

Последние три года я занимаюсь разработкой серверов на Node.js и в процессе работы у меня накопилась некоторая кодовая база, которую я решил оформить в виде фреймворка и выложил в open-source.
Основными особенностями фреймворка можно назвать:
- простую архитектуру, без всякой JS – магии
- автоматическую сериализацию/десериализацию моделей (например, не нужно проверять пришло ли поле с клиента, все проверяется автоматически)
- возможность генерации схемы API
- генерацию документации на основе схемы
- генерацию полностью типизированного SDK для клиента (на данный момент речь про JS frontend)
В данной статье мы поговорим немного о Node.js и рассмотрим данный фреймворк
Всем кому интересно – прошу под кат
В чем же проблема и зачем писать очередной велосипед?
Основная проблема серверной разработки на Node.js заключается в двух вещах:
- отсутствие развитого сообщества и инфраструктуры
- достаточно низкий уровень вхождения
С отсутствием инфраструктуры все просто: Node.js достаточно молодая платформа, поэтому вещи, которые можно удобно и быстро написать на более взрослых платформах (например тот же PHP или .NET) в Node.js вызывают сложности.
Что же с низким уровнем вхождения? Тут основная проблема в том, что с каждым оборотом колеса хайпа и приходом новых библиотек/фреймворков, все пытаются упростить. Казалось бы, проще — лучше, но т.к. пользуются этими решениями в итоге не всегда опытные разработчики — возникает культ поклонения библиотекам и фреймворкам. Наверное самый очевидный пример — это express.
Что не так с express? Да ничего! Нет, безусловно в нем можно найти недостатки, но express — это инструмент, инструмент которым нужно уметь пользоваться, проблемы начинаются когда express, или любой другой фреймворк, занимает главную роль в вашем проекте, когда вы слишком завязаны на нем.
Исходя из вышеперечисленного, начиная разрабатывать новый проект, я начал с написания некоторого "ядра" сервера, позже оно переносилось в другие проекты, дорабатывалось и в конечно итоге стало фреймврком Airship.
Основная концепция
Начиная продумывать архитектуру я задал себе вопрос: "Что делает сервер?". На самом высоком уровне абстракции сервер делает три вещи:
- получает запросы
- обрабатывает запросы
- отдает ответы
Все же просто, зачем усложнять себе жизнь? Я решил, что архитектура должна быть примерно следующей: у каждого запроса, поддерживаемого нашим севером, есть модель, модели запросов поступают в обработчики запросов, обработчики в свою очередь отдают модели ответов.
Важно заметить, что наш код ничего не знает про сеть, он работает только с инстансами обычных классов запросов и ответов. Этот факт позволяет нам не только доиться более гибкой архитектуры, но и даже сменить транспортный слой. Например мы можем пересесть с HTTP на TCP без изменения нашего кода. Безусловно это очень редкий случай, но такая возможность показывает нам гибкость архитектуры.
Модели
Начнем с моделей, что от них нужно? В первую очередь нам нужен простой способ сериализации и десериализации моделей, еще не помешает валидация типов при десериализации, т.к. пользовательские запросы — это тоже модели.
В дальнейшем описании я опущу некоторые детали, которые можно прочитать в документации, чтобы не раздувать статью.
Вот как это работает:
class Point {
@serializable()
readonly x: number
@serializable()
readonly y: number
constructor(x: number, y: number) {
this.x = x
this.y = y
}
}Как видим, модель — это обычный класс, единственное отличие — это использование декоратора serializable. С помощью этого декоратора мы указываем поля сериализатору.
Теперь мы можем сариализировать и десериализировать нашу модель:
JSONSerializer.serialize(new Point(1,2))
// { "x": 1, "y": 2 }
JSONSerializer.deserialize(Point, { x: 1, y: 2 })
// Point { x: 1, y: 2 }Если мы передадим данные неверного типа, то сериализатор выбросит исключение:
JSONSerializer.deserialize(Point, { x: 1, y: "2" })
// Error: y must be number instead of stringМодели запросов
Запросы — это те же модели, разница в том, что все запросы наследуются от ASRequest и используют декоратор @queryPath для указания пути запроса:
@queryPath('/getUser')
class GetUserRequest extends ASRequest {
@serializable()
private userId: number
constructor(
userId: number
) {
super()
this.userId = userId
}
}Модели ответов
Модели ответов тоже пишутся как обычно, но наследуются от ASResponse:
class GetUserResponse extends ASResponse {
@serializable()
private user: User
constructor(user: User) {
super()
this.user = user
}
}Обработчики запросов
Обработчики запросов наследуются от BaseRequestHandler и реализуют два метода:
export class GetUserHandler extends BaseRequestHandler {
// в этом методе мы обрабатываем запрос и возвращаем ответ
public async handle(request: GetUserRequest): Promise<GetUserResponse> {
return new GetUserResponse(new User(....))
}
// этот метод показывает какой запрос поддерживает обработчик
public supports(request: Request): boolean {
return request instanceof GetUserRequest
}
}Т.к. при таком подходе не очень удобно реализовывать обработку нескольких запросов в одном обработчике – существует потомок BaseRequestHandler, который называется MultiRequestHandler и позволяет обрабатывать несколько запросов:
class UsersHandler extends MultiRequestHandler {
// указываем какой запрос обрабатывает этот метод
@handles(GetUserRequest)
// теперь все запросы GetUserRequest будут попадать в этот метод
public async handleGetUser(request: GetUserRequest): Promise<ASResponse> {
}
@handles(SaveUserRequest)
public async handleSaveUser(request: SaveUserRequest): Promise<ASResponse> {
}
}Получение запросов
Существует базовый класс RequestsProvider, который описывает поставщика запросов в систему:
abstract class RequestsProvider {
public abstract getRequests(
callback: (
request: ASRequest,
answerRequest: (response: ASResponse) => void
) => void
): void
}Система вызывает метод getRequests, ждет запросов, обрабатывает их и передает ответ в answerRequest.
Для получения запросов по HTTP реализован HttpRequestsProvider, он работает очень просто: все запросы приходят через POST, а данные приходят в json. Использовать его тоже просто, достаточно передать порт и список поддерживаемых запросов:
new HttpRequestsProvider(
logger,
7000,
// поддерживаемые запросы
GetUserRequest,
SaveUserRequest
)Соединяем все вместе
Основной класс сервера — это AirshipAPIServer, в него мы передаем обработчик запросов и поставщика запросов. Т.к. AirshipAPIServer принимает только один обработчик — был реализован менеджер обработчиков, который принимает список обработчиков и вызывает нужный. В итоге наш сервер будет выглядеть так:
let logger = new ConsoleLogger()
const server = new AirshipAPIServer({
requestsProvider: new HttpRequestsProvider(
logger,
7000,
GetUserRequest,
SaveUserRequest
),
requestsHandler: new RequestHandlersManager([
new GetUserHandler(),
new SaveUserRequest()
])
})
server.start() Генерация схемы API
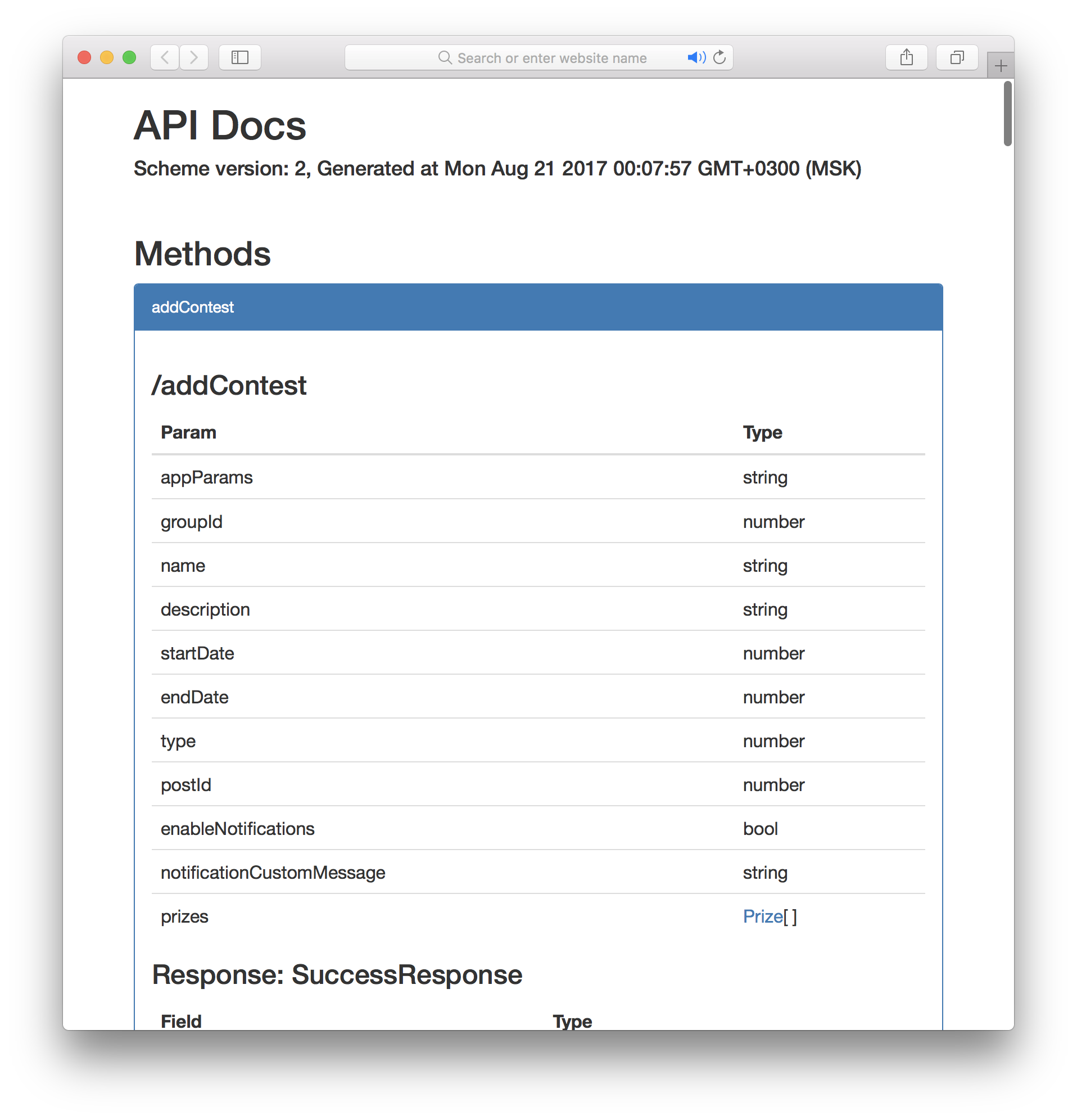
Схема API — это такой специальный JSON, который описывает все модели, запросы и ответы нашего сервера, его можно сгенерировать с помощью специальной утилиты aschemegen.
В первую очередь нужно создать конфиг, который укажет все наши запросы и ответы:
import {AirshipAPIServerConfig} from "airship-server"
const config: ApiServerConfig = {
endpoints: [
[TestRequest, TestResponse],
[GetUserRequest, GetUserResponse]
]
}
export default configПосле этого мы можем запустить утилиту, указав путь до конфига и до папки, в которую будет записана схема:
node_modules/.bin/aschemegen --o=/Users/altox/Desktop/test-server/scheme --c=/Users/altox/Desktop/test-server/build/config.jsГенерация клиентского SDK
Зачем же нам нужна схема? Например мы можем сгенерировать полностью типизированное SDK для фронтенда на TypeScript. SDK состоит из четырех файлов:
- API.ts — основной файл со всеми методами и работой с сетью
- Models.ts — тут находятся все модели
- Responses.ts — тут все модели ответов
- MethodsProps.ts — тут интерфейсы, описывающие запросы
Приведу кусок API.ts из рабочего проекта:
/**
* This is an automatically generated code (and probably compiled with TSC)
* Generated at Sat Aug 19 2017 16:30:55 GMT+0300 (MSK)
* Scheme version: 1
*/
const API_PATH = '/api/'
import * as Responses from './Responses'
import * as MethodsProps from './MethodsProps'
export default class AirshipApi {
public async call(method: string, params: Object, responseType?: Function): Promise<any> {...}
/**
*
*
* @param {{
* appParams: (string),
* groupId: (number),
* name: (string),
* description: (string),
* startDate: (number),
* endDate: (number),
* type: (number),
* postId: (number),
* enableNotifications: (boolean),
* notificationCustomMessage: (string),
* prizes: (Prize[])
* }} params
*
* @returns {Promise<SuccessResponse>}
*/
public async addContest(params: MethodsProps.AddContestParams): Promise<Responses.SuccessResponse> {
return this.call(
'addContest',
{
appParams: params.appParams,
groupId: params.groupId,
name: params.name,
description: params.description,
startDate: params.startDate,
endDate: params.endDate,
type: params.type,
postId: params.postId,
enableNotifications: params.enableNotifications,
notificationCustomMessage: params.notificationCustomMessage,
prizes: params.prizes ? params.prizes.map((v: any) => v ? v.serialize() : undefined) : undefined
},
Responses.SuccessResponse
)
}
...Весь этот код написан автоматически, это позволяет не отвлекаться на написание клиента и бесплатно получить подсказки названий полей и их типов, если ваша IDE это умеет.
Сгенерировать SDK тоже просто, нужно запустить утилиту asdkgen и передать ей путь до схем и путь, где будут лежать SDK:
node_modules/.bin/asdkgen --s=/Users/altox/Desktop/test-server/scheme --o=/Users/altox/Desktop/test-server/sdkГенерация документации
На генерации SDK я не остановился и написал генерацию документации. Документация достаточно простая, это обычный HTML с описанием запросов, моделей, ответов. Из интересного: для каждой модели есть сгенерированный код для JS, TS и Swift:
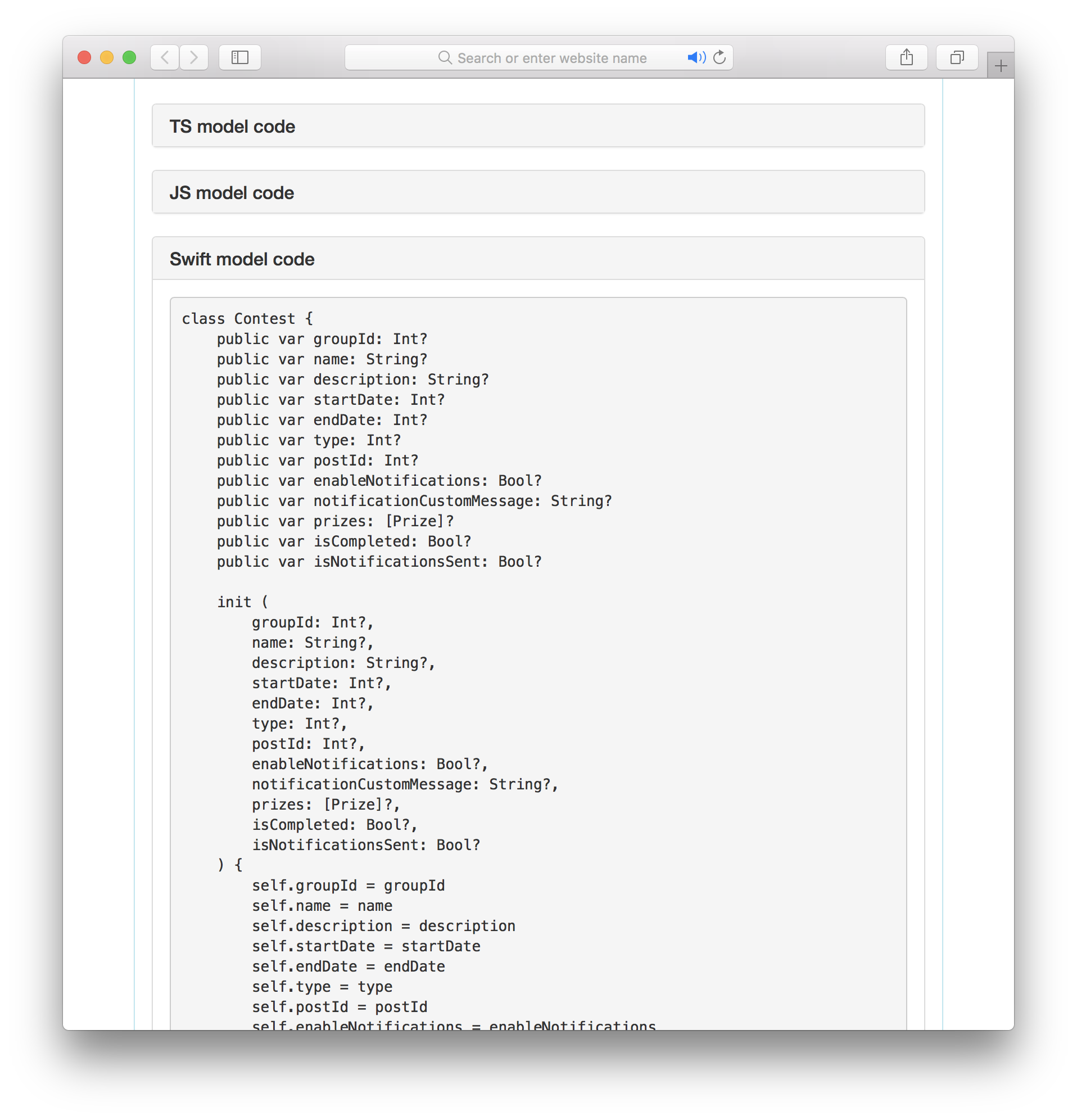
Заключение
Данное решение уже долгое время используется в production, помогает поддерживать старый код, писать новый и не писать код для клиента.
Многим и статья и сам фреймворк может показаться очень очевидным, я это понимаю, другие могут сказать, что такие решения уже есть и даже ткнуть меня носом в ссылку на такой проект. В свою защиту я могу сказать только две вещи:
- я таких решений в свое время не нашел, либо они мне не подошли
- писать свои велосипеды — это весело!
Если кому-то все вышеперечисленное понравилось — добро пожаловать в GitHub.
Комментарии (35)

vlreshet
08.02.2018 02:33+1проблемы начинаются когда express, или любой другой фреймворк, занимает главную роль в вашем проекте, когда вы слишком завязаны на нем.
Ну, как бы, на то он и фреймворк, чтобы завязываться на нём. Чем ваш фреймворк лучше того же Express?
zharikovpro
08.02.2018 12:24> Ну, как бы, на то он и фреймворк, чтобы завязываться на нём.
Это популярный, но не единственный подход. Например, Clean Architecture показывает, как свести зависимость от фреймворка к минимуму.vlreshet
08.02.2018 12:31+2На практике же при попытке максимально абстрагироваться от фреймворка на выходе получается такой адовый набор абстракций (все эти фабрики репозиториев фасадов) что это напоминает отдельный фреймворк, который служит прослойкой между первым, и проектом. Смысл сначала выбирать инструмент, а потом максимально от него отстраняться? Тогда уж лучше с нуля писать, тогда уж точно Clean Architecture получится, минимум зависимостей
mayorovp
08.02.2018 12:42+1Любая абстракция от фреймворка или библиотеки может быть достигнута лишь за счет отказа от части плюшек. Но зачем нужны фреймворки без плюшек?
zharikovpro
08.02.2018 12:50> Но зачем нужны фреймворки без плюшек?
Развивая метафору с плюшками — чтобы обмен веществ не сломался и от ожирения не разбомбило.mayorovp
08.02.2018 12:52+1Вот есть два фреймворка: А и Б, у А плюшек больше.
Зачем выбирать А, но писать без этих плюшек — если можно сразу же выбрать Б для той же цели?

jakobz
08.02.2018 08:53+2Мне кажется сама идея писать сервер на ноде — это следствие хайпа, а низкий порог вхождения — единственное, на чем эта идея до сих пор еще теплится.

jehy
08.02.2018 10:50+1Последние несколько лет пишу бэкенд на ноде для крупных проектов. По факту основные причины такие:
- Высокая производительность. Да, ясное дело, что тот же Go может быть быстрее, но не на порядок. Редко когда разница актуальна.
- Огромная скорость разработки
- Огромная экосистема
- Кроссплатформенность
- Бэкенд и фронтенд команды говорят на одном языке и переиспользуют компоненты
- Лёгкость отладки
- Гибкость и возможность подстроить под свои нужды и парадигмы
А насчёт низкого порога вхождения — как ни странно, это не так. Должно пройти немало времени, чтобы человек начал писать нормально серверный код. Ну или это должен быть разработчик с опытом работы на другом языке — тогда хватает 2-3 месяца.
К сожалению, сейчас примерно одинаковое количество внятных соискателей на Node.JS, Go и, например, питоне. Поэтому в текущей компании мы берём любых хороших разработчиков на несколько наших стеков, а потом собираем из них команды. И то нового коллегу найти получается очень редко — и это при условии отличных условий и зарплаты выше средней по рынку.
Ashot
08.02.2018 17:02+1А насчёт низкого порога вхождения — как ни странно, это не так.
Поддерживаю. Тут скорее приравнивают порог вхождения в JS и в Node.js.
Порог вхождения именно в язык JS – да, он довольно низкий.
Порог вхождения уже готового JS разработчика в Node.js для серверной разработки – да, для такого человека порог вхождения в Node будет ниже, чем в какой-то новый для него ЯП, но этот порог снижается исключительно за счёт уже знания JS.
Говорить про порог вхождения именно в Node.js, как по мне это странно и не очень правильно, он действительно не такой уж и низкий.
justboris
08.02.2018 12:41А что такое хайп? И почему из-за него люди выбирают ноду?
mayorovp
08.02.2018 12:49+1Хайп — это раздуваемый маркетологами вирусный пиар, когда люди переходят на новый продукт или технологию не из-за ее преимуществ, а просто из-за ее популярности.
А еще «хайп» — это Универсальный Контраргумент, используемый динозаврами для оправдания своего сидения на устаревших технологиях.
jakobz
08.02.2018 12:54Ну, хайп это как-то так:
автор ноды> чуваки, я тут прикрутил V8 к сокетам, можно фигачить JS на сервере. Там тредов только нету, но можно колбеками — так даже быстрее. С глобальными переменными только поаккуратнее, ну и прикрутите там чтобы если память утекла и все упало — сервак бы ребутался.
джависты и прочие дотнетчики> Вы там головой-то не поехали часом?
… конференции, доклады, активный пиар про асинхронный подход и перформанс, основанный на искажении реальности…
молодежь> ура! Node — самый быстрый способ писать серваки, колбеки — самый крутой способ писать код
… проходит 8 лет
автор ноды> я тут подумал что не очень была идея. Ну типа с потоками все-таки лучше, и вообще. Я сам на GO спрыгнул, гоп до кучки.
джависты и прочие дотнетчики> Ну наконец у них отлегло-то…
авторы GO> мы тут язык придумали, все быстро пыщ-пыщ, дженериков только нету, но они вам не нужны, чтобы лишний раз головой ну думать. Тулинга только толком нету, ну ничего, напишем. Не на джаве же писать? Хаха!
джависты и прочие дотнетчики> Вы там головой-то не поехали часом?
justboris
08.02.2018 14:39Cудя по вашему описанию, "джависты и прочие дотнетчики" руководствуются философией "если долго сидеть на берегу реки, то можно увидеть, как по ней проплывет труп твоего врага". Подход интересный, но развития никакого.
mayorovp
08.02.2018 14:54На самом деле, кстати, "прочие дотнетчики" давно уже научились использовать ноду для серверного рендера реактовых или ангуляровых шаблонов.
jakobz
08.02.2018 15:09-2У меня бек на дотнете, фронт на реакте, некоторые аппы изоморфные. Но мне в голову не придет идея писать бек на ноде, мне секса с npm и вебпаком за глаза хватает, чтобы оценить качество жизни в мире ноды. Спасибо, не надо. Скорее я бы с радостью фронтендный стек заменил бы на что-то, что не требует наличия ноды в моей жизни, ни в каких ф error is: npm ERR! errno -4048
mayorovp
08.02.2018 15:21+1Что же вы такое с npm делаете?..
staticlab
08.02.2018 16:06Судя по issue, это какая-то специфическая виндовая ошибка. Иногда лечится перезагрузкой системы.
mayorovp
08.02.2018 17:07Да я даже issue найти не могу
UPD: упс, надо было минус убрать :-)
Выглядит как обычная проблема возникающая при попытке пересоздания папки которая открыта другим процессом. Перезагрузка не нужна, надо просто не забывать останавливать сервер и всякие вотчи (webpack, gulp, tsc) во время обновления библиотек.

DarthVictor
09.02.2018 11:19Перезагрузкой не системы, а консоли. И не виндовая ошбика, а ещё досовская – именно в DOS было решено, что открытие файла/папки на чтение блокирует запись (хотя может я путаю и брешу Вам сейчас).
К слову последние три года эта ошбика – едва ли не единственная ошибка, возникавшая у меня при разработке на винде.

eGGshke
08.02.2018 10:46+2Казалось бы, проще — лучше, но т.к. пользуются этими решениями в итоге не всегда опытные разработчики — возникает культ поклонения библиотекам и фреймворкам. Наверное самый очевидный пример — это express.
Исходя из вышеперечисленного, начиная разрабатывать новый проект, я начал с написания некоторого «ядра» сервера, позже оно переносилось в другие проекты, дорабатывалось и в конечно итоге стало фреймврком Airship.
Это как вообще ?)
Не используйте express по назначению — пишите свой Airship ?)
Мне кажется вот в этом проблема ))
Altox Автор
08.02.2018 12:58Я плохо выразился, наверное. Airship — это больше про более высокий уровень абстракции и всякие плюшки, типа кодогенерации. Например ничто не мешает использовать express в рамках Airship, он будет очередным RequestsProvider и будет заниматься только приемом запросов.
eGGshke
08.02.2018 13:18+1Но зачем внедрять его только для этого, если он может полностью заменить, и дать более высокий функционал чем Airship ?)

sky2high0
08.02.2018 14:14Спасибо за статью.
Подход чем-то похож на GraphQL. К нему не присматривались?staticlab
08.02.2018 14:18Причём тут GraphQL?
sky2high0
08.02.2018 22:47В начале статьи описаны следующие требования:
- «автоматическую сериализацию/десериализацию моделей (например, не нужно проверять пришло ли поле с клиента, все проверяется автоматически)» — это в GraphQL из коробки и, в целом, и является одной из основных фишек GraphQL.
- «возможность генерации схемы API» — аналогично есть в GraphQL
- «генерацию документации на основе схемы» — если под документацией является графическое представление имеющегося API, то это решается инструментами типа github.com/gjtorikian/graphql-docs
- «генерацию полностью типизированного SDK для клиента » — есть очень много готовых клиентов для GraphQL на всех популярных платформах, в т.ч. на JS с хорошей интеграцией с React (Apollo или Relay от Facebook). См. github.com/chentsulin/awesome-graphql#lib
В силу того, что GraphQL — это стандартизированная спецификация, существует множество решений «вокруг», которые дают очень большое количество функциональности «на вырост» (типа выемка только тех полей моделей, что были запрошены, подписки на изменения, графическая «песочница» для работы с API (GraphiQL), всевозможные расширения для популярных IDE и т.д.).staticlab
08.02.2018 23:40GraphQL — это только API. Теперь ещё надо серверную часть, которая его будет обслуживать. А тут всё равно нужен фреймворк, не так ли?
sky2high0
09.02.2018 08:27И их есть у сообщества!) Например, для node.js — www.apollographql.com/servers — я его использовал в production, очень всё удобно сделано как express middleware.
А вообще есть не только на JS, вы можете поискать тут по слову server — github.com/chentsulin/awesome-graphql
serf
Прямо Spring MVC получается.
staticlab
У Pleerock получилось ещё спринговее: https://github.com/typestack/routing-controllers, https://github.com/typestack/typedi, https://github.com/typeorm/typeorm