
Привет, Хабр! Публикуем перевод статьи Эмиля Вальнер, в которой он рассказал, как за 3 шага и 100 строк кода написать собственную нейронную сеть с ботом, который будет раскрашивать черно-белые изображения. Проект будет состоять из нескольких статей. В этой мы расскажем, как устроена альфа-версия модели, способная обучаться на одном изображении и его же сделать цветным, а в следующей части построим нейросеть, уже способную обобщаться на новые картинки.

Чтобы разогреть ваш интерес, начнем с того, что у меня получилось в самом конце проекта:

Исходные черно-белые изображения взяты с Unsplash
Сегодня раскрашивание старых фотографий все еще делается вручную в фотошопе. Чтобы оценить всю трудоемкость этого процесса, посмотрите это видео:
Если вкратце, то раскрашивание одной картины может длиться до месяца! К примеру, одно лишь лицо требует до 20 слоев розовых, зеленых и синих оттенков, чтобы в точности передать дух картины.
Сегодня я покажу, как можно построить собственную нейронную сеть по раскрашиванию изображений в 3 этапа. Эта статья рассчитана на новичков в deep learning. Поехали!
На первом этапе я объясню основную идею подхода, и мы построим простейшую нейросеть из 40 строк кода, в качестве альфа-версии нашего бота. Тут не будет никакой магии, но зато поможет ознакомиться с синтаксисом. Затем мы усложним задачу и построим нейросеть, которая сможет обобщаться на новые изображения, на которых она не была обучена.
Наконец, на последнем этапе я представлю финальную версию бота, соединив нашу нейронную сеть с классификатором Inception Resnet V2, предобученным на 1,2 миллионах изображений. Для обучения самой нейронной сети будем использовать картинки с Unsplash.
Если вам не терпится попробовать самим, то держите Jupyter Notebook с альфа-версией бота, а также все 3 версии его бота на FloydHub и GitHub вместе со всем проектом, который я тестировал на облачной платформе от FloydHub.
В этой части изучим, как рендерить изображение, основы цифровых изображений и основную идею работы нашей нейросети.
Идея весьма проста. Каждое черно-белое изображение может быть представлено в виде сетки пикселей, где каждому пикселю присваивается значение от 0 до 255 (от черного к белому), характеризующее его яркость.

В свою очередь цветные изображения состоят из 3 слоев: красного, зеленого и синего. Новичку это может показаться нелогичным, ведь, к примеру, если представить лист дерева на белом фоне, то, очевидно, что он представлен только зеленым слоем, о каком красном вообще речь?
На самом деле, цветное изображение действительно можно представить в виде трех слоев, каждый из которых определяет не только цвет, но и яркость итоговой картинки:

Таким образом, каждому пикселю в цветном изображении соответствуют три слоя, и, как и в случае с черно-белыми изображениями, значение яркости от 0 до 255. Так, если во всех трех слоях нули, то цвет пикселя — черный, если смешать все три компонента, то получится белый, а если добавить равное количество красного и синего, то зеленый будет бледнее:

Как известно, нейронная сеть решает задачу обучения с учителем, пытаясь оценить функцию взаимосвязи между входными данными и целевой переменной. Конкретно в нашей задаче нейросеть должна найти функцию, связывающую черно-белые изображения с цветными. Принимая на вход сетку значений яркости черно-белых пикселей, на выходе мы должны получать три сетки, соответствующие цветовым компонентам:

Начнем с простой нейросети, которая будет раскрашивать лицо девушки. Результат работы представлен ниже. Написав всего 40 строк кода, мы сможем перейти от первой картинки ко второй, а третья является исходной цветной фотографией. Модель обучена и протестирована на одной и той же фотографии — это будет исправлено в бета-версии.
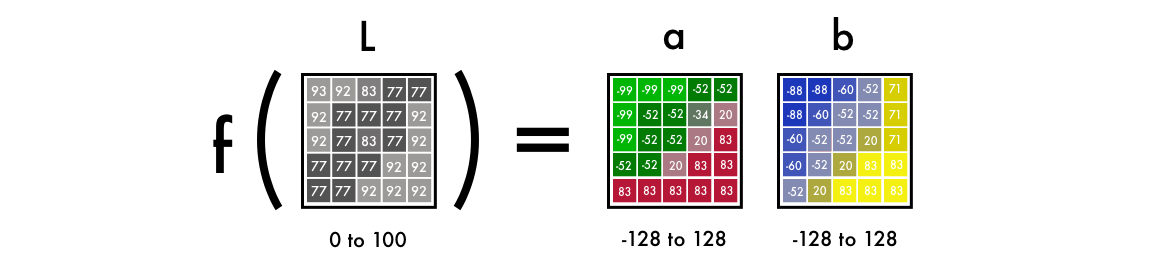
Цветовое пространство. Сначала необходимо изменить цветовые каналы на картинке с RGB на Lab, где L — освещение (lightness), а и b соответствуют красно-зеленому и сине-желтому цветам:
Как видно на картинке ниже, в модели Lab у изображения есть один слой в оттенках серого, а три цветовых канала были перекодированы в два. Кстати, научный факт — 94% клеток сетчатки глаза определяют яркость того, что мы видим, тогда как всего 6% распознают цвета. Также заметно, что черно-белое изображение более четкое, чем в a и b. Это одна из причин, почему стоит использовать его в качестве одного из слоев в конечном изображении.

Нейросеть. Идея нашей модели состоит в том, что, принимая на вход сетку значений черно-белого изображения, оцениваем два цветовых канала: ab в Lab. Затем, чтобы получить цветное изображения в качестве третьего слоя (L в Lab) добавляем исходное черно-белое изображение. В результате получаем Lab картинку:
Чтобы из одного слоя сделать два, будем использовать фильтры CNN (сверточной нейронной сети) — подобие синим/красным фильтрам в 3D очках. Каждый фильтр определяет, что будет изображено на картинке, они могут выделять или удалять что-то с изображения, чтобы извлекать нужную информацию. Затем нейросеть может создать новое изображение из фильтра, или соединить несколько фильтров в одну картинку.
Ниже представлен весь код для построения, обучения и тестирования нейросети. Его детали мы обсудим чуть позже.
Если вы никогда не пользовались FloydHub — облачной платформой для обучения и запуска deep learning моделей — то вы можете прочитать их 2-минутный гайд по установке или посмотреть мое 5-минутное видеоруководство или, наконец, прочитать эту пошаговую инструкцию. FloydHub — один из лучших и легчайших способов обучения моделей в облаке.
Как только FloydHub установлен, вставьте следующий код в командную строку:
Далее изменим рабочую директорию и запустим FloydHub:
Дашборд FloydHub откроется в вашем браузере. Затем вам придет запрос создать новый проект, названный colornet. Как только проект будет создан, вернитесь в командную строку и запустите ту же команду:
Теперь запустим нашу нейросеть:
Несколько замечаний:
Теперь мы будем работать в Jupyter Notebook. Под вкладкой Jobs на сайте FloydHub нажмите на ссылку Jupyter Notebook, а затем запустите скачанный файл:
Постепенно увеличивая параметр epochs (он регулирует, сколько раз нейросеть должна обучиться на данном изображении) c 1 до 10, 100, 500, 1000 и 3000 в model.fit(), посмотрите, как меняется качество обучения нейросети. Результат работы img_result.png вы можете найти в рабочей папке.
Еще раз: нейросеть принимает на вход сетку значений пикселей черно-белого изображения, а на выходе получаем две сетки с значениями яркости соответствующих цветов. Между входом и выходом мы создаем фильтры, чтобы соединить их вместе. Это и есть сверточная нейронная сеть. Когда мы обучаем модель, в качестве целевой переменной используем цветные изображения, конвертируя их из RGB в Lab:

Чтобы вычислить отклонение значений полученного изображения от исходного, мы должны отмасштабировать их на один интервал. Для этого воспользуемся функцией активации в виде гиперболического тангенса: каждому входному значению в ответ он выдает соответствующее в интервале от -1 до 1. Что нам и нужно.
В свою очередь, у исходного цветного изображения значения цветов находятся в интервале от -128 до 128, поэтому, разделив каждое из них на 128, мы и получим значения в том же интервале, что и оцененные моделью значения, и сможем посчитать ошибку.
После того, как ошибка посчитана, на следующей итерации обучения фильтры обновляются, уменьшая эту ошибку. Данный цикл продолжается, пока ошибка не упадет до минимального значения.
Теперь проясним некоторые детали в коде нейросети выше.
1.0/255 означает, что мы используем 24-битную RGB цветовую модель, то есть значения в интервале от 0 до 255 для каждого цветового канала и, соответственно, 16,7 млн цветовых комбинаций. В большем количестве нет нужды: люди могут воспринимать только до 10 млн цветов.
После изменения цветовой модели изображения с помощью функции rgb2lab() мы извлекаем его черно-белый слой, используя [:,:, 0], а команда [:,:, 1: ] выбирает два остальных: красно-зеленый и сине-желтый.
После окончания обучения модели мы создаем итоговое предсказание и конвертируем его в картинку, используя черно-белое изображение в качестве матрицы признаков X, а затем умножаем output на 128, чтобы получить правильные значения в Lab спектре.
Наконец, так как на выходе у нас получилось лишь два цветовых слоя, нам нужен третий — черно-белый. Поэтому мы создаем матрицу размера 400х400х3 для всех трех слоев, а затем копируем в нее output модели и сетку значений черно-белого изображения:
Увидимся в следующей статье, где мы научим нашу нейросеть обобщаться на новые картинки, которые она раньше не видела. Удачи!
Чтобы разогреть ваш интерес, начнем с того, что у меня получилось в самом конце проекта:
Исходные черно-белые изображения взяты с Unsplash
Сегодня раскрашивание старых фотографий все еще делается вручную в фотошопе. Чтобы оценить всю трудоемкость этого процесса, посмотрите это видео:
Если вкратце, то раскрашивание одной картины может длиться до месяца! К примеру, одно лишь лицо требует до 20 слоев розовых, зеленых и синих оттенков, чтобы в точности передать дух картины.
Сегодня я покажу, как можно построить собственную нейронную сеть по раскрашиванию изображений в 3 этапа. Эта статья рассчитана на новичков в deep learning. Поехали!
На первом этапе я объясню основную идею подхода, и мы построим простейшую нейросеть из 40 строк кода, в качестве альфа-версии нашего бота. Тут не будет никакой магии, но зато поможет ознакомиться с синтаксисом. Затем мы усложним задачу и построим нейросеть, которая сможет обобщаться на новые изображения, на которых она не была обучена.
Наконец, на последнем этапе я представлю финальную версию бота, соединив нашу нейронную сеть с классификатором Inception Resnet V2, предобученным на 1,2 миллионах изображений. Для обучения самой нейронной сети будем использовать картинки с Unsplash.
Если вам не терпится попробовать самим, то держите Jupyter Notebook с альфа-версией бота, а также все 3 версии его бота на FloydHub и GitHub вместе со всем проектом, который я тестировал на облачной платформе от FloydHub.
Основная идея
В этой части изучим, как рендерить изображение, основы цифровых изображений и основную идею работы нашей нейросети.
Идея весьма проста. Каждое черно-белое изображение может быть представлено в виде сетки пикселей, где каждому пикселю присваивается значение от 0 до 255 (от черного к белому), характеризующее его яркость.
В свою очередь цветные изображения состоят из 3 слоев: красного, зеленого и синего. Новичку это может показаться нелогичным, ведь, к примеру, если представить лист дерева на белом фоне, то, очевидно, что он представлен только зеленым слоем, о каком красном вообще речь?
На самом деле, цветное изображение действительно можно представить в виде трех слоев, каждый из которых определяет не только цвет, но и яркость итоговой картинки:
Таким образом, каждому пикселю в цветном изображении соответствуют три слоя, и, как и в случае с черно-белыми изображениями, значение яркости от 0 до 255. Так, если во всех трех слоях нули, то цвет пикселя — черный, если смешать все три компонента, то получится белый, а если добавить равное количество красного и синего, то зеленый будет бледнее:
Как известно, нейронная сеть решает задачу обучения с учителем, пытаясь оценить функцию взаимосвязи между входными данными и целевой переменной. Конкретно в нашей задаче нейросеть должна найти функцию, связывающую черно-белые изображения с цветными. Принимая на вход сетку значений яркости черно-белых пикселей, на выходе мы должны получать три сетки, соответствующие цветовым компонентам:
Альфа-версия
Начнем с простой нейросети, которая будет раскрашивать лицо девушки. Результат работы представлен ниже. Написав всего 40 строк кода, мы сможем перейти от первой картинки ко второй, а третья является исходной цветной фотографией. Модель обучена и протестирована на одной и той же фотографии — это будет исправлено в бета-версии.
Цветовое пространство. Сначала необходимо изменить цветовые каналы на картинке с RGB на Lab, где L — освещение (lightness), а и b соответствуют красно-зеленому и сине-желтому цветам:
# Получаем изображение
image = img_to_array(load_img('woman.png'))
image = np.array(image, dtype=float)
# Конвертируем изображение в lab модель
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
Y = Y / 128
X = X.reshape(1, 400, 400, 1)
Y = Y.reshape(1, 400, 400, 2)Как видно на картинке ниже, в модели Lab у изображения есть один слой в оттенках серого, а три цветовых канала были перекодированы в два. Кстати, научный факт — 94% клеток сетчатки глаза определяют яркость того, что мы видим, тогда как всего 6% распознают цвета. Также заметно, что черно-белое изображение более четкое, чем в a и b. Это одна из причин, почему стоит использовать его в качестве одного из слоев в конечном изображении.
Нейросеть. Идея нашей модели состоит в том, что, принимая на вход сетку значений черно-белого изображения, оцениваем два цветовых канала: ab в Lab. Затем, чтобы получить цветное изображения в качестве третьего слоя (L в Lab) добавляем исходное черно-белое изображение. В результате получаем Lab картинку:
Чтобы из одного слоя сделать два, будем использовать фильтры CNN (сверточной нейронной сети) — подобие синим/красным фильтрам в 3D очках. Каждый фильтр определяет, что будет изображено на картинке, они могут выделять или удалять что-то с изображения, чтобы извлекать нужную информацию. Затем нейросеть может создать новое изображение из фильтра, или соединить несколько фильтров в одну картинку.
Ниже представлен весь код для построения, обучения и тестирования нейросети. Его детали мы обсудим чуть позже.
# строим нейронную сеть
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
# заканчиваем модель
model.compile(optimizer='rmsprop',loss='mse')
# рбучаем нейросеть
model.fit(x=X, y=Y, batch_size=1, epochs=3000)
print(model.evaluate(X, Y, batch_size=1))
# соединение трех слоев в одной итоговой матрице
output = model.predict(X)
output = output * 128
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
# сохранение итоговой картинки
imsave("img_result.png", lab2rgb(canvas))
imsave("img_gray_scale.png", rgb2gray(lab2rgb(canvas)))Запуск нейросети на FloydHub
Если вы никогда не пользовались FloydHub — облачной платформой для обучения и запуска deep learning моделей — то вы можете прочитать их 2-минутный гайд по установке или посмотреть мое 5-минутное видеоруководство или, наконец, прочитать эту пошаговую инструкцию. FloydHub — один из лучших и легчайших способов обучения моделей в облаке.
Как только FloydHub установлен, вставьте следующий код в командную строку:
git clone https://github.com/emilwallner/Coloring-greyscale-images-in-KerasДалее изменим рабочую директорию и запустим FloydHub:
cd Coloring-greyscale-images-in-Keras/floydhub
floyd init colornetДашборд FloydHub откроется в вашем браузере. Затем вам придет запрос создать новый проект, названный colornet. Как только проект будет создан, вернитесь в командную строку и запустите ту же команду:
floyd init colornetТеперь запустим нашу нейросеть:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardНесколько замечаний:
- Я использую датасет на FloydHub (который я загрузил туда ранее) в папке data.
- Команда --tensorboard включает Tensorboard, а в режим работы Jupyter Notebook мы перешли с помощью --mode jupyter.
Теперь мы будем работать в Jupyter Notebook. Под вкладкой Jobs на сайте FloydHub нажмите на ссылку Jupyter Notebook, а затем запустите скачанный файл:
floydhub/Alpha version/working_floyd_pink_light_full.ipynbПостепенно увеличивая параметр epochs (он регулирует, сколько раз нейросеть должна обучиться на данном изображении) c 1 до 10, 100, 500, 1000 и 3000 в model.fit(), посмотрите, как меняется качество обучения нейросети. Результат работы img_result.png вы можете найти в рабочей папке.
Технические детали и разбор кода
Еще раз: нейросеть принимает на вход сетку значений пикселей черно-белого изображения, а на выходе получаем две сетки с значениями яркости соответствующих цветов. Между входом и выходом мы создаем фильтры, чтобы соединить их вместе. Это и есть сверточная нейронная сеть. Когда мы обучаем модель, в качестве целевой переменной используем цветные изображения, конвертируя их из RGB в Lab:
Чтобы вычислить отклонение значений полученного изображения от исходного, мы должны отмасштабировать их на один интервал. Для этого воспользуемся функцией активации в виде гиперболического тангенса: каждому входному значению в ответ он выдает соответствующее в интервале от -1 до 1. Что нам и нужно.
В свою очередь, у исходного цветного изображения значения цветов находятся в интервале от -128 до 128, поэтому, разделив каждое из них на 128, мы и получим значения в том же интервале, что и оцененные моделью значения, и сможем посчитать ошибку.
После того, как ошибка посчитана, на следующей итерации обучения фильтры обновляются, уменьшая эту ошибку. Данный цикл продолжается, пока ошибка не упадет до минимального значения.
Теперь проясним некоторые детали в коде нейросети выше.
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]1.0/255 означает, что мы используем 24-битную RGB цветовую модель, то есть значения в интервале от 0 до 255 для каждого цветового канала и, соответственно, 16,7 млн цветовых комбинаций. В большем количестве нет нужды: люди могут воспринимать только до 10 млн цветов.
После изменения цветовой модели изображения с помощью функции rgb2lab() мы извлекаем его черно-белый слой, используя [:,:, 0], а команда [:,:, 1: ] выбирает два остальных: красно-зеленый и сине-желтый.
После окончания обучения модели мы создаем итоговое предсказание и конвертируем его в картинку, используя черно-белое изображение в качестве матрицы признаков X, а затем умножаем output на 128, чтобы получить правильные значения в Lab спектре.
output = model.predict(X)
output = output * 128Наконец, так как на выходе у нас получилось лишь два цветовых слоя, нам нужен третий — черно-белый. Поэтому мы создаем матрицу размера 400х400х3 для всех трех слоев, а затем копируем в нее output модели и сетку значений черно-белого изображения:
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]Выводы из альфа-версии
- Ключ к успеху — начать с простого. Большинство реализаций, которые я смог найти, содержат от 2 до 10 тысяч строк кода, что существенно осложняет понимание логики всего проекта.
- Изучайте проекты в открытом доступе. Чтобы понять, что мне требуется написать, я просмотрел от 50 до 100 проектов на Github по раскрашиванию изображений.
- Не все работает так, как ожидаешь. Сначала я смог воссоздать только красные и желтые цвета, поскольку использовал активационную функцию Relu, а она дает на выходе лишь положительные числа, поэтому отрицательные значения, соответствующие синему и желтому оказались мне недоступны. Но в результате я выбрал гиперболический тангенс и проблема была решена!
- Понимание > скорость. Множество изученных мною реализаций были очень быстро написаны, но с ними было невозможно работать. Я в свою очередь сделал выбор в пользу скорости понимания вещей, а не написания кода.
Увидимся в следующей статье, где мы научим нашу нейросеть обобщаться на новые картинки, которые она раньше не видела. Удачи!
roryorangepants
https://m.habrahabr.ru/company/nixsolutions/blog/342388/
Вот здесь был перевод той же статьи. Или я ошибаюсь?