
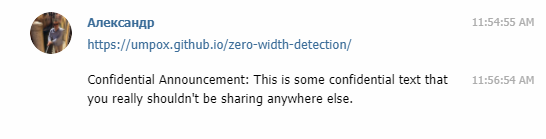
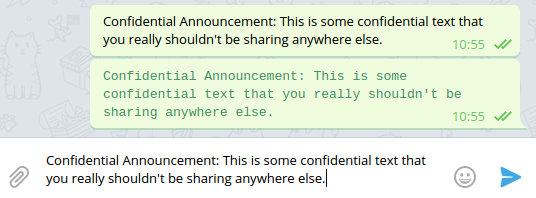
Символы нулевой ширины — это непечатаемые управляющие символы, которые не отображаются большинством приложений. Н?апример, в э?то пред?ложение я вст?авил де?сять про??белов н?улевой ширины, вы эт?о замет?или? (Подсказка: вставьте предложение в Diff Checker, чтобы увидеть местоположение символов!). Эти символы можно использовать как уникальные «отпечатки» текста для идентификации пользователей.

Безусловно, он может здесь быть. И вы никогда не догадаетесь
Зачем?
Ну, изначальная причина не слишком интересна. Несколько лет назад я с командой участвовали в соревнованиях по различным видеоиграм. У команды была приватная страничка для важных объявлений, среди прочего. Но в итоге эти объявления стали репостить в других местах, с издевательствами над командой, раскрывая конфиденциальную информацию и командную тактику.
Защита сайта казалась довольно стойкой, поэтому мы выдвинули предположение, что действует инсайдер, который входит по логину и паролю, а потом просто копирует объявление и размещает в другом месте. Поэтому я разработал скрипт, который в каждом объявлении невидимо отпечатывает имя пользователя, которому отображается это объявление.
После недавнего поста Зака Айсана стало понятно, что людям интересна тема непечатаемых символов. Так что я решил опубликовать этот метод здесь вместе с интерактивной демонстрацией для всех. Примеры кода обновлены для современного JavaScript, но общая логика одинакова.
Как?
Точные шаги и логика описаны ниже, но если в двух словах: строка имени пользователя преобразуется в двоичную форму, затем двоичный файл преобразуется в серию непечатаемых символов, представляющих каждый бит. Потом непечатаемая строка незаметно вставляется в текст. Если текст опубликован на другом сайте, строку непечатаемых символов можно извлечь и провести обратный процесс, чтобы выяснить имя пользователя, который сделал копипаст!
Фингерпринтинг текста
1. Получить имя пользователя, вошедшего в систему, и преобразовать его в двоичный файл.
Здесь мы просто преобразуем каждую букву имени пользователя в двоичный эквивалент.
const zeroPad = num => ‘00000000’.slice(String(num).length) + num;
const textToBinary = username => (
username.split('').map(char =>
zeroPad(char.charCodeAt(0).toString(2))).join(' ')
);2. Взять имя пользователя в бинарном формате и преобразовать его в непечатаемые символы
Следующий скрипт перебирает двоичную строку и преобразует каждый бит 1 в непечатаемый пробел, каждый 0 — в непечатаемый символ запрета лигатур (non-joiner). После преобразования каждой буквы вставляем непечатаемый символ разрешения лигатур (joiner) — и переходим к следующей.
const binaryToZeroWidth = binary => (
binary.split('').map((binaryNum) => {
const num = parseInt(binaryNum, 10);
if (num === 1) {
return '?'; // zero-width space
} else if (num === 0) {
return '?'; // zero-width non-joiner
}
return '?'; // zero-width joiner
}).join('') // zero-width no-break space
);3. Вставка «имени пользователя» в непечатаемый конфиденциальный текст
Здесь просто вставляем блок непечатаемых символов в конфиденциальный текст.
Извлечение имени пользователя из помеченного текста
Те же действия в обратном порядке.
1. Извлечь непечатаемое «имя пользователя» из конфиденциального текста
Удалить конфиденциальный текст из строки, оставив только непечатаемые символы.
2. Преобразовать непечатаемое «имя пользователя» обратно в двоичный файл
Здесь мы разбиваем строку на фрагменты, с учётом добавленных межбуквенных разделителей. Это даёт эквивалент в управляющих символах для каждой буквы имени пользователя! Перебираем символы и возвращаем 1 или 0, чтобы воссоздать двоичную строку. Если не находим соответствующий 1 или 0, то значит попали на межбуквенный разделитель (символ разрешения лигатур) и, таким образом, завершиили двоичное преобразование для символа: можно добавить к строке один пробел и переходить к следующему символу.
const zeroWidthToBinary = string => (
string.split('').map((char) => { // zero-width no-break space
if (char === '?') { // zero-width space
return '1';
} else if (char === '?') { // zero-width non-joiner
return '0';
}
return ' '; // add single space
}).join('')
);3. Преобразование имени пользователя из двоичного формата обратно в текст
В конце концов, анализируем двоичную строку и преобразуем каждую серию 1 и 0 в соответствующий символ.
const binaryToText = string => (
string.split(' ').map(num =>
String.fromCharCode(parseInt(num, 2))).join('')
);Заключение
Компании как никогда много внимания уделяют утечкам информации и поиску инсайдеров. Этот лишь один из многих трюков, которые можно использовать. В зависимости от направления вашей работы, может быть жизненно важно понимать риски, связанные с копированием текста. Очень немногие приложения отображают непечатаемые символы. Например, вы можете предположить, что ваш терминал попытается их отобразить (мой нет!).
Если вернуться к секретной доске объявлений, то план сработал как надо. Вскоре после внедрения скрипта вышло новое объявление. В течение нескольких часов текст распространили в другом месте с прикрепленной непечатаемой строкой. Имя пользователя виновника успешно идентифицировали, и его забанили: хэппи-энд!
Конечно, есть определённые оговорки по использованию этого метода. Например, если пользователь знает о скрипте, то теоретически может заменить непечатаемые символы, чтобы подставить другого человека. Так что лучше вместо имени пользователя вставлять уникальный секретный ID.
Чтобы поиграться со скриптом, запускайте демо или смотрите исходный код.
Комментарии (75)

mamont80
06.04.2018 09:59+1Шикарная история. Ещё одной параноей по слежке прибавилось. И ещё добавлю что от этих скрытых символов сложно избавиться, как, например, от форматирования. Если вставить в блокнот, потом снова скопировать, то символы сохранятся, а форматирование нет.

Sabin
06.04.2018 10:08Вариант для чужого офисного компьютера: вставлять в word с включённым отображением всех знаков

Mikhael1979
06.04.2018 10:32+1Вариант, работающий на 146%: перенабрать текст вручную (или использовать OCR).

GennPen
06.04.2018 10:44Либо использовать стандартный блокнот. При сохранении текста с кодировкой ANSI он выдаст предупреждение, что используются Unicode символы, и все скрытые непечатаемые символы улетают в трубу.
DrZlodberg
06.04.2018 10:52Подменять иногда рус на лат символы с одинаковым начертанием. Фиг кто заметит при беглом просмотре.
GennPen
06.04.2018 10:59Word выделяет такие слова как ошибочные.
DrZlodberg
06.04.2018 11:04Об этом не подумал. Но блокнот, вроде не проверяет. Хотя ворд периодически выделяет и правильные, слишком большое количество может быть подозрительным. Для больших текстов можно иногда добавлять второй пробел. Собственно в случае с большими текстами можно придумать массу синтаксически корректных замен, которые не спалить. Автоматически их делать для пары десятков вариантов тоже не проблема. Собственно идея давать различный текст подозреваемым была придумана не одну сотню лет назад.
bopoh13
06.04.2018 11:38<nerd>Только это был не текст, а словесная информация.</nerd>
DrZlodberg
06.04.2018 12:00Что есть «словесная» информация? Речь была об кусках теста с сайта (причём много их, как я понял), т.е. вполне подходит.
Формально — любая читаемая информация — текст. Даже числа и любые знаки. В т.ч. даже невидимые, как, собственно, в самой статье.

LoadRunner
06.04.2018 12:31Для больших текстов можно иногда добавлять второй пробел.
Лишний пробел довольно легко заметить в тексте, даже не читая его, просто при беглом просмотре. Если только он не попадает на конец строки.DrZlodberg
06.04.2018 12:56Даже если так — кто его заподозрит? И тем более будет исправлять. Обычно такие тексты копируют по принципу «синтаксис и пунктуация автора сохранены», сиреч — не глядя. Опечатки тоже обычно не правят. Собственно тексты без ошибок (особенно для внутреннего пользования) сейчас не редкость, и мало кто обращает на это внимание. Или вместо обычных использовать неразрывные.
Добавить пару пробелов в уникальной для юзера комбинации и всё. А для длинных текстов и небольшого количества клиентов — даже одного. Даже если кто придерётся, что текст кривой — всегда можно сослаться на залипший пробел (кстати при перекосе пробела на старой клаве такое случается, как и при слишком задранной скорости автоповтора).

GeneAYak
07.04.2018 04:36Вообще-то суть не в том, чтобы показать, что текст скопировали. А именно уличить того, кто его копирует. Смысл просто менять букву или пробел добавлять?
DrZlodberg
07.04.2018 09:20Вообще-то пробел можно добавлять в разные места, в уникальной для юзера комбинации. Потом просто по его положению можно узнать, какая из версий ушла. То, что текст скопирован известно уже по условию.

ainoneko
07.04.2018 18:37Дополнительная программа будет вставлять пробелы в случайные места, чтобы подставить кого-то другого?
DrZlodberg
07.04.2018 19:37Каким образом?
Чтобы подставить кого-то другого нужно как минимум:
1. Знать о том, что эта система вообще существует (т.е. это должен быть кто-то из очень своих)
2. Знать о том, какая комбинация кому соответствует (т.е. это должен быть кто-то из админов)
Собственно в любой случае тут уже не сработает никакой из вариантов предложенных в статье или комментариях.
fantast100
08.04.2018 12:34Вобще-то пользователей может быть больше, чем комбинаций.
DrZlodberg
08.04.2018 12:55Прикинем приблизительно. Текст 100 слов (очень короткий):
один пробел: 100 вариантов.
2 пробела: ~10000
Опечатка (например довольно типичная — замена 2х соседних букв местами): ~300..400
Опечатка (замена символа): ~6000..7000
Подсчёты крайне приблизительные, но порядок прикинуть позволяют.
И 100 слов — это очень мало. В этом комментарии их примерно 40.
DrZlodberg
06.04.2018 10:50Не. При желании можно, например, делать рандомные ошибки в словах. Потом по анализу можно поймать.

Keyten
06.04.2018 18:50Можно использовать разные типы кавычек, разные виды тире / дефисов / дефисоминусов / разделителей в телефонном номере / etc. Это ещё незаметнее.
И можно даже пойти ещё дальше и заменять слова на синонимы.
DrZlodberg
06.04.2018 10:46На самом деле тут можно предложить и менее палевный вариант. Например подменять символы на подобные по начертанию, но из других кодовых страниц (можно спалить шрифтом, у которого начертания отличаются) или псевдорандомно вставлять обычный/неразрывный пробел (при некоторой внимательности можно заметить). Оба варинта вполне пройдут через блокнот и ворд (вроде неразрывные он не отличает от обычных при показе)

FillCT
06.04.2018 14:03в ворде неразрывный пробел отличается от обычного, при включении непечатаемых символов сразу заметен.
Если текст направлен ограниченному количеству человек, можно вставить в середине предложение, в котором будут меняться синонимы слов в зависимости от пользователя. Затем по синонимам вычислять id пользователя. Еще лучше пораскидать таких слов по всему тексту в «случайном» порядке.DrZlodberg
06.04.2018 14:48Ну как вариант я подобное и предлагал. Синонимы — муторно и требует ручной работы. Да и работает только для ну очень ограниченного количества. Проще заменить какие-либо часто встречающиеся обороты или слова. Это можно делать и автоматически. Ну и чем больше их в тексте — тем, очевидно, больше возможных комбинаций.

sumanai
06.04.2018 11:34Firefox тоже подчёркивает. Плюс прямо на странице он разрывает слово, если нужно перенести, поэтому я подвох заметил сразу.
0mogol0
08.04.2018 12:33Я уже давно думал, что для отслеживания эл.книг можно использовать лишние / опциональные знаки препинания, например, заменять точку запятой, или запятую на точку с запятой. Если выделить десятка два-три таких мест (а лучше сотню, для дублирования), то можно каждой продаваемой книжке присваивать свой индивидуальный код, а дальше смотреть, кто из покупателей выложил книгу на флибусту. Чтобы найти все такие места потребуется не один экземпляр купить.

LukaSafonov
06.04.2018 10:03+2Схожие методы использовались на «околохакерских» форумах для идентификации каналов утечки информации.
questor
06.04.2018 19:51Это вы ещё не вспомнили 'вариант омега' про радиоигру разведок: помните точку в конце предложения?

Vkuvaev
09.04.2018 11:08Это, если не ошибаюсь, история о том, как британцы, судя по всему, не без помощи инсайдера, спалили кучу своих агентов в европе супротив германской разведки. Агенты должны были помечать точкой(или отсутствием), что раскрыты, и они это делали, но руководство проигнорило, и на них полагались как на надежных. В итоге в «надежную» точку досылали людей на погибель…
stepanovmm
06.04.2018 10:46+1Например, вы можете предположить, что ваш терминал попытается их отобразить (мой нет!).
Н<200b>апример, в э<200b>то пред<200b>ложение я вст<200b>авил де<200b>сять про<200b><200b>белов н<200b>улевой ширины, вы эт<200b>о замет<200b>или?
Для тех кому интересно(Vim).mayorovp
06.04.2018 10:50+4Еще вот так их можно найти (если знать что они там есть!):

Двойной клик выделяет кусок текста, ограниченный пробелами.

Serj_By
06.04.2018 12:02Чтобы избавится от этого недостатка, достаточно вставлять их до/после пробелов. Правда, текст для этого должен быть достаточно длинным.

Bringoff
06.04.2018 12:08Стандартный маковский тоже вполне справляется:
Скрытый текст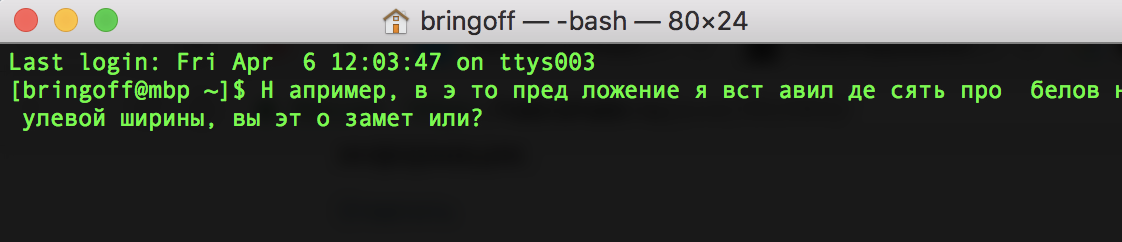

ionicman
06.04.2018 11:28Боже, зачем так сложно-то?
Во-первых любой нормальный rich-edit это покажет, во-вторых (вытекающее из первого) — ненадежно — символы могут быть потеряны при копировании или очистке и т.д.
Кодирование есть куда проще — знаками пунктуации. Тире и дефисов в юникоде штук 5, замена точек на точку с запятой и т.д.
Имея 5 вариантов — это уже 5 бит — 2^5 пользователей.
Никто на это не обратит внимание, как на похожие по начертанию символы или что-то еще. Все привыкли, что типографика всегда страдает.
saluev
06.04.2018 13:44Не понял вашу комбинаторику.
Если у тире пять вариантов, то одно тире в предложении даёт возможность идентифицировать 5 пользователей, два — 25 и так далее.
Но если тире в тексте больше одного, то их подозрительное различие будет визуально заметно. То же с пробелами разной ширины.ionicman
06.04.2018 14:20Имелось ввиду, что использовать символы там, где они и должны быть использованы. Даже в небольшом тексте практически всегда есть тире — вот их и использовать, только код символа использовать один из пяти.
Кроме того, можно составить текст так, чтобы там были по смыслу определенная типографика, а дальше — играться.

lostpassword
06.04.2018 11:38Так удалось вычислить инсайдера или нет?
Loki3000
06.04.2018 11:41+1Так удалось вычислить инсайдера или нет?
Если дочитать статью до конца, то вопрос отпадет.lostpassword
06.04.2018 11:41Почему-то не заметил то предложение. Спасибо!

achekalin
07.04.2018 08:58Концовка мягковато описана. С учётом "любви к нему" и усилий по вычислению, я прямо ждал ту картинку "он не сделал бекап и дропнул базу", ну или хотя бы что-то более суровое ("нашли его с группой товарищей и заставили вслух читать число пи до 1000 знака!"), чем просто забанили.
Alexus819
06.04.2018 12:46Н? апример, в э? то пред? ложение я вст? авил де? сять про?? белов н? улевой ширины, вы эт? о замет? или?
стандартный Windows cmd.exe

ooprizrakoo
06.04.2018 13:39+1Много лет назад, когда писатели-фантасты были гораздо ближе к фэндому, они давали свои первые версии романов своим знакомым (распространяя через фидо и затем интернет).
Однако для того, чтобы обезопаситься от утечек, многие из них каждому адресату отправляли тексты романов с некоторыми уникальными изменениями — лишний пробел между словами, запятая сдвинутая вправо, использование буквы «ё» там, где у других буква «е», и всё такое прочее. Не сказать, что утечки были массовой проблемой, но возможно в т.ч. потому, что получатели знали о возможном «фингерпринтстве», а инсайдеры более одного раза не могли предать чужое доверие.
nevzorofff
06.04.2018 18:19+3Сделать скриншот и публиковать его, а не копипасту. Можно ещё немного размыть или снизить разрешение, чтобы что-то невидимое для глаз исказилось.
Так многие и делают, особенно на мобилах, бо скриншот — одно нажатие кнопок, а копипаста — та ещё затея.
Keyten
06.04.2018 18:23+1Кстати, стоило бы делать так:
const zeroWidthSpace = '?'; const zeroWidthNonJoiner = '?'; const zeroWidthJoiner = '?'; const zeroWidthNoBreakSpace = ''; const binaryToZeroWidth = binary => ( binary.split('').map((binaryNum) => { const num = parseInt(binaryNum, 10); if (num === 1) { return zeroWidthSpace; } else if (num === 0) { return zeroWidthNonJoiner; } return zeroWidthJoiner; }).join(zeroWidthNoBreakSpace); );sasha1024
06.04.2018 18:30+4А ещё лучше:
const zeroWidthSpace = '\u200B'; const zeroWidthNonJoiner = '\u200C'; const zeroWidthJoiner = '\u200D'; const zeroWidthNoBreakSpace = '\uFEFF';

Sly_tom_cat
06.04.2018 23:34На сколько я помню этих символов нулевой длинны немного больше чем 2…
Плюс, как уже заметили выше есть еще одинаковые символы в разных языках.
Т.е. даже если применять преобразование бинарного в… то гораздо оптимальнее преобразовывать в 4-, 8-, 16-ричный код (используя больше символов). Так меньше символов на тот же объем информации потребуется.

youngmysteriouslight
07.04.2018 01:39Заметил раньше, чем первое предложение начал читать.

Подумал, что косяк переводчика, но нет, на хромиумовских браузерах таки пробела не видно.
IvanTamerlan
07.04.2018 19:22+1Ожидал после такой эпичной завязки игры шпионов продолжения в том же стиле, а не достаточно скучным и простым баном в качестве очень быстрой развязки после кульминации, когда шпиона вычислили.
Нашел инсайдера, который сливает данные? Просто прекрасно, теперь можно управлять сливаемыми данными! Т.е. тупо отправлять дезу, периодически проверяя, что на других сайтах именно деза с правильным отпечатком имени. И теперь начинается настоящая шпионская игра! Особенно для того, чтобы инсайдер не заметил изменения отношения и «все осталось как есть» (с доступом к архиву правильных записей, как вариант).
wxzarm
08.04.2018 12:33Я действительно удивился тому, что введенной мной значение было отображено. Почему-то мне казалось, что в браузере Google Chrome данная проблема уже давно исправлена (хотя что-то мне подсказывает, что я что-то путаю).
xinetus
08.04.2018 12:33Регулярные выражения спасут копипаст ;).
<!DOCTYPE html> <html lang="ru"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <meta name="Keywords" content="refining" /><meta name="abstract" content="refining" /><meta name="description" content="refining" /><meta name="viewport" content="width=device-width, initial-scale=1"/> <title>Чистильщик</title> </head> <body style="text-align:center;margin:0;"> <div> <textarea id='trash' type="text" style="width:90%;height:400px; text-align:center;"></textarea> </div> <button style="width:180px;height:60px;font: bold 20px/1.5 cursive; text-align:center;" id="_button">старт</button> <br/><br/> <div id="resultation"></div> <script> function refining(){ rG1=''; trash=String(document.getElementById('trash').value); var sG1=new Array(); for(i=0;i<trash.length;i++){sG1[i]=trash[i].replace(/[^а-яА-яa-zA-Z_0-9-—!"№%?*()\[\]+=@#$%^&*{}:;"'?><.,|\ \\\/\n\ ]/g, '\-');}; for(i=0;i<sG1.length;i++){rG1+=sG1[i];}; document.getElementById('resultation').innerHTML=rG1; }; document.getElementById('_button').onclick=refining; </script> </body> </html>
VladislaWoW
08.04.2018 12:33Такие пробелы нулевого размера и другие скрытые символы можна обнаружить еще на стадии копирования, с помощью обычной консоли браузера.

denis_skripnik
08.04.2018 12:33У этого метода есть значительный минус. При использовании программ экранного доступа, которыми пользуются незрячие, эти символы видны, их можно удалить или изменить при копировании.
Также такой текст очень неудобно слушать. Вот прочитайте написанный в посте текст вслух: так он и читается скринридером:
«Н апример, в э то пред ложение я вст авил де сять про белов н улевой ширины, вы эт о замет или?»
P. S. Сам символ озвучивается при посимвольном чтении, как «Пробел нулевой ширины».
retimer
08.04.2018 12:33А дать ограниченному кругу пользователей вообще разный текст — не рассматриваем? Зачем мудрить со скрытыми символами? Задача в том, чтобы найти подлеца, а не в написании кучи скриптов…
Solovej
08.04.2018 13:21Занятная вещица, особенно учитывая если работаешь под TOR сетью, толку от TOR сети нет если ник светится.
Получается надо текст писать картинкой и тогда есть хоть какой то вариант не спалится, хотя и с картинкой можно опростоволоситься.


 . Похоже, статья перекликается с этим переводом.
. Похоже, статья перекликается с этим переводом.










maxzh83
«Фингерпринтинг» звучит как брейнфакинг
marapper
Пальцеотпечаток из кук хабра сотрите.
alix_ginger
Из печенек же