
Так случилось в одной из больниц, где рентгеновский кабинет оснащен современным оборудованием, и стоимость одного только рентгеновского аппарата превышала 100 000$. Важный момент, что при реконструкции кабинета в расчет бралась только закупка непосредственно самого оборудования. Всякие «излишества» в виде ПК врача-рентгенолога и реализации системы хранения данных пациентов в этот расчет не вошли, и больнице было предложено за собственные средства приобретать все остальное, что необходимо для работы кабинета.

рис. 1
Собственных средств больницы хватило лишь на приобретение ПК для врача-рентгенолога с единственным жестким диском Seagate Constellation CS ST3000NC002-1DY166 емкостью 3 Тб. Первоначально планировалось это использовать как временное решение, а далее, когда появятся «свободные деньги», реализовать планы по созданию системы резервного копирования.
Но планам не суждено было сбыться. Денег больнице по-прежнему катастрофически не хватало, и была масса более приоритетных задач. В итоге, временное решение стало постоянным. Шли дни, на жестком диске накапливались данные пациентов, причем в некоторых случаях от этих данных могла зависеть человеческая жизнь.
Спустя три с половиной года грянул гром. Во второй половине дня врач заметил, что компьютер начал «задумываться», и привычные операции (просмотр и сохранение рентгеновских снимков) стали занимать значительно больше времени, чем обычно, и с каждым часом ситуация усугублялась до момента, когда продолжение работ стало невозможным, и пришлось прервать прием пациентов.
Технический персонал больницы в лице единственного системного администратора, работающего на ? ставки, смог лишь констатировать, что накопитель неисправен. После нескольких неуспешных попыток запуска программ автоматического восстановления накопитель начал постукивать, в связи с чем администратор принял решение остановиться и сообщить главврачу о том, что восстановить данные он не сможет.
С такой симптоматикой накопитель был доставлен в нашу лабораторию восстановления данных. Seagate Constellation CS ST3000NC002-1DY166 семейства Grenada. Жесткие диски этого семейства продавались весьма массово, и в связи с высокой распространенностью повидать их смогли во многих лабораториях восстановления данных. Не только нами, но и многими другими лабораториями был зафиксирован факт, что диски данного семейства при выходе из строя нередко оказываются с сильно поврежденным БМГ и запиленными пластинами.

рис. 2
На рис. 2 показан типичный случай разрушения поверхностей пластин, также показано загрязнение в труднодоступных местах. Как бы ни было сложно, но эту пыль настоятельно рекомендуется удалять до вскрытия накопителя, так как при вскрытии часть ее обязательно попадет в гермоблок.
Причины подобного явления волновали многих. Выдвигалось множество версий, некоторые звучали достаточно убедительно. Например, одна из распространившихся версий, опубликованная на Habrahabr "Если Seagate запылился…", гласила, что основной причиной начала деградационных процессов является попадание пыли из-за неподходящего уплотнителя между контактной колодкой и корпусом БМГ.
У этой версии есть недостатки. При обследовании немалого числа накопителей данного семейства с разрушениями на разных стадиях не подтверждается неплотное прилегание уплотнителя между контактной колодкой и корпусом жесткого диска. В ситуациях, где разрушение только-только началось, произошел неполный отказ одной или нескольких головок, но окончательного разрушения пластин (запиливания) еще не произошло, не обнаруживается признаков пыли под этим уплотнителем, что ставит версию под сомнение. Также не стыкуется с этой версией тот факт, что разрушение начинается не всегда с нулевой головки, хотя при попадании пыли снизу накопителя было бы логичным, чтобы деградировала в первую очередь именно нулевая головка и поверхность пластины. Точнее, деградационные процессы по нулевой головке начинаются не чаще процессов деградации по остальным головкам.
Современные накопители способны управлять высотой полета слайдеров над поверхностью пластин посредством нагревательного элемента и Seagate Grenada не является исключением.

рис. 3 (рисунок заимствован из публичного документа)
Анализ работы системы динамического изменения высоты полета (DFH) показывает, что при некоторых условиях возможно получить контакт слайдера с поверхностью, что в итоге спровоцирует начало деградационных процессов.
На основании этого анализа также можно дать рекомендацию ни в коем случае не менять платы между накопителями данного семейства без переноса ПЗУ, так как попытки старта с чужой платой (с чужими адаптивными параметрами в ПЗУ) могут привести к контакту слайдеров с поверхностью пластин. Тем более в накопителях Seagate F3 архитектуры попытки старта с чужим ПЗУ обречены на провал.
Когда мы видим, что к нам поступает Seagate Grenada, который со слов клиента начал постукивать, то диагностические мероприятия начинаем с обеспыливания накопителя и вскрытия в ламинарном боксе. Снимаем БМГ, фильтр рециркуляции воздуха и тщательно обследуем под микроскопом.
В нашем случае ярко выраженного повреждения пластин не было, фильтр рециркуляции воздуха не содержал в себе признаков металлических частиц, проблему выдавали едва заметные царапинки на слайдере №2. Остальные слайдеры видимых повреждений даже при сильном увеличении не имели. К сожалению, возможностей камеры микроскопа, вставляемой вместо одного из окуляров недостаточно, чтобы показать едва различимые повреждения слайдера.
Зная о рисках лавионообразного разрушения поверхности пластины при попытке чтения поверхности, над которой обнаруживается поврежденный слайдер, принимаем решение о физическом удалении поврежденного слайдера и подвески из БМГ. Попытка использовать оригинальный БМГ предпринимается с целью чтения остальных зон исправными оригинальными головками, так как адаптивные параметры накопителя для них подходят идеально. Получить устойчивое чтение донорскими головками не всегда возможно.
Выполняем процедуру сбора накопителя с одним физически удаленным слайдером и подвеской. Так как при физическом отсутствии одной из головок накопитель не сможет пройти процедуру калибровки, то необходимо модифицировать карту головок в ПЗУ, чтобы обойти этап калибровки по головке №2. Для этого карту головок в ПЗУ 0, 1, 2, 3, 4, 5 меняем на 0, 1, 1,3, 4, 5. Перед тем, как записывать модифицированное ПЗУ, создадим несколько резервных копий оригинального с обязательным сравнением результатов чтения с предыдущим.
С модифицированным ПЗУ данный накопитель вышел в готовность без лишних тревожных звуков.

рис. 4
Вносим изменения в настройки накопителя в ОЗУ: отключаем все процедуры оффлайн сканирования и автореаллокации при чтении и записи. Проверяем способность данных головок записывать на модуле, который не используется накопителем во время работы. Удостоверившись, что данная процедура отработала без нареканий, модифицируем модуль параметров, чтобы при дальнейших перезапусках накопителя не происходило старта нежелательных процедур.
Читаем содержимое 0 сектора и обнаруживаем там чьё-то упущение. На 3 ТБ диск с эмуляцией сектора 512 байт использовалась классическая таблица разделов вместо положенной GPT. На диске присутствуют три раздела.

рис. 5 — Таблица разделов
Первый раздел NTFS (0x07) имеет статус активного и начинается с 0x00000800 (2048) сектора, размер 0x00032000 (204 800) секторов.
Второй раздел NTFS (0x07) начинается с 0x00032800 (206 848) сектора, размер 0x06175800 (102 193 152) секторов.
Третий раздел NTFS (0x07) начинается с 0x061A8000 (102 400 000) сектора, размер 0xF9E58000 (4 192 567 296) секторов.
Заглянем в сектор 0x100000000 (4 294 967 296). Он целиком заполнен нулями, признаки таблицы разделов или загрузочного сектора раздела отсутствуют.
Предварительно можно сделать вывод, что данный диск использовался только в границах первых 2ТБ, оставшиеся 794,52ГБ не использовались в процессе эксплуатации.
Создаем задачу посекторного копирования в Data Extractor, строим карту зонного распределения без учета зон головки №2, так как самой головки нет, а вместо нее обманка в карте.
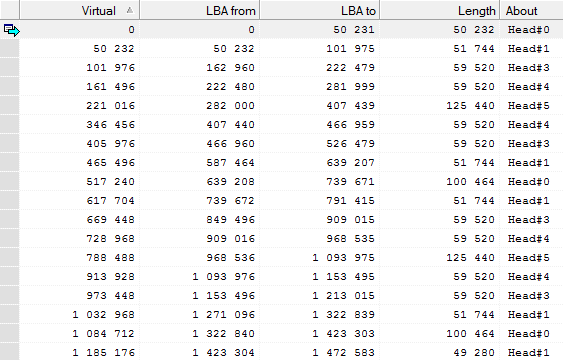
рис. 6 — Карта мини зон
Процесс чтения идет без особых затруднений, и в течение нескольких проходов получаем начитанными 4 846 ххх ххх секторов из 5 860 533 160. Непрочитанными по головкам 0, 1, 3, 4, 5 после нескольких операций перечитки осталось 72 сектора (36Кб), и все они сосредоточены на поверхности, читаемой головкой №5. Учитывая, что чтение было стабильным, то были прочитаны все зоны после 4 294 967 296 сектора. Предположение о том, что диск частично не использовался, получило подтверждение.
Исходя из анализа фрагментов прочитанных файловых систем по второму и третьему разделам, были установлены их роли. Второй раздел играл роль системного диска, и пользовательские данные там отсутствовали. На третьем же разделе, наоборот, были только пользовательские данные в виде файловой базы данных снимков пациентов.
Для полноценного чтения нам необходимо произвести пересадку донорского БМГ. Учитывая, что это Seagate Grenada, то выбор донора осуществляем среди аналогичных накопителей, принадлежащих этому семейству, с одинаковой ревизией коммутатора-предусилителя и близкими адаптивными параметрами. ST3000NC002, ST3000DM001 являются представителями одного семейства. Подобрав подходящий донор, выполним пересадку БМГ.

рис. 7
Записываем в винчестер-пациент ПЗУ с оригинальной картой головок обратно. При подаче питания слышим несколько неуверенное прохождение калибровочного теста, но, тем не менее, микропрограмма загружена, и система трансляции проинициализирована. Тестируем способность чтения головки №2 в зонах разной плотности. Удостоверившись, что чтение присутствует в разных зонах, приступаем к чтению пользовательских данных.
Просматриваем содержимое загрузочного сектора третьего раздела.

рис. 8 — Загрузочный сектор NTFS
По смещению 0x0B располагается WORD 0x0200, что означает, что размер сектора 512 байт.
По смещению 0x0D располагается BYTE 0x08, что означает, что в одном кластере 8 секторов, размер кластера вычисляется перемножением размера сектора на количество секторов в кластере, то есть 0x0200*0x08=0x1000 (4096) байт.
По смещению 0x30 располагается QWORD 0x00000000000C0000 (786 432) в нем указан номер первого кластера MFT.
Анализируем первую запись MFT, строим карту цепочек MFT третьего раздела и выполняем чтение недостающих фрагментов. MFT прочитана успешно, что позволяет отправить накопитель в спящий режим и провести полный анализ файловой системы на копии, чтобы иметь возможность построить карту расположения необходимых данных. Читать все подряд в подобной ситуации слишком большая роскошь, так как есть риски, что при чтении поврежденной поверхности будут продолжаться дальнейшие деградации.
На основании данных анализа строим цепочки расположения нужных файлов по головке №2 и объединяем их цепочки, которые расположены в границах одной мини-зоны. После данного действия немного добавится лишних данных, чтение которых не указано в техническом задании. Но подобный подход позволит пропускать целиком мини-зону в случае обнаружения нестабильного поведения, что повышает шансы на успешное вычитывание большего количества данных.
Далее следуют этапы локализации крупных дефектообразований на поверхности, читаемой головкой №2, и чтение с пропуском самых проблемных зон. Зоны с большим содержанием дефектов читаются в последнюю очередь, так как их чтение сопряжено с рисками окончательной деградации накопителя без дальнейшей возможности чтения данных.
На протяжении двух суток с постоянными изменениями сценариев чтения удается завершить вычитывание более, чем на 99,9% необходимых цепочек, и на этом положительная динамика останавливается, а на дефектных зонах появляется запил, подобный тому, что на рис. 2.

рис. 9 — Вид запила под микроскопом
К сожалению, иных вариантов чтения уже не было, это был последний шанс прочитать хоть что-то из поврежденных зон. При формировании отчета о файлах, расположенных в проблемных зонах, наблюдаем относительно неплохую картину: из более 198 000 файлов непрочитанными остаются чуть менее 2000. Но, отходя от сухих цифр, в которых рапортуется о 98,9% результате, приходит осознание того, что за этими чуть менее 2000 файлами стоит несколько сотен живых людей, чьи результаты посещения рентген-кабинета канули в небытие из-за мелочной экономии. Очень хочется верить, что утерянные результаты не были критически важными, и их потеря не отразилась на чьей-то жизни.
При выдаче данной информации была проведена консультация системного администратора, каким образом следить за состоянием жестких дисков. Накопители, подобные этому, не деградируют в одно мгновение. Если регулярно проверять показания SMART, контролировать хотя бы необходимый минимум атрибутов, а не ждать, когда накопитель начнет рапортовать «SMART status – BAD» на команду 0xB0 0xDA, то в большинстве случаев можно заметить надвигающуюся угрозу и своевременно предпринять меры. Разумеется, существуют иные проблемы, которые развиваются куда более стремительно, и регулярное наблюдение за показателями SMART ничем не поможет. Учитывая вероятность развития неблагоприятных событий, стоит хорошо продумать систему резервного копирования, причем контроль ее работы должен осуществляться не только единственным системным администратором.
Хочется надеяться, что после этого происшествия в данной больнице хоть что-то изменится в политике хранения данных пациентов, и подобные ситуации не повторятся впредь.
Предыдущая публикация: Грех администратора или восстановление данных из стучащего HDD Western Digital WD5000AAKX
Комментарии (91)

teemour
01.07.2017 00:34-5не растраивайтесь
зачем хранить эти рентгены, их пациенты выбрасывают почти сразу
hddmasters
01.07.2017 07:29+299% материала обычно не является критически важным, но есть исключения.
Vjatcheslav3345
01.07.2017 12:26+1Срок хранения твёрдых копий аналоговых изображений составляет 2 года при отсутствии патологии и 5 лет для снимков, отражающих патологические изменения. Снимки больных детей хранятся 10 лет*.
Это связано с тем, что состояние больного человека развивается со временем и старые снимки бывают полезны в специфических случаях а в общем случае — важнее свежие снимки.
*Проект Приказа Министерства здравоохранения РФ "Об утверждении Правил проведения рентгенологических исследований" (подготовлен Минздравом России 03.12.2016).
Есть и хорошие новости: хотя в этом новом проекте правил рентгенологических исследований и регламентируются только сроки для твёрдых копий, но наличие сервера в рентгенлаборатории уже предусмотрено. Со временем и до облачного хранения дойдёт дело.
По идее, неотключаемое прозрачное фоновое автоматическое резервное копирование ещё и должно было предусматриваться в самом ПО для АРМ рентгенлаборанта, причём оно должно было быть сделано с учётом сроков хранения — хотя и регламентируются пока только сроки для твёрдых копий. О пациенте поликлиника всё равно знает его дату рождения и дату съёмки — поэтому может автоматически делать копии снимков до 5 лет и снимков детей, размещая их в разных местах диска.

Gobl1n
01.07.2017 01:39Здравствуйте! Не первый раз читаю ваши success-story. Не могу не спросить, вот в этом случае, как на картинке, у винта были какие-нибудь шансы или уже бесполезно пытаться? Утром ушел на работу, вернулся через 9 часов, винт стучит. Выключил, выкрутил, повез в лабораторию. Прислали фотку, сказали, что вероятность какого-либо восстановления нулевая. Это правда, или попытаться стоило?
Фотографияhddmasters
01.07.2017 07:16Здравствуйте. При подобных запилах, как на вашем фото, обычно шансы около нуля.

Dmitry_4
01.07.2017 19:50-1Отправьте в АНБ, у них есть оборудование для восстановления, да и резервные копии ваших дисков надежно сохранены.
А про сигей — купил, почти новый диск начал тупить на запись. Сервис денег не вернул, ибо читалось все хорошо. Так же издох морской педик в портативном диске. Не покупайте поделки этой конторы никаноры.
hddmasters
01.07.2017 19:59А про сигей — купил, почти новый диск начал тупить на запись. Сервис денег не вернул, ибо читалось все хорошо.
таких историй от пользователей можно услышать про любого производителя.

{kind=link}
vilgeforce
01.07.2017 02:25На рисунке №2 что за интересная конструкция полукруглая над пластинами?
hddmasters
01.07.2017 07:19Разделитель. Его задачи рассекать потоки воздуха, чтобы снизить шумы. Кроме это происходит отвод тепла.
Vir2o
01.07.2017 04:09Здравствуйте! Мне последнее время не дает покоя один вопрос, связанный с HDD. Где-то месяц назад я купил новый ноутбучный диск WD Black. В том что он новый нет никаких сомнений: лично разрезал запечатанный антистатический конверт с силикагелем. Показатели SMART после первого запуска также показывали, что это было первое включение (атрибуты start/stop count, power cycle count и power-on hours count). Но! С момента первого включения атрибут BF (Shock sense) равен 4. И я теряюсь в догадках, это какие-то последствия заводских тестов? Никаким ударам диск не подвергался (при первом запуске, когда впервые всплыла эта 4, был в ssd отсеке десктопа, стоящего на полу). С тех пор BF не растет. Если вы работали с такими дисками, нет ли у них такой особенности что BF имеет ненулевое значение прямо с завода?
hddmasters
01.07.2017 07:23Здравствуйте. Ненулевого значения в новом диске не встречалось. Полагаю в вашем счетчик прирос на этапе между первым запуском и первым запуском программы просмотра показаний SMART. Современные диски весьма «нежные» порой чуть более сильный стук пальцами по клавишам воспринимается как ударные нагрузки и фиксируется в BF
Dmitri-D
01.07.2017 07:23-1Вооще первое правило — если винт еще откликается, но уже сбоит и постоянно рекалибруется — заморозить его. Да. Буквально. Засунуть в морозилку, опустить температуру существенно ниже комнатной. После этого _обычно_ они и грузятся и данные читаются, пока он не прогреется. Я так вытащил данные с нескольких винтов, которые уже даже не грузились.
Насчёт SMART — ни разу не помогло. SMART или молчит или выдает false positives. А вот что помогает — обдув винчестеров и контроль температуры, — ни в коем случае нельзя допускать нагрева свыше 40С.
Это довольно очевидно из картинки головки, которая нагревается резистором. Планирует она в зависимости от разницы температур — головки и поверхности диска. Чем горячее диск, тем меньше помогает прогрев головок. Получаем касание со всеми вытекающими.hddmasters
01.07.2017 07:27+2Вооще первое правило — если винт еще откликается, но уже сбоит и постоянно рекалибруется — заморозить его.
далеко не во всех случаях это будет полезно.
Насчёт SMART — ни разу не помогло. SMART или молчит или выдает false positives.
Смотря как за ним смотреть и трактовать показатели. Если ждать, чтобы накопитель на команды 0xB0 0xDA начал сообщать, что уже все плохо, то чаще SMART будет бесполезен, а если реагировать на первые признаки по RAW полям, то чаще можно успеть скопировать данные без особых затруднений.Dmitri-D
09.07.2017 09:01-2далеко не во всех случаях это будет полезно
Я не понял. Вы это пробовли во всех случах и в некоторых это не помогло, или просто высказываете своё мнение, которое не опирается на опыт?
Всё что я посоветовал — это мой опыт. Этот способ мне помог. Надеюсь кому-то еще поможет.
Смотря как за ним смотреть и трактовать показатели.
Нормальный протокол не допускает разной «трактовки». SMART 0 позволяет что-то трактовать так или иначе. Отсюда простовй вывод SMART не является нормальным протоколом. Каждый производитель наворотил что-то своё. Общие подходы не работают. Во всяком случае, мне не известны такой способ чтобы достоверно определить что диску плохо и он уже скоро скажет алаверды, независимо от производителя. Если вам известны — изложите. Будет полезно всем ознакомиться.khim
09.07.2017 10:58Нормальный протокол не допускает разной «трактовки»
Блеск. А ничего, что мы тут обсуждаем вещи, которые в принципе не могут однозначно что-либо трактовать?
Во всяком случае, мне не известны такой способ чтобы достоверно определить что диску плохо и он уже скоро скажет алаверды, независимо от производителя.
Они собственно, никому не известны. Если бы были известны — никакие «протоколы» были бы не нужны, просто можно было бы на этикетке диске при продаже писать «динск #12345, прикажет долго жить 5 сентяюря 2019 года, будьте осторожны».
Этот способ мне помог. Надеюсь кому-то еще поможет.
То есть когда вы даёте советы, которые могут привести к проблемам (несмотря на то, что вам они помогли) — это нормально. Если это делает кто-то другой, то виноваты разработчики винтов, протоколов, кто угодно, кроме раздолбая забывшего про бекапы!
hddmasters
09.07.2017 12:46Я не понял. Вы это пробовли во всех случах и в некоторых это не помогло, или просто высказываете своё мнение, которое не опирается на опыт?
Мы проверяли множество различных слухов. Учитывая огромную донорскую базу, у нас есть возможность экспериментировать с накопителями. Рекомендация бездумно морозить накопитель выйдет боком, так как при многих проблемах это как мертвому припарка. Кроме этого лишние попытки старта для полумертвого могут стать последними. Картинка с запилом, как на рис. 2 тоже может стать следствием действий пользователя над еще неокончательно умершим накопителем. Также имеет место негативное влияние в виде образования конденсата.
При коммерческом оказании услуги кому-либо морозить накопитель нельзя, учитывая все риски. Другое дело, если это ваш личный накопитель, на котором нет ценных для Вас данных. Тогда можно экспериментировать. Умрет окончательно, так умрет. Отдаст данные — хорошо, не потребуется заново качать с торрентов.
Всё что я посоветовал — это мой опыт. Этот способ мне помог. Надеюсь кому-то еще поможет.
хорошо бы пояснять опыт с инженерной точки зрения и также указывать на риски, которые с ним сопряжены.
Нормальный протокол не допускает разной «трактовки».
для начала S.M.A.R.T. не протокол. Какие протоколы используются в общении с накопителями можно прочитать в документации АТА стандарта.
Общие подходы не работают. Во всяком случае, мне не известны такой способ чтобы достоверно определить что диску плохо и он уже скоро скажет алаверды, независимо от производителя. Если вам известны — изложите. Будет полезно всем ознакомиться.
Общие подходы есть. И более того в публикации даже содержится ссылка на материал про SMART. Где описывается его устройство, как получаются показатели из накопителя и как они трактуются. А также указан набор атрибутов показатели которых желательно контролировать по RAW полям.
ExplosiveZ
01.07.2017 10:48Смотрю SMART(HDD).
Read error rate >140млн
Seek error rate >190млн
Reallocated sector count = 0.
Для второго диска:
Read error rate >120млн
Seek error rate >60трлн
Reallocated sector count = 0.
Диски пора менять? Если да, то что можете посоветовать, объемом >=1тб. Диски используются для различных проектов. Ко второму диску обращаюсь очень редко.hddmasters
01.07.2017 11:02Если никаких стуков нет, тест чтения поверхности проходит без каких-либо затруднений, то оснований для замены нет. Говоря о SMART пишите пожалуйста производителя и модель диска. Например Seagate будет помещать в SMART события об ошибках чтения и позиционирования во время работы и естественно эти показатели ежедневно будут расти, так как отражают реальную картину. Другие производители предпочитают не стимулировать рост показаний этих атрибутов и не фиксировать большинство событий.
ExplosiveZ
01.07.2017 12:28Спасибо.
Первый: ST1000DM003-1ER162
Второй: ST500LM000-SSHD-8GBhddmasters
01.07.2017 12:32Seagate в отличии от других производителей фиксирует ошибки в 1 и 7 атрибуте и весьма скурпулезно, отсюда такие огромные цифры в RAW полях. Ничего страшного в этих цифрах нет. Смотрите остальные рекомендованные параметры. Особое внимание 5 и 197.
sotnikdv
01.07.2017 12:43У Вас
волчанкаSeagate! Они (и кажется не только они) в raw аттрибуты суют не только сбои, но и успешные чтения, сколько то там бит на всего, сколько то там бит на сбои. Поэтому у совершенно нормального винта будут совершенно конские значения этих аттрибутов.
Также за Сигейтом замечал абсолютно чистый смарт, после ошибок чтения и релокаций. Поэтому смарту сигейта я бы не доверял совершенно. ИМХО.sotnikdv
01.07.2017 12:52In this concrete case the raw value for Seek error rate is 17262017054, or 0x000404E57A1E. The first 16 bits is 0x0004 and the last 32 bits are 0x04E57A1E. What this means is that there were 4 seek errors (meaning the head wasn't positioned correctly after being moved to some track) but there were 82147870 seeks in total. So, this is very very small fraction of errors.
И вот тут еще http://www.users.on.net/~fzabkar/HDD/Seagate_SER_RRER_HEC.html
Так что не пугайтесь.
P.S. Хотя я не доверяю одиночным дискам и сигейтам в особенности. 50 дисков на руках, сигейты особенно проблемные, особенно 3Тб, коих выбросил пачку через 1.5 года и 2х4Тб, которые ушли в мусор прямо из коробки после теста.
hddmasters
01.07.2017 12:54+1Ошибки чтения есть у всех жестких дисков и весьма массово. Но емкости ЕСС достаточно для коррекции ошибок. Микропрограммы накопителей других производителей не фиксируют эти события. Микропрограммы Seagate фиксируют. Особенно это хорошо заметно на жестких дисках Seagate, где присутствует атрибут 0xC3 (195) Hardware ECC Recovered. В них атрибуты 0x01 и 0xC3 растут синхронно.
Dioxin
03.07.2017 09:23+1Если у Вас серьезные проекты — сделайте софтовое зеркало хотя бы.

aik
03.07.2017 09:28+1Сперва надо озаботиться бэкапами. Зеркало можно потом, по остаточному принципу.
Dioxin
03.07.2017 09:30-1Спорный вопрос. Смотря чего Вы боитесь больше — вирусов или поломки винта.
Если второго — то зеркало лучше и делается проще/быстрее.
А вот потом уже можно бекапами отполировать систему.aik
03.07.2017 09:45+1Бэкап спасает от всего, в том числе и от поломки винта.
А зеркало вообще не спасает. Зеркало нужно для уменьшения времени простоя в случае смерти оборудования, не более. Потому для сохранения информации бэкап первостепенную важность имеет, а зеркалами надо по остаточному принципу заниматься. То есть иметь их неплохо, но всяко не за счет бэкапа.Dioxin
03.07.2017 09:48Зеркало спасает как раз от поломки винта, при этом Вы имее полную копию своей инфы и софта.
У Вас даже работа не остановится если один винт из зеркала умрет.
Бекап Вам не поможет в таком случае.aik
03.07.2017 09:59+3Смотря как у вас винт помер. Если одномоментно пропал — то да, поможет. А вот в случае протяженной деградации есть шансы отзеркалить битые файлы на второй винт.
У Вас даже работа не остановится если один винт из зеркала умрет.
Вот это и называется «обеспечение бесперебойности».
Бекап Вам не поможет в таком случае.
Как настроите, так и будет.
mickvav
01.07.2017 11:13А с показаниями смарта на ssd-ных дисках есть какой-то опыт работы?
От себя добавлю к списку атрибутов, которые неплохо бы мониторить, собственно температуру дисков — позволяет на ранних стадиях заметить засоренную вентиляцию, предсмертное состояние кулеров и т.п.hddmasters
01.07.2017 11:22+1А с показаниями смарта на ssd-ных дисках есть какой-то опыт работы?
Есть, но пока предпочту пособирать статистику проблем и показаний, а после будет выражено в виде небольшой заметки-рекомендации.
От себя добавлю к списку атрибутов, которые неплохо бы мониторить, собственно температуру дисков
данный атрибут я не описывал, так как это единственный атрибут, который основная масса пользователей, получивших показания SMARТ, адекватно оценивает.sotnikdv
01.07.2017 13:23Вот это было бы совсем недурно.
А то пока у меня сложилось впечатление, что SMART на SSD практически бесполезен. Все мои SSD или просто переставали распознаваться после ребута или просто отказывались писаться, без каких либо предварительных предупреждений.
В результате сей гнусной привычки все SSD стоят в рейдах. Или на машинах, с которых бекап сливается автоматически на большой сервак. А там тоже рейды.
Чем больше на руках дисков, тем больше понимания, что все смертны, но хуже всего, что внезапно смертныDmitri-D
01.07.2017 18:07смертны внезапно,
хуже того, бывают смертны группой — два подряд или три. Это из-за общих причин и главная — плотная установка, плохой обдув и в результате — перегрев.
40С — импирически установлено — критическая температура для HDD. Нельзя ее превышать никак.
Для SSD — пока нет статистики. Судя по технологии и росту отказов флеш памяти при нагреве — я так же не даю SSD нагреваться выше 40С.
По SMART — каждый производитель пихает туда всё что угодно. Нужен обзор и разъяснения производителей. Пока выглядит как мусор. Некоторые программы ставят цветовое сопровождение — типа зеленый — ок, желтый — предупреждение и красный — кирдык. У одного винта с рождения был один показатель желтый. Так он до сих пор желтый уже столько лет. А у недавно сдохшего — всю дорогу всё было зеленое. Сдох — там рассыпался подшипник шпинделя. Судя по дате производства — я как раз попал на «после фукусимы».hddmasters
01.07.2017 18:45Сдох — там рассыпался подшипник шпинделя.
Не совсем корректно «рассыпался». Заклинивать гидродинамический подшипник может из-за перегрева. Устройство подшипника простое: вал (втулка) с каналами для циркуляции смазки и корпус подшипника. Тонка пленка смазки — изолирующий слой уменьшающий потери на трение. Заклинивание вала обычно происходит из-за ударов, которые могут спровоцировать образование некой мини стружки + хорошая температура в итоге происходит практически закупоривание протоков и начинается хорошее трение с большим выделением тепла внутри подшипника, в некоторых случаях доходит чуть ли не до приваривания вала. При мгновенном заклинивании просходит резкая остановка с деформацией вала.

plin2s
04.07.2017 11:12Не могу согласиться. Дискам вредны перепады температур.
Из примеров:
Были много десктопных сигейтов работавших при 45-47 градусов (никогда не опускалась ниже 40 во включенном состоянии). Для них по даташиту максимальная рабочая температура была то ли 50, то ли 55.
До сих пор работает 2.5" Toshiba 1Tb, налет больше 20тыс. часов. Режим 24х7 с редкими отключениями. Температура средняя 53-55 грудусов (по даташиту максимум 55). Были довольно продолжительные периоды до 63 градусов в летнее время.
plin2s
04.07.2017 11:03Спасибо за статьи! Буду с нетерпением ждать про SSD.
Но пока что меня все еще мучает вопрос, на который не получилось найти адекватного ответа.
Может у вас найдется ответ? https://toster.ru/q/155183hddmasters
04.07.2017 14:14Признаки того, что появляются дефекты, обычно намекает на износ NAND памяти. Но при малом количестве исключенных (блоков, страниц) совсем необязательно, что проблема серьезная. Рекомендация — скопировать данные. Выполнить Security Erase и заново попробовать использовать. Если износ не носит массовый характер, то изделие еще поработает.
По поводу современных жестких дисков могу сказать, что при первых признаках дефектов в 0x05 и 0xС5 лучше не ждать больших цифр, а скопировать информацию заблаговременно.plin2s
04.07.2017 14:37Естественно. В вопросе я не уточнял, но речи конечно не идет о ценных данных.
Спасибо.
AcidVenom
01.07.2017 12:25Температура совсем не показатель. Вчера потерял рэйд0, температура проблемного диска была даже немного ниже.
hddmasters
01.07.2017 12:30Температура один из показателей, который стоит досматривать. Также необходимо помнить, что не только на температуру нужно смотреть.
И стоит учитывать, что некоторые проблемы развиваются лавинообразно. Особенно это касается накопителей у которых состоялся неудачный контакт слайдера с поверхностью (например из-за внешних факторов).
sotnikdv
01.07.2017 12:55Скажем так, изредка повышенная температура винта может говорить о том, что механике кранты и боржоми пить, собственно, уже поздно. Но зачастую, перегрев винта по внешним причинам может укоротить его жизнь.
А Вы смелый. Я тут одиночным винтам не очень доверяю, кроме фильмов, которых не жалко, а у Вас рейд 0.hddmasters
01.07.2017 13:00Скажем так, изредка повышенная температура винта может говорить о том, что механике кранты и боржоми пить, собственно, уже поздно.
при живом накопителе — это обычно говорит о том, что стоит подумать над организацией системы охлаждения или очистить от пыли текущую.sotnikdv
01.07.2017 13:18Так я ж о чем.
Но зачастую, перегрев винта по внешним причинам может укоротить его жизнь.
У нас тут кажется полное взаимопонимание ;)hddmasters
01.07.2017 13:37У нас тут кажется полное взаимопонимание ;)
Чуть более развернутый ответ про еще живые накопители.
AcidVenom
01.07.2017 13:05Какие показатели считать повышенными? 55+? 60+?
Для меня большую важность составляют 05, 187, 196-198, 200. Температуры снимаю раз в 5-10 минут.sotnikdv
01.07.2017 13:32А тут все зависит от температуры в корпусе и системы охлаждения. У меня все, что выше 45 вызывает нездоровый интерес, если на винтах нет нагрузки. А все, что выше 55 вызывает интерес независимо от нагрузки.
Но опять же, тесные корпуса и плохая система охлаждения вызывают перегрев винтов сама по себе, поэтому, ИМХО, уместно говорить о плюс к температуре внутри корпуса. Мои 45\55 это +25\+35 к температуре внутри корпуса.
Понятно, что чем меньше температура, тем эта дельта будет больше, а чем выше, тем меньше, ибо рассеивание тепла зависит от разности температур.
Но для околокомнатных температур я бы волновался на +25\+35 для покоя\работы.
Но опять же, для домашней системы там все относительно стабильно и можно не парится.
ИМХО
satter
01.07.2017 14:53hddmasters нет ли у вас опыта работы с новыми сериями seagate? посматриваю на ironwolf серию для домашнего хранилища
hddmasters
01.07.2017 14:58Новинки пока требуют обстоятельного исследования и сбора статистики. Как правило в первый год после выхода того или иного накопителя немного их попадает в наши застенки. Сегодня давать комментарии про Ironwolf преждевременно.
periskop
01.07.2017 14:53Спасибо! Читаю все статьи как хорошие детективы, особенно про грех админа понравилось.
Есть ли интересные данные про серию Constellation ES.3? Например, про ST2000NM0033?hddmasters
01.07.2017 15:02Бывали и такие накопители в работе. Семейство Megalodon. Чего-то особо интересного в них не наблюдалось. Типичные проблемы, как и у всех жестких дисков. Учитывая чуть более высокую цену менее распространены, посему попадаются к нам реже.
periskop
01.07.2017 15:30Спасибо.
Если можно, еще вопрос. Есть 2 диска WD Green серии WD15EADS-00P8B0, которым уже много лет (точно больше 7). Парковка головок каждые 10 секунд отключена, показатели смарт в норме, ошибка были давно только в UDMA_CRC_Error_Count, после переподключения кабеля все ок. Имеет ли смысл переставать их использовать и заменять на новые или можно использовать, если мониторить SMART?
SMART 1ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0 3 Spin_Up_Time 0x0027 186 179 021 Pre-fail Always - 5700 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 384 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 9 Power_On_Hours 0x0032 028 028 000 Old_age Always - 53108 10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0 11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 378 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 271 193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 122 194 Temperature_Celsius 0x0022 120 101 000 Old_age Always - 30 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 1 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0hddmasters
01.07.2017 16:03Имеет ли смысл переставать их использовать и заменять на новые или можно использовать, если мониторить SMART?
Я бы продолжил использование с контролем показаний. В профилактических мерах бы рассмотрел бы тест чтения всего логического пространства (обязательно наблюдая за ним)periskop
01.07.2017 16:06Спасибо! Например, копирование файлов с последующим сравнением с исходником или что-то другое имеете в виду?
hddmasters
01.07.2017 16:11Можете использовать бесплатный PC3000DiskAnalyzer и выполнить тест чтения от 0 сектора до последнего.
periskop
01.07.2017 16:36А, понял, спасибо, тогда викторией прогоню. Меня смутило, что речь шла о логическом пространстве.
hddmasters
01.07.2017 17:28Так все сектора с 0 по последний — это и есть логическое пространство для доступа к которому используется Logical Block Adressing, Как можете узреть во многих публикациях карты мини зон по физическим головкам реализующие тот или иной участок логического пространства. Реальная ж адресация с учетом размеров зон, деления на минизоны, резервных треков в каждой зоне, исключенных (дефектных) треков или секторов слишком сложна и слишком сильно отличается у разных накопителей. Посему и придумалось в свое время в АТА стандарте понятие LBA, чтобы дать больше воли производителям устройств. В итоге современные накопители достаточно интересные устройства живущие своей жизнью и реагирующие на запросы из внешнего мира, только в случае, если в работе внутренней микропрограммы, обслуживающей запросы извне, все гладко.
periskop
01.07.2017 22:02Спасибо за хорошее объяснение. Хоть новых фактов не узнал, но по полочкам уже известные хорошо разложили.
dmxrand
01.07.2017 17:28Немного офтопик. НО. Это не экономя на спичках. Это некомпетентность. Для хранения изображений полученных с медицинских аппаратов используют DICOM сервера. Да есть например OpenSource варианты http://www.orthanc-server.com/ Если говорить о коммерческих системах, то цена может легко переплюнуть 10000$
Почему я говорю о некомпетентности. Я сам слышал такую беседу: «А что насчет компьютеров? А что насчет них? Тут все просто. Компьютер в ДНС стоит 8000р. Если что даже мой сын подскажет — он вон учится на физмате и там ничего сложного нет». И все.hddmasters
01.07.2017 17:32Немного офтопик. НО. Это не экономя на спичках. Это некомпетентность.
в данном случае на комплексных решений от производителя сэкномили. А хватило бы одного простого NAS'а с ежедневным резервным копированием. Чтобы подобная неприятность не побеспокоила. И в этом случае изначально задумывались о простых решениях, но из-за постоянного откладывания решения произошло то, от чего нужно было застраховаться.

Retifff
01.07.2017 17:32Интересно, а сколько из этих 3-х терабайт было заполнено?
hddmasters
01.07.2017 17:44Предварительно можно сделать вывод, что данный диск использовался только в границах первых 2ТБ, оставшиеся 794,52ГБ не использовались в процессе эксплуатации.
Заполнение используемых 2ТБ было более, чем на 80%

vlad49
01.07.2017 17:45Что касается медицинских учреждений — давно нужно обязать их сгружать первичную документацию, снимки, анализы, заключения, истории — всё до последнего в одно общее облако, с возможностью доступа как для самого пациента, так и из других клиник. Такой гос. проект действительно пошел бы на благо, с учетом нынешнего состояния медицины.
khim
01.07.2017 18:37До общего облака — как пешком до луны. Было бы неплохо для начала научиться передавать данные хотя бы внутри одной больницы. Меня пару лет назад в 17ю по ОМС положили, а когда я оклемался и позвонил в страховую — на ДМС перевели. Так мне анализы заново пришлось сдавать! Это внутри одного отделения! Из одного бокса в другое перешел!
А вы говорите — облако.vlad49
01.07.2017 19:53Имеется ввиду гос. проект, с обязательным требованием к клиникам пользоваться облаком по любому чиху. Это автоматически наладит передачу данных и внутри них.

sumanai
01.07.2017 20:28+2Как будто вы не знаете, как это обычно делается. Будет и облако, и таскание бумажек.
hddmasters
01.07.2017 20:44Со скрипом, но внедрится. Первые годы будет так, как Вы говорите, а через 10 лет уже никто и не вспомнит про бумажки.
nerudo
01.07.2017 22:27Без серьезной централизованной проработки это наладит лишь регулярную утечку данных. А профукать их в «обюлаке» не сильно сложнее чем в своем шкафу.
zerg59
02.07.2017 12:00Сделают за многократно завышенный прайс из чего-попало и палок. Это же госпроект.

Bonio
01.07.2017 17:46А можно у вас проконсультироваться?
Есть один диск, этой мой системный диск, и однажды, то ли в результате отключения питания, то ли сам по себе, он выключился с нехарактерным щелчком, после чего в smart появилась вот такая запись (uncorrectable sector count). Это было примерно пол года назад, диск, как работал, так и работает, скорость отличная, переназначенных секторов нет, этот счетчик тоже не увеличивается. Что означает эта ошибка и стоит ли из за нее волноваться? Стоит ли что то предпринимать?
Жесткий диск WD, серия, кажется, RE, вот полное его название: WD2502ABYS.
Ну и попутно вопрос, что можно сказать про smart моего диска? На какие вообще параметры smart обращать внимание в дисках WD?
Скриншот CrystalDiskInfo
hddmasters
01.07.2017 17:52Жесткий диск WD, серия, кажется, RE, вот полное его название: WD2502ABYS.
Полное название на скриншоте «WD2502ABYS-01B7A0»
Есть один диск, этой мой системный диск, и однажды, то ли в результате отключения питания, то ли сам по себе, он выключился с нехарактерным щелчком, после чего в smart появилась вот такая запись (uncorrectable sector count).
если из-за аварийного отключения питания, то возможно ничего страшного. Рекомендация скопировать информацию, а после выполнить тест записи всего логического пространства, потом тест чтения, если проблем не будет обнаружено, то можно пользоваться накопителем далее (заново создать раздел(ы) и скопировать информацию обратно)
Bonio
01.07.2017 18:08Спасибо за ответ. А чем можно такой тест произвести?
Копировать диск (для последующего восстановления) лучше программой Acronis True Image или посоветуете что то другое?
И хотелось бы, хотя бы в общих чертах, услышать ответ на это: На какие вообще параметры smart обращать внимание в дисках WD?
Извините за кучу вопросов.hddmasters
01.07.2017 18:49Общие рекомендации по анализу SMART есть. Отдельного акцента на WD нет нужды делать.
А чем можно такой тест произвести?
можно использовать бесплатный PC3000 DiskAnalyzer
Копировать диск (для последующего восстановления) лучше программой Acronis True Image или посоветуете что то другое?
Это как Вам удобнее. Можете просто файловую копию, можете использовать средства вроде Acronis True Image

farwayer
01.07.2017 18:06Ну идеальная жеж реклама! Я теперь знаю, к кому обращаться если что)
Есть статистика по этому Seagate'у? Такой уже пару лет крутится с музыкой и фильмами.periskop
01.07.2017 22:06+1Ага, реклама отличная. До этого знал, что в случае чего можно обращаться к Сергею Казанцеву (кстати, он тоже из Минска), автору программы Victoria. Теперь вот еще 1 контакт есть.
hddmasters
01.07.2017 19:21+2Ну идеальная жеж реклама! Я теперь знаю, к кому обращаться если что)
На Хабрахабр преследуется иная цель. Слишком уж много становится жертв youtube, где демонстрируются неразумные способы восстановления данных. Данный цикл статей альтернативная точка зрения. Пытаюсь донести немного теоретической + практической части, чтобы у некоторых был выбор: прислушиваться к мнениям многих авторов видеороликов на youtube и совершать незамысловатые движения с огромным риском безвозвратного уничтожения или все же более ответственно подходить к вопросу.
Есть статистика по этому Seagate'у?
все умирают и Ваше не будет исключением. Контролируйте SMART, как именно, указано в публикации про SMART. При первых признаках — копируйте данные, так как эти признаки будут началом конца.
sanrega
02.07.2017 11:28Здравствуйте. У меня такой вопрос. Довольно долго для оценки состояния поверхности диска использовал MHDD, переведя диск в режим IDE. Многие современные материнские платы в IDE не переключаются и MHDD диски не определяет. Посоветуйте, пожалуйста, какой-нибудь аналогичный софт, который умеет работать в загрузочном режиме, не из-под Windows.
hddmasters
02.07.2017 11:45Здравствуйте. Я не пользуюсь подобным ПО, в силу наличия немалого числа профессиональных комплексов. Но если глянуть в поиск то из более свежего можно попробовать HDAT2
А вообще не пугайтесь тестировать под Windows. Можно в нулевом секторе 510/511 байты c 0x55 0xAA сменить на любое другое значение и после перезагрузки диск для ОС будет неразмеченым и влияение ОС на результаты тестирования будет минимальным. Можно обойтись и без перезагрузки выполнив нужные действия в панели управления дисками. Страхи про то, что многозадачная ОС повлияет на результаты тестирования преувеличены. Небольшие задержки могут возникать в некоторых случаях, но наша задача на скане найти дефекты, а они с одинаковым успехом будут найдены, что под DOS, что под Windows. Для того чтобы вернуть разделы обратно, достаточно будет в нулевом секторе вернуть обратно 0x55 0xAA. Если не было тестов с записью, то данные отобразятся вновь.sanrega
02.07.2017 12:06Спасибо за ответ! И отдельная благодарность за ваши публикации, всегда читаю с интересом.
Stalkeros
08.07.2017 17:43А подскажите, для чего нужны пластины на рис.2, захватывающий наполовину верхний блин и проходящие далее между остальными блинами? Я так понимаю, чаще встречаются они в серверных решениях, чем в бюджетных. Недавно разбирал старенький scsi диск, там тоже были эти «полукруги». Очень интересна их функция. Спасибо.
hddmasters
08.07.2017 17:57Их основное назначение — направить поток воздуха, так как это нужно накопителю (кроме этого уменьшится и шум). В накопителях, где эти сепараторы выполнены из алюминия они еще и помогают в отводе тепла.
proton17
Данные пациентов говорите… пришел я как-то в травмпункт в начале года, так мне направление на рентген распечатали на половинке А4, на обратной стороне которого была титульная страница карты какого-то больного с ФИО, телефоном, адресом, номером страховки и вроде паспортом. Видимо закончилась бумага в принтере и в ход пошли черновики… А вы про деньги на систему хранения данных…
AndreyD
Я какое-то время обслуживал принтеры для поликлиник (ремонт, замена расходников, но не бумаги). Так вот, зачастую, при наличии бумаги в поликлинике и свободному к ней доступу у персонала, они все равно пытались её экономить.
5ergunka
догадайтесь — «почему?»
а потому что потом на родительском собрании в школе можно гордо встать и сказать «я могу на работе распечатать! БЕСПЛАТНО!»
не нести же потом распечатки на «черновиках» — это ж позорище на весь класс на несколько лет сразу!
aik
Кое-где «черновики» требуют повторно использовать. У нас периодически тоже кто-нибудь такую рацуху пытается протолкнуть.
nerudo
Передо мной лежит (лежало) два результата моей флюрографии с одного и того же аппарата где доза облучения отличалась в 10 разСудя по всему нулем больше, нулем меньше напечатаь — пофиг.
artyums
Если это два разных снимка, то возможно они были сняты в разных режимах работы установки (например, один снимок в режиме флюорографа, а другой в режиме полноценного рентгеновского аппарата).