
Хотите исправлять ошибки быстрее и проще?
Тогда читайте мою статью, в которой я расскажу как можно выполнять мониторинг ошибок приложения с помощью расширения NLog.

Как это работает?
Решение для мониторинга ошибок должно быть пригодным для уже существующих приложений, где написано огромное количество кода, который ради мониторинга никто переделывать не будет.
Мониторинг ошибок должен выполняться прозрачно, это означает, что в обработчиках ошибок не должно быть кода, который занимается мониторингом.
Давайте внимательно посмотрим на типовой код обработки исключения:

Что можно использовать в качестве входной точки для мониторинга ошибок?
Верно, нам поможет система логирования.
Система логирования должна иметь расширение, которое будет заниматься сбором, группировкой и отправкой ошибок в систему мониторинга. Система мониторинга отправит уведомление разработчикам, разработчики исправят ошибку.
Ниже нарисована схема как это работает:
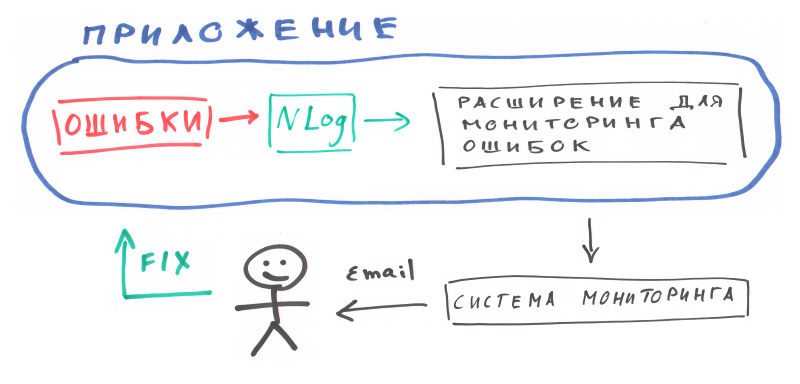
Именно такую схему работы реализовывает расширение NLog для системы мониторинга Zidium. Что такое Zidium? Это облачный сервис мониторинга приложений, который можно использовать бесплатно.
Установить расширение можно через nuget-пакет — NLog.Zidium
Узнать больше о расширении можно в документации.
Hello World
Чтобы показать, как всё работает, создадим простое консольное приложение и подключим его к системе мониторинга. Пусть в приложении будет ошибка, которая записывается в NLog.
Код приложения
using NLog;
using System;
namespace NLog2
{
class Program
{
private static Logger logger = LogManager.GetCurrentClassLogger();
static void Main()
{
logger.Info("Начинаем запуск приложения");
try
{
throw new Exception("Упс");
}
catch (Exception exeption)
{
logger.Error(exeption, "Ошибка запуска приложения");
}
LogManager.Flush();
}
}
}
Подключаем расширение к NLog
PM > Install-Package NLog.ZidiumНастраиваем Zidium.xml
Конфигурационный файл Zidium.xml должен быть в папке, где находится exe-файл программы.
<?xml version="1.0" encoding="utf-8" ?>
<root>
<access accountName="Test" secretKey="..." />
<defaultComponent id="3826486a-66ce-4a50-a310-4c87deaf01db" />
</root>
В файле нужно указать:
accountName – имя вашего аккаунта, можно посмотреть в личном кабинете
secretKey – секретный ключ API, можно посмотреть в личном кабинете
defaultComponent id – ID компонента, который нужно создать в личном кабинете системы мониторинга.
Настраиваем NLog.config
<?xml version="1.0" encoding="utf-8" ?>
<nlog xmlns="http://www.nlog-project.org/schemas/NLog.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
internalLogLevel="Trace"
internalLogFile="nlog-internal.log">
<targets>
<target name="ZidiumErrors" xsi:type="Zidium.Errors" />
</targets>
<rules>
<logger name="*" minlevel="Info" writeTo="ZidiumErrors" />
</rules>
</nlog>
Запуск приложения и проверка
Запустите консольное приложение, после завершения перейдите в личный кабинет системы мониторинга.
Если всё сделано верно, то компонент Hello World в личном кабинете системы мониторинга станет красным, вам будет отправлено email-уведомление. На странице Ошибки будет представлена статистика ошибок.
Заключение
Теперь вы знаете простой и быстрый способ подключения приложения к системе мониторинга ошибок. Исправляйте ошибки быстрее и легче.
Желаю всем успехов.
Комментарии (176)
mayorovp
25.01.2018 15:29+1Конфигурационный файл Zidium.xml должен быть в папке, где находится exe-файл программы.
Ну зачеееем?! Почему нельзя написать конфиг внутри элемента target? Или хотя бы указать путь к конфигу атрибутом...

mayorovp
25.01.2018 15:52Кстати, а о каком exe-файле идет речь в случае asp.net-сайта? Неужели w3wp.exe в системной директории? :-)

dothemain Автор
25.01.2018 16:03В случае asp.net приложения zidium.xml должен быть в корне, где лежит Web.config
mayorovp
25.01.2018 16:12Угу, я уже заметил… То есть по умолчанию его кто угодно может с сервера скачать, посмотреть настройки отсылки логов, после чего этими логами спамить? Отличная идея!
mayorovp
25.01.2018 16:11Сам спросил — сам отвечаю.
Файл Zidium.xml ищется в той же папке, где находится библиотека (!), но если эта папка называется "bin", а в родительской лежит файл web.config или global.asax — то берется именно родительская...
То есть с настройками по умолчанию файл Zidium.xml можно будет спокойно скачать с веб-сервера, со всеми
<access accountName="Test" secretKey="..." />. А еще клиентскую библиотеку нельзя будет засунуть в GAC (некоторые интеграторы любят ставить все сборки туда).
Вот зачем так делать? Скажите, чем вас
AppDomain.CurrentDomain.BaseDirectoryне устраивал?
ohotNik_alex
25.01.2018 16:42Sentry?
группирует логи. цепляется практически к любой системе логгирования. free (до определенного объема логов если не ошибаюсь, но все же). есть докер-образы. тэги. чем NLog превосходит ее?
Может ли она использовать для настройки logback.xml и т.п.?
ps отдельный вопрос по требованиям к системе. sentry прожорливая и это явный минус.mayorovp
25.01.2018 16:56Ну например тем что в случае Sentry нужно создать RavenClient, настроить его и выбрать способ доставить его до всех потребителей — а NLog сама решает эти задачи.
ohotNik_alex
25.01.2018 17:07ну так я и не жду, что системе просто покажут пальцем на цель.
создание клиента занимает 3 пункта в java приложении.
— зависимости
— логгер в logback.xml
— иногда нужно запустить приложение с флагом, указывающим имплементацию для логгера.
это при неопытности и инструкции перед глазами 10 минут.
честно не помню нужно ли создавать Bean в спринге для raven-клиента.
или NLog не потребует пересборки проекта и перезапуска? зацепится на горячее?mayorovp
25.01.2018 17:20Вы правда не видите разницы между
private static readonly ILogger log = Logmanager.GetCurrentClassLogger();и передачейIRavenClientчерез конструктор?
Представьте, что кусок программ писался без логов долгое время и накопил цепочку из 10 классов которые создают друг друга. Вы решили добавить логи в последний.
В случае NLog вы берете и добавляете их. В случае Sentry/RavenClient — надо будет протащить
IRavenClientчерез 10 конструкторов.
иногда нужно запустить приложение с флагом, указывающим имплементацию для логгера
Ну и как вы собрались менять имплементацию логгера флагом — если у разных логгеров разные интерфейсы?
Только не надо про Commons Logging — этот "общий знаменатель" довольно беден, и при работе через него Sentry окажется ничем не лучше чем log4j или NLog.
ohotNik_alex
25.01.2018 17:34я прикручивал Sentry к проекту, которому было лет 10. названные мною шаги — все, что я сделал чтобы получить информацию в dashboard.
никакой передачи в конструктор не было точно.
В случае Sentry/RavenClient — надо будет протащить IRavenClient через 10 конструкторов.
простите, вы в sentry отправляете вызывая напрямую ravenClient? оО зачем?! он же свободно перехватывает все, что поступит в него на appender в логгере, который уже есть в системе. в самих классах вообще ничего менять не требуется.
но если уж очень надо — утилитный класс со статик-полем… синглтон… варианты проектирования единого ресурса — тема любого собеседования.
Ну и как вы собрались менять имплементацию логгера флагом — если у разных логгеров разные интерфейсы?
до своих записей я увы прямо сейчас добраться не могу — закрыт evernote на работе.
но если кратко — log4j-api отдельный проект и как-то ведь живет.
указание логгера используется именно для ситуаций, когда транзитивно заходят log4j и logback, например.
это не более, чем указание Sentry "перехватывай то, что идет к logback, а не log4j". как он это будет делать — скрыто под капотом и программиста не касается.mayorovp
25.01.2018 18:37+1простите, вы в sentry отправляете вызывая напрямую ravenClient?
Нет, это вы предлагаете так делать. Вижу, вы используете log4j. В таком случае возвращаю вам ваш же вопрос:
Sentry?
группирует логи. цепляется практически к любой системе логгирования. free (до определенного объема логов если не ошибаюсь, но все же). есть докер-образы. тэги. чем log4j превосходит ее?ohotNik_alex
26.01.2018 10:20-1перечитайте, пожалуйста.
я спросил чем NLog превосходит Sentry, а не log4j
ravenClient напрямую из кода нигде не используется.
Достаточно только пунктов installation и usage.
и уже после их выполнения все будет работать.
никаких танцев с бубном и никаких новых файлов конфига как в случае с zidium.xml.
mayorovp
26.01.2018 10:25Тем не менее, ответьте пожалуйста на мой вопрос. Может, мне правда интересно узнать зачем вы используете Sentry если у вас уже есть log4j.
PS Перечитайте на всякий случай список хабов в которых расположен этот пост.ohotNik_alex
26.01.2018 10:42поясняю принцип работы Sentry. В общем абстрактном проекте в вакууме.
есть некое приложение. оно еще мааааленькое. логов там мало. потом кто-то понимает, что если сделать его большим — оно принесет чемодан денег и начинают его выращивать.
Все это время приложение пишет логи… там много мусора. сообщения о том, что пользователь успешно авторизовался… сообщения о том, что пользователь просмотрел 101 страницу с их полным списком… все это пишется log4j-подобным логгером в файл.
приходит админ и видит этот бардак… распиливает логи по уровням — в один все, в другой debug, в третий error. дышать становится легче…
приложение растет… разлетается в инстансы облака… работает на 3-4 машинах и собирать эти файлы уже проблема…
одна и та же ошибка, на которую нет времени потому что она не критична, повторяется каждые 2 минуты и полностью забивает лог-файлы. найти в error-логе одну новую ошибку среди 200 уже известных проблема.
а потом наконец-то до кого-то доходит, что можно прикрутить Sentry.
делается это оооочень трудным путем.
— добавляется maven-зависимость
— добавляется запись о новом аппендере в файл-конфиг уже существующего и работающего логгера приложения
теперь как только что-то попадает на отправку в логи — оно идет и в файл и в Sentry.
настраиваем уровень логов для Sentry-appender (он использует ravenClient внутри себя — во всяком случае для варианта http-нотификаций.)
заходим в Sentry и видим что-то типа

(оригинал взят отсюда)
все ошибки разложены по полочкам. в любую можно зайти и посмотреть stacktrace.
отличие от log4j в том, что там просто простыня из всего подрят без какой-то группировки и типизирования. на 300 ошибок может быть 297 одного типа и 3 критических. поверьте — найти эти 3 будет нереально. в Sentry это будет всего ДВЕ строки с количеством инцидентов.mayorovp
26.01.2018 10:58Хорошо, но зачем вы в таком случае используете log4j если Sentry настолько лучше?
ohotNik_alex
26.01.2018 11:06ну а зачем использовать info-файл, если есть DEBUG? иногда просто нужно посмотреть что происходило в системе без разграничений по времени события. редко, но случается.
это разные инструменты. один пишет все, второй шлет нотификации на инциденты и группирует события.
это за тем же, зачем включают создания dump-файла на падении jvm. чтобы было.
при наличии и Sentry и log4j однозначно все выбирают удобную админку вместо простыни. log4j лишь страховка например на случай отсутствия сети или на момент перезапуска Sentry.mayorovp
26.01.2018 11:10Чтож, теперь я готов ответить вам на ваш вопрос, хотя и нахожу этот ответ странным.
NLog лишь страховка например на случай отсутствия сети или на момент перезапуска Sentry.
ohotNik_alex
26.01.2018 11:15я не предлагал отказаться от других систем логгирования в пользу агрегатора данных.
изначальный вопрос был именно чем Nlog лучше уже имеющегося популярного решения Sentry.
сравнивать log4j и Sentry столь же корректно, как автомобиль и прицеп — функции схожие, но не тождественные. если есть возможность — лучше иметь и то и другое.
вы же не станете держать в одном проекте logback и log4j про запас? это уже практически одинаковые инструменты.mayorovp
26.01.2018 11:53изначальный вопрос был именно чем Nlog лучше уже имеющегося популярного решения Sentry.
Хорошо, но вы же в таком случае сможете объяснить чем log4j лучше уже имеющегося популярного решения Sentry?
ohotNik_alex
26.01.2018 12:08какая библиотека вам понравится — по алфавиту и полочкам или сваленная в кучу из самосвала посреди двора?
выше я уже отвечал на этот вопрос.mayorovp
26.01.2018 12:19В таком случае я могу вам ответить на ваш изначальный вопрос, хоть уже и не понимаю этого ответа:
какая библиотека вам понравится — по алфавиту и полочкам или сваленная в кучу из самосвала посреди двора?
PS читая этот пост я не поленился погуглить что такое Zidium. Отвечая на ваши комментарии я не поленился погуглить что такое Sentry. Также потенциально я мог и вовсе не знать что такое log4j и "спринг" — но знал, потому что интересуюсь соседними экосистемами.
Как так вышло, что вы до сих пор не зашли в гугл и не погуглили что такое NLog?
Я уже не говорю о том, что прежде чем писать комментарии, было бы неплохо почитать пост. Там в первом же примере кода есть строчка
using System;, которая как бы намекает, что вы ошиблись хабом и задаете тут не просто глупые — а идиотские вопросы, причем уже зная на них ответы.
Или вы просто тролль, и намеренно скрываете свое знание очевидных вещей?
ohotNik_alex
26.01.2018 13:11был такой форум… звался javatalks.
когда-то довольно активный… знаете на чем они погорели и почему от них ушла большая часть аудитории? модераторы начали вместо ответов говорить "посмотри в гугле".
зачем мне идти в поисковик, читать документацию, если меня интересует краткий ответ на мой вопрос и статья посвящена этой системе?
все что есть в этой статье в гугле есть — так может быть она и не нужна по вашей логике? если вы не можете ответить на мой вопрос — подождите пока до вопроса дойдут компетентные люди.
я погуглил что такое zidium когда стало ясно, что статья более с рекламным уклоном, нежели с желанием просвятить сообщество относительно новой альтернативной методики логгирования. честно говоря наколенная поделка на первый взгляд и интерес к нему угас как таковой. хранить логи на стороне неприемлемо от слова "совсем".
мог и вовсе не знать что такое log4j
нуууу… в этом случае и говорить не о чем. не знание азов лечится только книгами или практикой хотя бы на уровне джуна-стажера. это как человек, не знающий что-такое git.ps не смотря на то, что вы по 2 раза задаете одни и те же вопросы — я же не считаю, что передо мной идиотские вопросы, задаваемые троллем? хотя исправляемый текст в цитатах якобы на меня наводит на такую мысль.
я ответил, что вы сравниваете два разных продукта. "зачем нам шурупы, когда есть гвозди?". действительно, а зачем? (это риторический вопрос — ответа не требуется) аналогия с машиной и прицепом очевидно слишком сложна.
в первом же примере кода есть строчка using System;
действительно редкость для кода на C++
mayorovp
26.01.2018 13:54нуууу… в этом случае и говорить не о чем. не знание азов лечится только книгами или практикой хотя бы на уровне джуна-стажера. это как человек, не знающий что-такое git.
Вот только это азы экосистемы Java, а я на C# пишу. Вам не приходило в голову что не каждый программист в мире пишет на Java?
я ответил, что вы сравниваете два разных продукта
Вообще-то, вы первым решили сравнить два разных продукта.
хотя исправляемый текст в цитатах якобы на меня наводит на такую мысль.
Проекты NLog и log4j из одной семьи и решают одни и те же задачи. От замены одного названия на другое аргумент не перестает быть корректным (или не начинает). Является ли он при этом цитатой — не так важно.
По вашему исходному вопросу. Попробую объяснить последний раз. Вот вы пишите:
простите, вы в sentry отправляете вызывая напрямую ravenClient? оО зачем?! он же свободно перехватывает все, что поступит в него на appender в логгере, который уже есть в системе. в самих классах вообще ничего менять не требуется.
То есть вы предполагете что в проекте уже есть какой-то логгер, к которому можно прицепить аппендер.
Но откуда в проекте возьмутся логгеры и аппендеры если в нем нет NLog или хотя бы log2net? NLog — это и есть та самая библиотека, которая дает программисту логгеры и аппендеры (которые называются таргетами).
ohotNik_alex
26.01.2018 14:06Именно такую схему работы реализовывает расширение NLog для системы мониторинга Zidium.
де-факто статья не об NLog, а о его связке с zidium. здесь показано как связаться с этой тулой. но нет ни настроек уровней, ни записей в консоль/файл. по самой настройке NLog здесь нет практически НИЧЕГО.
Вообще-то, вы первым решили сравнить два разных продукта.
ложь. я попросил разницу между тем, что в статье и Sentry.
Вам не приходило в голову что не каждый программист в мире пишет на Java?
я пишу на десятке языков. C# в арсенале есть. не вижу особых проблем в понимании похожих синтаксисов.
каких-то глубоких знаний java здесь не требуется.
но для простоты я мог бы оперировать псевдоязыком — надеюсь вы не стали бы просить тогда писать строго на C#?
То есть вы предполагете что в проекте уже есть какой-то логгер, к которому можно прицепить аппендер.
если его нет, но это по всей видимости десктопный калькулятор, которому логи ни к чему. в наше время нет приложений, который зарабатывают деньги и при этом не пишут логов. так что да — я предполагаю, что система логгирования уже есть. а если ее нет — она должна быть добавлена обязательно первым же делом.
NLog — это и есть та самая библиотека, которая дает программисту логгеры и аппендеры
за это пояснение спасибо. теперь понял. а то по тону статьи выглядит так, будто это часть zidium. что-то вроде его плагинов.
полностью согласен, что я не правильно понял назначение этого инструмента и провел ложные аналогии.mayorovp
26.01.2018 14:21а то по тону статьи выглядит так, будто это часть zidium. что-то вроде его плагинов.
полностью согласенВот из этого фрагмента можно было бы понять что чьим плагином тут является:

PS
нуууу… в этом случае и говорить не о чем. не знание азов лечится только книгами или практикой хотя бы на уровне джуна-стажера. это как человек, не знающий что-такое git. :-)
Вот уж чего я не ожидал от кого-то кто знает C# — так это незнания того что такое NLog.
ohotNik_alex
26.01.2018 14:29я его использую в unity3d. там своя система логгирования.
Вот из этого фрагмента можно было бы понять что чьим плагином тут является:
разумеется. а еще можно было назвать статью как-то более четко. например, "использование zidium для логгирования ошибок". я думал это статья, а не кроссворд со скрытыми загадками.
а так сейчас поиск "логгирование с NLog" будет выводить сюда.
dothemain Автор
26.01.2018 13:41Есть ли logback для .NET?
ohotNik_alex
26.01.2018 13:52-1меня выше спрашивали про log4j. он есть. носит название log4net.
принципиальной разницы с версией java практически нет. а уж влияния на внешние инструменты тем более.
ps я так и не увидел ответа чем же Sentry хуже/лучше связки NLog + Zidium
вместо этого собеседник старается заглушить вопрос своим "а нафига вам Sentry если есть log4j?".
может быть вы ответите — а нафига нам NLog если есть log4j? аргументы "он раскладывает все по полочкам" приняты mayorovp не были.mayorovp
26.01.2018 13:57ps я так и не увидел ответа чем же Sentry хуже/лучше связки NLog + Zidium
Пожалуйста, укажите где именно в вашем первом комментарии, где вы задавали свой вопрос, находится слово "Zidium".
ohotNik_alex
26.01.2018 14:09из-за того, что в статье 90 процентов почему-то посвящено не настройке NLog, а Zidium, я получил ложное представление об этом инструменте. посчитал, что NLog это часть Zidium и ассоциировал их как единое целое.
на самом деле вопрос носил смысл "чем предложенное лучше/хуже Sentry". именно в таком виде. извиняюсь, что возникло недопонимание. когда говорят колесо, а тычат пальцем в телегу — не видя ранее ни того, ни другого не запутаться трудно.
плюсов я откровенно не увидел. из минусов — нет локальной версии, странные ограничения на объемы нотификаций.
dothemain Автор
26.01.2018 14:24я так и не увидел ответа чем же Sentry хуже/лучше связки NLog + Zidium
1) Sentry нельзя использовать прозрачно через NLog.
2) Если у вас связка log4net+Sentry, то чисто для мониторинга ошибок Sentry лучше, потому что в статистике ошибок показывает сколько пользователей затронула данная ошибка, zidium показывает только статистику ошибок.

3) Если вам хочется иметь комплексный мониторинг, то zidium поможет показать всю картину в одном окне. Zidium кроме мониторинга ошибок умеет выполнять проверки и проверять метрики. Например, мои windows-службы шлют в zidium проверку «биение-сердца». В итоге я получаю уведомления, когда случаются фатальные ошибки, или приложение упало совсем (или сервер)mayorovp
26.01.2018 14:28Sentry нельзя использовать прозрачно через NLog.
Ну на полчаса же задача! Берется вот этот файл — https://github.com/themotleyfool/SentryAppender/blob/master/src/app/SharpRaven.Log4Net/SentryAppender.cs — и часть строк копируется в заготовку таргета из примеров NLog...
ohotNik_alex
26.01.2018 14:35Sentry нельзя использовать прозрачно через NLog.
на самом деле можно и даже проще.
Если вам хочется иметь комплексный мониторинг, то zidium поможет показать всю картину в одном окне.
zabbix? зато платить не потребуется. и метрики и статус сервера. и локальное по без выноса непонятно к кому.
upd вижу, что у него беда с dotnet. не подойдет. но возможно все-таки есть смысл не стягивать на одну систему все?
dothemain Автор
26.01.2018 14:49Разве не удобно в одном месте увидеть, что ошибок нет, главная страница открывается, домен оплачен, а на сервере достаточно свободного места?
Если меня спросят всё ли в порядке сейчас с приложением, я смогу легко ответить.ohotNik_alex
26.01.2018 15:06ради этого платить абонентку?
может и удобно, но есть нишевые инструменты. если zidium начинает втаскивать в себя все, что можно — возникает логичный вопрос — для этого раздувается команда или падает качество компонентов?
плохо организованная сборка метрик может откусить не малую часть ресурсов. видел проект, в котором при отключении профилирования расходы падали процентов на 15. это действительно задача на порядки сложнее, чем насобирать 100500 http запросов.
одно окно это удобно, но и 2 как-то проблем не вызовут.
dothemain Автор
26.01.2018 15:16Если 2 окна проблем не создают, то и 3 окна тоже )
ohotNik_alex
26.01.2018 15:28точно!
зато в каждом будет инструмент, занимающийся своим делом, заточенный только на свою задачу, да еще и бесплатно.dothemain Автор
26.01.2018 16:01Мне удобно видеть итоговую картину (с учетом ошибок, проверок и метрик) в одном окне, вы делайте как удобно вам.

dothemain Автор
25.01.2018 20:30Пересборки проекта не потребуется, можно выполнять мониторинг ошибок даже сторонник приложений, если они NLog используют.

lair
26.01.2018 00:30Ключевое: "если они используют NLog".
LPDem
26.01.2018 11:06Хоть статья и про NLog, но по факту поддерживается у них и log4net, и net core logging. При необходимости можно и самому написать адаптер для любимой системы. Я, например, для javascript написал без проблем ) Само api там на json.
dothemain Автор
25.01.2018 20:36Sentry в бесплатном тарифе имеет ограничение One user, не получится использовать в команде. Ну и существующие приложения переделывать под конкретную систему мониторинга не хотелось.

crazylh
26.01.2018 07:35Таки ничего не мешает поднять selfhosted
LPDem
26.01.2018 11:08На Selfhosted надо тратить ресурсы. К тому же система мониторинга должна быть на порядок надёжнее систем, за которыми она следит, иначе в ней и смысла нет. Это всё уже значительно сложнее, особенно для небольших команд.
ohotNik_alex
26.01.2018 11:1715 минут + навыки по докеру… несколько инстансов?
если вы не можете найти ресурсов на 1 сервер — значит и приложение не такое уж огромное или просто нерентабельное.LPDem
26.01.2018 11:23А почему оно должно быть огромное? Например, у меня интернет магазин, это база данных + web + пара служб. Несложно и умещается на один виртуальный сервер. Но ошибки я же всё равно хочу мониторить. Развёртывать ради этого ещё один сервер, настраивать на нём что-то, сопровождать? Зачем?
ohotNik_alex
26.01.2018 11:30зачем сопровождать? какой-нибудь типовой jenkins годами можно не трогать — все работает. никто не заставляет вас добавлять туда модные фичи если они не нужны.
если приложение маленькое и логов мало — разграничить по уровню можно для начала.
Sentry в бесплатном тарифе имеет ограничение One user, не получится использовать в команде.
а зачем вам несколко пользователей если приложение на 1 виртуальный сервер? логи можно и под одной учеткой смотреть. не привязывать к AD и все.
LPDem
26.01.2018 11:04Sentry тоже вариант. Но это чисто облачный лог.
В статье это не очень подробно раскрыто, но Зидиум это не просто продвинутый лог, это мониторинг ошибок, с жизненным циклом каждой ошибки. Есть даже баг-трекер встроенный.
И всякие плюшки вроде метрик, но это уже не через NLog.ohotNik_alex
26.01.2018 11:11откуда здесь «облачный»? Zidium должен быть установлен на той же машине, что и приложение? из статьи мне показалось, что это не так.
Sentry ставится на отдельный сервер. в том числе и докером. арендовать хостинг не обязательно.
встроенный баг-треккер вроде в чистой Sentry отсутствует, но вот назначить ошибку на человека и пометить ее исправленной как в типовой таске — это есть.
самой лучшей плюшкой на мой взгляд является отправка на почту нотификации по подписке, что добавилось что-то новое. не надо сидеть и обновлять страницу.LPDem
26.01.2018 11:14Зидиум никуда не надо ставить. Это облачный сервис. Посмотрите на их сайте, если интересно )
И уведомления у них тоже есть, на почту и по смс.ohotNik_alex
26.01.2018 11:26лог не более 200 Мб в день на бесплатном аккаунте. ни о чем, честно говоря.
до 2000 ошибок в день против 10к на бесплатном тарифе в облаке и безлимите в локальной инсталяции. если все плохо — эти 2000 ошибок набегут очень быстро и всю вторую половину дня придется куковать. если все хорошо — лимит за сутки не перенесется.
установка на локальные сервера строго платная и обсуждается отдельно. для бизнеса хранение логов «где-то там» далеко не всегда подойдет.
инструмент несомненно интересный, но я даже личные приложения предпочитаю держать в максимально замкнутой системе.

crazylh
26.01.2018 07:33Поздравляю, вы изобрели Sentry. Расскажите зачем?
dothemain Автор
26.01.2018 08:101) чтобы использовать Sentry нужно вносить изменения в код
2) в Sentry нет проверок
3) в Sentry нет метрик
4) в Sentry нет логов
В zidium мониторинг ошибок, проверки, метрики и логи есть «всё в одном»ohotNik_alex
26.01.2018 10:15В Sentry есть логи. Все, что отправляете в логгер.
или у вас хранятся все логи. а NLog просто указывает на место?dothemain Автор
26.01.2018 10:34В личном кабинете для каждого компонента(приложения) можно установить минимальный уровень лога (например info), который будет записываться в zidium
ohotNik_alex
26.01.2018 10:49стоп… настройка NLog ведется не из приложения, а из личного кабинета?
каков принцип приема данных?
при повышении требований вы отказываетесь принимать данные или выполняется доступ к приложению с его перенастройкой?
кстати, аналогичная настройка и у Sentry -там тоже можно принимать хоть все info.
выше я еще спрашивал про прожорливость админки. подскажите, пожалуйста, как система почувствует себя на микрокомпьютере с минимумом ресурсов (кто-то типа 1 core 2GHz + 256 ram)mayorovp
26.01.2018 11:00Настройка NLog ведется, конечно же, из приложения. Только она очень простая: «пересылать все в Zidium». А у Zidium есть свои настройки — насколько я понял, в личном кабинете настраиваются уже они.
LPDem
26.01.2018 11:12Только она очень простая: «пересылать все в Zidium»
В конфиге NLog можно задать, что именно пересылать. Это фича NLog, она не зависит от того, какие адаптеры подключены.mayorovp
26.01.2018 11:54Ну, если выключить что-то на уровне NLog — то на уровне Zidium из личного кабинета включить уже не получится.
LPDem
26.01.2018 11:11пожалуйста, как система почувствует себя на микрокомпьютере с минимумом ресурсов (кто-то типа 1 core 2GHz + 256 ram)
Сам Зидиум в облаке, поэтому ваших ресурсов не тратит.
А адаптер логирования, думаю, потребляет минимально )ohotNik_alex
26.01.2018 11:32уже увидел, что selfhost версия у зидиума платная. интересовала именно она. совершенно не подходит — логи на стороне хранить желания нет ни малейшего.
LPDem
26.01.2018 11:35Ну, тут каждому своё. Сама статья несколько не про это, так что не буду флуд разводить.
dothemain Автор
26.01.2018 11:20Сначала лог фильтруется правилами Nlog, потом расширение фильтрует лог настройками из личного кабинета системы мониторинга.
crazylh
26.01.2018 16:401) чтобы использовать Sentry нужно вносить изменения в код
PM > Install-Package NLog.ZidiumА это по вашему что?
3) в Sentry нет метрик
Такой-то экспешен выпал 99 раз. Пардон, но наличие сообщений в Sentry уже само по себе метрика.
4) в Sentry нет логов
У вас будет стектрейс со всеми значениями переменных + у вас есть доступ к коду. Если вы по этим компонентам не можете реконструировать что произошло, то чем вам помогут логи?
dothemain Автор
26.01.2018 18:341) чтобы использовать Sentry нужно вносить изменения в код
PM > Install-Package NLog.Zidium
А это по вашему что?
это удобный способ установить нужные библиотеки, вы их можете и руками положить в папку с приложением если хотите. Можно даже подключиться к чужому приложению, где у вас нет исходных кодов
3) в Sentry нет метрик
Такой-то экспешен выпал 99 раз. Пардон, но наличие сообщений в Sentry уже само по себе метрика.
Имелись ввиду произвольные метрики. Sentry уведомит вас, если на диске осталось мало места? В zidium можно отправлять любые метрики и настроить пороговые значения для их контроля.mayorovp
26.01.2018 18:50Поставим вопрос по-другому, чем
Install-Package NLog.Zidiumпринципиально отличается отInstall-Package NLog.Targets.Sentry? Почему первое не считается внесением изменений в код — а второе считается?dothemain Автор
26.01.2018 19:00Ничем. Когда у меня была практика использования sentry, то все явно использовали api Sentry. Про возможность использовать Sentry из NLog я узнал из комментариев.

LeonidM
26.01.2018 10:29Класно. В конфигфайл, который доступен клиенту я включаю секретный ключ API. Никто не хочет завалить конкурента спамом? Надо лишь написать консольное приложение, которое будет генерировать разные ошибки/исключения.
ohotNik_alex
26.01.2018 10:53есть переменные окружения.
кроме того, этот ключ вероятнее всего можно поменять «на лету».
да и максимум, что уронят — систему логгирования на стороннем сервере. само приложение от этого не пострадает. (если, конечно, его не держат там же, где и отладочный инструментарий)LeonidM
26.01.2018 11:11можно поменять «на лету» == потерять логи от существующих клиентов в случае обычного (не веб) приложения. Ключ должен быть в коде(?), а не в конфиге. Но это ошибка разработчиков, а не автора.
ohotNik_alex
26.01.2018 11:34ключ может быть и в переменных окружения. (не знаю есть ли реально такая возможность у NLog)
его назначение только одно — чтобы система логгирования "узнала" отправителя.
какого-либо доступа он не даст.mayorovp
26.01.2018 11:56У Nlog такая возможность, конечно же, есть — но вот только она не поможет. Потому что у клиента Zidium свой собственный конфиг-файл.
dothemain Автор
26.01.2018 10:31Вы можете не указывать секретный ключ в конфиге, а устанавливать его программно через api.
LeonidM
26.01.2018 10:59+1В целом статья не о NLog, а о Zidium. Непонятный сервис, на котором даже нормально не зарегистрируешься (просят тлф, который я не даю всем подряд). Чистый пиар («Напишите статью или блог про систему мониторинга приложений Zidium, мы увеличим лимиты Вашего аккаунта в 10 раз»)
LPDem
26.01.2018 11:17Кстати да, указание телефона это не есть хорошо. Ну если что, есть сервисы получения разовых номеров.

achekalin
26.01.2018 11:14Написать в заголовке статьи или в первом абзаце, о какой технологии идет речь — наверное, все же бесценно.

Raimon
26.01.2018 16:07Использовал множество фреймворков логирования. Любимая, на данный момент, связка это Serilog + Seq.
lair
Серьезно. А документацию прочитать никак нельзя было, да?
Вы же понимаете, я надеюсь, что предлагаемый вами путь никак не помогает исправить ошибку, он просто позволяет узнать о ней немного раньше?
(и это не говоря про развитие систем структурированного логирования, где NLog, прямо скажем, не очень играет)
dothemain Автор
Дело не только в том, что об ошибке можно узнать раньше. Система мониторинга предоставляет для каждой ошибки стек и другую полезную техническую информацию, пользователи вам этого не сообщат в тех. поддержке, вам придется искать стек в логах, а это значит тратить время.
Например, на работе мы занимаемся поддержкой TSD (терминалы сбора данных), у нас нет доступа к этим устройствам, а ошибки исправлять надо, мониторинг ошибок тут сильно помогает. До мониторинга приходилось просить пользователей присылать логи, это было ужасно.
lair
Странно, а я думал, эту полезную техническую информацию предоставляет система логирования.
Тут помогает не мониторинг ошибок, а хранение логов не на устройстве.
dothemain Автор
Если вам нужно найти ошибку, то в большинстве случаев удобнее иметь сгруппированный список из 5 ошибок, чем лог из 1000 записей. Тот же Zidium умеет хранить логи, но я этим функционалом почти не пользуюсь (очень редко), потому что удобнее иметь список ошибок, он маленький.
lair
А чем "ошибка" отличается от "лога", простите?
А еще опыт показывает, что удобнее иметь структурированный лог, в котором есть вся информация по обрабатываемой операции, потому что самой ошибки регулярно мало для анализа.
dothemain Автор
В системе мониторинга Zidium лог — это просто строки текста, которые можно читать, фильтровать. Ошибка — это событие, которое имеет уникальный тип и стек. Ошибки группируются по типу. Для типа ошибки можно переопределить важность.
lair
Вот поэтому и надо пользоваться структурированными логами, а не "просто строками текста". Тогда, внезапно, выясняется, что, увидев ошибку, произошедшую в рамках конкретного HTTP-запроса, можно (а) посмотреть все остальные логи для этого запроса (иногда даже по распределенной системе) и (б) посмотреть, как себя вели остальные запросы на тот же адрес. В один клик.
Вот это — правда позволяет обрабатывать ошибки быстрее и эффективнее.
dothemain Автор
Структурированными логами не пользовался, надо попробовать, выглядит интересно.
LPDem
Структурированный лог, конечно, круто, но не для всех проектов нужна такая навороченность. Уже есть огромное количество сделанных сайтов и приложений, которые используют NLog или аналоги, и которые никто переделывать не будет. А подключить в конфиге адаптер для облачного мониторинга — это вполне реально, и выгода получается сразу же.
lair
А ничего навороченного, он в использовании не сложнее, чем любой другой.
Да, но это тривиальный пункт из документации на любой логгер.
LPDem
Польза от любой системы мониторинга в том, что можно обнаружить и исправить ошибку до того, как о ней узнают пользователи. Если ошибка произошла, но её успели увидеть только разработчики, то можно считать, что она и не происходила вовсе. Имея на руках стек и прочую информацию, можно быстренько поправить, прежде чем кто-то заметит.
lair
Спасибо, кэп. Но это именно "польза любой системы мониторинга", а не конкретного предложенного решения.
RomanPokrovskij
Извините, хочтеся задать вопрос по реплике: "(не говоря про) развитие систем структурированного логирования". Далее вы пишите " удобнее иметь структурированный лог, в котором есть вся информация по обрабатываемой операции". Видимо это раскрывает что за системы имеются ввиду — и да такие системы интересны. Но имеются ли ввиду библиотеки или системы соглашений?
Nlog конечно не умеет включать/выключать логирование всей информации обрабатываемой операции (и идентификацию такой операции во время исполнения) — так до сих пор я думал что это всегда решается ситуационными соглашениями по конфигурации логгирования в пользовательском коде. Можете ли дать ссылки на системы о которых вы говорите?
П.С. Сам таскаю такие соглашения из проекта в проект которые помогают включить логгинг «всего» (input, output, verbose ef, verbose custom) для конкретной операции, конкретного пользователя) при поиске глюков. Но могу сказать что такую систему соглашений в библиотеку очень трудно «запаковать» (всё пытаюсь), так как она все время хочет стать платформой: 1) появляется новый уровень абстракции — вы должны все операции запускать внутри особого хендлера — новый уровень абстракции всегда болезнено 2) кода не становится знаково меньше — определение такого хендлера в новом проекте НЕ сводится к десятку строк в одном файле 3) идет поперек доминирующей архитектурной идеи «делегируем DI в стандартный IoC контейнер» (стандартный ioc контейнер не умеет собиреть DI per-session/per-user) — «архитекторы» не принимают, что контейнер используется только для «взять конфигурацию» — а дальше строим объекты ручками (внедряя логгеры соответственно конфигурации и данным сессии — типа имени пользователя).
RomanPokrovskij
Поискал в интернете, есть такое: «структурированные логи — когда записи хранятся не просто в виде текста, а в виде структурированных данных» — не понял почему lair сказале «не про NLOG», у NLOG есть и проперти и категории, стандартый форматер в xml структуру сохранит отлично, а можно и свой написать. Реплики нуждаются в уочнении.
mayorovp
XML — это конечно хорошо, но туда надо еще и данные положить. А вот с тут-то с ними у NLog и беда: интерфейс логгеров заточен на прием текстовых данных и все.
Все богатые возможности по логированию всего и вся направлены на получение информации из окружения (статических полей), а вот чтобы записать строчку в лог указав ей при этом "Код ошибки — 0012" — приходится исхитряться.
RomanPokrovskij
Про кастом форматеры — наверняка вы правы.
Но не понял вы хотите «записать в строчку» — а это уже не «структурированный», поскольку абстракиция строка не имеет структуры. Вот если код обавить как property он его аккуратно как xml в отдельный тэг и положит (xml/nlog форматтер):
другой вопрос если вы и liar хотите форматтер в дб или любой другой ремоут, а он не пишется. понимаю, но не сочувствую (не правильно это).
mayorovp
Известно ли вам выражение «строка таблицы»? Имеет ли таблица структуру? :-)
lair
… я могу в NLog из кода написать
_logger.Info("Operation {Id} completed in {Elapsed} ms", operationId, elapsed.TotalMsи получить запись в логе со свойствамиId: ..., Elapsed: ...и возможностью выбрать все записи такого типа?RomanPokrovskij
Я сразу приведу код а потом пойду читать вашу статью (спасибо за ссылку).
var logEventInfo = new LogEventInfo()
{
Message = message,
Level = LogLevel.Info,
TimeStamp = DateTime.Now
};
logEventInfo.Properties[«Id»] = ...;
logEventInfo.Properties[«Elapsed»] = ...;
logger.Log(logEventInfo);
не совсем так как вы хотите, но записи в логе с <nlog:data name=«Elapsed» value="..." /> вы получите.
Про «выбрать запросы» я в недоумении, это задача другого уровня, в моей голове есть шаблон «лог надо скормить системе мониторинга и у нее и запрашивать».
lair
Значит, я был неправ, и NLog тоже научился структурированные данные. Когда я с ним работал, этого либо не было, либо, что более вероятно, это не было на поверхности.
В вашем примере нет одного важного пункта: а как, собственно, выглядит сообщение в коде и в логе (причем как структурированном, типа Эластика или Seq, так и, что важнее, в обычном, типа файлового, при настройках по умолчанию).
RomanPokrovskij
Полностью сообщения я не приевел, но отрывок (хмл) привел. Можно ли писать в файл с другой струкутрой то это не один а множество вопросов: 1) позовляет ли layout отформотировать properties как хочется? или 2) можно ли создать кастом форматер? Мне помнится да, но могу соврать — надо пробовать.
Я лучше поясню почему использую xml для verbose. Потому что не использую эластик для трейсинга (т.е. для отлавливания ошибок). Для трейсинга моя «платформа» работает лучше: клиент жалуется, включил ему и только ему трейсинг — или же редкая операция падает — включил трейсинг только ее (все без переустановки). При чем можно задать собирать сообщения с начала операции, в буфер, а сбросить буфер в файл реагируя на событие (вылет с ошибкой, нужный результат, слишком долгое исполнение). Порции данных получаются и полными и только то что необходимо. В xml же проще видны многострочные данные (сериализированный output, stacktrace).
А для мониторинга, сбора статистики я просто имею дюжину разных файлов которые можно грузить в эластик, но форматирую их прямо в строке, это жестко, но это файлы с жестко заданой целью (только длитиельность исполнения, только броузеры/разрешения и т.д.). Если цель лога жесткая то и формат жесткий: нет причин вводить лишние абстракции.
lair
Я спрашивал про текстовое сообщение, человекочитаемое. В моем примере это
"Operation {Id} completed in {Elapsed} ms"в коде иOperation CQ/15/83 completed in 182 msв логе.Лучше по сравнению с чем?
Я вот обычно заранее не знаю, что необходимо.
Хорошо, когда у вас есть конечное число жестко заданных целей. А мне надоело делать отдельный логгер под отдельную задачу.
RomanPokrovskij
я могу включать то что мне нужно (а именно инпут, оутпут, кастом вербос, вербосе EF с фильтром по операции/категории, пользователю, результату; есть еще опции, но список их безусловно конечен, т.е. то что предусмотрено ) без переустановки приложения.
Лучше потому что у меня точно контроллируемый IO и performance. Я не готов ими жертвовать ради того «что когда-нибудь мне может что-то понадобится». И я не готов держать в голове и осложнять себе трейсинг размышлениями кто создает мне эту нагрузку «апликация» или «трейсинг».
и трейсинг с логгингом я различаю безусловно.
lair
Эм, "я" (точнее, правильно написанная система) тоже так может. Непонятно, чему вы противопоставляете свой подход.
У полностью включенного логирования они тоже точно контролируемые.
Ну зато вы, видимо, готовы разбирать инцидент при его повторе, а не первом случае.
Ну так перформанс-тесты вроде как для этого существуют.
RomanPokrovskij
Во-первых если это вылет с ошибкой — я все же стактрейс имею, во вторых если это вылет с ошибкой и не периодическая операция — я имею почти все (по дефолту для таких операций идет сбор информации в буфер, и сброс на вылет с ошибкой). В третьих:
разбор инцидента вот просто «всегда» включает в себя повторение, и вопрос «можно ли повторить» — это первое что требуется установить. Когда пытаюсь повторить и включаю полный трейсинг. Так что такой задачи «со 100% успеха пойми в чем дело» просто нет. Не достижимы 100%
lair
Ну то есть ваш подход, на самом деле, ничем не отличается от "логируем все", только у вас есть ненулевой шанс потерять ваш буфер.
Угу, и вот для этого очень полезны логи.
Обратите внимание, вы так и не ответили на вопрос про текстовое представление сообщения в NLog.
RomanPokrovskij
я ответил: мне кажется можно. mayorovp
говорит что кажется нельзя. нужно смотреть документацию.
вы извините, я просто под рукой кода не имею, мне кажется я где-то в layout задавал форматирование propoerty
lair
Это не то. Мне нужно, чтобы формат текстового сообщения задавался программистом в момент вывода (я выше привел пример, как это выглядит).
Layout в конфиге просто не может знать про все property, их в приложении сотни.
RomanPokrovskij
я не очень понял что такое момент вывода
но то что вы привели выше
как по мне так точно можно сделать имея API вида.
и кастом форматера который выводит все properties.
может есть и из коробки.
lair
В коде я пишу:
_logger.Info("Operation {Id} completed in {Elapsed} ms", operationId, elapsed.TotalMs)В другом месте я пишу:
_logger.Verbose("User {Name} expired on {ExpirationDate}", username, DateTime.Now)В конфиге я пишу:
В файле получаю:
Но если я настрою конфиг так, что он будет писать в Seq или Elastic, я получу там и сообщение, и тип сообщения (
Operation {Id} completed in {Elapsed} msиUser {Name} expired on {ExpirationDate}), что позволит мне выбрать все сообщения такого типа (например, для графика по времени), и все переданные данные, что позволит мне, например, вытащить все сообщения, связанные с конкретной операцией.RomanPokrovskij
Спасибо за разъяснения. Я наверное устал и магию не увидел :( «ну просто такой кастом форматер». А можно сформулировать так: что нужно от API loggerа кроме возмжности задавать properties отдельно от сообщения (что с NLog возможно). Если ничего более — значит тред закончен.
lair
Я вам выше показал: возможность использовать переданные properties в сообщении. NLog это может?
mayorovp
Возможно, это повод перейти на другой контейнер...
RomanPokrovskij
а есть такие контейнеры? порекомендуйте.
я не сильно искал, потому что предпологаю, что если контейнер будет такой гибкий, что может все, даже по значению полученому в httprequest собрать мне акшн со всем полным verbose трейсингом по всей трубе, то ожидаемо что кода будет не меньше (чем при ручной сборки зависимостей), а сложности добавит еще как (болезненная новая абстракция).
mayorovp
Autofac умеет per-session, но не из коробки (надо собрать свой ILifetimeScopeProvider). C per-user то же самое.
Ninject умеет как per-session, так и per-user, или вовсе per-что-угодно из коробки (но вам все равно придется вручную уведомлять Ninject об окончании времени жизни ваших скоупов).
RomanPokrovskij
Спасибо за рекомендации. обязательно посмотрю для саморазвития, да и названия громкие, раньше или позже увижу у клиентов.
Скажите а вы сами что думаете о пользе приносимой внешними «третьесторонними» контейнерами? Я никак не могу увидеть их преимуществ перед «кастомными контейнерами» и собиранием зависимостей руками (контейнер как шаблон, а не как библиотека). Ну напр перед таким кодом:
Я не могу принять аргументы про «велосипед», тут нет никакого велосипеда. Про меньше кода — не на столько меньше.
У автоконтейнеров может быть динамическое связывание и видимо на них можно строить системы плагинов — но если такой задачи нет?
mayorovp
Контейнер помогает не забыть какую-нибудь ерунду когда кода много.
RomanPokrovskij
Спасибо за короткий список. С одной стороны мой опыт говорит что при ручном внедрении зависимостей, компилятор гораздо чаще помогает «не забыть» о новых параметрах, и избавляет от разных неприятных совпадений — вещи которые скрывает генерик контейнер и которые выясняются только в рантайм… С другой стороны в контейнере чистого ASP MVC Core приложения — зарегистрировано… 260 типов. Да это много кода и, согласен, только через дженерик контейнер можно предоставить возможность их всех перегрузить. Но это МС архитектор сидит и думает: как же им возможность такую предоставить. А что прикладнику надо думать о том же — это не очевидно. Да и два контейнера 1) генерик для платформы и 2) «ручного внедрения» будут жить независимо и «много кода» — никогда не попадает из 1го во 2ой потому что живут на разных уровнях.
Извиняюсь за длинноты и неуместную агитацию.
mayorovp
Ну вот вы, к примеру, только что забыли что надо еще и Dispose() всем созданным объектам вызывать… Сильно помог компилятор? :-)
RomanPokrovskij
Правильное решенение лежит в смене парадигмы на функциональную. Тогда на прикладном уровне просто нет оставляется возможность забыть о dispose.
тут dbContext будет жить ровно столько сколько нужно.
mayorovp
Это тоже хорошая практика — но она не подходит именно для тех случаев с которых вы начали разговор — для per session и per user объектов.
RomanPokrovskij
Именно так и работает! Создам container под данную сессиию и данного юзера и он соберет мне все как надо.
Я наоборот скажу я не могу представить ничего более удобного.
mayorovp
У как это будет выглядеть? В какой момент вы будете вызывать Dispose?
RomanPokrovskij
dipose dbContext'у вызовется сразу же как dbContextHandler выполнет код. Но мне не надо сохранять контекст на жизнь всей сессии. Мне надо чтобы во время сессии создавались «одинаково сконфигурированные» контекты (с тем же самым логгером, и даже логгер не надо чтобы жил сессию, мне надо чтобы он одинаково был сконфигурирован).
mayorovp
У вас в программе что, dbContext — единственный объект который требует Dispose()?
RomanPokrovskij
Их всегда еденицы. Если вы не пишите монолитного монстра.
lair
Как вам везет, однако. У меня вот много разных сервисом, работающих с ресурсами.
lair
А
dbContextHandlerнадо руками написать, да?RomanPokrovskij
И да и нет. Можно руками один раз на проект, а можно generic из своей библиотеки (я знаю новая абстракция это тяжело для других, должна быть мотивация, и тут вопрос на сколько вам важно избавиться от забытых dispose).
lair
Ну то есть все равно надо написать (либо в проекте, либо в библиотеке). А вы говорите — кода не больше.
У меня проблему забытых
Disposeрешает контейнер, так что мне это просто не нужно.RomanPokrovskij
А теперь пусть вам контейнер генерирует dbContext per user/per session? т.е. строит dbContext с логгерами которые зависят от httprequest. Контейнер платформы сможет такое?
lair
http://docs.autofac.org/en/latest/lifetime/instance-scope.html#instance-per-request
У меня работает в ванильном asp.net, OWIN и WebAPI.
RomanPokrovskij
Я в autofac не могу, я могу без него. Но поскольку у autofac авторитета больше придется присудить ему и вам победу.
Но не все ваши аргументы были удачны, или хорошо сформулированы, я бы это хотел донести. Надеюсь дискуссия была взаимовыгодной.
lair
Тогда не понятно, зачем вы спрашивали о преимуществах.
RomanPokrovskij
не знал — потому и спрашивал у знающих «можно ли такое или нет» есть премущества или нет? затем уже вопросы были ко мне (я благодорен за них, на самом деле я хоть и горжусь своим метапрограммированием, но не понимаю как его представить хотя бы даже в песочнице хабра).
lair
Не очень понятно, зачем вообще нужен такой контейнер, как вы показываете. Как его ожидаемый сценарий использования?
RomanPokrovskij
это ровно то что делает любое дженерик контейнер. я не понимаю смысл слова «зачем нужен». вот делает тоже что и дженирик.
lair
Я не уверен, что "любой дженерик контейнер" делает то же самое. Просто покажите конкретный пример использования, если не сложно.
RomanPokrovskij
там в верху есть использование контейнера для получения хендлера
вот вариант использования в качестве service locator. разница с использованием generic IServiceCollection мне была бы не заметна
lair
Это сервис-локатор. Я, скажем, использую сервис-локаторы только в случае невозможности написать иначе, и предпочитаю dependency injection. Как мне поможет ваш контейнер?
RomanPokrovskij
ммммм… IoC container и DI это разные вещи. вы же грамотный разработчик, мне очень не хочется с вами спорить, но вы просто не правы с такой формулировкой. то что у меня cutom container (сборщик зависимостей) а у вас generic не ставит между нами стены. может переформулируете?
lair
Я сказал именно то, что сказал. Я использую контейнер для DI, а не для SL. Как мне поможет ваш контейнер?
RomanPokrovskij
Не понимаю.
Вот два контейнера
как то что вы используете первый а я второй делает вас православным пользователем DI а меня еретиком? Я тоже люблю DI.
lair
Я (практически) не использую первый. Он используется фреймворками, на которых я пишу (и для которых придется написать дополнительный код, чтобы подключить ваш контейнер), а я работаю напрямую с созданными объектами, получая зависимости "магическим образом".
RomanPokrovskij
Да все так. Всех радует магия. Прикладники начинаюь писать свой код с этой радостью. Теперь появляется идея: а давайте регистрировать свои зависимости в контейнере платформы, а если он не тянет — меняем, давайте подсунем платформе другой контейнер.
В ASP я так же как и вы получую контроллер из контейнера платформы со всем чем в конструкторе. Затем в начале акшна получу создам свой кастом контроллер (передав динамическую информацию сессии или юзера) я даже могу получить factory этого моего контроллера из контейнера платформы и в этот factory скину динамические параметры (разницы нет). и начну получать свои компоненты из своего кастом контроллера. и на уровне business service ровно такой же DI продолжится: вот в реализации MyService в конструкторе все зависимости будут получены ровно согласно принцпипам DI, соберет не контейнер платформы, а мой. Понимаете? Контейнер не обязан быть всеобщим и дженерик. Контейнер обязан собирать зависимости и все.
lair
… это работает через ваш самописный котейнер?
… кажется, нет. Теперь у вас в системе два контейнера. И зачем мне это?
RomanPokrovskij
Вы цепляетесь к словам а не к архитектуре. Назовите мой контейнер «динамическим сборщиком зависимостей» в отличии от «статитического сборщика платформы» и вопрос исчезнет.
lair
А зачем мне два сборщика? Суть-то не меняется, как вы их не назовите.
У меня есть контроллер в WebAPI, он получает в конструктор правильно инициализированные зависимости, они при создании получают в конструктор правильно инициализированные зависимости, и так далее. И ничто из этого даже не знает, какой контейнер использовался (и использовался ли).
RomanPokrovskij
«Два сборщика» не название проблемы, как например «был один сервис стало два сервиса» не может быть проблемой, или «два builderа», надо понимать в чем трейдофф. «Ничто не знает» — не преимущество безусловное, поскольку ну а что в том что асп контроллер, знает о каком-то фактори в который скинет динамическую информуцию и далее получит business service из него? Что тут сломано?
lair
Здесь внесена лишняя зависимость, которая не приносит практической пользы (и усложняет миграцию в случае необходимости).
RomanPokrovskij
1) будующей миграцией оправдывают любой овердейзайн. как отличить отмазку от аргумента?
2) как это усложнит миграцию? кастомный сборник зависимостей — это ваш/мой код и все что он делает — собирает зависимости (нет ничего внешнего).
lair
… а чем вы оправдываете лишнюю зависимость, напомните?
Надо будет переписать весь код, зависящий от вашего кастомного контейнера. В том числе — в вашем случае — код внутри контроллера.
RomanPokrovskij
> а чем вы оправдываете лишнюю зависимость, напомните?
лишнюю абстракцию — мне так более понтяно — я оправдываю тем что она мне обеспечивает результат: построение бизнес сервисов с динамически заданым уровнем логгирования (конкретную сессию, конкретный данный акшн, на конкретный результат и т.д. надеюсь не забыли, действительно надеюсь — потому что именно гибкостью и хотел удивить). и я хочу думать как раз без лишних зависимостей обеспечивает: никаких autofac и ninject (вот уж где явные лишнии зависимости). и вы так представляете что кастом контейнер это какой-то сложный код. да это примитивное: проверь условие создай-положи в конструктор.
lair
Нет, именно зависимость. То, от чего зависит ваш контроллер.
Это все можно сделать на стандартном Autofac + Serilog. Так что вашу зависимость это никак не оправдывает.
Тем обиднее его писать каждый раз.
RomanPokrovskij
Почему вы отказываете Autofac в праве считаться зависимостью? мне аутофак не нужен, мне проще реализовать паттерно IoC Container самому под данный проект, уникальный да. уникальный но именно что дев-тайм. в этом есть преимущества.
lair
Потому что контроллер про него не знает.
RomanPokrovskij
если про него знает references ассембли это зависимость. будем считать что мы тут приниципиально расходимся. но кажется друг друга поняли.
А что если контроллер сам по себе генерируем и в нем не строчки кастомного кода? Строится по мете? Т.е. вызов создания моего кастомного контроллера в коде проекта есть только один раз, в одном фале (так же как и у вас autofac конфигурирутеся один раз)?
lair
Нет. Мы говорим про зависимости code units, а не сборок.
То непонятно, зачем вообще тратить на него силы.
mayorovp
В аду есть отдельный котел для тех кто складывает контейнер внутрь контейнера...
lair
Вот, кстати, хороший вопрос в контексте поста: как в вашем кастомном контейнере сделать так, что если какой-то компонент требует в качестве зависимости
ILogger, этотILoggerпараметризуется полным именем типа. Иными словами, мы для каждого компонента автоматически имеем логгер, в котором прописан правильный контекст.RomanPokrovskij
lair, ну все зависимости которые собирает контейнер можно собрать «руками», просто все. вы лучше скажите что должен показать вами выбранный пример?
lair
И написать для этого много повторяющегося кода. Зачем, если можно отдать это контейнеру?
Пример пользы, которую приносит готовое решение, по сравнению с самописным.
RomanPokrovskij
почему он должен быть повторяющимся. повторяющий код заключается в методы и перестает быть повторяющимся.
это работает в обе стороны: мне не ясна польза от регистрации своих зависимостей в контейнере платформы.
кроме того для меня польза очевидна. я могу без всякого труда собирать зависимости на динамических параметрах. у меня есть такой запрос
lair
Вот у вас есть сто конструкторов, каждый из которых принимает
ILogger. Остальные параметры у них отличаются. Приблизительно вот так:Как вы вынесете это в метод?
Я никакой не вижу. Иногда это, вероятно, требование.
RomanPokrovskij
повторю, я не пишу монолиты где вызовы ста сервисов. ставьте минус.
а создание зависимостей для своего скромного набора сервисов из каких пяти-десяти штук, я действительно пропишу вот так как вы показали. но я думаю и на сотню решусь: больше контроля компилятору в таком аду это наверное еще более важно.
lair
Вот вам и еще пример, где в вашем подходе надо писать больше кода.
Как компилятор спасет вас от следующей ошибки:
RomanPokrovskij
Я не говорил что больше не будет, будет. Я говорил можно избежать повторяещегося кода.
Вместо вашего у меня будет что-то вроде
вместо httpRequest можно любую динамическую информацию. понимаете, когда нужно трейсить мне нужно всё, а когда нужно — решается динамически. именно из этой потребности вытекают все мои решения. т.е. мне не надо сильно различать разные уровни логгирования для разных бизнес сервисов для трейсируемой сессии.
другой вопрос что если очень надо (например добавить категорию «имя бизнес сервиса») все это можно чисто программерскими методами решить (я тоже могу в рефлекшн и execution trees) как и генерик контейнер…
lair
Вы его не избежали.
Это не решает поставленную задачу: вброшенный логгер ничего не знает о сервисе, в который он вброшен.
Ну то есть написать еще кода, причем я пока даже не понимаю, какого, чтобы сохранить ваше ручное создание каждого сервиса.
И все это вместо того, чтобы взять готовое решение, которое все это умеет. Я решал ровно эту задачу на прошлой неделе, это потребовало доставить один пакет и вписать одну строчку кода.
RomanPokrovskij
нет, не для создания сервиса — для этого кода не надо, а для возможности принципиально недопустить ту возможную ошибку которую вы указали. я надеюсь что вы не будете допускать эмоционально окрашенных упрощений.
понимаете, это не совсем так. логгеры это не весь трейдофф за сто моих срочек кода против вашей одной. вот как выглядит мой контроллер:
В зависимости от мета (EF Core модели) он создаст полностью рабочий контроллер по стандартным лекалам с поддержкой редактирования one-many и many-many, возможностью перехвата ошибки дб и семантического его разбора, с возможностью проверки ошибки синхрона через rowversio, и еще многих разных штук. Это тысячи строк кода которые входят в наш трейд офф.
Только не подумайте что я только из таких контроллеров апликацию создаю, просто новый уровень абстракции «dbcontexthandlerов» мне позволил сделать «T4 генерируремые контроллеры» через execution tree.
П.С.
Это пример не кастом контроллера (он тут скрыт и будет создан глубже из динамики и IConfigurationRoot) а того что можно сделать имея новые абстракции.
lair
То есть конструкторы в вашем коде мне померещились?
Вот я и говорю, я пока не очень понимаю, как вы это сделаете, не написав свой собственный дженерик контейнер.
Нет, не входят. Потому что это не функциональность DI. (При этом нет никаких проблем вынести эту фабрику в тот же Autofac).
Угу, написать контроллер, который состоит исключительно из делегирования. Еще пара десяток строчек кода, без которых можно было бы обойтись.
lair
Давайте я просто дам ссылку, там много полезного сказано, и это будет быстрее, чем я это перепишу: https://nblumhardt.com/2016/06/structured-logging-concepts-in-net-series-1/