
Я считаю корнем проблемы то, что Даниел Канеман сформулировал как правило «Что видишь, то и есть». Оно в двух словах объясняет жёсткие ограничения человека на быстрое принятие решений, используя только имеющиеся данные и некоторые базовые эвристики. Замедление мышления требует времени и дисциплины — так что вместо этого мы пытаемся заменить сложные проблемы, которые не полностью понимаем, простыми.
В случае повторного использования интуиция просто и убедительно представляет труднодоступную в физическом мире аналогию программного обеспечения как «колесо», которое не следует изобретать заново. Это удобная ментальная модель, к которой мы часто возвращаемся при принятии решений о повторном использовании. Проблема в том, что такое представление о повторном использовании ошибочно или, по крайней мере, удручающе неполно. Давайте посмотрим, почему…
(Краткое предостережение: я говорю о крупномасштабном повторном использовании, а не об уровне методов и функций. Я совершенно не собираюсь применять принцип DRY на более низких уровнях детализации. Также я представляю повторное использование как применение неких сервисов, библиотек и прочего, созданного внутри компании, а не снаружи. Я не рекомендую создавать собственный фреймворк JS MVC! Ладно, теперь вернемся к первоначально запланированной статье...)
Интуиция
Представьте систему A, которая внутри содержит некоторую логику C. Вскоре должна быть построена новая система B, и ей тоже нужна такая же базовая логика C.

Разумеется, если мы просто выделим C из системы A, то можно использовать её в системе B без необходимости повторной реализации. Таким образом, экономия составляет время на разработку C — её понадобилось реализовать только один раз, а не снова для B.

В будущем ещё больше систем обнаружат потребность в том же общем коде, так что преимущества такого выделения и повторного использования будут расти почти в линейной прогрессии. Для каждой новой системы, которая повторно использует C вместо независимой реализации, мы получаем дополнительную экономию, равную времени на реализацию С.
Опять же, логика здесь простая и, казалось бы, железная — зачем разрабатывать несколько экземпляров C, если можно просто разработать один раз, а затем повторно использовать. Проблема в том, что картина более сложная — и то, что кажется лёгким трамплином для ROI, может превратиться в дорогую смирительную рубашку. Вот несколько вариантов, как наша базовая интуиция по поводу повторного использования может нас обмануть…
Реальность
Первая проблема — это выделение. Интуиция говорила, что C можно достать словно деталь конструктора — красиво и легко. Однако реальность распутывания общего кода может оказаться иной: вы пытаетесь вытащить одну макаронину из миски — и обнаруживаете, что блюдо целиком представляет собой лишь одну большую макаронину. Конечно, всё обычно не так плохо, но в коде много скрытых зависимостей и соединений, так что первоначальное представление об области C растёт по мере того, как вы начинаете его раскручивать. Почти никогда не бывает так просто, как вы ожидали.
Кроме того, почти всегда C нуждается в других вещах для работы (например, в других библиотеках, служебных функциях и т. д.). В некоторых случаях это общие зависимости (т. е. и A, и C нуждаются в них), а в некоторых случаях нет. В любом случае, простая картина A, B и C может выглядеть уже не такой простой. Для этого примера предположим, что A, B и C используют общую библиотеку L.
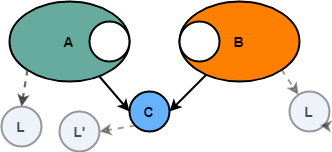
Другая проблема — изменение: у разных пользователей C часто будут несколько разные требования к тому, что она должна делать. Например, в C может быть какая-то функция, которая должна вести себя немного иначе, если её вызывает А, чем если её вызывает B. Общим решением для таких случаев является параметризация: данная функция принимает некоторый параметр, который позволяет ей понять, как себя вести с учётом того, кто её вызвал. Это может работать, но увеличивает сложность C, и логика тоже захламляется, поскольку код наполняется блоками вроде «Если вызов из А, то запустить такой блок логики».

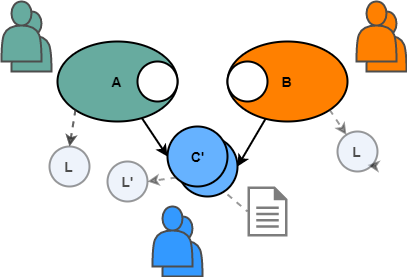
Даже если C действительно идеально подходит для A и B, всё равно изменения почти наверняка придётся делать с появлением новых систем, скажем, D и E. Они могли бы использовать C как есть, но тогда им самим понадобится доработка, небольшая или побольше. Опять же, каждое новое приспособление C представляет дополнительную сложность — и то, что раньше было легко в ней понять, теперь становится намного сложнее, поскольку C превращается во нечто большее, удовлетворяя потребности D, Е, F и так далее. Что приводит к следующей проблеме…
По мере роста сложности, разработчику всё сложнее понять, что делает C и как её использовать. Например, разработчик A может не понимать какой-либо параметр для функции C, поскольку он относится только к системам E и F. В большинстве случаев необходим некоторый уровень документации API (возможно, Swagger, Javadoc или более), для пояснения входа и выхода, исключительных условий и других SLA/ожиданий. И хотя документация сама по себе является хорошей вещью, она не лишена своих проблем (например, её нужно поддерживать в актуальном состоянии и т. д.).

Другим следствием повышенной сложности является то, что становится труднее поддерживать качество. Теперь C служит многим хозяевам, поэтому появляется много пограничных случаев для тестов. Кроме того, поскольку теперь C используется многими другими системами, влияние любого конкретного бага усиливается, так как он может всплыть в любой или всех системах. Часто при внесении любого изменения в C недостаточно протестировать только общий компонент/сервис, а требуется некий уровень регрессионного тестирования также А, B, D и всех остальных зависимых систем (неважно, используется сделанное изменение С в этой системе или нет!).
Опять же, поскольку мы говорим о повторном использовании в нетривиальном масштабе, то вероятно C придётся разрабатывать отдельной группе разработчиков, что может привести к потере автономии. У отдельных групп обычно свои собственные графики выпуска, а иногда и собственные процессы разработки. Очевидный вывод в том, что если команде A нужно какое-то улучшение в C, то ей вероятно придётся работать через процесс C, т. е. чемпион А должен предоставить требования, отстаивать свой приоритет и помогать в тестировании. Другими словами, команда A больше не контролирует свою собственную судьбу в отношении функциональности, которую реализует C — она зависит от команды, которая поставляет C.

Наконец, при обновлении С, по определению, появляются разные версии. В зависимости от характера повторного использования могут возникнуть различные проблемы. В случае повторного использования на этапе сборки (например, в библиотеке) разные системы (A, B, и т. д.) могут остаться со своими рабочими версиями и выбирать подходящий момент для обновления. Недостаток в том, что существуют разные версии C и есть вероятность, что какую-то одну ошибку придётся исправлять во всех версиях. В случае повторного использования во время выполнения (например микросервис) C должна либо поддерживать несколько версий своего API в одном экземпляре, либо просто обновиться без оглядки на обратную совместимость и, таким образом, заставить A и B обновиться тоже. В любом случае, значительно возрастают требования к надёжности и строгости процессов и организаций для поддержки такого повторного использования.
Вывод
В итоге, моя точка зрения заключается не в том, что следует избегать крупномасштабного повторного использования, а в том, что это не так просто, как говорит интуиция. Повторное использование действительно трудно, и хотя оно всё ещё может дать преимущества, которые перевешивает недостатки, но эти недостатки следует заранее реалистично рассмотреть и обсудить.
Даже после тщательного анализа, если крупномасштабное повторное использование является правильным, нужно принять решение о том, каким образом это сделать. Опыт подсказывает быть осторожнее со стрелками зависимости. Повторное использование, когда «повторный пользователь» находится под контролем, почти всегда проще реализовать и им проще управлять, чем повторным использованием, когда повторно используемый ресурс обращается к системе. В примере выше, если бы C была библиотекой или микросервисом, то A и B получили бы контроль. На мой взгляд, это ускоряет реализацию и уменьшает уровень управления/координации в долгосрочной перспективе.
Превращение C во фреймворк или платформу переключает стрелки зависимостей и усложняет контроль. Теперь A и B обязаны C. Такой тип повторного использования не только сложнее реализовать (и сделать это правильно), но он в дальнейшем приводит к более сильной блокировке (т. е. A и B полностью зависят от C). Народная мудрость гласит, что «библиотека — это инструмент, фреймворк — это образ жизни».

Наконец, хотелось бы узнать ваше мнение или опыт крупномасштабного повторного использования. Когда оно работает, а когда терпит неудачу?
Комментарии (41)

vanxant
04.04.2018 08:00+1Однобоко. Правильно было бы сравнить проблемы со случаем не-выделения С. Те же доп. переключатели логики или версионность, при условии, что А и В плотно друг с другом взаимодействуют

AllexIn
04.04.2018 09:26+1Мы пишем макарона-стайл код, поэтому повторное использование не работает, понятненько?

wert_lex
04.04.2018 10:40Имхо, это один из вариантов "преждевременная оптимизация — корень всех зол".
Далеко не всегда однозначно можно сказать, что C нужно выделять. Кроме того, нужно понимать, что выделение C — это не столько про скорость разработки (это надо еще подумать, что быстрее — копипаста или унести кусок функционала в отдельный класс/модуль), а про стоимость поддержки.
Соответственно, вариант "пишем в лоб два куска со сходным функционалом, не гнушаясь копипастой — проверяем боем — оптимизруем/реорганизуем" вполне себе годный вариант, который благодаря фазе "проверяем боем" отлично покажет есть ли смысл выносить C, да и вообще, есть ли это общее C.
Разумеется, это не касается совсем уж очевидных случаев, когда декомпозиция понятна заранее.

fpinger
04.04.2018 11:40+1Повторно используемая библиотека, пакет модуль, плагин или фреймвок — это продукты.
Если вы пишите отдельное приложение, но не библиотеку, пакет модуль, плагин или фреймвок, то повторное использование кода возможно только на уровне самого приложения.
Pusk1
04.04.2018 13:333 системы и взаимодействие между ними не проще, чем 2 с частью похожего функционала. Если при проектировании B предполагается, что C будет использоваться не только в А и B, то есть смысл реализовать C как выделенный из B. Выделение С из уже работающего A это отдельная задача, требующая дополнительной оценки целесообразности.

UltimaSol
04.04.2018 15:18Наконец, хотелось бы узнать ваше мнение или опыт крупномасштабного повторного использования. Когда оно работает, а когда терпит неудачу?
Есть мнение, что фреймворк-мейкерам не нужно отчаиваться в стремлении изготовить более высокоуровневое средство для задания логики С. Ну, то есть, когда логику C будет быстрее переписать заново со слов пользователя, чем кодить программистским языком с привлечением программистских же библиотек.
Опыт тоже есть в этом.

velvetcat
04.04.2018 17:16Полная лажа. Выделение и переиспользование знаний, технологий, решений, деталей, чего угодно — основа прогресса.
Стройте все изначально из правильных частей и не будет проблем с выделением.
ardraeiss
05.04.2018 08:33+1Рецептом «изначально правильных систем» в условиях неопределённости и недостаточности сведений о будущих(через полгода-год) решениях бизнеса поделитесь?
velvetcat
05.04.2018 14:53В том и дело, что надо проектировать под неопределенность — делать слабосвязанные взаимозаменяемые части.

aml
04.04.2018 19:48Всё в точности так! Каждое повторное использование рождает зависимость, а поддержка зависимости требует постоянных расходов на сопровождение и увеличивает сложность системы, что тоже имеет свою цену. Надо очень тщательно взвешивать плюшки, которые получаются от переиспользования, и недостатки.
shuron
05.04.2018 00:00Скорее в статье мне не хватает еще одной вещи…
С как компромис А и В (не говоря о Е и Д) уже сложнее просто суммы частного случая для А и частного (очень похожего) случая для Б.
Не всем очевидна эта истина.

Nick_Shl
04.04.2018 20:25+1Это не повторное использование. Это — совместное использование.
Повторное — это когда С берется из системы А, интегрируется в систему В и дальше системы А и В идут параллельными непересекающиеся курсами. И такой вариант даёт выигрыш для системы В по сравнению с "а давайте напишем С заново". Обычно под С заводится свой репозиторий, где для каждой системы(А, В и т.д.) заводится своя ветка С которая используется только в одной системе и нигде больше. А в транк сливают результаты фиксов в ветках и он используется только для ветвления при появлении нового проекта которому нужно С.
oygan
04.04.2018 20:50+1Тут нужно вспомнить о SOLID принципах, IoC и авто тестирование. Набраться опыта в данных сферах и сможете переиспользовать код.
Durimar123
05.04.2018 13:07-1И как переделать пилу в молоток?
А с точки зрения менеджмента и там и там одна металлическая часть и одна деревянная и оба инструмента нужны для работы по дереву.
Bonart
05.04.2018 03:12+2Автор оригинальной статьи демонстрирует главный антипаттерн разработки модульных приложений: представление сложности обеспечения модульности как сущностной (связанной со сложностью задачи) вместо акцидентной (связанной с существующими инструментами и практиками.
Все аргументы сводятся к одному: у нас говнокод и поэтому повторное использование "очень сложно".
У меня есть успешный опыт превращения спагетти-монолита в свободно расширяемый набор модулей за счет правильной методики и созданного в соответствии с ней велосипеда.
Принципы модульности:
- Автономность — модули можно создавать, тестировать и эксплуатировать независимо от любого конкретного набора других модулей. Это сразу требует, чтобы все зависимости и вся реализованная функциональность модулей описывались явными контрактами на уровне кода.
- Компонуемость — сборка приложения из набора модулей должна быть простой задачей, в идеале — решаемой автоматически.
- Рекурсивность — из набора модулей должен легко собираться композитный модуль, неотличимый от обычных модулей снаружи.
- Прозрачность — должна иметься возможность сгенерировать актуальную диаграмму компонентов для модулей в работающем приложении.
- Ортогональность — инструмент для организации модульности должен быть библиотекой, а не фреймворком. Правки в коде для поддержки модульности должны быть минимально возможными.
slonpts
05.04.2018 08:33А можете написать, какие технологии использовали?
Для самого кода (к примеру, ASP.NET MVC + React), для композиции модулей (DI?)?
Кстати, а модуль — это что? Библиотека?Bonart
05.04.2018 09:32А можете написать, какие технологии использовали?
Технологии тут как раз нерелевантны из-за пункта 5.
- Изначально делалось на Delhi 2007
- Контрактами были COM-интерфейсы (только из-за наличия у них GUID)
- Модуль — объект, реализующий интерфейс IModule: GUID модуля, имя модуля, список реализованных интерфейсов, список интерфейсов-зависимостей, методы для инициализации и финализации.
- Из набора модулей автоматически строился граф зависимостей.
- Из графа автоматически генерировалась диаграмма компонентов на языке PlantUML.
- Порядок инициализации и наличие циклов определялось топологической сортировкой.
- Композитный модуль строился на основе графа зависимостей подмодулей. Его зависимости — все интерфейсы, которые подмодули не реализовали сами, а реализованные контракты — подмножество таковых у внутренних модулей.
Сейчас в свободное от основной работы время занимаюсь библиотекой для дотнета: https://github.com/Kirill-Maurin/FluentHelium
Доклад по теме (прошлый февраль): https://www.youtube.com/watch?v=Gd9Ze7-CIb0&t=1005s
DI-контейнеры как есть для модульности пригодны только ограниченно: с прозрачностью и рекурсивностью у них никак.
Надо бы найти время и сделать-таки серию постов.
mayorovp
05.04.2018 09:45Хм. Кажется что ваш интерфейс IModule нарушает ваше же требование ортогональности… Но в случае COM по-другому просто не сделать, ведь для coclass нельзя объявить особый конструктор.
Bonart
05.04.2018 09:55Кажется что ваш интерфейс IModule нарушает ваше же требование ортогональности
Интерфейс — не нарушает.
Ортогональность соблюдена — и внутри, и снаружи модуля может быть что угодно, в отличие от требований фреймворков.
От COM взяли только базовые интерфейсы с GUID и счетчиками ссылок: Delphi в них умеет из коробки.
Реестр и прочее ActiveX барахло не использовалось.mayorovp
05.04.2018 09:59Я говорю не о реестре. Интерфейс IModule является частью инструмента для организации модульности, и все модули которые его реализуют — он зависят от этого инструмента. Через этот интерфейс инструмент для организации модульности диктует модулям как они должны выглядеть. То есть инструмент для организации модульности становится (микро)фреймворком, а не библиотекой.
Bonart
05.04.2018 10:53Фреймворк определяет структуру проекта.
Интерфейс же не мешает как реализовать модуль средствами на свой выбор, так и встроить реализованное в уже имеющийся проект.
Пример: двусторонняя интеграция с Autofac, можно как сделать модуль из контейнера, так и зарегистрировать модуль в вышестоящем контейнере
github.com/Kirill-Maurin/FluentHelium/blob/master/FluentHelium.Autofac/AutofacModuleExtensions.csmayorovp
05.04.2018 11:18Вот только чтобы сделать модуль из контейнера — вам нужно сначала вручную сформировать для него дескриптор, для чего нужно найти все зависимости. То есть сделать ту работу, которую обычно неявно делает Autofac…
Bonart
05.04.2018 11:40-1То есть сделать ту работу, которую обычно неявно делает Autofac…
Autofac, как и другие DI-контейнеры, эту работу вообще не делает ни явно, ни неявно. Нет метода, который вернул бы исчерпывающий список неразрешенных зависимостей. Только рантайм, только хардкор, только при попытке резолва из заранее сконфигурированного контейнера.
mayorovp
05.04.2018 12:30Он их определяет, только не собирает в один список.
Bonart
05.04.2018 12:47-1Он их определяет, только не собирает в один список.
Этого он тоже не делает.
Максимум, что умеет Autofac: при попытке разрешения найти первую неразрешаемую зависимость или цикл, после чего выкинуть исключение или вернуть false для TryResolve().
Эта работа годится только для минимальной индикации ошибок конфигурации контейнера.
Для задач модульности это и слишком поздно, и слишком мало.
Так определяется непрозрачность и нерекурсивность контейнеров:
- Граф зависимостей неявный
- Автоматическое определение зависимостей работает для типов, но не для контейнеров.
- До попытки разрешения не работает практически ничего.
С моей библиотекой можно построить явный граф зависимостей, определить циклы и неразрешенные зависимости еще до инициализации самих модулей.
Отсюда и велосипедостроение: я, к сожалению, не видел ни одной библиотеки, которая умела бы это из коробки.mayorovp
05.04.2018 12:57Вы осознаете что невозможно разрешить зависимость если само существование зависимости неизвестно? Очевидно, что внутри Autofac есть код который эти зависимости определяет, только результат его работы вам не виден.
Bonart
05.04.2018 13:16- Нет никакой необходимости разрешать зависимости до тех пор, пока не начата инициализация модулей.
- Список неразрешенных зависимостей для графа модулей необходимо построить заранее: это позволяет разрешить их за счет ядра или заявить как зависимости композитного модуля.
Autofac ничего из этого не умеет, превращая разрешение зависимостей в игру "Сапер" периода выполнения без индикации числа соседних мин.
Очевидно, что внутри Autofac есть код который эти зависимости определяет
Очевидно, что никакого списка зависимостей для дексриптора модуля Autofac создать не может, следовательно ваш тезис из цитаты ниже неверен.
Вот только чтобы сделать модуль из контейнера — вам нужно сначала вручную сформировать для него дескриптор, для чего нужно найти все зависимости. То есть сделать ту работу, которую обычно неявно делает Autofac…
mayorovp
05.04.2018 13:21Вы все пытаетесь рассказать как оно выглядит снаружи, а я говорю про то что происходит внутри.
Bonart
05.04.2018 13:35Ваш исходный тезис содержал посылку про якобы имеющееся дублирование работы Autofac.
Это очевидно неверно «снаружи».
Под капотом Autofac тоже ничего подобного не делает, по крайней мере на момент моего копания в его исходниках.
В нем нет выделенной функциональности построения графа зависимостей. Нет и анализа с целью определения исчерпывающего списка неразрешаемого в рамках имеющихся регистраций.
Autofac только пытается разрешать зависимости на лету, неразрешаемое он специально не ищет.mayorovp
05.04.2018 13:38Нет, я говорил именно про происходящее внутри.
Для того, чтобы превратить контейнер в модуль вашего формата, разработчик должен найти все зависимости и перечислить их.
Autofac тоже внутри ищет зависимости и разрешает их в правильном порядке. Но вторая задача намного проще первой.
И если я сам найду и определю все зависимости — мне уже не нужен Autofac, вот в чем проблема.Bonart
05.04.2018 13:59И если я сам найду и определю все зависимости — мне уже не нужен Autofac, вот в чем проблема.
Нет такой проблемы.
- То, что надо реализовать определяется не контейнером, а постановкой задачи.
- То, что надо выставить как зависимости — это НЕ список всех зависимостей в контейнере, это список только тех из них, которые не разрешаются внутри самого контейнера.
- Список таких зависимостей также определяется при постановке задачи — проектируя модуль, вы решаете, что он НЕ должен обеспечивать сам.
- Если уровнем выше использовать композитный модуль, то он сможет определить неразрешенные зависимости подмодулей автоматически и выставить их как свои — тут контейнер действительно может быть лишним.
- За связи, невидимые снаружи модуля, контейнер отвечает по-прежнему и нужен внутри модуля именно с
этой целью. - Простой для реализации модуль, конечно же, проще сделать без контейнера.
- В случае использования модуля, снаружи у вас может быть один контейнер, внутри другой, но оба они друг о друге ничего не знают и никак друг от друга не зависят.
- Это показатель реальной автономности модулей
BerkutEagle
Мне кажется, что все описанные проблемы — это следствие неверного первого шага (выделение).
Если мы начинаем вносить правки в функционал блока C в зависимости от «хотелок» зависимых систем — уже что-то пошло не так! Тем более, если эти правки специфичны.А проблемы неактуальности документации, потери автономности, поддержки качества, версионирования присущи практически всем более-менее крупным проектам. Они не исчезнут при отсутствии повторного использования.
Deosis
Вместо расширения функционала С можно вынести специфичное поведение в А.
Проблема только в том, что от С тогда может вообще ничего не остаться.
mayorovp
Если от C ничего не остается после вынесения специфичного поведения в A и B — значит, никакого C никогда не существовало, и выделение его в отдельную библиотеку — одна большая ошибка.
prospero78su
У вас была система А. ПОТОМ потребовалась система В. О том, что она вам потребуется — на этапе создания А — вы НЕ ЗНАЕТЕ. В системе В вам нужна немного изменённая подсистема С, для чего вам нужно залезть в работающий проект А, затратить ресурсы на явное выделение С, внесение изменений в работающий проект А, после чего провести тестирование на совместимость, оповестить заинтересованных клиентов (что на подписке) и т. п. Через некоторое время, у вас появляется система D…
BerkutEagle
Лично я считаю, что сначала надо дублировать, а уже потом, на этапе оптимизации, выносить дублирующийся код в отдельный модуль.
Иначе можно преждевременно оптимизировать до бесконечности.
Кривая развития каждого проекта петляет по-своему, и будущее не предопределено, поэтому стоя на берегу сложно выбрать между «пилим всё монолитно в А» и «сразу раскидываем функционал в А и С, вдруг пригодится».
Выбрав первый вариант можно сесть в лужу, когда появится В (но это если появится), выбрав второй — можно убить втрое больше времени на создание подсистем А и С, упустить клиентов, а потом ещё окажется, что В и не будет никогда, или будет, но работать с А и С в текущем варианте не сможет.
prospero78su
Всегда оптимизацию надо оставлять на потом. Сделать красиво важно, но сначала, чтобы хотя бы просто работало. Потом — немного напильника будет полезно.
playnet
Обычно такой подход означает МНОГО напильника, гораздо больше чем заранее заложенная возможности модульности. Но это при условии что будет несколько проектов. Когда был 1, и решили сделать второй — такого предположения не должно быть.
Ну и пока делаем «чтобы просто работало» — вполне можно делать быстро и как получится, а когда стабилизированы хотелки, апи и прочее — тогда начать делать новую версию, с нуля, с нужными разделениями и вероятно на более подходящем языке. Не затягивать этот процесс, а то легаси с детским кодом потом много лет будет аукаться.
prospero78su
Такой подход не предполагает много напильника. Много напильника требуется тогда, когда старший в группе — такого же детсадовского возраста, как и вся команда.
Иногда есть смысл и сделать новую версию. На счёт более подходящего языка — я против таких решений. Язык должен быть один с самого начала. И скилл прокачивается до зашкаливающего уровня, и переключение между особенностями кода в разы меньше. При использовании, скажем питона и фрипаскаля — разница между одним и тем же кодом будет угрожающей.
shuron
Дык вот реальность во многих коммандах именно такая. Плохо или с недостатком опыта обдуманное (см. ссылку на «Что видишь, то и есть») выделение "общего кода"…
Причем на моей памяти именно аргумент DRY, который не так легко паррировать в тех же самых кругах ;)