
В нашем блоге мы уже рассказывали о принципах организации репозитория большого проекта как совокупности независимых модулей, что позволяет организовать извлечение исходных кодов в произвольную файловую структуру рабочей копии. Разумеется, такой подход не мог не отразиться на системе сборки проекта, поскольку потребовал создание механизма отслеживания зависимостей между модулями с учетом их фактического размещения. Эта статья посвящена тому, как можно использовать возможности git-а для решения не только этой задачи, но и для извлечения фрагмента проекта с автоматическим учетом внутренних межмодульных зависимостей.

Изначально предполагалось снабдить эту публикацию фрагментами системы сборки в том виде, как она реализована в ЛИНТЕРе, однако мы не используем в этом проекте нативные модули git и применяем make утилиту собственной разработки. Поэтому, чтобы практическая ценность материала для читателей не пострадала, все примеры адаптированы для использования в связке git submodules и gnu make, что привело к определенным сложностям, которые будут указаны ниже.
В целях упрощения будем рассматривать интеграцию системы сборки с git-ом на примере условного продукта с названием project, который состоит из следующих функциональных модулей:
applications — непосредственно приложение;
demo — демонстрационные примеры;
libfoo и libbar — библиотеки, от которых зависит applications.
Граф зависимостей project будет следующим:
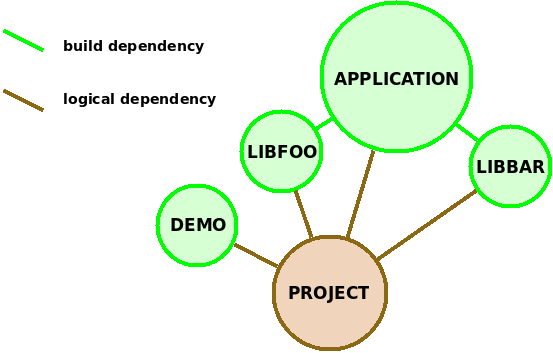
Иллюстрация 1: Граф зависимостей проекта
С точки зрения системы хранения версий проект разбит на пять отдельных репозиториев — четыре для модулей и пятый — project.git, выполняющий роль контейнера и содержащий систему сборки. Такой способ организации имеет несколько преимуществ в сравнении с монорепозиторием:
Несмотря на то, что рекурсивный подход к организации системы сборки оправданно критикуется, все-таки он позволяет существенно снизить затраты на сопровождение проекта, поэтому в нашем примере будем применять именно его. При этом, корневой makefile проекта должен не только «знать» положение модулей внутри проекта, но и обеспечивать вызов дочерних make-процессов в целях в нужной последовательности: от ветвей дерева зависимости к корням. Для этого следует явно описать эти межмодульные зависимости, в нашем примере это сделано следующим образом:
Корректный обход этого дерева можно обеспечить средствами make, создав динамические цели с явным указанием зависимостей, для чего объявим функцию gen-dep следующего вида:
Теперь, если в теле корневого Makefile вызвать gen-dep для всех модулей
то это сформирует следующие динамические цели во время исполнения (это можно проверить запустив make с ключом -p)
что позволяет при обращении к ним обеспечить вызов зависимостей в нужном порядке. При этом, если имя цели совпадет с существующим файлом или директорией, то это может нарушить выполнение, поскольку make «не знает» что эти наши цели — это действия, а не файлы, чтобы этого избежать явно укажем:
Допустим, что перед разработчиком стоит задача внесения изменений в application, для чего ему нужно получить только подмодули application, libbar, libfoo. Для этого система сборки должна на основе объявленных выше зависимостей сформировать описание модулей и их размещения для последующего использования git-ом, который, как известно, описывает зарегистрированные подмодули в файле с именем .gitmodules, расположенном в корне клонированного репозитория.
Внесем следующие изменения в наш пример, чтобы обеспечить генерацию .gitmodules минимального необходимого состава:
Теперь наш условный разработчик, вызвав make application сможет создать файл следующего содержания:
который уже может быть изменен и разобран средствами git-a, например таким образом:
Само по себе наличие файла .gitmodules в корне репозитория не регистрирует модули в индексе, поэтому до момента инициализации и клонирования подмодулей в файл можно внести все необходимые корректировки.
Что же касается непосредственно инициализации подмодулей — то тут проявляется первое серьезное неудобство в реализации нативных модулей в git-е: метаданные о модулях эта система управления версиями хранит и в индексе, и в файле .gitmodules. Заглянув в исходные коды становится понятным, что у нас есть две не самые лучшие альтернативы.
Первая — это внести информацию о модулях в индекс следующим образом:
в этом случае появляется возможность работать с подмодулями используя штатный git-submodule (итераторы, групповые операции и пр.), однако перемещение/удаление модулей, а также их ветвление будет требовать дополнительных вспомогательных операций. Описанная ситуация стала одной из причин, по которой мы отказались от использования git-submodules в репозитории ЛИНТЕРа. Альтернативой submodule add может служить клонирование модулей без регистрации в индексе, что можно сделать так:
в этом случае обязательно требуется явное указание всех $path в .gitignore, иначе git будет воспринимать клонированные подмодули как обычные директории и обрабатывать их и содержимое как неотслеживаемые файлы.
Так или иначе, после клонирования любым из указанных способов рабочая копия будет соответствовать ситуации извлечения выделенного фрагмента дерева
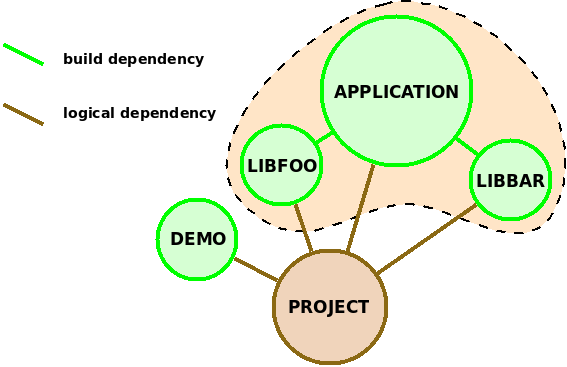
Иллюстрация 2: Граф зависимостей проекта. Заливкой выделено извлекаемое дерево модулей.
и, при условии правильного объявления межмодульных зависимостей, содержит все необходимое для компиляции application.
Еще одну задачу, которую решает система сборки — это определение текущего положения модулей. Для этого будем использовать сформированный нами ранее файл-описатель. Как и в случае с инициализацией — здесь есть несколько вариантов. Самое простое — это воспользоваться возможностями git config:
Такое решение не является идеальным с точки зрения переносимости, но другой вариант доступен только если использовать GNU make версии 4 и выше — в этом случае парсинг файла .gitmodules можно реализовать с использованием расширений GNU make.
Позволим себе еще раз напомнить, что пример доступный на github является адаптацией наших решений на базе связки linmodules+linflow для gitmodules+GNU make, поэтому некоторые недостатки сопряжения этих инструментов решены не самым изящным способом, а вызовы дочерних make файлов в модулях заменены на «пустышки».

Тем не менее, механизм зарекомендовал себя достаточно хорошо при работе с большим проектом и успешно «справляется» с репозиторием в 102 подмодуля git, между которыми существует 308 межмодульных связей (как логических, так и по сборке) с диаметром графа связей в 5 единиц (см. иллюстрацию выше).
Несколько слов о примерах
Изначально предполагалось снабдить эту публикацию фрагментами системы сборки в том виде, как она реализована в ЛИНТЕРе, однако мы не используем в этом проекте нативные модули git и применяем make утилиту собственной разработки. Поэтому, чтобы практическая ценность материала для читателей не пострадала, все примеры адаптированы для использования в связке git submodules и gnu make, что привело к определенным сложностям, которые будут указаны ниже.
Описание демонстрационного примера
В целях упрощения будем рассматривать интеграцию системы сборки с git-ом на примере условного продукта с названием project, который состоит из следующих функциональных модулей:
applications — непосредственно приложение;
demo — демонстрационные примеры;
libfoo и libbar — библиотеки, от которых зависит applications.
Граф зависимостей project будет следующим:
Иллюстрация 1: Граф зависимостей проекта
Организация хранения
С точки зрения системы хранения версий проект разбит на пять отдельных репозиториев — четыре для модулей и пятый — project.git, выполняющий роль контейнера и содержащий систему сборки. Такой способ организации имеет несколько преимуществ в сравнении с монорепозиторием:
- каждый подмодуль имеет отдельную историю правок;
- возможность клонирования только части проекта;
- каждый репозиторий может иметь индивидуальные правила и политики доступа;
- возможность извлечения проекта в произвольную структуру рабочей копии.
Подмодули и зависимости
Несмотря на то, что рекурсивный подход к организации системы сборки оправданно критикуется, все-таки он позволяет существенно снизить затраты на сопровождение проекта, поэтому в нашем примере будем применять именно его. При этом, корневой makefile проекта должен не только «знать» положение модулей внутри проекта, но и обеспечивать вызов дочерних make-процессов в целях в нужной последовательности: от ветвей дерева зависимости к корням. Для этого следует явно описать эти межмодульные зависимости, в нашем примере это сделано следующим образом:
MODS = project application libfoo libbar demo
submodule.project.deps = application demo
submodule.demo.deps = application
submodule.application.deps = libfoo libbar
submodule.libfoo.deps =
submodule.libbar.deps =Корректный обход этого дерева можно обеспечить средствами make, создав динамические цели с явным указанием зависимостей, для чего объявим функцию gen-dep следующего вида:
define gen-dep
$(1):$(foreach dep,$(submodule.$(1).deps),$(dep)) ;
endef Теперь, если в теле корневого Makefile вызвать gen-dep для всех модулей
$(foreach mod,$(MODS),$(eval $(call gen-dep,$(mod))))то это сформирует следующие динамические цели во время исполнения (это можно проверить запустив make с ключом -p)
project: application demo
demo: application
application: libfoo libbar
libbar:
libfoo: что позволяет при обращении к ним обеспечить вызов зависимостей в нужном порядке. При этом, если имя цели совпадет с существующим файлом или директорией, то это может нарушить выполнение, поскольку make «не знает» что эти наши цели — это действия, а не файлы, чтобы этого избежать явно укажем:
$(eval .PHONY: $(foreach mod,$(MODS), $(mod)))Допустим, что перед разработчиком стоит задача внесения изменений в application, для чего ему нужно получить только подмодули application, libbar, libfoo. Для этого система сборки должна на основе объявленных выше зависимостей сформировать описание модулей и их размещения для последующего использования git-ом, который, как известно, описывает зарегистрированные подмодули в файле с именем .gitmodules, расположенном в корне клонированного репозитория.
Внесем следующие изменения в наш пример, чтобы обеспечить генерацию .gitmodules минимального необходимого состава:
…
MODURLPREFIX ?= git@git-common.relex.ru/
MODFILE ?= .gitmodules
…
define tmpl.module
"[submodule \"$(1)\"]"
endef
define tmpl.path
"\tpath = $(1)"
endef
define tmpl.url
"\turl = $(1)"
endef
…
define submodule-set
submodule.$(1).name := $(2)
submodule.$(1).path := $(3)
submodule.$(1).url := $(4)
endef
define set-default
$(call submodule-set,$(1),$(1),$(1),$(MODURLPREFIX)$(1).git)
endef
define gen-dep
$(1):$(foreach dep,$(submodule.$(1).deps),$(dep))
@echo "Register module $(1)"
@echo $(call tmpl.module,$(submodule.$(1).name)) >> $(MODFILE)
@echo $(call tmpl.path,$(submodule.$(1).path)) >> $(MODFILE)
@echo $(call tmpl.url,$(submodule.$(1).url)) >> $(MODFILE)
endef
…
$(foreach mod,$(MODS),$(eval $(call set-default,$(mod))))Теперь наш условный разработчик, вызвав make application сможет создать файл следующего содержания:
[submodule "libfoo"]
path = libfoo
url = git@git-common.relex.ru/libfoo.git
[submodule "libbar"]
path = libbar
url = git@git-common.relex.ru/libbar.git
[submodule "application"]
path = application
url = git@git-common.relex.ru/application.gitкоторый уже может быть изменен и разобран средствами git-a, например таким образом:
git config -f .gitmodules --get submodule.application.path
applicationСамо по себе наличие файла .gitmodules в корне репозитория не регистрирует модули в индексе, поэтому до момента инициализации и клонирования подмодулей в файл можно внести все необходимые корректировки.
Что же касается непосредственно инициализации подмодулей — то тут проявляется первое серьезное неудобство в реализации нативных модулей в git-е: метаданные о модулях эта система управления версиями хранит и в индексе, и в файле .gitmodules. Заглянув в исходные коды становится понятным, что у нас есть две не самые лучшие альтернативы.
Первая — это внести информацию о модулях в индекс следующим образом:
#!/bin/sh
git config -f .gitmodules --get-regexp '^submodule\..*\.path$' |
while read path_key path
do
url_key=$(echo $path_key | sed 's/\.path/.url/')
url=$(git config -f .gitmodules --get "$url_key")
git submodule add --force $url $path
doneв этом случае появляется возможность работать с подмодулями используя штатный git-submodule (итераторы, групповые операции и пр.), однако перемещение/удаление модулей, а также их ветвление будет требовать дополнительных вспомогательных операций. Описанная ситуация стала одной из причин, по которой мы отказались от использования git-submodules в репозитории ЛИНТЕРа. Альтернативой submodule add может служить клонирование модулей без регистрации в индексе, что можно сделать так:
#!/bin/sh
git config -f .gitmodules --get-regexp '^submodule\..*\.path$' |
while read path_key path
do
url_key=$(echo $path_key | sed 's/\.path/.url/')
url=$(git config -f .gitmodules --get "$url_key")
git clone $url $path
doneв этом случае обязательно требуется явное указание всех $path в .gitignore, иначе git будет воспринимать клонированные подмодули как обычные директории и обрабатывать их и содержимое как неотслеживаемые файлы.
Так или иначе, после клонирования любым из указанных способов рабочая копия будет соответствовать ситуации извлечения выделенного фрагмента дерева
Иллюстрация 2: Граф зависимостей проекта. Заливкой выделено извлекаемое дерево модулей.
и, при условии правильного объявления межмодульных зависимостей, содержит все необходимое для компиляции application.
Определение положения модулей
Еще одну задачу, которую решает система сборки — это определение текущего положения модулей. Для этого будем использовать сформированный нами ранее файл-описатель. Как и в случае с инициализацией — здесь есть несколько вариантов. Самое простое — это воспользоваться возможностями git config:
define get-path
$(shell git config -f .gitmodules --get "submodule.$(1).path")
endef
define get-url
$(shell git config -f .gitmodules --get "submodule.$(1).url")
endef Такое решение не является идеальным с точки зрения переносимости, но другой вариант доступен только если использовать GNU make версии 4 и выше — в этом случае парсинг файла .gitmodules можно реализовать с использованием расширений GNU make.
Заключение
Позволим себе еще раз напомнить, что пример доступный на github является адаптацией наших решений на базе связки linmodules+linflow для gitmodules+GNU make, поэтому некоторые недостатки сопряжения этих инструментов решены не самым изящным способом, а вызовы дочерних make файлов в модулях заменены на «пустышки».
Тем не менее, механизм зарекомендовал себя достаточно хорошо при работе с большим проектом и успешно «справляется» с репозиторием в 102 подмодуля git, между которыми существует 308 межмодульных связей (как логических, так и по сборке) с диаметром графа связей в 5 единиц (см. иллюстрацию выше).
sn00p
gitmodules и gitignore в пару мегабайт каждый — это же просто мечта какая-то.
npechenkin
Вы преувеличиваете — «в пару мегабайт» в UTF-8 вмещается первый том «Войны и мира». С gitmodules и gitignore все скромнее выходит: упомянутые 102 модуля занимают ~10,4 кб в gitmodules и 1 (один) байт в gitignore. gitignore в нашем случае такой из-за того, что модуль-контейнер не содержит ничего кроме описателя. Приведенные размеры файлов, естественно, зависят от структуры желаемой рабочей копии.
В любом случае, в процессе разработки git-овский индекс куда как быстрее прирастает, чем эти файлы.
sn00p
Да, я утрировал )
Как вы в этой схеме с бранчами работаете, кстати? Или у вас только мастер?
npechenkin
Нет, не только мастер, а еще develop плюс по три релизные ветви на каждую редакцию продукта и переменное число ветвей для hotfix-ов и фич. Предыдущая публикация как раз была этому посвящена. Если коротко, то используется модифицированная под наши реалии и подмодули «удачная модель ветвления»
Кстати, заглавная иллюстрация в предыдущей статье отображает реальную ситуацию в проекте по ветвям модулей, хотя, признаюсь, я выбрал самый «зрелищный» момент из всех возможных.