
Забыл сказать самое главное, можно сказать что это моя проба пера тут. И так поехали.
Если в нашем приложении больше 5 таблиц, то уже было бы не плохо использовать какой-нибудь инструмент для визуального проектирования архитектуры БД. Поскольку для меня это хобби, то и использую я абсолютно бесплатный инструмент под названием Oracle SQL Developer Data Modeler (скачать его можно тут).

Данная программа позволяет визуально рисовать таблицы, и строить взаимосвязи с ними. Многие ошибки проектирования архитектуры БД можно избежать при таком подходе проектирования (это я уже вам говорю как профессиональный программист БД). Выглядит это примерно так:
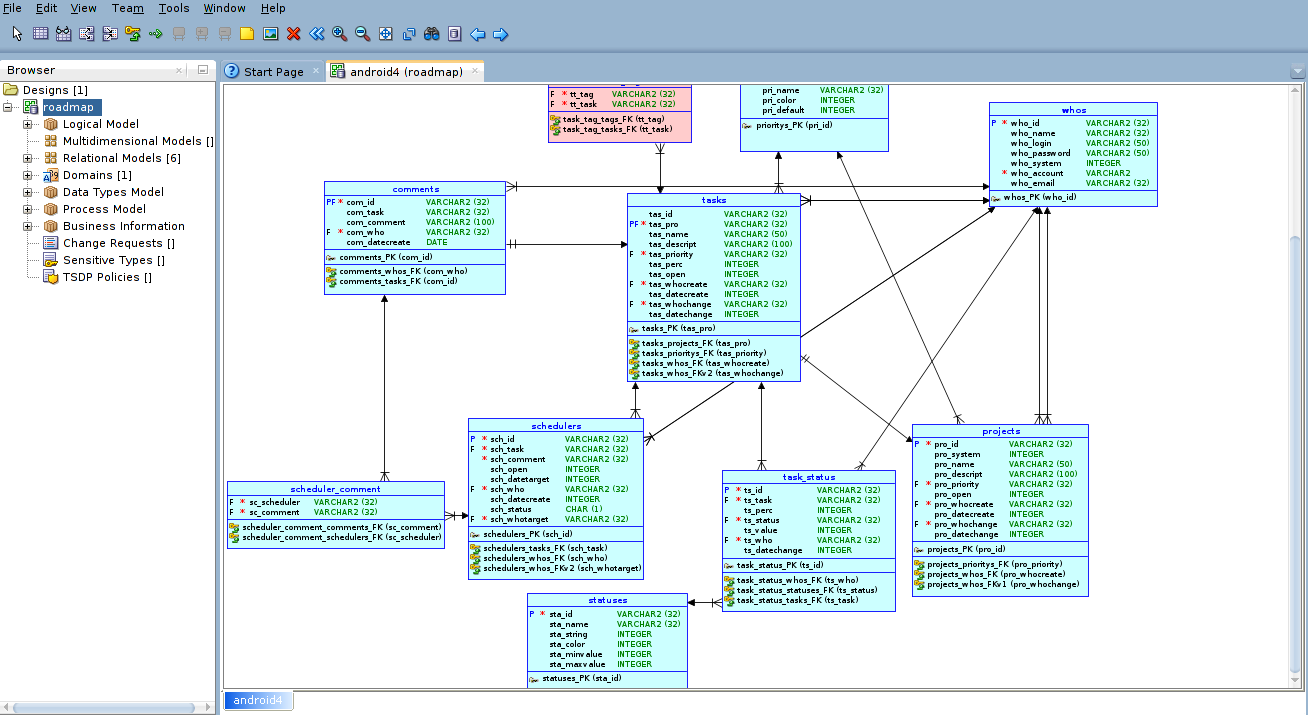
Спроектировав саму архитектуру, приступаем к более нудной части, заключающийся в созданий sql кода для создания таблиц. Для помощи в этом вопросе, я уже использую инструмент под названием SQLiteStudio (его в свою очередь можно скачать тут тут).
Данный инструмент является аналогом таких известных продуктов как SQL Naviagator, Toad etc. Но как следует из названия, заточен он под работу с SQLite. Он позволяет визуально создать БД и получить DDL код создаваемых таблиц. Кстати, он также позволяет создавать представления (View), которые вы тоже при желании можете использовать в своем приложении. Не знаю насколько правильный подход использования представлений в программах для Android, но в одном из своих приложений я использовал их.

Собственно говоря я больше не каких сторонних инструментов не использую, и дальше начинается магия с Android Studio. Как я уже писал выше, если начать внедрять SQL код в Java код, то на выходе мы получим плохочитаемый, а значит и плохо расширяемый код. Поэтому я выношу все SQL инструкции во внешние файлы, которые у меня находятся в директории assets. В Android Studio выглядит это примерно так:

Теперь давайте посмотрим на код внутри моего DBHelper который я использую в своих проектах. Сначала переменные класса и конструктор (тут без каких либо неожиданностей):
private static final String TAG = "RoadMap4.DBHelper";
String mDb = "db_";
String mData = "data_";
Context mContext;
int mVersion;
public DBHelper(Context context, String name, int version) {
super(context, name, null, version);
mContext = context;
mVersion = version;
}
Теперь метод onCreate и тут становится уже интереснее:
@Override
public void onCreate(SQLiteDatabase db) {
ArrayList<String> tables = getSQLTables();
for (String table: tables){
db.execSQL(table);
}
ArrayList<HashMap<String, ContentValues>> dataSQL = getSQLDatas();
for (HashMap<String, ContentValues> hm: dataSQL){
for (String table: hm.keySet()){
Log.d(TAG, "insert into " + table + " " + hm.get(table));
long rowId = db.insert(table, null, hm.get(table));
}
}
}
Логически он разделен на два цикла, в первом цикле я получаю список SQL — инструкций для создания БД и затем выполняю их, во втором цикле я уже заполняю созданные ранее таблицы начальными данными. И так, шаг первый:
private ArrayList<String> getSQLTables() {
ArrayList<String> tables = new ArrayList<>();
ArrayList<String> files = new ArrayList<>();
AssetManager assetManager = mContext.getAssets();
String dir = mDb + mVersion;
try {
String[] listFiles = assetManager.list(dir);
for (String file: listFiles){
files.add(file);
}
Collections.sort(files, new QueryFilesComparator());
BufferedReader bufferedReader;
String query;
String line;
for (String file: files){
Log.d(TAG, "file db is " + file);
bufferedReader = new BufferedReader(new InputStreamReader(assetManager.open(dir + "/" + file)));
query = "";
while ((line = bufferedReader.readLine()) != null){
query = query + line;
}
bufferedReader.close();
tables.add(query);
}
} catch (IOException e) {
e.printStackTrace();
}
return tables;
}
Тут все достаточно просто, мы просто читаем содержимое файлов, и конкатенируем содержимое каждого файла в элемент массива. Обратите внимание, что я произвожу сортировку списка файлов, так как таблицы могут иметь внешние ключи, а значит таблицы должны создаваться в определенном порядке. Я использую нумерацию в название файлов, и с помощью нею и произвожу сортировку.
private class QueryFilesComparator implements Comparator<String>{
@Override
public int compare(String file1, String file2) {
Integer f2 = Integer.parseInt(file1.substring(0, 2));
Integer f1 = Integer.parseInt(file2.substring(0, 2));
return f2.compareTo(f1);
}
}
С заполнением таблиц все веселей. Таблицы у меня заполняются не только жестко заданными значениями, но также значениями из ресурсов и UUID ключами (я надеюсь когда-нибудь прийти к сетевой версии своей программы, что бы мои пользователи могли работать с общими данными). Сама структура файлов с начальными данными выглядит так:

Несмотря на то, что файлы у меня имеют расширение sql, внутри не sql код а вот такая штука:
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:normal
pri_color:color:colorGreen
pri_default:int:1
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:hold
pri_color:color:colorBlue
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_task
pri_name:string:important
pri_color:color:colorRed
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:normal
pri_color:color:colorGreen
pri_default:int:1
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:hold
pri_color:color:colorBlue
pri_default:int:0
prioritys
pri_id:UUID:UUID
pri_object:string:object_project
pri_name:string:important
pri_color:color:colorRed
pri_default:int:0
Структура файла такая: я выполняю вызов функции split(":") применительно к строчке и если получаю что ее размер равен 1 то значит это название таблицы, куда надо записать данные. Иначе это сами данные. Первое поле это название поля в таблице. Второе поле тип, по которому я определяю что мне надо в это самое поле записать. Если это UUID — это значит мне надо сгенерировать уникальное значение UUID. Если string значит мне надо из ресурсов вытащить строковое значение. Если color, то опять-таки, из ресурсов надо вытащить код цвета. Если int или text, то я просто преобразую данное значение в int или String без каких либо телодвижений. Сам код выглядит вот так:
private ArrayList<HashMap<String, ContentValues>> getSQLDatas() {
ArrayList<HashMap<String, ContentValues>> data = new ArrayList<>();
ArrayList<String> files = new ArrayList<>();
AssetManager assetManager = mContext.getAssets();
String dir = mData + mVersion;
try {
String[] listFiles = assetManager.list(dir);
for (String file: listFiles){
files.add(file);
}
Collections.sort(files, new QueryFilesComparator());
BufferedReader bufferedReader;
String line;
int separator = 0;
ContentValues cv = null;
String[] fields;
String nameTable = null;
String packageName = mContext.getPackageName();
boolean flag = false;
HashMap<String, ContentValues> hm;
for (String file: files){
Log.d(TAG, "file db is " + file);
bufferedReader = new BufferedReader(new InputStreamReader(assetManager.open(dir + "/" + file)));
while ((line = bufferedReader.readLine()) != null){
fields = line.trim().split(":");
if (fields.length == 1){
if (flag == true){
hm = new HashMap<>();
hm.put(nameTable, cv);
data.add(hm);
}
// наименование таблицы
nameTable = line.trim();
cv = new ContentValues();
continue;
} else {
if (fields[1].equals("UUID")){
cv.put(fields[0], UUID.randomUUID().toString());
} else if (fields[1].equals("color") || fields[1].equals("string")){
int resId = mContext.getResources().getIdentifier(fields[2], fields[1], packageName);
Log.d(TAG, fields[1] + " " + resId);
switch (fields[1]){
case "color":
cv.put(fields[0], resId);
break;
case "string":
cv.put(fields[0], mContext.getString(resId));
break;
default:
break;
}
} else if (fields[1].equals("text")){
cv.put(fields[0], fields[2]);
} else if (fields[1].equals("int")){
cv.put(fields[0], Integer.parseInt(fields[2]));
}
}
flag = true;
}
bufferedReader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
return data;
}
Ну и в качестве постскриптума: я повторюсь сказав что я любитель в программировании под Android, что пол-беды. Вторая беда, что в моем окружении нет программистов под Android и собственно говоря не с кем не посоветоваться не устроить мозговой штурм как лучше что-то сделать. Приходится идти методом научного тыка, по пути наступая на грабли. Иногда бывает больно, но в целом круто. Проект над которым я сейчас работаю, уже переживает 4 реинкарнацию. Поэтому просьба не стреляйте в пианиста, я играю как умею. Если напишите как сделать лучше, буду благодарен и рад.
Комментарии (71)

sshikov
02.04.2017 13:45>Почему в книгах и в статьях не описываются инструменты для проектирования архитектуры базы данных и какие-нибудь паттерны для работы с базами данных на этапе их создания я честно говоря не знаю.
Между «я не знаю» и «этого нет» на самом деле очень большая разница. Этой теме уже лет 20, как минимум, и книг написано полно. Вы где-то не там ищете видимо.
Plesser
02.04.2017 13:50+1Наверное мне стоило уточнить, что я говорю про книги по программированию под Android
sshikov
02.04.2017 14:02А какая разница? Вы же сами говорите про проектирование архитектуры базы и паттерны?
Я знаю примерно один существенный фактор, который реально влияет именно на проектирование, когда мы говорим про Андроид — что у вас обычно очень мало ресурсов. И в общем-то довольно узкий выбор самих СУБД.Plesser
02.04.2017 14:12+3Как бы правильно выразить мою мысль… Вот откройте любую книгу или статью посвященную работе с БД под Android. Во всех книгах и статьях разбираются простые примеры (что логично) с внедрением SQL кода в код написанный на Java. С моей точки зрения, это как минимум дискуссионый вопрос.
Сам подход создания таким образом БД очень не удобный. Причем ладно я, Я зарабатываю на хлеб программированием на PL/SQL и я знаю инструменты для работы с БД и как они работают. Я могу найти способы как использовать уже имеющиеся знания для помощи при написания приложения (правильный или не правильный у меня подход это другой разговор). Собственно говоря, этой теме как раз и посвященна моя статья.
А вот новичку в программировании вынос мозга при проектировании своего приложения (при внедрения sql кода в java код), которое использует БД, гарантирован (это мое имхо).
То есть эта статья, не что иное как выработка подхода проектирования БД и внедрения его в приложение, которое будет работать на устройстве.sshikov
02.04.2017 20:36+3Нет, я вполне понял вашу мысль. Просто как бы… считать, что человек станет программистом, прочитав одну книгу о разработке под Андроид — это несколько наивно. Не станет. Если ему нужно будет разрабатывать базу данных — нужно будет почитать книгу по разработке баз данных.
И не просто прочитать, а попрактиковаться, а иначе будет как у меня в одном проекте, когда новые «работники», придя в проект, начали заявлять «а у вас тут база данных ненормализованная».
Тему «куда деть SQL при разработке на Java» тоже можно долго обсуждать, она тоже необъятная, и от нее можно будет прийти как к ORM, так и к инструментам типа JOOQ, QueryDSL и прочим, но тоже не сразу, и предварительно понимая некоторые другие базовые вещи — например, как сопровождать приложение, и какого рода изменения в SQL-запросах в нем возможны. И это все равно тема далеко не для одной книги.Plesser
02.04.2017 21:26Да согласен, но есть одно но. Книги по программированию под Android в отличие от книг БД по сути проводят читателя по всей технологической цепочке создания ПО: от простого Hello world и до публикации в маркете. Моя статья не о том как правильно программировать, ниже мне вполне справедливо накидали замечаний по коду, моя статья скорей о том с помощью каких инструментов и как следствие подходов к написанию самого кода можно себе немного облегчить жизнь.
sshikov
02.04.2017 21:49Так никтож не против ) Я лишь комментировал конкретную вещь о том, почему про это не пишут в книгах. Потому что это заслуживает отдельной книги, а время у авторов не бесконечное.
Просто тема внедрения SQL в java (а на самом деле и не в java вовсе — в большинстве других языков есть все теже самые проблемы, решаемые примерно также, плюс-минус особенности языка) — она не имеет одного наилучшего решения.
Что до вашего конкретного примера — то я бы посмотрел наверное на liquibase. Не буквально, и не прямо в том виде, в каком его обычно используют в проектах (не на Андроид), а скорее на заложенные в нем идеи, в том числе — возможность написания java-миграций. Тем более он open source, можно и в код заглянуть.Plesser
02.04.2017 21:54Спасибо! Обязательно посмотрю :). Что то мне подсказывает, что по тем советам и критике что мне пишут в комментариях скоро появится очередная реинкарнация моего проекта :)

Vladal
03.04.2017 10:40А посмотри урок Работа с базами данных SQLite в Android
Может, что-то прояснится или наоборот, уже знакомо.Plesser
03.04.2017 10:41Я с этих уроков начинал свое знакомство с Android :) Но опять таки основная проблема что там инжектят SQL код на моменте создания БД в Java код…

anyd3v
02.04.2017 15:11Как вы боритесь с миграцими? особенно если апдейт идет через несколько версий? (с версии 3 до версии 6 например) К сожалению в более менее среднем приложении этот вопрос всплывает не редко и это один из самых больных вопросов.
Plesser
02.04.2017 15:151) SQLiteStudio при изменении структуры таблицы сам генерит скрипт для изменения таблицы
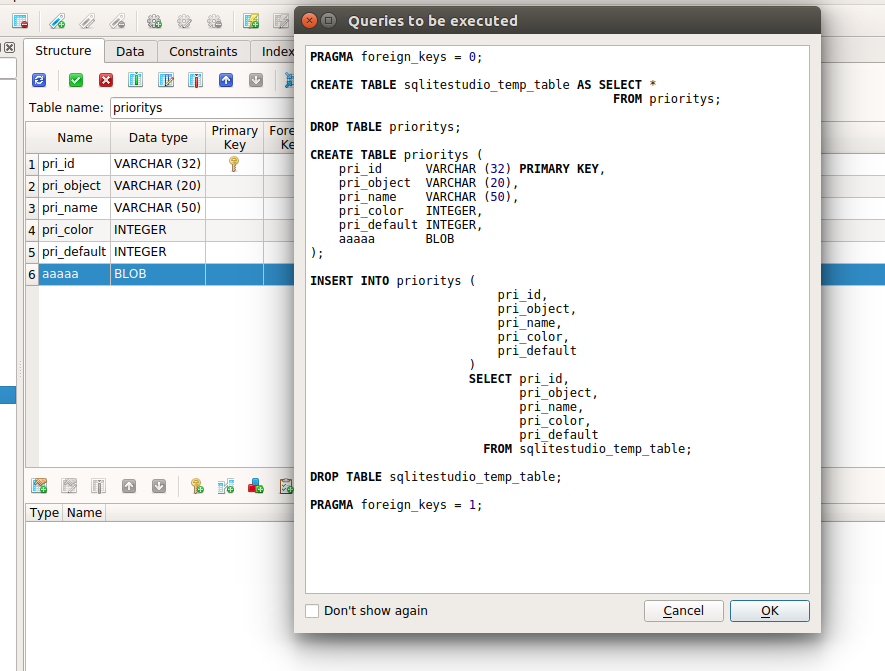 "
"
2) Что касается миграции с версии 3 на версию 6 — это хороший вопрос… пока не готов на него ответить. Спасибо что подняли его, буду думать :)
pavel_pimenov
03.04.2017 11:52На скрине добавили одно поле и с генерировался такой монстр вместо
ALTER TABLE xxx add column aaaaa BLOB;
Представь, что размер таблицы 5гб а места на диске всего свободно 3…
а если есть индексы/триггера — студия их восстанавливает?
по-моему скрипты миграции нужно писать руками и обрабатывать все исключительные ситуации
иначе есть риск, что ваше приложение у конечного пользователя сломается.
для этого в sqlite придумана PRAGMA user_version
по нему можно ветвится в коде миграции и делать нужные модификации базы в онлайне.Plesser
03.04.2017 12:05ну во первых мне сложно представить приложение с БД размером 5 гб на телефоне :)
ну и во вторых если вам надо добавить колонку в конец таблицы то да, Ваш вариант правильней. Если же Вам надо добавить колонку внутри других колонок то такой вариант уже не прокатит.
KamiSempai
04.04.2017 16:24А в чем польза определенного порядка колонок? Вы же с ними по названию работаете, а не по порядковому номеру.
Plesser
04.04.2017 16:44Работаю да — по названию. А определенный порядок читаемости колонок удобен при просмотре как структуры таблицы так и его содержимого в какой нибудь ide среде. Если у Вас колонок больше 7 то близкие по сущности колонки лучше группировать рядом друг с другом.
pavel_pimenov
04.04.2017 16:46По индексу на колонку можно сослаться в конструкции order by 2
менять позиции колонок — бомба замедленного действия.
могут сломаться клиенты где «зашито» что-то вроде select * from…
из полезного я помню только один случай реорганизации:
в oracle если колонки не заполнены(null) и находятся в конце, то они не занимают место в блоке.
т.е. разместив редко заполняемые поля в конец — можно сэкономить на диске.
KamiSempai
04.04.2017 17:01В order by указывается индекс колонки из выборки, порядок колонок из базы тут имеет значение только при выборке всех колонок через звездочку.
менять позиции колонок — бомба замедленного действия.
работать с индексами а не с именами — бомба замедленного действия.
Plesser
04.04.2017 17:18Работать с индексами колонок это потенциальная проблема. Указывать конструкцию order by индекс мало того что это потенциальная проблема, там еще и ухудшение читаемости кода когда у вас в выборке скажем 10 колонок, и вы делаете скажем order by 7

Bringoff
02.04.2017 18:50По идее, если надо мигрировать через несколько версий, поочередно будут происходить миграции 3->4->5->6
anyd3v
02.04.2017 18:56Да, это очевидно. Я для своих проектов использую подобное. Но с недавних пор начал задумываться над подобным стилем, что привел автор: хелпер + скрипты в ассетах. Вот и стало интересно как он это делает. В моем подходе я использую массив миграций, соответственно если если первая версия базы имеет номер 1, но ее можно привести к индексу массива: версия — 1, соответственно для миграции с n на m надо взять срез n...m-1. В подходе автора не совсем очевидно как это взять. А так было бы полезно адаптировать под свои нужды.
brnovk
02.04.2017 15:15+2Навскидку, несколько замечаний по коду:
- BufferedReader желательно закрывать в секции finally или использовать try-with-resource
- Контенкация строк в цикле — зло. В Java строки неизменяемые и это плодит новые объекты при каждой итерации. Используйте StringBuilder или StringBuffer.
- printStackTrace() в секции catch — имеет смысл только при отладке. Если исключение возникнет при работе готового приложения — есть вероятность, что вы об этом и не узнаете. Кидайте в лог или ловите/обработывайте все сразу выше.
- … файлы имеют расширение sql, внутри не sql код ... — подумайте, какого будет человеку который будет поддерживать ваш код. В sql-файлах ожидаются скрипты, не нужно пихать в него сырые табличные данные. Имхо (могу ошибаться), лучше уж — csv или какой-нибудь dat-файл.
- Использование «вложенных» коллекций в довольно простых случаях (ArrayList<HashMap>). Java — это объектно-ориентированный язык, лучше создать информативный объект враппер.
- Обилие magic numbers — сразу бросаются в глаза индексы массивов, но и строковых литералов хватает. Выносите в константы, читаемость только улучшиться.
- Ну и классическое — раздутые методы с кучей вложенных операторов, if (flag == true), неочевидные названия переменных и прочие ошибки начинающих.
Plesser
02.04.2017 15:20Большое спасибо за Ваши замечания! Как мне не хватает вот таких замечаний :(
sshikov
02.04.2017 20:43Хм. Ну, такого в вашем кода завались… его можно долго комментировать, почти что построчно:
ArrayList<HashMap<String, ContentValues>> data = new ArrayList<>();
Вообще принято писать как-то так:
List<Map<String, ContentValues>> data = new ArrayList<>();
А начать можно с того, что ваш кусок кода можно просто и логично разбить минимум на два метода — один из которых будет работать с одним файлом.

Alex837
02.04.2017 21:48Читал по диагонали… но имхо, для любителей SQL есть square/sqldelight, который при всех его недостатках предоставляет больше удобства чем велосипед в статье.
Plesser
02.04.2017 21:52Я так понимаю это какой то ORM… Я обязательно посмотрю его, но опять таки, ORM это штука для уже более мнее продвинутых программистов. Моя же статья больше предназначена для начинающих, как им облегчить жизнь…
Alex837
02.04.2017 23:19Это не ОРМ, это ОМ с тонкой прослойкой для опен хелпера для удобного использования скл. Он делает ровно то что вы хотели сделать своим кодом, только гораздо удобней, без вот этой всей порнографии, которая в посте наблюдается. Создание таблиц это конечно муторно, но это разовая операция. А вот запросы и с данными работать надо гораздо чаще.
>Моя же статья больше предназначена для начинающих, как им облегчить жизнь…
Я пока увидел только как усложнить жизнь начинающему разработчику по сравнению с обычным опен хелпером при сомнительных преимуществах. По моему опыту с начинающими программистами, любой ОРМ без скл им облегчает жизнь гораздо больше ибо нынче начинающий разработчик под андроид вообще не знает скл)) ну а для ценителей есть упомянутая мной либа, которая на этом скл и базируется.Plesser
03.04.2017 07:42Вот я начинающий разработчик, и лично мне с моими знаниями такой подход оказался легче. Возможно сам подход не правильный, но к сожалению в моем окружении нет людей которые могли бы сказать как правильно подходить. Ваш подход я обязательно изучу.

kaljan
03.04.2017 07:41ORM это штука для начинающих, имхо, т.к. написать плохой и опасный код при незнании SQL гораздо легче, чем написать говнокод с использованием ORM
ls18
03.04.2017 07:42Спасибо за статью :) Тоже есть не большой опыт работы разработчиком PL/SQL и так же присматриваюсь в сторону Java и Android.
Sashok69
03.04.2017 07:45Вместо потенциальных проблем с чтением таблиц и запоминанием связей (которые решаются опытом или тем же Data Modeler), получили вполне очевидные проблемы с нечитабельными файлами, их парсингом и обработкой ошибок. К тому же, насколько понимаю, будет проблематично ссылаться на таблицы/столбцы (как-то надо сохранять их названия?).
Есть стандартный способ работы с бд, который все знают, а с вашим придется разбираться.
Ну, и, как заметили, если очень хочется, лучше использовать orm.Plesser
03.04.2017 07:49Так я работаю стандартно с БД. Я просто навесил на эту работу свой примитивный враппер что бы мне легче было жить.
serg_deep
03.04.2017 07:46Читайте чужой код, не обязательно общаться с другими разработчиками. Чужой код огромная кладезь знаний и новых трюков. Не знаете как сделать, лезете на гитхаб и смотрите как это делали другие. Скил качается семимильными шагами.
Plesser
03.04.2017 07:47Я по возможности смотрю чужой код. Но тут та проблема, что надо знать куда смотреть. Я сейчас делаю свой проект, и как узнать из какого проетка на гите можно узнать где решаются подобные задачи…
alexhott
03.04.2017 08:35Проектировал много баз данных.
Для себя сделал вывод.
На этапе проектирования структуры базы данных действительно очень полезно использовать графические инструменты, какие угодно. Даже тот же MS ACess неплохо может справиться.
Но создавать объекты в БД лучше ручками, написав запросы.
Все это авто создание объектов — после него дольше править.TemaAE
03.04.2017 10:23Но хороший редактор в котором ты видишь список полей и быстро можешь добавить нужные с ручным выбором типов еще лучше :)

Arvalon
03.04.2017 09:42Мои 5 копеек.
Если БД простая то достаточно SQLiteOpenHelper'а, можно спроектировать всё в голове и написать класс — слой доступа к ней что бы уж где-то дальше не встречались sql-запросы.
А если табличек становиться уже много и так просто не разобраться то можно спроектировать, протестировать, наполнить данными базу где-нибудь во внешнем инструменте. Я отыскал для себя SQLite Expert Professional, в ней можно как и мышкой / мастером создавать таблички / запросы так и поработать с ними потом чистыми sql-запросами. Но эта софтина платная.

А затем что бы не переносить скрипты создания и заполнения БД можно положить наш готовый файл БД db2.sqlite в assets/databases и подцепить его SQLiteAssetHelper'ом
public class DatabaseOpenHelper extends SQLiteAssetHelper{ private static final String DATABASE_NAME = "DB2.sqlite"; private static final int DATABASE_VERSION = 1; public DatabaseOpenHelper(Context context) { super(context, DATABASE_NAME, null, DATABASE_VERSION); } }Plesser
03.04.2017 10:15А как Вы решаете вопрос с внесением изменения в структуру БД при использовании SQLiteAssetHelper в последующих версиях вашей программы?
subprogram
03.04.2017 15:56Если контент базы может изменяться в процессе работы приложения, то, очевидно, при начальной инициализации нужно копировать всю базу во внутреннюю память и открывать ее уже с помощью обычного хэлпера.
Если же структура и содержимое БД меняются только при обновлении версии приложения, то вообще никаких проблем нет.Plesser
03.04.2017 15:57Ок, то есть если нам надо писать данные в базу данных то мы должны копировать файл во внутреннею структуру.
Про изменение не понял. У Вас обновилась программа. Необходимо изменить структуру таблиц но при этом не потерять там данные.subprogram
03.04.2017 17:01Так данные могут меняться в приложении или нет? :)
Если нет, то и с обновлением нет проблем — БД лежит в assets-ах и обновляется вместе приложением. Миграцию поддерживать нет необходимости.Plesser
03.04.2017 17:21Именно что могут
subprogram
03.04.2017 18:52Тогда по первому варианту — при первом запуске копировать БД из assets-ов во внутреннюю память. Далее — проверять текущую версию БД и если она меньше, чем нужно, то последовательно применять скрипты миграции.
Arvalon
03.04.2017 19:08Или разрабатывать скрипты миграции в том же внешнем редакторе, переносить их в обновление и применять на БД, не перемещая её из assets.
subprogram
03.04.2017 20:04Что-то я не понимаю… Что значит «применять на БД, не перемещая её из assets»? Как можно изменить БД, которая находится в assets? Она же Read Only там.
Arvalon
04.04.2017 19:18Да, не так написал. Она сама копируется во внутреннюю память при первом обращении к ней. Это лежит на плечах SQLiteAssetHelper'а.
breakoffbrain
03.04.2017 10:44по-моему необходимо заняться рефакторингом кода. слишком большая вложенность, куча циклов, ArrayList в качестве возвращаемого значения. А если вы захотите изменить тип коллекции?
Plesser
03.04.2017 10:47Вы знаете, это уже 4 версия кода в моей программе. И я все время его рефакторю. До каких то вещей я дохожу сам, до каких то вещей нет…

kosmonaFFFt
03.04.2017 11:50А не смотрели в сторону Flyway (https://flywaydb.org/documentation/api/)? Я пару раз использовал в своих андроидовских хеллоуворлдах, решает сразу все проблемы инициализации и миграции БД.
Plesser
03.04.2017 12:07Не открывается сайт чего то, хотя гугле подтверждает что вы указали правильный путь.
Посмотрю обязательно потом. Я пока в самом начале пути и поэтому иду стандартными средствами
KomarovI
06.04.2017 14:11Почему в книгах и в статьях, посвященных программированию под Android, не описываются инструменты для проектирования архитектуры базы данных и какие-нибудь паттерны для работы с базами данных на этапе их создания я честно говоря не знаю
Чаще всего потому, что вычислительная мощность мобильных девайсов сильно уступает мощности компьютеров, потому, смысла в проектировании сложной БД особо не возникает, посколько это может оказать негативный эффект на перформанс.Plesser
06.04.2017 20:10Беспорно, вычислительная мощность уступает. Но тут разговор не о размере БД а о ее структуре. К примеру то приложение которое я сейчас делаю имеет 10 таблиц. И работать со SQL кодом в Java коде при создании таблиц это не айс…
alix_ginger
На мой взгляд, и я думаю, многие согласятся, можно достичь результата быстрее и с меньшим количеством потенциальных ошибок, если использовать какой-нибудь ORM-фреймворк.
Plesser
Я читал несколько статей про ORM-фрейморвки, и несмотря на ряд проблем, описываемых там, думаю когда нибудь перейти на них. А может и Google к тому времени включит какой нибудь фреймворк в свой официальный SDK.
serso
В последнем моём проекте попробовал GreenDAO и меня ждало разочарование. Переписал всё вручную в итоге. Возможно, есть и более удачные фреймворки
Bringoff
А что не устроило? Потому что как раз думал мигрировать с ormlite на greendao на одном legacy-проекте.
handbrake
Пользуясь случаем, а что не устроило в ormlite?
llerik
Пользовался ormlite в связке с h2.db. Все красиво написано, удобно пользоваться, написанием sql запросов текстом можно не морочиться. Вплоть до момента, когда надо обновлять таблицу. Нет ни версии БД, ни каких-то продуманных инструментов из коробки для обновления ее структуры. Пришлось писать дополнительную табличку с версией БД, и свои методы по обновлению, которые исполняют сырые запросы.
Bringoff
Самое основное — это скорость. В Ormlite вовсю используется рефлексия, что на андроиде довольно дорого. Ну и не развивается уже давно. Это расстраивает.
dmrt
О, идея!
Испльзовать ORM-фреймворк — отличная методология создания свой БД.
Сначала пишешь при коннекте «DBI:itsmysql:database=test;host=localhost» — устраняешь все ошибки, затем другие и другие ошибки.
dajver
Как минимум есть великолепный realm который выполняет все функции БД, со всеми связями и праймари ключами…