
Пару слов для начала
Итак, данный мануал подойдет для тех, кто ищет универсальный инструментарий для тестинга большого пула систем и решения большинства задач по нагрузочному тестированию. Статья рассчитана на новичков в этом деле, поэтому постараюсь максимально детализировать и упрощать процесс. Коротко обсудим каждый из элементов в нашей связке и перейдем к их первичной установке и настройке:
- Apache JMeter – инструмент для нагрузочного тестирования, который способен проводить тесты для JDBC-соединений, FTP, LDAP, SOAP, JMS, POP3, IMAP, HTTP и TCP из коробки и еще множество других протоколов и решений, используя различные плагины.
- Yandex.Tank – это облачный инструмент для нагрузочного тестирования, использует различные генераторы нагрузки, в том числе и JMeter.
- Yandex.OverLoad – сервис для удобного мониторинга и анализа серверов под нагрузкой.
Установка и настройка
Залогом успеха для правильной установки JMeter является правильная установка java. На данном этапе стоит сказать о том, что все манипуляции дальше будут происходить под ОС Linux. На официальном сайте хорошие мануалы со всеми нюансами:
С Java разобрались для контрольной проверки сделайте java -version в консоле, ответ должен быть примерно таким:

Теперь переходим к Apache JMeter. Ставить можно любую версию JMeter, но если встречаются проблемы типа “Error in NonGUIDriver” то, скорее всего, нужен танк свежей версии или можно без проблем перейти на точно рабочую 2.13. Вернемся к установке — она аналогична для всех версий:
Скачиваем клиент:
wget https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-2.13.tgz
Распаковываем:
tar -zxvf apache-jmeter-2.13.tgz
JMeter установлен и уже будет работать. Для первичной настройки достаточно будет внести только одно изменение. Идем по пути apache-jmeter-2.13/bin открываем для правки файл jmeter без расширения:
cd apache-jmeter-2.13/bin nano jmeter
Находим строку, как на скриншоте ниже. Выставляем значения heap size в соответствии с характеристиками используемого сервера. Первое значение HEAP Xms — объем оперативной памяти выделяемый процессу при его старте, а второе Xmx — максимальное значение оперативной памяти, которое будет доступно процессу.

Если сервер без GUI и доступ к нему удаленный, как в большинстве случаев, лучше поставить JMeter локально для отладки и записи скриптов. В идеале версии должны совпадать, но в большинстве случаев JMeter понимает скрипты соседних или младших версий. Конечно, на локальной машине тоже должна стоять Java и сам JMeter.
Переходим к установке и настройке Yandex.Tank, для этого достаточным должно оказаться выполнение этих действий:
sudo apt-get install python-pip build-essential python-dev libffi-dev gfortran libssl-dev sudo -H pip install --upgrade pip sudo -H pip install --upgrade setuptools sudo -H pip install https://api.github.com/repos/yandex/yandex-tank/tarball/master
Дальше следует рассказать нашему орудию куда стрелять и чем. Для этого создадим рабочую директорию на машине с танком с конфигурационным файлом load.ini:
mkdir test cd test nano load.ini
Содержимое конфигурационного файла является руководством к действиям танка, в нем необходимо отразить все ключевые моменты теста. Вот пример load.ini для теста с использованием JMeter:
Думаю, в блоке [tank] все понятно, если возникают вопросы есть описание каждого поля и блока от самих танкистов. Все самое интересное в блоке [jmeter].
Параметр jmx содержит путь непосредственно к скрипту, jmeter_path — это путь до исполнительного файла JMeter, ну и для того, чтобы танк не делал лишних движений, нужно указать версию JMeter'а в параметр jmeter_ver.
Разработка скрипта
Пришло время написать первый тест. Для этого открываем клиент JMeter - большинство Windows систем требуют запуск от имени администратора. Про то как начать осваивать JMeter, а заодно разобраться в его GUI хорошо написано в <a href="https://habrahabr.ru/post/140310/">этой статье</a>. У нас же пример с базой данных, что немного отличается от обычных http запросов. Первое отличие в том, что PostgreSQL не поддерживается в JMeter из коробки, поэтому нужно <a href="https://jdbc.postgresql.org/download.html">скачать</a> драйвер нужной версии. После чего нужно подложить скаченный .jar в директорию /lib в папке с JMeter. Этот же .jar нужно подложить по аналогичному пути на машине с танком. С драйвером разобрались переходим к скрипту.
Первое, что нужно сделать это настроить подключение к БД, для этого правой кнопкой жмем на Test Plan -> Add -> Config Element -> JDBC Connection Configuration. Дерево теста пополнится конфигурационным элементом, как на скриншоте:Перейдя на него, мы увидим много нужных полей. Тут нужно быть обратить внимание сначала на верхнюю часть:
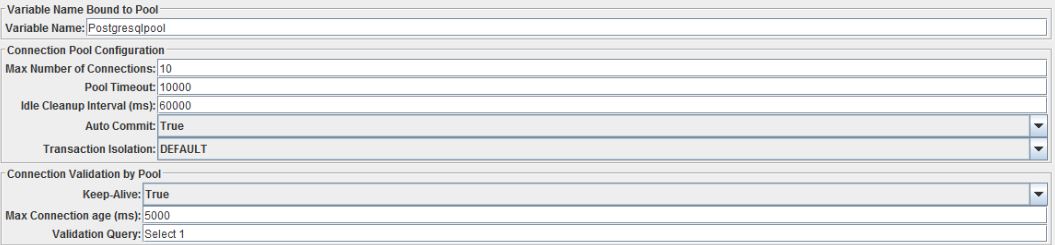
Здесь важно заполнить поле Variable Name. Это имя будет использоваться в JDBC Request (Sampler) для доступа к пулу сессий. Еще стоит обратить внимание на Max Number Of Connections, этот параметр лимитирует количество одновременных подключений к БД. Остальное в этом блоке можно оставить так как есть, если нет особых требований к таймаутам и жизненному циклу коннекта.

Переходим к блоку на скриншоте выше, тут от нас потребуется ввести данные для подключения к базе. Шаблон такой:
- Database URL: jdbc:postgresql://IPAddress:PortNo/DatabaseName?autoReconnect=true;
- JDBC Driver class: org.postgresql.Driver;
- Username: username of database;
- Password: password of database.
Приступаем к дальнейшему наполнению дерева теста. Опять нажимаем Test Plan -> Add -> Threads (Users) -> Thread Group.
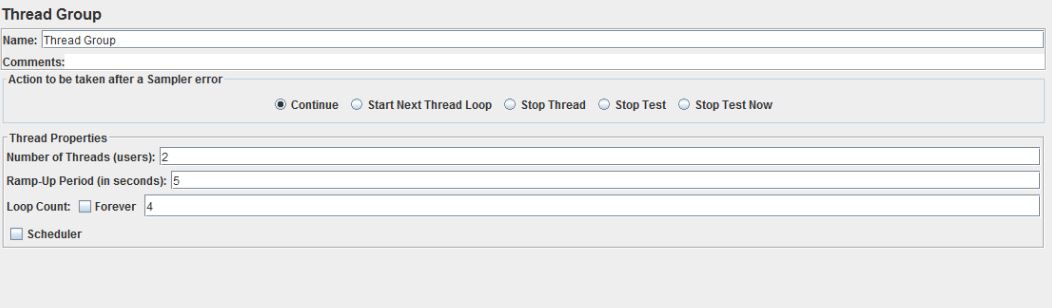
Перед нами панель управления стрельбой, именно тут вводим какое количество пользователей — Number of Threads, за какое время будет достигнуто — Ramp-Up Period и с какой интенсивностью каждый новый пользователь вместе с предыдущим будет повторять действия.Если нам необходимо максимально часто отправлять запросы ставим галочку “forever” напротив Loop Count. Для первого теста можно выставить значение в пару пользователей, с небольшим количеством повторений. Теперь переходим непосредственно к запросам в БД.
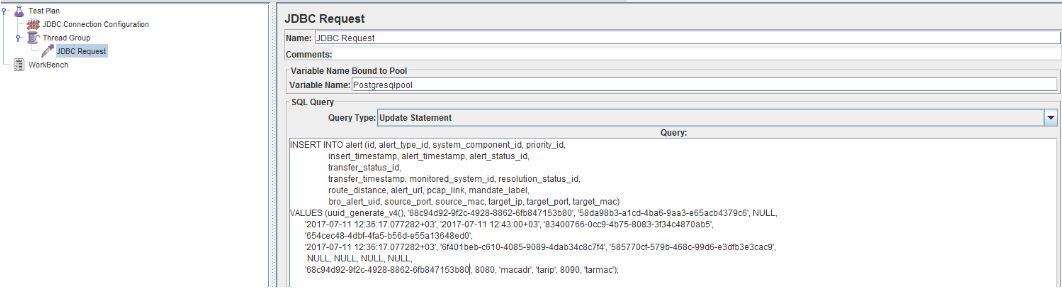
Для добавления в тест план семплера JDBC запроса нажимаем правой кнопкой на нужный нам Thread Group -> Add -> Sampler ->JDBC Request. Нас первоначально интересует поле Variable Name, оно должно совпадать с аналогичным параметром из JBDC Connection Configuration. После этого смотрим на выпадающий список Query Type, в зависимости от вашего запроса тут должно стоять соответствующее значение, например, для SELECT запроса в БД, нужно выбрать Select Statement, а для INSERT, COPY и UPDATE — Update Statement, как в нашем примере. В заключении работы с данным семплером нам необходимо задать тело запроса, которое должно соответствовать валидному SQL запросу.
В целом скрипт готов, но нам необходимо его отладить, делается это так:
- в нужный Thread Group после JDBC Request добавляем Debug Sampler. В нем будет отображаться ответ полученный после запроса к БД. Добавляется аналогично предыдущим элементам Thread Group -> Add -> Sampler -> Debug Sampler;
- для того, чтобы увидеть результаты работы того или иного семплера, в конце тест плана нам нужен мониторинг результатов — добавляется он так: Test Plan -> Add — > Listener -> View Results Tree. При запуске скрипта там будет детализация по всем выполненным запроса.
Пришло время тестового запуска пока из самого JMeter — для этого достаточно нажать

и нажать на View Results Tree. После отработки скрипта я получил следующие результаты:
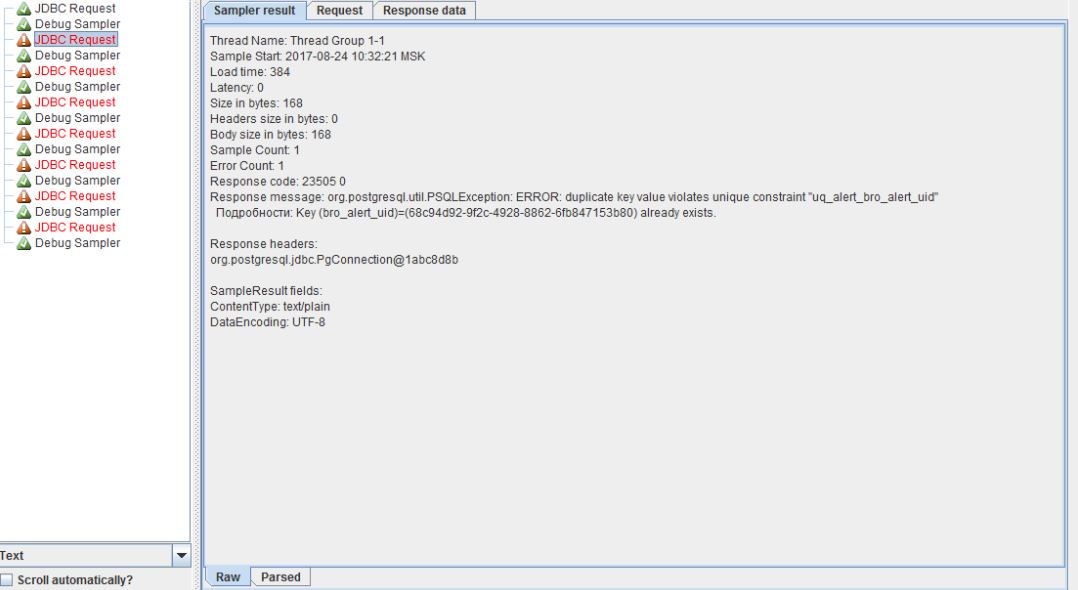
Отладка скрипта
Видим, что первый отработал успешно и смотрим на поле Response message, оно говорит о том, что поле должно быть уникальным. Значит переходим к параметризации. Есть много способов как это сделать, наиболее уникальным из них является параметризация с помощью BeanShell PreProcessor. Для этого нам нужно вставить перед нашим JDBC Request указанный выше препроцессор - Thread Group -> Add -> Pre Processors -> BeanShell PreProcessor. О препроцессорах можно почитать <a href="https://www.blazemeter.com/blog/quick-guide-jmeter-preprocessors">тут</a> или на <a href="http://jmeter.apache.org/usermanual/component_reference.html#BSF_PreProcessor_(DEPRECATED)">сайте</a> JMeter. BeanShell PreProcessor не рекомендуется использовать при больших нагрузках, как стабильный и быстрый вариант используйте JSR223 PreProcessor + Groovy. 
Тут никаких изысков — пишем на java, импортируем необходимый класс, объявляем переменную, присваиваем в нее в нее рандомную переменную нужного формата. Для того, чтобы положить полученную переменную в переменную JMeter используйте vars.put(). Теперь переходим в наш JDBC Request и добавляем вместо значения в уникальном поле переменную в формате ${needUUID}, пример на скриншоте ниже:
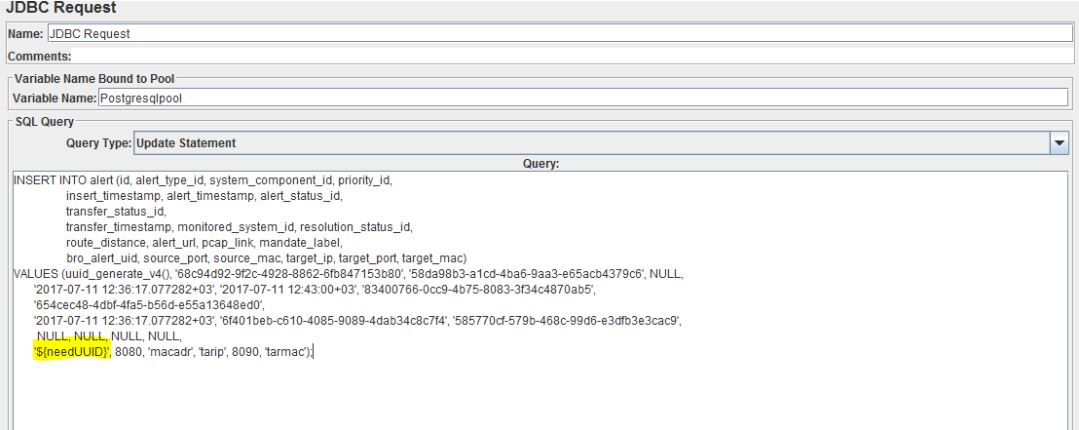
Конечная структура нашего тест плана выглядит следующим образом:
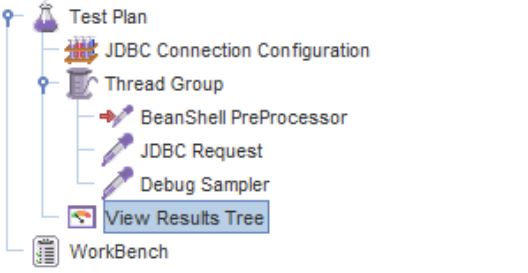
Делаем еще один запуск из JMeter, сразу смотрим на View Results Tree, выбираем Debug Sampler и встаем на вкладку Response Data:
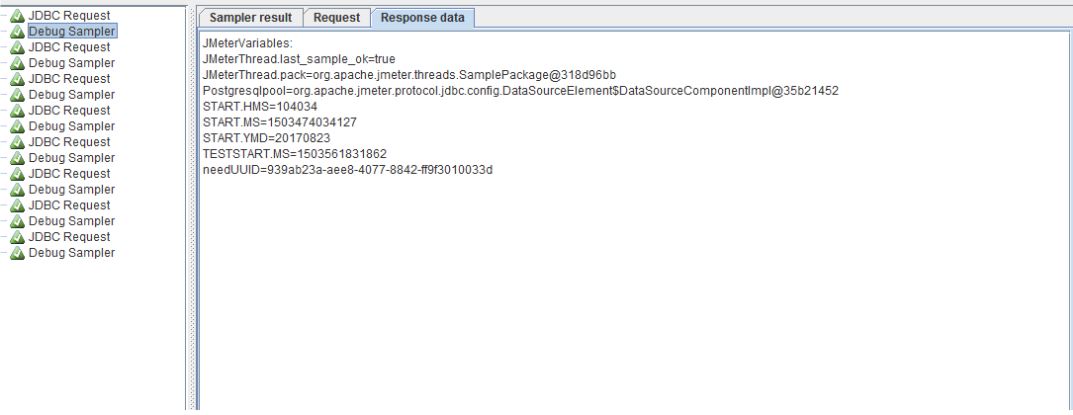
Тут можем убедиться, что наша переменная успешно сгенерировалась и для всех запросов она разная. Когда тест отлажен и готов к запуску нам необходимо убрать из него отладочные элементы, а именно Debug Sampler и View Results Tree. Делается это простым нажатием правой кнопки на элемент и выбором пункта Remove. На всякий случай прикладываю вид теста после этого:
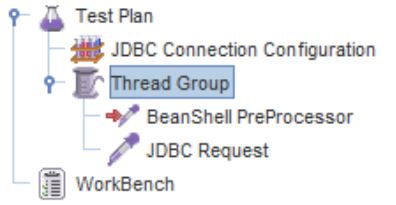
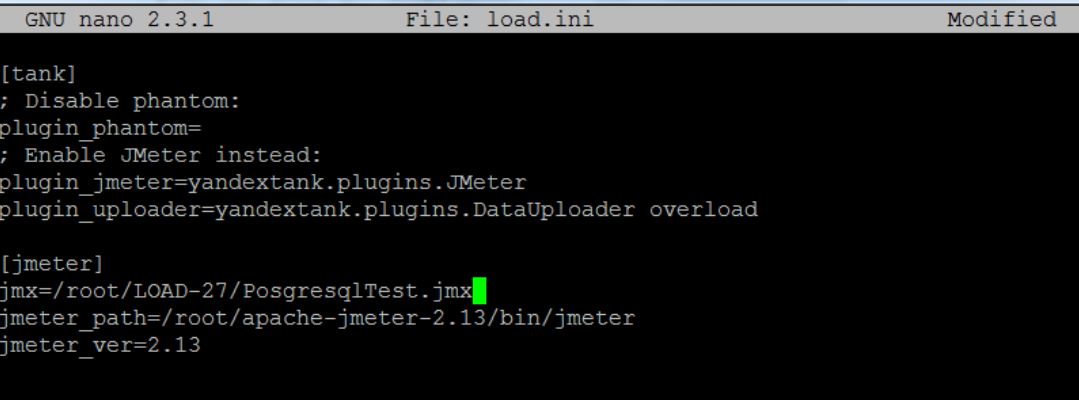
Теперь сохраняем тест и переносим на машину с танком. Вносим его в параметр “jmx” в файле load.ini и сохраняем. Используется абсолютная адресация. У меня выглядит так:
Пришло время первого запуска, чтобы понять, что на этом этапе все работает. Перед этим нам нужно проконтролировать добавление строк в БД. Для этого можно использовать инструмент pgAdmin или просто зайти на сервер с базой и сделать count строк до и после отработки скрипта. Коннект к базе выполняется подобной командой:
psql -h IpAddress -d dbName -U UserName
Сам count делаем так:
select count(*) from alert;
Возвращаемся на машину с танком, переходим в директорию где находится load.ini и вводим команду для запуска танка:
yandex-tank
Спустя несколько секунд после запуска появится окно с текущими параметрами теста. Учитывайте, что при коротких тестах танк может не успеть получить данные о текущих параметрах.
Мониторинг
Проверив выполнение и отработку теста перейдем к настройке мониторингов. Благо для настройки мониторинга средствами Overload, потребуется минимальные усилия. Достаточно следующих действий:- регистрация на Overload;
- получаем токен путем нажатия на иконку профиля в Overload и выбором “my api token”;
- создаем token.txt в той же папке, что и load.ini на машине с танком;
- заносим полученный токен в token.txt и сохраняем;
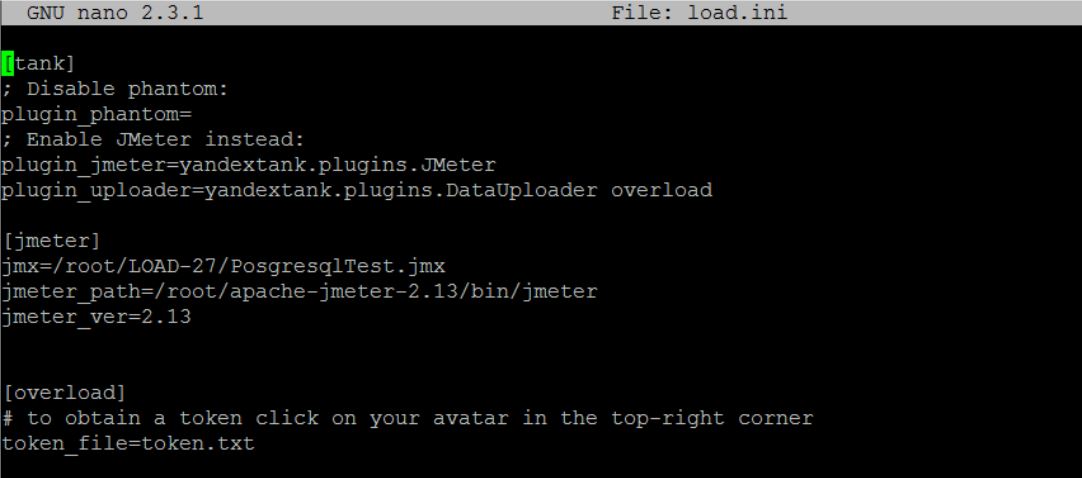
- добавляем блок [overload] в load.ini — описание от танкистов;
Получаем примерно следующее содержимое load.ini:
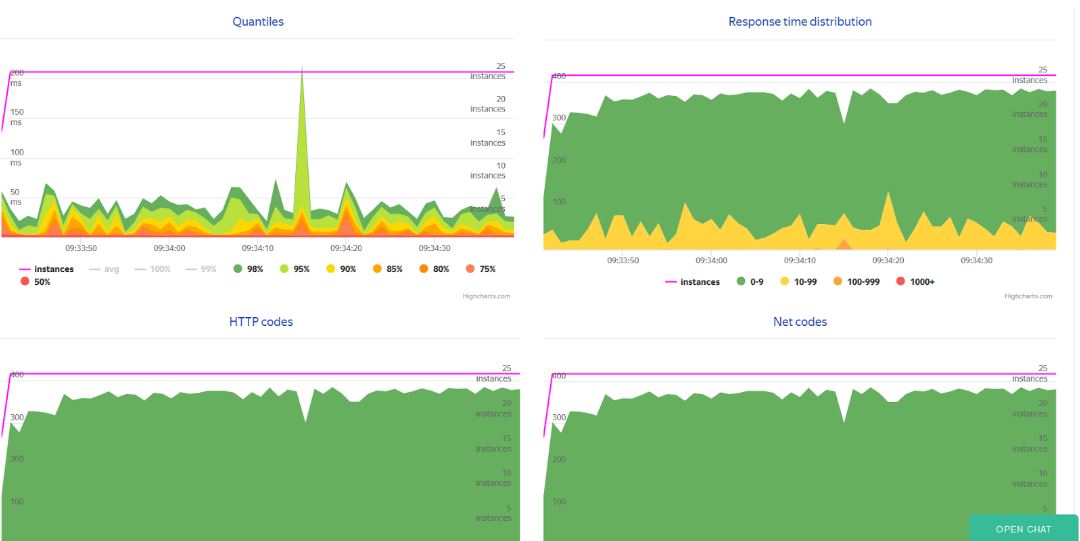
Теперь после запуска теста у нас профиле Overload будет отображаться текущий тест и все прошедшие со многочисленными полезными графиками:
C Overload закончили, теперь несколько слов о прочих метриках и их мониторинге. Существует множество гайдов для настройки мониторинга непосредственно БД, поэтому детально описывать этот процесс я не буду. Советую использовать telegraf для снятия метрик сервера и influxdb для базы данных. Вывод всех метрик можно организовать в Grafana. Для этого можно использовать процесс установки в этом гайде.
Напоследок хорошо было бы сказать о том, что с недавних пор, а именно, начиная с версии 3.2 у JMeter появились встроенное решение на базе infux для мониторинга, но там, в отличие от Overload, придется все настраивать самостоятельно.
На этом все. Всем хороших стрельб!
blind_oracle
PosgerSQL?
ilnuribat
там куча ошибок, дайте автору собраться, почитать сообщения в ЛС и поправить текст
а сама статья, на мой взгляд, хорошая