
Самодостаточная система — это та, которая способна восстанавливаться и адаптироваться. Восстановление означает, что кластер почти всегда будет в том состоянии, в котором его запроектировали. Например, если копия сервиса выйдет из строя, то системе потребуется ее восстановить. Адаптация же связана с модификацией желаемого состояния, так чтобы система смогла справиться с изменившимися условиями. Простым примером будет увеличение трафика. В этом случае сервисам потребуется масштабироваться. Когда восстановление и адаптация автоматизировано, мы получаем самовосстанавливающуюся и самоадаптирующуюся систему. Такая система является самодостаточной и может действовать без вмешательства человека.
Как выглядит самодостаточная система? Какие ее основные части? Кто действующие лица? В этой статье мы обсудим только сервисы и проигнорируем тот факт, что железо также очень важно. Такими ограничениями мы составим картину высокого уровня, которая описывает (в основном) автономную систему с точки зрения сервисов. Мы опустим детали и взглянем на систему с высоты птичьего полёта.
Если вы хорошо разбираетесь в теме и хотите сразу всё понять, то система изображено на рисунке ниже.
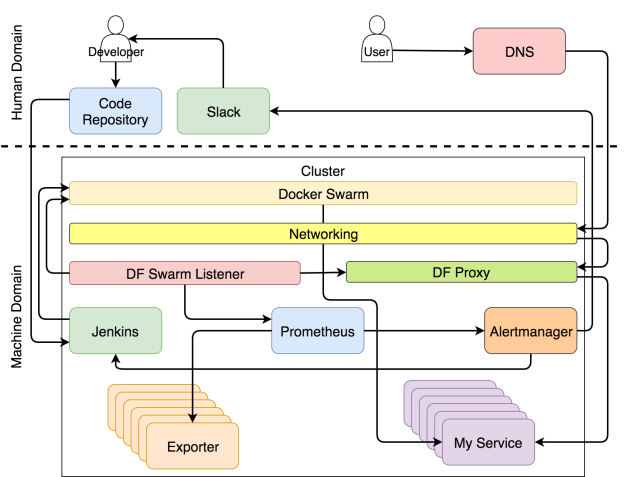
Система с самовосстанавливающимися и самоадаптирующимися сервисами
Возможно, в такой диаграмме сложно разобраться с ходу. Если бы я отделался от вас таким рисунком, вы могли бы подумать, что сопереживание — не самая яркая черта моего характера. В таком случае вы не одиноки. Моя жена думает так же даже безо всяких там диаграмм. Но в этот раз я сделаю всё возможное, чтобы поменять ваше мнение и начать с чистого листа.
Мы можем разделить систему на две основные области — человеческую и машинную. Считайте, что вы попали в Матрицу. Если вы не видели этот фильм, немедленно отложите эту статью, достаньте попкорн и вперёд.
В Матрице мир поработили машины. Люди там мало что делают, кроме тех немногих, которые осознали, что происходит. Большинство живут во сне, который отражает прошедшие события истории человечества. Тоже самое сейчас происходит с современными кластерами. Большинство обращается с ними, как будто на дворе 1999 год. Практически все действия выполняются вручную, процессы громоздкие, а система выживает лишь за счёт грубой силы и впустую затраченной энергии. Некоторые поняли, что на дворе уже 2017 год (по крайней мере на время написания этой статьи) и что хорошо спроектированная система должна выполнять большую часть работы автономно. Практически всё должно управляться машинами, а не людьми.
Но это не означает, что для людей не осталось места. Работа для нас есть, но она больше связана с творческими и неповторяющимися задачами. Таким образом, если мы сфокусируется только на кластерных операциях, человеческая область ответственности уменьшится и уступит место машинам. Задачи распределяются по ролям. Как вы увидите ниже, специализация инструмента или человеком может быть очень узкой, и тогда он будет выполнять лишь один тип задач, или же он может отвечать за множество аспектов операций.
Роль разработчика в системе
В область ответственности человека входят процессы и инструменты, которыми нужно управлять вручную. Из этой области мы пытаемся удалить все повторяющиеся действия. Но это не означает, что она должна вовсе исчезнуть. Совсем наоборот. Когда мы избавляемся от повторяющихся задач, мы высвобождаем время, которое можно потратить на действительно значимые задачи. Чем меньше мы занимаемся задачами, которые можно делегировать машине, тем больше времени мы можем потратить на те задачи, для которых требуется творческий подход. Эта философия стоит в одном ряду с сильными и слабыми сторонами каждого актера этой драмы. Машина хорошо управляется с числами. Они умеют очень быстро выполнять заданные операции. В этом вопросе они намного лучше и надежнее, чем мы. Мы же в свою очередь способны критически мыслить. Мы можем мыслить творчески. Мы можем запрограммировать эти машины. Мы можем сказать им, что делать и как.
Я назначил разработчика главным героем в этой драме. Я намеренно отказался от слова “кодер”. Разработчик — это любой человек, который работает над проектом разработки софта. Он может быть программистом, тестировщиком, гуру операций или scrum-мастером — это всё не важно. Я помещаю всех этих людей в группу под названием разработчик. В результате своей работы они должны разместить некий код в репозиторий. Пока его там нет, его будто бы и не существует. Не важно, располагается ли он на вашем компьютере, в ноутбуке, на столе или на маленьком кусочке бумаги, прикрепленном к почтовому голубю. С точки зрения системы этот код не существует, до тех пор пока он не попадет в репозиторий. Я надеюсь, что этот репозиторий Git, но, по идее, это может быть любое место, где вы можете хранить что-нибудь и отслеживать версии.
Этот репозиторий также входит в область ответственности человека. Хоть это и софт, он принадлежит нам. Мы работаем с ним. Мы обновляем код, скачиваем его из репозитория, сливаем его части воедино и иногда приходим в ужас от числа конфликтов. Но нельзя сделать вывод о том, что совсем не бывает автоматизированных операций, ни о том, что некоторые области машинной ответственности не требуют человеческого вмешательства. И всё же если в какой-то области большая часть задач выполняется вручную, мы будем считать ее областью человеческой ответственности. Репозиторий кода определённо является частью системы, которая требует человеческого вмешательства.
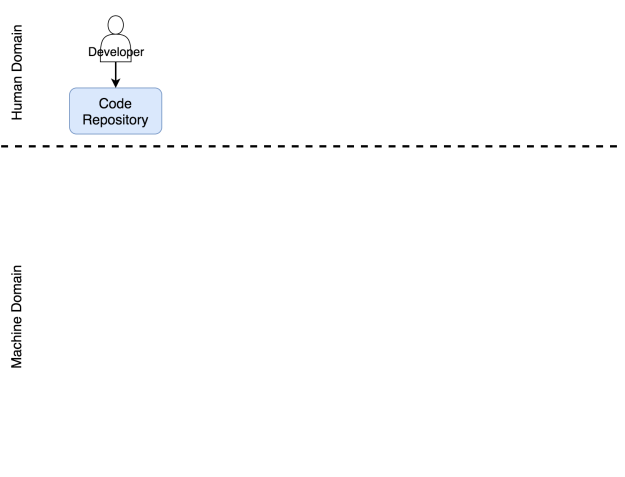
Разработчик отправляет код в репозиторий
Посмотрим, что происходит, когда код отправляется в репозиторий.
Роль непрерывного развертывания в системе
Процесс непрерывного развертывания полностью автоматизирован. Никаких исключений. Если ваша система не автоматизирована, то у вас нет непрерывного развертывания. Возможно, вам понадобится вручную деплоить в продакшн. Если вы вручную нажимаете на одну единственную кнопку, на которой жирным написано “deploy”, то ваш процесс является непрерывной доставкой. Такое я могу понять. Такая кнопка может потребоваться с точки зрения бизнеса. И все же уровень автоматизации в таком случае такой же, как и при непрерывном развертывании. Вы здесь только принимаете решения. Если требуется делать что-то еще вручную, то вы либо выполняете непрерывную интеграцию, либо, что более вероятно, делаете что-то такое, в чьем названии нет слова “непрерывный”.
Неважно, идет ли речь о непрерывном развертывании или доставке, процесс должен быть полностью автоматизированным. Все ручные действия можно оправдать только тем, что у вас устаревшая система, которую ваша организация предпочитает не трогать (обычно это приложение на Коболе). Она просто стоит на сервере что-то делает. Мне очень нравятся правила типа “никто не знает, что она делает, поэтому ее лучше не трогать”. Это способ выразить величайшее уважение, сохраняя безопасное расстояние. И все же я предположу, что это не ваш случай. Вы хотите что-нибудь с ней сделать, желание буквально раздирает вас на кусочки. Если же это не так и вам не повезло работать с системой аля “руки прочь отсюда”, то вам не стоит читать эту статью, я удивлён, что вы не поняли этого раньше сами.
Как только репозиторий получает commit или pull request, срабатывает Web hook, который в свою очередь отправляет запрос инструменту непрерывного развертывания для запуска процесса непрерывного развертывания. В нашем случае этим инструментом является Jenkins. Запрос запускает поток всевозможных задач по непрерывному развертыванию. Он проверяет код и проводит модульные тесты. Он создает образ и пушит в регистр. Он запускает функциональные, интеграционные, нагрузочные и другие тесты — те, которым требуется рабочий сервис. В самом конце процесса (не считая тестов) отправляется запрос планировщику, чтобы тот развернул или обновил сервис в кластере. Среди прочих планировщиков мы выбираем Docker Swarm.

Развертывание сервиса через Jenkins
Одновременно с непрерывным развертыванием работает еще другой набор процессов, которые следят за обновлениями конфигураций системы.
Роль конфигурации сервисов в системе
Какой бы элемент кластера ни поменялся, нужно заново конфигурировать какие-то части системы. Может потребоваться обновить конфигурацию прокси, сборщику метрик могут быть нужны новые цели, анализатору логов — обновить правила.
Не важно, какие части системы нужно поменять, главное — все эти изменения должны применяться автоматически. Мало кто будет с этим спорить. Но вот есть большой вопрос: где же найти те части информации, которые следует внедрить в систему? Самым оптимальным местом является сам сервис. Т.к. почти все планировщики используют Docker, логичнее всего хранить информации о сервисе в самом сервисе в виде лейблов. Если мы разместим эту информацию в любом другом месте, то мы лишимся единого правдивого источника и станет очень сложно выполнять авто-обнаружение.
Если информация о сервисе находится внутри него, это не означает, что эту же информацию не следует размещать в других местах внутри кластера. Следует. Однако, сервис — это то место, где должна быть первичная информация, и с этого момента она должна передаваться в другие сервисы. С Docker-ом это очень просто. У него уже есть API, к которому любой может подсоединиться и получить информацию о любом сервисе.
Есть хороший инструмент, который находит информацию о сервисе и распространяет ее по всей системе, — это Docker Flow Swarm Listener (DFSL). Можете воспользоваться любым другим решением или создать свое собственное. Конечная цель этого и любого другого такого инструмента — прослушивать события Docker Swarm. Если у сервиса есть особый набор ярлыков, приложение получит информацию, как только вы установите или обновите сервис. После чего оно передаст эту информацию всем заинтересованным сторонам. В данном случае это Docker Flow Proxy (DFP, внутри которого есть HAProxy) и Docker Flow Monitor (DFM, внутри есть Prometheus). В результате у обоих всегда будет последняя актуальная конфигурация. У Proxy есть путь ко всем публичным сервисам, тогда как у Prometheus есть информация об экспортерах, оповещениях, адресе Alertmanager-а и других вещах.
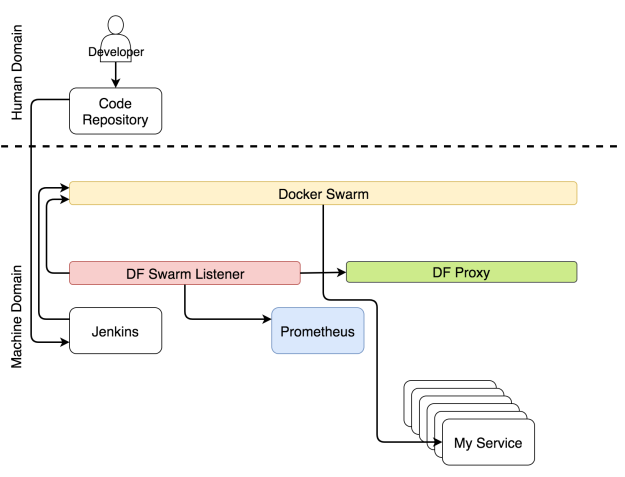
Реконфигурация системы через Docker Flow Swarm Listener
Пока идет развертывание и реконфигурация, пользователи должны иметь доступ к нашим сервисам без простоев.
Роль Proxy в системе
У каждого кластера должен быть прокси, который будет принимать запросы от единого порта и перенаправлять их в назначенные сервисы. Единственным исключением из правила будет публичный сервис. Для такого сервиса под вопросом будет не только необходимость прокси, но и кластера вообще. Когда запрос приходит в прокси, он оценивается и в зависимости от его пути, домена и некоторых заголовков перенаправляется в один из сервисов.
Благодаря Docker-у некоторые аспекты прокси теперь устарели. Больше не нужно балансировать нагрузку. Сеть Docker Overlay делает это за нас. Больше не нужно поддерживать IP-ноды, на которых хостятся сервисы. Service discovery делает это за нас. Все, что требуется от прокси, — это оценить заголовки и переправить запросы, куда следует.
Поскольку Docker Swarm всегда использует скользящие обновления, когда изменяется какой-либо аспект сервиса, процесс непрерывного развертывания не должен становиться причиной простоя. Чтобы это утверждение было верным, должны выполняться несколько требований. Должно быть запущено по крайней мере две реплики сервиса, а лучше еще больше. Иначе, если реплика будет только одна, простой неизбежен. На минуту, секунду или миллисекунду — неважно.
Простой не всегда становится причиной катастрофы. Все зависит от типа сервиса. Когда обновляется Prometheus, от простоя никуда не деться, потому что программа не умеет масштабироваться. Но этот сервис нельзя назвать публичным, если только у вас не несколько операторов. Несколько секунд простоя никому не навредят.
Совсем другое дело — публичный сервис вроде крупного интернет-магазина с тысячами или даже миллионами пользователей. Если такой сервис приляжет, то он быстро потеряет свою репутацию. Мы, потребители, так избалованы, что даже один-единственный сбой заставит нас поменять свою точку зрения и пойти искать замену. Если этот сбой будет повторяться снова и снова, потеря бизнеса практически гарантирована. У непрерывного развертывания много плюсов, но так как к нему прибегают довольно часто, становится все больше потенциальных проблем, и простой — одна из них. В самом деле, нельзя допускать простоя в одну секунду, если он повторяется несколько раз за день.
Есть и хорошие новости: если объединить rolling updates и множественные реплики, то можно избежать простоя, при условии, что прокси всегда будет последней версии.
Если объединить повторяющиеся обновления с прокси, который динамически перенастраивает сам себя, то мы получим ситуацию, когда пользователь может в любой момент отправить запрос сервису и на него не будет влиять ни непрерывное развертывание, ни сбой, ни какие-либо другие изменения состояния кластера. Когда пользователь отправляет запрос домену, этот запрос проникает в кластер через любую работающую ноду, и его перехватывает сеть Ingress Docker-а. Сеть в свою очередь определяет, что запрос использует порт, на котором слушает прокси и перенаправляет его туда. Прокси, с другой стороны, оценивает путь, домен и другие аспекты запроса и перенаправляет его в назначенный сервис.
Мы используем Docker Flow Proxy (DFP), который добавляет нужный уровень динамизма поверх HAProxy.
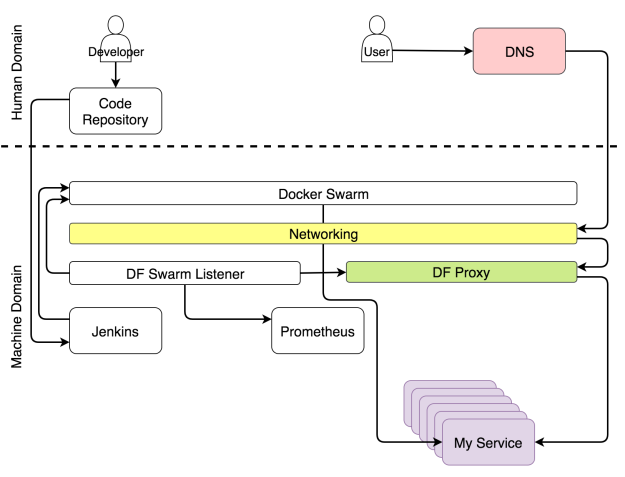
Путь запроса к назначенному сервису
Следующая роль, которую мы обсудим, связана со сбором метрик.
Роль метрик в системе
Данные — ключевая часть любого кластера, особенно того, который нацелен на самоадаптацию. Вряд ли кто-то оспорит, что нужны и прошлые, и нынешние метрики. Случись что, без них мы будем бегать как тот петух по двору, которому повар отрубил голову. Главный вопрос не в том, нужны ли они, а в том, что с ними делать. Обычно операторы бесконечными часами пялятся на монитор. Такой подход далек от эффективности. Взгляните лучше на Netflix. Они хотя бы подходят к вопросу весело. Система должна использовать метрики. Система генерирует их, собирает и принимает решения о том, какие действия предпринять, когда эти метрики достигают неких порогов. Только тогда систему можно назвать самоадаптирующейся. Только когда она действует без человеческого вмешательства, они самодостаточна.
Самоадаптирующейся системе надо собирать данные, хранить их и применять к ним разные действия. Не будем обсуждать, что лучше — отправка данных или их сбор. Но поскольку мы используем Prometheus для хранения и оценки данных, а также для генерации оповещений, то мы будем собирать данные. Эти данные доступны от экспортеров. Они могут быть общими (например, Node Exporter, cAdvisor и т.д.) или специфичными по отношению к сервису. В последнем случае сервисы должны выдавать метрики в простом формате, который ожидает Prometheus.
Независимо от потоков, которые мы описали выше, экспортеры выдают разные типы метрик. Prometheus периодически собирает их и сохраняет в базе данных. Помимо сбора метрик, Prometheus также постоянно оценивает пороги, заданные алертами, и если система достигает какого-то из них, данные передаются в Alertmanager. В большинстве случаев эти пределы достигаются при изменении условий (например, увеличилась нагрузка системы).
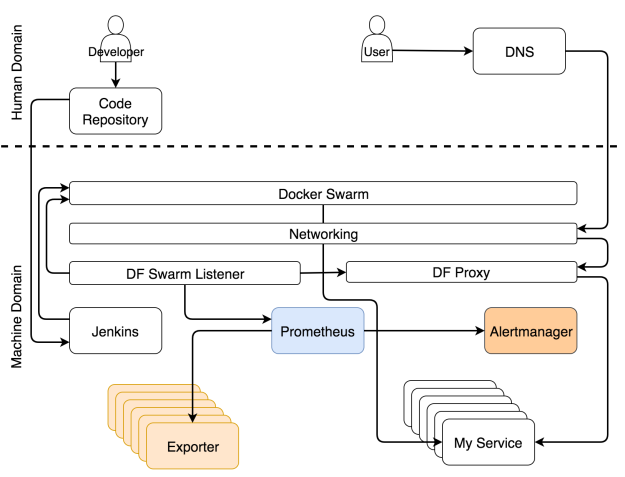
Сбор данных и оповещений
Роль оповещений в системе
Оповещения разделяются на две основные группы в зависимости от того, кто их получает — система или человек. Когда оповещение оценивается как системное, запрос обычно направляется сервису, который способен оценить ситуацию и выполнить задачи, которые подготовят систему. В нашем случае это Jenkins, который выполняет одну из предопределенных задач.
В самые частые задачи, которые выполняет Jenkins, обычно входит масштабировать (или демасштабировать) сервис. Впрочем, прежде чем он предпримет попытку масштабировать, ему нужно узнать текущее количество реплик и сравнить их с высшим и низшим пределом, которые мы задали при помощи ярлыков. Если по итогам масштабирования число реплик будет выходить за эти пределы, он отправит уведомление в Slack, чтобы человек принял решение, какие действия надо предпринять, чтобы решить проблему. С другой стороны, когда поддерживает число реплик в заданных пределах, Jenkins отправляет запрос одному из Swarm-менеджеров, который, в свою очередь, увеличивает (или уменьшает) число реплик в сервисе. Это процесс называется самоадаптацией, потому что система адаптируется к изменениям без человеческого вмешательства.
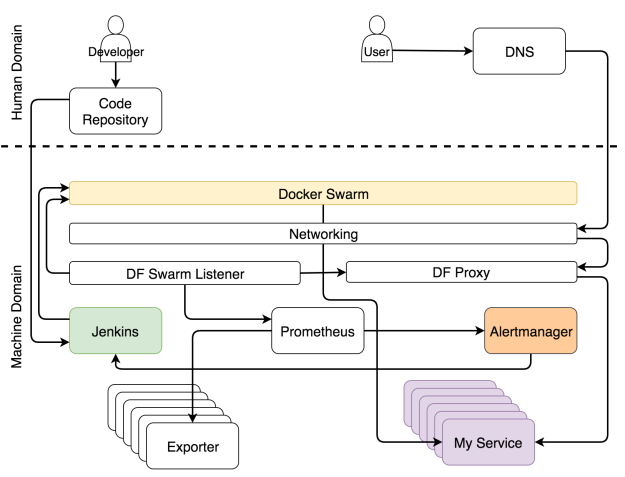
Уведомление системы для самоадаптации
Хоть и нашей целью является полностью автономная система, в некоторых случая без человека не обойтись. По сути, это такие случаи, которые невозможно предвидеть. Когда случается что-то, что мы ожидали, пусть система устранит ошибку. Человека надо звать, только когда случаются неожиданности. В таких случаях Alertmanager шлет уведомление человеку. В нашем варианте это уведомление через Slack, но по идее это может быть любой другой сервис для передачи сообщений.
Когда вы начинаете проектировать самовосстанавливающуюся систему, большинство оповещений попадут в категорию “неожиданное”. Вы не можете предугадать все ситуации. Единственное, что вы можете в данном случае — это убедиться, что неожиданное случается только один раз. Когда вы получаете уведомление, ваша первая задача — адаптировать систему вручную. Вторая — улучшить правила в Alertmanager и Jenkins, чтобы когда ситуация повторится, система могла бы справиться с ней автоматически.
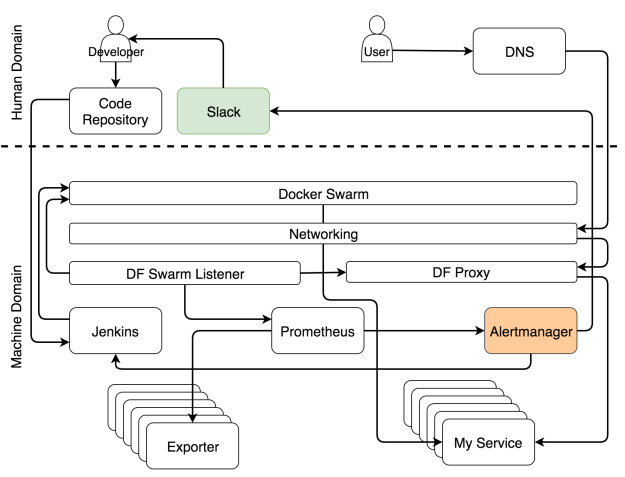
Уведомление для человека, когда случается что-то неожиданное
Настроить самоадаптирующуюся систему тяжело, и эта работа бесконечная. Ее постоянно нужно улучшать. А как насчет самовосстановления? Так ли сложно достичь и его?
Роль планировщика в системе
В отличие от самоадаптации, самовосстановления достичь сравнительно легко. Пока в наличии достаточно ресурсов, планировщик всегда будет следить, чтобы работало определенное число реплик. В нашем случае это планировщик Docker Swarm.
Реплики могут выходить из строя, они могут быть убиты и они могут находиться внутри нездорового нода. Это все не так важно, поскольку Swarm следит за тем, чтобы они перезапускались при необходимости и (почти) всегда нормально работали. Если все наши сервисы масштабируемы и на каждом из них запущено хотя бы несколько реплик, простоя никогда не будет. Процессы самовосстановления внутри Docker-а сделают процессы самоадаптации легко доступными. Именно комбинация этих двух элементов делает нашу систему полностью автономной и самодостаточной.
Проблемы начинают накапливаться, когда сервис нельзя масштабировать. Если у нас не может быть нескольких реплик сервиса, Swarm не сможет гарантировать отсутствие простоев. Если реплика выйдет из строя, она будет перезапущена. Впрочем, если это единственная доступная реплика, период между аварией и повторным запуском превращается в простой. У людей все точно так же. Мы заболеваем, лежим в постели и через какое-то время возвращаемся на работу. Если мы единственный работник в этой компании и нас некому подменить, пока мы отсутствуем, то это проблема. То же применимо и к сервисам. Для сервиса, который хочет избежать простоев, необходимо как минимум иметь две реплики.
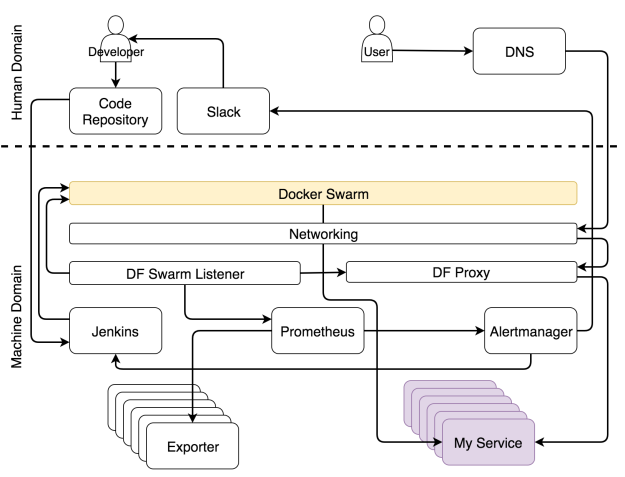
Docker Swarm следит, чтобы не было простоев
К сожалению, наши сервисы не всегда проектируются с учетом масштабируемости. Но даже когда она учитывается, всегда есть шанс, что ее нет у какого-то из сторонних сервисов, которыми вы пользуетесь. Масштабируемость — это важное проектное решение, и мы обязательно должны учитывать это требование, когда мы выбираем какой-то новый инструмент. Надо четко различать сервисы, для которых простой недопустим, и сервисы, которые не подвергнут систему риску, если они будут недоступны в течение нескольких секунд. Как только вы научитесь их различать, вы всегда будете знать, какие из сервисов масштабируемы. Масштабируемость — это требование беспростойных сервисов.
Роль кластера в системе
В конце концов все, что мы делаем, находится внутри одного и более кластеров. Больше не существует индивидуальных серверов. Не мы решаем, что куда направить. Это делают планировщики. С нашей (человеческой) точки зрения самый маленький объект — это кластер, в котором собраны ресурсы типа памяти и CPU.
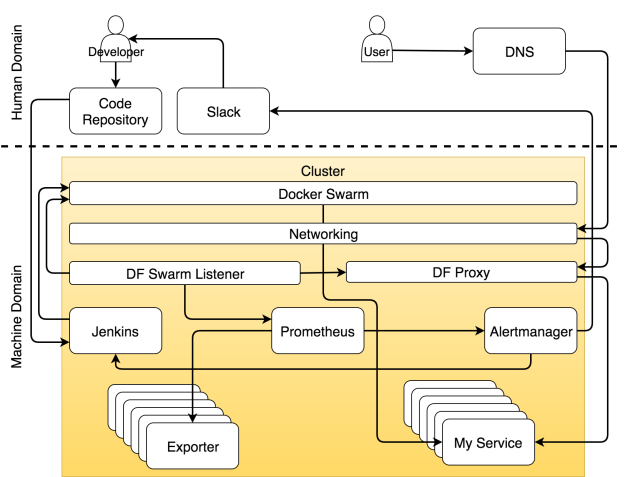
Все является кластером
Комментарии (17)
dmitry_ch
12.08.2017 08:53Так может все же Kubernetes?
r-moiseev Автор
12.08.2017 11:10Что пропадет из схемы при замене Swarm на Kubernetes. Ну кроме очевидного прокси.
dmitry_ch
12.08.2017 12:38Кубер как бы из коробки (если это можно назвать так) умеет и проверку живости сервисов, и несет понятие pod-а (когда на хосте рядом будут жить связанные сервисы). Кошку-то готовить надо уметь, причем там есть шутка в том, что не всякий кубер со всяким докером будут жить душа в душе (Докер уж очень от версии к версии меняется).
Но Swarm-у я бы меньше верил, именно из-за «милой» привычки авторов все ломать на каждой новой версии. У поста по ссылке есть продолжение.r-moiseev Автор
12.08.2017 12:53Если вы про health check то он есть в самом докере из коробки.
И все же я уточню вопрос. Как kubernetes из коробки решает вопрос мониторинга (не просто жив мертв) и авто скейлинга?
dmitry_ch
12.08.2017 12:57Из коробки и решает. Это не просто health check, это именно liveness (и не только http, конечно).
Из доки навскидку примерapiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-http spec: containers: - name: liveness args: - /server image: gcr.io/google_containers/liveness livenessProbe: httpGet: path: /healthz port: 8080 httpHeaders: - name: X-Custom-Header value: Awesome initialDelaySeconds: 3 periodSeconds: 3r-moiseev Автор
12.08.2017 13:09А я то спросил про мониторинг. Вот у меня пошел трафик, сервис загибается, как узнать и поднять доп реплики?

kiltum
12.08.2017 09:11+2Красиво, но без примеров/кусков кода/настроек выглядит как попытка обкатать идею на сообществе
r-moiseev Автор
12.08.2017 11:06Это ведь перевод… но мне теперь самому интересно это все реализовать.
kiltum
12.08.2017 13:51Упс, не заметил. Тогда вопрос снимается. Что касается реализации… не верю. На мой взгляд, слишком все тяжеловесное и не согласованное. Например jenkins и докер — неповоротливый тяжеловес и легкий попрыгунчик.

lexore
12.08.2017 18:33+1Хорошая статья, только режет глаз придуманное самим автором определение:
Самодостаточная система — это та, которая способна восстанавливаться и адаптироваться.
К переводчику претензий нет, просто в статье все-же описана self-sustaining system (самоподдерживающаяся система), а не self-sufficient (самодостаточная).
r-moiseev Автор
12.08.2017 18:39Да, это правда. Я тоже долго думал как перевести, и в итоге решил оставить оригинал

AndreyNagih
13.08.2017 15:58+1(юмор) Самодостаточной системе разработчик не нужен. И пользователь тоже. :-)

Hixon10
Спасибо за статью!
А можете немного подробнее рассказать про авто-масштабирования сервисов? Используете какие-то хитрые алгоритмы, ML? Или там какие-то базвоые эвристики?
r-moiseev Автор
В общем то никаких хитрых алгоритмов, стоит триггер на повышенную нагрузку в течении 30 секунд. При срабатывании триггера запускаем дополнительные инстансы. При падении нагрузки обратный порядок действий.
Лично не приходилось сталкиваться с ситуациями когда этого не достаточно.