

Мы в Skyeng очень много внимания уделяем анализу данных. Он позволяет нам правильно планировать работу и распределять ресурсы между различными задачами. Сегодня разработчик аналитики Глеб Сологуб расскажет, как он собрал для нас инфраструктуру сбора и анализа данных по всему нашему зоопарку сервисов и приложений, уложившись в годовой бюджет 12 тыс долларов.
У Skyeng есть своя экосистема, включающая веб-платформу, на которой ученики школы проходят интерактивные уроки с преподавателями, делают домашние задания и сдают тесты, а также несколько мобильных приложений под iOS и Android и браузерных расширений, которые помогают тренировать различные навыки английского языка.
«Мы быстрые и гибкие», любит повторять один из основателей компании Харитон Матвеев, поэтому у всех этих продуктов независимые команды разработки, использующие свои любимые стеки технологий, а значит, плодящие отдельные наборы баз данных. У каждой из этих команд свой менеджер, он же продакт, который опять-таки сам себе выбирает инструменты для продуктовой аналитики, будь то Google Analytics, Amplitude или что-то совсем экзотическое.
Этот подход классно работает, пока каждый из них измеряет только свои собственные KPI. Когда же появляются вопросы из серии: «Насколько быстрее и лучше изучают английский те, кто, кроме уроков с преподавателем, самостоятельно учат слова в приложении?», возникает нужда в кросс-продуктовой аналитике, для которой нужна специальная инфраструктура сбора и совместной обработки данных из различных источников.
Skyeng нанял меня с целью быстро собрать такую инфраструктуру на готовых платных сервисах в пределах бюджета размером в $12K на ближайший год, чтобы затем заменять их своими разработками по мере того, как это станет экономически оправданным.
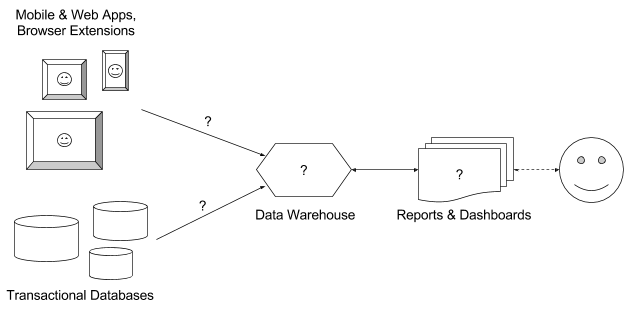
Мне нужно было построить инфраструктуру для сбора произвольных событий из всех продуктов, объединения их с нужными данными из различных баз в едином хранилище, анализа и визуализации этих данных в виде отчётов и дэшбордов; то есть решить 4 вопроса на картинке выше. Как же я разгадал этот ребус?
Какое выбрать хранилище данных?
Центральный вопрос — куда, собственно, складывать данные. Основных критериев в случае Skyeng было три:
- скорость выполнения аналитических запросов;
- стоимость решения;
- сложность интеграции с системами аналитики и сервисами сбора данных.
Требования по скорости не позволили использовать традиционные строковые реляционные БД, а возможные интеграционные сложности заставили отказаться от всяких видов Hadoop as a Service и таких малораспространенных вариантов, как ClickHouse и Azure SQL Data Warehouse.
Крупные компании для подобных задач набирают команду data-инженеров и собирают пачку Hadoop-кластеров или выделяют бюджет на загрузку данных в Vertica, чтобы собирать там свое хранилище данных, но планка по деньгам сразу отсекла такие варианты.
Компании поменьше для таких задач используют Redshift или BigQuery; по большому счёту, между ними и пришлось выбирать. На мой взгляд, бессмысленно сравнивать эти сервисы по скорости — они оба достаточно быстрые, кроме разных пограничных случаев. У обоих есть развитая экосистема и интеграция с множеством сервисов.
Что касается цены, на первый взгляд может показаться, что BigQuery значительно дешевле. В минимальной конфигурации 1 кластер Redshift дает 160GB места и стоит ровно $180 в месяц, а BigQuery имеет гибкий ценник — всего лишь $0.02 за 1GB в месяц. Однако стоимость Redshift не зависит от количества и нагрузки аналитических запросов, в то время как в BigQuery запросы отдельно тарифицируются по $5 за 1TB обработанных данных — казалось бы, недорого.
Но давайте посмотрим на то, как в BigQuery вычисляется размер данных, и вспомним, что это колоночная база, и что для получения даже одного поля из одной строки нужно вытащить всю колонку. Возьмём какой-нибудь простейший вопрос: например, нам нужно посчитать по датам число пользователей, открывших конкретную страницу платформы Vimbox, это будет такой типовой запрос к BigQuery:
select date(timestamp) as period, count(distinct user_id) as user_count
from [vimbox.pages]
where path = '/showcase'
group by period;Здесь достаются данные из двух колонок: user_id типа integer и path типа string. Если в табличке, скажем, 100 млн. строк, то стоимость такого запроса составит несколько центов. Если у вас, например, 100 отчётов с подобными запросами, каждый из которых пересчитывается 2 раза в сутки, то ваш счет за месяц будет измеряться уже сотнями долларов.
Можно, конечно, использовать разные ухищрения, чтобы минимизировать число обрабатываемых данных. Например, можно класть всё в partitioned table и доставать во всех отчётах только данные за небольшой период. Но тогда получается, что вместо того, чтобы воодушевлять, BigQuery дестимулирует вас использовать эти ваши большие и даже не очень большие данные. Вместо того, чтобы стараться делать всевозможные запросы в поисках инсайтов, вы всё думаете, как бы их ограничить, — это грустная история.
В общем, я остановился на Redshift, держа в уме, что если есть какая-то более оптимальная конфигурация с BigQuery, то можно использовать и его.
Какой выбрать сервис сбора событий?
Напомню, что базовыми элементами продуктовой аналитики являются события. Показ страницы на сайте или экрана в приложении, нажатие кнопки, успешная авторизация, ошибка системы, покупка товара — это всё различные события.
В традиционной веб-аналитике принято ставить счетчики так, чтобы отслеживать события показа всех страниц сайта. Такие сервисы, как Mixpanel и Heap, умеют автоматически отслеживать ещё и все клики (в GA для этого есть специальный плагин autotrack). Этот подход называют ретроактивной аналитикой, потому что все события собираются заранее, на всякий случай, а используются в отчётах только по мере необходимости. Heap и Segment умеют автоматически отслеживать переключения экранов мобильных приложений, но от этого толку мало, потому что экраны, в отличие от веб-страниц, обычно получают не очень содержательные названия вроде Table7, SEStart или UIAlertController.
Естественно все эти сервисы также имеют API для отправки произвольно заданных событий. И продуктовый подход к аналитике заключается как раз в том, что нет смысла собирать все подряд события, а в первую очередь нужно научиться сознательно отслеживать небольшое количество ключевых действий, к которым относятся, например, первые шаги новичков в процессе онбординга, регистрации, активации и основные действия постоянных пользователей.
Мне и моим коллегам в Skyeng такой подход нравится, только вот, когда у тебя 10 разных продуктов, написать для каждой команды разработчиков спецификацию отправки событий и придумать способ верификации того, что все события отправляются правильно, становится настоящей головной болью. Поэтому очень хотелось выбрать один сервис, который умеет собирать события со всех платформ (Web, iOS, Android) и по HTTP (для браузерных расширений и сервера) и делает это если не автоматически, то хотя бы каким-то унифицированным способом.
Кроме того нам нужен был сервис, который умеет не только собирать события, но еще и складывать их в хранилище данных. Возможность сырого экспорта событий в том или ином виде есть во всех сервисах. Даже в бесплатной версии GA вроде как есть хитрый способ выгружать единичные события через обычный Reporting API. Но регулярно и бесперебойно доставать сырые логи, обрабатывать их, вынимать нужные поля и складывать в структурированном виде в хранилище — задача сама по себе непростая, хотелось её тоже спихнуть на сервера и плечи сторонних разработчиков.
Я опробовал и сравнил несколько кросс-платформенных сервисов на предмет соответствия нашим требованиям, получилась такая табличка:
| Web | iOS | Android | HTTP | Ретроактивный сбор событий | Услуга по выгрузке данных в хранилище | Стоимость за год | |
|---|---|---|---|---|---|---|---|
| Mixpanel | + | + | + | + | с ограничениями | - | ~$50K |
| Amplitude | + | + | + | + | - | + | ~$50K |
| Heap | + | + | - | + | + | + | $31K |
| Localytics | + | + | + | + | - | + | $15.5K |
| Facebook Analytics | + | + | + | - | - | - | бесплатно |
| devtodev | + | + | + | + | - | - | $0.9K |
| Amazon Mobile Analytics | + | + | + | + | - | с ограничениями | ~$0.1K |
| Segment | + | + | + | + | с ограничениями | + | $3.6K |
| mParticle | + | + | + | + | - | + | $36K |
Стоимость за год в этой табличке рассчитана при условии ежемесячного отслеживания 30 тысяч активных пользователей, 600 тысяч сессий и 100 млн событий, а также услуги выгрузки данных в хранилище, если таковая предоставляется. Эти числа соответствовали годовому плану по росту Skyeng.
Специфика школы в том, что ядро активных пользователей пока ещё не очень велико (около 12 тысяч учеников за февраль 2017 года), но оно растет в 3 раза год от года, и в каждом из продуктов школы они проводят по несколько часов в неделю, уже сейчас ежедневно совершая миллионы различных действий. Поэтому, в отличие от других сайтов и приложений, где пользователей гораздо больше, а LTV сильно меньше, нам выгоднее пользоваться сервисами с моделью оплаты, зависящей от числа пользователей.
Первые 7 сервисов из таблички являются полноценными аналитическими платформами с различными инструментами визуализации, построения отчётов, маркетинговой коммуникации и т.п., а последние 2 специализируются именно на сборе событий из разных источников, обогащении их данными из различных CRM и маркетинговых сервисов и отправке их в хранилище данных.
Из всех 7 вариантов в бюджет вписывались только 4, а из них только Segment и Amazon Mobile Analytics предоставляли возможность автоматической выгрузки событий в хранилище данных. Однако решение от Amazon имеет довольно нелепое ограничение — каждый раз при добавлении нового свойства к событию нужно заново создавать схему автоматического экспорта, что приводит к потере всех уже экспортированных данных в Redshift. Нормально работает только автоматическая выгрузка событий в S3, но чтобы оттуда запихнуть их в Redshift, опять-таки нужно самому программировать data pipeline, а это отдельная работа с отдельной зарплатой.
В результате я выбрал Segment. У него есть SDK и API для сбора событий под все нужные нам платформы, и он умеет автоматически выгружать все данные в BigQuery и Redshift. Ретроактивно в нём можно собирать только некоторые события в мобильных приложениях, но зато у него продуманная система записи событий в хранилище и вообще проработанный подход к сбору событий, а ещё есть отладчик, в котором удобно смотреть поступающие в реальном времени события.
Особенно удачно в случае Skyeng то, что Segment берет деньги не за число собранных событий, а за число уникальных пользователей в месяц.
Какой выбрать сервис загрузки данных из баз?
Помимо сбора событий непосредственно из продуктов, нам нужно ещё и выгружать данные из их баз, а у Skyeng это целый зоопарк — разные инстансы разных версий MySQL и PostgreSQL, как облачные, так и на собственных серверах. Существуют решения, которые делают и то, и другое: например, Treasure Data и Alooma; однако стоимость у них крайне непрозрачна и в выделенный бюджет однозначно не вписывается (в год ~$30K за Alooma или $60K за Treasure Data при условии ежемесячной отправки 100 млн событий из приложений и 100 млн строк из баз данных).
Ещё раз уточню, что варианты писать своё ETL-решение, даже на основе существующих фреймворков типа Luigi или Airflow, и программировать пайплайны были отброшены сразу же, так как требуют как минимум ещё одной пары рук программиста и соответствующего увеличения фонда оплаты труда.
Из автоматических сервисов мне были известны только FlyData, Fivetran, Xplenty и Stitch, и я выбрал просто самый дешёвый из них — Stitch даёт бесплатный триал на месяц, в течение которого можно выгрузить все исторические данные и настроить инкрементальную репликацию новых данных (до 100 млн строк в месяц за $500).
В отличие от Xplenty, который по сути является полноценным ETL-сервисом с поддержкой различных трансформаций данных, Stitch имеет довольно примитивный интерфейс и позволяет просто отметить галочками, какие таблицы и какие поля из них (или все) вы хотите реплицировать, с какой периодичностью и каким способом.
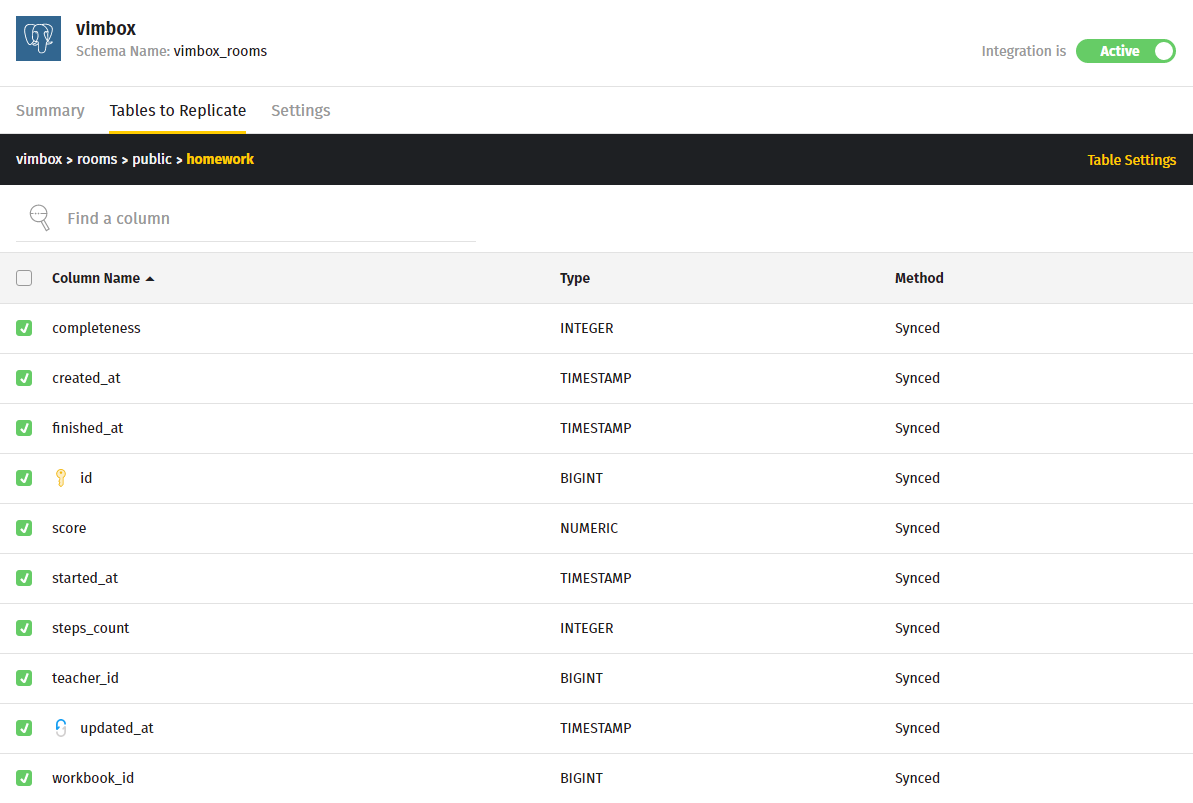
В Stitch поддерживается полная перезапись и инкрементальная репликация по ключу, которым может быть, например, первичный ключ, если строки в исходную таблицу только добавляются, но не изменяются, либо, например, updated_at, если это поле хранит дату последнего изменения строки. При необходимости трансформации данных до перенесения в хранилище нужно прямо в исходной базе создать view с нужными данными и реплицировать этот view аналогичным образом.
Должен сказать, что такое простое решение оказывается достаточным в большинстве случаев.
Stitch поддерживает различные хранилища, сам осуществляет преобразования типов данных в зависимости от хранилища (например, json и enum переводит в varchar в случае Redshift), а также следит за структурой исходной базы и изменениями в таблицах — новые колонки подцепляются автоматически. Ещё у них толковая служба поддержки, которая много раз помогала мне решать самые разные вопросы прямо в окошке чата.
По деньгам всё же это первый кандидат на замену в выбранной архитектуре, потому что при росте числа реплицируемых таблиц очень быстро станет выгодным просто завести отдельного ETL-разработчика.
Какую выбрать систему аналитики?
После того, как все данные попали в хранилище, встаёт вопрос, как их анализировать и визуализировать. Планка по деньгам опять-таки сыграла решающую роль — я был вынужден сразу отбросить прекрасные и очень дорогие инструменты для визуальной BI-аналитики вроде Looker и Chartio, а также слишком дорогие SQL-only решения вроде Periscope Data.
Выбор стоял между Mode, Redash и Plotly. Все эти сервисы позволяют подключаться к различным хранилищам данных, делать к ним SQL-запросы и визуализировать их различными способами, строить отчёты и дэшборды и давать к ним доступ другим пользователям.
Mode кроме того позволяет делать пост-обработку данных при помощи python-библиотек, подключать различные библиотеки для кастомной визуализации, делать отчёты с параметрами, а также хранит историю изменений запросов в своём репозитории. На более высоком уровне подписки доступна функция сохранения select-запросов в качестве определений.
Redash позволяет делать отчёты с параметрами двух видов: просто фильтрами, которые влияют на отображение уже полученных результатов запроса, и параметрами, которые будут подставляться в сам запрос.
В Redash можно переиспользовать уже написанные куски SQL-кода, сохранив их как сниппеты. В отличие от других вариантов, у Redash есть прекрасная функция автопересчёта запросов по расписанию, а ещё механизм оповещений в Slack или на почту, триггером для которых является изменение заданного значения в результатах запроса. На более высоких уровнях подписки как в Redash, так и в Mode есть возможность администрирования доступа к отчётам для групп пользователей.
Plotly изначально был просто JavaScript-библиотекой для визуализации с открытым исходным кодом, а сейчас он обладает самыми навороченными средствами визуализации данных и имеет API для ещё нескольких языков, включая Python, R и Julia. Функция создания дэшбордов появилась в нём относительно недавно. В отличие от Redash и Mode, у Plotly более простая система контроля доступа — можно лишь расшарить график или дэшборд по ссылке либо в публичный доступ.
По деньгам расклад такой: у Plotly стоимость зависит от числа аналитиков, $0.4K на человека в год, просмотр готовых отчётов не требует подписки. Самый дешёвый план у Mode включает 10 аккаунтов и 5 тысяч SQL-запросов и стоит $3K в год. Минимальная стоимость Redash без ограничения по числу просматривающих отчёты пользователей — $1.2K в год, а с разграничением прав доступа на уровне отчетов — $5.4K в год, но при этом можно безвозмездно поднять его на своём сервере.
Эта особенность Redash привлекала больше всего, так как в поставленной задаче предполагалось поэтапно заменять самые дорого обходящиеся сервисы собственными разработками. С учётом того, что у меня с ним уже был большой опыт работы, я выбрал именно его.
Результат

За 4 месяца мне удалось собрать всю эту инфраструктуру, подключить в неё данные из всех продуктов и их баз и построить около 90 отчётов и дэшбордов по различным KPI и метрикам, потратив всего около $2K (с учётом 3 месяцев бесплатного триала Redshift, прогрессивной ставки помесячной оплаты Stitch и Segment, и того, что мы пока помещаемся в не самый дорогой план Redash).
В частности, удалось по каждому продукту посчитать долю активных учеников школы, которые им пользуются:

Может показаться, что это простая задача, но на самом деле тут нужно было собрать воедино данные из этих продуктов (например, события тренировки из приложения Words) и данные о занятиях из базы школы.
Построенная инфраструктура легко горизонтально масштабируется при увеличении количества обрабатываемых данных, а использованный стек сервисов можно модифицировать и дополнять с разных сторон другими элементами вроде Amazon Machine Learning в качестве сервиса машинного обучения или различных CRM и маркетинговых платформ в качестве отдельных источников данных.
Всем компаниям, которые давно хотят построить свою инфраструктуру облачной аналитики, но опасаются влететь в копеечку, советую перестать бояться и начать это делать, нынче это стало гораздо проще и дешевле, чем было пару лет назад.
P.S. Прямо накануне этой публикации я обнаружил ещё один недорогой сервис Holistics, который можно использовать и для создания отчетов, и для репликации данных из базы, но протестировать его ещё не успел.
P.P.S. Было бы круто добавить сюда вакансию от Глеба, но он ее уже успешно закрыл. Поэтому просто напоминаем: у нас есть много интересной работы для интересных людей. Присоединяйтесь!
Комментарии (13)

Eclipse2186
26.04.2017 11:42Exponea же. В связке с GBQ, используемой для долгосрочного хранения — и аналитика и персонализация и маркетинговые коммуникации, кроссканально. Зато будет база in-memory, терабайты за секунды без семплинга.

mngr
26.04.2017 12:48Спасибо, не знал про такой сервис. Подозреваю, что он обойдется дороже $12K в год. Запросил у них цены, отпишусь по результатам.
Eclipse2186
26.04.2017 13:03Ну, у нас прайс за 570 евро в месяц, хотя мы небольшие. Но зато это фул-стек а не отдельные тулзы.
mngr
26.04.2017 13:43Подозреваю, что это у вас цена для старых пользователей.
Мне ответили так:
«Прайс ззависит от количества одновременно хранимых событий в базе быстрого доступа. Тут, правда, очень сложно судить о активности в ваших мобильных приложениях, не знаком с ними, но я думаю, что вам стоит ориентироваться на 25М — 50М — 100М. Это, соответственно, €2200 / 3400 / 4700 в месяц.»Eclipse2186
26.04.2017 14:00Уже два года почти, да. У нас меньше тариф. Но вы по сравнению с нами побольше будете.

AnBeeToSee
26.04.2017 19:05Глеб, а сколько потребителей?
Сколько людей строит отчетность?
Работает только в вебе или есть мобильные приложения?mngr
26.04.2017 19:10У нас сейчас 5 человек, которые пишут отчеты, около 30 менеджеров, которые имеют доступ ко всем отчетам и активно пользуются ими в Redash, и еще много рядовых сотрудников, которым выдан доступ только к конкретным отчетам.
Мобильного приложения у Redash нету, но просматривать отчеты с телефона вполне реально, там адаптивная верстка.Eclipse2186
26.04.2017 22:43Слушайте, а зачем пять человек? Что они все делают?
mngr
26.04.2017 23:32Да много чего делают. Я занимаюсь продуктовой аналитикой. Мой коллега сейчас делает модель прогноза оттока клиентов Отдел статистики делает отчёты для операционного отдела,

aramais
30.04.2017 12:52А почему даже не попробовали Clickhouse?
Clickhouse пока (!) мало распространен, но очень быстр, по скорости транзакций не уступает Vertica а местами отрабатывает быстрее.mngr
30.04.2017 13:11Передо мной стояла задача выбрать такое хранилище данных, в которое можно было бы загружать события с мобильных устройств и реплицировать данные из других баз, а потом делать на нем аналитические отчёты в облаке, и всё это на готовых сервисах, без программирования.
Насколько мне известно, для ClickHouse просто не существует таких сервисов, есть только API. По крайней мере, ни один из приведённых в статье сервисов с ClickHouse не работает, поэтому я и не рассматривал её всерьёз, только упомянул вскользь.
Если вы знаете такие сервисы, буду благодарен за информацию о них.
S0krat
На параграфе «Какой выбрать сервис сбора событий?» я умер весь. Где Amazon Kinesis Firehose??? Если выбран Amazon Redshift, то для сбора событий ничего более естественного, чем Amazon Kinesis Firehose — придумать невозможно.
mngr
Amazon Kinesis Firehose предназначен для стриминга данных с сервера, а у нас стояла задача собирать события из самых разных сервисов, в том числе мобильных приложений, которые работают в офлайн-режиме. Firehose сам по себе эту задачу не решает. Можно было бы написать свое решение для сбора и хранения событий на мобильном устройстве и отправки их на сервер при подключении к интернету, решить кучу побочных проблем, вроде правильного расчёта времени события, но зачем это делать, если есть недорогие готовые решения?