
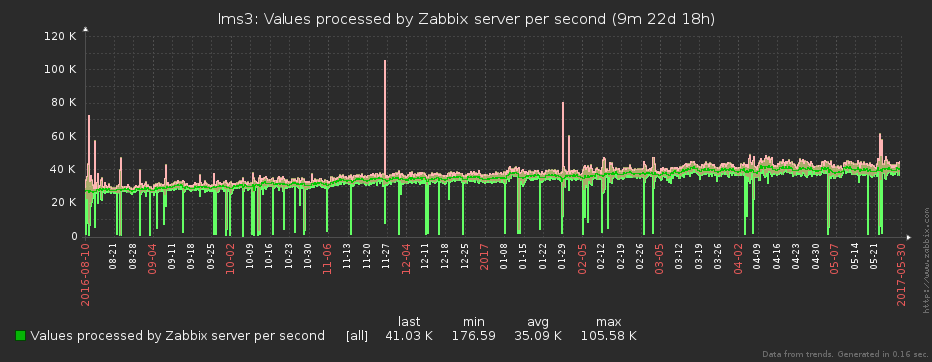
В первой части статьи про нашу систему мониторинга мы рассказали, какие организационные и технические проблемы заставили нас заняться расширением функционала Zabbix. В этой — покажем, как именно нам удается «переваривать» миллионы ежесекундно снимаемых отсчетов и превращать их в 40K+ values-per-second без потери ключевой информации.
Одной из «больных» тем мониторинга является его потенциальная неполнота. В особо клинических случаях можно иметь развернутый сервер, настроенные и работающие на нем сервисы, и… узнать о каких-то проблемах на нем исключительно по факту «падения» сервиса-потребителя, потому что мониторинг знает про все это добро «ровно ничего».
Чтобы таких ситуаций не возникало, помимо служебных инструкций, мы постарались максимально использовать и технические средства контроля за ситуацией.
Когда админы разворачивают новый сервер, они подключают его в Spacewalk (бесплатный аналог Red Hat Network Satellite). Эта полезная штука разворачивает на сервере конфиги и ПО, включая все необходимое для мониторинга. В том числе устанавливает наш пакет sbis3mon-discovery-scripts – легковесную утилиту на Python, которая запускается «по крону» каждый час, сканирует сервер и отправляет данные о найденных сервисах в реестр обнаружения (Discovery Registry).
Таким образом, sbis3mon имеет возможность запрашивать из реестра данные о серверах и сервисах, которые можно мониторить. Теперь включить наблюдение за сервером и его сервисами можно в один клик, просто выбрав его из списка в админке.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Автоматически подцепятся все найденные сервисы. Если в будущем на этом сервере будет развернут ещё какой-то сервис, он также добавится в мониторинг уже без участия админов.
Конечно же, есть возможность добавить сервер и вручную или клонированием.
В тот момент, когда админ добавил сервер или подключил для наблюдения новый сервис, происходит запуск соответствующих плагинов и установка соединений управляющих транспортов:
В большинстве случаев это подключение – единственное устанавливаемое к сервису, и оно живёт либо до дисконнекта, либо до первой ошибки. В последнем случае попытка реконнекта происходит автоматически через заданный интервал.
Мы стараемся использовать доступные нативные интерфейсы сервисов для получения статистики. За исключением мониторинга Windows и IIS мы не используем агентов. Хотя сейчас есть идея, как избавиться и от них.
После установки соединения плагин получает с сервиса конфигурацию: список его сущностей (список баз, перечень подмонтированных дисков, или активных сетевых интерфейсов, …).
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Список сущностей плагин отправляет в модуль zabbixSync, который отвечает за создание или синхронизацию в Zabbix’е «хоста» и описанных плагином структур: итемов, графиков, скринов (дашбордов) и триггеров. Да, вся визуализация и логика триггеров – тоже часть кода.
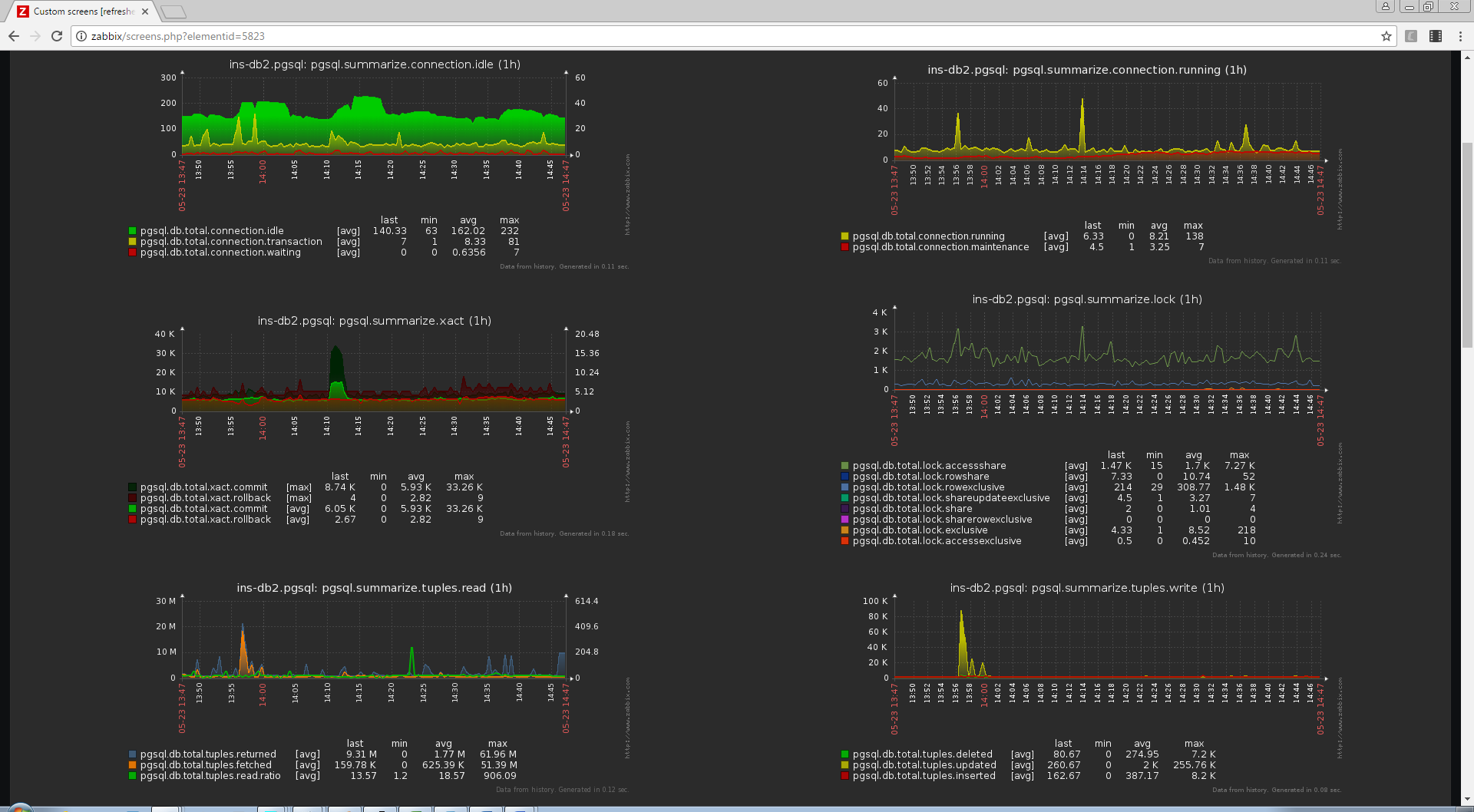
Для каждой сущности генерируется свой комплексный экран, позволяющий сразу визуально оценить наличие проблем или аномалий. Иногда также создаются сводные экраны, на которых может отражаться информация по группе сущностей – например, статистика суммарно по всем базам на конкретном инстансе PostgreSQL или загрузка CPU на каждом из юнитов бизнес-логики, обслуживающих один сервис.
В целом, у нас получилось, что на разработку, что конкретно и зачем мы хотим снимать, как это можно сделать наиболее эффективно, как все это вывести «красиво и понятно», времени тратится по каждому плагину даже больше, чем на саму реализацию сбора данных.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Одновременно с синхронизацией с Zabbix через заданные интервалы начинается опрос заданных сервисов. Для каждого из соответствующих плагинов координатор формирует и отправляет на выполнение задачу.
Плагин может различным образом обрабатывать, агрегировать и преобразовывать полученную информацию, прежде чем отправить её дальше – всё зависит от заложенной в него логики.
Например, плагин мониторинга linux-сервера устроен примерно следующим образом:
Обычно съем метрик практически в каждой системе происходит по принципу «спросил – узнал», и важно наличие самой возможности «спросить» что нужно. Когда же у вас высоконагруженная система, все меняется в корне.
Поэтому в особо критичных случаях мы считываем данные даже с минимальным квантом в 1 секунду. За счёт чего не пропускаем проблемы, которые возникали между соседними съёмами при меньшей частоте.
Мы стараемся сводить нагрузку на целевые серверы к минимуму, поэтому парсинг ответов проводим уже на стороне коллектора мониторинга. При этом за один запрос мы получаем сразу максимум необходимых данных, что также даёт синхронность метрик во времени. Но главное не заставлять целевую систему делать лишнего, что на самом деле не требуется.
В качестве ядра нашей системы мы выбрали NodeJS – и это неспроста. Кроме легкости разработки, активного сообщества и библиотеки модулей на все случаи жизни, у нее есть большой и жирный плюс в виде асинхронности «из коробки», идеально подходящей к нашим задачам.
Из описания нашей методики съема данных видно, что большую часть времени каждый плагин «ничего не делает», ожидая поступления новой порции данных от источника в активном соединении. Получается, что в рамках одного процесса мы можем одновременно эффективно обслуживать большое количество таких подключений. И асинхронность ядра позволяет нам делать это легко и удобно!
Конечно, чтобы не перегрузить eventloop процесса коллектора, мы его тоже постоянно мониторим (примерно как в этой статье), и перераспределяем задачи в соответствии с нагрузкой.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
В конечном счёте, полученные данные отправляются дальше – в модуль аппроксимации.
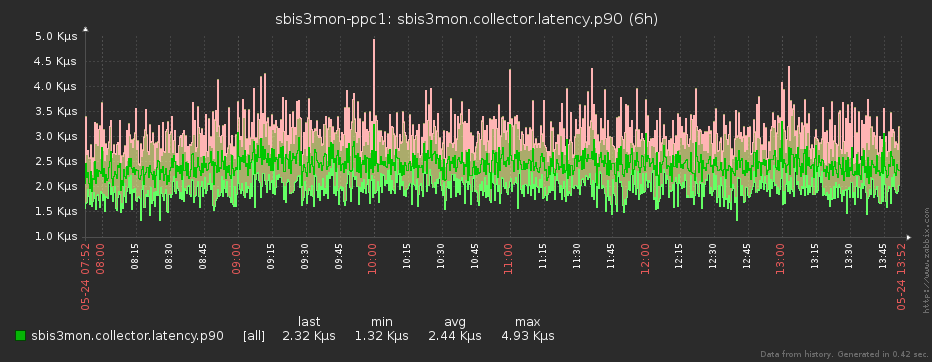
Понятно, что даже если мы снимаем данные посекундно, то ни Zabbix’у, ни смотрящему в него человеку, счастья от такой частоты нет совсем. Один «ляжет» под нагрузкой (мы ведь помним, что данные снимаются с нескольких тысяч серверов), у другого «вытекут глаза» от чехарды на графике.
Чтобы всем было полегче, перед отправкой в Zabbix мы «сжимаем» полученный массив исходных отсчетов до интервала, заданного в плагине для конкретной метрики. Но это не просто усреднение значения – с ним мы безвозвратно потеряли бы информацию о максимумах и минимумах на интервале. Все несколько хитрее.
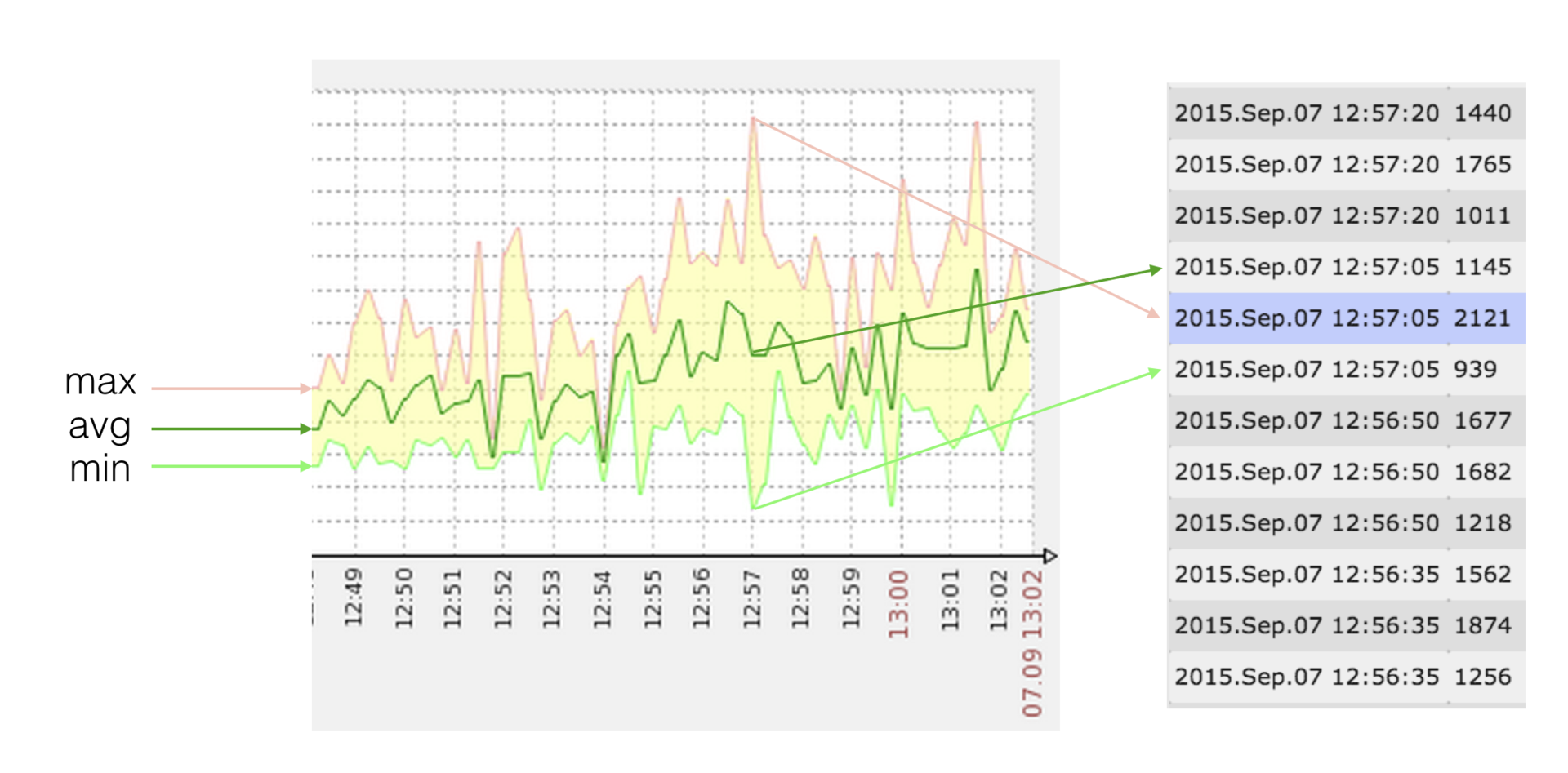
Поскольку на своих графиках Zabbix позволяет отображать min/max/avg-значения метрики, а значений в каждой точке (timestamp) может быть одновременно несколько, то этим мы и воспользовались.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Допустим, у нас есть достаточно редко изменяющаяся метрика (объем занятого места на диске), которую мы снимаем поминутно, а видеть хотим одно значение в час:
Теперь возьмем загрузку CPU, которую снимаем посекундно, а видеть новые точки хотим лишь раз в 10 секунд:
В чем же сложность?
Мы должны послать в Zabbix такой набор значений, что {min,max,avg}(zabbix) = {min,max,avg}(source). Если с min/max все просто и понятно, то «целевую» avg приходится иногда «подбирать» как решение уравнения:
Инициализируем массив результата:
Таким образом, мы не пропустим сильное отклонение величины от среднего, раз можем повесить триггер на max или min, а график от avg визуально будет выглядеть так же, как если бы мы отправляли «сырые» данные.
Пока существующее решение уже позволяет нам значительно экономить дисковые ресурсы и снизить нагрузку на СХД и сам Zabbix, мы пытаемся придумать, как здесь можно применить какой-либо алгоритм потоковой аппроксимации. Если есть идеи – делитесь в комментариях.
Многие еще из первой части статьи уже догадались, что все наши метрики имеют тип trapper, раз данные для них мы собираем и отправляем сами через протокол zabbix sender.
Чтобы уменьшить «непрофильную» нагрузку (открытие соединения, запуск парсера, …) при обработке принимаемых значений, мы группируем отсчеты в пакеты – по таймеру, чтобы не допустить сильного отставания от realtime, и по количеству (примерно по 1000), чтобы не «заткнуть» trapper-процесс обработкой надолго.
Поскольку в рамках одного nodejs-процесса у нас активно сразу много поставляющих данные плагинов, их данные очень удобно пакетируются и отправляются одним потоком. Получается, что и количество независимых «отправителей», дергающих zabbix, у нас тоже достаточно мало.
Благодаря использованию такой схемы, мы уже давно забыли, что такое nodata-«дыры» на графиках, вызванные перегрузкой Zabbix – ведь для этого должны оказаться заняты все трапперы.
При подключении к кластеру сбора нового коллектора или при выходе из него (штатно или в результате аварии), задачи автоматически перераспределяются мастер-процессом в соответствии с заданными «весами» инстансов.
Мастер никак не работает с тем трафиком, который принимают или генерируют коллекторы поэтому нет никаких потерь на «бутылочном горлышке» или разрыва в выполнении активных задач при сбое самого координатора. В результате, мы получили эффект «настоящего» линейного масштабирования.
Сейчас у нас работает всего 2 инстанса сбора с загрузкой около 25%.
При использовании в качестве ядра NodeJS становится очень удобно разрабатывать эффективный фронтенд на «хипстерских» инструментах: React+Redux, ES6, Babel, Webpack, …
Мы любим наших пользователей, поэтому стараемся сделать процесс их работы с системой максимально простым и удобным. Ведь если взаимодействовать с системой тяжело, то усиливается роль человеческого фактора, возрастает вероятность допустить ошибку.
Ошибки мы не любим и поэтому сделали некоторые полезные фишки:
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
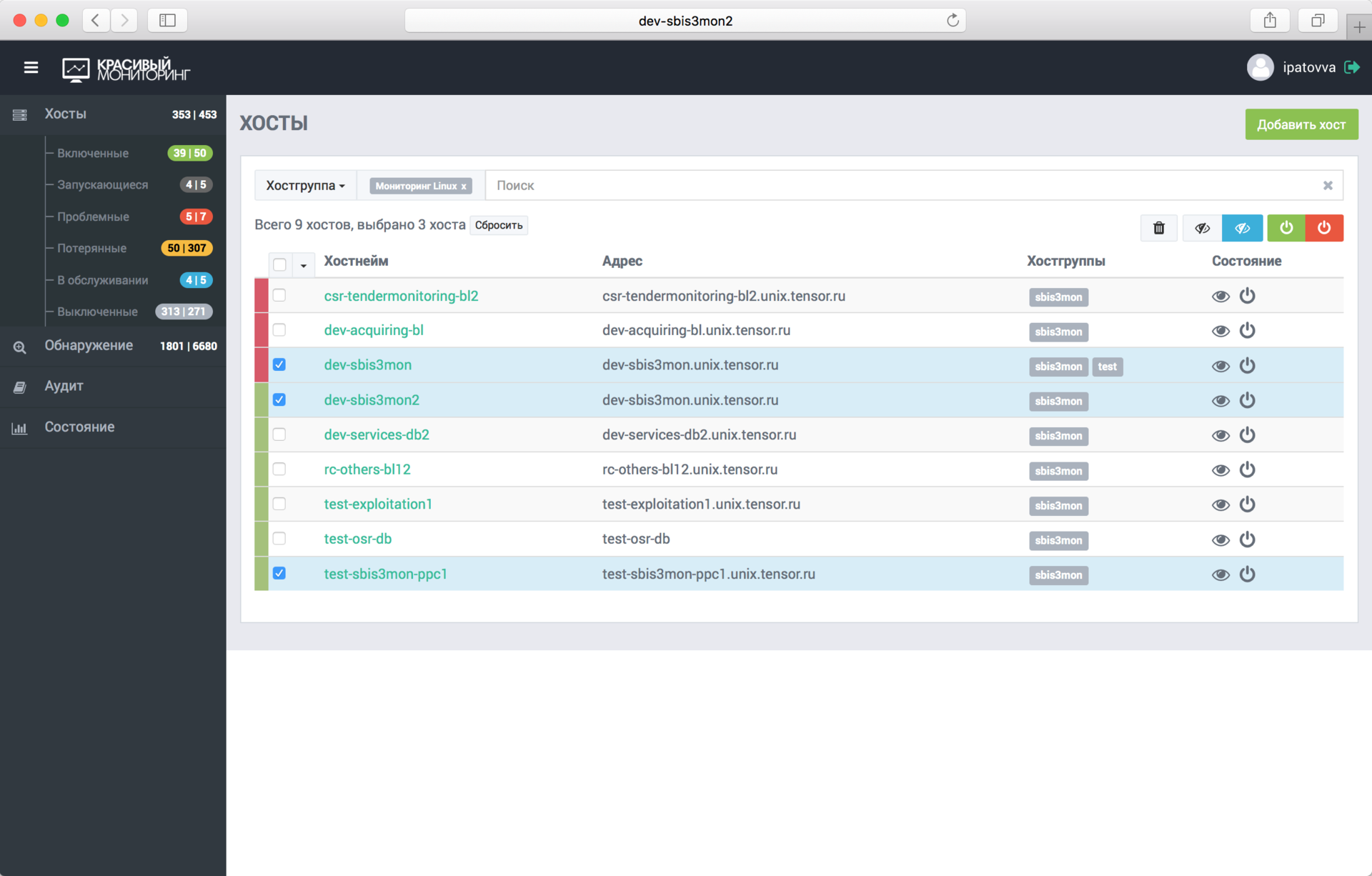
Через админку пользователи добавляют и удаляют хосты и сервисы, выводят их на обслуживание (когда данные продолжают идти, а алерты отключаются). Сюда выводятся все ошибки мониторинга (неверные реквизиты доступа, невозможность «достучаться» до сервера, …). Здесь же есть аудитлог (аналогичный Zabbix’у), в который записываются все действия пользователей, что бывает полезно при разборах полётов.
Фактически, админка самого Zabbix используется у нас уже только в каких-то нетипичных ситуациях, но не в оперативной работе.
Таким образом, с помощью sbis3mon мы решили многие наболевшие проблемы, при этом, не травмировав пользователей и сохранив привычный для них Zabbix.

Теперь мы можем мониторить огромное количество хостов и сервисов. Большая часть работы автоматизирована. Мы получили в свои руки довольно гибкий инструмент, который хорошо зарекомендовал себя в работе и помогает отлавливать большинство известных (и не очень) нам проблем.
Чтобы сделать представление о системе более ясным, прикладываю ссылку на запись семинара 2015 года. С тех пор многое изменилось, но суть осталась.
Сейчас мы работаем над тем, чтобы сделать систему более гибкой, не завязанной на нашу инфраструктуру, регламенты и привычки, и поделиться ей с сообществом, выложив в открытый доступ.
Следите за новостями в нашем блоге. До скорых встреч!
Авторы: kilor (Кирилл Боровиков) и vadim_ipatov (Вадим Ипатов)
Новый сервер? Автоматом
Одной из «больных» тем мониторинга является его потенциальная неполнота. В особо клинических случаях можно иметь развернутый сервер, настроенные и работающие на нем сервисы, и… узнать о каких-то проблемах на нем исключительно по факту «падения» сервиса-потребителя, потому что мониторинг знает про все это добро «ровно ничего».
Чтобы таких ситуаций не возникало, помимо служебных инструкций, мы постарались максимально использовать и технические средства контроля за ситуацией.
Когда админы разворачивают новый сервер, они подключают его в Spacewalk (бесплатный аналог Red Hat Network Satellite). Эта полезная штука разворачивает на сервере конфиги и ПО, включая все необходимое для мониторинга. В том числе устанавливает наш пакет sbis3mon-discovery-scripts – легковесную утилиту на Python, которая запускается «по крону» каждый час, сканирует сервер и отправляет данные о найденных сервисах в реестр обнаружения (Discovery Registry).
Таким образом, sbis3mon имеет возможность запрашивать из реестра данные о серверах и сервисах, которые можно мониторить. Теперь включить наблюдение за сервером и его сервисами можно в один клик, просто выбрав его из списка в админке.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Автоматически подцепятся все найденные сервисы. Если в будущем на этом сервере будет развернут ещё какой-то сервис, он также добавится в мониторинг уже без участия админов.
Конечно же, есть возможность добавить сервер и вручную или клонированием.
Включаемся!
В тот момент, когда админ добавил сервер или подключил для наблюдения новый сервис, происходит запуск соответствующих плагинов и установка соединений управляющих транспортов:
- ssh – для сбора данных с Linux;
- postgresql – выполняет прямое подключение к базам через нативный протокол;
- redis – к redis;
- … и т.д.
В большинстве случаев это подключение – единственное устанавливаемое к сервису, и оно живёт либо до дисконнекта, либо до первой ошибки. В последнем случае попытка реконнекта происходит автоматически через заданный интервал.
Мы стараемся использовать доступные нативные интерфейсы сервисов для получения статистики. За исключением мониторинга Windows и IIS мы не используем агентов. Хотя сейчас есть идея, как избавиться и от них.
Плагин – основа конфигурации
После установки соединения плагин получает с сервиса конфигурацию: список его сущностей (список баз, перечень подмонтированных дисков, или активных сетевых интерфейсов, …).
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Список сущностей плагин отправляет в модуль zabbixSync, который отвечает за создание или синхронизацию в Zabbix’е «хоста» и описанных плагином структур: итемов, графиков, скринов (дашбордов) и триггеров. Да, вся визуализация и логика триггеров – тоже часть кода.
Для каждой сущности генерируется свой комплексный экран, позволяющий сразу визуально оценить наличие проблем или аномалий. Иногда также создаются сводные экраны, на которых может отражаться информация по группе сущностей – например, статистика суммарно по всем базам на конкретном инстансе PostgreSQL или загрузка CPU на каждом из юнитов бизнес-логики, обслуживающих один сервис.
В целом, у нас получилось, что на разработку, что конкретно и зачем мы хотим снимать, как это можно сделать наиболее эффективно, как все это вывести «красиво и понятно», времени тратится по каждому плагину даже больше, чем на саму реализацию сбора данных.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Свет, камера… снова плагин!
Одновременно с синхронизацией с Zabbix через заданные интервалы начинается опрос заданных сервисов. Для каждого из соответствующих плагинов координатор формирует и отправляет на выполнение задачу.
Плагин может различным образом обрабатывать, агрегировать и преобразовывать полученную информацию, прежде чем отправить её дальше – всё зависит от заложенной в него логики.
Например, плагин мониторинга linux-сервера устроен примерно следующим образом:
- при разворачивании сервера через spacewalk на него сразу «заливается» ключ sbis3mon для доступа по SSH;
- при активации мониторинга коллектор получает задачу для linux-плагина * плагин устанавливает SSH-соединение с помощью NodeJS-модуля ssh2;
- в установившейся сессии запускаем на выполнение команду, которая сама будет отдавать нам все данные с нужной частотой:
watch -n 1 cat /proc/meminfo # все, дальше парсим на приемнике
Правила съема. Метод sbis3mon
Обычно съем метрик практически в каждой системе происходит по принципу «спросил – узнал», и важно наличие самой возможности «спросить» что нужно. Когда же у вас высоконагруженная система, все меняется в корне.
Например, у нас была ситуация, когда в какой-то момент виртуальная машина, на которой жила база «под реальным highload’ом», критичным ко времени отработки каждого миллисекундного запроса, «вставала колом» на 2-3 секунды. Снимая данные по CPU раз в 15 секунд, мы просто не наблюдали этих проблем – они «проскакивали» между отсчетами.
Поэтому в особо критичных случаях мы считываем данные даже с минимальным квантом в 1 секунду. За счёт чего не пропускаем проблемы, которые возникали между соседними съёмами при меньшей частоте.
Мы стараемся сводить нагрузку на целевые серверы к минимуму, поэтому парсинг ответов проводим уже на стороне коллектора мониторинга. При этом за один запрос мы получаем сразу максимум необходимых данных, что также даёт синхронность метрик во времени. Но главное не заставлять целевую систему делать лишнего, что на самом деле не требуется.
Например, изначально мониторинг состояния и количества сетевых соединений у нас был реализован через netstat. И все было хорошо, пока не начали появляться серверы с десятками и сотнями тысяч активных соединений – диспетчеры на Nginx, шина сообщений на RabbitMQ, … В какой-то момент мы увидели, что выполнение команды «для мониторинга» просаживает CPU в разы относительно прикладной нагрузки! Пришлось срочно переделывать съем данных через ss.
«А вместо сердца – пламенный мотор!»
В качестве ядра нашей системы мы выбрали NodeJS – и это неспроста. Кроме легкости разработки, активного сообщества и библиотеки модулей на все случаи жизни, у нее есть большой и жирный плюс в виде асинхронности «из коробки», идеально подходящей к нашим задачам.
Из описания нашей методики съема данных видно, что большую часть времени каждый плагин «ничего не делает», ожидая поступления новой порции данных от источника в активном соединении. Получается, что в рамках одного процесса мы можем одновременно эффективно обслуживать большое количество таких подключений. И асинхронность ядра позволяет нам делать это легко и удобно!
Конечно, чтобы не перегрузить eventloop процесса коллектора, мы его тоже постоянно мониторим (примерно как в этой статье), и перераспределяем задачи в соответствии с нагрузкой.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Компрессия данных
В конечном счёте, полученные данные отправляются дальше – в модуль аппроксимации.
Понятно, что даже если мы снимаем данные посекундно, то ни Zabbix’у, ни смотрящему в него человеку, счастья от такой частоты нет совсем. Один «ляжет» под нагрузкой (мы ведь помним, что данные снимаются с нескольких тысяч серверов), у другого «вытекут глаза» от чехарды на графике.
Чтобы всем было полегче, перед отправкой в Zabbix мы «сжимаем» полученный массив исходных отсчетов до интервала, заданного в плагине для конкретной метрики. Но это не просто усреднение значения – с ним мы безвозвратно потеряли бы информацию о максимумах и минимумах на интервале. Все несколько хитрее.
Поскольку на своих графиках Zabbix позволяет отображать min/max/avg-значения метрики, а значений в каждой точке (timestamp) может быть одновременно несколько, то этим мы и воспользовались.
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Допустим, у нас есть достаточно редко изменяющаяся метрика (объем занятого места на диске), которую мы снимаем поминутно, а видеть хотим одно значение в час:
[12345,12345,…,12345] > {min = 12345, avg = 12345, max = 12345} > zabbix = [12345]
в этом случае нам достаточно всего одного значения в точке
Теперь возьмем загрузку CPU, которую снимаем посекундно, а видеть новые точки хотим лишь раз в 10 секунд:
[10,20,30,40,50,50,40,30,20,10] > {min = 10, avg = 30, max = 50} > zabbix = [10,30,50]
в этом случае нам достаточно всего 3 значений вместо 10 исходных
В чем же сложность?
Мы должны послать в Zabbix такой набор значений, что {min,max,avg}(zabbix) = {min,max,avg}(source). Если с min/max все просто и понятно, то «целевую» avg приходится иногда «подбирать» как решение уравнения:
(A * min + B * max + q) / (A + B + 1) = avg
где A,B – целые; min <= q <= max
Инициализируем массив результата:
[10,10,30,10,50,10,40,10,20,10] > {min = 10, avg = 20, max = 50} > zabbix = [10,50,…], > .push(min)
> zabbix = [10,50,10,…], > .push(min)
> zabbix = [10,50,10,10]
в этом случае нам понадобилось уже 4 значения, но все равно не 10
Таким образом, мы не пропустим сильное отклонение величины от среднего, раз можем повесить триггер на max или min, а график от avg визуально будет выглядеть так же, как если бы мы отправляли «сырые» данные.
Пока существующее решение уже позволяет нам значительно экономить дисковые ресурсы и снизить нагрузку на СХД и сам Zabbix, мы пытаемся придумать, как здесь можно применить какой-либо алгоритм потоковой аппроксимации. Если есть идеи – делитесь в комментариях.
Оптимизация отправки метрик
Многие еще из первой части статьи уже догадались, что все наши метрики имеют тип trapper, раз данные для них мы собираем и отправляем сами через протокол zabbix sender.
Чтобы уменьшить «непрофильную» нагрузку (открытие соединения, запуск парсера, …) при обработке принимаемых значений, мы группируем отсчеты в пакеты – по таймеру, чтобы не допустить сильного отставания от realtime, и по количеству (примерно по 1000), чтобы не «заткнуть» trapper-процесс обработкой надолго.
Поскольку в рамках одного nodejs-процесса у нас активно сразу много поставляющих данные плагинов, их данные очень удобно пакетируются и отправляются одним потоком. Получается, что и количество независимых «отправителей», дергающих zabbix, у нас тоже достаточно мало.
Благодаря использованию такой схемы, мы уже давно забыли, что такое nodata-«дыры» на графиках, вызванные перегрузкой Zabbix – ведь для этого должны оказаться заняты все трапперы.
Масштабирование и отказоустойчивость
При подключении к кластеру сбора нового коллектора или при выходе из него (штатно или в результате аварии), задачи автоматически перераспределяются мастер-процессом в соответствии с заданными «весами» инстансов.
Мастер никак не работает с тем трафиком, который принимают или генерируют коллекторы поэтому нет никаких потерь на «бутылочном горлышке» или разрыва в выполнении активных задач при сбое самого координатора. В результате, мы получили эффект «настоящего» линейного масштабирования.
Сейчас у нас работает всего 2 инстанса сбора с загрузкой около 25%.
«Сделай мне красиво!»
При использовании в качестве ядра NodeJS становится очень удобно разрабатывать эффективный фронтенд на «хипстерских» инструментах: React+Redux, ES6, Babel, Webpack, …
Мы любим наших пользователей, поэтому стараемся сделать процесс их работы с системой максимально простым и удобным. Ведь если взаимодействовать с системой тяжело, то усиливается роль человеческого фактора, возрастает вероятность допустить ошибку.
Ошибки мы не любим и поэтому сделали некоторые полезные фишки:
- массовые операции;
- клонирование хостов;
- автодополнение по мере ввода, где это возможно;
- различные фильтры;
- realtime-статусы;
- …
Изображение кликабельно, открывается в текущей вкладке веб-браузера.
Через админку пользователи добавляют и удаляют хосты и сервисы, выводят их на обслуживание (когда данные продолжают идти, а алерты отключаются). Сюда выводятся все ошибки мониторинга (неверные реквизиты доступа, невозможность «достучаться» до сервера, …). Здесь же есть аудитлог (аналогичный Zabbix’у), в который записываются все действия пользователей, что бывает полезно при разборах полётов.
Фактически, админка самого Zabbix используется у нас уже только в каких-то нетипичных ситуациях, но не в оперативной работе.
Результаты
Таким образом, с помощью sbis3mon мы решили многие наболевшие проблемы, при этом, не травмировав пользователей и сохранив привычный для них Zabbix.
Теперь мы можем мониторить огромное количество хостов и сервисов. Большая часть работы автоматизирована. Мы получили в свои руки довольно гибкий инструмент, который хорошо зарекомендовал себя в работе и помогает отлавливать большинство известных (и не очень) нам проблем.
Чтобы сделать представление о системе более ясным, прикладываю ссылку на запись семинара 2015 года. С тех пор многое изменилось, но суть осталась.
Забегая вперёд
Сейчас мы работаем над тем, чтобы сделать систему более гибкой, не завязанной на нашу инфраструктуру, регламенты и привычки, и поделиться ей с сообществом, выложив в открытый доступ.
Следите за новостями в нашем блоге. До скорых встреч!
Авторы: kilor (Кирилл Боровиков) и vadim_ipatov (Вадим Ипатов)
Поделиться с друзьями
qwertyRu
добрый день,
Вы упомянули, что используете spacewalk. Можете сказать через каким образом добиваетесь «разворачивает на сервере конфиги и ПО» (я тоже использую spacewalk).
Правильно ли предполагаю, что конфиги распространяете через подписку системы на нужный канал конфигураций?
Как поступаете в такой ситуации:
Есть установленный на сервере пакет foo-1.1.1 Вышло обновление до foo-1.1.2, spacewalk (если настроена автоматическая обновление репозиториев) указала, что надо обновить пакет (желтый значок). Мы решили не обновлять этот пакет пока не выйдет версия foo-1.2.1. Как «сбросить» желтый значок?
PSN35
Добрый день.
При использовании системы управления Spacewalk необходимо в обязательном порядке использовать механизмы "Stored Profiles". Данный механизм позволит Вам создать набор из групп систем с одинаковыми пакетными наборами.
Для примера: имеем группу серверов баз данных с PostgreSQL. Все сервера группы выполняют одинаковую роль и должны иметь одинаковый набор пакетов. Для этого с эталонного сервера создаем «System Profile» и получаем снимок состояния пакетов для данной группы серверов. Далее применяем данный снимок на всю группу и получаем абсолютно идентичные по набору пакетов сервера.
Применять каждый раз обновления при получении очередной порции Errata смысла не имеет. Необходимо четко разграничивать критичность уязвимостей и не забывать об этапе отладки приложения. После прохождения данных процедур — изготавливается новый «System Profile». Далее он опять применяется на группу серверов.
Уведомления о доступности обновлений не сбрасываются просто так. Это индикатор для администратора о наличии новых пакетов. Оценить критичность обновлений можете используя функционал процедуры «System Currency» (более подробно см. форум )