
Новые инструкций, такие как Intel Software Guard Extensions (Intel SGX) и Intel Control-flow Enforcement Technology (Intel CET), также способны предоставить абсолютно новую функциональность.

Хороший вопрос заключается в том, как скоро новые инструкции, добавленные в архитектуру, достигают конечного пользователя. Могут ли операционные системы и другие приложения воспользоваться новыми инструкциями, принимая во внимание, что они, как правило, обеспечивают обратную совместимость и способность исполняться независимо от модели установленного процессора? Много лет назад использование новых инструкций достигалось с помощью пересборки программы под новую архитектуру и добавления проверок, предотвращающих запуск на старой аппаратуре и печатающих что-то вроде “sorry, this program is not supported on this hardware”.
Я воспользовался полноплатформенным симулятором Wind River Simics, чтобы узнать, в какой степени современное программное обеспечение способно использовать новые инструкции, оставаясь при этом совместимым со старым оборудованием.
Экспериментальная установка
Чтобы выяснить, насколько программное обеспечение может динамически адаптироваться к различному оборудования, я воспользовался Simics моделью «generic PC» платформы и двумя различными моделями процессоров: Intel Core i7 первого поколения (кодовое имя Nehalem, выпущен в конце 2008 года) и Intel Core i7 шестого поколения (кодовое имя Skylake, выпущен в середине 2015).
Исследовались следующий сценарии загрузки ОС Linux, запускаемые на описанный выше конфигурациях:
- Ubuntu 16.04, версия ядра 4.4, год выпуска 2016,
- Yocto 1.8, версия ядра 3.14, год выпуска 2014,
- Busybox с ядром 2.6.39, год выпуска 2011.
Один и тот же образ диска использовался для тестирования, тем самым гарантируя, что программный стек останется неизменным. Отличалась только конфигурация процессора в виртуальной платформе. Ожидалось, что Linux, работающий на более новом оборудовании, будет использовать новые инструкции. Каждая конфигурация запускалась с подключенным механизмом инструментации, который считал, сколько раз выполнилась каждая инструкция. Существующий в Simics механизм для инструментации не изменяет поведения гостевых приложений и позволяет изучать загрузку BIOS и ядра операционной системы за счет того, что оперирует на уровне команд процессора. При этом исполняющиеся приложение не может определить, запущено оно с инструментацией или без. Каждая конфигурация исполнялась по 60 секунд виртуального времени. Этого достаточно, чтобы загрузить BIOS и операционную систему. После каждого запуска выбиралось по 100 наиболее часто используемых инструкций, которые использовались для дальнейшего анализа.
Изучение основ идентификации процессоров
В основе данной работы лежит предположение о том, что программное обеспечения может динамически адаптировать исполняемый код в зависимости от используемого оборудования. То есть одна и та же бинарная структура может использовать различные инструкции на разном оборудовании.
Для того, чтобы понять, как работает подобная динамическая адаптация нужно разобраться с тем, как работает железо. Далеко в прошлом, когда процессоров было мало и новые модели появлялись достаточно редко, программное обеспечение могло легко проверить, происходит ли исполнение на Intel 80386 или 80486, Motorola 68020 или 68030 и адаптировать свое поведение соответствующим образом. Сейчас же существует огромное количество разнообразных систем. Для решения задачи идентификации на IA-32 процессорах следует использовать инструкцию CPUID, которая сама по себе является сложной системой, описывающей различные аспекты оборудования.
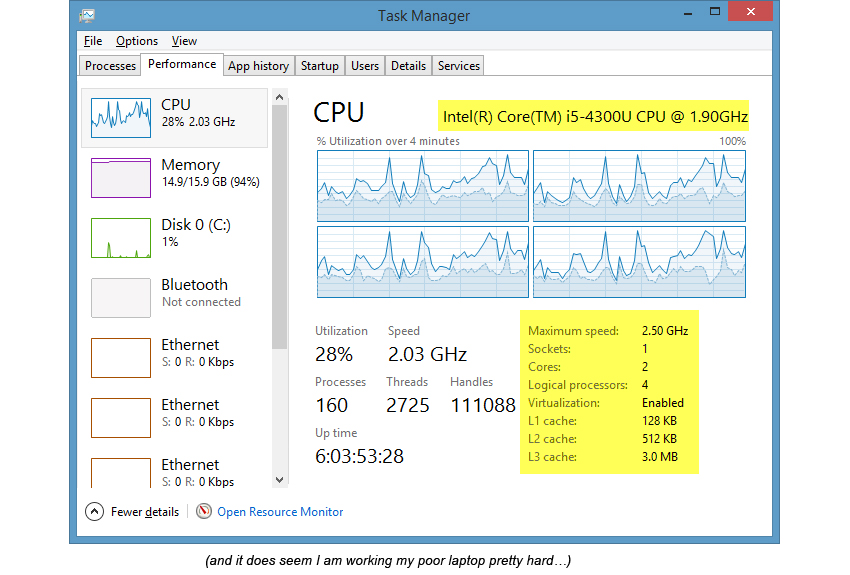
Вы, наверняка, уже встречали информацию, полученную с помощью инструкции CPUID, даже не задумываясь о ее источнике. Например, Task Manager в Microsoft Windows 8.1 показывает информация о типе процессора и некоторых других его характеристиках, которые получены с помощью инструкции CPUID:
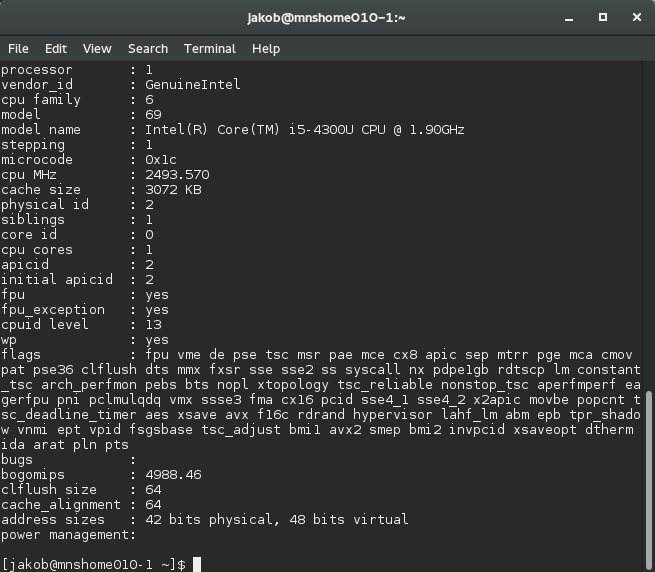
На Linux команда «cat /proc/cpuinfo» способна показать исчерпывающую информация о процессоре, включающую флаги расширений набора команд, которые доступны в текущей системе. Каждое расширение имеет свой флаг, наличие которое программное обеспечение должно проверить перед началом исполнения. Вот пример информации, собранной на процессоре Intel Core i5 четвертого поколения:
CPUID предоставляет информацию о различных расширениях набора команд, доступных в процессоре, но как программное обеспечение на самом деле использует эти флаги для того, чтобы выбрать соответствующий бинарный код в зависимости от аппаратуры? Не разумно было бы применять «if-then-else» конструкцию в каждом месте, которое собирается использовать «нестандартные» инструкции. Достаточно сделать проверку только один раз, так как эти характеристики не изменятся в течении сессии.
Linux обычно использует указатели на функции, использующие различные инструкции для реализации одной и той же функциональности. Хороший пример можно найти в файле arch/x86/crypto/sha1_ssse3_glue.c (источник elixir.free-electrons.com/linux/v4.13.5/source):

Эти функции проверяют наличие определенной функциональности и регистрирует соответствующую hash функцию. Порядок вызова гарантирует, что будет использована наиболее эффективная реализация. Конкретно в данном случае наилучшее решение основывается на инструкциях расширения SHA-NI, но, если они не доступны, используются AVX или SSE реализации.
Результаты
Приведенный ниже график содержит результаты запуска шести разных конфигураций (два процессора и три операционные системы). Он показывает все инструкции, количество которых превышает 1% от общего числа в каком-либо запуске. «v1» означает запуск на модели Core i7 первого поколения, «v6» — шестого.
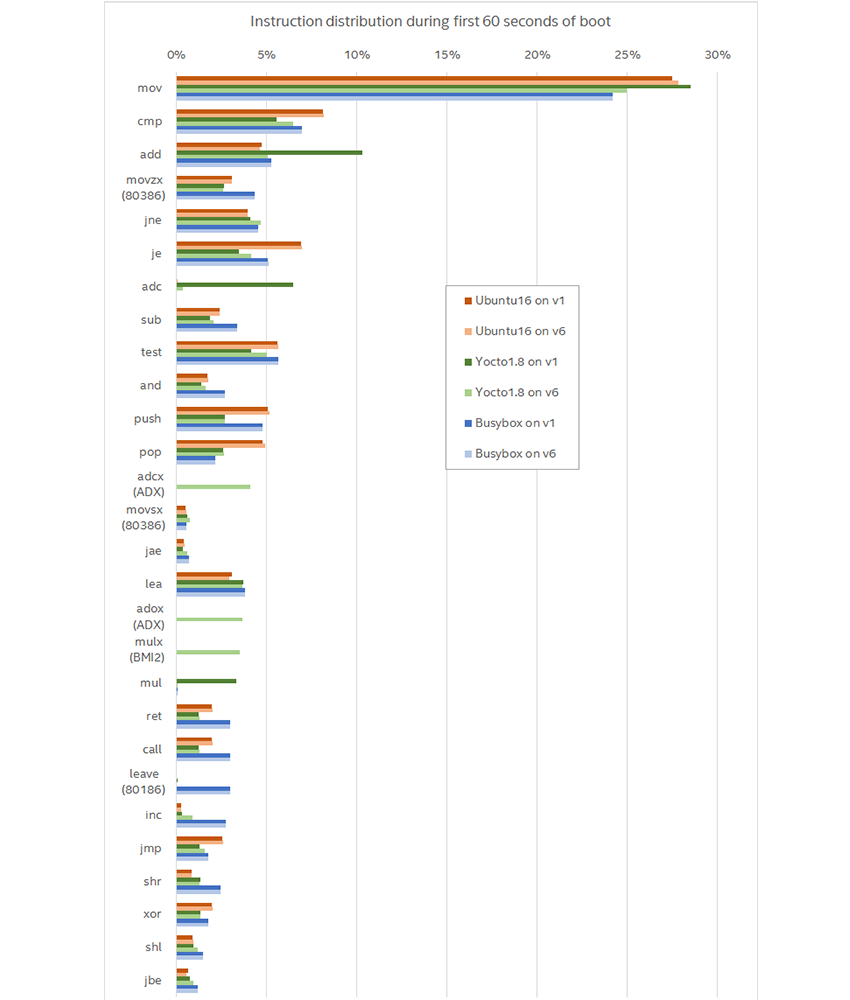
Первый вывод, который напрашивается: большинство инструкций не очень то и новые. Они скорее относятся к базовым инструкциям, добавленным еще в Intel 8086: move, compare, jump и add. Для более новых инструкций в скобочках написано название расширения, в котором они были добавлены. Всего шесть более или менее новых инструкций в списке из 28 наиболее часто используемых.
Очевидно, что присутствует вариации между различными версиями Linux вдобавок к вариациям, вызванным использованием разных процессоров. Например, BusyBox, сконфигурированный со старым ядром, использует инструкцию LEAVE, которая не является популярной для других версий ядра, к тому же он значительно меньше использует инструкцию POP. Однако это не дает ответ на вопрос, как программное обеспечение использует новые инструкции, когда они доступны. Для нашей цели наиболее интересны вариации, вызванные сменой поколения процессора при запуске одного и того же программного стека.
Все исследуемые в рамках данной работы сценарии представляют собой загрузку операционной системы Linux с различными параметрами ядра. К тому же различные дистрибутивы могут быть собраны разными версиями компилятора с использованием различных флагов. Таким образом бинарный код, даже собранный с использованием одних и тех же исходников, может отличаться.
На примере Yocto, мы видим этот эффект. Yocto использует инструкции ADCX, ADOX и MULX (входящие в расширения ADX и BMI2). Этот пример также хорошо демонстрирует скорость, с которой новые инструкции могут появиться в программном обеспечении. Эти три инструкции были добавлены в процессоре Intel Core пятого поколения, который был выпущен примерно одновременно с Linux ядром, используемым в Yocto. То есть поддержка новых инструкций была добавлена к моменту появления процессора на рынке. И это не удивительно, так как спецификация к новым инструкциям зачастую публикуется раньше, чем их аппаратная реализация. То есть программное обеспечение может заранее адаптировать свое поведение (интересная статья на эту тему) под новую аппаратуру, зачастую используя виртуальные платформы для отладки и тестирования.
Однако Ubuntu 16.04 с более новым ядром не использует ADX и BMI2, что говорит о том, что оно было сконфигурировано по-другому. Возможно, это связано с версией или флагами компилятора, параметрами ядра или набором установленных пакетов.
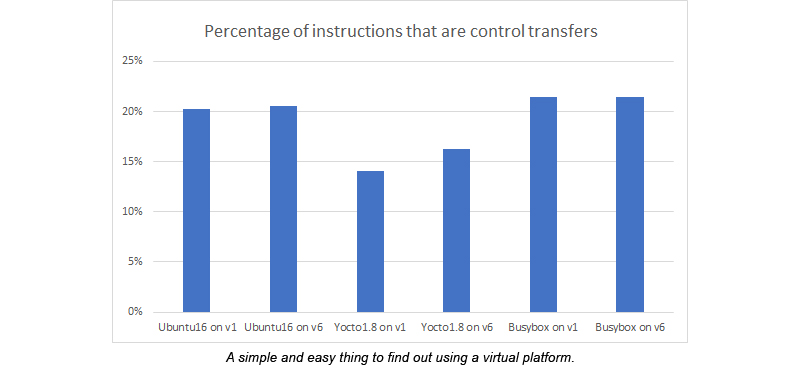
Изменение потока управления
Еще одна вещь, на которую было интересно обратить вникание — какие инструкции используются для изменения потока управления. Классическое правило, описанное в не менее классической книге Хеннесси и Паттерсона гласит, что каждая шестая инструкция — Jump. Однако проведенные измерения показали, что примерно одна инструкция из пяти является инструкцией, изменяющей поток управления. Ближе к одной из шести для Yocto.
Векторные инструкции
Пожалуй, наиболее известные общественности расширения набора команд — это Single Instruction Multiple Data (SIMD) или, иначе говоря, векторные инструкции. Векторные инструкции присутствуют в IA-32 процессорах, начиная с расширения MMX, добавленного в Intel Pentium в 1997 году. Сейчас наличие MMX инструкций фактически гарантировано. Можно заметить, что некоторые из них присутствуют на графике самых популярных инструкций. Далее было добавлено множество различных Streaming SIMD Extensions (SSE) инструкций и наиболее новые AVX, AVX2 и AVX512.
Я не ожидал большого количества векторных инструкций, учитывая, что изучалась загрузка операционной системы и BIOS. Однако примерно 5-6% исполненных инструкций оказались векторными. Количество исполненных векторных инструкций, измеренное как процент от общего количества выполненных инструкций и сгруппированное по расширениям:
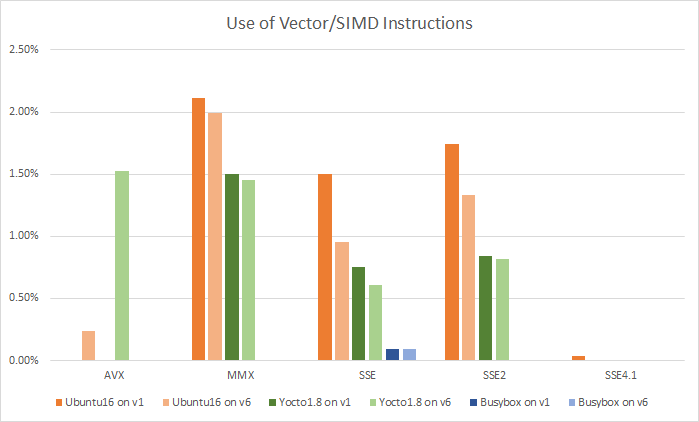
Первое, что бросается в глаза — Busybox фактически не использует векторные инструкции. Следующее интересное наблюдение заключается в том, что, при смене процессора первого поколения на процессор шестого, количество более старых инструкций уменьшается, а количество новых растет. В частности, прослеживается замена старых SSE инструкций, на более новые AVX и AVX2.
Simics
Как было сказано в самом начале, провести данное исследование с помощью Simics было не сложно. Очевидным образом, Simics имеет доступ ко всем инструкциям, исполняющимся на всех процессорах в моделируемой системе (данные эксперименты проводились на двухъядерной системе, однако второе ядро не выполняло никаких инструкций во время загрузки). Сценарии были полностью автоматизированы, включаю выбор устройства, на котором установлена ОС, ввод имени пользователя и пароля в конце загрузки. Каждый сценарий запускался один раз, так как повторные запуски покажут точно такие же результаты (мы исследуем повторяющиеся сценарии, начинающиеся с одного и того же места).
Заключение
Было поучительно узнать, как программные стеки адаптируются и используют новые инструкции на более новых процессорах. Современные программы адаптивны и будут исполнять различный код в зависимости от используемой аппаратуры без перекомпиляции. Во всех изученных сценариях один и тот же программный стек использовался на разных моделируемых системах, при этом используя разные инструкции в зависимости от их доступности. Исследование представляет собой отличный пример данных, которые с легкостью могут быть получены с помощью моделирования, но едва ли могут быть собраны на реальной аппаратуре.
Комментарии (30)
Sdima1357
30.11.2017 16:32Абсолютно бессмысленный тест. Бинарные сборки компилируются для охвата большинства компьютеров присутствующих на рынке. Идеология Unix — совместимость на уровне исходного кода, а не бинарников. Поэтому «run time» адаптацию под процессор почти никто не делает. Хотите использовать расширенные инструкции в ядре — перекомпилируйте ядро на своей машине.Хотите использовать расширенные инструкции в приложении — перекомпилируйте приложение
DistortNeo
30.11.2017 19:44Хотите использовать расширенные инструкции в ядре — перекомпилируйте ядро на своей машине. Хотите использовать расширенные инструкции в приложении — перекомпилируйте приложение
Не совсем верно. Многие инструкции нужно использовать явно, да и для компилятора автоматическая векторизация кода — задача не из простых. Поэтому если в исходном коде не предусмотрено использование этих инструкций, то их не будет и в бинарнике.
Sdima1357
30.11.2017 19:53gcc очень неплохо справляется с векторизацией. Намного лучше, чем большинство известных мне программистов…
DistortNeo
30.11.2017 20:12+1Главный вопрос: а много ли существует задач, для которых векторизация вообще возможна?
Sdima1357
30.11.2017 20:26Это другой вопрос. Ну для обработки изображений все очевидно. Для ОС — наверное шифровка-дешифровка, контрольные суммы, те же memset-memcopy
DistortNeo
30.11.2017 19:53Замечание по разделу "векторные инструкции":
На деле используются только скалярные инструкции векторных расширений. Пример: арифметика с плавающей точкой. SSE-инструкции удобнее и эффективнее, чем их x87 аналоги. AVX же даёт выигрыш за счёт большего числа регистров (16 регистров в 64-битном режиме против 8 SSE). Другой пример: memset/memcpy — использование 256-битных регистров более эффективно, чем 128-битных.
Sdima1357
30.11.2017 20:19На деле используются только скалярные инструкции векторных расширений
Вы глубоко ошибаетесь. Вот простейший код test1.cpp:
void summ(float* src1,float* src2,int n) { for(int k=0;k<n;k++) { src1[k]+=src2[k]; } }
gcc -O4 -march=native -mavx -ffast-math -funroll-loops -S test1.cpp
// кусочек листа из середины
.L8:
vmovups (%rax,%r8), %ymm14
addl $8, %r13d
vaddps (%r10,%r8), %ymm14, %ymm15
vmovaps %ymm15, (%r10,%r8)
vmovups 32(%rax,%r8), %ymm0
vaddps 32(%r10,%r8), %ymm0, %ymm1
vmovaps %ymm1, 32(%r10,%r8)
vmovups 64(%rax,%r8), %ymm2
vaddps 64(%r10,%r8), %ymm2, %ymm3
vmovaps %ymm3, 64(%r10,%r8)
vmovups 96(%rax,%r8), %ymm4
vaddps 96(%r10,%r8), %ymm4, %ymm5
vmovaps %ymm5, 96(%r10,%r8)
vmovups 128(%rax,%r8), %ymm6
vaddps 128(%r10,%r8), %ymm6, %ymm7
vmovaps %ymm7, 128(%r10,%r8)
vmovups 160(%rax,%r8), %ymm8
vaddps 160(%r10,%r8), %ymm8, %ymm9
vmovaps %ymm9, 160(%r10,%r8)
vmovups 192(%rax,%r8), %ymm10
vaddps 192(%r10,%r8), %ymm10, %ymm11
vmovaps %ymm11, 192(%r10,%r8)
vmovups 224(%rax,%r8), %ymm12
vaddps 224(%r10,%r8), %ymm12, %ymm13
vmovaps %ymm13, 224(%r10,%r8)
addq $256, %r8
cmpl %r11d, %r13d
jb .L8
DistortNeo
30.11.2017 20:231. И много ли подобных кусков кода в ядрах операционных систем?
2. Часто ли критичный код компилируется с параметром оптимизации, большим, чем O2?Sdima1357
30.11.2017 20:41И много ли подобных кусков кода в ядрах операционных систем
Не могу Вам ответить, я занимаюсь обработкой изображений
Часто ли критичный код компилируется с параметром оптимизации, большим, чем O2
Если программа не работает с O3 или O4 — значит вы не умеете ее готовить :)
Справедливости ради, более или менее это стало нормально работать совсем недавно.
slonopotamus
01.12.2017 09:10Если я ничего не путаю, в ядре вообще нет работы с float'ами.
Насчет -O3 не могу с вами согласиться. В том же gcc просто тонны багов, которые не возникают при более безопасном -O2 и ниже. Пруфы добываются в их багтрекере. Причем из них большая часть самого неприятного характера — miscompilation, т.е. компилятор выдает бинарники которые делают не то что должна делать программа.
А зачем вы принудительно делаете -mavx? Пусть оно само решает, использовать его или нет, м?
- Гентушники обычно предпочитают более безопасный вариант:
-march=native -mtune=native -O2
Sdima1357
01.12.2017 12:341 естественно нет. Зато есть int32 в soft raid например и не только там
2 в целом согласен, однако баги исправляются, а в заголовке статьи речь идёт не только об ОС но и о приложениях.
3 потому что я хочу в данном коде именно AVX, а не SSE 4.2 например
4 а Вы попробуйте скомпилировать с О3. Если Ваша программа перестала работать то 99.9% это именно баги в исходном коде а не компиляторе.
Во многом проблемы с компилятором связанны именно с интелем. Весьма экзотические ограничения на выравнивание памяти для векторных инструкций, впрочем ситуация исправляется потихоньку. Большая часть крешей была связана именно с выравниваниемDistortNeo
01.12.2017 21:02а Вы попробуйте скомпилировать с О3. Если Ваша программа перестала работать то 99.9% это именно баги в исходном коде а не компиляторе.
А если падает сам компилятор? У меня такое один раз было.
Во многом проблемы с компилятором связанны именно с интелем. Весьма экзотические ограничения на выравнивание памяти для векторных инструкций, впрочем ситуация исправляется потихоньку. Большая часть крешей была связана именно с выравниванием
Эта проблема актуальна только для древних процессоров. Современные процессоры нормально работают с невыровненными данными, даже без значимого падения произодительности.
Sdima1357
01.12.2017 21:151 Уронить компилятор несложно… язык template полный по Тьюрингу.
2 Таких древних на руках ровно половина. Вам накидать код который будет валиться на выравнивании на старых i7?DistortNeo
01.12.2017 21:26> 2 Таких древних на руках ровно половина. Вам накидать код который будет валиться на выравнивании на старых i7?
Я знаю, что доступ к невыровненным данным с вызывает исключение на процессорах, не поддерживающих AVX. Но начиная с AVX, такой проблемы больше нет.
И да, из-за этого есть проблема с написанием legacy-кода, использующего только SSE. На своём компьютере всё работает прекрасно, но гарантии, что невыровненного доступа нет, нет.Sdima1357
01.12.2017 21:52«Но гарантии нет»
Ну вот я и говорю что проблема не с операционкой или компилятором, а с зоопарком процессоров на руках у пользователей и написать бинарные или даже в исходники для оптимальной работы на всём зоопарке просто нереально. Есть ещё и атомы всякие обрезанные и армы и мипсы и тд Линукс ведь много платформ поддерживает.

sumanai
01.12.2017 22:44Эта проблема актуальна только для древних процессоров. Современные процессоры нормально работают с невыровненными данными, даже без значимого падения произодительности.
Кроме х86 ничего нет? Хотя да, нету.DistortNeo
01.12.2017 22:49Кроме х86 ничего нет? Хотя да, нету.
А что, SSE/AVX где-то ещё есть?
sumanai
01.12.2017 22:51Нет, там есть невыровненные данные и всякие инструкции, с ними не работающие.

yulyugin Автор
04.12.2017 13:34А почему Вы решили, что SSE регистров только 8? В 64-битном их 16.
Intel® 64 and IA-32 Architectures Software Developer’s Manual:
In 64-bit mode, eight additional XMM registers are accessible. Registers XMM8-XMM15 are accessed by using REX prefixes
slonm
01.12.2017 12:06Библиотека OpenSSL содержит много оптимизаций. Часть из них задается при компиляции, а часть включается на основании определения поддерживаемых инструкций в рантайме

BD9
01.12.2017 17:03Почему-то ничего не сказано про винду.
При этом новые выпуски без новых инструкций не работают:
- Windows 8.0: The minimum system requirements for Windows 8 are slightly higher than those of Windows 7. The CPU must support the Physical Address Extension (PAE), NX bit, and SSE2.
- Windows 8.1: To install a 64-bit OS on a 64-bit PC, your processor needs to support CMPXCHG16b, PrefetchW, and LAHF/SAHF
Ничего не сказали про Clear Linux, который улучшала Intel (использование новых инструкций процессоров Intel).
Здесь сравнивают 15 выпусков Linux (в т.ч. — Clear Linux).yulyugin Автор
04.12.2017 13:28Винда описана в следующей статье этого цикла software.intel.com/en-us/blogs/2017/11/09/follow-up-how-does-microsoft-windows-10-use-new-instruction-sets
Могу тоже ее перевести.
masai
А насколько большой прирост быстродействия даст использование новых инструкций именно в ядре ОС? Оно всё же не занимается высокопроизводительными вычислениями. Скажем, хэши, как упоминалось в статье, можно хорошо оптимизировать. А в целом как? Есть смысл?
Marwin
учитывая современную любовь к насыщенному интерфейсу, теней и полупрозрачности, графическая подсистема могла бы получить заметный выигрыш от вектора особенно на мобильных процессорах
TrueMaker
На сколько я понимаю, за всё это отвечает графическая подсистема, а не сам CPU, разве не так?
Marwin
Насколько я понимаю, виндовый GDI не ускоряется видеокартой. Только, начиная с WPF, пошли подвижки
TrueMaker
Я без понятия, в общем-то, на счёт внутренних отрисовок в приложениях, но почти на 100% уверен что основные элементы, такие как окна, тени окон, просто тени (не рисуемые вручную) используют для этого графическую подсистему. В общем, кто-то знающий детали наверняка отпишет в этот тред.
lorc
Еще в win98 использовалось аппаратное ускорение для BitBlt: www.asmcommunity.net/forums/topic/?id=8610
Рисовать графику процессором — очень медленно.
Да и все современные графические системы (SurfaceFlinger, Weston, WPF, Xorg) пытаются делать композицию аппаратно. При чем аппаратно — это не OpenGL/Direct3D. Это — поддержка нескольких слоев видеокартой.
Например, для SurfaceFlinger — OpenGL является fallback опцией, если композицию не удалось сделать аппаратными средствами. А делать композицию на CPU, он, кажется, совсем не умеет.
Gumanoid
Некоторые новые инструкции предназначены именно для ускорения ядра, например XSAVEOPT, XSAVEC, XSAVES.