

7 ноября на конференции HighLoad++ 2017, в секции «DevOps и эксплуатация» прозвучал доклад «Лучшие практики CI/CD с Kubernetes и GitLab». В нём мы делимся практическим опытом решения проблем, возникающих при построении эффективного процесса CI/CD на базе указанных Open Source-решений.
По традиции рады представить видео с докладом (около часа, гораздо информативнее статьи) и основную выжимку в текстовом виде.
CI/CD и ключевые требования
Под CI/CD (Continuous Integration, Continuous Delivery, Continuous Delivery) мы понимаем все этапы доставки кода из Git-репозитория в production и последующее его обслуживание вплоть до «снятия» с production. Существующие интерпретации терминов CI/CD допускают различное отношение к этому последнему этапу (эксплуатации в production), но наш опыт говорит, что его исключение из CI/CD приводит к многочисленным проблемам.
Перед тем, как описывать конкретные практики, мы обобщили те основные факторы, которые влияют на сложность CI/CD:
- Как построен основной процесс? Возможные варианты: одно или несколько окружений, динамические окружения, несколько распределённых площадок.
- Как осуществляется тестирование? Запуск анализатора кода, unit-тесты без окружения (т.е. без runtime-зависимостей), функциональные/интеграционные/компонентные тесты в окружении, тесты в «полном» окружении для микросервисов (end-to-end, регрессии).
- Какое разделение прав требуется? Простое (только писать код/выкатывать для определённых пользователей), разные права по окружениям, multi-stage approval (тимлид разрешает выкат на stage, а QA — на production), коллегиальное решение.
- Какова архитектура приложения? Stateless-сервис, stateful-приложение, многокомпонентное приложение, микросервисная архитектура.
Все эти варианты сведены в общий график, на котором проиллюстрировано, какими инструментами можно закрыть те или иные потребности:
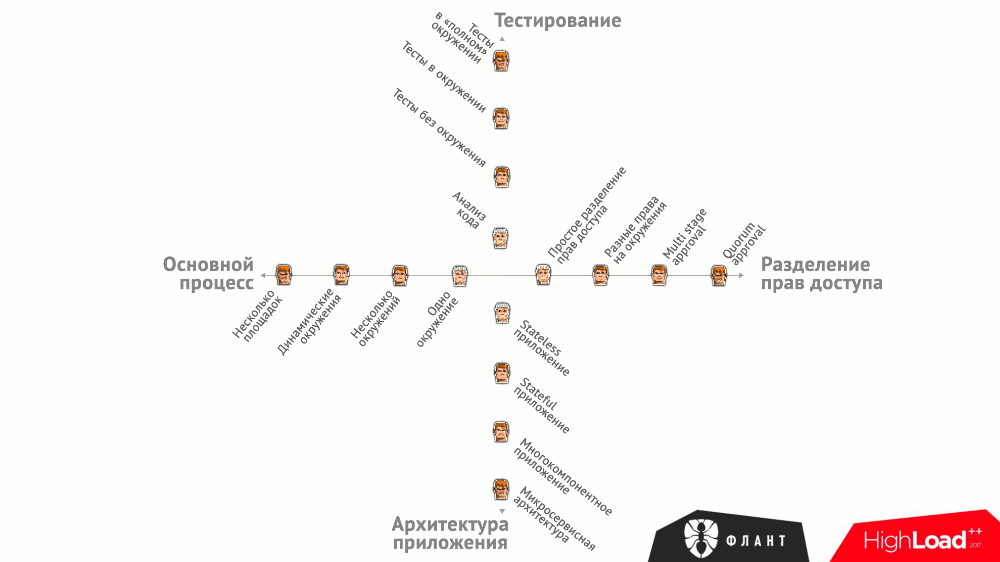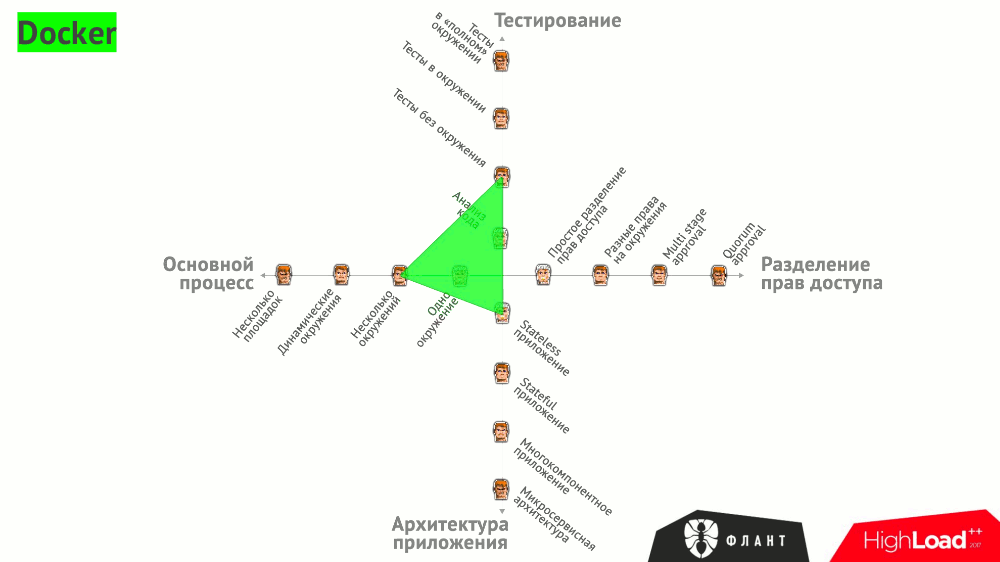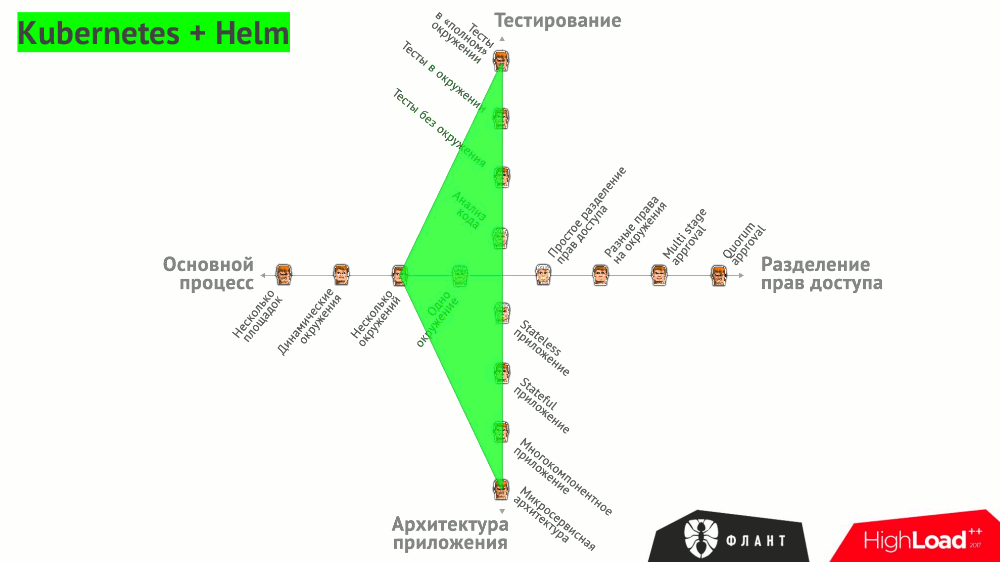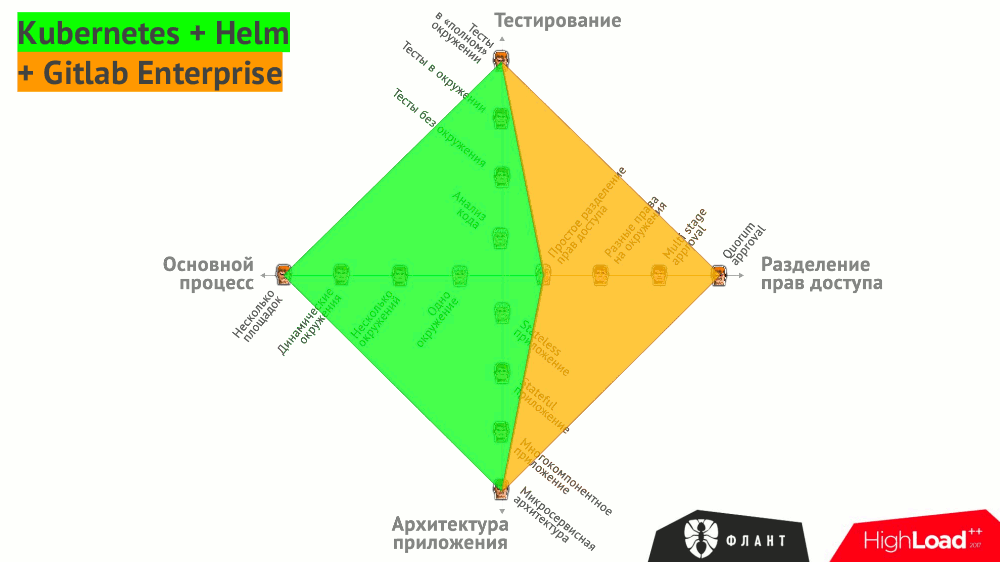
Есть и другие — более общие (но не менее важные!) — требования, предъявляемые к CI/CD:

Наконец, у нас как компании, внедряющей и обслуживающей системы для CI/CD, есть дополнительные требования к используемым продуктам:
- они должны быть Open Source (это и наш «взгляд на жизнь», и практическая сторона вопроса: доступность кода, отсутствие ограничений в применении);
- «разномасштабность» (продукты должны одинаково эффективно работать в компаниях и с одним разработчиком, и с пятьюдесятью);
- интероперабельность (совместимость друг с другом, независимость от поставщика оборудования, облачного провайдера и т.п.);
- простота эксплуатации;
- ориентированность на будущее (мы должны быть уверены не только в том, что продукты подходят сейчас, но и имеют перспективы развития).
Решения для CI/CD
Стек продуктов, удовлетворяющих всем требованиям, у нас получился следующий:
- GitLab;
- Docker;
- Kubernetes;
- Helm (для управления пакетами в Kubernetes);
- dapp (наша Open Source-утилита для упрощения/улучшения процессов сборки и деплоя).
А общий цикл CI/CD от Git до эксплуатации при использовании перечисленных инструментов выглядит так:
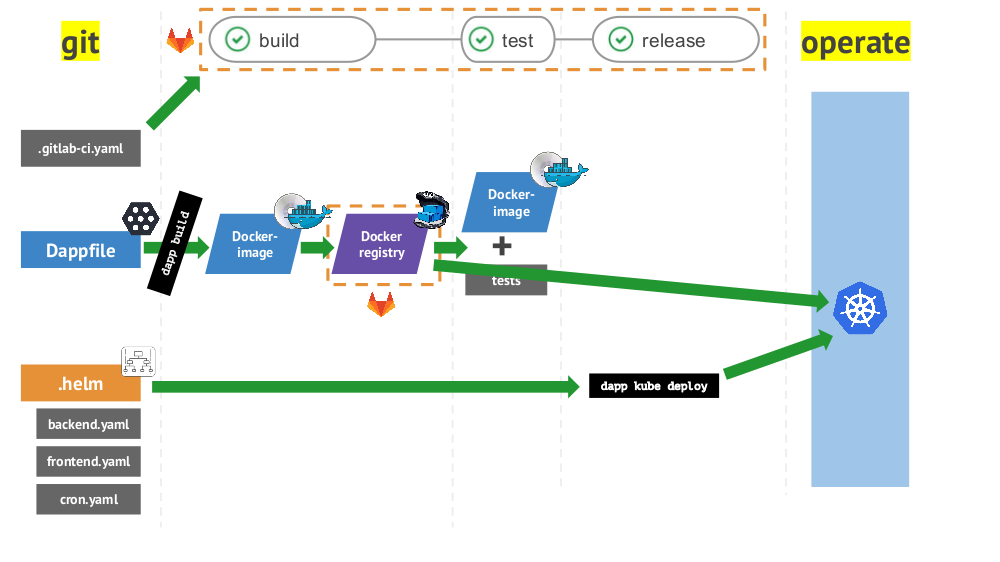
Практики
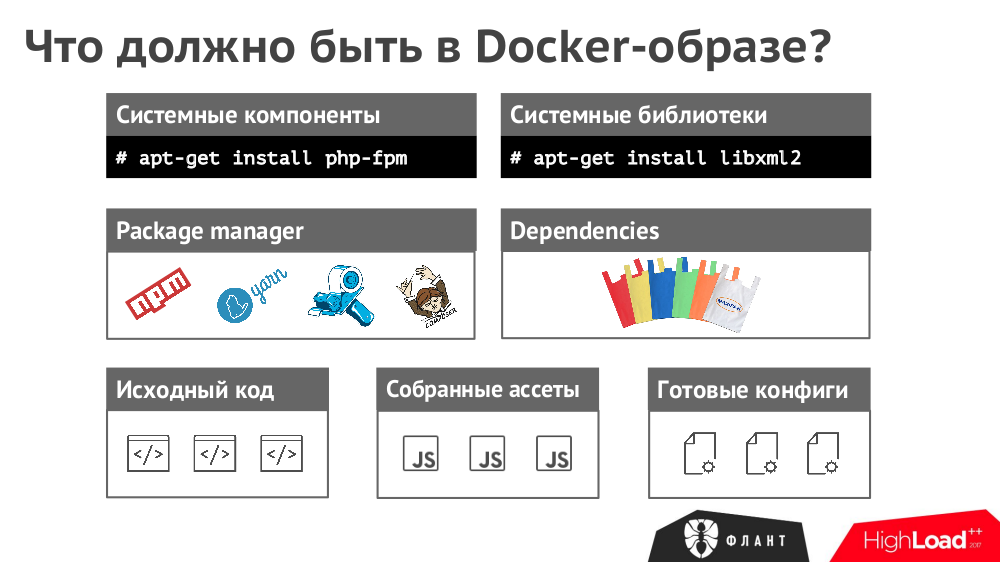
№1. Состав Docker-образа
Образ должен содержать всё, что требуется для работы приложения:
№2. Один образ для всего
Собранный однажды Docker-образ должен использоваться везде. Иначе на проверку к QA может попасть не то же самое, что будет выкачено на production (повторно собранное в другой момент времени).
У себя мы собираем временные образы из
git branch и релизные образы из git tag: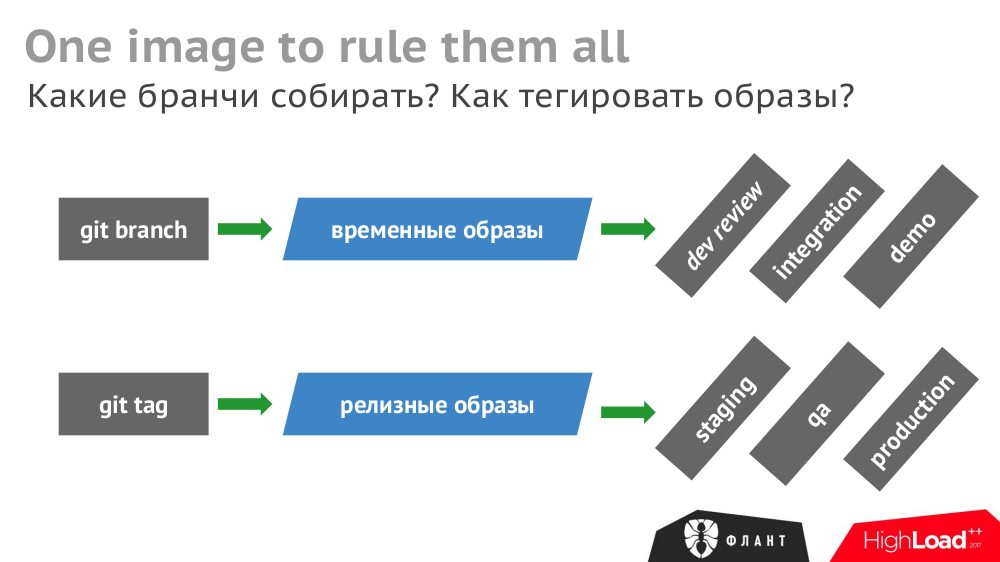
№3. Выкат и миграции
Работа различных компонентов, описанных в Kubernetes (бэкенд как Deployment, СУБД как StatefulSet и т.п.), может зависеть друг от друга. В случае «прямолинейного» выката K8s будет обновлять компоненты и перезапускать их (в случае неуспешного старта):
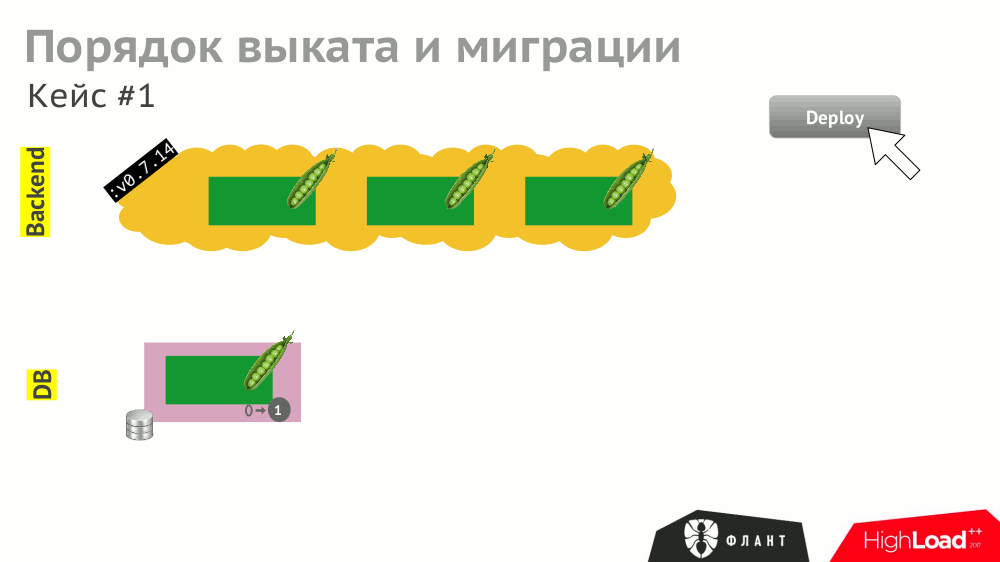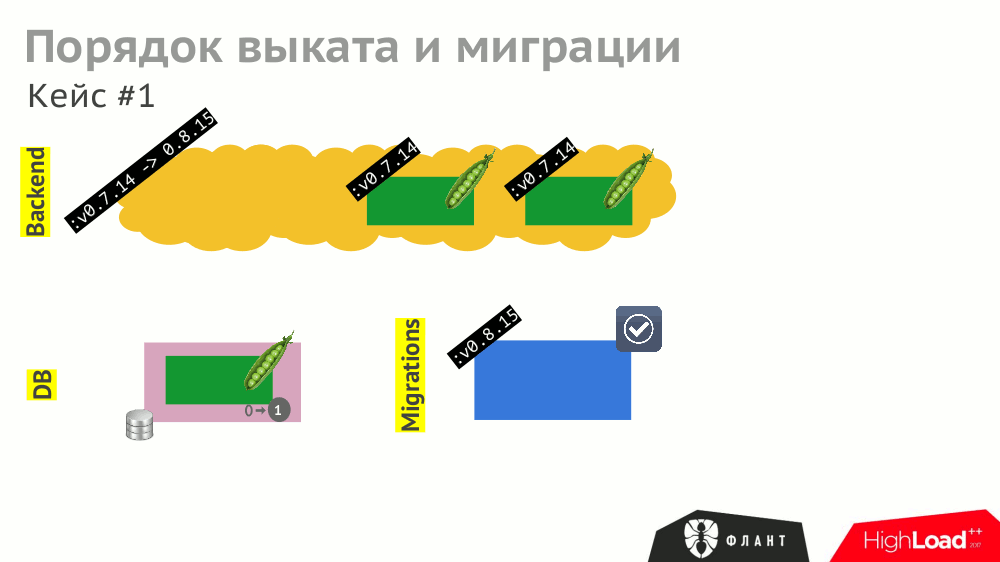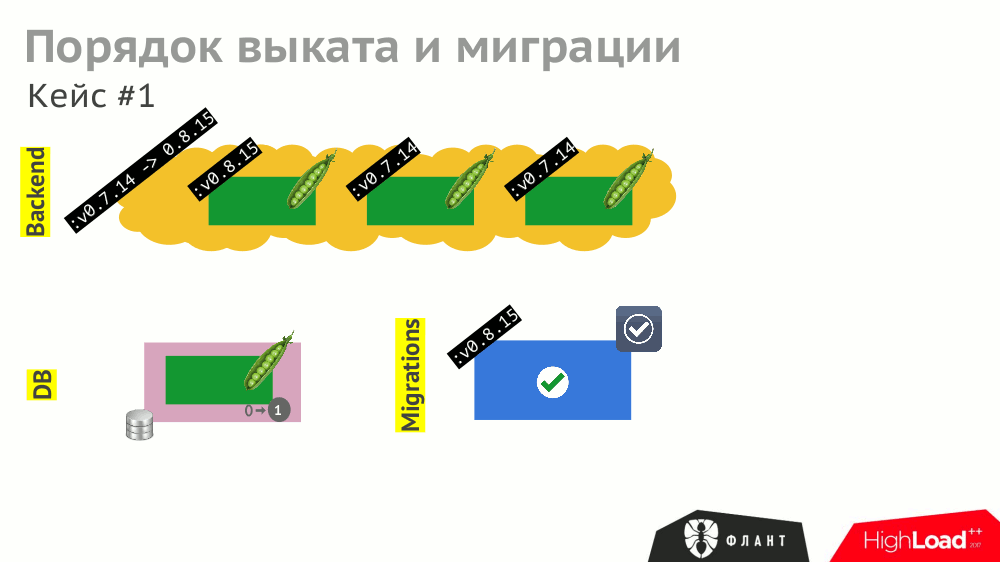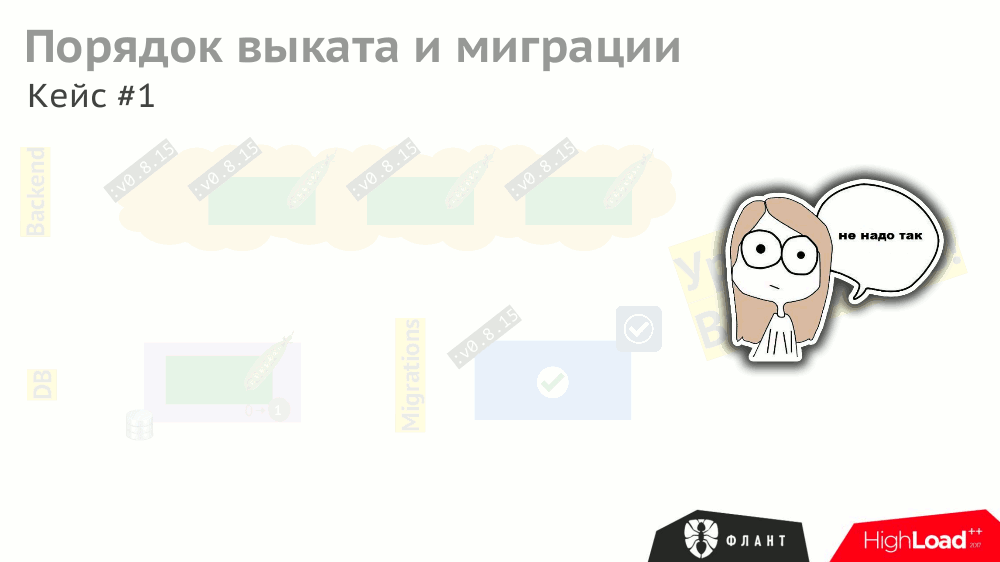
И даже при корректной обработке всех этих событий компонентами (что тоже надо предусмотреть) общее время выката затянется из-за различных таймаутов в Kubernetes, срабатывающих (и накапливающихся) из-за необходимости ожидания запуска других служб (например, бэкенд ждёт доступности обновлённой базы данных, т.е. с проведённой миграцией).
Чтобы сократить время выката, нужно учитывать (и прописывать) не только явные зависимости между компонентами (бэкенд ждёт доступности СУБД), но и косвенные (бэкенд не должен обновляться до проведения миграций).
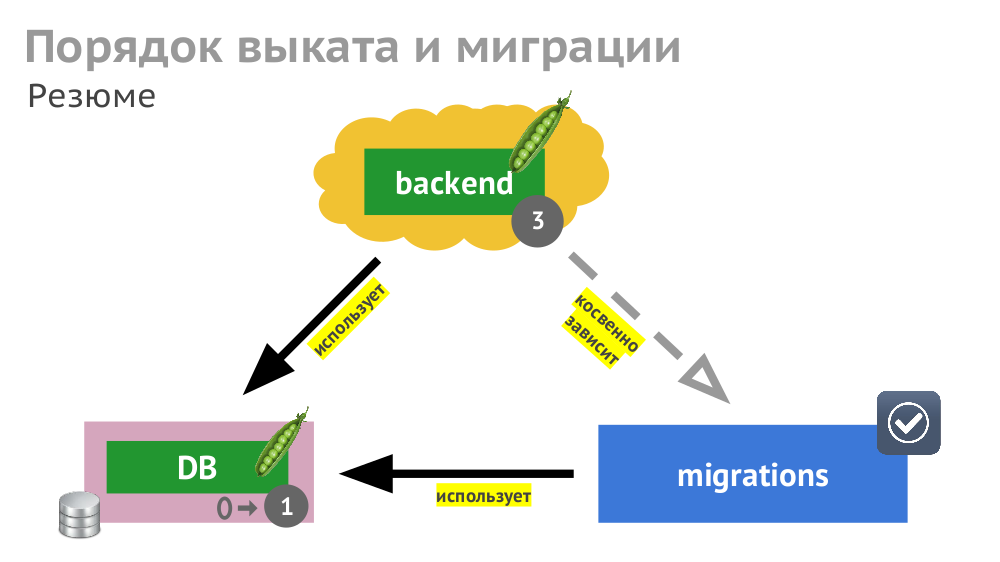
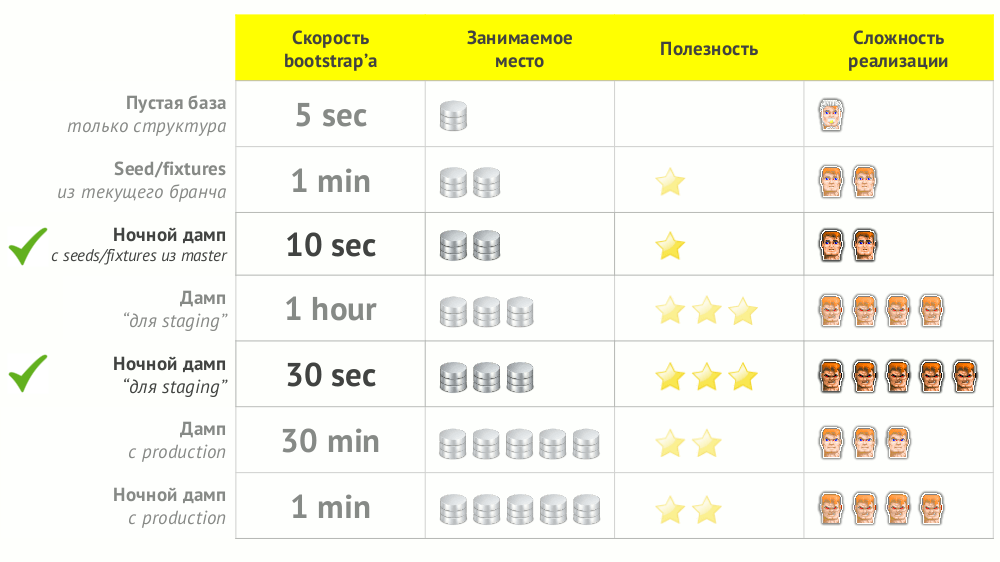
№4. Bootstrap БД
СУБД наполняют данными двумя путями: загрузкой готового дампа или загрузкой сидов/фикстур. Путь в Kubernetes для первого случая — это после старта СУБД запускать задание (Job), которое загружает дамп. После этого — запуск миграций (они косвенно зависят от дампа), а затем — запуск бэкенда (косвенно зависит от миграций).
Последовательность запуска для случая с сидами меняется и выглядит так: 1) СУБД, 2) миграции, 3) задание с сидами, 4) бэкенд (можно запустить в параллель с сидами, т.к. от сидов не должен зависеть).

Перебрав различные пути bootstrap'а БД, мы пришли к оптимальности двух: ночной дамп с seeds/fixtures из master и ночной дамп для staging.
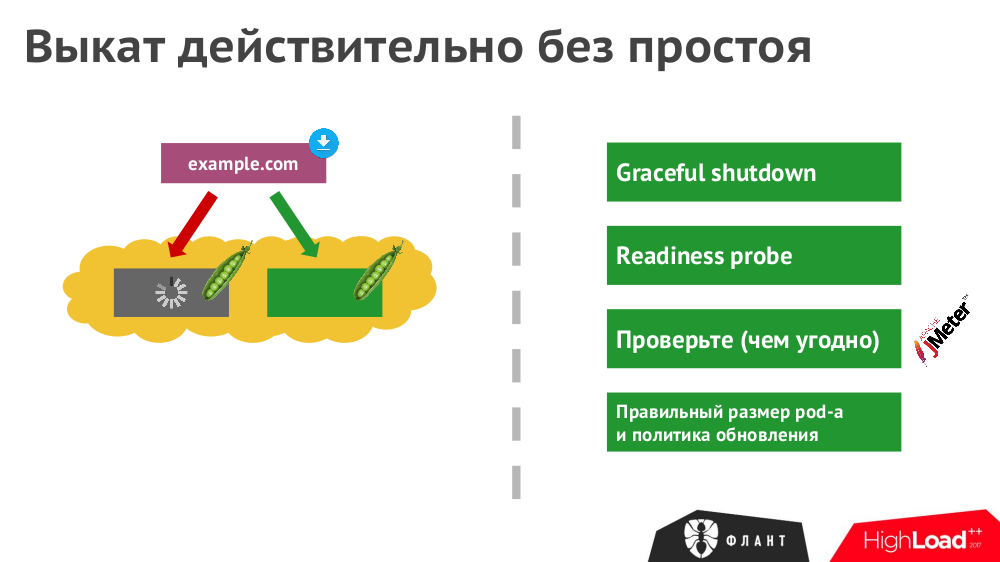
№5. Выкат без простоя
Даже при правильном деплое новых версий приложения в Kubernetes не все нюансы будут автоматически учтены. Чтобы действительно гарантировать полное отсутствие простоя:
- не забывайте про корректное завершение всех HTTP-запросов,
- проверяйте реальную доступность приложения (открытый порт) с помощью прописанных в K8s readiness probes,
- симулируйте нагрузку во время деплоя (проверяйте, все ли запросы выполнились),
- предусматривайте запас производительности у подов, доступных в инфраструктуре на время деплоя.
№6. «Атомарность» выката
Если во время обновления какого-либо компонента инфраструктуры произошла ошибка (обновление не смогло выкатиться), в пайплайнах GitLab будет соответствующее уведомление, однако сама инфраструктура останется в переходном состоянии. Проблемный компонент не сохранит оригинальную (старую) версию, как «подумает» GitLab, а будет в состоянии не до конца выкатившейся новой версии.
Проблема решается использованием встроенной возможности отката (rollback) в случае возникновения такой ошибки. Причем скорее всего это стоит предусмотреть только в production, т.к. в dev-контурах вы с большой вероятностью захотите посмотреть на проблемный компонент в его переходном состоянии (разобраться в причинах возникновения проблемы).
№7. Динамические окружения
Встроенные в GitLab возможности позволяют при git push'е любого branch (при наличии Helm chart для полного bootstrap'а инфраструктуры) разворачивать в Kubernetes готовую к использованию инсталляцию приложения (с одноимённым пространством имён). Аналогично будет происходить удаление пространства имён при удалении branch'а.
Однако при активном использовании этой возможности, требуемые для инфраструктуры ресурсы быстро разрастаются. Поэтому есть несколько рекомендаций по оптимизации динамических окружений:

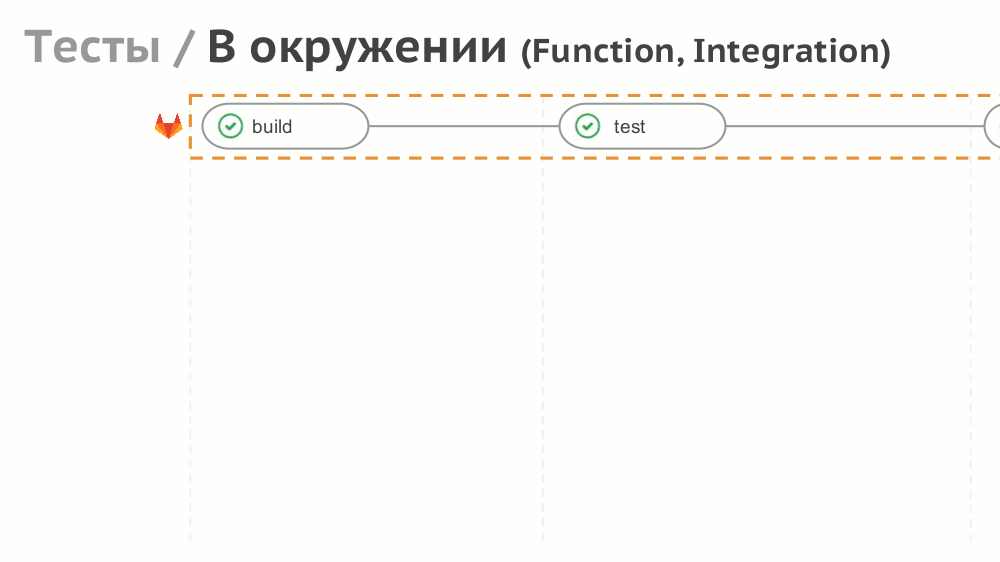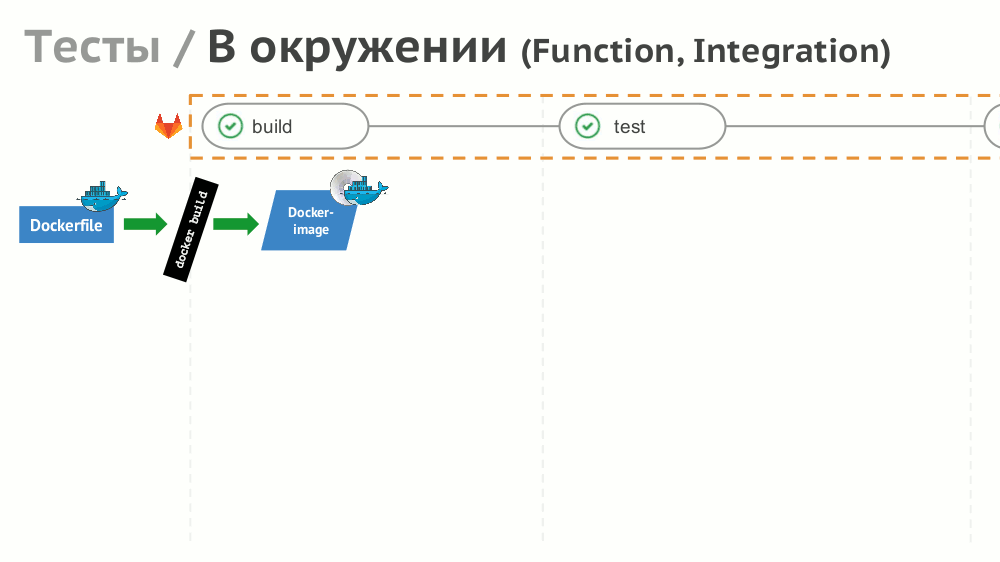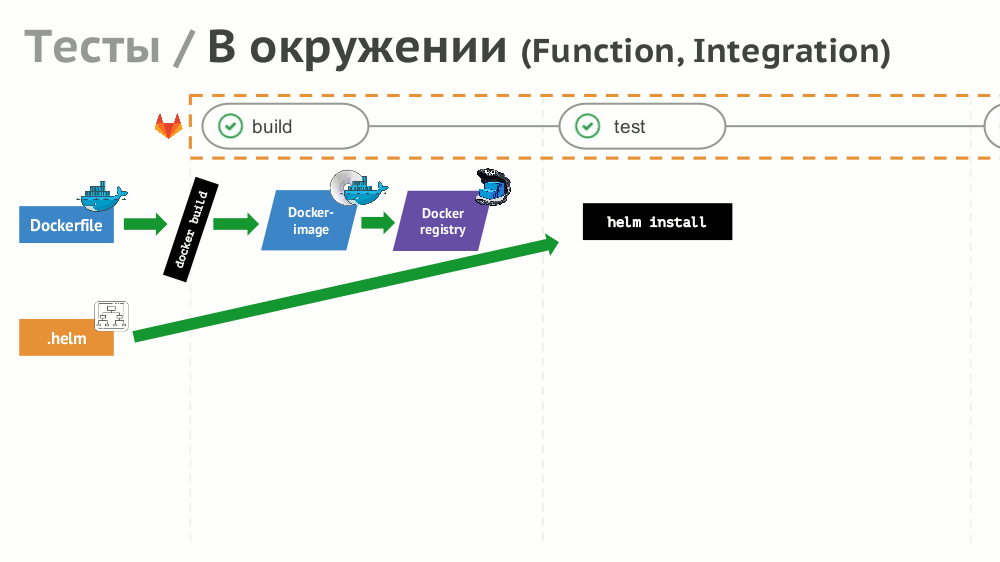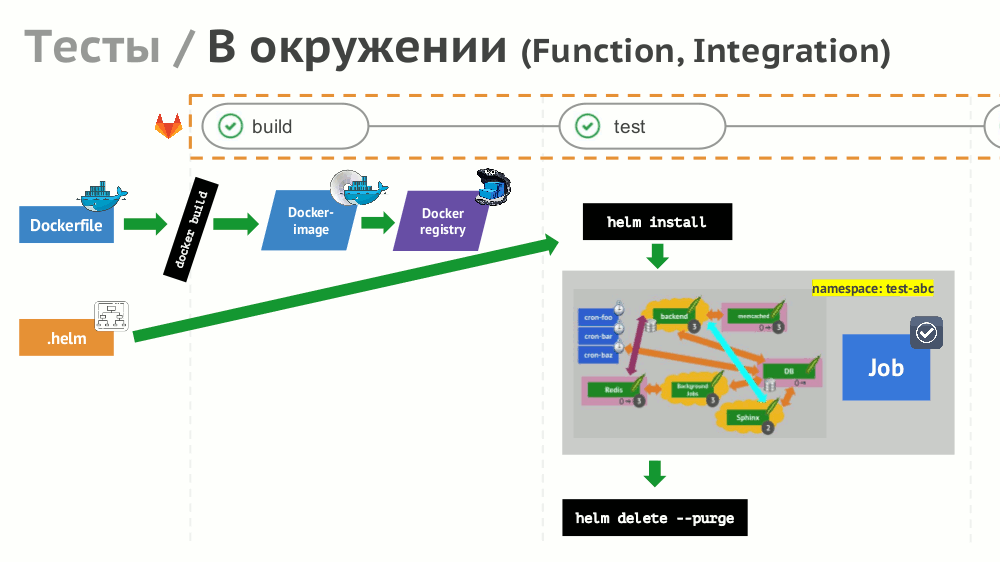
№8. Тесты
Если с реализацией простых тестов (не нуждающихся в окружении) всё просто, то для функционального и интеграционного тестирования предлагаем создавать динамическое окружение с помощью Helm:
Итоги
Возвращаясь к начальному графику с требованиями к CI/CD…
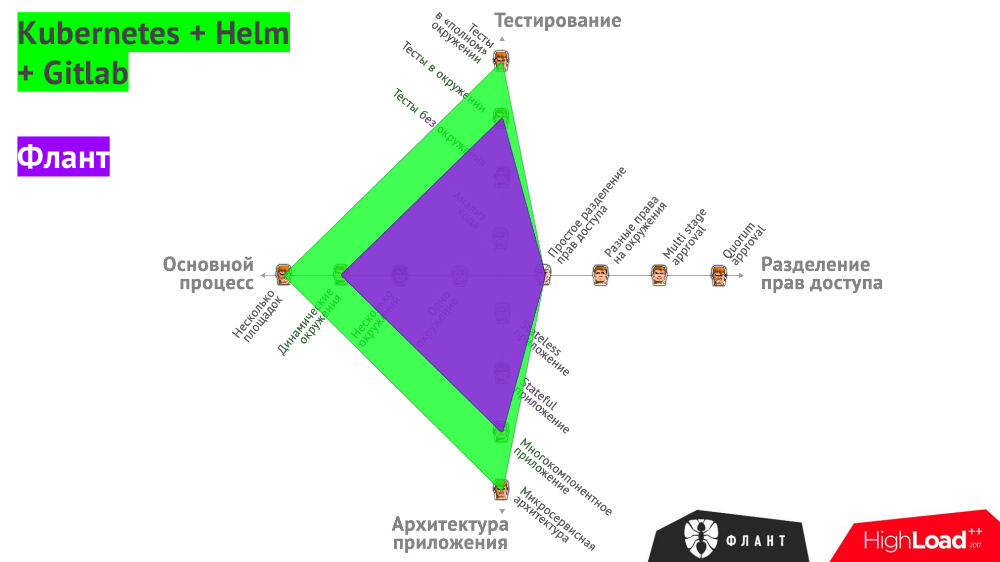
Описанные практики на базе Open Source-продуктов позволяют решать задачи, отмеченные зелёным цветом. Фиолетовым выделена область проблем, с которыми мы в компании «Флант» работаем буквально каждый день.
Видео и слайды
Видео с выступления (около часа) опубликовано в YouTube.
Презентация доклада:
P.S.
Другие доклады в нашем блоге:
- «Наш опыт с Kubernetes в небольших проектах (обзор и видео доклада)»; (Дмитрий Столяров; 6 июня 2017 на RootConf);
- «Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp» (Дмитрий Столяров; 8 ноября 2016 на HighLoad++);
- «Практики Continuous Delivery с Docker» (Дмитрий Столяров; 31 мая 2016 на RootConf).
Вероятно, вас также заинтересуют следующие публикации: