
При переходе к распределённым системам с большим количеством инстансов сервисов в полный рост встают проблемы их обнаружения (service discovery) и балансировки запросов (load balancing) между ними. Как правило, для их решения используются такие специализированные инструменты как Consul, Eureka или старый добрый Zookeeper, в сочетании с Nginx, HAProxy и некоторым мостом между ними (см. registrator).
Основная проблема в подобном подходе это большое количество интеграций, и, как следствие, точек где что-то может пойти не так. Ведь помимо вышеупомянутых решений наверняка будет использоваться локальный маленький PaaS (например Mesosphere Marathon или Kubernetes). Последние, к слову, уже хранят необходимую конфигурацию об окружении (ведь через них идёт весь деплоймент). И встаёт вопрос, а можем ли мы отказаться от специализированных инструментов для service discovery и переиспользовать тот же Marathon для этой задачи?
Краткий ответ — можем. Если интересно как — читайте дальше.
Диспозиция
Итак, что у нас есть в наличии:
- Apache Mesos и его верный фреймворк Marathon в качестве системы оркестрации сервисов
- Сервисы, которые написаны с использованием фреймворка Spring Boot и его расширения Spring Cloud
Mesos без сахара (читай без фреймворков) это система управления ресурсами кластера, которую можно расширять с помощью фреймворков. Фреймворки служат разным целям. Какие-то умеют запускать широкий спектр краткосрочных задач (Chronos), другие долгоживущих (Marathon). А некоторые заточены под конкретные продукты, такие как Hadoop или Jenkins.
Mesosphere Marathon представляет из себя тот самый фреймворк, который умеет управлять запуском, остановкой и в целом планированием работы долгоживущих задач, к которым можно отнести сервисы, обрабатывающие клиентские, и не очень, запросы на длительном промежутке времени.
Spring Cloud это тоже фреймворк, но уже для разработки этих самых сервисов, в котором реализованы как основные паттерны для их работы в распределённых системах, так и конкретные интеграции этих паттернов с существующими на рынке решениями (например, с тем же Consul-ом).
В рамках Spring Cloud-а для решения задачи обнаружения сервисов есть фактически две реализации.
Первую, с помощью Netflix Zuul, можно отнести к шаблону Server-Side Service Discovery. Суть шаблона заключается в том, что мы делаем некоторое количество роутеров, которые знают текущее местоположение и различную мета-информацию об инстансах сервисов, и предоставляют постоянные http-ресурсы, через которые идёт проксирование запросов к ним. Если абстрагироваться от Spring-а, то классическим роутером является nginx при условии его динамической конфигурации.
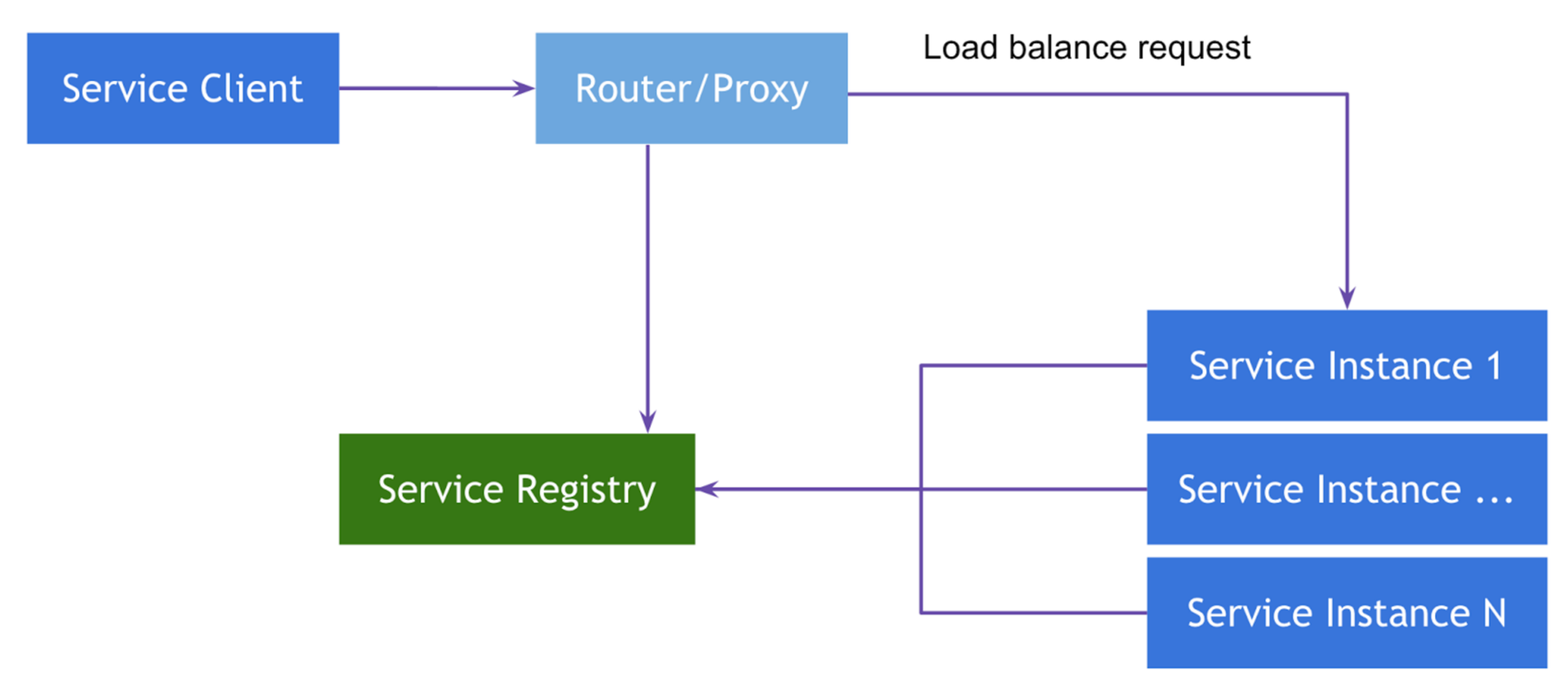
Вторая реализация относится к классу Client-Side Service Discovery. Основное её отличие от предыдущей состоит в отсутствии роутера, а следовательно промежуточного звена и лишней точки отказа, как класса. Вместо этого в качестве роутера используется "умный" клиентский балансировщик, который также знает всё, что нужно знать, про инстансы сервисов, которые он вызывает. В Spring Cloud в качестве такого балансировщика используется Netflix Ribbon.
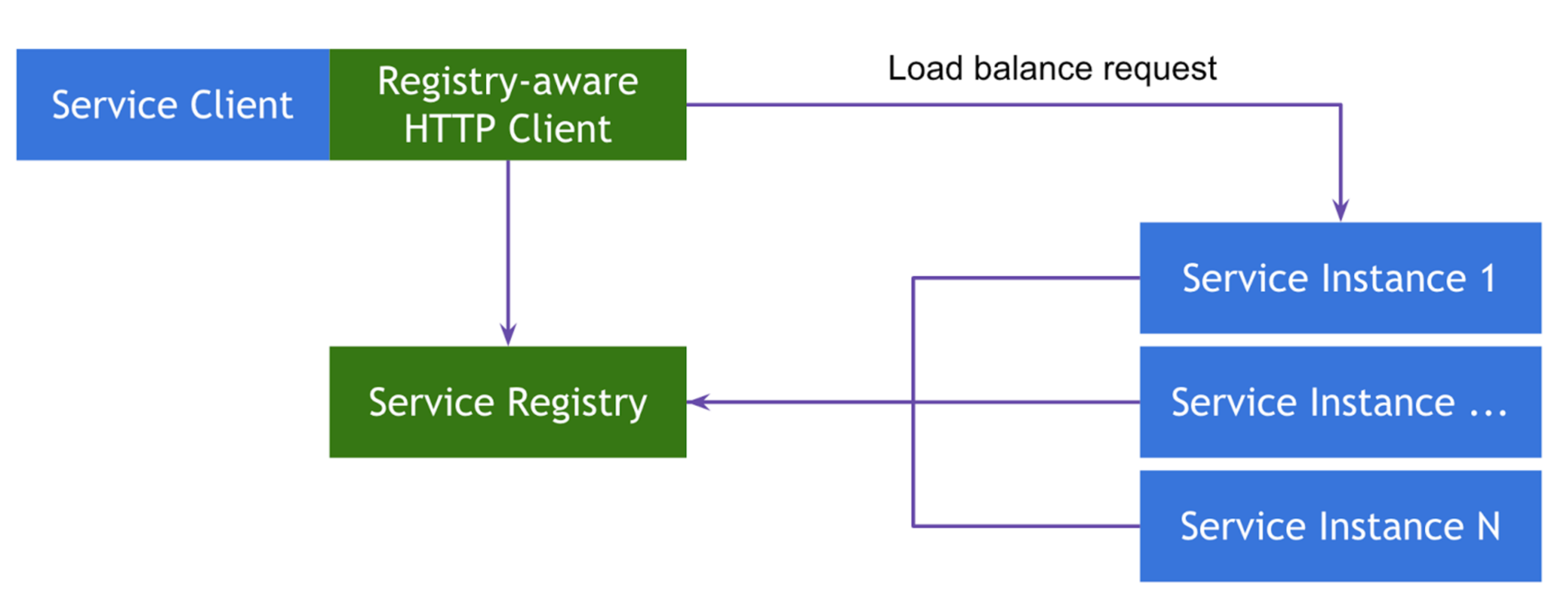
В этом цикле статей мы подробнее остановимся на клиентской реализации шаблона, хотя и про серверную тоже поговорим.
@EnableDiscoveryClient
В Spring-е почти всё можно сделать работающим влепив над классом/методом/переменной один-другой десяток аннотаций и прописав немножко конфигурации в yaml-файл. Ну ок, предположим, что не всё, но многое.
Методичка учит нас, что добавив magic-аннотацию @EnableDiscoveryClient над своим приложением, у нас будет работать (после пары зависимостей и настроек, но об это чуть позже) обнаружение сервисов. По крайней мере локально внутри нашего приложения. Сделать это можно очень просто, даже напрягаться не надо:
@SpringBootApplication
@EnableDiscoveryClient
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}После этого начинается магия в которой нет волшебства. Spring увидев эту аннотацию загружает все конфигурации, которые указаны в META-INF/spring.factories в качестве загружаемых для EnableDiscoveryClient:
org.springframework.cloud.client.discovery.EnableDiscoveryClient=org.springframework.cloud.xxx.discovery.XXXDiscoveryClientConfigurationОткуда и какие вообще могут быть загружены конфигурации? Для ответа на этот вопрос нужно сказать, что сам Spring Cloud состоит из базовой части, в которой есть необходимые интерфейсы и общая логика реализации различных шаблонов, и коннекторы, которые поставляются в виде starter-ов, и в которых есть конкретная имплементация для конкретных решений. Схематично мы можем изобразить это так: 
Например, если мы подключим стартер для Netflix Eureka, то у нас в classpath будет одна фабричная конфигурация. Если же стартер для Consul-а, то другая.
Засада тут однако в том, что сама по себе аннотация, при промышленной, а не "хэллоуворлд" разработке, чуть менее чем полностью бесполезна, поскольку весь профит находится в области прописывания правильных настроек в bootstap.yml. И для каждого коннектора они, как вы уже наверное догадались, свои.
Почему так сделано понять несложно. Eureka, Consul и Marathon устроены совершенно по разному. К ним нужно по разному подключаться. У них разный API и фичи, которые специфичны для конкретного решения. Сделать универсальный конфиг невозможно, да и в общем-то незачем.
Однако вернёмся к конфигурации, которая тянется с помощью @EnableDiscoveryClient. И первое что приходит в голову, и что быстро находится через поиск в любимой IDE, это реализация интерфейса DiscoverClient. Самый главный (по крайней мере на первый взгляд) интерфейс выглядит так:
public interface DiscoveryClient {
public String description();
public ServiceInstance getLocalServiceInstance();
public List<ServiceInstance> getInstances(String serviceId);
public List<String> getServices();
}В принципе, тут всё довольно очевидно. Мы можем получить описание для HealthIndicator-а. Можем получить сами себя. Можем получить все инстансы по некоторому идентификатору сервиса. И, наконец, можем получить список всех известных сервисов (точнее их идентификаторов).
Самое время реализовать интерфейс для того, чтобы получать данные из Marathon-а.
Первая кровь
Как получить данные? Это первый вопрос, который нам нужно решить. И это не то, чтобы трудно.
Во-первых, у него есть мощный API. Во-вторых, есть уже готовый для Java SDK.
Берём ноги в руки и реализуем получение списка всех сервисов:
@Override
public List<String> getServices() {
try {
return client.getApps()
.getApps() //тавтология, но что поделать
.parallelStream()
.map(App::getId) //получаем идентификаторы
.map(ServiceIdConverter::convertToServiceId) //немного магии не помешает
.collect(Collectors.toList());
} catch (MarathonException e) {
return Collections.emptyList();
}
}Никакой магии за исключением ServiceIdConverter::convertToServiceId. Что это за странный конвертер спросите вы. И тут надо сказать об одной особенности представления идентификаторов сервисов в Marathon-е. В общем случае они подчиняются следующему шаблону:
/group/path/appно символ / не может использоваться для построения виртуального хоста. И, таким образом, некоторые части Spring Cloud-а, в которых используется идентификатор сервиса в качестве виртуального хоста, работать не будут. Поэтому вместо / будем использовать другой разделитель, который разрешён присутствовать в имени хоста, а именно точку. Именно поэтому мы вынуждены получить соответствие /group/path/app на group.path.app. Что собственно конвертер и делает.
Получение всех инстансов сервиса реализовано несколько сложнее, но тоже никакого ракетостроения:
@Override
public List<ServiceInstance> getInstances(String serviceId) {
try {
return client.getAppTasks(ServiceIdConverter.convertToMarathonId(serviceId))
.getTasks()
.parallelStream()
.filter(task -> null == task.getHealthCheckResults() || //health-чеков нет, ну и ладно
task.getHealthCheckResults()
.stream()
.allMatch(HealthCheckResult::isAlive) //все должны быть живы
)
.map(task -> new DefaultServiceInstance(
ServiceIdConverter.convertToServiceId(task.getAppId()),
task.getHost(),
task.getPorts().stream().findFirst().orElse(0), //magiс zero
false
))
.collect(Collectors.toList());
} catch (MarathonException e) {
log.error(e.getMessage(), e);
return Collections.emptyList();
}
}Основное, что нам нужно проверить, это то, что для сервиса прошли все health-чеки: HealthCheckResult::isAlive, ведь наша задача работать только с теми, кто жив. Механизм health-чеков предоставляется самим Marathon-ном, который даёт возможность их настройки и сам же следит за здоровьем вверенных ему сервисов, раздавая безвозмездно эту информацию через API.
Помимо этого, нам нужно не забыть опять же сконвертировать идентификатор в правильное представление и выбрать только один, первый, порт: task.getPorts().stream().findFirst().orElse(0).
Так так так, скажете вы. А что же делать, если портов у приложения несколько? К сожалению, выбор у нас невелик. Мы с одной стороны должны вернуть объект, реализующий интерфейс ServiceInstance, у которого есть метод getPort, который понятное дело может вернуть только один порт. А с другой, мы на самом деле не знаем, какой порт из списка брать. Marathon не даёт нам об этом какой-либо информации. Поэтому берём тот, что указан первым. Авось повезёт.
Можно попробовать решить эту проблему так, как решает её registrator при регистрации сервисов в том же Consul-е. Это учитывать порт сервиса в его идентификаторе. Тогда идентификатор сервиса будет примерно таким: group.path.app.8080 в случае, если портов больше одного.
Немного отвлеклись. Самое время добавить новоиспечённую имплементацию как бин:
@Configuration
@ConditionalOnMarathonEnabled
@ConditionalOnProperty(value = "spring.cloud.marathon.discovery.enabled", matchIfMissing = true)
@EnableConfigurationProperties
public class MarathonDiscoveryClientAutoConfiguration {
@Autowired
private Marathon marathonClient;
@Bean
public MarathonDiscoveryProperties marathonDiscoveryProperties() {
return new MarathonDiscoveryProperties();
}
@Bean
@ConditionalOnMissingBean
public MarathonDiscoveryClient marathonDiscoveryClient(MarathonDiscoveryProperties discoveryProperties) {
MarathonDiscoveryClient discoveryClient =
new MarathonDiscoveryClient(marathonClient, marathonDiscoveryProperties());
return discoveryClient;
}
}Что тут важно. Во-первых мы используем conditional-аннотации: @ConditionalOnMarathonEnabled и @ConditionalOnProperty. То есть, если в настройках будет отключена функциональность, например через настройку spring.cloud.marathon.discovery.enabled, то конфигурация грузиться не будет.
Во-вторых, над нашим клиентом стоит волшебная аннотация @ConditionalOnMissingBean, которая даёт возможность в конкретном приложении переопределить бин так, как это будет нужно пользователю.
Нам остаётся сделать самую малость. Сконфигурировать клиента для Marathon-а. Наивная, но при этом рабочая, реализация конфигурации выглядит так:
spring:
cloud:
marathon:
scheme: http #url scheme
host: marathon #marathon host
port: 8080 #marathon portДля этого нам нужен класс с его настройками:
@ConfigurationProperties("spring.cloud.marathon")
@Data //lombok is here
public class MarathonProperties {
@NotNull
private String scheme = "http";
@NotNull
private String host = "localhost";
@NotNull
private int port = 8080;
private String endpoint = null;
public String getEndpoint() {
if (null != endpoint) {
return endpoint;
}
return this.getScheme() + "://" + this.getHost() + ":" + this.getPort();
}
}и очень похожая на предыдущую конфигурация:
@Configuration
@EnableConfigurationProperties
@ConditionalOnMarathonEnabled
public class MarathonAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public MarathonProperties marathonProperties() {
return new MarathonProperties();
}
@Bean
@ConditionalOnMissingBean
public Marathon marathonClient(MarathonProperties properties) {
return MarathonClient.getInstance(properties.getEndpoint());
}
}После этого мы можем радостно идти в наше приложение, заавтовайрить DiscoveryClient:
@Autowired
private DiscoveryClient discoveryClient;и, к примеру, получить список всех инстансов для некоторого сервиса:
@RequestMapping("/instances")
public List<ServiceInstance> instances() {
return discoveryClient.getInstances("someservice");
}И тут нас ожидает первый сюрприз. Наша цель ведь не в том, чтобы получить список инстансов, а в том, чтобы делать балансировку между ними. И оказывается, что DiscoveryClient для этого не то чтобы сильно полезен, потому что просто напросто никак в реализации балансировки не участвует. Ок, вру. Немного участвует, например при динамической регистрации endpoint-ов в Zuul-е. Ещё он используется для health-индикаторов. Но это в принципе всё его стандартное применение. Не так уж много правда?
Итого
Мы смогли проинтегрироваться с Marathon-ом. Это хорошо. Мы даже можем теперь получить список сервисов и их инстансов.
Но вместе с тем, у нас остались как минимум две нерешённые проблемы. Первая связана с тем, что у нас в конфигурации указан лишь один инстанс мастера Marathon-а для подключения. Если он упадёт, то мы перестанем владеть информацией, а следовательно и миром.
Вторая — мы так и не добрались до реализации клиентской балансировки и в руках у нас пока что детская игрушка, а не инструмент решающий проблемы.