
В рядах инструментов JetBrains пополнение. Мы запускаем открытую бета-версию Datalore — умной веб-среды для анализа и визуализации данных на языке Python.
Машинное обучение уверенно захватывает мир: алгоритмы интеллектуального анализа данных стоят за современными коммерческими разработками и исследованиями. Мы разработали приложение, с которым решать задачи машинного обучения легко и приятно: все необходимые инструменты data science доступны из коробки, а умный редактор кода на Python облегчает процесс анализа данных.

Возможности Datalore
Во-первых, как и все продукты JetBrains, Datalore — это умный редактор кода: с автодополнениями, подсветкой синтаксиса и инспекциями.

Самая классная фича редактора кода — интеншны (intentions). В зависимости от задачи, внизу окна редактирования появляется релевантный интеншн — “load dataset”, “train test split” “select model” и т.д. Выберите нужное действие, и код для подгрузки датасета или модели автоматически сгенерируется в ячейке редактора. А результаты сразу же отобразятся в окне вывода.
Автодополнения и интеншны облегчают работу в редакторе кода. Можно перестать беспокоиться и сосредоточиться на анализе данных и подборе параметров модели.
Во-вторых, мы поддерживаем инкрементальные вычисления: при подборе параметров, замене одной строки или добавлении ячейки не нужно запускать весь воркбук с нуля. Datalore автоматически запускает вычисление только тех операций, которые зависели от правок. С учетом того, что все вычисления запускаются автоматически, в окне вывода всегда будут самые актуальные цифры и таблицы.
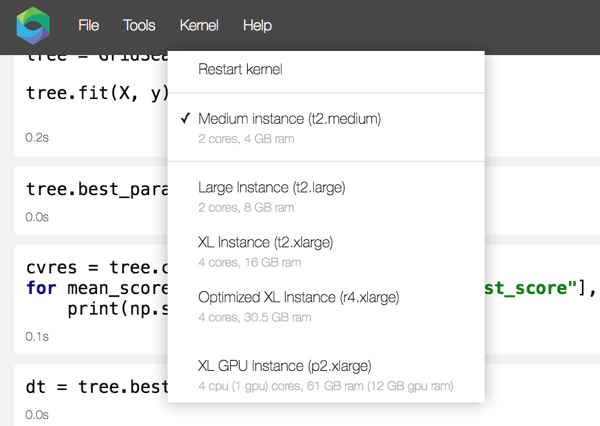
Кроме этого, Datalore дает доступ к разным вычислительным мощностям в зависимости от задачи.
В-третьих, мы собрали основные инструменты data science в одном веб-приложении: от базовых библиотек для работы с данными, библиотеки алгоритмов машинного обучения sklearn и алгоритмов deep learning pytorch до мощных инструментов для визуализации.
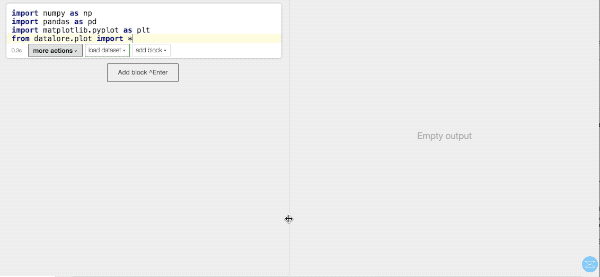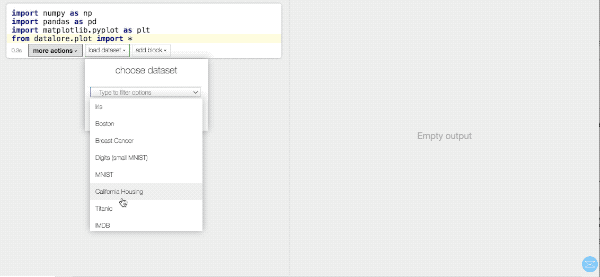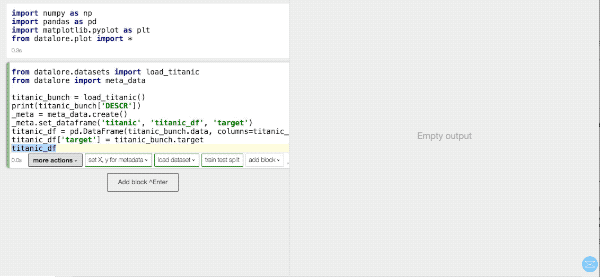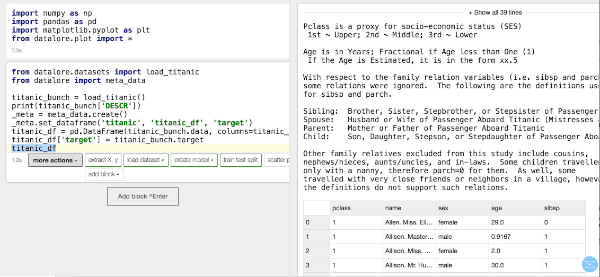
Инструменты действительно мощные. Наша библиотека datalore.plot — это реализованный на Питоне аналог библиотеки ggplot языка R. Модуль datalore.geo_maps разработан специально для создания интерактивных карт.

Если вы только начинаете работать с данными, подгрузите один из предустановленных датасетов (Iris, Titanic, MNIST) и поиграйте с разными моделями и параметрами. А загрузка своих данных возможна через встроенный файловый менеджер: он сохраняет исходный .csv-файл и конвертирует его в pandas-датафрейм по нажатию соответствующего интеншна.
Datalore сохраняет весь процесс анализа в облаке. Работа начинается с удобного файлового хранилища всех воркбуков. Отсюда же можно поделиться c коллегами ссылкой на воркбук и решать задачу вместе: Datalore поддерживает одновременную работу нескольких пользователей.

Изменения в воркбуке сохраняются автоматически (и никаких безнадежно утраченных данных). Если что-то пошло не так, можно откатиться к предыдущим вариантам анализа и отследить хронику изменений с помощью встроенной системы контроля версий.
Лицензирование
В режиме public beta Datalore доступен по бесплатному коммьюнити-плану. В дальнейшем плата за использование будет зависеть от объема загруженных данных и использованных мощностей.
Что дальше?
Регистрируйтесь на datalore.io и подгружайте первый датасет!
Жаждем услышать мнение о Datalore от всех, кто часто и придирчиво работает с задачами машинного обучения: аналитиков, data scientists, исследователей и студентов. Мы хотим сделать самый удобный инструмент для интеллектуального анализа данных и с нетерпением ждем ваши отзывы. Пишите на наш форум, чтобы оставить комментарий о продукте и связаться с нами и другими пользователями.
upd 15.02 Если вы запустили сложный алгоритм, использовали более мощные вычислительные инстансы и получили сообщение «Surcharge limit reached» — пожалуйста, расскажите на форуме, какую задачу вы решали, и мы пришлем вам код для активации дополнительного времени работы с инстансами.
Комментарии (33)


Artgor
12.02.2018 17:48Стало интересно по поводу оплаты — насколько сможете конкурировать с Amazon/ Google Cloud?
Возможна ли самостоятельная установка необходимых библиотек?
Ну и в целом, в чем преимущество перед тем же Colaboratory?igRo
12.02.2018 18:19+1Amazon и Google Cloud это поставщики вычислительных мощностей, собственно мы в качестве вычислительных агентов сейчас используем инстансы первого (мы сохранили именование типов для удобства пользователей). Datalore же в свою очередь предоставляет сверх этого умный редактор, инкрементальное перевычисление и другие инструменты.
Установка библиотек доступна из conda, pip и git репозиториев (в т.ч. приватных).

Arseny_Info
12.02.2018 19:31+2Честно говоря, подход разочаровал. Хотелось бы что-то, больше похожее на PyCharm — нативный клиент, поддержку версионирования, всякие привычные фичи любой IDE типа jump to definition.
Анализ данных — это не только про «подобрать модельку» или «посмотреть на графики».igRo
12.02.2018 19:37Основные привычные фичи есть (jump to, extract, rename, show sources, help и многие другие), если чего то не хватает — пожалуйста пишите, будем рады обратной связи! Ознакомиться со списком шорткатов можно по нажатию shift+F1

gurinderu
12.02.2018 23:49+1Мне не совсем понятно, чем это лучше того же Jupiter или Apache Zeppelin? Почему только python и только на вашем железе? Совсем неоднозначный продукт пока что выходит
igRo
13.02.2018 00:07Основные отличия Datalore от Jupyter и проектов на нем основанных — это инкрементальное перевычисление ячеек (блоков) и наличие интеншнов — и то и то лучше попробовать вживую, кроме этого мы старались сделать редактор более удобным и функциональным, поэтому мы будем рады, если вы поделитесь своим опытом использования продукта.
ZoyaCherkasova Автор
13.02.2018 00:10В первую очередь, поддержкой «умного» кодирования: в тот же Jupiter весь код для анализа нужно писать ручками или копировать-вставлять. В Datalore все, что вы пишете в редакторе, анализируется — а дальше и автодополнение на ходу, и быстрый поиск и переименование объектов во всем коде одним кликом, и те же интеншны — когда для рутинных действий не нужно ничего прописывать, можно нажать одну кнопочку, и редактор сам напишет код с учетом ваших данных и переменных.
И прочая работа редактора кода, направленная на то, чтобы человек как можно больше думал про специфику задачи машобуча и как можно меньше отвлекался на кодерскую рутину. Если редактор кода в этом помогает — почет и хвала такому редактору кода)
Но да, есть куда расти.
А Python — лидирующий язык data science (например, пруф), с ним и работаем.Roman_Kh
13.02.2018 01:59В jupyter'е тоже есть автодополнение и поиск. Переименование в реальной жизни датасаентолога крайне редко когда требуется, чтобы этим можно было гордиться.
Интеншены — захардкоженное баловство. Ни один из них в реальной работе никогда не требуется.
Редактор кода вообще никогда не был проблемой для анализа данных. Так что вы совершенно зря педалируете эту "редакторовость". Не цепляет совершенно.

philipto
14.02.2018 12:20+2А вот для человека, впервые увидевшего Datalore, интеншены — подспорье, с ними проще понять, когда и как тут данные загружать, как нарисовать график и т.п. — даже если забыл (или не знал) как это правильно делать в Python. Т.е. учить на этом людей проще, по-моему. Или нет, как считаете?
shabunc
14.02.2018 15:46+1Наша задача — это не только дать удобный инструмент тем, кто уже называет себя дата-сайентистом, но и снизить порог вхождения для людей, которые себя таковыми пока не считают. Есть целый класс хороших статистиков, физиков, биоинформатиков и представителей других профессий, чья работа сопряжена с обработкой больших массивов информации. Это прекрасные профессионалы в своей сфере, но совсем не обязательно — хардкорные программисты вообще и питонисты в частности.
Им интеншены помогут. Но помогут они и тем, кто прекрасно умеет писать код, просто хочет автоматизировать этот процесс.
ne-bo
13.02.2018 11:39-1Я люто ненавижу jupyter notebook'и, но они повсюду, пойду гляну, вдруг Jet Brains хоть немного сделало их лучше.
Но идеально было бы нормально работать с ноутбуками в pycharm, конечно.
unih
13.02.2018 14:24+1Продукты JBrain обычно очень радуют, особенно длинными дедлайновыми ночами.
То что видел симпатично, но как то… не совсем то без чего жить тяжело и тоскливо.
1) Хочу оффлайн или возможность развернуть на своем железе. Нынешняя контора принципиально ничего в облака не кладет. Да и перевод всего нашего безобразия в облако, с рилтаймом, блекждеком и девочками — задача чуть более чем нетривиальная.
2) Пока не понял, как эта штука дружит со спарк зоопарком.
3) Опять же, может пока не разобрался как это сделать, но я хочу запустить кучу моделек и уйти пить кофий. А потом смотреть на красиво оформленные результаты.
Ну и то что сверху набросали, типа приличного контроля версий, командной работы и все такое.
Все предыдущие ваши продукты однозначно говорят — сделаете, допилите, будет счастье.
xkrt
14.02.2018 11:42Для моего проекта так же критично развернуть продукт на нашем железе и подружить его со Spark'ом. Без этого выглядит интересно, но бесполезно.

i_osipov
14.02.2018 11:49Первое, что бросилось в глаза после Jupiter — отсутствие command mode и введение кучи шорткатов. Так проще довести до «беты» или не планировали добавлять?
ZoyaCherkasova Автор
14.02.2018 13:40У нас сейчас нет планов разделять воркфлоу на “edit mode” и “command mode” — хочется развивать интерфейс в том направлении, чтобы не пришлось помнить ни про шорткаты ни про то, находишься ли ты сейчас в режиме редактирования.
philipto
14.02.2018 12:13+1А я вот Datalore люблю не совсем за то, что в статье рассказано. В Datalore есть, например, поддержка LaTeX. Это значит, что любой студент или научный работник, который делает исследование с использованием каких-то данных, может:
1) писать статью и код в одном окне,
2) хранить свои данные в Datalore (лишняя точка бэкапа не помешает, студенты и ученые на моих глазах не раз теряли данные когда ноутбук неожиданно сдох — да-да, несмотря на 2018 год уже),
3) когда написали и отладили код, иметь актуальный код прямо в статье + актуальную версию данных в облаке, все в одном workbook => нет проблем потом повторить исследование, если понадобится, или отдать все коллегам для проверки,
4) экспортировать (вот этого пока нет, а хотелось бы) результат в .pdf и отправить сразу в журнал для публикации.
Упомянутая в статье возможность отрисовывать данные на карте — это значительно круче, чем может показаться из короткого описания. Вот, например, у вас есть данные по местам, где произошли преступления в городе. Вы можете отрисовать crime heat map с точностью до дома, и посмотреть, какие районы в городе действительно опасны, а какие незаслуженно имеют плохую репутацию. И так по любому городу в мире, для которого есть такая статистика с геопривзякой. И делать динамические heat map, чтобы друг за другом показывались карты за разные годы, чтобы видеть, как в каком-нибудь, скажем, East Palo Alto становится менее стрёмно по мере постройки рядом все новых и новых корпусов Facebook.
Так что Datalore, на самом деле, может пригодиться не только тем, кто имеет дело с очень большими и очень секретными данными (проблема развертывания onsite/offline для них как раз очевидна), но и (пока еще) довольно широкой научной общественности, причем не только в условной Швейцарии.Roman_Kh
14.02.2018 13:21+1В jupyter'е есть и LaTeX, и экспорт в PDF, и рисование каких угодно карт, и статьи народ в нем пишет (научные и не очень), и блоги делает.
А еще можно несложно интегрировать jupyter и overleaf и получить отличный инструмент для создания и публикации научных статей.
Roman_Kh
Эта штука работает только на вашем сайте и на своих мощностях ее не развернуть?
Что есть из инструментов командной работы? Разграничение доступа? Код-ревью? Комментарии? Ветки? Пулл-реквесты?
igRo
На текущий момент вычисление производится на облачных агентах, локально развернуть возможности нет.
Для совместной работы у нас есть общий доступ к папкам и документам — позволяет видеть курсор друг друга и наблюдать изменения в реальном времени, при этом уровень доступа настраивается индивидуально для каждого пользователя (полный доступ, только редактирование или только чтение). Версионирование реализовано при помощи истории изменений, пулл-реквестов и коммитов нет. В редакторе можно вставлять python комментарии и вставлять заметки используя markdown блоки или docstring.
Roman_Kh
Пока это все больше похоже на забавное баловство, для серьезной работы с данными не пригодное вообще.
Чтобы сделать простенькую, но полезную модель надо написать 5000 строк кода, потом 28000 раз их отредактировать и в конце-концов 4500 строк стереть — история изменений станет нечитаемой, в ней ничего не получится найти.
Нужны нормальные коммиты, теги, версии.
Видеть курсор вообще не надо. Зато надо уметь сливать куски кода, написанные разными людьми.
Также нужна нормальная работа с python-модулями, чтобы при изменении не надо было перезапускать кернел и все ячейки.
Что с распределенной работой? Сможете сделать "удаленные" ячейки, каждая из которых запускается на отдельном сервере со своими данными? А в ноутбуке пусть будет виден прогресс.
Пока данных мало, то и проблем с анализом нет, а когда датасеты в сотнях и тысячах Гб, что вы можете предложить? Добавьте встроенный функционал по (фоновому) копированию данных на вычислительные инстансы.
Да и про запуск инстансов стоит внимательно подумать: сразу ставить драйвера, устанавливать пакеты, загружать и запускать докер-контейнеры.
igRo
Для упрощения работы с историей у нас есть возможность создавать чекпоинты и просматривать изменения только по ним, в остальном мы пока не стремимся заменить полноценную систему контроля версий — но при необходимости мы поддерживаем установку библиотек из git репозитория.
Запуск вычислительного агента с дефолтным набором библиотек происходит для пользователя в фоне и не требует от него никаких действий.
По остальным пунктам идет работа, но деталей пока рассказать не могу.
ZoyaCherkasova Автор
Во-первых, спасибо за развернутый отзыв. Честно.
Во-вторых, все потому «похоже на забавное баловство», что бета-версия. Чтобы можно было работать с серьезными данными — бета-версия теперь открыта, и нам нужны развернутая критика вроде вашего комментария. Поэтому честное спасибо.
В-третьих, по остальным пунктам идет серьезная работа, и вы подкинули нам пару идей в эту работу по улучшению функциональности.
Cистема контроля версий, как упомянул коллега, действительно базовая — для веб-приложения (а не полноценной IDE) в настоящем масштабе более продвинутый вариант не актуален, мы сосредоточены на других задачах. В том числе всего, связанного с нормальным функционированием инстансов. Stay tuned (:
Arseny_Info
Собственно, отсюда и скепсис: почему веб-приложение, а не полноценная IDE?
ZoyaCherkasova Автор
Чтобы объединить в одном продукте поддержку кодирования, как это умеют другие продукты jb, и онлайн-доступ к вычислительным мощностям — не у каждого под рукой есть ядра GPU, увы, чтобы хоба и анализировать сотни и тысячи гигабайт данных.
alex4321
Как будто приконнектиться к удалённому, допустим jupyter-у можно только из браузера.
В любом случае — удачи.
Roman_Kh
Пока этот продукт выглядит как "Я менеджер по маркетингу, но теперь я называю себя дата-саентистом"

Для работы одного дата-саентиста вполне достаточно jupyterlab'а. Так что если вы хотите сделать удобный продукт для дата-саентистов, то datalore надо переписывать почти полностью.
Как видите, редактора в списке нет совсем, потому что подойдет почти любой.
Если в восьмой версии выпустите автоматическое переименование, то мы порадуемся, но только если в восьмой. А в первой не надо.
Вот примеры реальных ноутбуков дата-саентистов:
https://github.com/analysiscenter/cardio/blob/master/cardio/models/dirichlet_model/dirichlet_model_training.ipynb
https://github.com/analysiscenter/cardio/blob/master/tutorials/II.Pipelines.ipynb
https://github.com/analysiscenter/radio/blob/master/tutorials/RadIO.IV.ipynb
Поработайте с ними и поймете, что проблемы дата-саентистов вообще не там, где вы думали. А им все еще нужна удобная среда для работы. И это даже близко не datalore.
ZoyaCherkasova Автор
Что же, до зрелой среды для работы нам еще расти и расти. Датасаентисты нашей команды присмотрятся к примерам, которые вы скинули — будем учитывать, куда работать с такими пожеланиями и нашими ресурсами.
А вы уже потыкали в Datalore или пока бегло ознакомились? Список исчерпывающий, но было бы жутко интересно узнать на конкретных местах, где ваш опыт работы с данными наткнулся на пробелы в продукте.
Arseny_Info
11. Инфраструктура для хранения результатов экспериментов (что-то вроде github.com/mitdbg/modeldb)
xander27
Про возможность локального развертывания — в некоторых областях, без нее будет достаточно сложно, даже без учета объема. Например в финтехе, нужно будет, как минимум, каждый раз обфусцировать часть данных, иначе можно очень больно получить пинка от безопасников. Да и даже с учетом этого, не факт что разрешат.
ZoyaCherkasova Автор
Могу сказать только что 1) мы думаем об этом, 2) надо с чего-то начать и смотреть, чего не хватает пользователям. Точка зрения от специфики задач финтеха — интересный аспект, спасибо, что поделились!