
История появления
Одной из главных целей команды разработчиков GitHub всегда была высокая производительность. У них даже существует поговорка: «it's not fully shipped until it's fast» (продукт считается готовым только тогда, когда он работает быстро). А как понять, что что-то работает быстро или медленно? Нужно мерять. Измерять правильно, измерять надёжно, измерять всегда. Нужно следить за измерениями, визуализировать всевозможные метрики, держать руку на пульсе, особенно, когда дело имеешь с высоконагруженными онлайн системами, такими как GitHub. Поэтому метрики — это инструмент, позволяющий команде предоставлять столь быстрые и доступные сервисы, почти без даунтаймов.
В своё время GitHub одними из первых внедрили у себя инструмент под названием statsd от разработчиков из Etsy. statsd — это агрегатор метрик, написанный на Node.js. Его суть состояла в том, чтобы собирать всевозможные метрики и агрегировать их в сервере, для последующего сохранения в любом формате, например, в Graphite в виде данных на графике. statsd — это хороший инструмент, построенный на UDP сокетах, удобный в использовании как на основном Rails приложении, так и для сбора простейших метрик, наподобие вызова nc -u. Проблема с ним начала проявляться позже, по мере роста количества серверов и метрик, отправляемых в statsd.
Так, например, некоторые метрики показывались некорректно, а некоторые, в особенности новые, вообще не собирались. Виной тому были почти 40%-ые потери UDP пакетов, которые просто не успевали обработаться и отбрасывались. Природа однопоточного Node.js с использованием единственного UDP сокета дала о себе знать.
Но масштабировать было не так просто. Для того, чтобы распределить сбор и обработку пакетов по нескольким серверам, нужно было шардировать не по IP, а по самим метрикам, иначе бы на каждом сервере был свой набор данных для всех метрик. А задача шардирования по метрикам непростая, для её решения GitHub написал свой парсер UDP пакетов и балансировку по названию метрики.
Это сгладило ситуацию, позволило увеличить количество инстансов statsd до четырёх, но являлось полумерой:
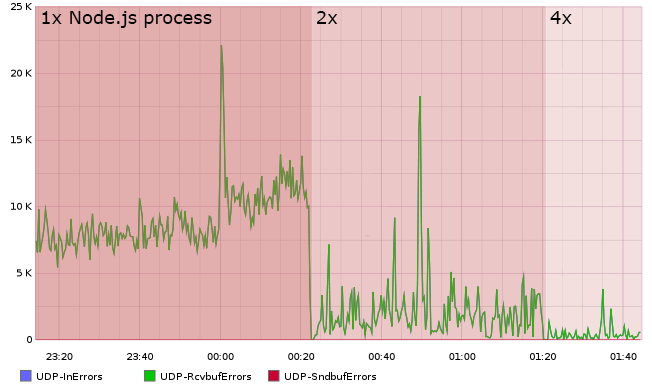
4 сервера statsd, еле собирающих метрики, плюс самописный балансировщик нагрузки, занимающийся парсингом UDP пакетов, в итоге вынудил переписать всё более правильно, на чистом С, с нуля, сохранив обратную совместимость. Так появися Brubeck.
Brubeck
Но переписывание Node.js приложения (event-loop, написанный на С на основе libuv) на чистый С, с использованием того же самого libuv — сомнительное занятие. Поэтому решено было пересмотреть саму архитектуру приложения.
Во-первых, отказались от event-loop на сокете. Действительно, когда в тебя льётся 4 миллиона пакетов в секунду, нет смысла каждый раз крутиться в цикле и спрашивать, не появились ли новые данные для чтения, так как, скорее всего, они там уже появились, и не одни :)
Event-loop заменили на пул потоков воркеров, использующих один общий сокет с сериализацией доступа к нему. Позже, механизм улучшили ещё, добавив поддержку SO_REUSEPORT для сокетов из linux 3.9, что позволило отказаться от сериализации доступа воркеров к сокету в самом агрегаторе. (прим. по этой теме интересно будет почитать статью как nginx внедрил поддержку SO_REUSEPORT).
Во-вторых, наличие нескольких потоков, работающих с одними и теми же метриками, означает, что у нас разделение данных. Для безопасного доступа к разделяемым данным необходим механизм синхронизации доступа, например, локи (lock), что не есть хорошо в условиях высокой конкуренции за доступ к данным и при необходимости высокой производительности. На помощь приходят lock-free алгоритмы, в частности, lock-free реализация хеш-таблицы, в которой хранятся метрики. (на самом деле там lock-free только на чтение, а на запись optimistic locking, но это не страшно для приложений с высоким reads-to-writes rate, т.к. метрики добавляются и удаляются гораздо реже, чем приходят в них сами данные).
В-третьих, агрегация данных внутри одной метрики синхронизировалась через spinlock — крайне дешёвый механизм в плане затратов ресурсов CPU и переключения контекстов, что так же не вызвало затруднений, т.к. борьбы за данные внутри одной метрики почти не было.
Результат
Простая многопоточная архитектура агрегатора позволила добиться неплохих результатов: на протяжении последних двух лет единственный сервер с Brubeck дорос до обработки 4.3 миллиона метрик в секунду, без потери пакетов даже в пиковой нагрузке. Вся инфа и данные достоверно взяты с блога разработчиков.
Brubeck был выложен в open-source: github.com/github/brubeck
В нём уже есть многое из statsd, но ещё не всё. На данный момент разработка ведётся активно, сообщество находит баги и быстро исправляет.
Комментарии (11)

nucleusv
24.06.2015 12:54Не пробовали github.com/lomik/go-carbon?



kt97679
25.06.2015 05:26Из statsd можно собрать кластер при помощи вот этого: github.com/hulu/statsd-router

octave
28.06.2015 20:32Есть еще Heka hekad.readthedocs.org/en/v0.9.2 — не знаю, на сколько производительный, но он еще и logstash заменяет.
octave
28.06.2015 20:39А вообще, не совсем понятно, зачем агрегировать метрики со всех серверов на одном бедном statsd/brubeck/whatever? Мы держим statsd на каждом сервере, агрегируем на месте и складываем оттуда напрямую в графит. Проблем с произвотидельностью statsd не было, даже на балансерах, где проскакивает 2600 метрик в секунду. Не 4.3 миллиона, конечно, но у нас столько и не будет никогда с одного сервера.
Один общий statsd/аналог следует держать рядышком для подсчета гистограм/персентилей, ибо их нужно агрегировать в одном месте. «Гистограммные» метрики — это около 5% от всех наших метрик, что пишем. Так что, statsd там тоже хватит.kt97679
29.06.2015 00:00Каким образом у вас одни метрики идут на локальный statsd, а другие на общий? Это логика вашего приложения и вы используете разные адреса для разных метрик?
octave
29.06.2015 08:07Сейчас никак, мы только планируем это делать. Сейчас у нас персентили считает каждый сервер сам по себе, что не совсем удобно, когда хочется посмотреть общую картину. Тут есть несколько вариантов:
1. Проксировать «персентильные» метрики конвенционально по имени (скажем, если есть суффикс «histogram»)
2. На уровне конфига statsd/аналога перечислять список метрик (возможно, со звездочками) которые пойдут на центральную считалку. Тут Heka выглядит более удобным инструментом для таких дел. Поскольку помимо метрик если еще и логи, которые тоже нужно доставлять, а с Хекой их еще можно сразу превращать и в метрики за компанию.
3. В логике приложения я бы этого не делал. У нас несколько десятков сервисов на разных языках, работают над ними разные команды. Данную логику лучше инкапсулировать на уровне платформы и протокола, чтобы минимизировать риск что-то сделать не так. Суффикс «histogram» кажется приемлемым компромиссом.

knutov
05.07.2015 15:32А есть где-то мануал, как все поставить с нуля, включая агентов и вебинтерфейс?
realloc
Чем он лучше statsite?
hell0w0rd
Вы статью вообще не читали? Отказались от event-loop архитектуры, тк в таком проекте она бесполезна, idle не бывает.
По ссылке используется libevent github.com/armon/statsite/blob/master/src/networking.c#L30