

Как правило, при обсуждении диагностических возможностей PVS-Studio за кадром остаются рекомендации, выдаваемые анализатором по поводу микрооптимизаций Си и Cи++ кода. Конечно, микрооптимизации не так важны, как диагностики, выявляющие ошибки, но про них тоже интересно поговорить.
Микрооптимизации
Я продолжаю цикл статей, связанных с анализом кода операционной системы Tizen. Проект Tizen, (включая сторонние библиотеки) насчитывает около 72 500 000 строк кода на языке Си и Си++. Проект интересен мне своим размером, так как позволяет демонстрировать различные аспекты использования методологии статического анализа кода.
В предыдущей статье "27000 ошибок в операционной системе Tizen" я показал, как можно оценочно посчитать количество ошибок, которые могут быть выявлены статическим анализатором кода. В статье также рассмотрено большое количество фрагментов кода, демонстрирующих возможности анализатора в выявлении разнообразных типов дефектов. Однако, помимо выявления ошибок анализатор может предложить ряд улучшений, влияющих на производительность кода.
Сразу скажу, что PVS-Studio не выступает и не может выступать как замена инструментам профилирования программ. Выявить узкие места могут только динамические анализаторы программ. Статические анализаторы не знают, какие входные данные получают программы и как часто выполняется тот или иной участок кода. Поэтому мы и говорим, что анализатор предлагает выполнить некоторые "микро оптимизации" кода, которые вовсе не гарантируют прироста производительности.
Если от использования микрооптимизаций не стоит ждать заметного прироста производительности, то нужны ли они вообще? Да, и у меня есть для этого следующие обоснования:
- Соответствующие диагностики анализатора часто выявляют плохой код. Изменяя его, программист сделает код проще, понятнее и часто короче.
- От микрооптимизаций мало проку в Release-версии, так как компиляторы сейчас умеют отлично оптимизировать код. Зато в Debug версии некоторые микрооптимизации совсем не «микро» и позволяют ускорить работу приложения, что бывает весьма полезно.
В PVS-Studio пока мало диагностик, посвященных микрооптимизациям (см. диагностики с номерами V801-V820), но постепенно мы будем развивать набор этих диагностик. В статьях мы редко обращали внимание на них, поэтому сейчас в процессе изучения кода Tizen есть подходящий момент поговорить на эту тему.
Итак, давайте рассмотрим существующие предупреждения PVS-Studio, посвященные микрооптимизациям.
Примеры срабатываний
Как я писал в предыдущей статье, я изучил около 3.3% кода Tizen. Поэтому я смогу спрогнозировать, сколько предупреждений определенного типа выдаст PVS-Studio для всего проекта, умножая количество найденных сообщений на 30.

Прошу запомнить этот множитель 30, так как я буду постоянно его использовать в дальнейших вычислениях.
V801: It is better to redefine the N function argument as a reference
Неэффективно делать функции, принимающие «тяжёлые» аргументы по значению. Диагностика срабатывает, когда аргументы являются константными и значит точно не будут изменяться в теле функции.
Пример из кода Tizen:
inline void setLogTag(const std::string tagName) {
m_tag = tagName;
}PVS-Studio: V801 Decreased performance. It is better to redefine the first function argument as a reference. Consider replacing 'const… tagName' with 'const… &tagName'. Logger.h 110
Создаётся лишний объект tagName, что является дорогой операцией. В этом коде выполняются такие операции, как выделение памяти и копирование данных. Причем, этих дорогостоящих операций можно избежать. Самый простой вариант — передавать аргумент по константной ссылке:
inline void setLogTag(const std::string &tagName) {
m_tag = tagName;
}Так мы избавились от выделения памяти и копирования строки.
Есть и другой вариант. Можно убрать const и при этом не копировать, а перемещать данные:
inline void setLogTag(std::string tagName) {
m_tag = std::move(tagName);
}Этот код будет столь же эффективным.
Вариант с std::string, конечно, безобиден. Создание лишней строки неприятно, но не может как-то сказываться на скорости работы. Однако, могут встретиться и более серьезные ситуации, когда, например, зря создаётся массив строк. С одним таким случаем мы ознакомимся ниже, когда будем говорить о диагностике V813.
Всего анализатор выдал 76 предупреждений на изученные мною проекты.
Следует учитывать, что анализатор иногда может выдавать срабатывания, не приносящие практической пользы. Например, анализатор не сможет отличить самодельный умный указатель от элемента односвязного списка. И там и там будет указатель (на строку / следующий элемент). И там и там будет целочисленная переменная (длина строки / значение элемента списка). Вроде бы одно и то же, но затраты на копирование таких объектов будут принципиально разные. Конечно, можно заглянуть в конструктор копирования и попытаться понять, что к чему, но в целом всё это безнадёжное занятие. Поэтому такие срабатывания есть смысл игнорировать и для их подавления следует использовать один из механизмов, предоставляемых анализатором PVS-Studio. Про эти механизмы, я, пожалуй, в дальнейшем напишу отдельную статью.
Сейчас нам понадобится множитель 30, про который я говорил ранее. Используя его, я могу подсчитать, что для всего проекта Tizen анализатор PVS-Studio выдаст около 76*30=2280 предупреждений V801.
V802: On 32-bit/64-bit platform, structure size can be reduced from N to K bytes by rearranging the fields according to their sizes in decreasing order
Диагностика V802 ищет структуры и классы, размер которых можно уменьшить за счёт сортировки полей в порядке убывания их размера. Пример неоптимальной структуры:
struct LiseElement {
bool m_isActive;
char *m_pNext;
int m_value;
};Данная структура в 64-битном коде (LLP64) займет 24 байта, что связано с выравниванием данных. Если поменять последовательность полей, то ее размер составит всего 16 байт. Оптимизированный вариант структуры будет выглядеть так:
struct LiseElement {
char *m_pNext;
int m_value;
bool m_isActive;
};Отметим, что приведенная структура всегда занимает 12 байт в 32-битной программе, в какой бы последовательности не располагались поля. Поэтому, при проверке 32-битной конфигурации (ILP32LL), сообщение V802 выдано не будет.
Следует отметить, что оптимизация структур не всегда возможна и не всегда необходима.
Оптимизация невозможна, если нужно сохранить совместимость формата данных. Ещё чаще подобная оптимизация просто не нужна. Если объекты неоптимальной структуры создаются десятками или сотнями, то никакого полезного выигрыша не получится. Есть смысл задумываться о такой оптимизации, когда количество элементов исчисляется миллионами. Ведь чем меньше размер будет занимать каждая структура, тем больше таких структур будет помещаться в кэши микропроцессора.
Как видите, область применения диагностики V802 крайне мала, поэтому чаще всего эту диагностику разумно выключить, чтобы она не мешалась. Соответственно, я не вижу смысла считать, сколько неоптимальных структур может найти PVS-Studio в коде Tizen. Думаю, что в более чем 99% случаев оптимизировать структуры не надо. Продемонстрирую здесь только саму возможность такого анализа, приведя одно предупреждение, выданное на код Tizen.
typedef struct {
unsigned char format;
long long unsigned fields;
int index;
} bt_pbap_pull_vcard_parameters_t;PVS-Studio: V802 On 32-bit platform, structure size can be reduced from 24 to 16 bytes by rearranging the fields according to their sizes in decreasing order. bluetooth-api.h 1663
Если анализатор не ошибается, то при компиляции кода для платформы Tizen, тип long long unsigned должен быть выравнен по границе 8 байт. Если честно, мы пока этот момент не уточняли, так как эта платформа новая для нас, но в знакомых мне системах дело обстоит именно так :).
Итак, раз переменная fields выравнивается по границе 8 байт, то структура будет выглядеть в памяти так:

Можно перетасовать члены класса следующим образом:
typedef struct {
long long unsigned fields;
int index;
unsigned char format;
} bt_pbap_pull_vcard_parameters_t;Тогда удастся сэкономить 8 байт и структура будет размещена в памяти следующим образом:
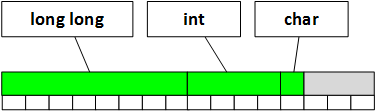
Как видите, размер структуры сократился.
V803. It is more effective to use the prefix form of ++it. Replace iterator++ with ++iterator
В книгах рекомендуют использовать в циклах префиксный инкремент итераторов, вместо постфиксного. Вопрос, насколько это актуально в наши дни, рассматривается в статьях:
- Андрей Карпов. Есть ли практический смысл использовать для итераторов префиксный оператор инкремента ++it, вместо постфиксного it++.
- Silviu Ardelean. pre vs. post increment operator – benchmark.
Краткий вывод такой. Для Release-версии приложения разницы нет. Для Debug-версии разница есть, причём существенная. Поэтому рекомендация актуальна и её стоит придерживаться. Часто полезно, чтобы и Debug-версия работала быстро.
Рассмотрим пример срабатывания анализатора:
void ServiceManagerPrivate::loadServiceLibs()
{
auto end = servicesLoaderMap.end();
for(auto slm = servicesLoaderMap.begin(); slm !=end; slm++ ){
try{
ServiceFactory* factory=((*slm).second->getFactory());
servicesMap[factory->serviceName()] = factory;
}catch (std::runtime_error& e){
BROWSER_LOGD(e.what() );
}
}
}PVS-Studio: V803 Decreased performance. In case 'slm' is iterator it's more effective to use prefix form of increment. Replace iterator++ with ++iterator. ServiceManager.cpp 67
Будет полезно заменить slm++ на ++slm. Конечно, одна замена ничего не даст и к этому надо подходить систематически. Для проверенного мною кода анализатор выдал 103 рекомендации. Это значит, что при желании можно будет модифицировать в Tizen около 3000 мест. Благодаря таким изменениям, отладочная версия будет работать капельку быстрее.
V804: The 'Foo' function is called twice in the specified expression to calculate length of the same string
Встречаются ситуации, когда в коде два или более раз вычисляется длина одной и той же строки. В отладочной версии — это однозначное замедление работы программы, особенно если код выполняется много раз. Как будет обстоять дело в Release-версии неизвестно, но высока вероятность, что компилятор не догадается объединить насколько вызовов функции strlen в один вызов.
Рассмотрим пример кода.
static isc_result_t
buildfilename(...., const char *directory, ....)
{
....
if (strlen(directory) > 0U &&
directory[strlen(directory) - 1] != '/')
isc_buffer_putstr(out, "/");
....
}PVS-Studio: V804 Decreased performance. The 'strlen' function is called twice in the specified expression to calculate length of the same string. dst_api.c 1832
Два раза вычисляется длина названия директории. Кстати, для этого кода ещё будет выдано предупреждение V805, но про это мы поговорим ниже.
Этот код можно улучшить, добавив временную переменную для хранения длины:
const size_t directory_len = strlen(directory);
if (directory_len > 0U &&
directory[directory_len - 1] != '/')
isc_buffer_putstr(out, "/");Я не говорю, что так надо обязательно поступить. Сам я думаю, что данный код можно отставить таким, какой он есть. Мне просто нужен демонстрационный пример. То, что конкретно здесь правка кода не даст выигрыша, ничего не значит. Могут встретиться места, где такая оптимизация может существенно ускорить работу циклов, в которых идёт обработка строк.
Для проверенного кода анализатор выдал 20 предупреждений. Общее прогнозируемое количество предупреждений 600.
V805: It is inefficient to identify an empty string by using 'strlen(str) > 0' construct
Вернёмся к коду, рассмотренному в предыдущем разделе.
if (strlen(directory) > 0U &&
directory[strlen(directory) - 1] != '/')PVS-Studio: V805 Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'. dst_api.c 1832
Помимо сохранения длины строки в промежуточную переменную, существует и другой способ оптимизировать код. Первый вызов strlen нужен для того, чтобы проверить, пустая строка или нет. На самом деле использование функции strlen для этой цели является избыточной операцией, ведь достаточно проверить только значение первого байта строки. Поэтому можно оптимизировать код так:
if (*directory != '\0' &&
directory[strlen(directory) - 1] != '/')Или так:
if (directory[0] &&
directory[strlen(directory) - 1] != '/')И так далее. Как вы понимаете, вариантов как можно изменить код, много. Не важно, как записана проверка, главное, что не надо проходить по всем символам строки, чтобы понять пустая она или нет. Конечно, компилятор может угадать замысел программиста и соптимизировать проверку в Release версии, но заранее рассчитывать на такой подарок не стоит.
Ещё один пример:
V805 Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) != 0' construct. A more efficient way is to check: str[0] != '\0'. bt-util.c 376
void _bt_util_set_phone_name(void)
{
char *phone_name = NULL;
char *ptr = NULL;
phone_name = vconf_get_str(VCONFKEY_SETAPPL_DEVICE_NAME_STR);
if (!phone_name)
return;
if (strlen(phone_name) != 0) { // <=
if (!g_utf8_validate(phone_name, -1, (const char **)&ptr))
*ptr = '\0';
bt_adapter_set_name(phone_name);
}
free(phone_name);
}PVS-Studio: V805 Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) != 0' construct. A more efficient way is to check: str[0] != '\0'. bt-util.c 376
Ничего особенного в этом коде нет. С его помощью я хотел специально продемонстрировать, что это типовой и крайне распространённый способ проверять, пустая строка или нет. На самом деле я даже удивлён, почему в Си нет какой-то стандартной функции или макроса для выявления пустой строки. Вы даже не представляете, как много таких неэффективных проверок живёт в наших программах. Сейчас я вас шокирую.
В проверенной мною части Tizen анализатор PVS-Studio выявил 415 мест, где используется функция strlen или её аналог, чтобы определить пустая строка или нет.
Соответственно прогнозируемое количество предупреждений для всего проекта Tizen составляет 12450.
Представляете, как часто микропроцессор гоняет бестолковые циклы для поиска терминального нуля и забивает кэши данными, которые ему, возможно, и не пригодятся.
На мой взгляд, есть смысл избавляться от таких неэффективных вызовов функций strlen. Можно написать:
- if (*phone_name)
- if (*phone_name != '\0')
- if (phone_name[0])
- if (phone_name[0] != '\0')
Но мне такие варианты не нравятся, так как такой код сложно читать. Намного лучше в Си сделать специальный макрос, а в Си++ inline-функцию. Такой код будет читаться намного лучше:
if (is_empty_str(phone_name))Ещё раз повторю, что для меня странно, что за все годы так и не был создан универсальный стандартный метод проверки Си-строк на пустоту. На мой взгляд, это порождает во многих проектах огромное количество кода, который мог бы работать немного быстрее. Согласитесь, 12450 неэффективных проверок заслуживают внимания.
V806: The expression of strlen(MyStr.c_str()) kind can be rewritten as MyStr.length()
Если предупреждений V805 было огромное количество, то для проверенных проектов анализатор выдал всего 2 предупреждения V806. Давайте взглянем на одну из этих редких птиц:
static void
panel_slot_forward_key_event (
int context, const KeyEvent &key, bool remote_mode)
{
....
if (strlen(key.get_key_string().c_str()) >= 116)
return;
....
}PVS-Studio: V806 Decreased performance. The expression of strlen(MyStr.c_str()) kind can be rewritten as MyStr.length(). wayland_panel_agent_module.cpp 2511
Обычно такая ситуация возникает после рефакторинга старого C-кода, который превратился в Си++ код. Длина строки в переменной типа std::string определяется с помощью strlen. Способ явно неэффективный, да ещё и усложняющий код. Нормальный способ:
if (key.get_key_string().length() >= 116)
return;Код стал короче и быстрее. Ожидаемое количество предупреждений в проекте Tizen: 60.
V807: Consider creating a pointer/reference to avoid using the same expression repeatedly
Иногда в программах можно встретить выражение, включающее в себя много операторов "->" и ".". Например, что-то подобное:
To()->be.or->not().to()->be();В России это называют «программирование с использованием паровозика». Я не знаю, есть ли англоязычный аналог такому стилю кодирования, но думаю в любом случае понятно, почему здесь упоминается поезд.
Такой код считается плохим, и в книгах, посвященных качеству кода, его рекомендуют избегать. Всё ещё хуже, если такие «паровозики» повторяются многократно. Во-первых, они загромождают текст программы, а во-вторых могут снижать производительность программы. Рассмотрим один из таких случаев:

PVS-Studio: V807 Decreased performance. Consider creating a reference to avoid using the same expression repeatedly. ImageObject.cpp 262
На мой взгляд, этот код будет выглядеть лучше, если его написать так:
for (....) {
auto &keypoint = obj.__features.__objectKeypoints[keypointNum];
os << keypoint.pt.x << ' ';
os << keypoint.pt.y << ' ';
os << keypoint.size << ' ';
os << keypoint.response << ' ';
os << keypoint.angle << ' ';
os << keypoint.octave << ' ';
os << keypoint.class_id << '\n';
}Будет ли такой код выполняться быстрее? Нет. По сравнению с медленным выводом данных в поток, все остальные операции несущественны, даже если мы говорим об отладочной версии.
Зато второй вариант кода короче, его легче читать и сопровождать.
Как я уже сказал, здесь мы не получим выигрыша производительности. Однако, могут найтись места, где подобная оптимизация может быть полезной. Такое случается, если в «паровозике» встречаются вызовы медленных длинных функций. В таких местах компилятор не может догадаться как выполнить оптимизацию и получается огромное количество избыточных вызовов функций.
Всего анализатор указал на 93 фрагмента кода. Прогнозируемое общее количество предупреждений равно 2700.
V808: An array/object was declared but was not utilized
Следующая диагностика весьма интересна. Она выявляет переменные и массивы, которые не используются. Чаще всего, такие артефакты возникают в процессе рефакторинга, когда забывают удалить объявление более неиспользуемой переменной.
Неиспользуемая переменная также может свидетельствовать о логической ошибке в программе, но, по моему опыту, такое бывает редко.
Анализатор выдает предупреждение в следующих случаях:
- Создается, но не используется массив. Это значит, что функция использует больше стековой памяти, чем необходимо. Во-первых, это может способствовать ситуации, когда произойдет переполнение стека. Во-вторых, это может снизить эффективность работы кэша в микропроцессоре.
- Создаются, но не используются объекты классов. Анализатор предупреждает не обо всех объектах, а о тех, которые гарантированно нет смысла создавать и при этом не использовать. Например, std::string или CString. Создание и уничтожение таких объектов — пустая трата процессорного времени и стека.
Отдельно отмечу, что анализатор не ругается на лишние переменные, например, типа float или char. В этом случае получается невероятное количество неинтересных ложных срабатываний. Таких ситуаций очень много в коде, где широко используются макросы или директивы препроцессора #if..#else..#endif. Причем, эти лишние переменные безобидны, так как компилятор удалит их в процессе оптимизации.
Давайте посмотрим пару примеров предупреждений, выданных для кода Tizen:
void CynaraAdmin::userRemove(uid_t uid)
{
std::vector<CynaraAdminPolicy> policies;
std::string user =
std::to_string(static_cast<unsigned int>(uid));
emptyBucket(Buckets.at(Bucket::PRIVACY_MANAGER),true,
CYNARA_ADMIN_ANY, user, CYNARA_ADMIN_ANY);
}PVS-Studio: V808 'policies' object of 'vector' type was created but was not utilized. cynara.cpp 499
Переменная policies не используется. Её нужно просто удалить.
А теперь более подозрительный код:
static void _focused(int id, void *data, Evas_Object *obj,
Elm_Object_Item *item)
{
struct menumgr *m = (struct menumgr *)data;
Elm_Focus_Direction focus_dir[] = {
ELM_FOCUS_LEFT, ELM_FOCUS_RIGHT, ELM_FOCUS_UP, ELM_FOCUS_DOWN
};
int i;
Evas_Object *neighbour;
if (!obj || !m)
return;
if (m->info[id] && m->info[id]->focused)
m->info[id]->focused(m->data, id);
for (i = 0; i < sizeof(focus_dir) / sizeof(focus_dir[0]); ++i)
{
neighbour = elm_object_focus_next_object_get(obj, i);
evas_object_stack_above(obj, neighbour);
}
}PVS-Studio: V808 'focus_dir' array was declared but was not utilized. menumgr.c 110
Массив focus_dir не используется. Это странно, и возможно здесь есть какая-то ошибка, а возможно и нет. Мне сложно дать ответ, не приступив к серьезному изучению кода.
Для проверенного кода анализатор выдал 30 предупреждений. Прогнозируемое количество предупреждений для всего кода равно 900.
V809: The 'if (ptr != NULL)' check can be removed
Мы добрались до диагностики, которая даёт больше всего срабатываний. Очень часто люди пишут вот такой код:
if (P)
free(P);
if (Q)
delete Q;Этот код избыточен. Функция free и оператор delete совершенно корректно работают с нулевыми указателями.
Код можно упростить:
free(P);
delete Q;Лишняя проверка ничего не даёт и только замедляет код.
Здесь мне могут возразить, что такой код как раз быстрее. Если указатель нулевой, то не надо заходить внутрь функции free или оператора delete и делать проверку где-то там внутри них.
Я не согласен. Большинство кода написано из расчёта, что указатели не нулевые. Нулевой указатель это обычно особая/аварийная ситуация, которая возникает редко. Поэтому почти всегда, когда мы обращаемся к free/delete, то передаём туда ненулевой указатель. А раз так, то предварительная проверка вредна, а заодно загромождает код.
В качестве примера рассмотрим вот такую функцию:
lwres_freeaddrinfo(struct addrinfo *ai) {
struct addrinfo *ai_next;
while (ai != NULL) {
ai_next = ai->ai_next;
if (ai->ai_addr != NULL)
free(ai->ai_addr);
if (ai->ai_canonname)
free(ai->ai_canonname);
free(ai);
ai = ai_next;
}
}Здесь сразу две лишних проверки, о которых информирует анализатор:
- V809 Verifying that a pointer value is not NULL is not required. The 'if (ai->ai_addr != NULL)' check can be removed. getaddrinfo.c 694
- V809 Verifying that a pointer value is not NULL is not required. The 'if (ai->ai_canonname)' check can be removed. getaddrinfo.c 696
Давайте удалим избыточные проверки:
lwres_freeaddrinfo(struct addrinfo *ai) {
struct addrinfo *ai_next;
while (ai != NULL) {
ai_next = ai->ai_next;
free(ai->ai_addr);
free(ai->ai_canonname);
free(ai);
ai = ai_next;
}
}На мой взгляд, код стал намного проще и красивее. Отличный пример рефакторинга.
В проверенных мною проектах анализатор выявил 620 лишних проверок!

Это значит, что для всех проектов, анализатор выдаст около 18600 предупреждений! Ого! Вы только представьте, можно спокойно удалить 18600 операторов if.
V810: The 'A' function was called several times with identical arguments
#define TIZEN_USER_CONTENT_PATH tzplatform_getenv(TZ_USER_CONTENT)
int _media_content_rollback_path(const char *path, char *replace_path)
{
....
if (strncmp(path, TIZEN_USER_CONTENT_PATH,
strlen(TIZEN_USER_CONTENT_PATH)) == 0) {
....
}V810 Decreased performance. The 'tzplatform_getenv(TZ_USER_CONTENT)' function was called several times with identical arguments. The result should possibly be saved to a temporary variable, which then could be used while calling the 'strncmp' function. media_util_private.c 328
Анализатор выявляет код, в котором присутствует вызов функции, которой в качестве фактических аргументов передаётся результат нескольких вызовов одной и той же функции. Причем эти используемые функции вызываются с одинаковыми аргументами. Если эти функции работают медленно, то код можно оптимизировать, поместив результат в промежуточную переменную.
В приведённом выше коде дважды вызывается функция tzplatform_getenv с одинаковым фактическим аргументом.
Для проверенного кода было всего 7 срабатываний и все они показались мне неинтересными. Поэтому считать ничего не будем.
V811: Excessive type casting: string -> char * -> string
Анализатор выявляет ситуации, когда строки копируются неэффективным способом. Рассмотрим пример:
std::string A = Foo();
std::string B(A.c_str());Строка B создаётся с помощью конструктора, принимающего на вход простой указатель на строку, заканчивающуюся терминальным нулём. Прежде чем будет выделена память под буфер, требуется узнать длину строки A. Для вычисления длины строки придётся пройтись по всем её символам. Это неэффективно, так как на самом деле длину можно было сразу получить из строки A. Код лучше переписать так:
std::string A = Foo();
std::string B(A);Этот код не только более быстрый, но и более короткий.
Теперь рассмотрим пример срабатывания диагностики на коде Tizen:
void PasswordUI::changeState(PasswordState state)
{
....
std::string text = "";
....
switch (m_state) {
case PasswordState::ConfirmPassword:
text = TabTranslations::instance().ConfirmPassword.c_str();
m_naviframe->setTitle("IDS_BR_HEADER_CONFIRM_PASSWORD_ABB2");
break;
....
}PVS-Studio: V811 Decreased performance. Excessive type casting: string -> char * -> string. Consider inspecting the expression. PasswordUI.cpp 242
Для проверенных мною проектов анализатор выдал 41 предупреждение. Это значит, можно ожидать что анализатор выявит в проекте Tizen 1230 таких неэффективных копирований строк.
V812: Ineffective use of the 'count' function
Для проверенных проектов не было выдано ни одного предупреждения V812, поэтому только кратко поясню что это.
Результат вызова функций count или count_if из стандартной библиотеки сравнивается с нулем. Это может быть потенциально медленно, потому что этим функциям необходимо обработать весь контейнер, чтобы посчитать количество нужных элементов. Если значение, которое вернула функция, сравнивается с нулем, то нам интересно, есть ли хотя бы 1 такой элемент или их нет совсем. Проверку, что элемент присутствует/отсутствует в контейнере более эффективно можно выполнить, используя функцию find или find_if.
Неэффективно:
void foo(const std::multiset<int> &ms)
{
if (ms.count(10) != 0) Foo();
}Эффективно:
void foo(const std::multiset<int> &ms)
{
if (ms.find(10) != ms.end()) Foo();
}V813: The argument should probably be rendered as a constant pointer/reference
Аргумент, представляющий собой структуру или класс, передается в функцию по значению. Анализатор, проверяя тело функции, пришел к выводу, что этот аргумент не модифицируется. С целью оптимизации такой аргумент можно передавать как константную ссылку. Это может ускорить выполнение программы, поскольку при вызове функции будет скопирован только адрес, а не весь объект класса.
Диагностика V813 схожа с V801, но в данном случае переменная не отмечена как const. Это означает, что анализатору предстоит самому попытаться разобраться, модифицируется переменная в функции или нет. Если модифицируется, то предупреждение выдавать не надо. Изредка бывают ложные срабатывания, но в целом диагностика работает хорошо.
Рассмотрим пример функции, обнаруженной с помощью этой диагностики.
void
addDescriptions(std::vector<std::pair<int, std::string>> toAdd)
{
if (m_descCount + toAdd.size() > MAX_POLICY_DESCRIPTIONS) {
throw std::length_error("Descriptions count would exceed "
+ std::to_string(MAX_POLICY_DESCRIPTIONS));
}
auto addDesc = [] (DescrType **desc, int result,
const std::string &name)
{
(*desc) = static_cast<DescrType *>(malloc(sizeof(DescrType)));
(*desc)->result = result;
(*desc)->name = strdup(name.data());
};
for (const auto &it : toAdd) {
addDesc(m_policyDescs + m_descCount, it.first, it.second);
++m_descCount;
}
m_policyDescs[m_descCount] = nullptr;
}PVS-Studio: V813 Decreased performance. The 'toAdd' argument should probably be rendered as a constant reference. CyadCommandlineDispatcherTest.h 63
По значению передаётся массив типа std::vector<std::pair<int, std::string>>. Согласитесь, что скопировать такой массив — очень дорогая операция.
При этом, массив используется только для чтения. Намного лучше будет объявить функцию так:
void addDescriptions(
const std::vector<std::pair<int, std::string>> &toAdd)Большинство случаев, конечно, более безобидны. Рассмотрим такой пример:
void TabService::errorPrint(std::string method) const
{
int error_code = bp_tab_adaptor_get_errorcode();
BROWSER_LOGE("%s error: %d (%s)", method.c_str(), error_code,
tools::capiWebError::tabErrorToString(error_code).c_str());
}PVS-Studio: V813 Decreased performance. The 'method' argument should probably be rendered as a constant reference. TabService.cpp 67
Здесь всего лишь создаётся одна лишняя строка. Не страшно, но всё равно этот код заставляет грустить программиста-перфекциониста.
Для проверенных мною проектов анализатор выдал 303 предупреждения. Таким образом, расчётное значение для проекта Tizen составляет 9090 предупреждений. Думаю, среди них может найтись немало мест, которые действительно заслуживают чтобы их оптимизировали.
V814: The 'strlen' function was called multiple times inside the body of a loop
Читатель, наверное, уже заметил, что в основном микрооптимизации связаны со строками. Причина заключается в том, что большая часть этих диагностик разработана по предложению одного клиента, для которого важна эффективная работа со строками. Диагностика, которую мы сейчас рассмотрим, не является исключением и также связана со строками.
Анализатор выявляет циклы, в которых осуществляется вызов функции strlen(S) или аналогичной ей. При этом строка S не меняется, и значит, её длину можно вычислить заранее.
Рассмотрим пару примеров срабатывания этой диагностики. Пример 1.
#define SETTING_FONT_PRELOAD_FONT_PATH "/usr/share/fonts"
static Eina_List *_get_available_font_list()
{
....
for (j = 0; j < fs->nfont; j++) {
FcChar8 *family = NULL;
FcChar8 *file = NULL;
FcChar8 *lang = NULL;
int id = 0;
if (FcPatternGetString(fs->fonts[j], FC_FILE, 0, &file)
== FcResultMatch)
{
int preload_path_len = strlen(SETTING_FONT_PRELOAD_FONT_PATH);
....
}PVS-Studio: V814 Decreased performance. The 'strlen' function was called multiple times inside the body of a loop. setting-display.c 1185
Сколько будет итераций цикла, столько раз мы будем считать длину строки "/usr/share/fonts". Есть большой шанс, что компилятор догадается как соптимизировать этот код. Однако, нет гарантии, что выполнить оптимизацию получится, кроме того, отладочный код в любом случае будет работать медленнее чем мог бы.
Улучшить код очень просто: достаточно поместить строчку вычисления длины строки до начала цикла.
Второй пример.
static void
BN_fromhex(BIGNUM *b, const char *str) {
static const char hexdigits[] = "0123456789abcdef";
unsigned char data[512];
unsigned int i;
BIGNUM *out;
RUNTIME_CHECK(strlen(str) < 1024U && strlen(str) % 2 == 0U);
for (i = 0; i < strlen(str); i += 2) {
const char *s;
unsigned int high, low;
s = strchr(hexdigits, tolower((unsigned char)str[i]));
RUNTIME_CHECK(s != NULL);
high = (unsigned int)(s - hexdigits);
s = strchr(hexdigits, tolower((unsigned char)str[i + 1]));
RUNTIME_CHECK(s != NULL);
low = (unsigned int)(s - hexdigits);
data[i/2] = (unsigned char)((high << 4) + low);
}
out = BN_bin2bn(data, strlen(str)/2, b);
RUNTIME_CHECK(out != NULL);
}PVS-Studio: V814 Decreased performance. Calls to the 'strlen' function have being made multiple times when a condition for the loop's continuation was calculated. openssldh_link.c 620
Анализатору не нравится вот эта строка:
for (i = 0; i < strlen(str); i += 2) {На каждой итерации цикла будет происходить вычисление длины строки, переданной в качестве аргумента. Перфекционист в шоке.
Примечание. Как правило, такой код пишут люди, работавшие ранее с языком Pascal (средой Delphi). В Pascal граница окончания цикла вычисляется один раз, поэтому, там подобный код уместен и распространён. Подробности (см. главу «18. Знания, полученные при работе с одним языком, не всегда применимы к другому языку»).
Кстати, на оптимизацию со стороны компилятора здесь тоже особенно надеяться не стоит. Указатель на строку поступил извне. Да, внутри функции мы не можем поменять строку (она ведь const char *). Но это не значит, что её не может поменять кто-то извне. Вдруг это строку меняет, например, функция strchr. Мало ли…
Возможно, не всем понятно, как это константная ссылка может меняться. Сейчас поясню.
int value = 1;
void Foo() { value = 2; }
void Example(const int &A)
{
printf("%i\n", A);
Foo();
printf("%i\n", A);
}
int main()
{
Example(value);
return 0;
}Хотя аргумент A имеет тип const int &, в начале будет напечатано число 1, а затем 2.
Вот так. Всё дело в том, что const — это часть интерфейса доступа, которая говорит, что нельзя менять переменную. Но это не значит, что переменная вообще не меняется.
Оптимизированный вариант кода:
static void
BN_fromhex(BIGNUM *b, const char *str) {
static const char hexdigits[] = "0123456789abcdef";
unsigned char data[512];
unsigned int i;
BIGNUM *out;
const size_t strLen = strlen(str);
RUNTIME_CHECK(strLen < 1024U && strLen % 2 == 0U);
for (i = 0; i < strLen; i += 2) {
const char *s;
unsigned int high, low;
s = strchr(hexdigits, tolower((unsigned char)str[i]));
RUNTIME_CHECK(s != NULL);
high = (unsigned int)(s - hexdigits);
s = strchr(hexdigits, tolower((unsigned char)str[i + 1]));
RUNTIME_CHECK(s != NULL);
low = (unsigned int)(s - hexdigits);
data[i/2] = (unsigned char)((high << 4) + low);
}
out = BN_bin2bn(data, strLen / 2, b);
RUNTIME_CHECK(out != NULL);
}В проверенных проектах анализатор выявил 112 использований функции strlen в циклах, которые можно на самом деле вызывать однократно. Предположительное общее количество предупреждений составит 3360.
У читателя уже чешутся руки взять анализатор PVS-Studio и начать улучшать мир? Мы только за! Скачать пробную версию анализатора можно здесь.
V815: Consider replacing the expression 'AA' with 'BB'
В классах строк реализованы операторы, которые позволяют более эффективно очистить строку или проверить, что строка является пустой. Имеется в виду, что код:
void f(const std::string &A, std::string &B)
{
if (A != "")
B = "";
}лучше заменить на:
void f(const std::string &A, std::string &B)
{
if (!A.empty())
B.clear();
}Сможет компилятор в Release-версии оптимизировать код и построить для первого и второго варианта функции идентичный бинарный код?
Я поэкспериментировал с компилятором, который был под рукой, а именно с Visual C++ (Visual Studio 2015). Для проверки на пустую строку он построил идентичный код. А вот оптимизировать первый вариант очистки строки он не смог, и в двоичном коде остался вызов функции std::basic_string::assign.

Пример срабатывания диагностики на коде Tizen:
services::SharedBookmarkFolder
FoldersStorage::getFolder(unsigned int id)
{
BROWSER_LOGD("[%s:%d] ", __PRETTY_FUNCTION__, __LINE__);
std::string name = getFolderName(id);
....
if (name != "")
folder = std::make_shared<services::BookmarkFolder>(
id, name, count);
return folder;
}PVS-Studio: V815 Decreased performance. Consider replacing the expression 'name != ""' with '!name.empty()'. FoldersStorage.cpp 134
Это был пример неэффективной проверки того, что строка не пустая. У меня есть пример и неэффективной очистки строки:
....
std::string buffer;
....
bool GpsNmeaSource::tryParse(string data)
{
....
buffer = "";
....
}PVS-Studio: V815 Decreased performance. Consider replacing the expression 'buffer = ""' with 'buffer.clear()'. gpsnmea.cpp 709
Я согласен, что диагностика спорная. Некоторым программистам, например, нравится проверять, что строка пустая с помощью выражения (str == "") и нравится очищать строки с помощью присваивания. Они считают, что такой код более понятен и легко читается. Мне сложно что-то возразить, тем более, что мой эксперимент показал, что проверка (str == "") оптимизируется компилятором в Release версии.
Стоит использовать описанные микрооптимизации или нет, решать программисту. Если он считает, что они бессмысленны, то диагностику можно просто отключить. Тем не менее, смысл в ней существует, так как создавалась она по заказу нашего пользователя, а значит она нужна людям.
Всего анализатор PVS-Studio выдал 63 предупреждения этого типа для проверенных проектов. Если разработчики посчитают эти предупреждения заслуживающими внимания, то всего их будет около 1890.
V816: It is more efficient to catch exception by reference rather than by value
Исключение эффективнее перехватывать не по значению, а по ссылке. Заодно это позволяет избежать некоторых других ошибок. Например, так можно избежать проблемы «срезки» (slice). Однако, эта тема выходит за рамки описания данной диагностики. Для борьбы со срезкой существует диагностика V746.
Пример срабатывания диагностики:
std::string make_message(const char *fmt, ...)
{
....
try {
p = new char[size];
} catch (std::bad_alloc) {
Logger::getInstance().log("Error while allocating memory!!");
return std::string();
}
....
}PVS-Studio: V816 It is more efficient to catch exception by reference rather than by value. LoggerTools.cpp 37
Лучше написать:
} catch (std::bad_alloc &) {Я насчитал 84 срабатывания анализатора для проверенного кода. Прогноз: около 2500 предупреждений.
V817: It is more efficient to search for 'X' character rather than a string
Неэффективный поиск одиночных символов в строках. Проще всего будет пояснить диагностику, рассмотрев 2 случая. Первый:
void URIEntry::_uri_entry_editing_changed_user(void* data,
Evas_Object*, void*)
{
....
if ((entry.find("http://") == 0)
|| (entry.find("https://") == 0)
|| (entry.find(".") != std::string::npos)) { // <=
self->setDocIcon();
} else {
....
}PVS-Studio: V817 It is more efficient to seek '.' character rather than a string. URIEntry.cpp 211
Точку лучше искать как символ, а не как подстроку. Т.е. более эффективным кодом будет:
|| (entry.find('.') != std::string::npos)) {И ещё одна схожая ситуация:
char *_gl_info__detail_title_get(
void *data, Evas_Object *obj, const char *part)
{
....
p = strstr(szSerialNum, ",");
....
}PVS-Studio: V817 It is more efficient to seek ',' character rather than a string. setting-info.c 511
Для поиска запятой лучше воспользоваться функцией strchr:
p = strchr(szSerialNum, ',');В проверенных мною проектах PVS-Studio обнаружил 37 мест, где неэффективно ищутся символы в строке. Прогноз для всего проекта Tizen: 1110.
Новые диагностики
В момент, когда пишется эта статья, в PVS-Studio версии 6.16 появились новые диагностики V818, V819, V820. Когда я изучал проект Tizen эти диагностики были как раз в разработке и поэтому я не могу привести никаких примеров их срабатывания. Вы можете ознакомиться с этими диагностиками, перейдя по ссылкам:
- V818. It is more efficient to use an initialization list rather than an assignment operator.
- V819. Decreased performance. Memory is allocated and released multiple times inside the loop body.
- V820. The variable is not used after copying. Copying can be replaced with move/swap for optimization.
Итоги
Надеюсь, благодаря этой статье, мои читатели познакомились с набором диагностик PVS-Studio, о которых мы практически никогда не упоминаем. Возможно, для кого-то эти диагностики окажутся полезными. Сейчас в основном эти диагностики ориентированы на поиск неэффективных способов работы со строками (std::string, CString и т.д.). Однако, мы будем постепенно включать в этот набор диагностики для выявления медленного кода иной природы.
Давайте ради интереса подсчитаем количество сообщений, которые на мой взгляд могут быть полезны проекту Tizen и используемым в нём библиотекам.
- V801 — 2280
- V803 — 3000
- V804 — 600
- V805 — 12450
- V806 — 60
- V807 — 2700
- V808 — 900
- V809 — 18600
- V811 — 1230
- V813 — 9090
- V814 — 3360
- V815 — 1890
- V816 — 2500
- V817 — 1110
ИТОГО: около 59000 предупреждений
Я вовсе не призываю начинать изучать все эти предупреждения и править код. Я понимаю, что подобные правки не повысят хоть сколько-то заметно производительность операционной системы. Более того, если делать так много правок, есть высокий риск случайно что-то сломать, допустив опечатку.
И тем не менее я считаю эти предупреждения анализатора полезными. Их разумное использование позволит писать более простой и эффективный код.
Моё мнение: нет смысла трогать старый код. Однако, стоит разрабатывать новый код уже с учётом этих диагностик микрооптимизаций. Эта статья хорошо показывает, что можно написать код чуть лучше в очень многих местах.
Заключение
Предлагаем установить PVS-Studio и попробовать проверить свои проекты. Под Windows вам будет сразу доступна демонстрационная версия. Чтобы попробовать Linux версию, напишите нам, и мы отправим вам временный лицензионный ключ.
Спасибо всем за внимание.
Дополнительные рекомендуемые материалы
- Андрей Карпов. 27000 ошибок в операционной системе Tizen.
- Сергей Васильев. Как PVS-Studio может помочь в поиске уязвимостей?
- Андрей Карпов. Предоставляем анализатор PVS-Studio экспертам безопасности.
- Андрей Карпов. Команда PVS-Studio: аудит кода и другие услуги.
- Сергей Хренов. PVS-Studio как плагин для SonarQube.
- Екатерина Миловидова. Баг месяца: эстафета от PC-Lint к PVS-Studio.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. Exploring Microoptimizations Using Tizen Code as an Example
Прочитали статью и есть вопрос?
Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: Ответы на вопросы читателей статей про PVS-Studio, версия 2015. Пожалуйста, ознакомьтесь со списком.
Поделиться с друзьями
Комментарии (9)

kafeman
17.07.2017 12:40+2Любителям экономить на спичках могу еще посоветовать явно указывать компилятору на маловероятные ветки в условиях. Например, в GCC для этого есть __builtin_expect:
if (__builtin_expect(smth == NULL, 0)) return EINVAL; if (__builtin_expect(user_id != owner_id, 0)) return EACCES; return 0;
Приведенный выше код GCC скомпилирует как:
if (smth != NULL) { if (user_id == owner_id) { return 0; } return EACCES; } return EINVAL;
В приведенных вами фрагментах кода очень много таких мест, где условия идут в «неверном» порядке.kafeman
17.07.2017 12:48+2Макрос:
#if defined(__GNUC__) && (__GNUC__ > 2) #define likely(expr) (__builtin_expect((expr), 1)) #define unlikely(expr) (__builtin_expect((expr), 0)) #else #define likely(expr) (expr) #define unlikely(expr) (expr) #endif
В коде:
if (unlikely(smth == NULL)) { /* ... */ }
mayorovp
17.07.2017 14:48Осторожнее с диагностикой V813 — замена значения на константную ссылку может поломать функцию если ее реализация где-то полагается на тот факт, что разные переменные указывают на разные участки памяти.


sborisov
Интересно, помогает ли с оптимизациями этот статический анализатор
Можно было бы попробовать собрать и загрузить Tizen для статического анализа coverity и посмотреть, что выдаст этот анализатор.
Andrey2008
Интересно. Попробуйте.
sborisov
Спасибо. Тогда бы надо пройтись по всем, чтобы была сводная таблица
Andrey2008
Непременно. Рад, что Вы готовы провести такое сравнение. Желаю удачи.