
В наше время термин “BIG DATA” у всех на слуху. После появления в сети и в прессе многочисленных публикаций, связанных с обработкой «больших данных», интерес к этой теме постоянно растет. Все более широким спросом пользуются системы управления базами данных с
использованием технологии NoSQL. Всем понятно, что для построения систем “BIG DATA” необходимо располагать внушительными аппаратными ресурсами. Еще более важно уметь оптимально использовать вычислительные ресурсы системы и эффективно их масштабировать. Это неизбежно меняет подходы к построению систем обработки данных. Если раньше системы строились по принципу централизации хранилища данных, с которым работает набор мощных вычислительных серверов, то сейчас такой подход постепенно отходит на второй план. Появляется все больше систем, построенных на базе кластера из большого количества стандартных серверов средней мощности. Централизованного хранилища в такой системе нет. Для работы с данными внутри кластера используется модульная распределенная система хранения с использованием локальных дисковых ресурсов каждого сервера. Если раньше масштабирование осуществлялось за счет добавления дисков в централизованную систему хранения и модернизации вычислительных серверов, то сейчас эти же вопросы решаются просто добавлением стандартных узлов в кластер. Этот подход получает все большее распространение.
В процессе эксплуатации таких систем часто приходится сталкиваться с проблемами нехватки вычислительных ресурсов на некоторых узлах. Встречаются ситуации, когда нагрузка на узлы кластера распределяется неравномерно – одна часть узлов простаивает, а другая перегружена различными задачами. Эти проблемы можно решать «экстенсивно», добавляя в кластер все новые и новые узлы – что многие, кстати говоря, и практикуют. Можно, однако, применять «интенсивный» подход, оптимизируя распределение ресурсов между различными задачами и различными узлами кластера.
Так или иначе, в последнее время назрела насущная потребность в системе, способной быстро и гибко перераспределять имеющиеся в наличии ресурсы в ответ на изменяющиеся условия нагрузки. На практике для реализации указанных выше функций система должна обеспечивать выполнение трех главных условий:
Идея создания системы управления кластером с обобщенными вычислительными ресурсами некоторое время назад была реализована силами Apache Foundation в продукте под названием MESOS. Этот продукт позволяет как раз обеспечить выполнение первого условия – объединить вычислительные ресурсы нескольких аппаратных серверов в один распределенный набор ресурсов, организовав кластерную вычислительную систему.

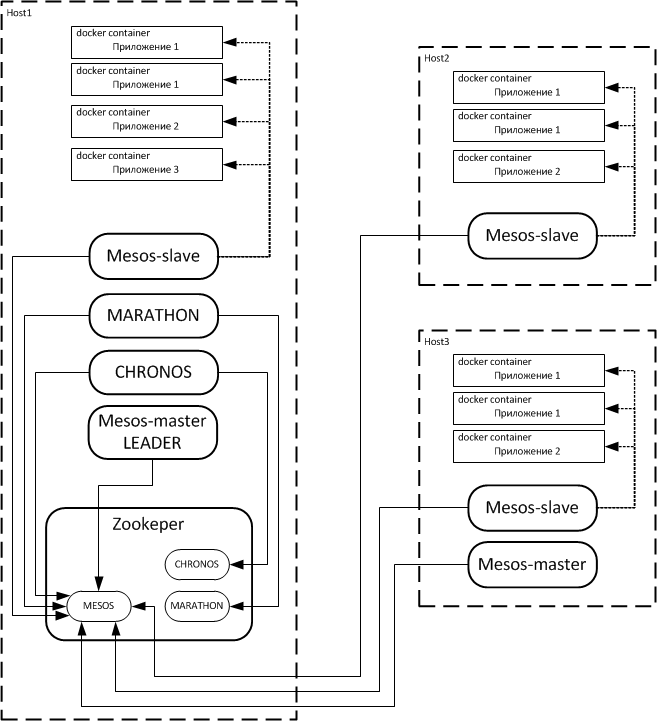
В двух словах как это устроено: на каждом узле кластера запускается сервис MESOS, причем он может работать в двух режимах – mesos-master и mesos-slave. Таким образом, каждый узел кластера получает или роль mesos-slave, или роль mesos-master, или обе роли в месте, что тоже возможно. Mesos-slave узлы предназначены для запуска приложений по команде, получаемой от узла mesos-master. Узлы mesos-master управляют процессом запуска приложений на узлах кластера, обеспечивая, таким образом, выполнение и второго условия – позволяют запустить произвольное приложение на произвольном узле кластера. Mesos-master узлов обычно 2 или 3 для обеспечения отказоустойчивости. Поскольку по умолчанию на узле запускаются обе роли одновременно, на большинстве узлов роль mesos-master целесообразно отключать. Взаимодействие mesos-slave и mesos-master узлов осуществляется средствами Apache Zookeeper. Функциональность системы Apache MESOS возможно гибко расширять, встраивая в MESOS сторонние приложения в качестве framework’ов.
Ключевой подход Apache MESOS заключается в том, что mesos-slave узлы учитывают существующие на них свободные аппаратные ресурсы – CPU и RAM – сообщая mesos-master узлам об их количестве. В результате mesos-master владеет полной информацией о доступных на узлах mesos-slave вычислительных ресурсах. При этом он не только выдает команду slave узлу на запуск приложения, но и способен принудительно задать количество вычислительных ресурсов, которыми это приложение может располагать. Эта задача решается при помощи механизма контейнеризации приложений. Процесс запускается в т. н. контейнере – замкнутой операционной среде. Основа контейнера – файл-образ, в котором установлено ядро ОС, развернуты корневая FS, все необходимые системные библиотеки и так далее. При старте контейнера запускается ядро системы из образа. После этого запускается само приложение в выделенном, заранее подготовленном для него операционном окружении. Получается некое подобие виртуальной машины для одного процесса. Здесь важно то, что применение контейнеризации позволяет выделять для каждого контейнера фиксированный объем ОЗУ и фиксированное количество ядер CPU (в том числе и дробное, меньшее 1 – 0,5 ядра, например).

Таким образом, мы можем обеспечить выполнение и третьего условия – реализуем возможность выделять каждой задаче определенный объем вычислительных ресурсов из общего набора. Следует отметить, что изначально Apache MESOS решал озвученные задачи с использованием своих собственных алгоритмов контейнеризации приложений, однако после появления на рынке продукта docker последний полностью заместил встроенные средства контейнеризации Apache MESOS. Так или иначе, на текущий момент интеграция docker в решения с Apache MESOS получила широкое распространение и является стандартом де-факто. Позиции docker в этой сфере еще больше упрочились благодаря сервису docker hub – системе бесплатного распространения контейнеризованных приложений, по идеологии чем-то схожей с известным сервисом git-hub. Используя этот сервис, разработчики могут публиковать свои приложения в формате готовых контейнеров docker, чем многие, кстати, активно пользуются в последнее время.
Теперь, если на каком-нибудь mesos-slave узле ресурсы исчерпываются, это сразу «становится известно» mesos-master узлу, и он не может запустить приложение на таком slave-узле. В этом случае mesos-master будет вынужден искать другой, менее нагруженный mesos-slave. Это приводит к тому, что более требовательные к наличию вычислительных ресурсов задачи будут «вымещаться» на менее нагруженные узлы кластера. Таким образом, мы получаем полноценный кластер с обобщенными ресурсами, который может задавать определенное количество ресурсов, выделяемых приложению для работы.
К сожалению, очевидным недостатком решений на базе Apache MESOS является ориентированность на единовременный запуск одной копии приложения на отдельном узле кластера, без контроля состояния приложения и без поддержания его работоспособности на долговременной основе. Однако эта проблема не так давно была решена компанией MESOSPHERE. На рынок были выведены продукты MARATHON и CHRONOS. Эти продукты позволяют управлять запуском приложений в среде Apache MESOS. Взаимодействуя через Apache zookeeper с mesos-master, они встраиваются в его структуры в качестве framework’ов, обеспечивая системе новые функциональные возможности. MARATHON предназначен для запуска приложений, которые должны работать долгое время в непрерывном режиме. Он осуществляет возможности масшта¬би¬ро¬ва¬ния и мониторинга работоспособности запущенных с его помощью приложений. В набор стандартных функций MARATHON входят возможности одновременного запуска экземпляра приложения на всех узлах кластера, запуск приложения на определенной части узлов кластера, регулирование количества копий приложения, запускаемых на одном узле кластера и проч. CHRONOS, в свою очередь, обладая сходной функциональностью, ориентирован на запуск разовых задач по расписанию.
Оба из перечисленных приложений снабжены своим собственным интерфейсом управления, которое осуществляется с использованием протокола HTTP и технологии REST API. Фактически MARATHON встает между пользователем и mesos-master, принимая запрос на запуск приложения по REST API в формате JSON. В запросе пользователь, помимо прочего, может сконфигурировать общее количество экземпляров запускаемого приложения в масштабе кластера, количество экземпляров приложения на один узел, количество системных ресурсов, выдаваемых каждому экземпляру приложения и т. д.
Как уже упоминалось выше, многие разработчики начинают распространять свои приложения в виде docker-контейнеров. В частности компания MESOSPHERE успешно использует данный подход, в результате чего рассмотренные в этой статье приложения MARATHON и CHRONOS в настоящий момент доступны в виде готовых контейнеров. Их использование упрощает процесс обслуживания этих подсистем, позволяет без труда перемещать их между узлами кластера, существенно ускоряет процесс обновления версий и так далее. Опыт собственных разработок, а также опыт сторонних компаний дает возможность считать этот подход наиболее вероятной тенденцией развития технологий в данной отрасли.
Подводя итог, можно сказать, что в нашем распоряжении есть технология, которая на практике способна решить сформулированные в начале статьи задачи, выполнить три главных требования: обеспечить возможность прозрачного использования обобщенных вычислительных ресурсов IT-системы, предоставить возможность запускать произвольные задачи на произвольном узле системы и налаживать механизм назначения определенного объема вычислительных ресурсов из общего кластерного набора каждой задаче в отдельности.
В завершении будет не лишним отметить, что эффективность описанного в статье похода подтверждена успешным опытом внедрения и эксплуатации решений, разработанных с использованием описанных выше технологий, несколькими петербургскими IT-компаниями.
Более детально технологии, рассмотренные в данной статье, описаны здесь.
использованием технологии NoSQL. Всем понятно, что для построения систем “BIG DATA” необходимо располагать внушительными аппаратными ресурсами. Еще более важно уметь оптимально использовать вычислительные ресурсы системы и эффективно их масштабировать. Это неизбежно меняет подходы к построению систем обработки данных. Если раньше системы строились по принципу централизации хранилища данных, с которым работает набор мощных вычислительных серверов, то сейчас такой подход постепенно отходит на второй план. Появляется все больше систем, построенных на базе кластера из большого количества стандартных серверов средней мощности. Централизованного хранилища в такой системе нет. Для работы с данными внутри кластера используется модульная распределенная система хранения с использованием локальных дисковых ресурсов каждого сервера. Если раньше масштабирование осуществлялось за счет добавления дисков в централизованную систему хранения и модернизации вычислительных серверов, то сейчас эти же вопросы решаются просто добавлением стандартных узлов в кластер. Этот подход получает все большее распространение.
В процессе эксплуатации таких систем часто приходится сталкиваться с проблемами нехватки вычислительных ресурсов на некоторых узлах. Встречаются ситуации, когда нагрузка на узлы кластера распределяется неравномерно – одна часть узлов простаивает, а другая перегружена различными задачами. Эти проблемы можно решать «экстенсивно», добавляя в кластер все новые и новые узлы – что многие, кстати говоря, и практикуют. Можно, однако, применять «интенсивный» подход, оптимизируя распределение ресурсов между различными задачами и различными узлами кластера.
Так или иначе, в последнее время назрела насущная потребность в системе, способной быстро и гибко перераспределять имеющиеся в наличии ресурсы в ответ на изменяющиеся условия нагрузки. На практике для реализации указанных выше функций система должна обеспечивать выполнение трех главных условий:
- Обеспечивать возможность объединить вычислительные ресурсы отдельных серверов в общий набор.
- Обеспечивать возможность запускать произвольное приложение на произвольном узле кластера.
- Обеспечивать возможность выделять вычислительные ресурсы из общего набора каждой задаче в отдельности в определенном объеме.
Идея создания системы управления кластером с обобщенными вычислительными ресурсами некоторое время назад была реализована силами Apache Foundation в продукте под названием MESOS. Этот продукт позволяет как раз обеспечить выполнение первого условия – объединить вычислительные ресурсы нескольких аппаратных серверов в один распределенный набор ресурсов, организовав кластерную вычислительную систему.
В двух словах как это устроено: на каждом узле кластера запускается сервис MESOS, причем он может работать в двух режимах – mesos-master и mesos-slave. Таким образом, каждый узел кластера получает или роль mesos-slave, или роль mesos-master, или обе роли в месте, что тоже возможно. Mesos-slave узлы предназначены для запуска приложений по команде, получаемой от узла mesos-master. Узлы mesos-master управляют процессом запуска приложений на узлах кластера, обеспечивая, таким образом, выполнение и второго условия – позволяют запустить произвольное приложение на произвольном узле кластера. Mesos-master узлов обычно 2 или 3 для обеспечения отказоустойчивости. Поскольку по умолчанию на узле запускаются обе роли одновременно, на большинстве узлов роль mesos-master целесообразно отключать. Взаимодействие mesos-slave и mesos-master узлов осуществляется средствами Apache Zookeeper. Функциональность системы Apache MESOS возможно гибко расширять, встраивая в MESOS сторонние приложения в качестве framework’ов.
Ключевой подход Apache MESOS заключается в том, что mesos-slave узлы учитывают существующие на них свободные аппаратные ресурсы – CPU и RAM – сообщая mesos-master узлам об их количестве. В результате mesos-master владеет полной информацией о доступных на узлах mesos-slave вычислительных ресурсах. При этом он не только выдает команду slave узлу на запуск приложения, но и способен принудительно задать количество вычислительных ресурсов, которыми это приложение может располагать. Эта задача решается при помощи механизма контейнеризации приложений. Процесс запускается в т. н. контейнере – замкнутой операционной среде. Основа контейнера – файл-образ, в котором установлено ядро ОС, развернуты корневая FS, все необходимые системные библиотеки и так далее. При старте контейнера запускается ядро системы из образа. После этого запускается само приложение в выделенном, заранее подготовленном для него операционном окружении. Получается некое подобие виртуальной машины для одного процесса. Здесь важно то, что применение контейнеризации позволяет выделять для каждого контейнера фиксированный объем ОЗУ и фиксированное количество ядер CPU (в том числе и дробное, меньшее 1 – 0,5 ядра, например).
Таким образом, мы можем обеспечить выполнение и третьего условия – реализуем возможность выделять каждой задаче определенный объем вычислительных ресурсов из общего набора. Следует отметить, что изначально Apache MESOS решал озвученные задачи с использованием своих собственных алгоритмов контейнеризации приложений, однако после появления на рынке продукта docker последний полностью заместил встроенные средства контейнеризации Apache MESOS. Так или иначе, на текущий момент интеграция docker в решения с Apache MESOS получила широкое распространение и является стандартом де-факто. Позиции docker в этой сфере еще больше упрочились благодаря сервису docker hub – системе бесплатного распространения контейнеризованных приложений, по идеологии чем-то схожей с известным сервисом git-hub. Используя этот сервис, разработчики могут публиковать свои приложения в формате готовых контейнеров docker, чем многие, кстати, активно пользуются в последнее время.
Теперь, если на каком-нибудь mesos-slave узле ресурсы исчерпываются, это сразу «становится известно» mesos-master узлу, и он не может запустить приложение на таком slave-узле. В этом случае mesos-master будет вынужден искать другой, менее нагруженный mesos-slave. Это приводит к тому, что более требовательные к наличию вычислительных ресурсов задачи будут «вымещаться» на менее нагруженные узлы кластера. Таким образом, мы получаем полноценный кластер с обобщенными ресурсами, который может задавать определенное количество ресурсов, выделяемых приложению для работы.
К сожалению, очевидным недостатком решений на базе Apache MESOS является ориентированность на единовременный запуск одной копии приложения на отдельном узле кластера, без контроля состояния приложения и без поддержания его работоспособности на долговременной основе. Однако эта проблема не так давно была решена компанией MESOSPHERE. На рынок были выведены продукты MARATHON и CHRONOS. Эти продукты позволяют управлять запуском приложений в среде Apache MESOS. Взаимодействуя через Apache zookeeper с mesos-master, они встраиваются в его структуры в качестве framework’ов, обеспечивая системе новые функциональные возможности. MARATHON предназначен для запуска приложений, которые должны работать долгое время в непрерывном режиме. Он осуществляет возможности масшта¬би¬ро¬ва¬ния и мониторинга работоспособности запущенных с его помощью приложений. В набор стандартных функций MARATHON входят возможности одновременного запуска экземпляра приложения на всех узлах кластера, запуск приложения на определенной части узлов кластера, регулирование количества копий приложения, запускаемых на одном узле кластера и проч. CHRONOS, в свою очередь, обладая сходной функциональностью, ориентирован на запуск разовых задач по расписанию.
Оба из перечисленных приложений снабжены своим собственным интерфейсом управления, которое осуществляется с использованием протокола HTTP и технологии REST API. Фактически MARATHON встает между пользователем и mesos-master, принимая запрос на запуск приложения по REST API в формате JSON. В запросе пользователь, помимо прочего, может сконфигурировать общее количество экземпляров запускаемого приложения в масштабе кластера, количество экземпляров приложения на один узел, количество системных ресурсов, выдаваемых каждому экземпляру приложения и т. д.
Как уже упоминалось выше, многие разработчики начинают распространять свои приложения в виде docker-контейнеров. В частности компания MESOSPHERE успешно использует данный подход, в результате чего рассмотренные в этой статье приложения MARATHON и CHRONOS в настоящий момент доступны в виде готовых контейнеров. Их использование упрощает процесс обслуживания этих подсистем, позволяет без труда перемещать их между узлами кластера, существенно ускоряет процесс обновления версий и так далее. Опыт собственных разработок, а также опыт сторонних компаний дает возможность считать этот подход наиболее вероятной тенденцией развития технологий в данной отрасли.
Подводя итог, можно сказать, что в нашем распоряжении есть технология, которая на практике способна решить сформулированные в начале статьи задачи, выполнить три главных требования: обеспечить возможность прозрачного использования обобщенных вычислительных ресурсов IT-системы, предоставить возможность запускать произвольные задачи на произвольном узле системы и налаживать механизм назначения определенного объема вычислительных ресурсов из общего кластерного набора каждой задаче в отдельности.
В завершении будет не лишним отметить, что эффективность описанного в статье похода подтверждена успешным опытом внедрения и эксплуатации решений, разработанных с использованием описанных выше технологий, несколькими петербургскими IT-компаниями.
Более детально технологии, рассмотренные в данной статье, описаны здесь.
Поделиться с друзьями
denissa
Добрый день. А есть информация какие компании используют эту технологию и под какие задачи?
shurup
Про известных компаний-пользователей Mesos у нас тут в комментариях на днях писали. А вообще есть вот такой крутой список.