
Когда я писал статью со сравнением нового серверного процессора Centriq от Qualcomm с нашими нынешними Xeon на микроархитектуре Intel Skylake, то заметил тревожный феномен.
Бенчмарки OpenSSL 1.1.1dev показали, что производительность шифра ChaCha20-Poly1305 не слишком хорошо масштабируется. В одном потоке задача выполнялась с производительностью примерно 2,89 ГБ/с, а на 24 ядрах в 48 потоках — всего чуть более 35 ГБ/с.

Изображение CC BY-SA 2.0 от blumblaum
Это действительно очень большая цифра, но я ожидал увидеть что-то ближе к 69 ГБ/с, ведь 35 ГБ/с — это чуть более 1,46 ГБ/с на ядро или примерно 50% от максимальной производительности ядра. AES-GCM масштабируется гораздо лучше, до 80% производительности ядра, что понятно, потому что CPU способен поддерживать более высокую тактовую частоту (турбо) на одном ядре, но не на всех сразу.

Почему же ChaCha20-Poly1305 так плохо масштабируется? Причина в AVX-512. Это новый набор инструкций Intel, который добавляет много 512-битных инструкций SIMD и расширяет большинство существующих до 512 бит. Проблема с настолько широкими инструкциями в том, что им нужна энергия. Много энергии. Представьте единственную инструкцию, которая выполняет работу 64-х обычных однобайтовых инструкций или 8-ми полновесных 64-битных инструкций.
Чтобы удержать контроль над энергопотреблением Intel разработала нечто под названием «динамичное масштабирование тактовой частоты». Оно снижает базовую частоту процессора, если используются инструкции AVX2 или AVX-512. Это не последняя инновация, она существует уже три года с момента выпуска Haswell с набором инструкций AVX2.
Масштабирование происходит хуже, если много ядер выполняют инструкции AVX-512 при использовании умножения.
Если вы запускаете только код AVX-512, то всё нормально. Частота снижается, но общая производительность всё равно выше, потому что каждая инструкция выполняет больше работы.
В программе OpenSSL 1.1.1dev реализовано несколько вариантов шифра ChaCha20-Poly1305, в том числе варианты AVX2 и AVX-512. В BoringSSL работает другая AVX2-версия ChaCha20-Poly1305. Теперь понятно, почему BoringSSL показывает всего лишь 1,6 ГБ/с на одном ядре, по сравнению с 2,89 ГБ/с у OpenSSL.
Так что произойдёт, если добавить немного инструкций AVX-512 в вашу обычную вычислительную нагрузку? У нас работают процессоры Xeon Silver 4116 с базовой частотой 2,1 ГГц, в конфигурации с двойным сокетом. Судя по таблице на wikichip, запуск AVX-512 всего на одном ядре снижает базовую частоту до 1,8 ГГц. Запуск AVX-512 на всех ядрах снижает её до 1,4 ГГц.
А теперь представьте, что у вас веб-сервер на Apache или nginx. Вдобавок много других сервисов, выполняющих реальную, важную работу. Что произойдёт, если вы начнёте шифровать трафик шифром ChaCha20-Poly1305 с использованием AVX-512? Вот таким вопросом я задался.
Я скомпилировал две версии nginx, одну с OpenSSL1.1.1dev, а другую с BoringSSL, и установил их на сервер с двумя процессорами Xeon Silver 4116, с 24 ядрами в общей сложности.
Сервер был сконфигурирован на выдачу HTML-страницы среднего размера и выполнение некоторой осмысленной работы с ней. Я использовал LuaJIT для удаления переносов строки и лишних пробелов, а также brotli для сжатия файла.
Затем измерил количество запросов в секунду, которые сервер обрабатывает при полной нагрузке. Вот что получилось:
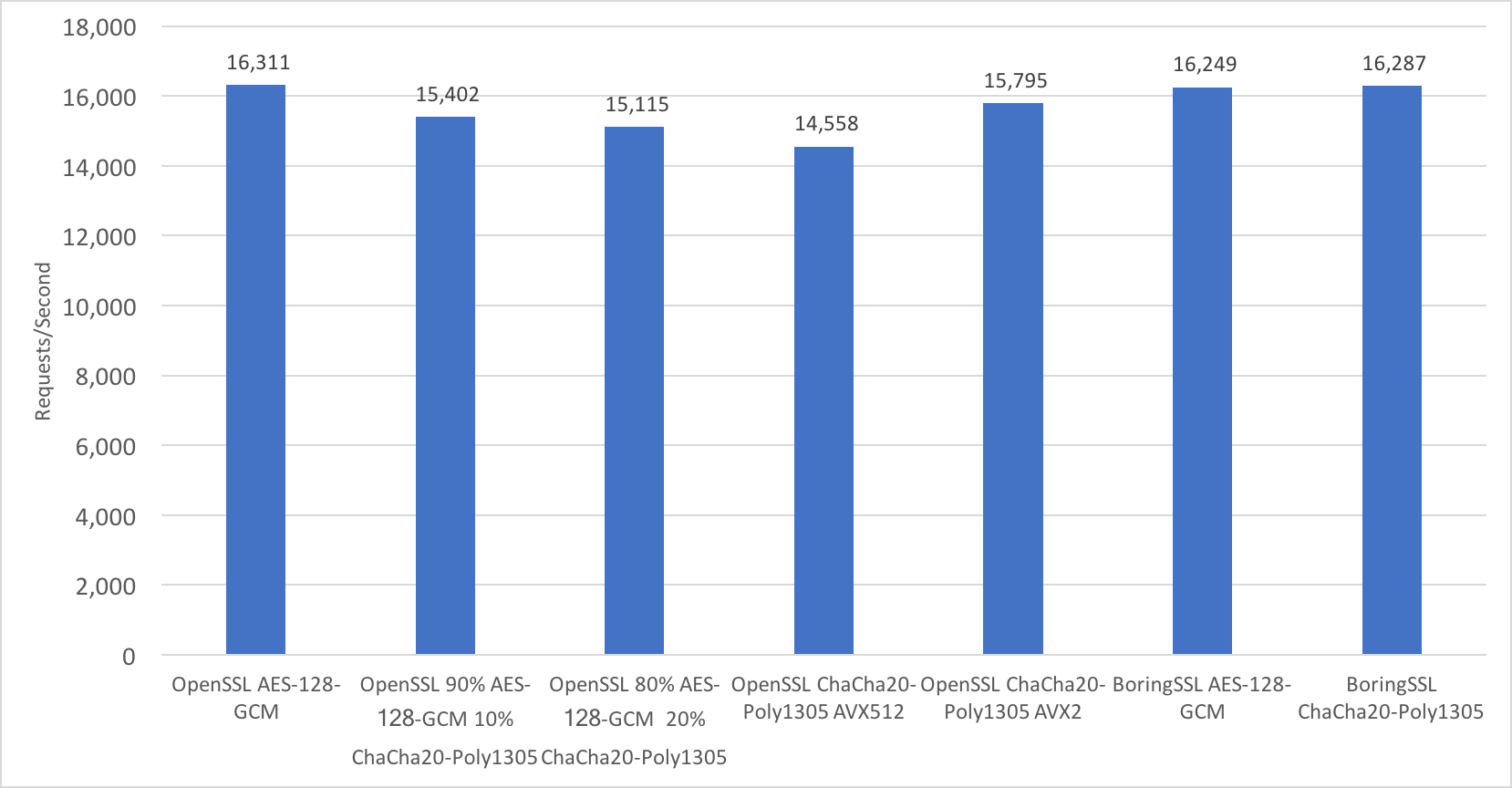
При использовании ChaCha20-Poly1305 вместо AES-128-GCM сервер с OpenSSL обрабатывал на 10% меньше запросов в секунду. И это немало! Это словно отключить два ядра просто так. Кто-то может подумать, что причиной является изначальная низкая производительность ChaCha20-Poly1305. Но нет.
Во-первых, BoringSSL работает одинаково хорошо и с AES-GCM, и с ChaCha20-Poly1305.
Во-вторых, даже если по ChaCha20-Poly1305 шифруется всего 20% запросов, пропускная способность сервера снижается более чем на 7%, а при обработке 10% запросов шифром ChaCha20-Poly1305 она снижается на 5,5%. Для справки, у Cloudflare около 15% запросов TLS используют шифр ChaCha20-Poly1305.
В конце концов, по статистике
Сложно сказать, насколько замедляется каждое конкретное ядро в каждый момент времени, но вот некоторые результаты, которые выдал
Ещё одно интересное отличие в том, что ChaCha20-Poly1305 с AVX2 немного медленнее работает в OpenSSL, чем в BoringSSL. Почему такое может быть? Причина в том, что код BoringSSL не использует инструкции умножения AVX2 для Poly1305, а только простые операторы xor, shift и add для ChaCha20, что позволяет инструкциям работать на базовой частоте.
OpenSSL 1.1.1dev пока находится в разработке, так что я думаю, что со снижением производительности ещё никто не столкнулся. Мы в этом году перешли на BoringSSL, так что производительность наших серверов не изменится из-за этой проблемы.
Что произойдёт в будущем — непонятно. Intel анонсировала очень крутые новые расширения ISA для будущих поколений процессоров, которые должны ещё больше увеличить производительность криптографии. Эти расширения включают в себя AVX512+VAES, AVX512+VPCLMULQDQ и AVX512IFMA. Но если к тому времени не решат проблему динамического масштабирования тактовой частоты, то использование этих инструкций в криптографических библиотеках общего назначения принесёт больше вреда, чем пользы.
Проблема будет не только у криптографических библиотек. OpenSSL не делает ничего плохого, пытаясь добиться максимально возможной производительности, наоборот, я и сам написал немало кода AVX-512 для OpenSSL. Наблюдаемое поведение — неприятный побочный эффект. Сейчас немало других библиотек используют инструкции AVX и AVX2. Вероятно, они обновятся и в какой-то момент перейдут на AVX-512, а пользователи вряд ли будут осведомлены об особенностях реализации. Если вам не требуются AVX-512 для каких-то конкретных высокопроизводительных задач, я бы предложил отключить AVX-512 на своём сервере или настольном компьютере, чтобы избежать случайного снижения тактовой частоты.
Бенчмарки OpenSSL 1.1.1dev показали, что производительность шифра ChaCha20-Poly1305 не слишком хорошо масштабируется. В одном потоке задача выполнялась с производительностью примерно 2,89 ГБ/с, а на 24 ядрах в 48 потоках — всего чуть более 35 ГБ/с.
Изображение CC BY-SA 2.0 от blumblaum
Это действительно очень большая цифра, но я ожидал увидеть что-то ближе к 69 ГБ/с, ведь 35 ГБ/с — это чуть более 1,46 ГБ/с на ядро или примерно 50% от максимальной производительности ядра. AES-GCM масштабируется гораздо лучше, до 80% производительности ядра, что понятно, потому что CPU способен поддерживать более высокую тактовую частоту (турбо) на одном ядре, но не на всех сразу.
Почему же ChaCha20-Poly1305 так плохо масштабируется? Причина в AVX-512. Это новый набор инструкций Intel, который добавляет много 512-битных инструкций SIMD и расширяет большинство существующих до 512 бит. Проблема с настолько широкими инструкциями в том, что им нужна энергия. Много энергии. Представьте единственную инструкцию, которая выполняет работу 64-х обычных однобайтовых инструкций или 8-ми полновесных 64-битных инструкций.
Чтобы удержать контроль над энергопотреблением Intel разработала нечто под названием «динамичное масштабирование тактовой частоты». Оно снижает базовую частоту процессора, если используются инструкции AVX2 или AVX-512. Это не последняя инновация, она существует уже три года с момента выпуска Haswell с набором инструкций AVX2.
Масштабирование происходит хуже, если много ядер выполняют инструкции AVX-512 при использовании умножения.
Если вы запускаете только код AVX-512, то всё нормально. Частота снижается, но общая производительность всё равно выше, потому что каждая инструкция выполняет больше работы.
В программе OpenSSL 1.1.1dev реализовано несколько вариантов шифра ChaCha20-Poly1305, в том числе варианты AVX2 и AVX-512. В BoringSSL работает другая AVX2-версия ChaCha20-Poly1305. Теперь понятно, почему BoringSSL показывает всего лишь 1,6 ГБ/с на одном ядре, по сравнению с 2,89 ГБ/с у OpenSSL.
Так что произойдёт, если добавить немного инструкций AVX-512 в вашу обычную вычислительную нагрузку? У нас работают процессоры Xeon Silver 4116 с базовой частотой 2,1 ГГц, в конфигурации с двойным сокетом. Судя по таблице на wikichip, запуск AVX-512 всего на одном ядре снижает базовую частоту до 1,8 ГГц. Запуск AVX-512 на всех ядрах снижает её до 1,4 ГГц.
А теперь представьте, что у вас веб-сервер на Apache или nginx. Вдобавок много других сервисов, выполняющих реальную, важную работу. Что произойдёт, если вы начнёте шифровать трафик шифром ChaCha20-Poly1305 с использованием AVX-512? Вот таким вопросом я задался.
Я скомпилировал две версии nginx, одну с OpenSSL1.1.1dev, а другую с BoringSSL, и установил их на сервер с двумя процессорами Xeon Silver 4116, с 24 ядрами в общей сложности.
Сервер был сконфигурирован на выдачу HTML-страницы среднего размера и выполнение некоторой осмысленной работы с ней. Я использовал LuaJIT для удаления переносов строки и лишних пробелов, а также brotli для сжатия файла.
Затем измерил количество запросов в секунду, которые сервер обрабатывает при полной нагрузке. Вот что получилось:
При использовании ChaCha20-Poly1305 вместо AES-128-GCM сервер с OpenSSL обрабатывал на 10% меньше запросов в секунду. И это немало! Это словно отключить два ядра просто так. Кто-то может подумать, что причиной является изначальная низкая производительность ChaCha20-Poly1305. Но нет.
Во-первых, BoringSSL работает одинаково хорошо и с AES-GCM, и с ChaCha20-Poly1305.
Во-вторых, даже если по ChaCha20-Poly1305 шифруется всего 20% запросов, пропускная способность сервера снижается более чем на 7%, а при обработке 10% запросов шифром ChaCha20-Poly1305 она снижается на 5,5%. Для справки, у Cloudflare около 15% запросов TLS используют шифр ChaCha20-Poly1305.
В конце концов, по статистике
perf, рабочая нагрузка AVX-512 потребляет всего 2,5% времени CPU, когда все запросы используют шифр ChaCha20-Poly1305, и менее 0,3% при его использовании для 10% запросов. Но независимо от этих цифр CPU всё равно снижает тактовую частоту, потому что он всегда так делает, если инструкции AVX-512 работают на всех ядрах.Сложно сказать, насколько замедляется каждое конкретное ядро в каждый момент времени, но вот некоторые результаты, которые выдал
lscpu. При запуске бенчмарка openssl speed -evp chacha20-poly1305 -multi 48 он показал CPU MHz: 1199.963, при запуске OpenSSL со всеми соединениями AES-GCM выдал CPU MHz: 2399.926, а для OpenSSL со всеми соединениями ChaCha20-Poly1305 — CPU MHz: 2184.338, то есть на 9% меньше.Ещё одно интересное отличие в том, что ChaCha20-Poly1305 с AVX2 немного медленнее работает в OpenSSL, чем в BoringSSL. Почему такое может быть? Причина в том, что код BoringSSL не использует инструкции умножения AVX2 для Poly1305, а только простые операторы xor, shift и add для ChaCha20, что позволяет инструкциям работать на базовой частоте.
OpenSSL 1.1.1dev пока находится в разработке, так что я думаю, что со снижением производительности ещё никто не столкнулся. Мы в этом году перешли на BoringSSL, так что производительность наших серверов не изменится из-за этой проблемы.
Что произойдёт в будущем — непонятно. Intel анонсировала очень крутые новые расширения ISA для будущих поколений процессоров, которые должны ещё больше увеличить производительность криптографии. Эти расширения включают в себя AVX512+VAES, AVX512+VPCLMULQDQ и AVX512IFMA. Но если к тому времени не решат проблему динамического масштабирования тактовой частоты, то использование этих инструкций в криптографических библиотеках общего назначения принесёт больше вреда, чем пользы.
Проблема будет не только у криптографических библиотек. OpenSSL не делает ничего плохого, пытаясь добиться максимально возможной производительности, наоборот, я и сам написал немало кода AVX-512 для OpenSSL. Наблюдаемое поведение — неприятный побочный эффект. Сейчас немало других библиотек используют инструкции AVX и AVX2. Вероятно, они обновятся и в какой-то момент перейдут на AVX-512, а пользователи вряд ли будут осведомлены об особенностях реализации. Если вам не требуются AVX-512 для каких-то конкретных высокопроизводительных задач, я бы предложил отключить AVX-512 на своём сервере или настольном компьютере, чтобы избежать случайного снижения тактовой частоты.