
Предисловие переводчика: Недавно я рассказал о том, как реализовать процедуру планирования выпуска релизов по продуктам с помощью семейства продуктов Atlassian и дал ссылки на статьи как сделать тоже самое в Team Foundation Server и Redmine.
А что делать если компания не дозрела купить JIRA, TFS или Redmine, как обойтись только Excel-ем?
И эта статья о том как это сделать.

В этой статье я хочу рассказать о простом механизме составления плана выпуска релизов. Не буду вдаваться в принципы и ценности, лежащие в основе гибкого планирования выпуска релизов, но в конце статьи найдёте ссылки на материалы, которые помогут в этом разобраться.
Это лишь один из способов составить план выпуска релизов и уверен, что существует много других вариантов. Я использовал этот подход со многими командами разного размера во многих проектах различной величины и сложности. Во многих случаях я его расширял и дополнял, но основы всегда оставались прежними и хорошо работают. Буду рад комментариям о том, как вы это делаете со своими командами.
Список пользовательских историй (Product Backlog)
Для начала нам понадобится список пользовательских историй (Product Backlog). Для простоты в нём будут только четыре поля:
ID — уникальный идентификатор для каждой истории. В моем примере я начал с 1000. Рекомендую не использовать ID в качестве поля приоритета по умолчанию (видел и такие варианты его применения).
User Story — простое короткое название для каждой пользовательской истории. Не надо пытаться прописать историю полностью в поле «Название пользовательской истории», в расширенной версии списка вы можете добавить отдельные поля: полное описание истории, критерии приемки, вариант классификации и другие.
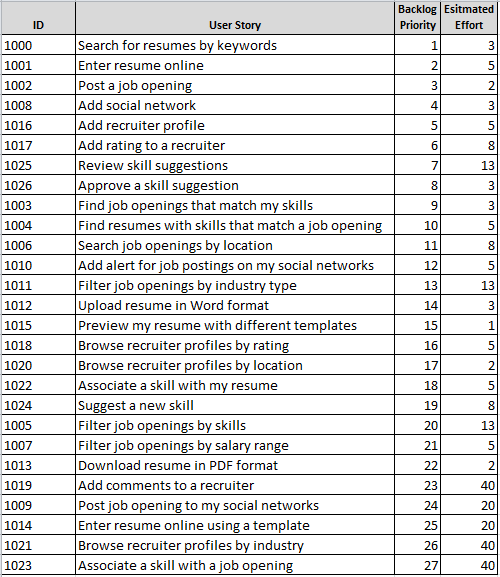
Приоритет — в этом поле указывается порядок, в котором Владелец Продукта (Product Owner) хочет получать истории. У этого числа не должно быть никакой скрытой логики, встроенной в число (чуть позже поясню что имею ввиду).
Оценка трудоемкости — оцененная командой трудоемкость реализации истории. Не буду предлагать сразу использовать Story Points, дни разработки, часы. Скажу только что в начале предлагаю использовать систему высокоуровневой оценки, которой будет удобно пользоваться Scrum-команде (тоже чуть позже станет ясно что имею ввиду).
Добавление пользовательских историй
Существует множество методов сбора пользовательских историй, таких как рабочие группы по генерации пользовательских историй, фокус-группы клиентов и т.д. Не буду сейчас об этом так как это не предмет этой статьи. Однако Владелец Продукта собирает и добавляет их в список. Обычно, когда мы проводим «мозговой штурм» по историям, мы просто записываем их в том порядке в каком генерим и не пытаемся классифицировать или расставлять приоритеты на этом этапе. Иногда это может мешать потоку идей. Таким образом, вам нужно составить список историй.
Вот простой пример первоначального списка историй в Excel (простейший инструмент, который можно использовать после стикеров на стене).

Первоначальная высокоуровневая приоритезация
Когда у вас есть список, некоторые говорят, что нужно попросить команду, чтобы они оценили его, но я советую вам сделать первый раунд высокоуровневой приоритезации, таким образом вы сфокусируете время и внимание команды на тех историях, которые сперва посчитаете самыми важными.
Не делайте это сложнее, чем это необходимо. Используйте простую метрику с несколькими значениями, такими как: must (обязательно), need (однозначно нужно), want (хотелось бы). Или используйте 1,2,3. Или — Высокий, Средний, Низкий. На самом деле между ними нет особой разницы. Для моего примера я буду использовать 1,2,3, так как потом будет легче отсортировать список в Excel.
Посмотрите на список и уделите обсуждению каждой истории не более одной минуты, чтобы каждой дать её первоначальный приоритет. Убедитесь, что все, кто участвует в этом мероприятии, понимают, что это не окончательный приоритет и что по ходу проекта он может быть повторно переоценен и изменен. Это поможет обуздать желание анализировать каждую вещь до смерти.
Вот наш список историй (Product Backlog) с первичными приоритетами. (ПРИМЕЧАНИЕ: Истории я выдумал, поэтому не цепляйтесь к ним).

Первоначальные высокоуровневые оценки трудоемкости
Как только мы получили отсортированный по первоначальным приоритетам список историй, отдайте его Scrum команде, чтобы она предоставила некоторые начальные высокоуровневые оценки трудоемкости. На этом этапе процесса можно использовать подобный подход, как и с приоритетами, используя простой показатель, такой как Small (маленькая), Medium (средняя) и Large (большая). Как и в случае с приоритетами эти оценки не являются окончательными и команде будет предложено более внимательно изучить их в будущем, поэтому постарайтесь не тратить на них слишком много времени. Удачи вам в этом, потому что инженеры любят быть точными и очень трудно заставить их быть поверхностными (не углубляться). Вы можете использовать любой из методов оценки, который знаете, например, Planing Poker или что-то другое что годится для вашей команды.
Если ваша команда уверена, что они могут использовать их нормальную метрику для оценки (например, последовательность Фибоначчи), тогда позвольте им её использовать. Предлагаемые мною подходы доказали на практике, что являются лучшими в начале, когда все ещё в общих чертах, и вы хотите просто получить представление о том, что нужно сделать в первую очередь и насколько велики будут затраты на это. Как уже говорил, вы будете постоянно уточнять приоритеты и оценки по ходу проекта. Если ваш список историй будет достаточно большим (длинным), вам стоит сосредоточиться на самых верхних историях, поскольку они должны быть самыми ценными для бизнеса.
Список пользовательских историй с первоначальными оценками трудоемкости.

Уточнение пользовательских историй и приоритетов
Теперь, когда Владелец Продукта имеет некоторое представление о том, насколько трудоемки истории, он может захотеть изменить приоритеты и/или разделить некоторые истории. После того, как он решил в каком порядке хотел бы их получать, пришло время изменить подход для указания приоритета истории.
Как говорил, в поле приоритет (порядок выполнения) не должно быть никакой дополнительной логики. Видел использование номера вот в таком виде — 1102, что означало, что заинтересованные стороны хотят, чтобы историю реализовали к февралю 2011 года. Это не очень хороший подход, поскольку оказывает давление на команду, чтобы она реализовала историю до этой даты и заинтересованные стороны подразумевает, что это та дата когда это будет сделано. Но это число обычно не основано ни на скорости команды, ни на какой-либо оценке предоставленной командой, поэтому это рецепт катастрофы.
Лучший способ гарантировать, что поле не будет использовано таким образом, это всегда начинать с 1 и последовательно назначать номера остальным историям. Каждый раз, когда вы переставляете истории в списке номер приоритета начинается с 1. После того, как итерация разработки (Sprint) выполнена, вы вновь назначаете приоритет для всех оставшихся в списке историй опять начиная с 1. Это делает довольно сложным встраивание любого типа логики в число.
Список историй с приоритетом — порядком выполнения.

Уточнение оценок трудоемкости
Как и после первоначальной приоритезации, передайте список историй Scrum команде, чтобы она уточнила свои оценки в вашей обычной системе измерений (если только она не сделала это в самом начале). Уделите больше времени верхним историям, поскольку скорее всего они будут реализовываться в следующих предстоящих итерациях. Затем попытайтесь пройти по списку историй так далеко, насколько сможете (в зависимости от его размера и доступного времени команды). В общем ваша Scrum команда должна тратить от 10% до 15% своего времени в течении каждой итерации на то, чтобы помогать причесывать (grooming) список историй, когда в нем будут появляться новые пользовательские истории (User Story), которые не были заявлены в начале его составления.
Теперь у нас есть список историй, который приоритезирован и оценен в меру возможностей команды.

Вы заметите, что некоторые из историй в списке имеют довольно большие оценки. Это может быть вызвано многими факторами, такими как неопределенность, риск, чистый размер, сложность и что-то ещё. Scrum команда должна определить максимальный размер для истории, который она позволит включить в итерацию. Выставление этой границы дает команде инструмент для возврата историй, которые, по их мнению, не могут быть выполнены за одну итерацию. Владелец Продукта должен разбить эти истории или дать ответы на вопросы команды, чтобы она могла уточнить и уменьшить свои оценки.
Крупные пользовательские истории находятся внизу списка, так как мы не ожидаем, что они будут реализованы в ближайшее время, мы вернемся к ним позже, когда они поднимутся в списке и приблизятся к тому, чтобы быть включенными в итерацию. Если у вас есть большие истории в верхней части списка, их нужно разбивать до тех пор пока они не будут приемлемого размера или не будут перенесены вниз списка.
В этом списке большие истории перемещены в нижнюю часть, а поле приоритета заново заполнено начиная с 1. В моем примере Scrum команда определила, что любая история размером больше 13 слишком велика для одной итерации.
Определение начальной производительности
Производительность (Velocity) — это сумма всех оценок трудоемкости, которые команда завершает в ходе итерации. В начале проекта вы можете не иметь представления о том какая будет производительность (мощность) вашей команды. Видел всевозможные варианты с онлайн-алгоритмами и большой математикой, на основе длины итерации, доступных дней разработчиков, размера команды и т.д. Какой бы метод вы ни использовали, просто знайте, что скорее всего ошибетесь и это нормально. После первой итерации у вас будет реальная производительность для начала её использования и отслеживания.
Предлагаю встретиться с Scrum командой и обсудить истории, стоящие в верхней части списка, и спросить как много историй они могут взять в первую итерации. Поскольку шансы ошибиться всё таки велики, не тратьте на это слишком много времени и не задерживайте команду чтобы это посчитать.
Для примера будем считать начальную плановую производительность равной 15. Продолжительность итерации будет составлять 3 недели и наш проект стартует 01.01.2013.
Создание первоначального плана выпуска релизов
Имея приоритезированный и оцененный список историй, а также начальную производительность команды (которую я люблю называть плановой производительностью при планировании выпуска релизов) можем сделать наш первый проход по составлению плана выпуска релизов. Просто начинаем с верхней части списка и прокладываем себе путь вниз, суммируя оценки, пока не достигнем 15 (или прямо перед тем, как пройдем через это число). Если у нас есть история с оценкой в 13, а затем следующая имеет оценку 3, то мы не должны совмещать их в итерации, так как это приведет к превышению плановой производительности равной 15. Когда добираемся до историй в нижней части списка, которые слишком велики для реализации в одной итерации, на них и останавливаемся.
Делая это в Excel я использую альтернативные цвета, чтобы легко показать группировку историй в итерациях, как показано ниже.

Теперь когда истории сгруппированы в итерации, на основе плановой производительности, можем использовать предлагаемую дату начала проекта и длину нашей итерации, чтобы добавить даты группам и получить представление о сроках реализации историй. Помните, что это очень высокий уровень и вы будете постоянно пересматриваться план при каждой новой итерации, поэтому рассматривайте его как живой документ.
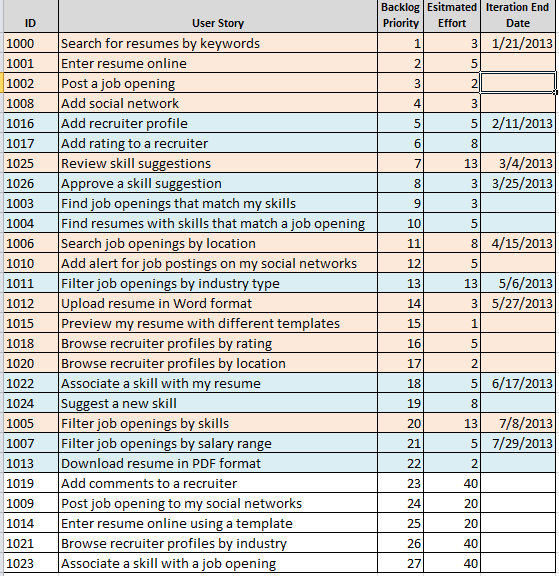
На этом этапе ваш Владелец Продукта сможет начать обсуждение с соответствующими заинтересованными лицами даты релизов. Некоторые компании выпускают релиз всякий раз, когда считают, что имеют достаточную ценность для своих клиентов, поэтому в начале заинтересованные лица будут в основном игнорировать даты и просто смотреть сколько историй из списка они уже получили и сколько ещё осталось до того момента, когда функциональность может быть передана клиенту. Тогда у них появится некоторое представление о том, когда это может быть, с учетом что на следующей итерации это будет пересмотрено.
Если ваша компания делает запланированные выпуски релизов (например, плановый релиз в середине года или какой-то другой вариант), вы сможете найти дату окончания итерации близкую к дате выпуска релиза. Затем вы можете увидеть, какая функциональность будет реализована и какую ценность доставите клиенту. Проблемы могут возникнуть, когда плановый срок реализации группы функциональных возможностей, которая должна быть доставлена как единое целое, чтобы предоставить клиенту наибольшую ценность, превышает вашу целевую дату выпуска, и в этом случае Владельцу Продукта, возможно, придётся сделать некоторый сложный выбор.
Вероятней всего произойдёт причёсывание (grooming) списка историй как только это станет ясно. Таким образом, Владелец Продукта может перемещать истории, разбивать их, комбинировать и т.д. Всякий раз, когда Владелец Продукта причёсывает список историй, он должен уведомить команду, чтобы она пересмотрела свои оценки. Это должно произойти, даже если он просто перемещает некоторые истории, поскольку некоторые оценки могут иметь предположения относительно пункта Б, который легче реализовать, если история А уже сделана и если он меняет их местами, тогда оценки необходимо уточнить.
Рассмотрите вариант создать отдельный Лист в электронной таблице с историями, которые не понадобятся в предстоящей версии, и использовать Лист с теми что нужны в качестве рабочего плана выпуска релиза. Тогда Владелец Продукта сможет перемещать истории между листами. Это помогает, если у вас большой список историй, а в плане выпуска их не так много. Ведение их по отдельности может облегчить управление ими.
Пересмотр плана выпуска на каждой итерации
В ходе каждой итерации Владелец Продукта будет постоянно причесывать список историй работая с заинтересованными сторонами, чтобы добавить, удалить, уточнить и расставить приоритеты, а также получить оценки от Scrum команды.
В конце итерации можете взять последнюю фактическую производительность Scrum команды и использовать ее вместе со своими историческими данными, чтобы скорректировать плановую производительность. Один из подходов состоит в том, чтобы взять 3 самые низкие и усреднить для расчета наихудшей плановой производительности, а затем усреднить 3 самые высокие для наилучшего сценария. Предоставление заинтересованным сторонам плана выпуска релизов с этим диапазоном поможет им не цепляться за отдельные даты в них.
Обновленный план выпуска релизов должен быть передан команде и заинтересованным лицам после каждой итерации. По мере продвижения к целевой дате выпуска релиза, список историй и план выпуска будут становится более четкими и точными. Главное понять, что план выпуска похож на Etch-A-Sketch, который вы встряхиваете и воссоздаете в конце каждой итерации, основываясь на последних фактических данных.
Дополнение и совершенствование плана выпуска релизов
Этот простой подход работает хорошо, но в большинстве случаев понадобится его расширить и дополнить, чтобы удовлетворить ваши конкретные потребности. Будьте осторожны, чтобы не добавить слишком много и сделать из плана выпуска То что он перестанет быть планом. Это очень легко сделать. Вот несколько распространенных дополнений, которые мне приходилось делать по разным причинам.
Добавление ошибок — я участвовал во многих дискуссиях о том, как обрабатывать ошибки, когда дело доходит до включения их в список и план выпуска. Многие люди не любят тратить время на то, чтобы оценивать трудоемкость устранения ошибок, так как часто бывает необходимо сперва разобраться в её причинах, прежде чем сделать более или менее точную оценку. В этих случаях я видел, как они помещали ошибки в свои собственные списки и просто выделяли определенный процент производительности каждой итерации для решения наиболее критичных из них. Если это тоже ваш подход, тогда скорректируйте плановую производительность, чтобы исключить выделенную трудоемкость на исправление ошибок при планировании выпуска релизов.
К сожалению, многие компании приходят в Agile со значительным списком ошибок, которые необходимо устранить. В их случаях мы добавляли ошибки в список историй так же, как и истории. Они оценивались и им назначались приоритеты точно так же, как и другим историям из списка. Это приводит к повышению накладных расходов, но иногда это оправданно, если вам нужно взять под контроль влияние накопившихся ошибок на продукт. Поскольку ошибки находятся в списке, можно использовать нормальную плановую производительность во время планирования выпуска релизов. Если у вас все еще есть значительное количество новых ошибок, то вы можете скорректировать свою плановую производительность на основании исторической информации о среднем количестве новых ошибок, появляющихся в результате каждой итерации. Конечно, если вы находитесь в такой ситуации, у вас явно есть проблема с качеством, и вам нужно предпринять какие-то шаги, чтобы улучшить качество ваших процессов и процессов, отвечающих за качество.
Одновременно с добавлением ошибок в список мы также добавили в него новое поле с названием Type (Тип), которое может быть либо User Story (Пользовательская история), либо Bug (Ошибка), чтобы их можно было различать при просмотре списка или плана выпуска. Также можно использовать разные цвета, чтобы потом, основываясь на их значении (например, зеленый для пользовательских историй и красный для ошибок), быстрым взглядом на план выпуска получить представление о том, сколько в этом релизе новых «фич».
Категоризация и группировка — часто группа историй составляет «фичу» (бизнес-функцию) и должна быть поставлена вся вместе, чтобы дать клиенту достаточную ценность от нового релиза. Заинтересованным лицам нравятся такие отчеты по этим «фичам», которые показывают когда все необходимые истории будут реализованы или сколько историй в группе уже сделано и сколько ещё осталось сделать. Чтобы это показать-увидеть достаточно добавить столбец под названием «Категория». Проблемы с использованием этого отчёта возникают когда появляется потребность во множественных или иерархических группировках. Можно попробовать несколько простых вариантов для таких случаев, например, добавив дополнительные столбцы категорий (Категория 1, Категория 2 или Основная Категория, ПодКатегория и т.д.). Можно также придерживаться одного поля и использовать разделитель, но это не так легко фильтровать в Excel, чтобы составить простой отчет.
Базовые линии (baselines) — это неудивительно что всегда найдётся кто-то кто спросит как текущий план выпуска выглядит по сравнению с тем, как он выглядел в прошлом. Это может быть очень опасно, поскольку отражает неспособность принять изменения, которые являются основной ценностью Agile. Если вас попросят что-то подобное, рекомендую разобраться в том зачем им нужно это знать и что они собираются делать с этой информацией. Предполагается, что список историй (Product Backlog) будет меняться, и поскольку план выпуска является простым наложением на его верхнюю часть, то это значит что он также должен измениться.
Ценность для бизнеса и рентабельность инвестиций (ROI) — бизнес-ценность иногда ошибочно рассматривается как единственный показатель для сортировки списка историй. Обычно бизнес-ценность является чем-то осязаемым, например, добавление «фичи» X приведет к увеличению на 10% числа клиентов в следующем квартале и приведет к дополнительным продажам в размере 1 000 000 долларов. С этим не поспоришь. Но что, если оценка трудоемкости реализации «фичи» X составляет 1 500 000 долларов?
Есть также случаи, когда вы можете реализовать «фичу» по менее веским причинам. У вас может быть важный клиент, который очень помогает в тестировании предварительных (бета) релизов. У них может быть «фича», которую они действительно очень хотят, но она не так сильно нужна более широкому кругу клиентов (рынку). Вы можете решить реализовать эту «фичу», чтобы сохранить эти отношения.
Это говорит о том, что существует множество переменных, которые могут входить в определение «Ценности» истории из списка. Считаю, что дача оценки бизнес-ценности себя оправдывает и я использую её как еще один параметр при определении приоритета истории в общем списке. Попытайтесь сохранить его простым показателем и дать пояснения как им пользоваться. Одним из примеров может быть рейтинг от 0 до 1000, где 1000 наибольшее значение. Конечно, сразу же всем историям выставят 1000 и как раз тут понадобится руководство (пояснения). Например, диапазон от 750 до 1000 для историй, которые, если они не будут реализованы в следующем релизе, будут стоить компании значительной доли рынка через потерю существующих или потенциальных клиентов.
Использование такой шкалы дает возможность выполнить простые вычисления рентабельности инвестиций (ROI). Разделите бизнес-ценность на предполагаемую трудоемкость, чтобы получить представление об относительной рентабельности. Это очень упрощенный подход к расчету рентабельности инвестиций, но он хорош на высоком уровне. Можно увидеть, что история, оцененная в 1000, но с оценкой трудоемкости 20, имеет меньше ROI, чем история на 500 и трудоемкостью 5.
Что ещё почитать по теме на Habrahabr
Как это сделать с помощью других инструментов
- в Team Foundation Server — О гибком планировании и управлении работами в TFS 11 Beta
- в Redmine — Оперативное планирование в Redmine
- в JIRA — Реализация процедуры «Планирование выпуска релизов по продуктам» инструментами семейства Atlassian
Концептуальные статьи
Поделиться с друзьями
Комментарии (3)

NeverIn
04.04.2017 21:27А багами занимается отдельная команда? По какому принципу оценивается estimate бага?

Locolind
04.04.2017 21:54NeverIn вам этот комментарий нужно оставить на английском языке в блоге Tommy Norman-а.
А багами занимается отдельная команда?
В оригинальной статье говорится что багами занимается та же самая команда. Автор говорит что чаще встречает два варианта.
Первый — что кто-то из разработчиков узнаёт что это «его» (он разрабатывал то, что выдаёт ошибку) и забирает этот баг в свой персональный список, выделяя на их устранение определенное количество времени на цикл разработки (Sprint).
Второй — что они добавляются в общей список (Product Backlog) и команда тратит общее время на цикл разработки, чтобы устранить те из них, чтобы были добавлены в Sprint Backlog.
По какому принципу оценивается estimate бага?
Если баги добавляются в Product Backlog также как User Story в момент старта, когда Product Backlog-а ещё нет, то в этом случае оценка будет происходить по тем же принципам что и весь список. Сперва: smal, medium, big. Затем уже используются цифровые оценки.
Если баги будут появляться в ходе каждой итерации и добавляться в персональные списки, то затраты на их устранение оцениваться не будут, а оценивается только степень критичности бага.
Если баги будут добавляться в Product Backlog, то оцениваются в единицах трудоемкости той системы координат, которую выбрала команда для Product Backlog-а.
На что Автор обращает особое внимание, что те с кем ему доводилось работать сперва настаивали на том, чтобы проанализировать баг, чтобы понять что не так, перед тем как давать какую-то оценку.
maxru
Докупить Redmine?