
В прошлом году я написал статью для Smashing Magazine о Houdini и назвал его «самым потрясающим проектом CSS, о котором вы никогда не слышали». В этой статье я объясню, что набор Houdini API позволит (среди прочего) расширить функции CSS через полифиллы таким способом, какой просто невозможен сегодня.
Хотя та статья была в целом хорошо принята, один и тот же вопрос постоянно задавали мне в письмах и твиттере. Основная суть вопроса:
И я понял — конечно же, у людей возникают такие вопросы. Если вы никогда не пробовали сами написать полифилл CSS, то, вероятно, никогда не испытывали эту боль.
Так что лучший способ ответить на этот вопрос — и объяснить, почему меня так восхищает Houdini — это наглядно показать, почему настолько трудно использовать полифиллы CSS.
И лучший способ сделать это — написать полифилл самим.
Примечание: эта статья представляет собой текстовую версию лекции, которую я прочитал на dotCSS 2 декабря 2016 года. В статье рассматривается чуть больше подробностей, но если вы предпочитаете посмотреть видео, я его тоже вставил сюда.
Ключевое слово
Функция, из которой мы хотим сделать полифилл — это новое (предположим, что оно новое) ключевое слово
Вот пример использования random:
Как видите, поскольку
На протяжении всей остальной статьи мы будем работать с демо-страницей, которую я показывал в своей лекции. Вот как она выглядит:
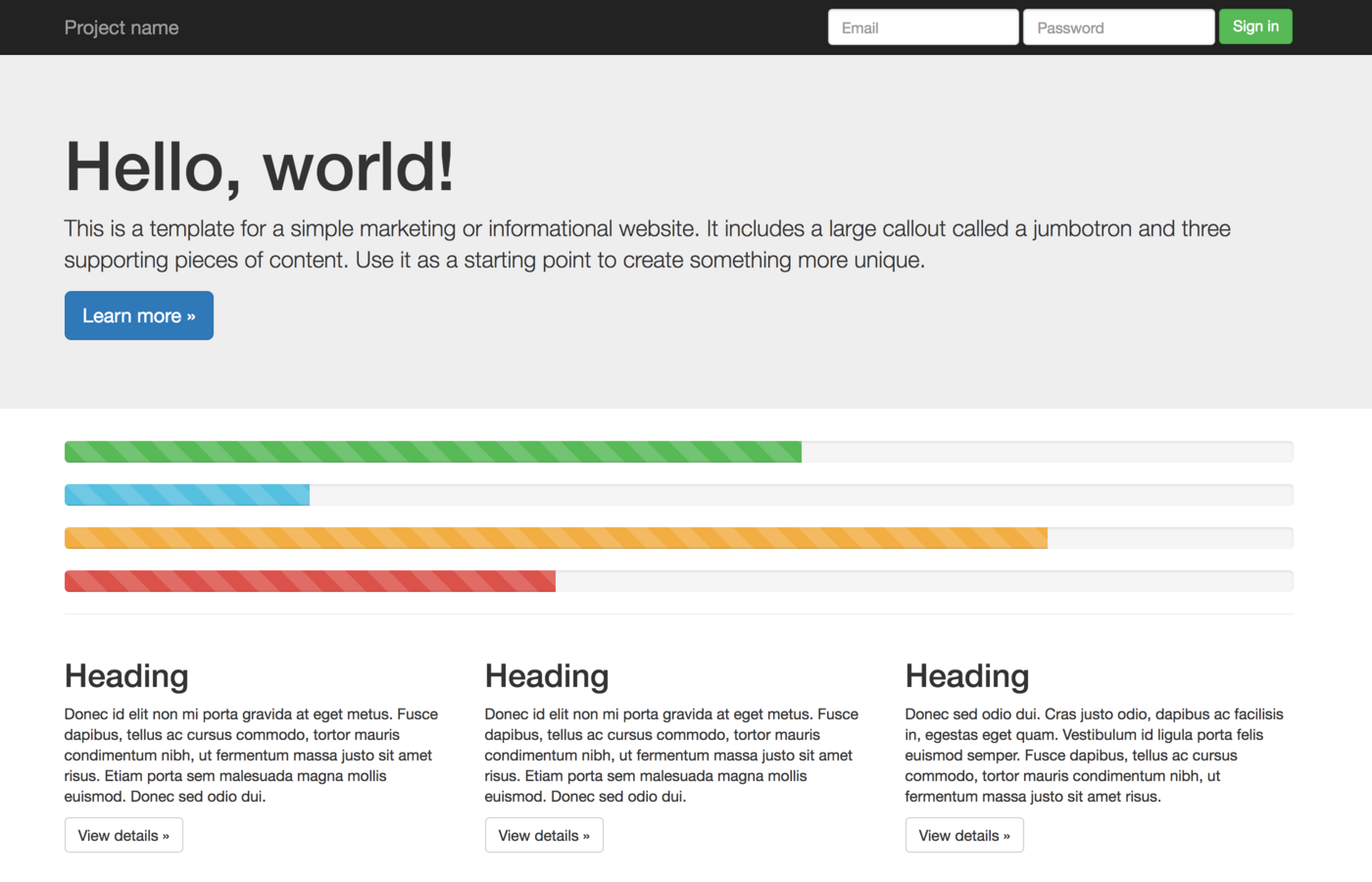
Пример, как может выглядеть сайт, где используется ключевое слово
Это базовая страница “Hello World” из стартового шаблона Bootstrap, где в верхнюю часть области контента добавлены четыре элемента
Кроме
Хотя на моей демо-странице явно указана значения ширины индикаторов выполнения, идея в том, что при использовании полифиллов каждый раз при загрузке страницы эти индикаторы будут иметь разную, случайную ширину.
В JavaScript полифиллы относительно просто написать, потому что язык настолько динамичный и позволяет вам изменять встроенные объекты в реальном времени.
Например, если хотите сделать полифилл из
С другой стороны, CSS не настолько динамичен. Невозможно (по крайней мере, пока) изменить среду выполнения таким образом, чтобы сообщить браузеру о новой функции, которую он нативно не поддерживает.
Это значит, что для применения полифилла с функцией в CSS, которую браузер не поддерживает, вам придётся динамически изменить CSS, чтобы подделать поведение функции с помощью функций CSS, которые браузер поддерживает.
Другими словами, вам нужно превратить это:
в нечто вроде такого, что случайно генерируется во время выполнения кода в браузере:
Теперь мы знаем, что нам нужно изменить существующий CSS и добавить новые правила стилей, которые имитируют поведение функции из полифилла.
Наиболее естественным местом, где вы могли бы предположить возможность совершения такого действия, будет CSS Object Model (CSSOM), доступный через
Примечание: в настоящем полифилле вы не будете использовать простую функцию поиска и замены слова
Если загрузить демо № 2, вставить вышеприведённый код в консоль JavaScript и запустить, то он реально сделает то, что должен делать, но после его выполнения вы не увидите никаких индикаторов выполнения случайной ширины.
Причина в том, что в CSSOM нет ни одного правила с ключевым словом
Как вы наверное уже знаете, если браузер встречает правило CSS, которое не понимает, то просто игнорирует его. В большинстве случаев это хорошо, потому что так вы можете загружать CSS в старые браузеры и не поломаете страницу. К сожалению, это также означает, что если вам нужен доступ к изначальному, неизменённому CSS, то придётся доставать его самостоятельно.
Правила CSS можно добавить на страницу с помощью или элементов
Следующий код определяет функцию
Если открыть демо № 3 и вставить вышеприведённый код в консоль JavaScript для установки функции
Когда вы получили оригинальный текст CSS, нужно осуществить парсинг.
Вы можете подумать, что если в браузере уже есть встроенный парсер, то можно вызвать какую-то функцию и распарсить CSS. К сожалению, так не получится. И даже если бы браузер давал доступ к функции
Есть несколько хороших open source парсеров CSS, и для целей данного демо мы будем использовать PostCSS (поскольку он работает как браузер и поддерживает систему плагинов, которая пригодится нам позже).
Если запустить
то получим что-то вроде такого:
Это то, что известно как абстрактное синтаксическое дерево (АСД), а вы можете представить его как собственную версию CSSOM.
Теперь у нас есть служебная функция для получения полного текста CSS и функция для его парсинга, тогда вот как выглядит наш полифилл на данный момент:
Если открыть демо № 4 и посмотреть в консоль JavaScript, то увидите лог объекта, содержащий полное АСД для PostCSS для всех стилей на странице.
К настоящему моменту мы написали много кода, но удивительно, что он совершенно не связан с реальной функциональностью нашего полифилла. Это была просто необходимая платформа для того, чтобы вручную сделать много вещей, которые браузер должен был сделать за нас.
Для реальной реализации логики полифилла нам нужно:
PostCSS поставляется с хорошей системой плагинов со многими вспомогательными функциями для модификации абстрактного синтаксического дерева CSS. Мы можем использовать эти функции, чтобы заменить встреченные
Ещё одна приятная особенность использования плагинов PostCSS — у них уже есть встроенная логика для вставки АСД в строковом виде обратно в CSS. Всё что нужно сделать — это создать инстанс PostCSS, передать его плагину (или плагинам), которые вы хотите использовать, и запустить
Для замены стилей страницы мы можем написать служебную функцию (похожую на
Вооружённые нашим плагином PostCSS для изменения АСД CSS и двумя служебными функциями для извлечения и обновления стилей страниц, код нашего полифилла теперь выглядит так:
Если откроете демо № 5, то можете увидеть его в действии. Обновите страницу несколько раз, чтобы почувствовать настоящую случайность!
… хм-м-м-м-м, не совсем то, что вы ожидали, не так ли?
Хотя плагин технически работает, он вставляет одно и то же случайное значение для каждого элемента, который соответствует функции замены.
Это полностью логично, если подумать о то, что мы сделали — мы просто заменили единственное свойство на единственное правило.
Правда в том, что даже простейшие полифиллы CSS требуют больше чем переписывания отдельных значений свойств. Большинство из них требуют ещё знания DOM, а также конкретных деталей (size, contents, order и т. д.) отдельных элементов, соответствующих требованиям. Вот почему препроцессоров и серверных решений для этой проблемы никогда не будет достаточно самих по себе.
Но встаёт важный вопрос: как нам обновить полифилл, чтобы определить отдельные элементы?.
По моему опыту, есть три варианта определения отдельных элементов DOM, но все они недостаточно хороши.
Как показывает практика, чаще всего авторы полифиллов решают проблему определения отдельных элементов с помощью селектора правил CSS, чтобы найти подходящие элементы на странице и напрямую применить инлайновые стили к ним.
Вот как нужно изменить наш плагин PostCSS именно таким образом:
Демо № 6 показывает этот код в действии.
Поначалу он вроде работает нормально, но его, к сожалению, легко сбить. Предположим, что мы обновили CSS и добавили ещё одно правило после нашего правила
Код вверху декларирует, что элементы всех индикаторов загрузки на страницы должны иметь случайную ширину, кроме тех элементов индикаторов загрузки, которые зависят от элемента с идентификатором
Конечно, это не сработает, потому что мы применяем инлайновые стили напрямую к элементу. Значит, эти стили будут более специфичными, чем стили, определённые в
Это означает, что наш полифилл не соответствует некоторым фундаментальным предположениям о работе с CSS (так что лично я нахожу этот способ неприемлемым).
Второй вариант допускает, что во многих случаях реального применения первый вариант не срабатывает, так что он пытается исправить ситуацию. В частности, во втором варианте мы обновляем нашу реализацию, чтобы:
Да, если вы не поняли, я только что описал каскад, выполнение которого предполагает зависимость от браузера.
Хотя определённо возможно заново реализовать такой каскад на JavaScript, тут будет немало работы, так что я определённо посмотрел бы, что там в варианте № 3.
Третий вариант — который я считаю лучшим среди худших — это переписать CSS и преобразовать правила с одним селектором, который соответствует многим элементам, в несколько правил, каждое из которых будет соответствовать только одному элементу, при этом не меняя окончательный набор элементов.
Поскольку последнее предложение выглядит не вполне осмысленно, позвольте проиллюстрировать это примером. Рассмотрим файл CSS, который включен в страницу и содержит три элемента параграфа:
Если мы добавим уникальный атрибут данных к каждому параграфу в DOM, то можем переписать CSS следующим образом, чтобы определять каждый параграф своим собственным, индивидуальным правилом:
Конечно, если вы заметили, такой вариант всё ещё не очень хорошо работает, потому что влияет на специфичность этих селекторов, что вероятно приведёт к непредусмотренным побочным эффектам. Однако, мы можем обеспечить сохранение правильного каскадного порядка, увеличив специфичность всех остальных селекторов на странице на то же количество, применив такой умный хак:
Изменения выше применяют функциональный селектор псевдокласса
Демо № 7 показывает результат реализации такой стратегии, и вы можете посмотреть исходный код демо и изучить полный набор изменений в плагине
Самое лучшее в третьем варианте то, что он продолжает давать браузеру обрабатывать каскад, в чём браузер действительно хорош. Это значит, что вы можете использовать запросы media, декларации
Может показаться, что способом № 3 я решил все проблемы с полифиллами CSS, но это очень далеко от истины. По-прежнему остаётся много проблем, некоторые из которых можно решить (затратив много дополнительного времени), а другие — невозможно, и поэтому они неизбежны.
Прежде всего, я умышленно оставил без внимания некоторые части CSS, которые могут существовать на странице, но недоступны для запросов DOM по тегам
Мы можем обновить наш полифилл для этих случаев, но для этого потребуется много дополнительной работы, которую я не хотел бы обсуждать в этой статье.
Ещё мы даже не рассматривали того, что случится при изменении DOM. В конце концов, мы переписываем наш CSS в соответствии со структурой DOM. Это значит, что нам придётся переписывать каждый раз, когда DOM изменится.
Кроме вышеописанных проблем (которые трудные, но разрешимые), существуют некоторые проблемы, которых невозможно избежать:
Наш полифилл для ключевого слова
Одно решение, которое я пропустил в своей лекции (из-за ограниченного времени), может потенциально смягчить первые две из трёх вышеуказанных проблем. Это парсинг и выборка CSS на стороне сервера на этапе построения.
Затем вместо загрузки файла CSS со стилями вы загружаете файл JavaScript, который содержит АСД. Тогда первым делом вы переведёте АСД в строковый вид и добавите стили на страницу. Вы можете даже включить тег
Например, вместо такого:
у вас будет это:
Как я упомянул, это решает проблему необходимости включать полный парсер CSS в ваш комплект JavaScript и также позволяет заблаговременно парсить CSS, но не решает всех проблем с производительностью.
Но в любом случае вам всегда придётся переписывать CSS, как только потребуются изменения.
Чтобы понять, почему производительность полифиллов настолько низкая, вам в самом деле нужно понять конвейер рендеринга в браузере — особенно те шаги рендеринга, к которым вы имеете доступ как разработчик.
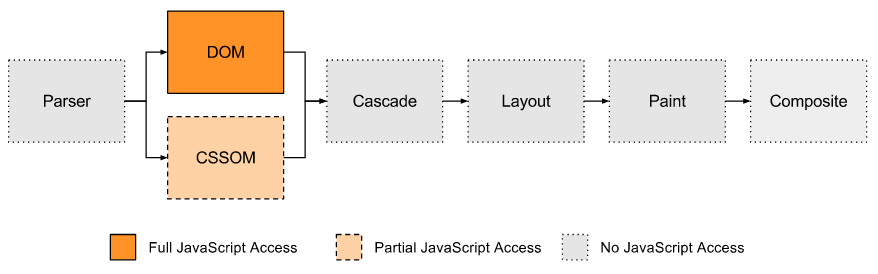
Доступ JavaScript к конвейеру рендеринга в браузере
Как видите, единственной реальной точкой входа является DOM, которую наш полифилл использовал посредством запросов элементов, соответствующих селектору CSS, а также путём обновления текста CSS в теге
Но с учётом текущего механизма доступа JavaScript к конвейеру рендеринга в браузере, вот какой путь приходится выбрать нашему полифиллу.
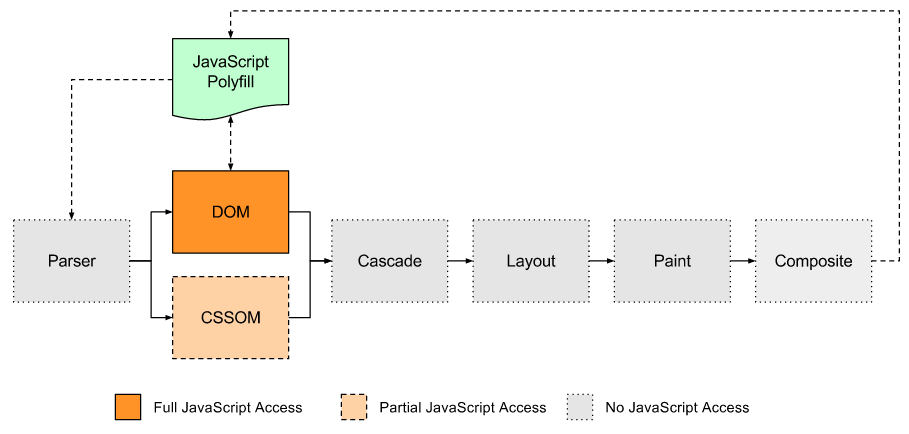
Точки входа полифилла в конвейер рендеринга в браузере
Как видите, JavaScript не может вмешиваться в исходный конвейер рендеринга после создания DOM, так что любые внесённые полифиллом изменения заставляют начать процесс рендеринга сначала.
Это означает, что полифиллы CSS никак не могут работать на 60 fps, поскольку все обновления приводят к последующему рендерингу и поэтому к последующему фрейму.
Хотелось бы, чтобы из этой статьи вы вынесли понимание, что создание полифиллов на CSS особенно трудно, потому что вся наша работа как разработчиков заключается в обходе ограничений стилей и вёрстки современного веба.
Вот список вещей, которые наш полифилл должен сделать самостоятельно — это вещи, которые браузер уже делает, но мы как разработчики не имеем доступа к этим функциям:
И это именно то, что меня восхищает в Houdini. Без программных интерфейсов Houdini разработчикам придётся прибегать к хакам и обходным путям, что ведёт к снижению производительности и удобства для пользователей.
И это означает, что полифиллы обязательно будут либо:
К сожалению, избавиться от всех трёх недостатков мы не можем. Приходится выбирать.
Без примитивов стилизации низкого уровня инновации будут двигаться со скоростью самого медленного браузера.
Разработчики из сообщества JavaScript жалуются на большую скорость внедрения инноваций. Но вы никогда не услышите такого в CSS. И частично из-за ограничений, описанных в статье.
Думаю, нам нужно это изменить. Думаю, нам нужно #makecssfatigueathing.
Хотя та статья была в целом хорошо принята, один и тот же вопрос постоянно задавали мне в письмах и твиттере. Основная суть вопроса:
Что такого сложного в полифиллах CSS? Я использую много полифиллов CSS, и они у меня нормально работают.
И я понял — конечно же, у людей возникают такие вопросы. Если вы никогда не пробовали сами написать полифилл CSS, то, вероятно, никогда не испытывали эту боль.
Так что лучший способ ответить на этот вопрос — и объяснить, почему меня так восхищает Houdini — это наглядно показать, почему настолько трудно использовать полифиллы CSS.
И лучший способ сделать это — написать полифилл самим.
Примечание: эта статья представляет собой текстовую версию лекции, которую я прочитал на dotCSS 2 декабря 2016 года. В статье рассматривается чуть больше подробностей, но если вы предпочитаете посмотреть видео, я его тоже вставил сюда.
Ключевое слово random
Функция, из которой мы хотим сделать полифилл — это новое (предположим, что оно новое) ключевое слово
random, которое возвращает число между 0 и 1 (так же, как Math.random() в JavaScript). Вот пример использования random:
.foo {
color: hsl(calc(random * 360), 50%, 50%);
opacity: random;
width: calc(random * 100%);
}Как видите, поскольку
random возвращает безразмерное число, то его можно использовать с calc(), чтобы превратить практически в любое значение. И поскольку у него может быть любое значение, то его можно применить с любым свойством (например, color, opacity, width и т. д.).На протяжении всей остальной статьи мы будем работать с демо-страницей, которую я показывал в своей лекции. Вот как она выглядит:
Пример, как может выглядеть сайт, где используется ключевое слово
randomЭто базовая страница “Hello World” из стартового шаблона Bootstrap, где в верхнюю часть области контента добавлены четыре элемента
.progress-bar.Кроме
bootstrap.css, она содержит ещё один файл CSS со следующим правилом:.progress-bar {
width: calc(random * 100%);
}Хотя на моей демо-странице явно указана значения ширины индикаторов выполнения, идея в том, что при использовании полифиллов каждый раз при загрузке страницы эти индикаторы будут иметь разную, случайную ширину.
Как работают полифиллы
В JavaScript полифиллы относительно просто написать, потому что язык настолько динамичный и позволяет вам изменять встроенные объекты в реальном времени.
Например, если хотите сделать полифилл из
Math.random(), то пишете что-то вроде такого:if (typeof Math.random != 'function') {
Math.random = function() {
// Implement polyfill here...
};
}С другой стороны, CSS не настолько динамичен. Невозможно (по крайней мере, пока) изменить среду выполнения таким образом, чтобы сообщить браузеру о новой функции, которую он нативно не поддерживает.
Это значит, что для применения полифилла с функцией в CSS, которую браузер не поддерживает, вам придётся динамически изменить CSS, чтобы подделать поведение функции с помощью функций CSS, которые браузер поддерживает.
Другими словами, вам нужно превратить это:
.foo {
width: calc(random * 100%);
}в нечто вроде такого, что случайно генерируется во время выполнения кода в браузере:
.foo {
width: calc(0.35746 * 100%);
}Изменение CSS
Теперь мы знаем, что нам нужно изменить существующий CSS и добавить новые правила стилей, которые имитируют поведение функции из полифилла.
Наиболее естественным местом, где вы могли бы предположить возможность совершения такого действия, будет CSS Object Model (CSSOM), доступный через
document.styleSheets. Код может выглядеть примерно так:for (const stylesheet of document.styleSheets) {
// Flatten nested rules (@media blocks, etc.) into a single array.
const rules = [...stylesheet.rules].reduce((prev, next) => {
return prev.concat(next.cssRules ? [...next.cssRules] : [next]);
}, []);
// Loop through each of the flattened rules and replace the
// keyword `random` with a random number.
for (const rule of rules) {
for (const property of Object.keys(rule.style)) {
const value = rule.style[property];
if (value.includes('random')) {
rule.style[property] = value.replace('random', Math.random());
}
}
}
}Примечание: в настоящем полифилле вы не будете использовать простую функцию поиска и замены слова
random, потому что оно может присутствовать в разных формах, а не только в ключевом слове (например, в URL, в названии какого-то свойства, в закавыченном тексте в свойстве content и т. д.). Реальный код в окончательной версии демо использует более надёжный механизм замены, но для простоты я здесь использую упрощённую версию.Если загрузить демо № 2, вставить вышеприведённый код в консоль JavaScript и запустить, то он реально сделает то, что должен делать, но после его выполнения вы не увидите никаких индикаторов выполнения случайной ширины.
Причина в том, что в CSSOM нет ни одного правила с ключевым словом
random!Как вы наверное уже знаете, если браузер встречает правило CSS, которое не понимает, то просто игнорирует его. В большинстве случаев это хорошо, потому что так вы можете загружать CSS в старые браузеры и не поломаете страницу. К сожалению, это также означает, что если вам нужен доступ к изначальному, неизменённому CSS, то придётся доставать его самостоятельно.
Извлечение стилей страниц вручную
Правила CSS можно добавить на страницу с помощью или элементов
<style>, или <link rel="stylesheet">, так что для получения изначального, неизменённого CSS вы можете применить querySelectorAll() на документе и вручную достать содержимое любых тегов <style> или применить fetch(), получив URL ресурсов для всех тегов <link rel="stylesheet">.Следующий код определяет функцию
getPageStyles, которая должна вернуть полный код CSS для всех стилей страницы:const getPageStyles = () => {
// Query the document for any element that could have styles.
var styleElements =
[...document.querySelectorAll('style, link[rel="stylesheet"]')];
// Fetch all styles and ensure the results are in document order.
// Resolve with a single string of CSS text.
return Promise.all(styleElements.map((el) => {
if (el.href) {
return fetch(el.href).then((response) => response.text());
} else {
return el.innerHTML;
}
})).then((stylesArray) => stylesArray.join('\n'));
}Если открыть демо № 3 и вставить вышеприведённый код в консоль JavaScript для установки функции
getPageStyles(), то вы сможете запустить код ниже, чтобы получить лог полного текста CSS:getPageStyles().then((cssText) => {
console.log(cssText);
});Парсинг извлечённых стилей
Когда вы получили оригинальный текст CSS, нужно осуществить парсинг.
Вы можете подумать, что если в браузере уже есть встроенный парсер, то можно вызвать какую-то функцию и распарсить CSS. К сожалению, так не получится. И даже если бы браузер давал доступ к функции
parseCSS(), это не отменяет того факта, что браузер не понимает ключевое слово random, так что функция parseCSS(), вероятно, всё равно не будет работать (есть надежда, что будущие спецификации парсинга позволяет обработку незнакомых ключевых слов, которые иным образом совместимы с существующим синтаксисом).Есть несколько хороших open source парсеров CSS, и для целей данного демо мы будем использовать PostCSS (поскольку он работает как браузер и поддерживает систему плагинов, которая пригодится нам позже).
Если запустить
postcss.parse() на следующем тексте CSS:.progress-bar {
width: calc(random * 100%);
}то получим что-то вроде такого:
{
"type": "root",
"nodes": [
{
"type": "rule",
"selector": ".progress-bar",
"nodes": [
{
"type": "decl",
"prop": "width",
"value": "calc(random * 100%)"
}
]
}
]
}Это то, что известно как абстрактное синтаксическое дерево (АСД), а вы можете представить его как собственную версию CSSOM.
Теперь у нас есть служебная функция для получения полного текста CSS и функция для его парсинга, тогда вот как выглядит наш полифилл на данный момент:
import postcss from 'postcss';
import getPageStyles from './get-page-styles';
getPageStyles()
.then((css) => postcss.parse(css))
.then((ast) => console.log(ast));Если открыть демо № 4 и посмотреть в консоль JavaScript, то увидите лог объекта, содержащий полное АСД для PostCSS для всех стилей на странице.
Внедрение полифилла
К настоящему моменту мы написали много кода, но удивительно, что он совершенно не связан с реальной функциональностью нашего полифилла. Это была просто необходимая платформа для того, чтобы вручную сделать много вещей, которые браузер должен был сделать за нас.
Для реальной реализации логики полифилла нам нужно:
- Изменить АСД CSS, заменить встреченные
randomслучайным числом. - Вставить изменённое АСД в строковом виде обратно в CSS.
- Заменить существующие стили страниц на изменённые стили.
Изменение абстрактного синтаксического дерева CSS
PostCSS поставляется с хорошей системой плагинов со многими вспомогательными функциями для модификации абстрактного синтаксического дерева CSS. Мы можем использовать эти функции, чтобы заменить встреченные
random случайным числом:const randomKeywordPlugin = postcss.plugin('random-keyword', () => {
return (css) => {
css.walkRules((rule) => {
rule.walkDecls((decl, i) => {
if (decl.value.includes('random')) {
decl.value = decl.value.replace('random', Math.random());
}
});
});
};
});Вставка АСД в строковом виде обратно в CSS
Ещё одна приятная особенность использования плагинов PostCSS — у них уже есть встроенная логика для вставки АСД в строковом виде обратно в CSS. Всё что нужно сделать — это создать инстанс PostCSS, передать его плагину (или плагинам), которые вы хотите использовать, и запустить
process(), который должен вернуть объект с CSS в строковом виде:postcss([randomKeywordPlugin]).process(css).then((result) => {
console.log(result.css);
});Замена стилей страницы
Для замены стилей страницы мы можем написать служебную функцию (похожую на
getPageStyles()), которая находит все элементы <style> и <link rel="stylesheet"> и удаляет их. Она также создаёт новый тег <style> и устанавливает содержимое стиля на любой текст CSS, который передан функции:const replacePageStyles = (css) => {
// Get a reference to all existing style elements.
const existingStyles =
[...document.querySelectorAll('style, link[rel="stylesheet"]')];
// Create a new <style> tag with all the polyfilled styles.
const polyfillStyles = document.createElement('style');
polyfillStyles.innerHTML = css;
document.head.appendChild(polyfillStyles);
// Remove the old styles once the new styles have been added.
existingStyles.forEach((el) => el.parentElement.removeChild(el));
};Собираем всё вместе
Вооружённые нашим плагином PostCSS для изменения АСД CSS и двумя служебными функциями для извлечения и обновления стилей страниц, код нашего полифилла теперь выглядит так:
import postcss from 'postcss';
import getPageStyles from './get-page-styles';
import randomKeywordPlugin from './random-keyword-plugin';
import replacePageStyles from './replace-page-styles';
getPageStyles()
.then((css) => postcss([randomKeywordPlugin]).process(css))
.then((result) => replacePageStyles(result.css));Если откроете демо № 5, то можете увидеть его в действии. Обновите страницу несколько раз, чтобы почувствовать настоящую случайность!
… хм-м-м-м-м, не совсем то, что вы ожидали, не так ли?
Что пошло не так
Хотя плагин технически работает, он вставляет одно и то же случайное значение для каждого элемента, который соответствует функции замены.
Это полностью логично, если подумать о то, что мы сделали — мы просто заменили единственное свойство на единственное правило.
Правда в том, что даже простейшие полифиллы CSS требуют больше чем переписывания отдельных значений свойств. Большинство из них требуют ещё знания DOM, а также конкретных деталей (size, contents, order и т. д.) отдельных элементов, соответствующих требованиям. Вот почему препроцессоров и серверных решений для этой проблемы никогда не будет достаточно самих по себе.
Но встаёт важный вопрос: как нам обновить полифилл, чтобы определить отдельные элементы?.
Определение отдельных соответствующих элементов
По моему опыту, есть три варианта определения отдельных элементов DOM, но все они недостаточно хороши.
Вариант № 1: инлайновые стили
Как показывает практика, чаще всего авторы полифиллов решают проблему определения отдельных элементов с помощью селектора правил CSS, чтобы найти подходящие элементы на странице и напрямую применить инлайновые стили к ним.
Вот как нужно изменить наш плагин PostCSS именно таким образом:
// ...
rule.walkDecls((decl, i) => {
if (decl.value.includes('random')) {
const elements = document.querySelectorAll(rule.selector);
for (const element of elements) {
element.style[decl.prop] =
decl.value.replace('random', Math.random());
}
}
});
// ...Демо № 6 показывает этот код в действии.
Поначалу он вроде работает нормально, но его, к сожалению, легко сбить. Предположим, что мы обновили CSS и добавили ещё одно правило после нашего правила
.progress-bar..progress-bar {
width: calc(random * 100%);
}
#some-container .progress-bar {
width: auto;
}Код вверху декларирует, что элементы всех индикаторов загрузки на страницы должны иметь случайную ширину, кроме тех элементов индикаторов загрузки, которые зависят от элемента с идентификатором
#some-container. В этом случае ширина не должна быть случайной.Конечно, это не сработает, потому что мы применяем инлайновые стили напрямую к элементу. Значит, эти стили будут более специфичными, чем стили, определённые в
#some-container .progress-bar.Это означает, что наш полифилл не соответствует некоторым фундаментальным предположениям о работе с CSS (так что лично я нахожу этот способ неприемлемым).
Вариант № 2: инлайновые стили
Второй вариант допускает, что во многих случаях реального применения первый вариант не срабатывает, так что он пытается исправить ситуацию. В частности, во втором варианте мы обновляем нашу реализацию, чтобы:
- Проверить остальной CSS на наличие соответствующих правил, а затем заменить ключевое слово random случайным числом и применить эти декларации в виде инлайновых стилей только в том случае, если это последнее соответствующее правило.
- Погодите, это же не работает, потому что нужно учитывать специфичность, так что придётся вручную парсить каждый селектор для вычисления. Тогда мы можем сортировать соответствующие правила в возрастающем порядке специфичности и применять декларации только с самого специфичного селектора.
- Ох, а ещё есть элементы
@media, так что здесь тоже нужно вручную проверять соответствие.
- И если говорить о нарушениях правил, то есть ещё
@supports— не забудем о нём.
- И последнее: нужно учитывать наследование свойств, так что для каждого элемента придётся пройтись по дереву DOM и проверить все родительские элементы, чтобы получить полный набор вычисленных свойств.
- Ой извините, ещё кое-что: нужно также учитывать декларацию
!important, которая вычисляется для каждого свойства, а не для каждого правила. Поэтому требуется сохранить отдельную карту для них, чтобы выяснить, какая декларация в итоге выиграет.
Да, если вы не поняли, я только что описал каскад, выполнение которого предполагает зависимость от браузера.
Хотя определённо возможно заново реализовать такой каскад на JavaScript, тут будет немало работы, так что я определённо посмотрел бы, что там в варианте № 3.
Вариант № 3: переписать CSS для определения отдельных соответствующих элементов, сохраняя каскадный порядок
Третий вариант — который я считаю лучшим среди худших — это переписать CSS и преобразовать правила с одним селектором, который соответствует многим элементам, в несколько правил, каждое из которых будет соответствовать только одному элементу, при этом не меняя окончательный набор элементов.
Поскольку последнее предложение выглядит не вполне осмысленно, позвольте проиллюстрировать это примером. Рассмотрим файл CSS, который включен в страницу и содержит три элемента параграфа:
* {
box-sizing: border-box;
}
p { /* Will match 3 paragraphs on the page. */
opacity: random;
}
.foo {
opacity: initial;
}Если мы добавим уникальный атрибут данных к каждому параграфу в DOM, то можем переписать CSS следующим образом, чтобы определять каждый параграф своим собственным, индивидуальным правилом:
* {
box-sizing: border-box;
}
p[data-pid="1"] {
opacity: .23421;
}
p[data-pid="2"] {
opacity: .82305;
}
p[data-pid="3"] {
opacity: .31178;
}
.foo {
opacity: initial;
}Конечно, если вы заметили, такой вариант всё ещё не очень хорошо работает, потому что влияет на специфичность этих селекторов, что вероятно приведёт к непредусмотренным побочным эффектам. Однако, мы можем обеспечить сохранение правильного каскадного порядка, увеличив специфичность всех остальных селекторов на странице на то же количество, применив такой умный хак:
*?:not(.z) {
box-sizing: border-box;
}
p[data-pid="1"] {
opacity: .23421;
}
p[data-pid="2"] {
opacity: .82305;
}
p[data-pid="3"] {
opacity: .31178;
}
.foo:not(.z) {
opacity: initial;
}Изменения выше применяют функциональный селектор псевдокласса
:not() и передают ему имя класса, которого точно нет в DOM (в данном случае я выбрал .z;, так что если вы используете класс .z; в DOM, то придётся выбрать другое имя). И поскольку :not() всегда соответствует несуществующему элементу, его можно использовать для увеличения специфичности селектора без изменения его соответствия.Демо № 7 показывает результат реализации такой стратегии, и вы можете посмотреть исходный код демо и изучить полный набор изменений в плагине
random-keyword.Самое лучшее в третьем варианте то, что он продолжает давать браузеру обрабатывать каскад, в чём браузер действительно хорош. Это значит, что вы можете использовать запросы media, декларации
!important, нестандартные свойства, правила @support или любые функции CSS, и всё будет нормально работать.Недостатки
Может показаться, что способом № 3 я решил все проблемы с полифиллами CSS, но это очень далеко от истины. По-прежнему остаётся много проблем, некоторые из которых можно решить (затратив много дополнительного времени), а другие — невозможно, и поэтому они неизбежны.
Нерешённые проблемы
Прежде всего, я умышленно оставил без внимания некоторые части CSS, которые могут существовать на странице, но недоступны для запросов DOM по тегам
<style> и <link rel="stylesheet">:- Инлайновые стили
- Теневая модель документа (Shadow DOM)
Мы можем обновить наш полифилл для этих случаев, но для этого потребуется много дополнительной работы, которую я не хотел бы обсуждать в этой статье.
Ещё мы даже не рассматривали того, что случится при изменении DOM. В конце концов, мы переписываем наш CSS в соответствии со структурой DOM. Это значит, что нам придётся переписывать каждый раз, когда DOM изменится.
Неизбежные проблемы
Кроме вышеописанных проблем (которые трудные, но разрешимые), существуют некоторые проблемы, которых невозможно избежать:
- Требуется огромное количество дополнительного кода.
- Способ не работает с таблицами стилей cross-origin (non-CORS).
- Полифилл ужасно работает, если/когда нужны изменения (например, изменения DOM, обработчики прокрутки/изменения размера и т. д.).
Наш полифилл для ключевого слова
random — достаточно простой пример. Но я уверен, что вы можете легко представить себе полифиллы для чего-то вроде position: sticky, и тогда всю описанную здесь логику нужно будет перезапускать каждый раз, когда пользователь осуществил прокрутку страницы, что совершенно ужасно скажется на производительности.Возможности для улучшения
Одно решение, которое я пропустил в своей лекции (из-за ограниченного времени), может потенциально смягчить первые две из трёх вышеуказанных проблем. Это парсинг и выборка CSS на стороне сервера на этапе построения.
Затем вместо загрузки файла CSS со стилями вы загружаете файл JavaScript, который содержит АСД. Тогда первым делом вы переведёте АСД в строковый вид и добавите стили на страницу. Вы можете даже включить тег
<noscript>, который ссылается на оригинальный файл CSS в том случае, если пользователь отключил JavaScript.Например, вместо такого:
<link ref="stylesheet" href="styles.css">у вас будет это:
<script src="styles.css.js"></script>
<noscript><link ref="stylesheet" href="styles.css"></noscript>Как я упомянул, это решает проблему необходимости включать полный парсер CSS в ваш комплект JavaScript и также позволяет заблаговременно парсить CSS, но не решает всех проблем с производительностью.
Но в любом случае вам всегда придётся переписывать CSS, как только потребуются изменения.
Понимание последствий для производительности
Чтобы понять, почему производительность полифиллов настолько низкая, вам в самом деле нужно понять конвейер рендеринга в браузере — особенно те шаги рендеринга, к которым вы имеете доступ как разработчик.
Доступ JavaScript к конвейеру рендеринга в браузере
Как видите, единственной реальной точкой входа является DOM, которую наш полифилл использовал посредством запросов элементов, соответствующих селектору CSS, а также путём обновления текста CSS в теге
<style>.Но с учётом текущего механизма доступа JavaScript к конвейеру рендеринга в браузере, вот какой путь приходится выбрать нашему полифиллу.
Точки входа полифилла в конвейер рендеринга в браузере
Как видите, JavaScript не может вмешиваться в исходный конвейер рендеринга после создания DOM, так что любые внесённые полифиллом изменения заставляют начать процесс рендеринга сначала.
Это означает, что полифиллы CSS никак не могут работать на 60 fps, поскольку все обновления приводят к последующему рендерингу и поэтому к последующему фрейму.
Подведение итогов
Хотелось бы, чтобы из этой статьи вы вынесли понимание, что создание полифиллов на CSS особенно трудно, потому что вся наша работа как разработчиков заключается в обходе ограничений стилей и вёрстки современного веба.
Вот список вещей, которые наш полифилл должен сделать самостоятельно — это вещи, которые браузер уже делает, но мы как разработчики не имеем доступа к этим функциям:
- Выборка CSS
- Парсинг CSS
- Создание CSSOM
- Обработка каскада
- Инвалидация стилей
- Повторная валидация стилей
И это именно то, что меня восхищает в Houdini. Без программных интерфейсов Houdini разработчикам придётся прибегать к хакам и обходным путям, что ведёт к снижению производительности и удобства для пользователей.
И это означает, что полифиллы обязательно будут либо:
- Слишком большие
- Слишком медленные
- Слишком неправильные
К сожалению, избавиться от всех трёх недостатков мы не можем. Приходится выбирать.
Без примитивов стилизации низкого уровня инновации будут двигаться со скоростью самого медленного браузера.
Разработчики из сообщества JavaScript жалуются на большую скорость внедрения инноваций. Но вы никогда не услышите такого в CSS. И частично из-за ограничений, описанных в статье.
Думаю, нам нужно это изменить. Думаю, нам нужно #makecssfatigueathing.
Поделиться с друзьями