
В нашем случае диски пронумерованы представителем заказчика от 0 до 9 со словами: «именно в таком порядке они были использованы в массиве, и никто их местами не менял». Данное утверждение подлежит обязательной проверке. Также мы были поставлены в известность, что данный массив использовался в качестве хранилища для ESXi сервера, и на нем должно содержаться несколько десятков виртуальных машин.
Перед тем, как начать любые операции над дисками из массива, необходимо проверить их физическую целостность и исправность, а также создать копии и далее работать исключительно с копиями для безопасного проведения работ. При наличии серьезно поврежденных накопителей рассмотреть необходимость проведения работ по извлечению данных, то есть если серьезно поврежден только один накопитель, то необходимо выяснить посредством анализа массива, собранного из оставшихся дисков, содержал ли проблемный HDD актуальные данные, или им нужно пренебречь и получить недостающие данные за счет XOR операции над остальными участниками одного из RAID 5, в который входил данный диск.
Было выполнено создание копий, в результате которого выяснилось, что 4 накопителя имеют дефекты между LBA 424 000 000 и LBA 425 000 000, выражается это в виде нечитаемых нескольких десятков секторов на каждом из проблемных дисков. Непрочитанные сектора в копиях заполняем паттерном 0xDE 0xAD для того, чтобы потом была возможность идентификации пострадавших данных.
Первичный анализ подразумевает идентификацию RAID контроллера, к которому были подключены диски, точнее идентификацию расположения метаданных RAID контроллера, чтобы эти области не включать при сборке в массив.

В данном случае в последнем секторе каждого из дисков обнаруживаем характерные 0xDE 0x11 0xDE 0x11 c дальнейшей пометкой бренда RAID контроллера. Метаданные данного контроллера располагаются исключительно в конце LBA диапазона, какие-либо буферные зоны в середине диапазона данным контроллером не используются. На основании этого и предыдущих данных следует вывод, что сбор массива должен начинаться с LBA 0 каждого из дисков.
Зная, что суммарная емкость массива более 2 TB, проводим поиск в LBA 0 каждого из дисков таблицы разделов (защитной MBR)

и GPT заголовка в LBA 1.

В этом случае данных структур не обнаружено. Данные структуры обычно становятся жертвами необдуманных действий обслуживающего сервер персонала, который не отрабатывал ситуации отказа системы хранения данных и не изучал особенностей работы конкретного RAID контроллера.
Для дальнейшего анализа особенностей массива необходимо произвести на одном из дисков поиск регулярных выражений монотонно возрастающих последовательностей. Это могут быть как таблицы FAT или достаточно большой фрагмент MFT, так и иные удобные для анализа структуры. Зная, что на данном массиве содержались виртуальные машины с ОС Windows, мы можем предположить, что внутри данных машин использовалась файловая система NTFS. На основании этого проводим поиск записей MFT по характерному регулярному выражению 0x46 0x49 0x4C 0x45 с нулевым смещением относительно 512-байтного блока (сектора). В нашем случае после LBA 2 400 000 (1,2GB) обнаруживается достаточно протяженный (более 5000 записей) фрагмент MFT. В нашем случае размер записи MFT стандартный и составляет 1024 байт (2 сектора).

Локализуем границы найденного фрагмента с записями MFT и проверим наличие фрагмента с записями MFT в этих границах на остальных дисках-участниках массива (границы могут чуть-чуть отличаться, но не более чем на размер блока, используемого в RAID массиве). В нашем случае наличие записей MFT подтверждается. Листаем записи с анализом номеров (номер DWORD располагается по смещению 0x2C). Анализируем количество блоков, где возрастание номера записи MFT происходит с изменением на единицу, на основании этого рассчитываем размер блока, используемого в данном RAID массиве. В нашем случае размер составляет 0x10000 байт (128 секторов или 64KiB). Далее выберем среди записей MFT какое-либо из мест, где записи MFT или результат их XOR операции симметрично располагаются на всех дисках-участниках и составим матрицу с номерами записей, с которых начинаются блоки массива с удвоенным количеством строк.
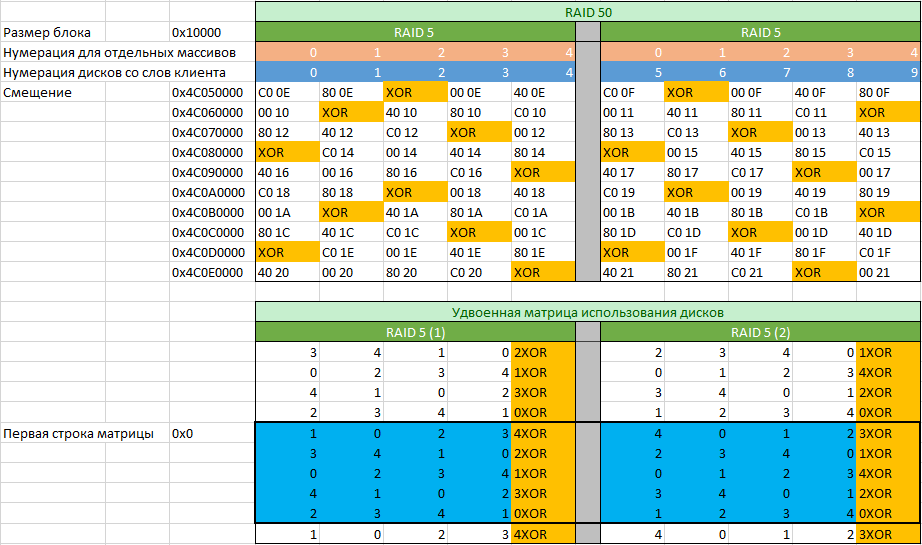
По номерам записей определим какие из дисков входят в первый RAID 5, а какие во второй. Проверку корректности выполняем посредством XOR операции. В нашем случае согласно таблицы мы видим, что нумерация дисков представителем заказчика была сделана неверно, так как матрицы обоих массивов отличаются по расположению блока четности (обозначенного как “XOR”). Также видим, что в данном массиве нет задержки четности, так как с каждой строкой меняется положение блока четности.
Заполнив таблицу номерами записей MFT по указанным смещениями с каждого из дисков, можно перейти к заполнению удвоенной матрицы использования дисков. Удвоена она из-за того, что формировать матрицу мы начали в произвольном месте. Следующей задачей ставится определить с какой строки начинается правильная матрица. Задача легко выполнима, если взять первые пять смещений, указанные на рисунке выше и умножить на 8. Далее решить простой пример в виде а=a+b где стартовые значения a=0x0 b=0x280000 (0x280000=0x10000*0x28, где 0x28 является количеством блоков с данными, которые содержатся в матрице использования дисков) и решать его в цикле, пока он не достигнет одного из значений смещений умноженного на 8.
После построения матрицы использования дисков мы можем произвести сбор массива любыми доступными для этого средствами, умеющими работать с матрицей произвольного размера. Но такой вариант сбора массива не будет учитывать актуальности данных на всех дисках, в связи с чем необходимы дополнительные анализы для исключения диска содержащего неактуальные данные (он был первым исключен из массива).
Для определения неактуального диска обычно не требуется полный сбор массива. Достаточно собрать первые 10-100GB и проанализировать найденные структуры. В нашем случае оперируем началом массива из 20GB. Как уже писалось, защитная MBR и GPT на дисках отсутствуют, и, естественно, их нет в собранном массиве, но при поиске достаточно быстро можно найти magic блок VMFS, отняв от его позиции 0x100000 (2048 секторов), получим точку начала VMFS раздела. Определив положение fdc.sf (file descriptor system file), проведем анализ его содержимого. Во многих случаях анализ этой структуры позволит найти место, где присутствуют ошибочные записи. Сопоставив его с матрицей использования дисков, получим номер диска, содержащего неактуальные данные. В нашем случае этого оказалось достаточно и дополнительные аналитические мероприятия не потребовались.
Выполнив сбор массива целиком с компенсацией недостающих данных за счет XOR операции, получили полный образ массива. Зная локализацию дефектов и локализацию файлов виртуальных машин в образе, возможно установить, на какие именно файлы виртуальных машин приходятся дефекты. Выполнив копирование файлов виртуальных машин из VMFS хранилища, можем смонтировать их в ОС как отдельные диски и выполнить проверку целостности файлов, содержащихся в виртуальных машинах посредством поиска файлов, содержащих сектора с паттерном 0xDE 0xAD. Сформировав список поврежденных файлов работу по восстановлению информации из поврежденного RAID 50 можно считать завершенной.
Обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить работу специалиста.
Комментарии (45)
whitedruid
20.04.2017 07:52Спасибо за статью! Жаль, что не упомянули. Было бы очень интересно узнать чем пользуются для восстановления данных с RAID (ПО и программно-аппаратные комплексы).

hddmasters
20.04.2017 08:03Материал в заметка подан так, чтобы не привязываться к конкретным ПАК. Описана сама методика.
Насчет комплексов, то сегодня на мой взгляд на рынке стран СНГ два ценных продукта:
1. Raid Explorer от Soft-Center (но без понимания устройства файловых систем может показаться совсем бесполезным)
2. DataExtractor RAID Edition от НПП АСЕ (Привязывается либо к PC3000Express, либо к PC3000SAS)
В каждом из инструментов есть намеки на автоматизацию, но сработают они, как правило лишь в случае массивов без серьезных проблем. Для качественного выполнения работ все равно будут требоваться знания основ и понимание устройства того или иного RAID массива.

agalitski
20.04.2017 17:26+2На скриншотах WinHex — удобен для анализа сложных повреждений. Позволял собирать относительно сложные массивы до появления других продуктов с зачатками автоматизации. Иллюстрации к кейсам по RAID я, например, тоже люблю делать в Excel.
Пример иллюстрации из кейса "Восстановление RAID6 после выпадения 5 дисков подряд":

hddmasters
20.04.2017 17:47+1На скриншотах WinHex — удобен для анализа сложных повреждений.
все же на этапе анализа я отдаю предпочтение ручному режиму в Raid Explorer от Soft-Center. Очень быстро можно заглядывать в одни и те же места по разным дискам и удобные горячие клавиши для пролистывания окна редактора с нужным шагом. Winhex в этой заметке использовался для наглядности, чтоб не вызывать вопросов у читателей по поводу hex редактора.
Я ранее себе на сайт материал по сбору RAID 6 выкладывал много лет назад, но в виде обычного примера, без рассмотрения практического случая.И уже не показывал сырец из Excel как здесь.agalitski
20.04.2017 18:16+1Я так давно начал пользоваться винхексом, что все остальные утилиты для анализа не рассматриваю даже. Каждый любит тот инструмент, к которому привык и все они чем-то хороши.
А вот для финальной сборки чего-то действительного сложного в последнее время предпочитаю data extractor raid edition. Их скилл разработки явно выше и мой самописный дестрайпер (написан в середине 2000-х, когда не было софта для сборки не только для hp delay, но даже для forward dynamic) давно пылится без дела.
На сколько я знаю, еще полтора года назад (осень 2015-го) raid explorer не умел пересчитывать второй missing диск в raid6. А о поддержке разных полиномов для второй контрольной суммы RAID6, думаю, речи нет и сейчас.
Или есть?
Я ранее себе на сайт материал по сбору RAID 6 выкладывал много лет назад, но в виде обычного примера, без рассмотрения практического случая.И уже не показывал сырец из Excel как здесь.
Очень круто сделаны иллюстрации! Так логично сделать их таблицами! Респект!hddmasters
20.04.2017 18:31На сколько я знаю, еще полтора года назад (осень 2015-го) raid explorer не умел пересчитывать второй missing диск в raid6. А о поддержке разных полиномов для второй контрольной суммы RAID6, думаю, речи нет и сейчас.
Или есть?
К сожалению Raid Explorer для RAID 6 только и умеет пересчитывать XOR и по сию пору нет поддержки VMFS. Для финальных сборов не самых простых массивов тоже использую PC3000SAS&DE Raid Edition.

mikkisse
20.04.2017 08:29Спасибо. Было очень интересно.
hddmasters
20.04.2017 09:01Пожалуйста. В рабочих перерывах, возможно будут написаны и иные материалы по теме восстановления данных, которые возможно будут изложены более подробно и доходчиво.

tumbler
20.04.2017 08:43Читаешь вот это всё и думаешь: это какой же багаж знаний по теме у автора!
А что в домашних условиях? Недавно пришлось спасать семейный архив с диска, который не хотел нормально работать. Несколько секторов не прочиталось, и хотя все файлы успешно перенеслись с образа на новый жиск, непонятно, как определить их целостность. Как в таких случаях "дешево и сердито" защититься от сбоя накопителя?

DaemonGloom
20.04.2017 15:52Хранить резервную копию и считать md5/sha-1 хэши файлов. Периодически проверять. Для дома — лучше не используйте уровни raid, кроме простого зеркала. Помните, что raid не заменяет резервную копию. Можно использовать какой-либо контроллер с raid и поддержкой ecc памяти, который сам делает периодическую проверку данных.
hddmasters
20.04.2017 08:56+3Какие бы вы меры защиты не придумывали, как бы бережно не относились к накопителю, но потерять данные можно в одно мгновение. Нет более дешевого и сердитого метода защитить себя от потери данных, чем заниматься резервным копированием. И чем больше копий дорогих Вам данных на разных и не зависимых друг от друга накопителях, тем ниже вероятность потери.
По вопросу проверки целостности: в процессе копирования желательно было использовать ПО, которое умеет заполнять непрочитанные сектора в копии произвольным паттерном (по желанию оператора). Далее стояла бы задача воспользоваться поиском и найти файлы содержащие внутри себя паттерн.
P.S. пытаясь копировать HDD с дефектами в домашних условиях помните, что Вы сильно рискуете усугубить проблему вплоть до невозможности восстановления данных. Современные накопители весьма склонны к запиливанию, в связи с чем методика линейного чтения неуместна.
rockin
20.04.2017 12:39В моей вселенной нет места тому, кто не создаёт резервных копий с критичных данных
Это вообще как возможно — создать рейд на почти 5Тб, и не озаботиться резервным копированием?!
Бывает потому что всякое, это сбои на носителях информации составляют 99% проблем.
А в моей практике, например, был даже локальный пожар в одном из отдельно стоящих серверов. Что-то коротнуло, ну и повышенный температурный режим диски не выдержали.
Также были маски-шоу, когда сервер назад мы получили без дисков. Попробуй докажи, что диски там были.
Другими словами, резервные копии требуется создавать всегда, обязательно на отдельном физически хранилище, крайне желательно в другой стойке и просто супер, когда ваши бекапы хранятся вообще в другом здании.hddmasters
20.04.2017 12:54К сожалению во многих организациях администрированием заняты либо ленивые и безответственные, либо не обладающие должной квалификацией кадры. В итоге организации несут убытки в результате действий или бездействия своих же работников.

navion
20.04.2017 17:29Вариант с кроиловом на бекапе вы исключаете?
hddmasters
20.04.2017 17:54Конечно есть случаи, где виноват исключительно руководитель, который своим волевым решением лишил системных администраторов возможности наладить резервное копирование. Но и не меньше случаев, где есть недоработки со стороны системных администраторов.
navion
20.04.2017 19:54Смотря что понимать под «возможностью», наверняка можно собрать кластер из древнего хлама, взять какой-нибудь опенсорс и ценой героических усилий сваять что-то условно рабочее.
Но работа сисадмина обычно подразумевает несколько иное, хотя и раздолбайства хватает.
Dmitry_4
21.04.2017 07:29-3Есть целая секта слабоумных, использующих рейд к месту и не к месту. Особенно дома, на софт контроллерах в биосе и т.п.
Вот это самые страшные люди
rockin
21.04.2017 09:47+1Дома — ничего страшного, это их собственные проблемы
А вот чем софт-контроллер не угодил?! В случае краха хотя бы один диск с данными, но останется.
Это вполне нормальное решение для нетребовательных задач, для ограниченного бюджета и так далее.
И бизнес начинается с совсем крошечных размеров, с двух-пяти сотрудников и совсем низких доступных средств. Сейчас, конечно, очень выручают такой бизнес облака, но какие облака тем, кому нужны терабайты, а это и дизайнеры, и архитекторы, и проектировщики.
Так что, не вижу ничего зазорного использовать тот же ownCloud и простенький десктоп. Для начала.
Вместе с этим, не отменяется обязательность постоянного резервного копирования критичных данных.Dmitry_4
21.04.2017 10:02-1При развале софтрейда потерять данные гораздо вероятнее, чем с одиночным диском
hddmasters
21.04.2017 10:37+1Если рассматривать только такое событие, как выход диска из строя, то выше вероятность потерять данные на одиночном диске, чем например на двух дисках организованных средствами ОС в RAID 1 (зеркало). Но как показывает практика рассматривать нужно куда большее число потенциально возможных событий.
Dmitry_4
21.04.2017 10:51Однажды утром биос фирмы говнобайд сказал мне 'какой такой рейд, не знаю ничего'. С зеркал удалось что-то собрать, а вот чередующиеся разделы утерялись. Вероятность сбоя всей этой грабли намного выше, чем просто диска. Как, у тебя ошибки црц из за кабеля? Срочно развалить рейд!
hddmasters
21.04.2017 12:01Как, у тебя ошибки црц из за кабеля? Срочно развалить рейд!
описан случай с SAS накопителями, в сервере в корзине. Дефекты поверхности не из-за кабеля. RAID остановлен, так как не хватило избыточности данных для продолжения работы. Аварийное отключение дисков или отвал кабеля не приводит к массовому образования дефектов.
Однажды утром биос фирмы говнобайд сказал мне 'какой такой рейд, не знаю ничего'. С зеркал удалось что-то собрать, а вот чередующиеся разделы утерялись
так с зеркал без проблем можно было получить 100% результат. По поводу чередующихся разделов тоже нет больших сложностей. Но создавая чередующийся раздел без избыточности сами должны понимать, что это в угоду скорости, а не надежности.
rockin
21.04.2017 11:27Я забыл уточнить, что я имел в виду исключительно RAID 1
Всё, для ничего остального софтовый рейд смысла особого не имеет.
Если только какие-то примитивные разделы под кеш устраивать.Dmitry_4
21.04.2017 11:54Все задачи домашнего рейда прекрасно решаются SSD и облачными хранилищами с онлайн-синхронизацией.
hddmasters
21.04.2017 12:06+1Скорость интернета многим не позволит комфортно работать с облачными хранилищами. Также всплывает вопрос стоимости хранилищ большого объема и вопрос конфиденциальности. Не каждый человек хочет, чтобы его информация подвергалась анализу.
Вспомнить относительно недавний случай с dropbox. Подобные случаи очень наглядно демонстрируют, что не все гладко с исполнением договорных обязательств со стороны облачных сервисов.
jok40
21.04.2017 12:58SSD всё ещё слишком дорогие. Облачные хранилища — тоже не бесплатны. Плюс интернет нужен неслабый. Так что не надо быть столь категоричным. Зеркало на встроенном в мать чипсете из больших дешёвых HDD — вполне себе нормальное решение для дома, которое спасёт данные при умирании одного из дисков.

mitzury
20.04.2017 14:36всегда для восстановления пользовался R-studio.
Но и из проблем были единичные диски с незначительными повреждениями.
В подобном случае как в статье, R studio могла бы помочь?hddmasters
20.04.2017 14:54В подобном случае как в статье, R studio могла бы помочь?
в автоматическом режиме нет. Если проводить все анализы в hex редакторе, как описано в заметке, то можно собрать два отдельных RAID 5, потом из двух собранных RAID5 собрать RAID 0. Но потребуется несколько пересборов, чтобы исключить диск с неактуальными данными. И насколько мне помнится в R-Studio не декларировалась поддержка VMFS. Потребуются дополнительные средства для разбора VMFS.
Также потребовались бы средства для вычитывания проблемных дисков в файлы образы. Исходя из их состояния вряд ли бы R-Studio продемонстрировала бы максимально возможный результат вычитывания проблемных зон.
Noa69
20.04.2017 14:55Данный RAID 50 представляет из себя комбинированный массив, который рассматриваем как два массива RAID 5, объединенных в массив RAID 0.
По описанию звучит как попытка самоубистваhddmasters
20.04.2017 14:58По описанию звучит как попытка самоубиства
Описание на самом деле не более страшное, чем в случае обычного RAID 5. Отмечены достоинства в сравнении с обычным RAID 5 для подобного количества дисков. Страшным данный массив может показаться в случае отказа, так как автоматического решения посредством программ автоматического восстановления не будет. Но если системный администратор знает устройство массива или делает своевременно резервные копии, то бояться совершенно нечего.Noa69
20.04.2017 16:12делает своевременно резервные копии
Вот я собственно про это сочетание: нет резервной копии (а ей не было, судя по тому что вам пришлось с мертвого массива выковыривать данные), и используем подобные «очень быстрые» raid массивы.
agalitski
20.04.2017 17:46+1RAID50 — это легитимный уровень RAID как и другие составные уровни RAID(wiki Nested RAID levels). Попытка самоубийства (с элементами экономии и садомазо) это:
- собрать из 8 разношерстных дисков 4 штуки RAID1 средствами контроллера Adaptec
- на каждом RAID1 создать VMFS datastore
- на них создать 1 виртуальную машину и к ней 4 flat vmdk диска
- в машину установить Windows Server, в котором из подключенных 4 дисков сделать один LDM том, на котором и хранить данные
Ссылка на полное описание кейса.Noa69
21.04.2017 12:21Это уже не попытка вовсе, а самое настоящее преднамеренное сомоубиство.
Рэйд 0 тоже Легитимный и корерктный уровень рейда, только это сосвсем не означает что запихнуть в него 12 дисков и не бекапиться — норма.
jok40
21.04.2017 07:56Было выполнено создание копий, в результате которого выяснилось, что 4 накопителя имеют дефекты между LBA 424 000 000 и LBA 425 000 000, выражается это в виде нечитаемых нескольких десятков секторов на каждом из проблемных дисков.
Интересно, что должно было произойти с массивом, чтобы у него перестали читаться четыре диска из десяти в одной и той-же области?hddmasters
21.04.2017 09:05Интересно, что должно было произойти с массивом, чтобы у него перестали читаться четыре диска из десяти в одной и той-же области?
наиболее вероятно, что некое единовременное воздействие на сами диски.
Alexsandr_SE
21.04.2017 09:49Интересно что за диски и откуда одинаковые повреждения? Физические повреждения на диске между LBA 424 000 000 и LBA 425 000 000 или нет?
hddmasters
21.04.2017 13:35Дефектообразования. Исходя из локализации дефектов с высокой вероятностью можно говорить о возможном физическом воздействии на сервер.
Carnolio
Где можно получить такие знания или это все только опытным путем?
hddmasters
Знания об устройстве RAID массивов формируются на основе анализа распределения данных RAID контроллерами. Какой-либо ценной литературы, где подробно изложено устройство массивов и нюансы метаданных RAID контроллеров мне не встречалось. Только исследовательский путь в познании нюансов работы конкретных RAID контроллеров.
navion
В новостях писали, что крупнейшие компании по восстановлению данных (вроде Seagate и Ontrack) получали документацию по контроллерам SSD от производителей, наверняка и по RAID-контроллерам у них есть все спецификации под NDA.
hddmasters
А не могли бы Вы указать адрес подобной новости?
al_ace
В случае классических RAID информация о контроллере дает не так уже и много. В лучшем случае вы найдете метаданные на дисках и по ним узнаете конфигурацию. Однако есть еще очень много других проблем:
— умирающие HDD
— неактуальные участники (относительно «живые» диски, которые были давно исключены из массива)
— всякие попытки «самолечения» из-за которых образуется каша в данных