
Любой, кто работает в сфере e-commerce, рано или поздно сталкивается с необходимостью быть первым среди конкурентов. Одним из наиболее эффективных инструментов в данном вопросе является управление ценой. Результаты маркетинговых исследований показывают, что среди тех потребителей, которые готовы сменить поставщика промышленного оборудования и инструментов, треть называет низкую цену как решающий фактор выбора нового поставщика. На просторах интернета существует куча разных сервисов, но по тем или иным причинам они не подходили.
Способы получения информации о ценах конкурентов
Инструменты
Исторически сложилось, что интернет-магазин – на 1C-Bitrix, поэтому мониторинг цен был написан на php. Но это неправильный подход, поэтому ниже будет описан алгоритм парсинга на Node.js.
Для примера возьмем товар iphone в разных магазинах и будем производить мониторинг его цены.
Создадим таблицу конкурентов:
Далее нам потребуется URL для товаров и список элементов в HTML-документе. Создаем таблицу списков элементов:
Создаем таблицу, в которой будут храниться url, цены и т.д.:
Пример заполнения таблицы competitors:

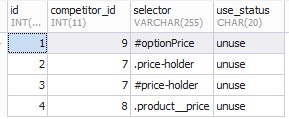
Пример заполнения таблицы competitors_selector:
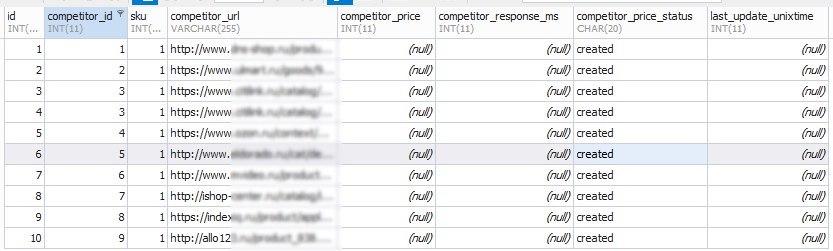
Пример заполнения таблицы competitors_data:
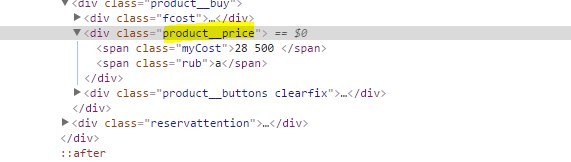
Данные из competitors_selector заполняются на основе селекторов:

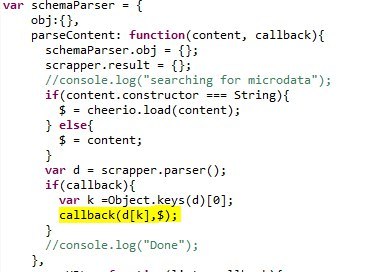
На данный момент каждый уважающий себя интернет-магазин использует microdata. Существует огромное количество парсеров, на разнообразных языках программирования. Так как мы определились, что пишем на Node.js, то воспользуемся прекрасным модулем semantic-schema-parser. Сам модуль умещается в 149 строк и под капотом у него отличный парсер контента cheerio. Немного доработаем модуль, добавив в callback объект $.
Но не стоит забывать о том, что многие интернет-магазины все еще не используют microdata. Тут вступают в дело данные competitors_selector. В опциях запроса поставим максимум 5 редиректов, user-agent как yandex bot, и timeout 2 сек.
Для загрузки html используем библиотеку needle. Для упрощения формирования запросов к БД воспользуемся шаблонизатором templayed.
Запросы к БД:
Алгоритм парсинга следующий:
Код класса Scraping представлен ниже. В коде используется велосипед для того, чтобы одновременно асинхронно анализировать url. Изначально задумка была:
Но пока что реализация следующая:
В результате получаем следующие данные:
На изображении видно, что можно отследить самую дорогую и самую дешевую цену конкурента, время ответа сервера. Теперь можно отправлять это в ценообразование, для пересмотра ценовой политики.
Подводя итог, хочется сказать, что с применением microdata парсинг названия товаров, цены и категории существенно упрощается. Но есть еще большая ложка дегтя:
Те же магазины, которые не используют microdata, в качестве селекторов используют не id, а class, что правильно с точки зрения верстки, но усложняет парсинг (к примеру, в документе у нас могут быть 7 элементов с class='price', а цены будут находиться только в 4, 5, 6, 10). Также не всегда в элементе существует цена в удобном формате:
На данный момент, с появлением microdata, парсинг стал намного проще.
В следующей статье попробую показать, как реализован алгоритм автоматического сопоставления url-карточки конкурента и карточки в интернет-магазине.
Способы получения информации о ценах конкурентов
- Самый простой и эффективный способ мониторинга цен на данный момент — pricelab. Но в нем можно проверить только те товары, которые уже участвуют в Яндекс.Маркете. То есть, ваш основной конкурент должен быть в Яндекс.Маркете, интересующий вас товар также должен быть выгружен, и вы сами должны выгрузить свой товар.
Какие же минусы это за собой влечет? Учитывая то, что в Яндекс.Маркете цена клика соразмерна цене SKU, то многие не будут размещать в нем специализированные товары с большой ценой, да и самим размещать такой товар нерентабельно.
У нас реализован небольшой скрипт для мониторинга цен с pricelab, но некоторые ключевые позиции не выгружаются в pricelab. - Договориться с работником конкурента. Это не совсем правильный и честный способ. Поэтому сразу отклоняется.
- Парсинг сайта конкурента. Это популярный метод и он достается практически даром. Ниже будет описан именно он.
Инструменты
- База данных.
- Алгоритм парсинга.
Исторически сложилось, что интернет-магазин – на 1C-Bitrix, поэтому мониторинг цен был написан на php. Но это неправильный подход, поэтому ниже будет описан алгоритм парсинга на Node.js.
Для примера возьмем товар iphone в разных магазинах и будем производить мониторинг его цены.
Создадим таблицу конкурентов:
competitors
CREATE TABLE panda.competitors (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
)
ENGINE = INNODB
CHARACTER SET utf8
COLLATE utf8_general_ci;
Далее нам потребуется URL для товаров и список элементов в HTML-документе. Создаем таблицу списков элементов:
competitors_selector
CREATE TABLE panda.competitors_selector (
id int(11) NOT NULL AUTO_INCREMENT,
competitor_id int(11) DEFAULT NULL,
selector varchar(255) DEFAULT NULL,
use_status CHAR(20) DEFAULT 'unused',
PRIMARY KEY (id)
)
ENGINE = INNODB
CHARACTER SET utf8
COLLATE utf8_general_ci;
Создаем таблицу, в которой будут храниться url, цены и т.д.:
competitors_data
CREATE TABLE panda.competitors_data (
id INT(11) NOT NULL AUTO_INCREMENT,
competitor_id INT(11) DEFAULT NULL,
sku INT(11) DEFAULT NULL,
competitor_url VARCHAR(255) DEFAULT NULL,
competitor_price INT(11) DEFAULT NULL,
competitor_response_ms INT(11) DEFAULT NULL,
competitor_price_status CHAR(20) DEFAULT 'created',
last_update_unixtime INT(11) DEFAULT NULL,
PRIMARY KEY (id)
)
ENGINE = INNODB
CHARACTER SET utf8
COLLATE utf8_general_ci;
Пример заполнения таблицы competitors:
Пример заполнения таблицы competitors_selector:
Пример заполнения таблицы competitors_data:
Данные из competitors_selector заполняются на основе селекторов:
На данный момент каждый уважающий себя интернет-магазин использует microdata. Существует огромное количество парсеров, на разнообразных языках программирования. Так как мы определились, что пишем на Node.js, то воспользуемся прекрасным модулем semantic-schema-parser. Сам модуль умещается в 149 строк и под капотом у него отличный парсер контента cheerio. Немного доработаем модуль, добавив в callback объект $.
Но не стоит забывать о том, что многие интернет-магазины все еще не используют microdata. Тут вступают в дело данные competitors_selector. В опциях запроса поставим максимум 5 редиректов, user-agent как yandex bot, и timeout 2 сек.
Для загрузки html используем библиотеку needle. Для упрощения формирования запросов к БД воспользуемся шаблонизатором templayed.
Запросы к БД:
resetSelectorsStatus.sql
UPDATE
competitors_selector
SET
use_status = 'unuse'
WHERE 1;
selectcSelectors.sql
SELECT *
FROM competitors_selector
selectcURLs.sql
SELECT * FROM competitors_data
updateCompetitorData.sql
UPDATE
competitors_data
SET
competitor_price = '{{price}}'
,competitor_response_ms = {{response_ms}}
,last_update_unixtime = {{response_time}}
,competitor_price_status = '{{status}}'
WHERE id = {{id}}
Алгоритм парсинга следующий:
- Сбрасываем selector.
- Формируем объект из DOM-селекторов.
{ключ:['selector1','selector2']}
- Загружаем HTML.
- Анализируем microdata.
- Если в microdata нет необходимых данных, то анализируем selector'ы.
- Если данные не определены, то выставляем null.
Код класса Scraping представлен ниже. В коде используется велосипед для того, чтобы одновременно асинхронно анализировать url. Изначально задумка была:
- Агрегировать конкурентов из competitors_data.
- Выставить количество одновременных асинхронных запросов.
- Каждого конкурента опрашиваем через timeout.
Но пока что реализация следующая:
Полный код
var needle = require('needle');
var mysql = require('mysql');
var templayed = require('templayed');
var fs = require('fs');
var schema = require("semantic-schema-parser");
var Scraping = new function(){
//1. Подключаемся к БД
_this = this;
_this.DB = mysql.createConnection({
host : 'localhost',
user : '******************',
password : '******************',
database : 'panda'
});
_this.querys = {};
_this.selectors = {};//dom селекторы для Scraping'a
_this.rows = null;//Массив из url
_this.workers = 5;//Количество одновременных асинхронных опросов
_this.needleOptions = {
follow_max : 5 // Максимум 5 редиректов
,headers:{'User-Agent': 'Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) '}
,open_timeout: 2000 // if we don't get our response headers in 5 seconds, boom.
}
this.run = function(){
_this.DB.connect();
_this.queryLoad();
_this.resetSelectorsStatus();
}
//--------------------// //Загружаем шаблоны запросов {операция блокирующая(синхронная)}
this.queryLoad = function(){
_this.querys['selectcSelectors'] = fs.readFileSync('sql/selectcSelectors.sql', 'utf8');
_this.querys['resetSelectorsStatus'] = fs.readFileSync('sql/resetSelectorsStatus.sql', 'utf8');
_this.querys['selectcURLs'] = fs.readFileSync('sql/selectcURLs.sql', 'utf8');
_this.querys['updateCompetitorData'] = fs.readFileSync('sql/updateCompetitorData.sql', 'utf8');
};
//--------------------// //Сбрасываем статус селекторов
this.resetSelectorsStatus = function(callback){
_this.DB.query( _this.querys['resetSelectorsStatus'], function(err, rows) {
_this.selectcSelectors();
});
}
//--------------------// //----Массив DOM електоров
this.selectcSelectors = function(callback){
_this.DB.query( _this.querys['selectcSelectors'] , function(err, rows) {
if (!err){
rows.forEach(function(item, i, arr) {
if (!_this.selectors[item.competitor_id]){_this.selectors[item.competitor_id]=[];}
_this.selectors[item.competitor_id].push({id:item.id,selector:item.selector});
});
_this.selectcURLs();
}
});
}
//--------------------//
this.selectcURLs = function(callback){
_this.DB.query( _this.querys['selectcURLs'] , function(err, rows) {
if (!err){
_this.rows = rows;
_this.workersTask();
}
});
}
//--------------------//
this.workersTask = function(){
__this = this;
__this.worker = [];
for (var i = 0; i < _this.workers; i++) {
__this.worker[i] = {
id:i
,status: 'run'
,allTask : function(){
var status = {};
status['run'] = 0;
status['iddle'] = 0;
__this.worker.forEach(function(item){
if(item.status==='run'){status['run']++;}
else{status['iddle']++;}
});
return status;
}
,timeStart : new Date().valueOf()
,func: function(){
_this.parseData(__this.worker[this.id])
}
}
__this.worker[i].func();
}
}
//--------------------//
this.parseData = function(worker){
__this = this;
var count = _this.rows.length;
var startTime = new Date().valueOf();
if(count > 0 ){
var row = _this.rows.shift();//удаляет первый элемент из rows и возвращает его значение
var URL = row.competitor_url;
needle.get(URL, _this.needleOptions, function(err, res){
if (err) {worker.func(); return;}
var timeRequest = ( new Date().valueOf() ) - startTime;
schema.parseContent(res.body, function(schemaObject, $){
price = _this.parseBody(schemaObject,$,row);
status = ( price!='NULL' ) ? 'active' : 'error';
//console.log(res.statusCode, 'timeout:'+timeRequest, 'price:'+price, worker.id, URL, row.id);
_this.updateCompetitorData({
id : row.id
,status:status
,response_time:( new Date().valueOf() )
,response_ms:timeRequest
,price:price
});
worker.func();
});
});
}else{
worker.status = 'idle';
if(worker.allTask().run===0){
console.log('Мы все завершили, мы молодцы');
_this.DB.end();//Закрываем соединение с бд;
}
}
}
_this.parseBody = function(schemaObject,$,row){
var price;
schemaObject.elems.forEach(function(elemsItem, i) {
if(!elemsItem.product)return;
elemsItem.product.forEach(function(productItem, i) {
if(!productItem.price)return;
price = ( productItem.price['content'] ) ? productItem.price['content'] :
( productItem.price['text'] ) ? productItem.price['text'] :
null;
price = price.replace(/[^.\d]+/g,"").replace( /^([^\.]*\.)|\./g, '$1' );
price = Math.floor(price);
});
});
if( (!price) && (_this.selectors[row.competitor_id]) ){
_this.selectors[row.competitor_id].forEach(function(selector){
price_text = $(selector.selector).text();
if (price_text){
price = price_text.replace(/[^.\d]+/g,"").replace( /^([^\.]*\.)|\./g, '$1' );
price = Math.floor(price);
//Обновляем статус о том что selector был использован
//-------------------------------------------------//
return;
}
});
}
if(!price){price = 'NULL'};
return price;
}
//--------------------//
_this.updateCompetitorData = function(data){
query = templayed( _this.querys['updateCompetitorData'] )(data);
_this.DB.query( query , function(err, rows) {});
}
//--------------------//
_this.run();
}
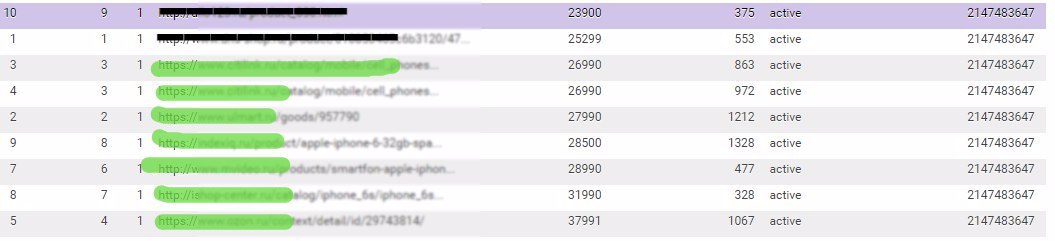
В результате получаем следующие данные:
На изображении видно, что можно отследить самую дорогую и самую дешевую цену конкурента, время ответа сервера. Теперь можно отправлять это в ценообразование, для пересмотра ценовой политики.
Подводя итог, хочется сказать, что с применением microdata парсинг названия товаров, цены и категории существенно упрощается. Но есть еще большая ложка дегтя:
- Не все интернет-магазины используют microdata.
- Не у всех microdata валидная (яркий пример – ozone).
- Не все интернет-магазины используют в microdata данные о цене, названии, категории.
- Некоторые магазины в microdata используют вместо content поле text, либо наоборот.
Те же магазины, которые не используют microdata, в качестве селекторов используют не id, а class, что правильно с точки зрения верстки, но усложняет парсинг (к примеру, в документе у нас могут быть 7 элементов с class='price', а цены будут находиться только в 4, 5, 6, 10). Также не всегда в элементе существует цена в удобном формате:
<div class="price price_break"><ins class="num">2980</ins><ins class="rub"> руб.</ins></div>На данный момент, с появлением microdata, парсинг стал намного проще.
В следующей статье попробую показать, как реализован алгоритм автоматического сопоставления url-карточки конкурента и карточки в интернет-магазине.
Поделиться с друзьями
Комментарии (4)

fijj
18.05.2017 10:45Исторически сложилось, что интернет-магазин – на 1C-Bitrix, поэтому мониторинг цен был написан на php. Но это неправильный подход, поэтому ниже будет описан алгоритм парсинга на Node.js.
Что неправильного в написание парсера на php? Почему node.js а не python например?
pan-alexey
18.05.2017 10:48Что неправильного в написание парсера на php?
В написании парсера на php ничего не правильного, неправилен подход — необходимо именно событийный ЯП. Про вопрос почему не python или java, можно и на C если захотеть, но я выбрал JS как знакомый для меня ЯП.
hamMElion
Очень интересный, амбициозный проект!
Да, тут основная сложность в разрозненности и нестабильности источников информации: страницы, их адреса, Dom, айдишники и прочие атрибуты постоянно меняются, поэтому для поддержки скрипта нужны будут люди. И чем больше база конкурентов, тем больше нагрузка на этих людей. Опять же, требования к полноте и достоверности данных нужно как-то покрывать, поэтому важно собирать по максимуму инфы, иначе картина рынка будет искажённой и полагаться на такие данные, при принятии решений, будет опасно.
Т.е., в целом, нужно иметь команду, постоянно переписывающую много кода (из плюсов, можно экономить на качестве). Тут, как мне кажется, выбор node.js и js прекрасный. Вот с реляционной бд я не очень согласен: структуру менять сложнее, у вас разреженность вижу большая достаточно. Можно было бы взять хорошую документоориентированную бд, типа монги, и хранить все там. Можно даже сразу в, скажем, elastic search и к нему отчёты уже независимо прикрутить, которые на лету генерировать можно, т.к. скорость позволяет :) Ну и используйте преимущество node.js -закладывайте модульность, так с кодом работать будет легче.
Ах, самое главное — обязательно продумайте систему мониторинга ошибок при парсинге, чтобы сразу в одном месте видеть, где и на каком конкуренте какой код не смог отработать (скажем, структура сайта поменялась), чтобы сразу знать куда лезть, чтобы починить!
Очень надеюсь, что у вас все получится и жду продолжения!
pan-alexey
Большое спасибо за отзыв, но это не проект. Сложилась необходимость реализовать это в кратчайшие сроки. Что касается выбора БД — то тут все же исторически сложилось что у нас MySQL. Всю фичи node.js — вообще надо использовать кластеры, надо разбить на модули, и много чего можно сделать. По вопросу аналитики — необходимы код ответа, title и т.п. По поводу elasticsearch — он как раз таки и используется, но немного в другой стезе (для сопоставления товара конкурентов с товаром из магазина)