

Почему так?
Как-то раз, когда я проходил по офису, меня остановил один разработчик и попросил помочь с юнит-тестами. У него возникли какие-то сложности при использовании Mockito для тестирования вот этого кода:

Мой ответ его, кажется, удивил. Я сказал: «Это не нужно тестировать».
«Конечно, нужно!» — ответил он. «Как я иначе узнаю, что всё работает?»
«Это совершенно прозрачный код. В нём ничего такого нет: ни атрибутов conditional, ни циклов, ни трансформаций. Просто обычный кусок связующего кода».
«Но если не провести тест, кто угодно может прийти, внести какие-нибудь изменения и всё сломать!»
«Послушай, пусть даже этот воображаемый недотёпа или злодей действительно придёт и всё испортит — как ты думаешь, что он сделает, когда соответствующий юнит-тест провалится? Удалит, и все дела».
«Ну а если бы тебе пришлось писать тест?»
«В таком случае я бы вышел из положения вот так».

«Но ты же не используешь Mockito!»
«И что? Mockito никак здесь тебе не помогает. Даже наоборот, мешается. С ним тест не станет ни проще, ни читабельнее».
«Но мы же решили, что будем проводить все тесты с помощью Mockito!»
Мой ответ: «…»
Когда я в следующий раз с ним столкнулся, он с гордостью поведал мне, что всё-таки сумел написать этот тест на Mockito. Я понимаю, какое удовлетворение испытываешь, когда получается заставить что-то работать, и всё же мне как-то взгрустнулось.
Другой пример
Другой раз меня подозвал разработчик, окрылённый высоким покрытием кода одного из своих новых приложений и вспыхнувшей любовью к BDD (разработке на основе поведения). Просматривая код, мы нашли такой тест на Cucumber:
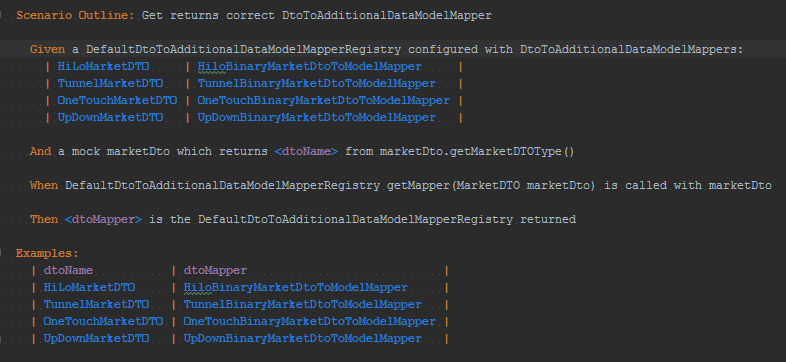
Тех, кто работал с Cucumber, не удивит объём вспомогательного кода, которого он требует:

И всё это ради того, чтобы протестировать следующее:

Да-да, простой map lookup. У меня были достаточно доверительные отношения с этим разработчиком, чтобы сказать ему без обиняков: «Столько времени потрачено впустую».
Он ответил: «Но мой начальник рассчитывает, что я буду писать тесты для всех классов».
«И во что это тебе обходится?»
«Обходится?»
«К тому же, этого не имеет никакого отношения к BDD».
«Знаю, но мы решили проводить все тесты при помощи Cucumber».
Мой ответ: «...».
Я понимаю, какое удовлетворение испытываешь, когда удаётся приспособить инструмент под свои нужды, и всё же мне как-то взгрустнулось.
В чём трагедия?
Трагедия в том, что двое талантливых разработчиков (я бы охотно сходил с ними на командное интервью) убивают время на подобные тесты — тесты, от которых никакого проку и которые следующим поколениям разработчиков из IG придётся поддерживать в рабочем состоянии.
Трагедия в том, что вместо того, чтобы выбрать подходящий инструмент для работы, мы мучаемся с теми, которые совершенно не годятся, и сами не знаем зачем.
Трагедия в том, что, когда «хорошая практика» становится общепринятой, мы будто забываем, как к ней пришли, какие преимущества она предлагает, и — самое-то главное — каких затрат она требует.
Вместо того, чтобы иметь это всё в виду, мы просто автоматически применяем её, особо не задумываясь, и в итоге получаем весьма посредственные результаты — теряем большую часть преимуществ, а платим при этом полную цену (иногда и с накруткой). Мой опыт говорит, что создание качественных юнит-тестов — работа непростая.
Так стоит ли обрабатывать код целиком?
Да, это должен проделать каждый… но только в рамках одного проекта.
У нас более чем достаточно примеров одной крайности: проектов без единого юнит-теста, и мы уже знаем, как мучительно с ними работать. Но мало у кого есть опыт взаимодействия с противоположной крайностью: проектов, где требуют стопроцентного покрытия кода и во всём придерживаются TDD. Юнит-тесты (особенно те, где реализуется подход test first) — отличная практика, но нам необходимо понимать, какие тесты полезны, а какие — только снижают продуктивность.
Помните: ничто не обходится нам даром, палочек-выручалочек не существует. Всегда лучше остановиться и подумать.
Комментарии (96)

noomorph
12.05.2017 12:21+5Я был достаточно высокого мнения об этом разработчике, чтобы сказать без обиняков
I had enough trust with the developer to bluntly say,
Может, лучше было бы перевести как-то вроде «У меня были достаточно доверительные отношения с этим разработчиком, чтобы сказать без обиняков», потому что, честно говоря, «высокое мнение» сбило с толку при чтении.

EverydayTools
12.05.2017 13:43Такой вариант перевода тоже рассматривали, но склонились «высокому мнению». Если это сбивает с толку, лучше исправим.

poxvuibr
13.05.2017 10:29+2Почему вы склонились к высокому мнению, когда никакого высокого мнения там нет?
noomorph
12.05.2017 13:25+4В целом, с посылом статьи я согласен, и мне кажется уже изначально некорректно требовать 100% покрытия кода именно от юнит-тестов, ведь не каждая строка имеет одинаковую ценность и смысл.
Так, например, нередко приходится написать пространное полотно конфигурации (подписаться, отписаться на события, проинициализировать ряд вещей, передать им ссылки друг на друга), но все это само по себе не имеет никакого смысла и ценности в отрыве от той большой общей задачи, для которой вообще этот код был написан.
То есть, технически-то можно протестировать строчку за строчкой, но такие тесты будут практически бесполезны, так как подобная (решаемая конфигурационным кодом) задача попросту неосязаема для близоруких проверок юнит-тестов, и поддается рассмотрению лишь взору интеграционных и end-to-end тестов.
Но, даже если мы напишем более релевантные тесты для таких случаев, задействуя альтернативные инструменты, то может возникнуть другой вопрос — как совместить по разным инструментам задачу подсчета покрытия кода (и зачем)? Насчет первого — тут я даже не уверен, делает ли так кто либо… суммируют ли E2E+Integration+Unit coverage? Думаю, что да, но реже, чем стоило бы.
Зачем суммировать? Ну, положим, если все же мы будем суммировать покрытие, и у нас будут оставаться в коде места, которые ни разу не выполнились в ходе прогона самых разнообразных тестов, то тогда мы сможем идентифицировать все места в существующей кодовой базе, которые имеют неясное предназначение, потенциально являясь источником недоразумений и/или багов.
И, наконец, если это на поверку оказывается нужной логикой, и этот код имеет право на существования, то тут мы подходим к заключительному, не самому приятному вопросу. Почему нам не подошли существующие инструменты для тестирования такого кода?
А это реальная ведь ситуация. За примерами далеко ходить не надо, если взять фронт-энд разработку — как насчет затерянного одинокого экзотического обработчика события, срабатывающего только для мобильного браузера Windows Phone 7? Можно понять человека, отказавшегося покрывать это тестами и проверившего обработчик пару раз вручную на живом телефоне.
Я думаю, что если бы написать такой экзотический тест было бы не дольше 20-30 минут и 10-20 строчек кода, то грешно было бы не написать. Но если же это грозит такими радужными перспективами как писать разные костыли, прикручивать друг к другу проекты номинально несовместимые или малоподдерживаемые, то ради чего?
В любом случае, мы здесь выиграем в том, что выявим недостатки в существующих инструментах тестирования и потенциально сможем добиться их улучшения (если это того стоит, ха-ха, ибо пример с WP7, пожалуй, слишком «суров»). А если мы не захотим или не сможем этого сделать, то как минимум у нас в проекте засчет интегрального такого покрытия будет всегда актуальная обновляемая карта «белых пятен на карте», перепись эдаких тихих омутов с чертями, что позволит держать их популяцию под хоть каким-то, но контролем.
Shifty_Fox
12.05.2017 16:07+5Задача юнит тестов не заключается в том чтобы тестировать итоговую работу приложения. Юнит тесты и выполняют возложенную на них задачу — тестировать отдельно каждую строчку кода как API. Они дают уверенность, что если приложение работает неправильно, то хотя бы кирпичики из которых оно состоит — надежны, и ошибку следует искать на более высоком уровне абстракции.

aamonster
12.05.2017 23:14+2По моему опыту, основная польза от юнит-тестов — само деление кода на такие независимые кирпичики.
oxidmod
12.05.2017 13:38-1На самом деле не вижу проблемі со 100% покрытием юнит тестами. Если достаточно дробить классы, то и тесты выходят короткими и простыми. Да, бывают случаи когда никуда не уйти от пачки зависимостей и приходится их мокать, но это происходит не так часто

Guderian
12.05.2017 13:43+4«Это совершенно прозрачный код. В нём ничего такого нет: ни атрибутов conditional, ни циклов, no трансформаций. Просто обычный кусок связующего кода».
Странно это читать от человека, который чуть выше говорит о «tests first». Мы пишем тесты не зная реализации. И делаем это в том числе и для того, чтобы появление ошибочных «атрибутов conditional, циклов, трансформаций» было контролируемо.JPEG
12.05.2017 15:14+2Вот вы молодцы, вы инкапсуляцию не нарушаете. А мы тестим именно реализацию, потому что так сказал насяльника. Хорошие программисты как-то интуитивно держат баланс между гибкостью и формализмом, а неопытные просто добивают "покрытие" до 100% и идут спать. К ним статья, по-моему, и обращается.

ApeCoder
12.05.2017 18:11А мы тестим именно реализацию, потому что так сказал насяльника.
Интересно, как он сказал это? Непокрытый код значит, что требование, которое он рализует непокрыто. Просто это сигнал к тестированию требований.
JPEG
12.05.2017 18:29+2Очень просто, как всегда и делают, чтобы запороть проект: сказал нужно 100% покрытие, но БЫСТРО! То есть не вдумчивого тестирования требовал, где покрытие, это только вспомогательный сигнал, а просто числа процентов покрытия равного 100. И быстро :)
ApeCoder
13.05.2017 19:42+1Предсказываю, что это замедлит разработку — тесты будут хрупкие и непонятные и в какой-то момент очень много усилий будет тратиться на то, чтобы исправить непонятно почему падающие тесты.
JPEG
13.05.2017 19:54Совершенно согласен. Ладно бы поддерживать хорошие тесты, а они же именно что непонятные.
Особенно радуют ребята, которые называют свои буквальные непонятные многословные тесты почему-то спеками, не понимая, что спеки — это живая спецификация, которая как бы должна объяснять, как некий код правильно использовать без страха что-то сломать, так как разрабы сами тестят этой же спекой.
taujavarob
16.05.2017 17:56-2А мы тестим именно реализацию, потому что так сказал насяльника
Стоп. Если известно, что в методе должно обязательно быть обращение, например, к базе данных, (например, подключение) то логично это и протестировать в тестах — было оно или нет (передав, к примеру, тем или иным образом (через параметр или инверсию — тут не расматриваем), мок объекта-подключения к базе, в этот тестируемый метод)!
Если это не тестировать, то как узнать — был ли в тестируемом методе вызван метод подключения к базе или нет?
Если и это нам не надо узнавать — то вопрос — что же мы должны в этом случае тестировать? — Тестировать метод как «чёрный ящик»? — но в методе происходит подключение к базе, к примеру — что же мы можем оттестировать тогда такое в этом тестируемом нами методе?
Если это не узнавать — то что именно тестировать в тестируемом методе, где происходит подключение к базе, к примеру?
Я понимаю, к примеру, тестировать метод — который должен что-то вернуть никуда не обращаясь вообще (метод как "чистая функция") тогда ясно, что мы сочиняем набор тестов и смотрим соответствие — значения параметров переданных тестируемому методу — анализ результата из тестируемого метода.
Но и в этом случае, к примеру, нам известно, что при таких то значениях параметров метод не обращается во вне (к базе, инету, объекту ...), а при других значениях должен обязательно обратиться. — Что в этом случае тестировать, если мы не знаем реализации?
Тут вопрос такой — что есть такое «реализация» методом конкретного интерфейса?, к примеру — это «чёрный ящик» или реализация методом «спецификации».
Во втором случае ваш «насяльник» считает что вы должны знать спецификацию (алгоритм), которую реализует (имплементирует) ваш тестируемый метод.И он прав. имхо.
Если он не прав — то скажите мне, что вы тогда можете оттестировать в таком вот тестируемом методе («не чистой функции», грубо выражаясь)?
Вы хотите сказать — что надо стремиться чтобы таких методов не было, чтобы все методы можно было тестировать только и только разными значениями входных параметров? — Но в ООП это невыполнимо вообще. В ООП методы не есть «чистая функция» вовсе.
mayorovp
16.05.2017 18:46Если метод загружает данные из БД, то у правильного теста входные данные — это то, что лежит в БД (или в ее моке), а выход — то, что возвращает метод. Это — тест спецификации.
У корявого теста входа нет, а выход — это последовательность обращений к БД, которую нельзя нарушать. Это — тест реализации.
JPEG
16.05.2017 19:16Код, настолько неотделимый от базы данных приходится локализовывать и тестить вместе с базой.
А если в такт статье, то мой ответ: «...».taujavarob
17.05.2017 18:06Если метод загружает данные из БД, то у правильного теста входные данные — это то, что лежит в БД (или в ее моке), а выход — то, что возвращает метод. Это — тест спецификации.
СТОП СТОП
Мы тестируем метод, в котором используется, к примеру, объект сервиса (база ли это, или иное — не важно).
Если этот сервис просто возвращает что-то и мы тестируем метод который возвращает что-то основанное на возврате этого сервиса - то тут вы правы.
Но часто у нас есть такие методы, например:
Начало Метода
- Соединиться с сервисом и получить от него токен.
- Послать сервису данные, используя этот токен.
- Закрыть сервис.
Конец Метода.
Как вы собираетесь тестировать такой Метод без проверки что конкретно дёргали у мок-сервиса и в какой последовательности? — а был ли вызван метод у мок-сервиса о получении токена?, а был был ли вызван метод у мок-сервиса о передаче и что было передано?, а был ли вызван метод у мок-сервиса о закрытии сервиса?
Или далее, стандартный вывод в лог (в файл и т.п.):
Начало Метода (параметр)
- вывести в лог параметр (loger.log(параметр) )
Конец Метода.
Как вы оттестируете этот Метод, без тестирования того, что в этом Методе в этом случае (при этом значении параметра, к примеру) должно быть логирование, то есть должен быть вызван метод вывода в лог (метод log(...) мок-логера)?
И реальных примеров методов где есть вывод инфы (в файл, в лог, в консоль, редирект и прочее) полно в коде встречается. — Как тестировать такие методы без проверки вызова методов мок-объекта того или иного вида сервиса вывода инфы.
Можно, наверное, предложить вариант — создание специального объекта мок-сервиса, который бы «сохранял в себе» выводимую инфу и после вызова тестируемого Метода проверять этот объект мок-сервиса на наличие в нём выводимой инфы.
— Вы считаете это было бы лучше чем просто создать обычный мок-сервис по имеющемуся у нас файлу интерфейса этого сервиса и проверить при тестирование Метода (внутри которого используется этот сервис), а был ли вызван метод у этого мок-сервиса и с каким значение параметра?
P.S.
JPEGКод, настолько неотделимый от базы данных приходится локализовывать и тестить вместе с базой.
Называйте это базой или сервисом, сервисом вывода в консоль, в файл, в лог, редирект и прочее — то есть сервисом, который внутри тестируемого Метода «выводит инфу» (или обращается за установкой соединения, к примеру) во вне!
Как оттестировать такой Метод? Как оттестировать такой Метод не запросив (в написанном вами коде теста) — а был ли вызван метод у мока этого сервиса?
JPEG
17.05.2017 18:16+2Легко попасть в такие условия, когда уже ни вверх, ни вниз. Опытный скалолаз тем и отличается от мёртвого, что не загоняет себя в такие ситуации. Об этом, имхо, и статья.
mayorovp
17.05.2017 19:40Пожалуйста, используйте меньше жирного. Ну невозможно же нормально читать текст в пятнах...
В первом примере все просто. Если для общения с сервисом есть специальный протокол с состоянием — то последовательность вызовов, конечно же, является частью спецификации протокола.
Но при этом, к примеру, сам факт соединения с сервисом — это уже делать реализации! Тест не должен падать, к примеру, если не было сделано ни одного вызова к сервису (при условии выполнения остальных условий корректности).
Вывод в лог же у бизнес-методов тестировать не нужно совсем.
ApeCoder
18.05.2017 09:41Передать целостную инмемори реализацию сервиса.
Нам не надо знать, был ли получен или нет токен. Нам надо знать, что работа с сервисом происходит корректно. То есть передать такой сервис с которым можно работать только получив токен. Соответственно, тест не будет проверять вызван ли метод. Он будет проверять "или метод вызван или токен не нужен"
ApeCoder
18.05.2017 09:52Начало Метода
…
Конец Метода.Заметим еще что вы думаете тестированием реализации, попробуйте думать интерфейсом — какие требования к интерфейсу метода? И по ним построить тесты.
taujavarob
19.05.2017 18:36Заметим еще что вы думаете тестированием реализации, попробуйте думать интерфейсом — какие требования к интерфейсу метода? И по ним построить тесты.
Пример 1:
Метод сменить_имя(сервис, номер_записи, новое_имя) сервис.сменить_имя_записи(номер_записи, новое_имя); Конец Метода.
Мой вариант метода тестирования:
Метод тестировать_сменить_имя () создать мок-сервис; Правило проверки выполнения теста: Если был вызов мок-сервис.сменить_имя_записи() и параметры были равны: (номер_записи = 789, новое_имя = "Иванов" ), то ok иначе тест провален вызвать тестируемый метод: сменить_имя (мок-сервис, 789, "Иванов"); Конец Метода.
Ваш вариант этого теста?
P.S.
mayorovpЕсли метод загружает данные из БД, то у правильного теста входные данные — это то, что лежит в БД (или в ее моке), а выход — то, что возвращает метод. Это — тест спецификации.
Если не тестировать вызов метода у мок-сервиса, то, к примеру
Пример 1:
Метод получить_имя (сервис, номер_записи) имя = сервис.найти_имя_записи (номер_записи); return имя; Конец Метода.
Ваш, как я понял, вариант метода тестирования будет примерно таким:
Метод тестировать_получить_имя() создать мок-сервис; настроить мок-сервис:if вызван метод мок-сервис.найти_имя_записи(456) вернуть "Василий" Правило проверки выполнения теста: Если вызов получить_имя(мок-сервис, 456) возвращает "Василий", то ok иначе тест провален. вызвать тестируемый метод: получить_имя(мок-сервис, 456); Конец Метода.
Всё как-бы нормально, вы не проверяете — был ли вызван у мок-сервис метод.
Но тогда и для такого тестируемого метода ваши тесты пройдут нормально:
Метод получить_имя (сервис, номер_записи) return "Василий"; Конец Метода.
Что конечно же будет неверным.mayorovp
19.05.2017 18:59Такие методы нет необходимости не только тестировать — но даже писать. Это касается обоих примеров.
Что же касается трюка с
return "Василий"— то код-ревью не просто так придумали.
ApeCoder
19.05.2017 22:19[Test] void changeName_ShouldSetNewName() var service = new InMemoryService(); service.addRecord(recordId, OldName); subject.changeName(service, recordID, NewName); service.getName(recordID).should().be(NewName); }
Заметьте, что здесь мы абстрагируемся от того, каким именно споcобом vмы работаем с сервисом. Может быть, в будущем появится какой-то еще метод для более удобной работы с именем и от этого ничего ровно не изменится — требование сформулировано в абстрактной форме.
Но, так как метод не вносит вообще никакой собственной ценности. Я бы просто сделал inline method :)
ApeCoder
19.05.2017 22:21Но тогда и для такого тестируемого метода ваши тесты пройдут нормально:
По классическому TDD мы и должны сначала написать такой метод. А потом написать красный тест.
taujavarob
22.05.2017 12:36-1Заметьте, что здесь мы абстрагируемся от того, каким именно споcобом vмы работаем с сервисом
Вы привели тест который ничего не тестирует вовсе. Ваш код просто создаёт мок-сервис и вызывает его методы
Выше я приводил примере методов которые надо оттестировать — в этих методах вызываются сервисы (по крайней мере один). Нам нужны тесты этих методов, а не тесты сервисов в них используемых.
Например в этом методе вызывается один раз метод одного сервиса:
Метод сменить_имя(сервис, номер_записи, новое_имя) сервис.сменить_имя_записи(номер_записи, новое_имя); Конец Метода.
А вот пример метода в котором вызываются методы у двух сервисов (кэш и сервис):
Метод получить_имя (кэш, сервис, номер_записи) имя = кэш.найти_имя_записи (номер_записи); if (имя == null) { имя = сервис.найти_имя_записи (номер_записи); } return имя; Конец Метода.
Я считаю, что в тестировании методов внутри которых вызываются методы сервисов вида:
- get
- put
- post
- update
- delete
- find
надо обязательно проверять — был ли вызван метод мок-сервиса?
Иначе мы не сможет полноценно протестировать метод у которого внутри вызыватся методы сервиса.
Под сервисом я понимаю — любой внешний объект, у которого вызывается любой метод типа вышеперечисленных.
ApeCoderПо классическому TDD мы и должны сначала написать такой метод. А потом написать красный тест.
Ок.
Вначале пишем наш тестовый метод:
Метод тестировать_получить_имя() создать мок-сервис; настроить мок-сервис:if вызван метод мок-сервис.найти_имя_записи(456) вернуть "Василий" Правило проверки выполнения теста: Если вызов получить_имя(мок-сервис, 456) возвращает "Василий", то ok иначе тест провален. вызвать тестируемый метод: получить_имя(мок-сервис, 456); Конец Метода.
Потом пишем наш метод:
Метод получить_имя (сервис, номер_записи) //TODO return "Иван"; Конец Метода.
Ок. Наш тестовый метод — «тестировать_получить_имя()» — теперь красный.
Далее пишем код нашего метода:
Метод получить_имя (сервис, номер_записи) имя = сервис.найти_имя_записи (номер_записи); return "Василий"; Конец Метода.
Всё — тест проходит — но это неправильно!
mayorovpТакие методы нет необходимости не только тестировать — но даже писать. Это касается обоих примеров.
Наверное вы правы. Но, понимаете, в реальном мире не все методы есть «чистые функции».
В реальном мире приходится и выводить в консоль или файл или лог, менять данные в базе, переадресовывать запрос и т.п. — то есть в реальном мире требуется взаимодействие с внешним миром. И это я пишу без сарказма.
mayorovpЧто же касается трюка с return «Василий» — то код-ревью не просто так придумали.
Вы, надеюсь, в этом месте пошутили.ApeCoder
22.05.2017 12:59Вы привели тест который ничего не тестирует вовсе. Ваш код просто создаёт мок-сервис и вызывает его методы
Нет. subject.changeName вызывает метод SUT
надо обязательно проверять — был ли вызван метод мок-сервиса?
Иначе мы не сможет полноценно протестировать метод у которого внутри вызыватся методы сервиса.Можем. Надо думать требованиями а не реализацией.
Всё — тест проходит — но это неправильно!
- Если неправильно, надо надо повторить Red-Green-Refactor
- Надо писать простейшую реализацию сначала. Я бы сначала проверил поведение при отсутствии человека в базе
Прочитайте, пожалуйста книжку про юнит тесты. Например http://xunittestpatterns.com

AstarothAst
12.05.2017 14:34+16Странно, в заголовок вынесено стопроцентное покрытие, а приведенные примеры — один про человека, который поставил себе целью вовсе не покрытие, а использование москиты, а второй, похоже, просто перся от того, что наваял огромную портянку кода. При чем тут стопроцентное покрытие кода тестами, когда банально два оболтуса занимались черте чем?

sshikov
12.05.2017 23:50А что, по вашему написание теста для первого примера кода, без использования mockito, будет более полезным? Даже не так — оно вообще будет полезным? Попытка использовать негодные инструменты тут вторична, а первичной является идея тестировать то, что тестировать не нужно.
Для меня очевидна простая мысль — никому не нужны тесты сами по себе. Тесты — это инструмент обеспечения правильности программы, которая делает полезное дело. Если вы допустим можете доказать, что программа правильна — вам не нужно ее тестировать, вы уже достигли своей цели.
Если у вас есть убежденность, основанная на вашем знании устройства и анализе кода, что этот код правильный — это тоже может быть вполне достаточной причиной (может быть, но может и нет!), чтобы этот кусок кода не тестировать. Хотя бы потому, что ресурсы ваши всегда ограничены. Вы либо пишете тесты, либо делаете что-то другое, возможно более полезное. Либо обеспечиваете 100% покрытие, либо выпускаете новые функции, либо рефакторите код, делая его более простым и надежным by design.
А представьте, что дело обстоит так: вы выпустили релиз 1.0 своего продукта. Пользователи его применяют, прибыль растет, все довольны, багов мало или вовсе нет. А покрытие тестами скажем 10%. Вам все еще нужно 100% покрытие? А нафига, если потребитель доволен?

youlose
13.05.2017 09:01+2Вы исходите из ошибочного предположения что продукт написан и не изменяется. Если продукт развивается, то в нём появляются изменения которые как раз и могут ломать всё что угодно и тесты предназначены именно для этого, чтобы дать гарантию того что после внесения изменений весь предыдущий функционал продолжает работать как надо.
sshikov
13.05.2017 09:41Я до такого нигда не обобщал. Я исхожу из предположения, что все продукты разные, то о чем вы говорите — вполне имеет место, но к 100% покрытию имеет мало отношения — потому что как правило компоненты продукта развиваются и изменяются в разной мере, причем сильно в разной.
Некоторые вообще никогда не меняются, будучи написанными. Некоторые имеют сложную логику, а некоторые — рутинные и тривиальные. И подходить к их тестированию нужно соответственно- прилагая голову. И я этот пост понимаю именно так.
soniq
14.05.2017 21:28Вот вы пишете, что продукт меняется. Значит, какие-то фичи добавляются и для них нужен новый код, и новые тесты. Или какие-то фичи теряют актуальность — и код для них можно выбросить, вместе с тестами. Ещё бывает так, что для какой-то фичи написан плохой код, и надо бы его переписать, тут-то нам тесты и могли бы помочь. Если бы были написаны хорошо, но наивно рассчитывать, что разработчик написал плохой код, но хорошие тесты для него. Напрашивается вывод, что не очень-то и нужны такие тесты.
youlose
14.05.2017 22:12+1«Значит, какие-то фичи добавляются и для них нужен новый код, и новые тесты»
В этом случае тесты и блистают, потому что когда добавляется функционал количеством разработчиков больше одного, крайне велика вероятность что что-то сломается в неожиданном месте.
«Или какие-то фичи теряют актуальность — и код для них можно выбросить, вместе с тестами. „
Это некоторый необходимый оверхед от тестов
“Ещё бывает так, что для какой-то фичи написан плохой код, и надо бы его переписать, тут-то нам тесты и могли бы помочь.»
Да для рефакторинга очень подходит, я участвовал во многих проектах где был плохо написанный фунционал и его боялись править, с тестами такого бы не было.
«Если бы были написаны хорошо, но наивно рассчитывать, что разработчик написал плохой код, но хорошие тесты для него. Напрашивается вывод, что не очень-то и нужны такие тесты.»
Эта мысль не очень ясна,
тесты нужны не для того чтобы писать хороший код (есть побочный эффект тестирования, выраженный в том, что в коде появляются хорошие и расширяемые интерфейсы взаимодействия между различными частями программы, но это не значит что код будет красиво и эффективно написан). И если тесты есть, они уже полезны. А умение писать хорошие тесты приходит после нескольких переделываний кучи плохих тестов (на моей практике это тесты со сложной логикой и неправильное взаимодействие между частями функционала(много лишней инициализации)) после изменения функционала в одном и том же месте.
Случаи где я считаю что не нужно писать тесты — это там где нет требования к высокому качеству кода (прототипы, говносайты, обучение) и/или разработчик только один или несколько полностью изолированных. В остальных случаях тесты пригодятся и уменьшат многодневные разборы багов практически до нуля.
100% покрытие тестами я не пробовал, тестирую только сложные/вычислительные части кода или там где возникает много багов.soniq
15.05.2017 03:22А умение писать хорошие тесты приходит после нескольких переделываний кучи плохих тестов
Умение писать хороший код приходит после того как достаточно поработаешь с плохим кодом. К некоторым разработчикам это умение приходит, а некоторые так и остаются говнокодерами. От плохого кода тесты не защищают, хороший код и так хороший. На кой вообще сдались эти юниты?youlose
15.05.2017 05:05+2Ещё раз, тесты нужны чтобы гарантировать, что весь функционал внедрённый ранее работает по-старому это не связано с хорошим или плохим кодом.
Плюс к этому не надо верить в миф о том что «есть люди которые всегда пишут хороший код». Программист может не выспаться, напиться/накуриться, его может бросить жена и.т.д., то есть он может находиться в изменённом/нестабильном состоянии сознания абсолютно в любой момент времени. И в такие моменты он вряд ли будет писать хороший код, а учитывая оптимизм разработчиков, даже осознавая проблему изменённого сознания они скорее всего продолжат работу.
Также есть такой момент, что программисты одинаковых категорий («сеньоры», например) могут придерживаться разных взглядов на парадигмы программирования, в разной степени глубины знать инструменты и их особенности (кто-то программируя на JS знает что {} + [] == 0, а кто-то нет и для написания хорошего поддерживаемого кода это знать необязательно) и.т.п. И когда один из них написал кусок кода, а другой туда вносит изменения, то с отсутствием тестов ему придётся анализировать большое количество кода написанного ранее и нет никакого гарантированного способа (кроме тестов, пока что) что внеся изменения он не сломает предыдущий функционал. По сути своим опытом и временем потраченным на внесение изменений он только уменьшить шансы на поломку.
Могу привести пример из своей практики: я исправлял баг в продукте с большой кодовой базой и выяснилось (из git) что этот кусок кода исправлялся несколькими разными программистами раз 6 за год, причём большая часть изменений — одни удаляли строчки, другие добавляли почти те же самые. То есть был изначальный баг, где завуалированно изменялся массив по которому проводилась итерирование (который допустил тим-лид этого проекта, кстати, и это реально высокой квалификации программист). Так вот первые люди приходили исправлять этот баг, вносили одни изменения и тот баг с которым они пришли исправлялся, но открывался другой баг который приходили другие люди и вносили изменения которые возвращали тот баг что чинили предыдущие. Так вот если бы на каждый баг они добавляли тесты, то после первого исправления, вторые бы исправив на старый лад прогнав тесты увидели бы что тот баг открывается и им бы пришлось его исправить раз и навсегда. То есть тестирование — это ещё и своего рода совместная база знаний о багах получается.
И ещё один случай опишу:
я писал через TDD универсальный автономный парсер RSS лент. Написал всё работает, все довольны. Через некоторое время выясняется что в некоторых случаях определяется неправильная кодировка и в базу пишутся кракозябры. После 5 минутного анализа выясняется что я брал данные о кодировке из заголовков HTTP (так было быстрее и удобнее), а на 30% RSS веб сервер отдавал одну кодировку, а по факту была другая, а она ещё внутри прописана (а может быть и не прописана, там всё паршиво с однообразием по-факту =) ). Ну и я радостный написал пару строк кода и исправил проблему, запустил тесты и часть тестов сломалось, тоже мелкая и понятная проблема, новая правка, часть других тестов сломалось и.т.д. Надёжно исправить я смог только с 6го раза + я написал несколько новых тест кейсов для ситуаций где кодировки заголовков и контента не совпадают.
youlose
15.05.2017 05:21А про плохие тесты:
они влияют на то что при простых изменениях в коде приходиться править много тестов. То есть увеличивает (иногда существенно) время внесения исправлений, потому тестирование и не «взлетает» в большинстве команд.
MaksSlesarenko
16.05.2017 13:18Вы исходите из ошибочного предположения что продукт написан и не изменяется. Если продукт развивается, то в нём появляются изменения которые как раз и могут ломать всё что угодно и тесты предназначены именно для этого, чтобы дать гарантию того что после внесения изменений весь предыдущий функционал продолжает работать как надо.
Не все тесты предназначены для этого, к примеру функциональные тесты — да, а юнит тесты — нет, т.к. юнит тест ничего не знает ни о функионале, ни о продукте.
ApeCoder
13.05.2017 19:48+3А нафига, если потребитель доволен?
На этом уровне нельзя сказать нафига. Потому, что вы постулируете, что потребитель доволен. А надо понять, доволен ли потребитель больше с тестами или без тестов. Это то же самое, что говорить, "Какая разница из чего сделана автомашина — из металла или бумаги, если она прочная" — в том то и дело, что из бумаги она или непрочная или толстая.
Правильные тесты дают некоторую уверенность, что можно делать рефакторинг и ничего не сломать, также проверяют дизайн на то, что он состоит из независимых частей, в результате эти части проще понимать и модифицировать по отдельности.
100% покрытие вряд ли практично (интересно было бы посмотреть на достаточно большой практичный пример).
sshikov
13.05.2017 19:59-1Ничего я не постулирую. Я лиш описываю один из вариантов — заказной софт, под конкретного заказчика, который сидит в этой же компании. Разработчик вполне может (и знает реально), доволен ли потребитель.
100% покрытие вряд ли практично
Так а я о чем? Я в основном именно про то, что это непрактично в первую очередь. Даже если вы точно собираетесь рефакторить, и вам нужны тесты как показатель того, что вы не сломали — редко кто рефакторит весь код целиком.
ApeCoder
14.05.2017 13:06редко кто рефакторит весь код целиком
Часто рефакторинг делается просто как часть начальной разработки — просто в процессе. Разработка фичи как серия рефакторингов в добавлением функциональности. И тут тесты могут помочь уже в процессе начальной разработки фичи.

unabl4
12.05.2017 15:04+9Я не из мира джавы (явы), но уже давно пришел к личному выводу, что имеет смысл писать больше высокоуровневых тестов, а юнит-тесты писать только когда логика там совсем заковыристая и нужен пруф, что она работает или в случае, когда ручное тестирование занимает больше времени, чем написание тестов. Экономит приличное кол-во времени, позволяя сосредоточиться на чем-то более важном, чем мифическое 100% покрытие, которое само по себе ничего не дает — все равно когда-нибудь рухнет в том месте, где вообще не ожидаешь и тогда, когда вообще не ожидаешь. Но это имхо, конечно.
gro
12.05.2017 15:54А что будет, когда жахнет едрёна бомба? Помогут ли юнит-тесты?
Дали доступ к коду разгильдяю-саботажнику, который удаляет тесты, потому что они не работают и виноваты тесты?
Это из серии, что инкапсуляция призвана защищать от злоумышленников.
Barafu
12.05.2017 16:14+7Помешались все на этих unit-тестах. Половина unit-тестов заменяется assert-ом в нужном месте.

bogolt
12.05.2017 21:51+4Ассерт неудобен тем, что выстреливает только в момент выполнения участка кода.
MaksSlesarenko
16.05.2017 13:22Помешались все на этих unit-тестах. Половина unit-тестов заменяется assert-ом в нужном месте.
А вторая половина зменяется code-style валидаторами
Kroid
12.05.2017 17:26+1«Послушай, пусть даже этот воображаемый недотёпа или злодей действительно придёт и всё испортит — как ты думаешь, что он сделает, когда соответствующий юнит-тест провалится? Удалит, и все дела».
Нельзя так просто взять и удалить неработающий тест, если код остался.
Этот воображаемый злодей может с тем же успехом переписать существующую миграцию, а потом ресетнуть бд на проде, чтобы получилось её накатить заново.

iKBAHT
12.05.2017 17:31+4100% покрытие кода тестами не гарантирует правильное поведение кода. Покрытие конкретной строки кода говорит лишь о том, что строка была исполнена, но ничего не говорит о правильности исполнения.
Правильное поведение кода гарантирует мутационное тестирование.AstarothAst
12.05.2017 19:03+5100% покрытие кода тестами, вообще говоря, гарантирует, что вы ничего не сломаете что-то исправляя или дополняя. А правильное поведение гарантируют функциональные тесты.
PS мутационное тестирование мало того, что на практике малоприменимо из-за большого количества ложных срабатываний, так еще и не для того. Мутационное тестирование призвано проверить, что ваши тесты действительно что-то да тестируют.sshikov
12.05.2017 21:30+1Тесты вообще ничего не гарантируют на 100%. Простой пример — в той же Java и других языках с исключениями, когда одна строка кода выполнена, то дальше управление перейдет либо к следующей строке (не учитываем пока if и пр.), либо неизвестно куда, потому что в теории при выполнении может быть выброшено произвольное (хотя и конечное) число разных исключений.
Полное покрытие — это значит, что вы вообще говоря, все эти случаи протестировали. Т.е. не просто каждая строка кода была выполнена, но и все пути переходов тоже.
Мало того, что этого почти никогда не делают, но еще и по причине раздельной компиляции вы как правило не можете знать, какие именно вещи происходят в коде, который вы в конкретной строке вызываете. То есть статический анализ кода вам не покажет, все ли пути вы протестировали. В динамических языках все еще хуже.
oxidmod
12.05.2017 22:21Вот именно так и тестирую. Хеппи пас и все ошибки
sshikov
12.05.2017 23:33+1Мой ответ: «…»
Вот и не жалко же людям свое время тратить на ерунду? Лучше бы функциональность новую разрабатывали.
P.S. Я все равно не верю, что все ошибки. Потому что статический анализ неполноценный в большинстве языков, а то что вы думаете на эту тему, может быть очень далеко от того, что есть на самом деле.
oxidmod
13.05.2017 01:00Вы не в состоянии определить все ли throw протестировали? Сколько их у вас на один метод приходится?
sshikov
13.05.2017 09:44А вы в состоянии определить, сколько разных RuntimeException может выкинуть конкретная строка кода? А если там вызов чужой библиотеки? И даже если можете — вы будете их все тестировать? И зачем? А если нет — то о каком 100% покрытии вы говорите, в каком смысле?
Кроме того, это был лишь один пример. Тоже самое, только в еще более ярком виде, касается многопоточного асинхронного кода. Для него вообще не существует адекватных средств тестирования, а варианты поведения и последовательности событий начинают зависеть просто от времени.
oxidmod
13.05.2017 10:20Я понял в чем проблема. Да, shit happens. Если софт не рассчитан на постоянную работу в условиях нехватки памяти, то вполне законно может упасть при out of memory. Но свой код, свою логику вы можете покрыть на 100%. И автор сторонней либы покроет свой код на 100%. И в итоге все будет хорошо.
А вот если ваш софт как-то выкручивается в условиях нехватки памяти, то эту логику вы тоже протестируете
youlose
12.05.2017 17:31А откуда берётся wishlists в первом примере, это глобальная переменная?
P.S. Не умею на джаве писать, в принципе код понятный, но откуда взялась эта магия непонятно.oxidmod
12.05.2017 18:07с шарпо-джавах вроде не обязательно писать this. это просто обращение к свойству текущего объекта. Хотя когда еще лабы пилил на шарпе указывал this всегда… так код както понятней выглядит для меня))
santa324
12.05.2017 17:38+5Всегда ненавидел эти бессмысленные требования писать тесты для всего.
Нормальный программист может адекватно оценить когда тест писать выгодно(затраты на написание теста меньше чем экономия потом на поиске ошибок) а когда нет. Это часть архитектуры и программист сам должен решать где они нужны а где нет, а не следовать слепым правилам.oxidmod
12.05.2017 18:16+8Вы все правильно говорите, но часто бывает вот так:
1. Тривиальный метод, зачем тут тест???
2. Ну добавилась еще строчка, все еще тривиальный метод, пофиг на тест.
…
k. Новый человек добавил условие/строку/етс, пошел искать тест который нужно поправить, а теста нет. Ну нет так нет…
…
n. Имеем трудночитаемое и непокрытое тестами нечто.
Лично для меня, ценность тестов еще и в том, что плохо написаный код трудно тестировать. Приходится мокать целые цепочки зависимостей и формировать простыни из проверок. Если я ловлю себя на том, что тест стал не очень, значит пришла пора чтото делать с тех долгом.santa324
12.05.2017 19:02+1Тут проблема не в отсутствии теста а в безразличном отношении тех кто туда дописывает. Не думаю что обязаловка тестов тут чем-то поможет. Допишут код, тест как-нибудь залечат и ладно.
Я стараюсь писать тесты когда они простые, покрывают много потенциальных ошибок, не сломаются при ожидаемых доработках кода который тестируют и т.п. Но такие тесты придумать совсем не просто, и далеко не везде возможно.
А тестировать плоский тривиальный код, который с 99.999999% вероятностью не содержит ошибок, а если и содержит то они тут же выстрелят и элементарно будут найдены и исправлены — это пустая трата времени
funca
12.05.2017 22:37На стадии эксплуатации это «элементарно» может стоить несколько недель. Ведь в таком случае баг еще надо найти, описать, засабмитать, приоритезировать, разобраться, починить, проревьювать, протестить, задеплоить, зарелизить, обновить.
Xandrmoro
12.05.2017 19:22-1Где-то в промежутке этот код перестанет проходить ревью и его распилят на тривиальные методы, которым снова не нужны тесты.
В целом, если в рамках одного метода появляется достаточно сложная логика для того, чтобы имело смысл её тестировать — это сигнал не к написанию ещё двух десяток строк бесполезного кода, а к тому, что этот метод пора рефакторить. Да, бывают случаи, когда отрефакторить действительно нельзя, но это исчезающие доли процента от общего количества кода.
vics001
12.05.2017 19:38-1Написать качественный тест, гораздо сложнее, чем написать качественный код. А написать качественный код уже сложно.
Да, конечно, существуют абстракции, которые идеальны изолированы для тестирования, коллекции, алгоритмы… Но если это логическая конструкция, по типу UIListAdapter, который существует, чтобы отображать ui строчки и все, что делает это делегирует коллекцию? То зачем это? Или CollectionOfFavorites, которое на 90% состоит из прямых вызовов Collection, что мы тестируем, ArrayList?
JPEG
13.05.2017 20:09Мне в JS помог переход на функциональное программирование внутри модулей. То есть снаружи всё выглядит как компонент, но внутри только функции (без
this, но не чистые, конечно). Слава redux'у за популяризацию, теперь хотя бы у виска не крутят, когда про такое говорю :)

andreycha
15.05.2017 11:03Ну нет так нет…
Плохой программист. Хороший не поленится добавить хотя бы тест, которые проверяет то, что он изменил. А при наличии времени — покрыть сразу весь метод.
ArsenAbakarov
12.05.2017 21:52+3А я вот все смотрю на куски кода после «Тех, кто работал с Cucumber, не удивит объём вспомогательного кода, которого он требует», точнее на имена классов и мои глаза уже больше чем 5 рублевая монета…
DtoAdditionalDataModelMapperRegistryStepDefs…

jakobz
12.05.2017 22:08-4А мне кажется, что в приведенных примерах не только тестов не надо, но и код, ими тестируемый — явно признак запущенной стадии ООП головного мозга.

velvetcat
12.05.2017 23:57-3Статья — полный бред.
Автор начал про TDD, а рассказывает про "написал херовый код, как мне его теперь протестировать" и предлагает в качестве фикса тестирование реализации одного конкретного метода, а не целого поведения, ради которого создавался этот класс, что добавляет хрупкости и не приносит никакой пользы.
Кстати, про хрупкость таких тестов не сказано ни слова, а это гораздо большая проблема, чем то, о чем с претензией на тотальный срыв покровов говорится в статье.
Человек за 15 лет практики не понял, что TDD — это способ избежать появления такого кода и таких тестов.
я свято придерживался принципов TDD
Ну понятно, такой же ***, как и те, кого он приводит в качестве примера. Фу.
P.S. Выше в комментах уже приводили эти доводы, но мне хотелось дополнить их выводом, выделенным курсивом. И простите за жесткость. Заколебало.

vladislav_starkov
13.05.2017 02:27Жесть. А ведь тестировать нужно только public-интерфейсы для связи с внешним миром. Все остальное остается в black-box и, в случае неисправности, проявит себя при тестировании public-интерфейсов.
funca
13.05.2017 11:38Взять например популярный патерн «Command», с единственным «execute()» в интерфейсе, и кучей indirect inputs/outputs внутри, на которых код может валиться.

YemSalat
13.05.2017 07:42+3Чето я не понял… Автор вроде пишет про TDD, а в примере его спрашивают про то как написать тест для уже существующего реализованного функционала.
TDD же про:
разработка через тестирование, или, как её раньше называли, подход test-first
Получается что проблема не в методологии, а в том что автор ей не следует.funca
13.05.2017 11:41-2Люди часто говорят «TDD», подразумевая использование юнит тестов, а не конкретную методологию.
ElectroGuard
13.05.2017 10:02+2Есть хорошая русская пословица — заставь дурака молиться он и лоб расшибёт. Умеренность хороша во всём. Особенно в программировании.

kontiky
15.05.2017 06:19Из статьи я так и не понял, когда же не нужно писать тесты, а когда — необходимо. Одна вкусовщина: «Этот код слишком простой. Зачем его тестировать?» Объективные-то критерии существуют?
Xandrmoro
15.05.2017 21:24Метод не нужно тестировать, если он выполняет одну задачу и не имеет сайдэффектов (или если проксирует покрытый тестами сложный метод).
Ivan22
16.05.2017 09:08Внезапно — Универсального ответа не существует! А истина — в поисках идеального баланса между нулевым и 100% покрытием. Который конечно же на каждом проекте и в каждом случае свой. И вообще — это работа тест лида.
p.s. То же самое происходит с излишней оптимизацией и рефакторингом да и много с чем еще.

y90a19
16.05.2017 11:41+2У меня это критерий когда я боюсь этого кода и хочу руками проверить что он работает.
Регулярные выражения — тест нужен. Преобразования данных — тест нужен. Поиск по каким-то данным — тест нужен.
Присваивание переменной — тест не нужен. Условный оператор — тест не нужен.
ElectroGuard
15.05.2017 22:48+1Очень везет, когда баги статические. Когда же приложение с кучей потоков, всё динамическое, куча событий, гигабайты логов — вот это настоящий вызов. Попробуй тут тест напиши.
y90a19
16.05.2017 11:36Юнит-тесты знают о деталях реализации, тем самым нарушая инкапсуляцию и являясь антипаттерном.
Для чего он предназначен? Для фиксирования логики работы. Но логика работы проверяется при дебаге, и никто не будет менять эту логику без веских причин или случайно.
Если же код правится, то эти тесты падают, и их тоже приходится править. И опять они бесполезны.
Да и что они тестируют? Что мои глаза меня не обманывают? Что компилятор не сломался?
Юнит-тесты полезны только для функций преобразования данных, когда код не очевиден (в этом юнит-тесте должны быть только наборы входных и выходных данных, оно не должно знать о реализации этого преобразования). И видимо для этого юнит-тесты изначально и предназначались.
А основную работу должно выполнять интеграционное тестирование, на выходе и в стыках интеграции между другими модулями. И оно тоже не должно знать о деталях реализации.
Плюс не надо забывать что юнит-тесты это тоже код, который надо поддерживать. При 100% тестировании количество кода увеличивается раза в 4. Соответственно увеличивается время изменений и цена продукта.
Опять же при 100% покрытии крупный рефакторинг практически невозможен. — нужно будет выкинуть все эти тестыpoxvuibr
16.05.2017 11:45+1Для чего он предназначен? Для фиксирования логики работы. Но логика работы проверяется при дебаге, и никто не будет менять эту логику без веских причин или случайно
В первую очередь TDD предназначено для того, чтобы разрабатывать. Логика работы в таком случае проверяется не дебагом, а запуском тестов, в которых эту логику придётся описать в явном виде.
Да и что они тестируют? Что мои глаза меня не обманывают? Что компилятор не сломался?
Что код соответствует ожиданиям программиста. Обновили библиотеку и хотите понять, что это не сломало ваш код? Запустите юнит тесты.
Опять же при 100% покрытии крупный рефакторинг практически невозможен.
Вот без тестов он действительно невозможен. Рефакторинг это такая штука, которая не меняет логику. Узнать, что логика не изменилась можно только запустив юнит тесты. Если их нет — нельзя понять ломает рефакторинг что-то, или нет.
y90a19
16.05.2017 11:56+1Логика работы в таком случае проверяется не дебагом, а запуском тестов, в которых эту логику придётся описать в явном виде
Неужели прямо в ТЗ описана вся реализация вплоть до присвоений переменных?
Нет, там описаны наборы входных и выходных данных. Именно это и надо тестировать — что мы подали на вход и что получили на выходе. Но не реализацию
Обновили библиотеку и хотите понять, что это не сломало ваш код?
решается любым интеграционным smoke тестом. Тем более что все ломается обычно на стыках слоев и инициализации и конфигурации фреймворков, что юнит-тест не способен протестировать.
Рефакторинг это такая штука, которая не меняет логику.
Именно что меняет логику и реализацию, но при этом входные и выходные данные не должны измениться.
При 100% покрытии любое изменение кода вызывает падение юнит-тестов, тем самым делая их бесполезнымиpoxvuibr
16.05.2017 12:08+2Неужели прямо в ТЗ описана вся реализация вплоть до присвоений переменных?
Нет, есть огромная куча кода, которая в ТЗ не описана вообще. И для неё естественно надо писать юнит тесты. Чтобы понимать, что она работает так, как ожидается.
Нет, там описаны наборы входных и выходных данных.
В ТЗ описано чего хочет заказчик. Иногда это наборы данных, иногда это вокрфлоу, иногда что-то ещё.
решается любым интеграционным smoke тестом.
Он не покажет что конкретно сломалось.
Тем более что все ломается обычно на стыках слоев и инициализации и конфигурации фреймворков, что юнит-тест не способен протестировать.
Бывает по разному. В моей практике много раз бывало, что ломался код, который опирался на сторонние библиотеки. Юнит тесты сразу показывали где.
Именно что меняет логику и реализацию
Рефакторинг логику не изменяет по определению. Если вы под рефакторингом имеете в виду любую доработку вообще, то это определение не канонично.
y90a19
16.05.2017 13:19Чтобы понимать, что она работает так, как ожидается.
проверять что компилятор не сломался? Сам код уже не является этим описанием? А вы тесты на тесты не пробовали писать? В тестах тоже есть логика, которую надо тестировать
Он не покажет что конкретно сломалось.
юнит-тест, тем более на моках отсекает все сторонние библиотеки. Он предназначен для тестирования только абстрактной логики в вакууме у нашего проекта
Если вы под рефакторингом имеете в виду любую доработку вообще, то это определение не канонично.
где проходит граница между рефакторингом и доработкой? Для меня это изменяются ли выходные данные. Например перевод процедурного кода на ООП — внутренняя логика меняется, выходные данные не должны. Это рефакторингpoxvuibr
16.05.2017 14:23проверять что компилятор не сломался? Сам код уже не является этим описанием? А вы тесты на тесты не пробовали писать? В тестах тоже есть логика, которую надо тестировать
Нет, проверять, что ожидания соответствуют реальности. Ожидания описаны в юнит-тесте, реальность в коде. Кроме того, юнит-тест пишется раньше кода. Это облегчает и ускоряет разработку и это немаловажно.
юнит-тест, тем более на моках отсекает все сторонние библиотеки.
Если цель — тестировать что эта библиотека не сломана, то не отсекает.
где проходит граница между рефакторингом и доработкой?
Это всегда непросто сказать. Вот например переписывание программы на другом языке — точно не рефакторинг, хотя для пользователя ничего не меняется.
Например перевод процедурного кода на ООП — внутренняя логика меняется, выходные данные не должны.
Придётся выбросить большинство существующих юнит тестов и написать новые. Масштаб рефакторинга очень большой. Фактически это могло бы быть переписывание кода с C на C++. Или, с тем же успехом на Java :)
ApeCoder
16.05.2017 13:31+2Юнит-тесты знают о деталях реализации, тем самым нарушая инкапсуляцию и являясь антипаттерном.
Юнит тесты знают только об итерфейсе юнита.
Для чего он предназначен? Для фиксирования логики работы. Но логика работы проверяется при дебаге, и никто не будет менять эту логику без веских причин или случайно.
При изменении надо следить чтобы другие требования не нарушались.
Если же код правится, то эти тесты падают, и их тоже приходится править.
При правильно написанных тестах надо править только тесты, которые тестируют изменяемое требование.
А основную работу должно выполнять интеграционное тестирование, на выходе и в стыках интеграции между другими модулями. И оно тоже не должно знать о деталях реализации.
https://testing.googleblog.com/2015/04/just-say-no-to-more-end-to-end-tests.html
Опять же при 100% покрытии крупный рефакторинг практически невозможен. — нужно будет выкинуть все эти тесты
Отрефакторить. Требования никуда не деваются — меняется только форма их представления
y90a19
16.05.2017 13:47Юнит тесты знают только об итерфейсе юнита.
у адептов принято тестировать и private методы
При изменении надо следить чтобы другие требования не нарушались.
согласен
При правильно написанных тестах надо править только тесты, которые тестируют изменяемое требование.
Проблема в том, что для достижения этих «100% покрытия» пишется очень много тестов. И их невозможно написать без дублирования требований. В итоге малейшее изменение выливается в многочасовую правку тестовApeCoder
16.05.2017 14:18Кто такие адепты? Вот например известная книжка http://xunitpatterns.com/Principles%20of%20Test%20Automation.html читать с use the front door first. Вы не путаете покрытие приватных методов с тестированием реализации?
И их невозможно написать без дублирования требований.
Тесты должны рефакториться так же как и код.
funca
17.05.2017 01:18Кстати, если возникает желание протестировать приватный метод, стоит еще раз критически взглянуть на архитектуру.
Возможно кто-то в спешке нагородил процедурщину. А еще может быть, что класс пытается брать на себя больше одной ответственности (поэтому дополнительную фунциональность, которая не является ответственностью класса, завернули в приватный метод). В этом случае стоит попытаться вынести функциональность приватного метода в отдельный класс, где она будет основной, а следовательно публичной, и тестировать по обычной методике.
kaljan
как минимум, коммит, в котором будет безосновательно удален тест — не пройдет код ревью и ему придется починить тест
JPEG
Почему же безосновательно? Чувак потрёт и тестируемый код тоже. С точки зрения код-ревью всё чисто и тесты зелёные. А остальное — (какбэ) вкусовщина.
Имхо, про эту "вкусовщину" и речь в статье. Много встречал тестов тестирующих не полезный функционал, а просто верифицирующих детали реализации. Самый жесткий пример, это тестить if передавая true или false и проверяя, смогёт ли он правильно разветвить программу.
Shifty_Fox
Если тестируемый код стерт, и юнит тест стерт — все хорошо. Код покрыт на 100%.
Если помимо этого «Чувак» напишет новый код — ему придется написать и новый юнит тест — иначе коммит не пройдет, т.к. код покрыт не на 100%.
Покрывать тестами каждую строчку может быть нудно, но чисто в рамках заданной ситуации — покрытый на 100% код действительно что-то мне гарантирует, как минимум выполнение спецификации моих тестов в каждой строчке кода.
mayorovp
Это работает только когда тесты реально отражают спецификацию, а не реализацию.
Chamie
Тут уже становится непонятно, как мерить процент покрытия, раз тесты покрывают не код реализации, а спецификацию.