
В посте Тесты, которые тестируют тесты я описал свой взгляд на верификацию программ через дублирование их логики в виде отдельной модели и последующее сравнение с ней. В качестве частного случая выступили юнит-тесты.
В этот раз, опираясь на изложенные идеи, я попробую сформулировать общий подход к оценке уровня верифицированности ПО.
Введение
Разрабатывая ПО мы, по сути, занимаемся формализацией некоторой предметной области, результатом которой является появление описывающей её модели.
Проверить точность реализации модели можно только сравнив её с внешним по отношению к модели образцом:
- оригинальной предметной областью — запустив ПО на эксплуатацию;
- другой моделью, разработанной для той же предметной области.
Конечно, при сравнении моделей происходит не столько их проверка, сколько «синхронизация», так как при обнаружении различий нельзя определённо сказать в какой из двух моделей ошибка.
Почему дублирование логики работает
Пусть:
- при разработке модели 1 вероятность допустить ошибку равна p1;
- при разработке модели 2 вероятность допустить ту же ошибку равна p2;
Тогда:
- вероятность допустить эту ошибку одновременно в двух моделях равна p1*p2 (для сокращения текста примем, что это независимые события);
- это, обычно, значительно меньше исходных вероятностей.
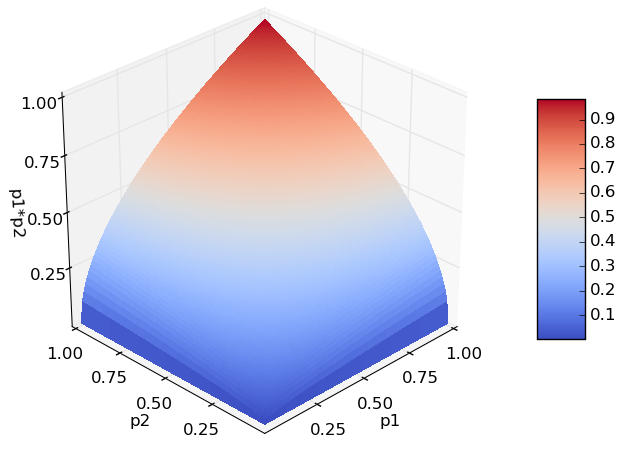
Этот график отображает изменение вероятности появления одинаковой ошибки в двух моделях и призван добавить веса статье.
Из данных соображений следует, что желательно выбирать модели, организованные на разных принципах, чтобы вероятности допущения однотипных ошибок отличались. В противном случае, верификация будет пропускать целый класс ошибок, вероятности совершить которые для данного типа моделей стремятся к 1.
В случае, когда тестовая модель закрывает только часть функциональности оригинальной модели, разумно рассматривать её покомпонентно: так, что тестовая модель либо закрывает весь компонент либо нет.
Популярные методы верификации
Давайте рассмотрим наиболее популярные методы повышения качества ПО и продемонстрируем, что каждый из них основан на формировании отдельной модели предметной области и сравнении её с основной.
Для этого определим свойства, которыми могут отличаться методы:
- способ реализации — как реализуется дублирующая модель;
- способ верификации — как осуществляется сравнение моделей;
Тесты (автоматические, полуавтоматические, ручные)
способ реализации: код (или алгоритм действий человека), реализующий создание окружения и проверяющий результат работы целевой модели;
способ верификации: вызов кода программы тестами или ручная работа тестировщика;
Статический анализ
способ реализации: модель задана правилами внутри проверяющего софта, например: компилятора, pylint, PVS-Studio. В частных случаях может существовать дополнительная спецификация, например: описание типов, расширенная спецификация алгоритмов (пример: habrahabr.ru/post/251751);
способ верификации: вызов внешнего верификатора для анализа кода целевой модели;
Парное программирование и ревью кода
способ реализации: модель находится в голове напарника;
способ верификации: сравнение напарником своей модели с тем, что вы пишите;
Полное дублирование системы
способ реализации: полный аналог целевой модели, разработанный другой командой;
способ верификации: сравнение состояний двух моделей и результатов их функционирования;
Пара слов о типизации
На мой взгляд, её нельзя считать отдельным методом верификации, а правильнее отнести к:
- статическому анализу, если она статическая;
- к тестированию, если она динамическая.
Соответственно, типизация имеет все особенности соответствующих методов.
Как эти соображения можно использовать?
Мы можем укрепить нашу аргументацию при организации процесса тестирования и получить несколько правдоподобных метрик «верифицированности» проекта.
Метрики
Самая простая приходящая на ум метрика — уровень покрытия дублированием целевой системы. Иными словами: сколько проверочных моделей повторяет каждый кусок функциональности оригинальной системы.
- минимальное покрытие — минимальное количество моделей на кусок функциональности оригинальной модели;
- среднее покрытие — среднее количество моделей на кусок функциональности; можно посчитать, например, разбив оригинальную систему на компоненты, посчитав покрытие каждого компонента и взяв среднее.
Организация процесса тестирования
Зная особенности проекта и команды мы можем выбирать виды контроля качества удобным для нас способом.
Мы можем, например, установить, что хотим иметь минимальное покрытие равное 1 — т.е. минимум по одной дублирующей модели на кусок функциональности.
Исходя из этого требования, мы направляем все ресурсы отдела тестирования на 100% проверку UI, а для внутренних компонентов выделяем разработчика для написания unit-тестов.
Альтернативой было бы размазать усилия отдела тестирования по всему проекту и получить покрытие в 0.5 модели (экспертная оценка), но сэкономить усилия разработчиков, отправив лишнего человека заниматься парным программированием особо критичного компонента (покрытие которого станет равно 1.5).
Резюме
В этой статье, конечно, нет претензий на какое-то открытие. Но есть попытка добавить больше формальности и обоснованности в процесс организации разработки ПО.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (6)

amarao
16.06.2015 18:35+3Это формальная сторона. Спасибо за раскрытие.
А есть ещё практическая: «тестами затыкаются грабли, на которые мы уже наступали». На удивление экономная и эффективная технология. Баги, которые никто не допускает, не покрываются тестами (экономия времени). Баги у которых высокая вероятность попасться (уже попались) — покрываются и более не появляются.
Кроме того, «написание тестов по мотивам реальных багов» обычно позволяет лучше сформулировать тесты, в том числе неявно подразумеваемые обстоятельства.
Это я про приёмочные тесты в основном, но думаю, что для юнит-тестов оно тоже нужное.
Tiendil Автор
16.06.2015 21:33Я только добавлю, что закрывать тестами надо не конкретный баг, а класс багов, к которому он относится. Потому как снаряды дважды в одну воронку всё-таки редко попадают.
В рамках исправление конкретной ошибки, можно и чисто под неё тест написать, но это сугубо для удобства программиста.
vladimirkolyada
По поводу вероятностей p1, p2: вероятность одновременного наступления двух независимых событий равна произведению вероятностей этих событий.
Но с каких пор события генерации ошибки в двух разных моделях одной группой разработки будут независимые? Как вы хотите этого добиваться? Это возможно лишь в случае, когда две группы ничего не знают друг о друге и их результаты скрыты друг от друга, что влечет появление двух разных моделей, которые не верифицировать по причине их резкого отличия?
Tiendil Автор
Я рискнул предположить, что это позволительное допущение (в основном для упрощения и сокращения текста).
Хотя, безусловно, признаю что события не независимые и этот вопрос обязательно нужно раскрыть подробно. Для этого и создан опрос в конце статьи.
bak
Мало того — очень часто разные разработчики наступают на одинаковые грабли при решении одинаковых задач. Если одна группа допустила в каком-то месте ошибку — высока вероятность что и другая её допустит.
Tiendil Автор
Это частный случай ситуации, о которой я вскользь упомянул. Модели надо строить на максимально различных базисах, в случае разработчиков, логично выбирать людей с разным опытом и использовать разные технологии.
Конечно, при этом следует учитывать соотношение цена/профит.