

Наши клиенты хранят списки из тысяч компаний, и обычно там первозданный хаос.
Возьмем список торговых точек, через которые сельхозпроизводитель продает товары по всей стране. Названия магазинов пишут как хотят, поэтому типичный список выглядит так:
- Евразия.
- «САКУРА» Японская кухня.
- Доминант.
- Магазин-бутик «Евразия».
- Милениум, ООО, продуктовый магазин.
- Киви/ООО/Челябинск.
- Супермаркет эко-продуктов «Доминант».
Точки № 1 и № 4 — дубли, № 3 и № 7 — тоже, но поди разберись.
А разобраться надо: когда в списке из 1000 торговых точек 300 дублей, у производителя начинаются проблемы.
- Проваливается план продаж. Думаешь, что продаешь через 1000 магазинов, а на самом деле 300 из них — дубли;
- торговые представители занимаются непонятно чем. Торгпреды должны гонять по точкам, наводить порядок на полках и дозаказывать товар. Если в базе дубли, персонал получает непонятные маршруты и работает вхолостую.
Первая реакция — почистить руками живых операторов. Бесполезно. Люди все равно ошибаются, потому что названия порой пишут уж совсем экзотически. Да и дорого выходит.
Мы взялись за проблему с перебора готовых решений.
Готовые инструменты не подходят
Старый добрый Excel очевидно не справится с задачей, потому что условие дублирования
«Дадатовский» поиск дублей физических лиц, тоже не подошел. Он сравнивает людей по ФИО, адресу и дополнительным полям вроде телефона. Но алгоритм сравнения ФИО не подойдет для названий, а находить дубли по одному только адресу нельзя: любой ТЦ с кучей отделов-бутиков сломает всю статистику.
Оставался еще шанс: у нас есть enterprise-движок «Фактор», который приводит названия к виду ЕГРЮЛ — госреестра юрлиц. Но и он не помог: название точки часто не имеет отношения к названию юрлица. Если ООО «Вектор+» назвало магазин «Уют», в отчет пойдет «Уют». ЕГРЮЛ не поможет.
В итоге мы взяли поиск дублей по физическим лицам и доработали. Адреса он и так сравнивал, нужно было научить его сравнивать названия.
Находим смысловую основу названия
Чтобы сравнить названия компаний, нужно сначала очистить их от шелухи — найти смысловую основу. Мы это делаем регулярными выражениями.
Чистим пунктуацию:
- добавляем пробелы после запятых;
- меняем зачеркивания на пробелы;
- удаляем из названия все, кроме букв, цифр и пробелов.
Удаляем все, что попадает в типичные паттерны. Наш аналитик просмотрел 10 000 записей в отчетах о торговых точках. В итоге он составил базу паттернов, которые замусоривают названия. «Дадата» удаляет:
- типы торговых точек: «прод. магазин», «минимаркет», «супермаркет», «универмаг», «эко-магазин», «сеть магазинов» и т. д.;
- все, что в скобках и после них: «Социальная Аптека 6 (104, г.Батайск)» > «Социальная Аптека 6»;
- все, кроме первого слова, если три слова записаны через слэш: «Башмедсервис/ООО/Челябинск» > «Башмедсервис». Вероятно, в таком формате названия выгружают из учетных систем или реестров, потому что проблема очень частая;
- город из начала: «КРЫМСК, ООО *БЕРЕЗКА*» > «ООО *БЕРЕЗКА*»;
- адрес из хвоста: «ООО „Нордекс М“ г.Апатиты Мурманская область» > «ООО „Нордекс М“»;
- хвост после ОПФ: «Статус ООО ДОГОВОРА НЕТ» > «Статус ООО».
Если захотеть, обойти алгоритм просто: паттернов немного. Но проблемы с дублями появляются из-за отсутствия стандартов, а не злого умысла. В реальной жизни перечисленного хватает.
Удаляем ОПФ: ЗАО, ОАО, ПАО и расшифровки типа «откр. акц. общ.».
В результате от названий компаний остаются только смысловые части, которые и сравнивает «Дадата».
Сравниваем смысловые основы и адреса
Само по себе совпадение названий — очень слабый критерий. Поэтому в «Дадату» обычно загружают еще и адрес, а иногда — телефон.
Сервис находит смысловые основы названий и стандартизует адреса. И начинается собственно дедупликация: «Дадата» собирает записи из входных файлов в кучу и сравнивает каждую с каждой.
Алгоритм проверяет пары по сценариям, всего их десять. Примеры:
| Сценарий | Вероятность дубля |
|---|---|
| Названия совпадают, остальные поля пустые | 100% |
| Названия похожи, адреса совпадают | 95% |
| Названия совпадают, адрес отличается расширением номера дома (литерой, буквой и т. д.) | 95% |
| Названия похожи, телефоны совпадают | 70% |
- если основы оканчиваются числом, и числа отличаются, «Дадата» считает названия разными. Иначе под фильтр попадут, например, «Социальная аптека Доктор Живаго 12» и «Социальная аптека Доктор Живаго 13»;
- у совпадения адресов бо?льший вес, чем у совпадения названий. Если названия совпадают на 60%, а адреса — на 100%, то вероятность дубля — 95%;
- среди сценариев, которые подходят паре записей, «Дадата» выбирает тот, что дает наибольший процент похожести.
Когда сервис нашел вероятность дублей, он выносит вердикт:
- > 85% похожести — гарантированный дубль. Можно автоматически сливать записи в одну;
- < 85% — возможно, дубль. Система маркирует записи меткой «похожие» и ID. По ID в итоговом файле пользователь выбирает группы похожих записей;
- если ни один сценарий не подошел, значит, записи разные.
Наш алгоритм не найдет все дубли как 100%. Похожие точки он просто пометит, чтобы оператор разобрал их руками. Тут есть простор для доработок, мы еще будем его допиливать.
Пусть трудятся роботы
Тем временем мы в 10 раз снизили цены на поиск дублей. Теперь «Дадата» ищет одинаковых людей и компании всего по 1 копейке за обработанную запись.
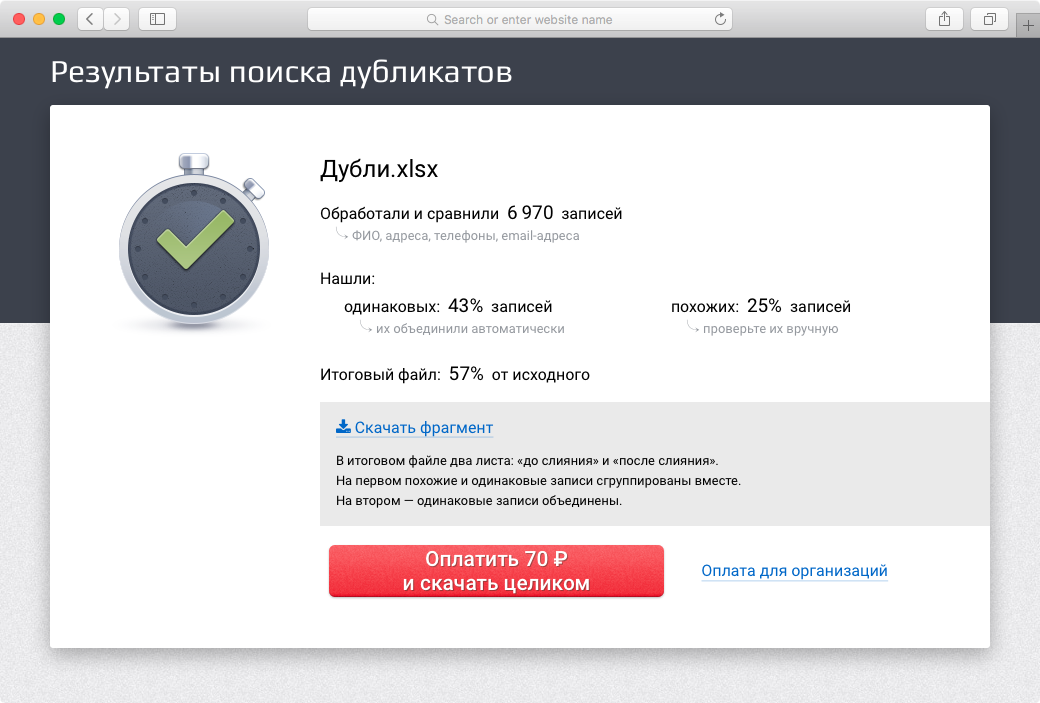
«Дадата» сначала примет файлы и покажет число дублей, и только потом спросит, хотите ли вы платить
Регистрируйтесь, заливайте файлы — и можно чистить от дублей списки торговых точек, контрагентов, клиентов, кого угодно.
Комментарии (11)

AndreyMtv
28.11.2017 17:00Расскажите клиентам, что у магазинов ИНН/КПП существуют. Ах, да, тогда вы им не нужны будете…
Производитель не знает с кем заключает договора, не в курсе инн, кпп клиентов их юридических и физических адресов, только названия (написанные на клочке помятой газеты).
И тут появляется Герой на белом коне и всех спасает.
Ugrum
28.11.2017 17:15+2Расскажите клиентам, что у магазинов ИНН/КПП существуют
Да вы чо? Правда что ли? У всех магазинов?
Вы немного не в теме, похоже.
Магазин (условно)-«Эльдорадо», у него есть только адрес и телефоны, возможно сайт, а вот юрлицо, фактически ведущее коммерческую деятельность в это магазине, (условно)-ООО «Эльтрейд», вот у него уже есть ИНН/КПП, которые будут регулярно меняться (в наших экономических реалиях), со сменой юрлица.
mapatka
28.11.2017 17:50Зря вы так.
Дадата крутой сервис.
Я, правда, использую как частное лицо) Когда письма отправляю — пробиваю индекс.AndreyMtv
28.11.2017 17:57-1Ну вот. Есть же реальные клиенты у них, с реальными потребностями. Почему бы не описать несколько реальных задач вместо высосанной из пальца легенды.
rmpl
29.11.2017 00:42Just in case — ИНН у сетки филиалов будет общий, удачи в попытке их различить :)
AndreyMtv
28.11.2017 17:50-1Нереальный юзеркейс абсолютно. Какой то сферический агропроизводитель доставляет товары по всей стране, при этом не знает кому именно он их доставляет. При этом зачем то завел в базу 30% дублей.

Akuma
28.11.2017 22:40Вот вы сметесь, а оно примерно так и есть.
Связывать магазин и ИНН, как вы указывали выше, не получится, т.к. магазин может часто менять юрлиц, а может быть разное юрлицо у разных магазинов в пределах города и т.п.

JosefDzeranov
28.11.2017 18:01iodzeranov.ru/olympiad_tasks_backend2 также имел возможность решать такую задачу, реализовывал подобным образом.
dabar347
>город из начала: «КРЫМСК, ООО *БЕРЕЗКА*» > «ООО *БЕРЕЗКА*»;
А не приведет это к ложным срабатываниям? В разных городах могут быть разные магазины с одинаковым названием (если мне память не изменяет это должно быть легально).
nalgeon
В связке с адресом — не приведёт. А торговые точки всегда именно в паре с адресами идут.
dabar347
А ну тогда отлично. А вообще интересное решение кейса.