detection research. Tech. Rep. TR 2007-541. Queens University
Roy CK, Zibran MF, Koschke R (2014) The vision of software clone management: past, present, and future (keynote paper). In: 2014 Software evolution week — IEEE conference on software maintenance, reengineering, and reverse engineering, (CSMR-WCRE). IEEE, pp 18-33
Siegmund J, Kastner C, Apel S, Parnin C, Bethmann A, Leich T, Saake G, Brechmann A (2014) Understanding understanding source code with functional magnetic resonance imaging. In: Proceedings of the international conference on software engineering (ICSE). ACM, pp 378-389
Svajlenko J, Roy CK (2014) Evaluating modern clone detection tools. In: 30th IEEE International conference on software maintenance and evolution (ICSME). IEEE, pp 321-330
van Tonder R, Le Goues C (2016) Defending against the attack of the micro-clones. In: 2016 IEEE 24th International conference on program comprehension (ICPC). IEEE, pp 1-4
Trafton JG, Altmann EM, Ratwani RM (2011) A memory for goals model of sequence errors. Cogn Syst Res 12:134-143 CrossRef Google Scholar
Xie S, Khomh F, Zou Y (2013) An empirical study of the fault-proneness of clone mutation and clone migration. In: Proceedings of the 10th working conference on mining software repositories (MSR). IEEE
Zibran MF, Saha RK, Asaduzzaman M, Roy CK (2011) Analyzing and forecasting near-miss clones in evolving software: an empirical study. In: Proceedings of the international conference on engineering of complex computer systems (ICECCS). IEEE, pp 295-304
Авторское право
Коллектив авторов, 2016
Открытый доступ
На данную статью распространяется действие лицензии Creative Commons Attribution 4.0 International, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии, что лицензиат указывает авторство и место размещения оригинального текста, а также предоставляет ссылку на лицензию Creative Commons и обозначает изменения, если таковые были сделаны.
Поделиться с друзьями
Комментарии (9)

Killy
15.03.2017 02:14При вычитке текста есть такой приём — читать с конца в начало, чтобы не отвлекаться на содержание и не проскакивать куски текста.
В какой-то мере это можно попробовать адаптировать для ревью кода — повторяющиеся блоки читать снизу вверх.
Killy
15.03.2017 02:25По поводу добытия живых примеров ошибок.
Есть сервисы лайв-кодинга, например watchpeoplecode, liveedu (бывший livecoding), и даже twitch.
Можно проверить соответствующие исходники (там где доступны, если доступны) и найти соответствующие фрагменты на видео.

Carburn
15.03.2017 05:29+1TL;DR

Envek
15.03.2017 10:05+8Программисты не могут правильно скопипастить и отредактировать одну строчку кода несколько раз, потому что они человеки (и раздолбаи). В итоге в таких кусках постоянно ошибки, обычно в самой последней строке или аргументе. Обращайте особое внимание при ревью кода
и купите у нас PVS-Studio.
KIVagant
Подход выглядит очень научным (видимо таким и является), но читать такую статью не очень интересно. Прочитал последние пару абзацев, взял на заметку, что при дублировании строк или вставке кусочков кода нужно внимательно следить за последними строками и инструкциями.
m03r
Это и есть перевод научной статьи. Другое дело, что с оформлением тут совсем беда: код вставлен картинками, ссылки на сноски потеряны, исследования, в оригинале называющиеся C1 и C2, превратились в C1 и С2, текст сносок есть, а самих сносок нет, ну и качество некоторых картинок, мягко говоря, сомнительное. Особенно неприятно это в связи с тем, что перевод опубликован от имени одного из авторов статьи.
SystemXFiles
Внимательно следить может наоборот усугубить ситуацию, ибо область внимания сужается очень, из-за чего можно пропустить порой даже очевидные ошибки. Единственное, что реально помогает, это code review. Можно конечно тестами покрывать, но по опыту знаю, что тестами в большом модуле не напасешься и некоторые ситуацию даже не догадаешься проверить.
Deosis
Судя по примерам ошибка происходит в случае нескольких правок после вставки.
Поэтому стоит запоминать количество изменений, которые надо внести после правки (хотя это не поможет если отвлекут)
Можно попробовать определить макрос или шаблон вида:
Только не знаю, в каком языке такое допустимо